 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On Out-of-distribution Detection with Energy-based Models
Jul 03, 2021
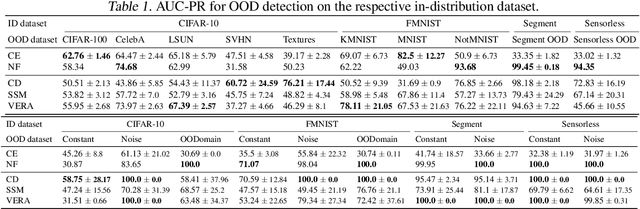
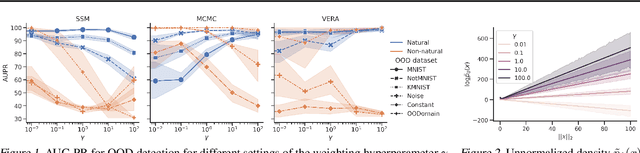
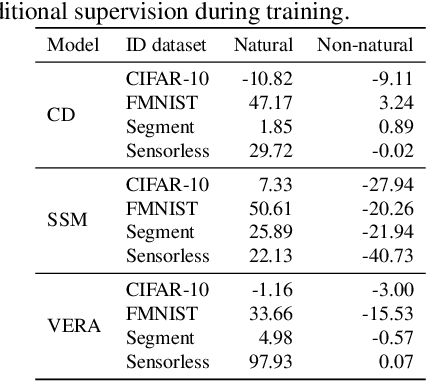
Several density estimation methods have shown to fail to detect out-of-distribution (OOD) samples by assigning higher likelihoods to anomalous data. Energy-based models (EBMs) are flexible, unnormalized density models which seem to be able to improve upon this failure mode. In this work, we provide an extensive study investigating OOD detection with EBMs trained with different approaches on tabular and image data and find that EBMs do not provide consistent advantages. We hypothesize that EBMs do not learn semantic features despite their discriminative structure similar to Normalizing Flows. To verify this hypotheses, we show that supervision and architectural restrictions improve the OOD detection of EBMs independent of the training approach.
Discriminative Triad Matching and Reconstruction for Weakly Referring Expression Grounding
Jun 08, 2021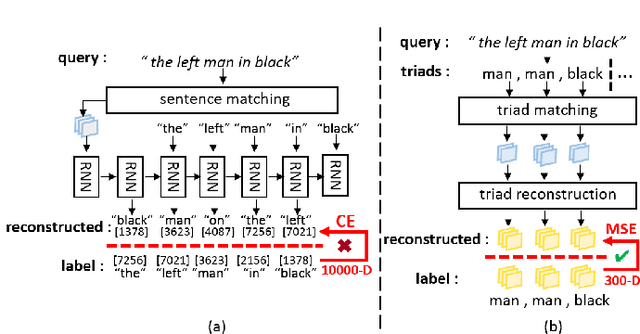
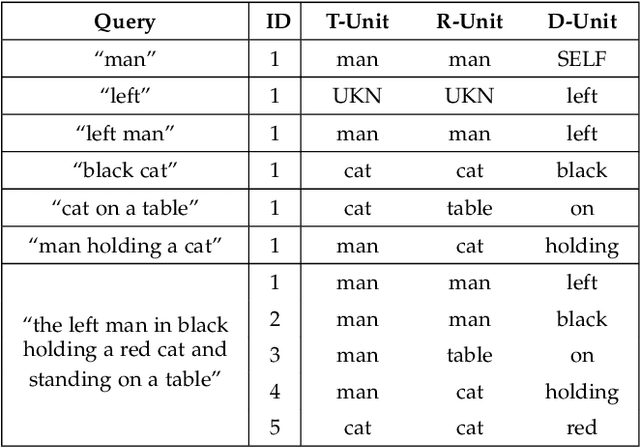
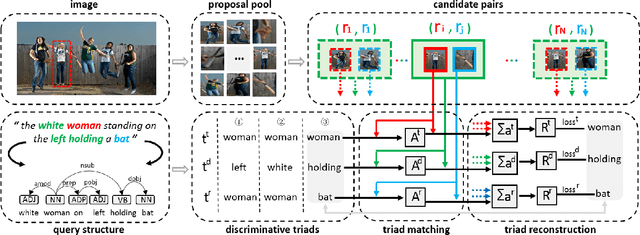
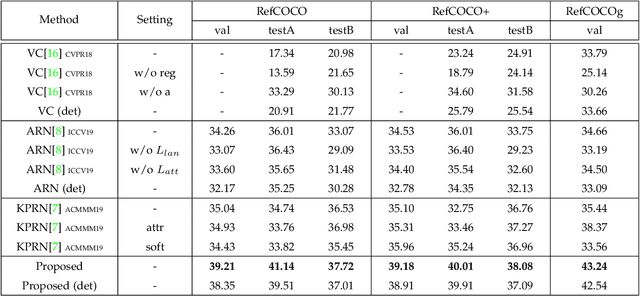
In this paper, we are tackling the weakly-supervised referring expression grounding task, for the localization of a referent object in an image according to a query sentence, where the mapping between image regions and queries are not available during the training stage. In traditional methods, an object region that best matches the referring expression is picked out, and then the query sentence is reconstructed from the selected region, where the reconstruction difference serves as the loss for back-propagation. The existing methods, however, conduct both the matching and the reconstruction approximately as they ignore the fact that the matching correctness is unknown. To overcome this limitation, a discriminative triad is designed here as the basis to the solution, through which a query can be converted into one or multiple discriminative triads in a very scalable way. Based on the discriminative triad, we further propose the triad-level matching and reconstruction modules which are lightweight yet effective for the weakly-supervised training, making it three times lighter and faster than the previous state-of-the-art methods. One important merit of our work is its superior performance despite the simple and neat design. Specifically, the proposed method achieves a new state-of-the-art accuracy when evaluated on RefCOCO (39.21%), RefCOCO+ (39.18%) and RefCOCOg (43.24%) datasets, that is 4.17%, 4.08% and 7.8% higher than the previous one, respectively.
Video Contrastive Learning with Global Context
Aug 05, 2021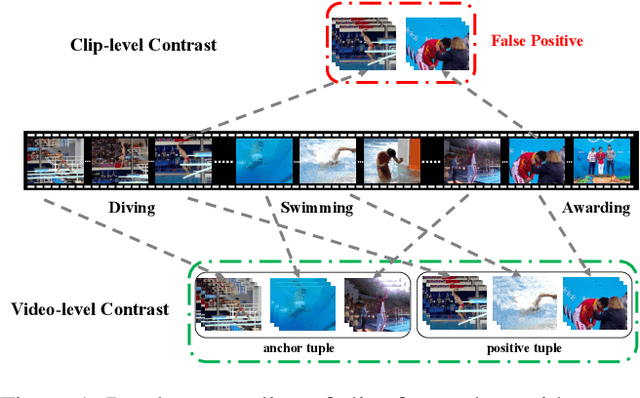

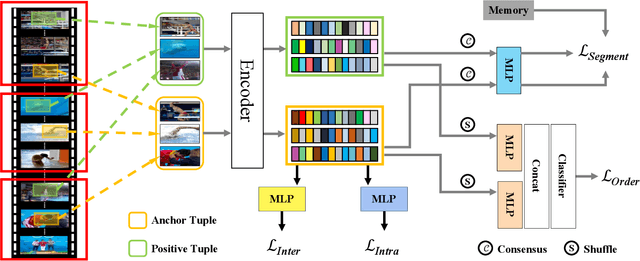
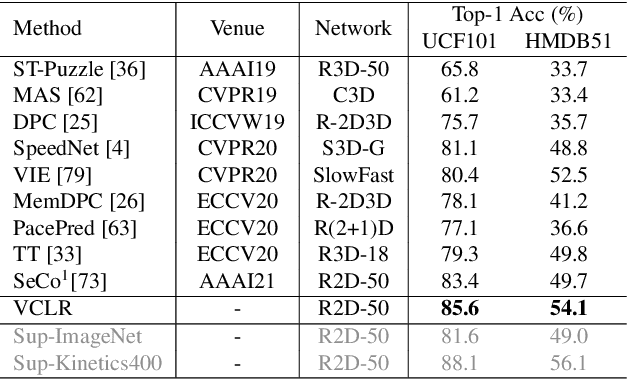
Contrastive learning has revolutionized self-supervised image representation learning field, and recently been adapted to video domain. One of the greatest advantages of contrastive learning is that it allows us to flexibly define powerful loss objectives as long as we can find a reasonable way to formulate positive and negative samples to contrast. However, existing approaches rely heavily on the short-range spatiotemporal salience to form clip-level contrastive signals, thus limit themselves from using global context. In this paper, we propose a new video-level contrastive learning method based on segments to formulate positive pairs. Our formulation is able to capture global context in a video, thus robust to temporal content change. We also incorporate a temporal order regularization term to enforce the inherent sequential structure of videos. Extensive experiments show that our video-level contrastive learning framework (VCLR) is able to outperform previous state-of-the-arts on five video datasets for downstream action classification, action localization and video retrieval. Code is available at https://github.com/amazon-research/video-contrastive-learning.
Gastric histopathology image segmentation using a hierarchical conditional random field
Mar 04, 2020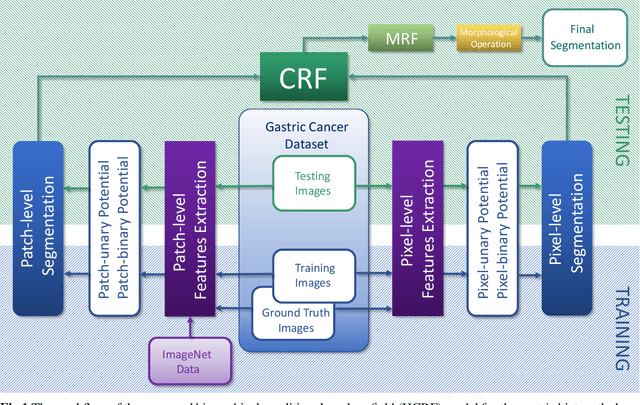

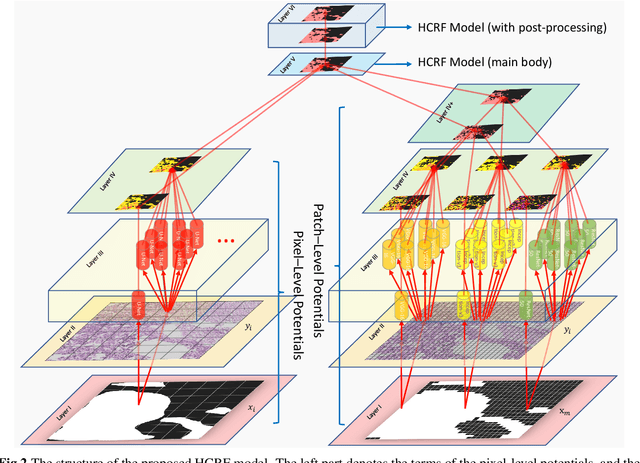

In this paper, a Hierarchical Conditional Random Field (HCRF) model based Gastric Histopathology Image Segmentation (GHIS) method is proposed, which can localize abnormal (cancer) regions in gastric histopathology images obtained by optical microscope to assist histopathologists in medical work. First, to obtain pixel-level segmentation information, we retrain a Convolutional Neural Network (CNN) to build up our pixel-level potentials. Then, in order to obtain abundant spatial segmentation information in patch-level, we fine-tune another three CNNs to build up our patch-level potentials. Thirdly, based on the pixel- and patch-level potentials, our HCRF model is structured. Finally, graph-based post-processing is applied to further improve our segmentation performance. In the experiment, a segmentation accuracy of 78.91% is achieved on a Hematoxylin and Eosin (H&E) stained gastric histopathological dataset with 560 images, showing the effectiveness and future potential of the proposed GHIS method.
Efficient Certified Defenses Against Patch Attacks on Image Classifiers
Feb 08, 2021

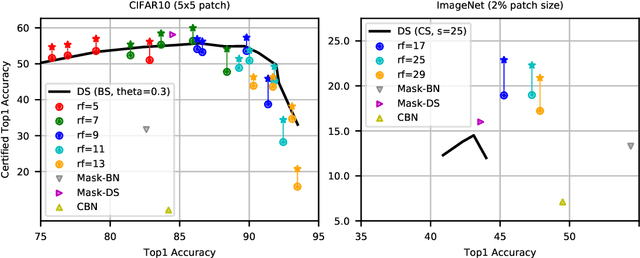
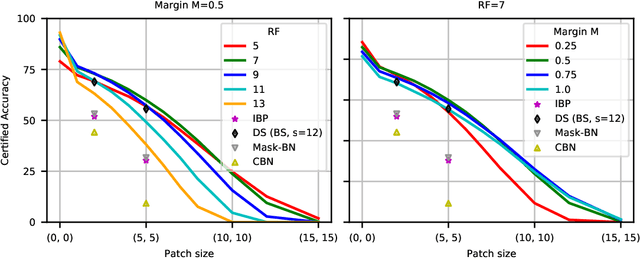
Adversarial patches pose a realistic threat model for physical world attacks on autonomous systems via their perception component. Autonomous systems in safety-critical domains such as automated driving should thus contain a fail-safe fallback component that combines certifiable robustness against patches with efficient inference while maintaining high performance on clean inputs. We propose BagCert, a novel combination of model architecture and certification procedure that allows efficient certification. We derive a loss that enables end-to-end optimization of certified robustness against patches of different sizes and locations. On CIFAR10, BagCert certifies 10.000 examples in 43 seconds on a single GPU and obtains 86% clean and 60% certified accuracy against 5x5 patches.
Boosting Deep Hyperspectral Image Classification with Spectral Unmixing
Apr 03, 2020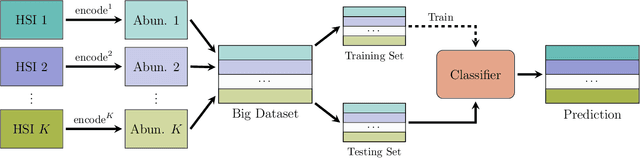
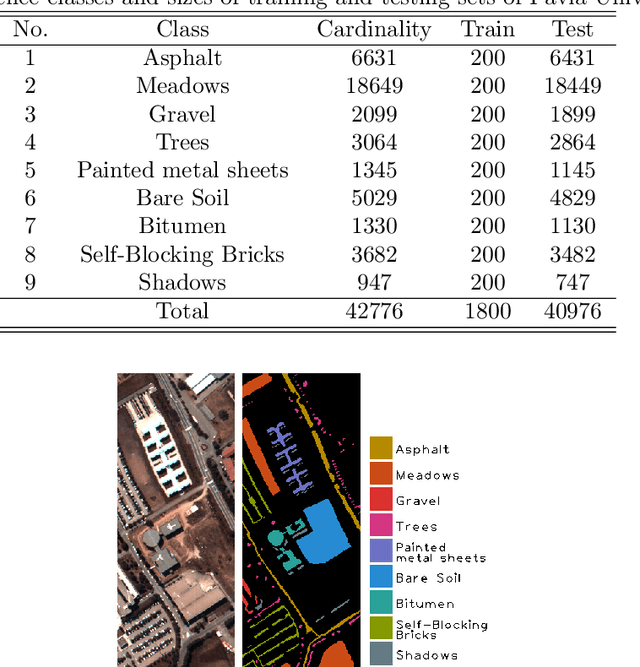
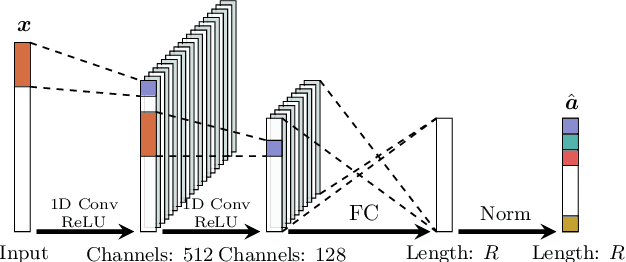
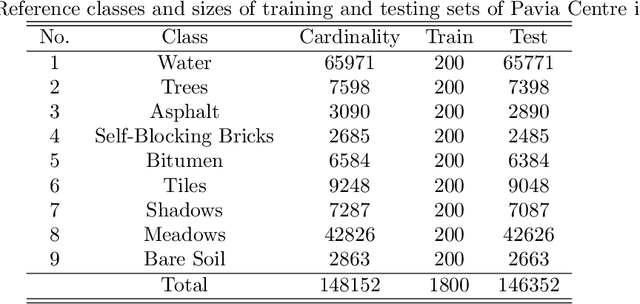
Recent advances in neural networks have made great progress in addressing the hyperspectral image (HSI) classification problem. However, the overfitting effect, which is mainly caused by complicated model structure and small training set, remains a major concern when applying neural networks to HSIs analysis. Reducing the complexity of the neural networks could prevent overfitting to some extent, but it declines the networks' ability to extract more abstract features. Enlarging the training set is also difficult. To tackle the overfitting problem, we propose an abundance-based multi-HSI classification method. By applying an autoencoder-based spectral unmixing technique, different HSIs are firstly converted from the spectral domain to the abundance domain. After that, the abundance representations from multiple HSIs are collected to form an enlarged dataset. Lastly, a simple classifier is trained, which makes predictions over all the involved datasets. Taking advantage of the spectral unmixing, transforming the spectral features to the abundance features significantly simplifies the classification tasks. This enables the use of a simple network as the classifier, thus alleviating the overfitting effect. Moreover, as much dataset-specific information is eliminated by the spectral unmixing, a compatible classifier suitable for different HSIs is trained. A several times enlarged training set is constructed by assembling the abundances from different HSIs. The effectiveness of the proposed method is verified by the ablation study and the comparative experiments. On four datasets, the proposed method provides comparable results with two state-of-the-art methods, but using a much simpler model.
Associative Memories via Predictive Coding
Sep 16, 2021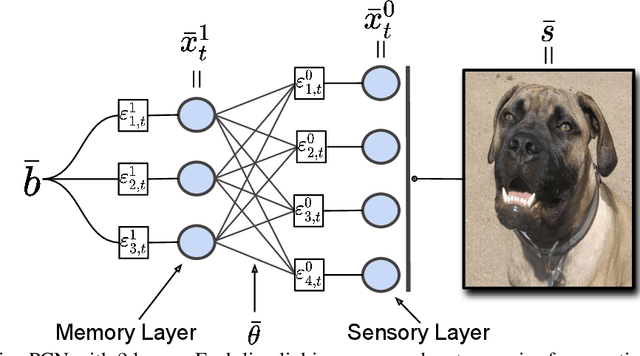
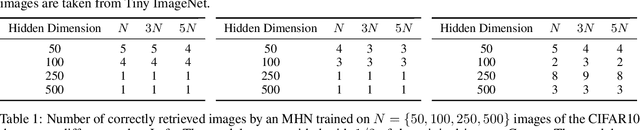
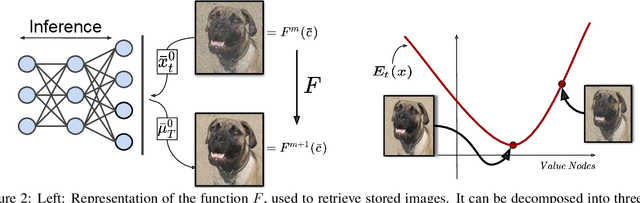
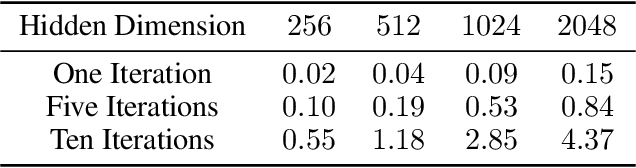
Associative memories in the brain receive and store patterns of activity registered by the sensory neurons, and are able to retrieve them when necessary. Due to their importance in human intelligence, computational models of associative memories have been developed for several decades now. They include autoassociative memories, which allow for storing data points and retrieving a stored data point $s$ when provided with a noisy or partial variant of $s$, and heteroassociative memories, able to store and recall multi-modal data. In this paper, we present a novel neural model for realizing associative memories, based on a hierarchical generative network that receives external stimuli via sensory neurons. This model is trained using predictive coding, an error-based learning algorithm inspired by information processing in the cortex. To test the capabilities of this model, we perform multiple retrieval experiments from both corrupted and incomplete data points. In an extensive comparison, we show that this new model outperforms in retrieval accuracy and robustness popular associative memory models, such as autoencoders trained via backpropagation, and modern Hopfield networks. In particular, in completing partial data points, our model achieves remarkable results on natural image datasets, such as ImageNet, with a surprisingly high accuracy, even when only a tiny fraction of pixels of the original images is presented. Furthermore, we show that this method is able to handle multi-modal data, retrieving images from descriptions, and vice versa. We conclude by discussing the possible impact of this work in the neuroscience community, by showing that our model provides a plausible framework to study learning and retrieval of memories in the brain, as it closely mimics the behavior of the hippocampus as a memory index and generative model.
Complex-valued reservoir computing for aspect classification and slope-angle estimation with low computational cost and high resolution in interferometric synthetic aperture radar
Apr 22, 2021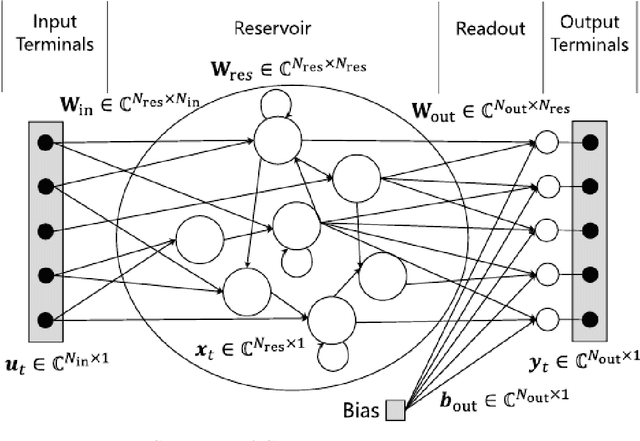

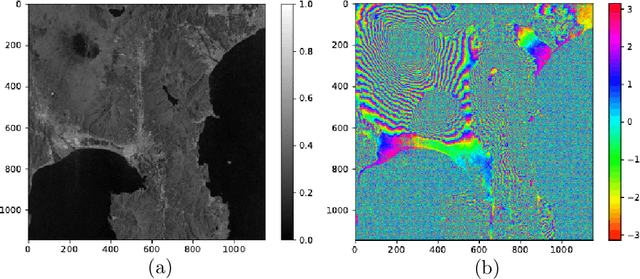

Synthetic aperture radar (SAR) is widely used for ground surface classification since it utilizes information on vegetation and soil unavailable in optical observation. Image classification often employs convolutional neural networks. However, they have serious problems such as long learning time and resolution degradation in their convolution and pooling processes. In this paper, we propose complex-valued reservoir computing (CVRC) to deal with complex-valued images in interferometric SAR (InSAR). We classify InSAR image data by using CVRC successfully with a higher resolution and a lower computational cost, i.e., one-hundredth learning time and one-fifth classification time, than convolutional neural networks. We also conduct experiments on slope angle estimation. CVRC is found applicable to quantitative tasks dealing with continuous values as well as discrete classification tasks with a higher accuracy.
Imperceptible Adversarial Examples by Spatial Chroma-Shift
Aug 05, 2021
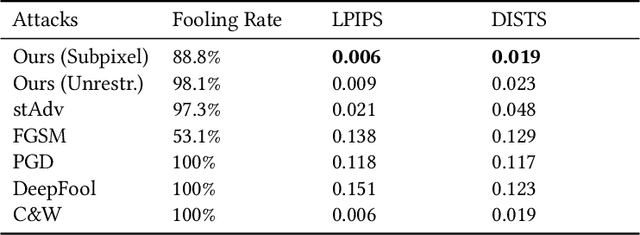

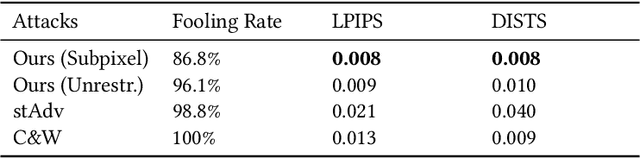
Deep Neural Networks have been shown to be vulnerable to various kinds of adversarial perturbations. In addition to widely studied additive noise based perturbations, adversarial examples can also be created by applying a per pixel spatial drift on input images. While spatial transformation based adversarial examples look more natural to human observers due to absence of additive noise, they still possess visible distortions caused by spatial transformations. Since the human vision is more sensitive to the distortions in the luminance compared to those in chrominance channels, which is one of the main ideas behind the lossy visual multimedia compression standards, we propose a spatial transformation based perturbation method to create adversarial examples by only modifying the color components of an input image. While having competitive fooling rates on CIFAR-10 and NIPS2017 Adversarial Learning Challenge datasets, examples created with the proposed method have better scores with regards to various perceptual quality metrics. Human visual perception studies validate that the examples are more natural looking and often indistinguishable from their original counterparts.
Dynamic Event Camera Calibration
Jul 28, 2021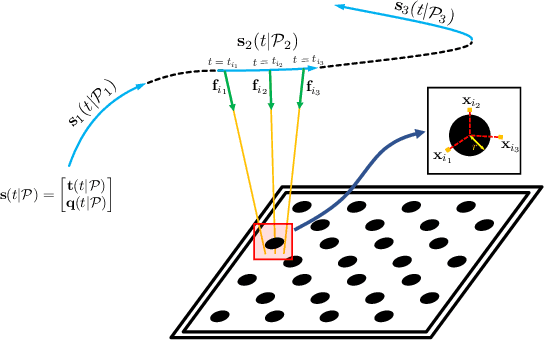
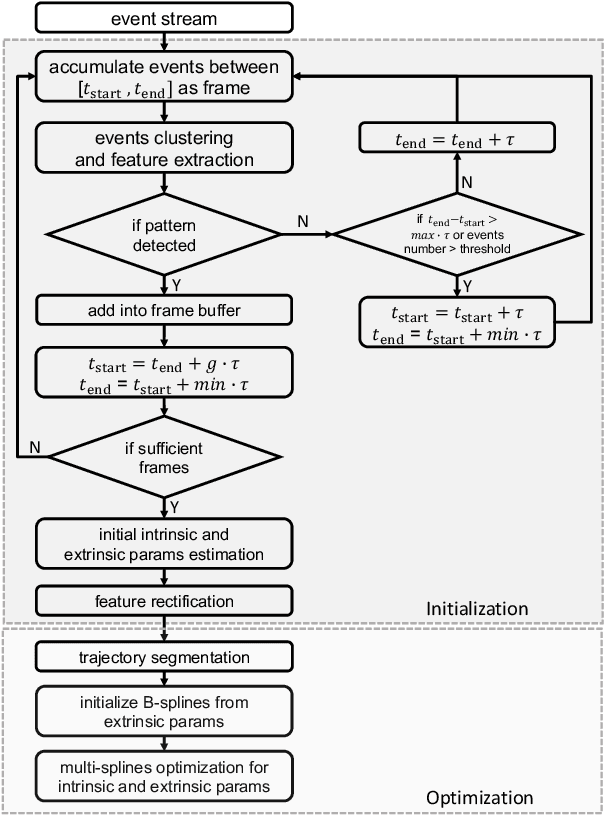


Camera calibration is an important prerequisite towards the solution of 3D computer vision problems. Traditional methods rely on static images of a calibration pattern. This raises interesting challenges towards the practical usage of event cameras, which notably require image change to produce sufficient measurements. The current standard for event camera calibration therefore consists of using flashing patterns. They have the advantage of simultaneously triggering events in all reprojected pattern feature locations, but it is difficult to construct or use such patterns in the field. We present the first dynamic event camera calibration algorithm. It calibrates directly from events captured during relative motion between camera and calibration pattern. The method is propelled by a novel feature extraction mechanism for calibration patterns, and leverages existing calibration tools before optimizing all parameters through a multi-segment continuous-time formulation. As demonstrated through our results on real data, the obtained calibration method is highly convenient and reliably calibrates from data sequences spanning less than 10 seconds.