 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Primary and Secondary Social Media Source Identification
May 05, 2021
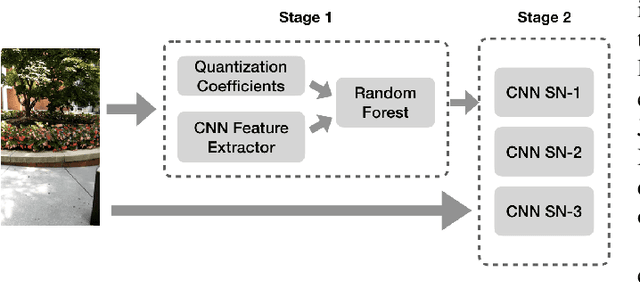
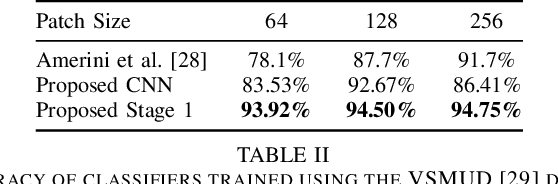

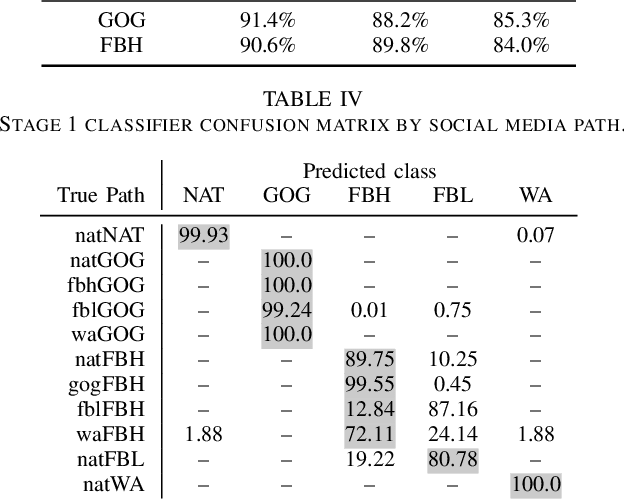
Social networks like Facebook and WhatsApp have enabled users to share images with other users around the world. Along with this has come the rapid spread of misinformation. One step towards verifying the authenticity of an image is understanding its origin, including it distribution history through social media. In this paper, we present a method for tracing the posting history of an image across different social networks. To do this, we propose a two-stage deep-learning-based approach, which takes advantage of cascaded fingerprints in images left by social networks during uploading. Our proposed system is not reliant upon metadata or similar easily falsifiable information. Through a series of experiments, we show that we are able to outperform existing social media source identification algorithms. and identify chains of social networks up to length two with over over 84% accuracy.
Control Design of Autonomous Drone Using Deep Learning Based Image Understanding Techniques
Apr 28, 2020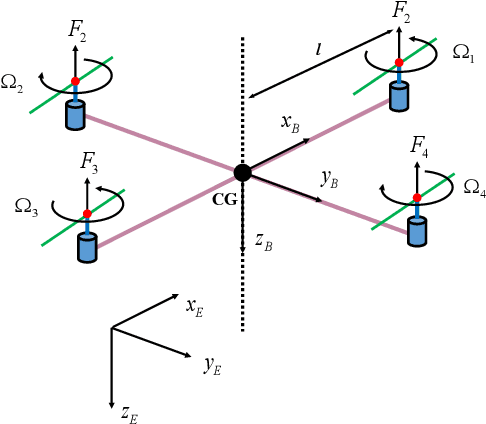
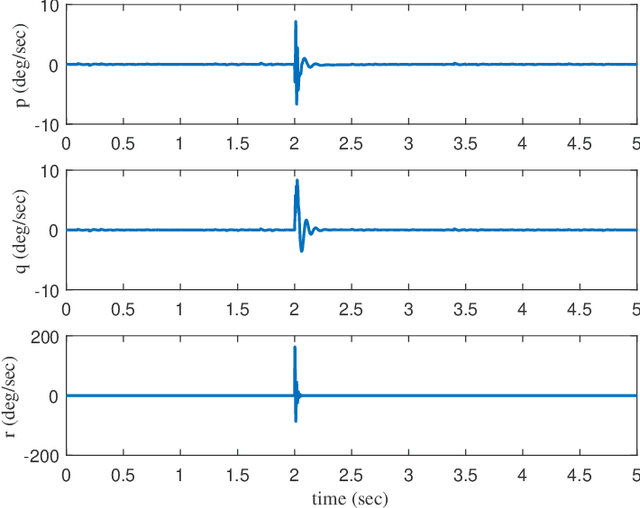
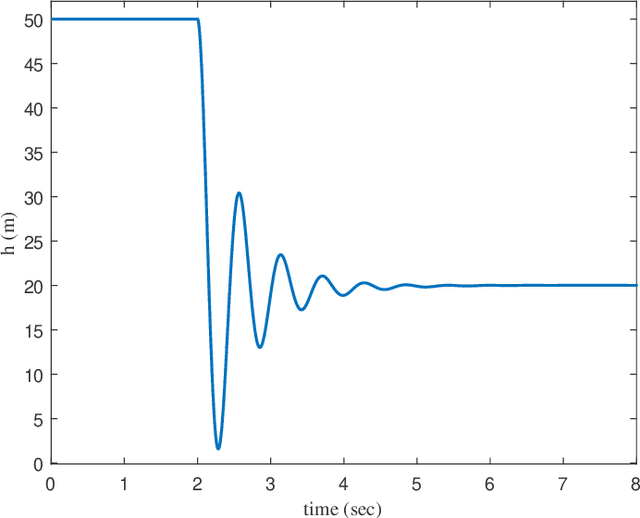
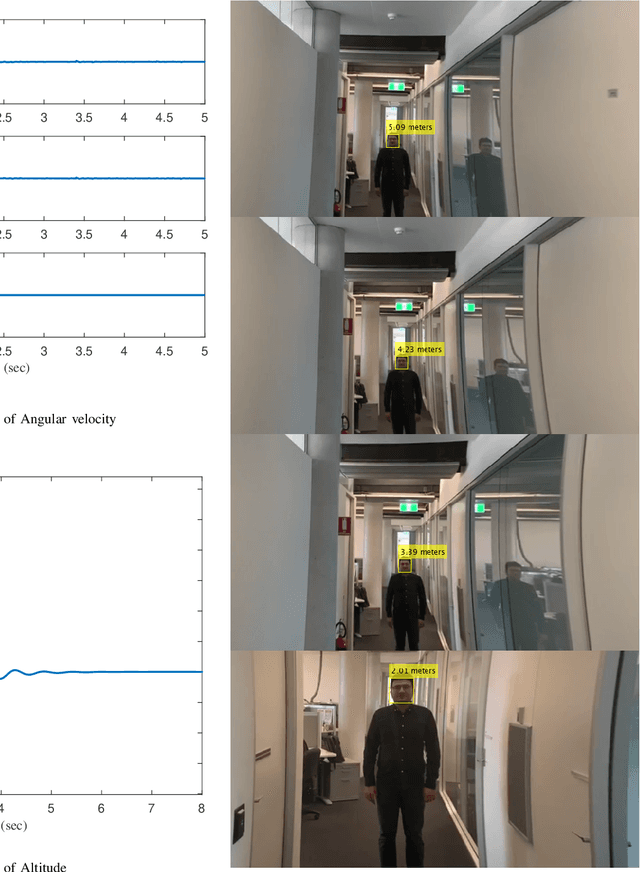
This paper presents a new framework to use images as the inputs for the controller to have autonomous flight, considering the noisy indoor environment and uncertainties. A new Proportional-Integral-Derivative-Accelerated (PIDA) control with a derivative filter is proposed to improves drone/quadcopter flight stability within a noisy environment and enables autonomous flight using object and depth detection techniques. The mathematical model is derived from an accurate model with a high level of fidelity by addressing the problems of non-linearity, uncertainties, and coupling. The proposed PIDA controller is tuned by Stochastic Dual Simplex Algorithm (SDSA) to support autonomous flight. The simulation results show that adapting the deep learning-based image understanding techniques (RetinaNet ant colony detection and PSMNet) to the proposed controller can enable the generation and tracking of the desired point in the presence of environmental disturbances.
A framework for the automation of testing computer vision systems
May 10, 2021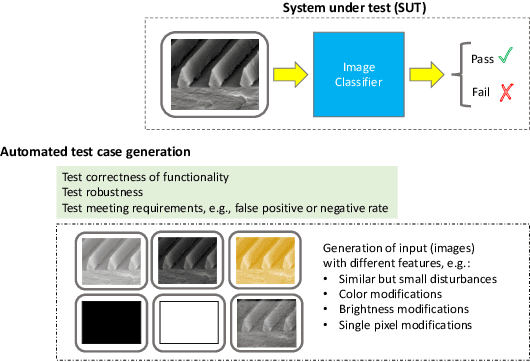

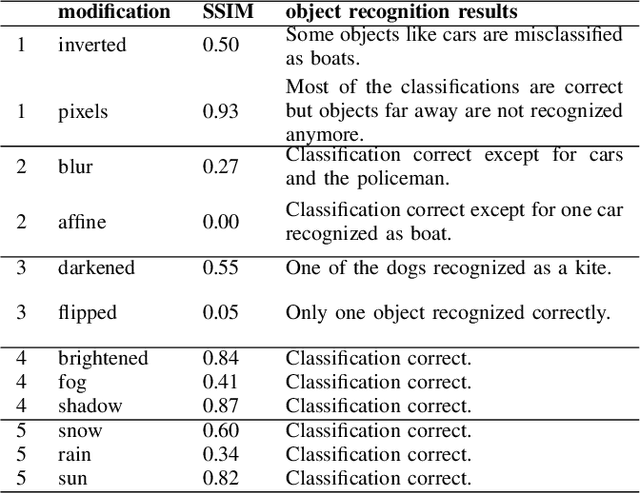
Vision systems, i.e., systems that allow to detect and track objects in images, have gained substantial importance over the past decades. They are used in quality assurance applications, e.g., for finding surface defects in products during manufacturing, surveillance, but also automated driving, requiring reliable behavior. Interestingly, there is only little work on quality assurance and especially testing of vision systems in general. In this paper, we contribute to the area of testing vision software, and present a framework for the automated generation of tests for systems based on vision and image recognition. The framework makes use of existing libraries allowing to modify original images and to obtain similarities between the original and modified images. We show how such a framework can be used for testing a particular industrial application on identifying defects on riblet surfaces and present preliminary results from the image classification domain.
Face Identification Proficiency Test Designed Using Item Response Theory
Jun 22, 2021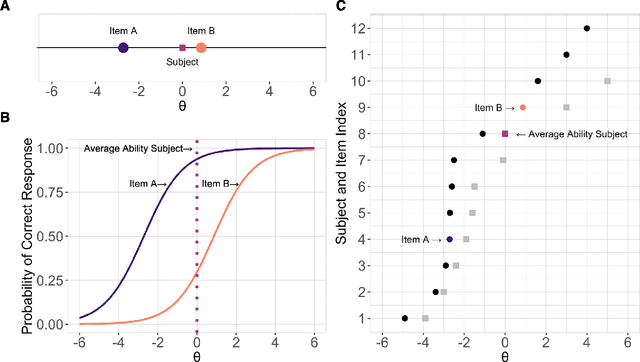
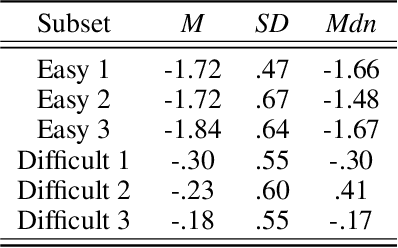
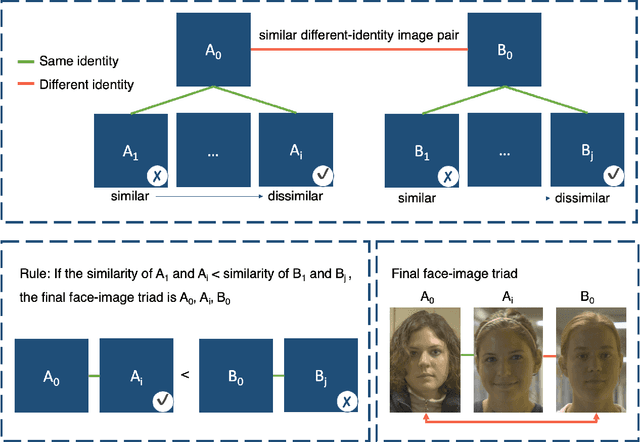
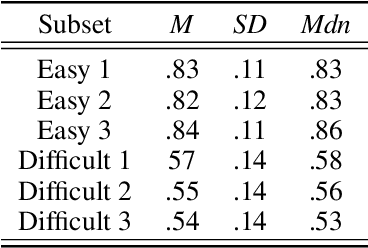
Measures of face identification proficiency are essential to ensure accurate and consistent performance by professional forensic face examiners and others who perform face identification tasks in applied scenarios. Current proficiency tests rely on static sets of stimulus items, and so, cannot be administered validly to the same individual multiple times. To create a proficiency test, a large number of items of "known" difficulty must be assembled. Multiple tests of equal difficulty can be constructed then using subsets of items. Here, we introduce a proficiency test, the Triad Identity Matching (TIM) test, based on stimulus difficulty measures based on Item Response Theory (IRT). Participants view face-image "triads" (N=225) (two images of one identity and one image of a different identity) and select the different identity. In Experiment 1, university students (N=197) showed wide-ranging accuracy on the TIM test. Furthermore, IRT modeling demonstrated that the TIM test produces items of various difficulty levels. In Experiment 2, IRT-based item difficulty measures were used to partition the TIM test into three equally "easy" and three equally "difficult" subsets. Simulation results indicated that the full set, as well as curated subsets, of the TIM items yielded reliable estimates of subject ability. In summary, the TIM test can provide a starting point for developing a framework that is flexible, calibrated, and adaptive to measure proficiency across various ability levels (e.g., professionals or populations with face processing deficits)
Fully Neural Network Mode Based Intra Prediction of Variable Block Size
Aug 05, 2021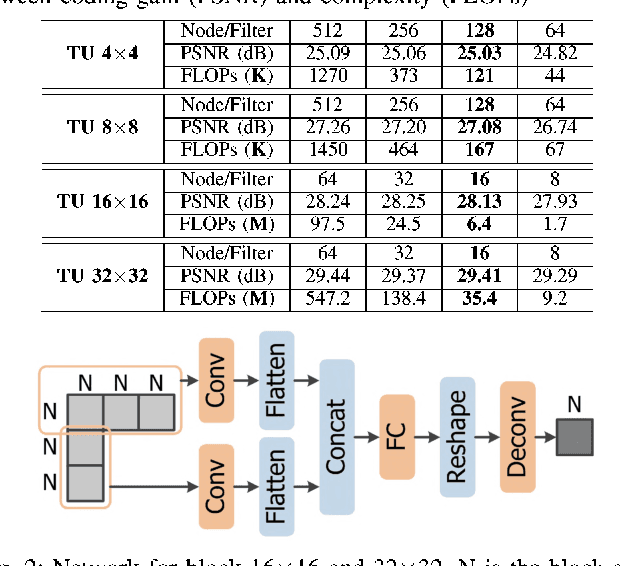

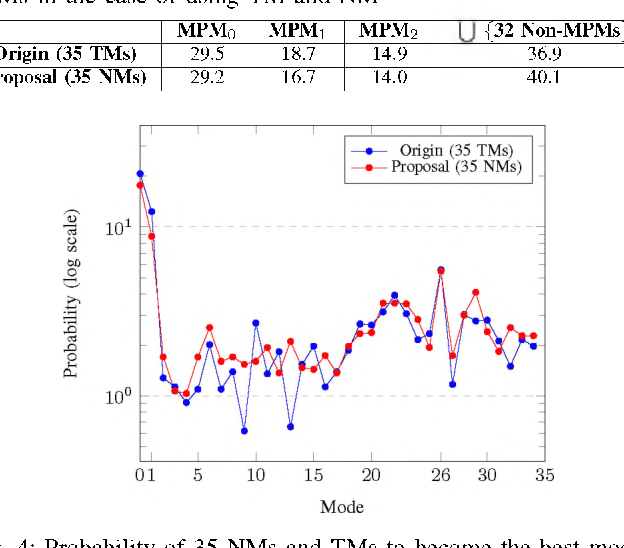
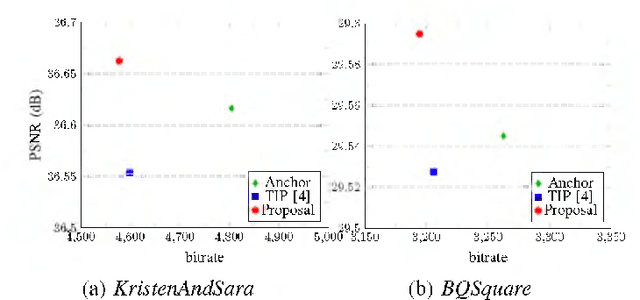
Intra prediction is an essential component in the image coding. This paper gives an intra prediction framework completely based on neural network modes (NM). Each NM can be regarded as a regression from the neighboring reference blocks to the current coding block. (1) For variable block size, we utilize different network structures. For small blocks 4x4 and 8x8, fully connected networks are used, while for large blocks 16x16 and 32x32, convolutional neural networks are exploited. (2) For each prediction mode, we develop a specific pre-trained network to boost the regression accuracy. When integrating into HEVC test model, we can save 3.55%, 3.03% and 3.27% BD-rate for Y, U, V components compared with the anchor. As far as we know, this is the first work to explore a fully NM based framework for intra prediction, and we reach a better coding gain with a lower complexity compared with the previous work.
Proba-V-ref: Repurposing the Proba-V challenge for reference-aware super resolution
Jan 26, 2021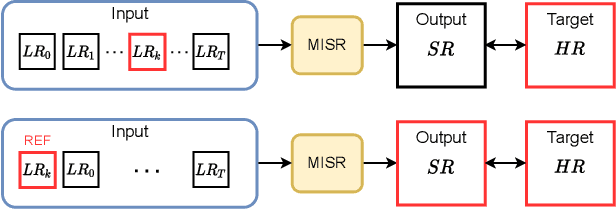

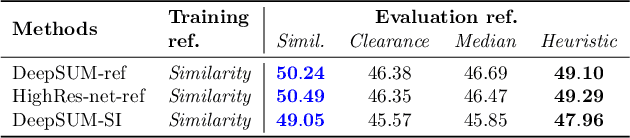

The PROBA-V Super-Resolution challenge distributes real low-resolution image series and corresponding high-resolution targets to advance research on Multi-Image Super Resolution (MISR) for satellite images. However, in the PROBA-V dataset the low-resolution image corresponding to the high-resolution target is not identified. We argue that in doing so, the challenge ranks the proposed methods not only by their MISR performance, but mainly by the heuristics used to guess which image in the series is the most similar to the high-resolution target. We demonstrate this by improving the performance obtained by the two winners of the challenge only by using a different reference image, which we compute following a simple heuristic. Based on this, we propose PROBA-V-REF a variant of the PROBA-V dataset, in which the reference image in the low-resolution series is provided, and show that the ranking between the methods changes in this setting. This is relevant to many practical use cases of MISR where the goal is to super-resolve a specific image of the series, i.e. the reference is known. The proposed PROBA-V-REF should better reflect the performance of the different methods for this reference-aware MISR problem.
Learning to Separate Multiple Illuminants in a Single Image
Nov 29, 2018



We present a method to separate a single image captured under two illuminants, with different spectra, into the two images corresponding to the appearance of the scene under each individual illuminant. We do this by training a deep neural network to predict the per-pixel reflectance chromaticity of the scene, which we use in conjunction with a previous flash/no-flash image-based separation algorithm to produce the final two output images. We design our reflectance chromaticity network and loss functions by incorporating intuitions from the physics of image formation. We show that this leads to significantly better performance than other single image techniques and even approaches the quality of the two image separation method.
Can self-training identify suspicious ugly duckling lesions?
May 15, 2021
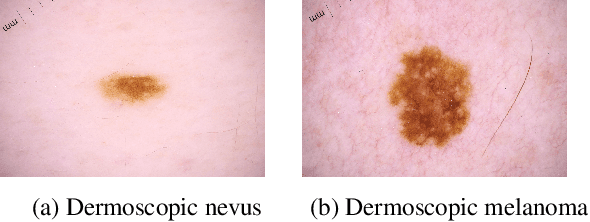

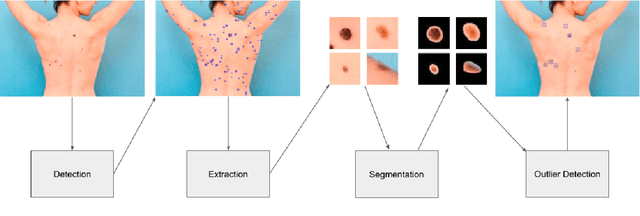
One commonly used clinical approach towards detecting melanomas recognises the existence of Ugly Duckling nevi, or skin lesions which look different from the other lesions on the same patient. An automatic method of detecting and analysing these lesions would help to standardize studies, compared with manual screening methods. However, it is difficult to obtain expertly-labelled images for ugly duckling lesions. We therefore propose to use self-supervised machine learning to automatically detect outlier lesions. We first automatically detect and extract all the lesions from a wide-field skin image, and calculate an embedding for each detected lesion in a patient image, based on automatically identified features. These embeddings are then used to calculate the L2 distances as a way to measure dissimilarity. Using this deep learning method, Ugly Ducklings are identified as outliers which should deserve more attention from the examining physician. We evaluate through comparison with dermatologists, and achieve a sensitivity rate of 72.1% and diagnostic accuracy of 94.2% on the held-out test set.
Matching Disparate Image Pairs Using Shape-Aware ConvNets
Nov 24, 2018



An end-to-end trainable ConvNet architecture, that learns to harness the power of shape representation for matching disparate image pairs, is proposed. Disparate image pairs are deemed those that exhibit strong affine variations in scale, viewpoint and projection parameters accompanied by the presence of partial or complete occlusion of objects and extreme variations in ambient illumination. Under these challenging conditions, neither local nor global feature-based image matching methods, when used in isolation, have been observed to be effective. The proposed correspondence determination scheme for matching disparate images exploits high-level shape cues that are derived from low-level local feature descriptors, thus combining the best of both worlds. A graph-based representation for the disparate image pair is generated by constructing an affinity matrix that embeds the distances between feature points in two images, thus modeling the correspondence determination problem as one of graph matching. The eigenspectrum of the affinity matrix, i.e., the learned global shape representation, is then used to further regress the transformation or homography that defines the correspondence between the source image and target image. The proposed scheme is shown to yield state-of-the-art results for both, coarse-level shape matching as well as fine point-wise correspondence determination.
Splitfed learning without client-side synchronization: Analyzing client-side split network portion size to overall performance
Sep 19, 2021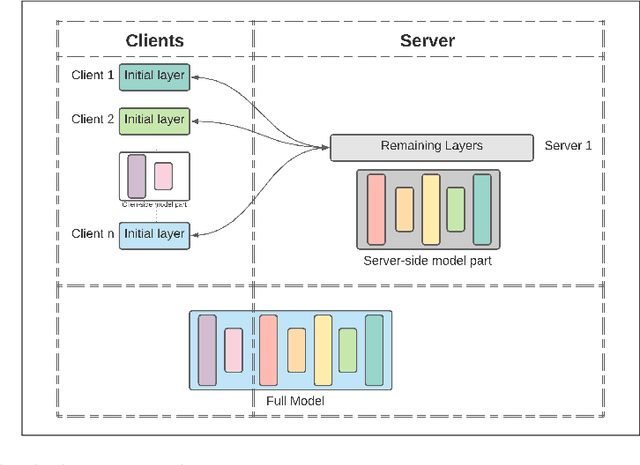
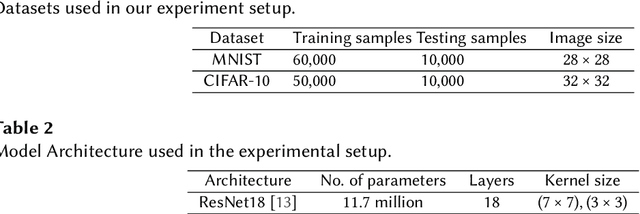
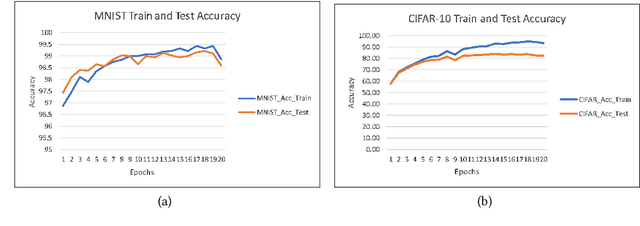
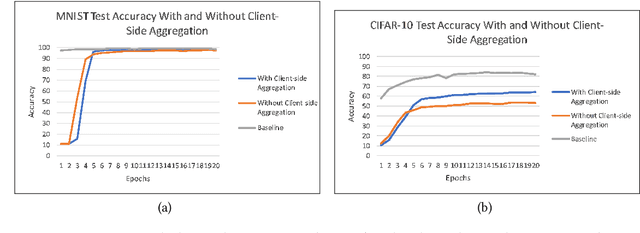
Federated Learning (FL), Split Learning (SL), and SplitFed Learning (SFL) are three recent developments in distributed machine learning that are gaining attention due to their ability to preserve the privacy of raw data. Thus, they are widely applicable in various domains where data is sensitive, such as large-scale medical image classification, internet-of-medical-things, and cross-organization phishing email detection. SFL is developed on the confluence point of FL and SL. It brings the best of FL and SL by providing parallel client-side machine learning model updates from the FL paradigm and a higher level of model privacy (while training) by splitting the model between the clients and server coming from SL. However, SFL has communication and computation overhead at the client-side due to the requirement of client-side model synchronization. For the resource-constrained client-side, removal of such requirements is required to gain efficiency in the learning. In this regard, this paper studies SFL without client-side model synchronization. The resulting architecture is known as Multi-head Split Learning. Our empirical studies considering the ResNet18 model on MNIST data under IID data distribution among distributed clients find that Multi-head Split Learning is feasible. Its performance is comparable to the SFL. Moreover, SFL provides only 1%-2% better accuracy than Multi-head Split Learning on the MNIST test set. To further strengthen our results, we study the Multi-head Split Learning with various client-side model portions and its impact on the overall performance. To this end, our results find a minimal impact on the overall performance of the model.