 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SER-FIQ: Unsupervised Estimation of Face Image Quality Based on Stochastic Embedding Robustness
Mar 20, 2020
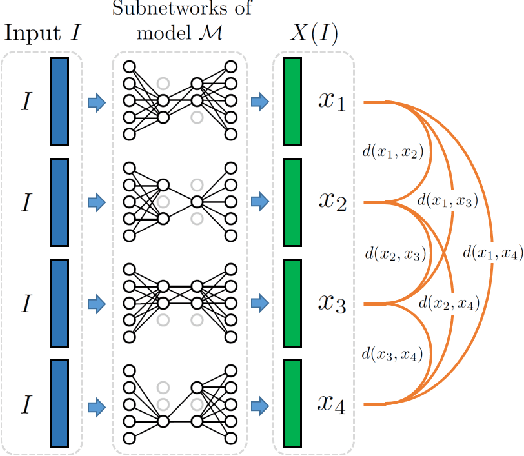
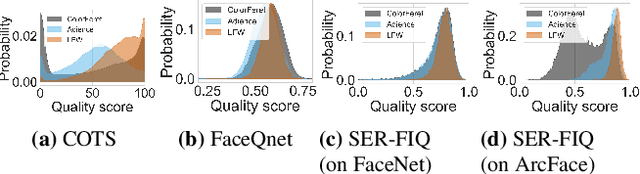
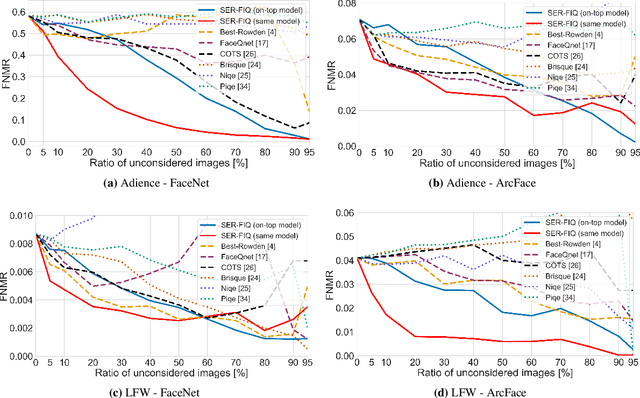

Face image quality is an important factor to enable high performance face recognition systems. Face quality assessment aims at estimating the suitability of a face image for recognition. Previous work proposed supervised solutions that require artificially or human labelled quality values. However, both labelling mechanisms are error-prone as they do not rely on a clear definition of quality and may not know the best characteristics for the utilized face recognition system. Avoiding the use of inaccurate quality labels, we proposed a novel concept to measure face quality based on an arbitrary face recognition model. By determining the embedding variations generated from random subnetworks of a face model, the robustness of a sample representation and thus, its quality is estimated. The experiments are conducted in a cross-database evaluation setting on three publicly available databases. We compare our proposed solution on two face embeddings against six state-of-the-art approaches from academia and industry. The results show that our unsupervised solution outperforms all other approaches in the majority of the investigated scenarios. In contrast to previous works, the proposed solution shows a stable performance over all scenarios. Utilizing the deployed face recognition model for our face quality assessment methodology avoids the training phase completely and further outperforms all baseline approaches by a large margin. Our solution can be easily integrated into current face recognition systems and can be modified to other tasks beyond face recognition.
Self-Guided Instance-Aware Network for Depth Completion and Enhancement
May 25, 2021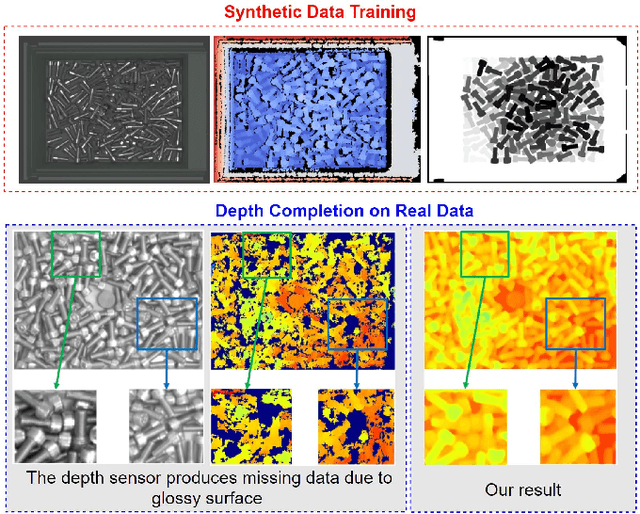
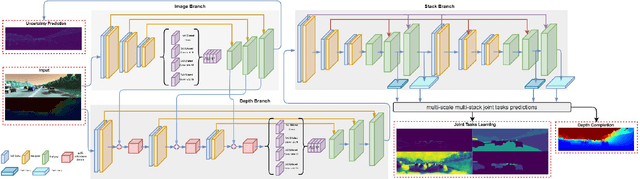
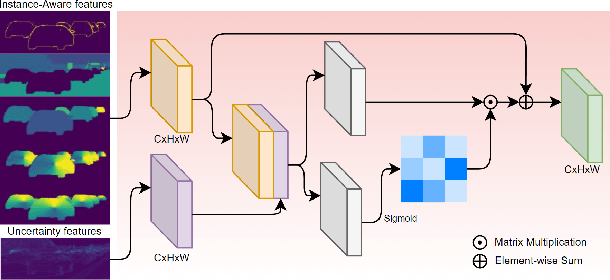
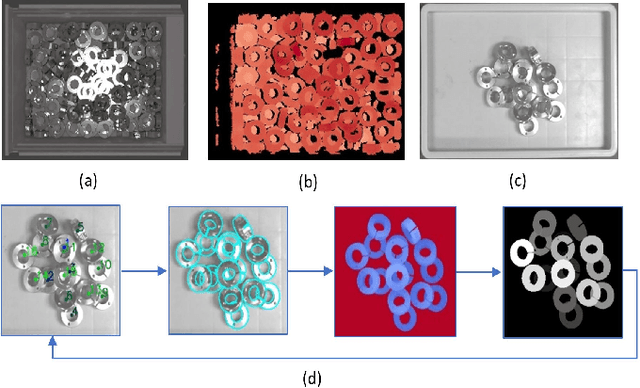
Depth completion aims at inferring a dense depth image from sparse depth measurement since glossy, transparent or distant surface cannot be scanned properly by the sensor. Most of existing methods directly interpolate the missing depth measurements based on pixel-wise image content and the corresponding neighboring depth values. Consequently, this leads to blurred boundaries or inaccurate structure of object. To address these problems, we propose a novel self-guided instance-aware network (SG-IANet) that: (1) utilize self-guided mechanism to extract instance-level features that is needed for depth restoration, (2) exploit the geometric and context information into network learning to conform to the underlying constraints for edge clarity and structure consistency, (3) regularize the depth estimation and mitigate the impact of noise by instance-aware learning, and (4) train with synthetic data only by domain randomization to bridge the reality gap. Extensive experiments on synthetic and real world dataset demonstrate that our proposed method outperforms previous works. Further ablation studies give more insights into the proposed method and demonstrate the generalization capability of our model.
Challenges for machine learning in clinical translation of big data imaging studies
Jul 07, 2021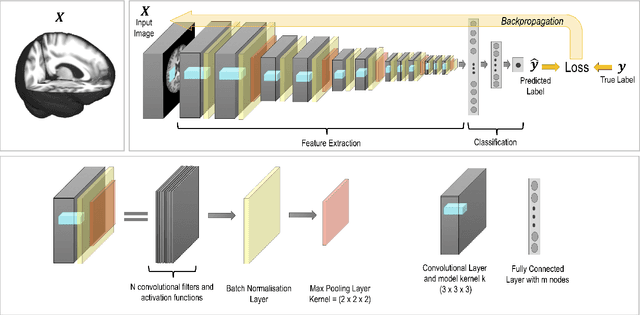

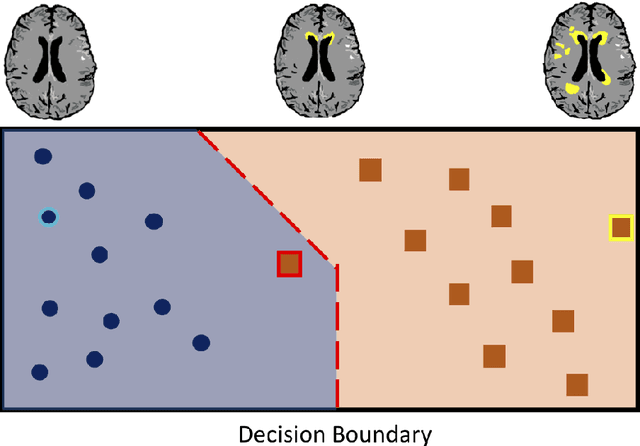
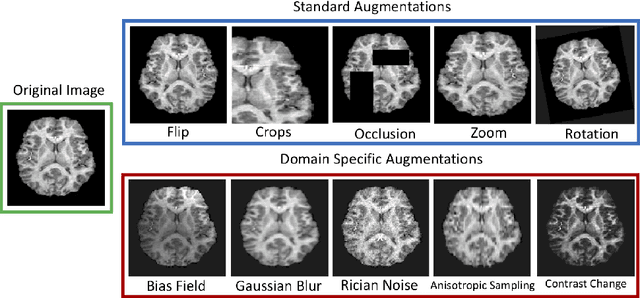
The combination of deep learning image analysis methods and large-scale imaging datasets offers many opportunities to imaging neuroscience and epidemiology. However, despite the success of deep learning when applied to many neuroimaging tasks, there remain barriers to the clinical translation of large-scale datasets and processing tools. Here, we explore the main challenges and the approaches that have been explored to overcome them. We focus on issues relating to data availability, interpretability, evaluation and logistical challenges, and discuss the challenges we believe are still to be overcome to enable the full success of big data deep learning approaches to be experienced outside of the research field.
Colorization Transformer
Feb 08, 2021

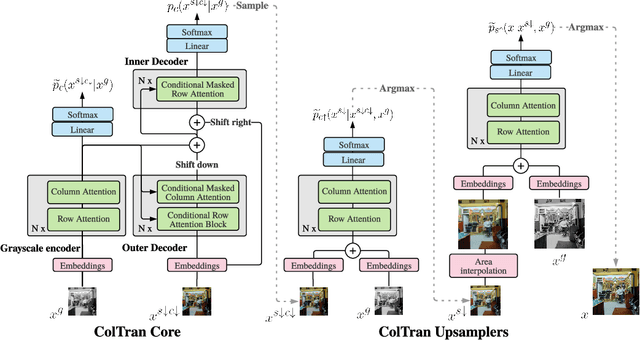
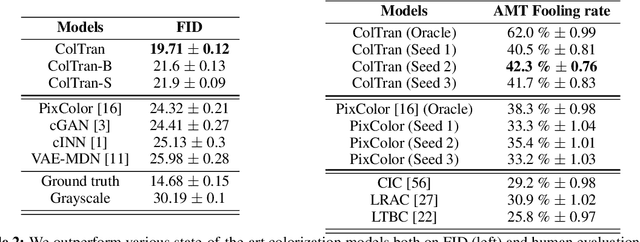
We present the Colorization Transformer, a novel approach for diverse high fidelity image colorization based on self-attention. Given a grayscale image, the colorization proceeds in three steps. We first use a conditional autoregressive transformer to produce a low resolution coarse coloring of the grayscale image. Our architecture adopts conditional transformer layers to effectively condition grayscale input. Two subsequent fully parallel networks upsample the coarse colored low resolution image into a finely colored high resolution image. Sampling from the Colorization Transformer produces diverse colorings whose fidelity outperforms the previous state-of-the-art on colorising ImageNet based on FID results and based on a human evaluation in a Mechanical Turk test. Remarkably, in more than 60% of cases human evaluators prefer the highest rated among three generated colorings over the ground truth. The code and pre-trained checkpoints for Colorization Transformer are publicly available at https://github.com/google-research/google-research/tree/master/coltran
Ground Encoding: Learned Factor Graph-based Models for Localizing Ground Penetrating Radar
Mar 29, 2021

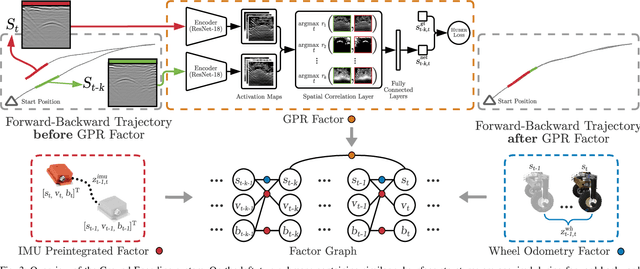

We address the problem of robot localization using ground penetrating radar (GPR) sensors. Current approaches for localization with GPR sensors require a priori maps of the system's environment as well as access to approximate global positioning (GPS) during operation. In this paper, we propose a novel, real-time GPR-based localization system for unknown and GPS-denied environments. We model the localization problem as an inference over a factor graph. Our approach combines 1D single-channel GPR measurements to form 2D image submaps. To use these GPR images in the graph, we need sensor models that can map noisy, high-dimensional image measurements into the state space. These are challenging to obtain a priori since image generation has a complex dependency on subsurface composition and radar physics, which itself varies with sensors and variations in subsurface electromagnetic properties. Our key idea is to instead learn relative sensor models directly from GPR data that map non-sequential GPR image pairs to relative robot motion. These models are incorporated as factors within the factor graph with relative motion predictions correcting for accumulated drift in the position estimates. We demonstrate our approach over datasets collected across multiple locations using a custom designed experimental rig. We show reliable, real-time localization using only GPR and odometry measurements for varying trajectories in three distinct GPS-denied environments. For our supplementary video, see https://youtu.be/HXXgdTJzqyw.
Scene-and-Process-Dependent Spatial Image Quality Metrics
Jul 21, 2019
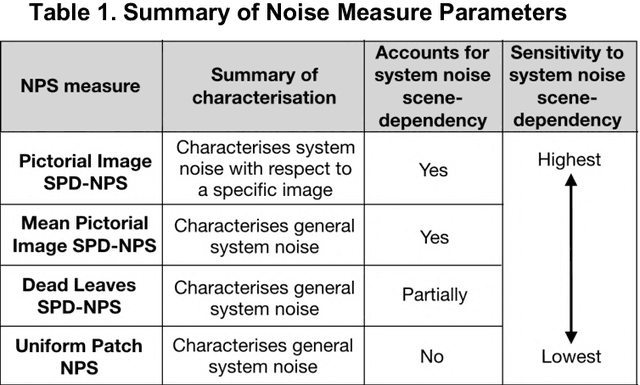
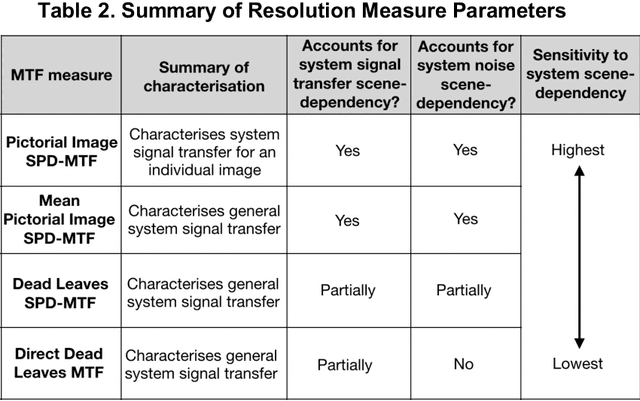
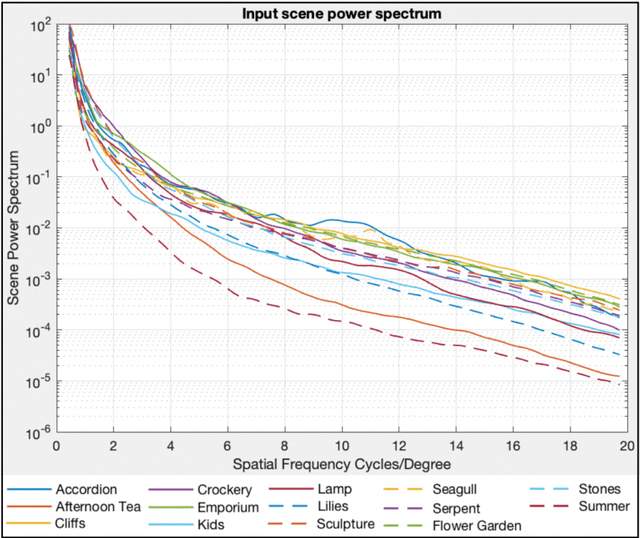
Spatial image quality metrics designed for camera systems generally employ the Modulation Transfer Function (MTF), the Noise Power Spectrum (NPS), and a visual contrast detection model. Prior art indicates that scene-dependent characteristics of non-linear, content-aware image processing are unaccounted for by MTFs and NPSs measured using traditional methods. We present two novel metrics: the log Noise Equivalent Quanta (log NEQ) and Visual log NEQ. They both employ scene-and-process-dependent MTF (SPD-MTF) and NPS (SPD-NPS) measures, which account for signal-transfer and noise scene-dependency, respectively. We also investigate implementing contrast detection and discrimination models that account for scene-dependent visual masking. Also, three leading camera metrics are revised that use the above scene-dependent measures. All metrics are validated by examining correlations with the perceived quality of images produced by simulated camera pipelines. Metric accuracy improved consistently when the SPD-MTFs and SPD-NPSs were implemented. The novel metrics outperformed existing metrics of the same genre.
Partial 3D Object Retrieval using Local Binary QUICCI Descriptors and Dissimilarity Tree Indexing
Jul 07, 2021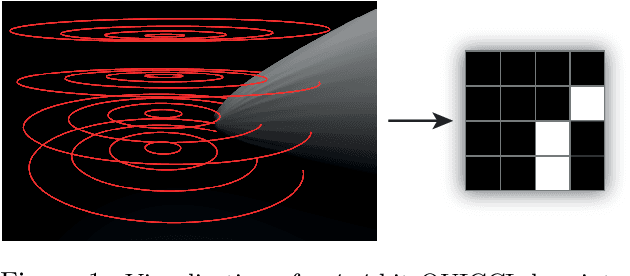

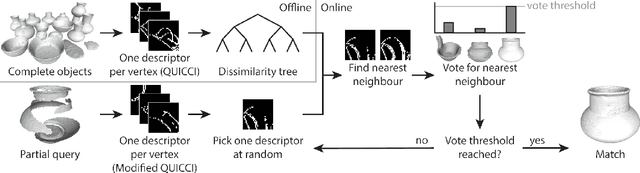
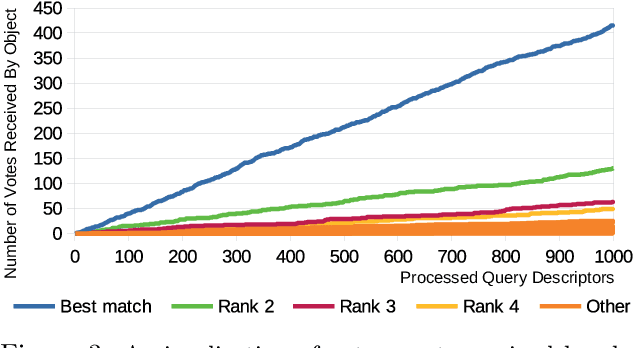
A complete pipeline is presented for accurate and efficient partial 3D object retrieval based on Quick Intersection Count Change Image (QUICCI) binary local descriptors and a novel indexing tree. It is shown how a modification to the QUICCI query descriptor makes it ideal for partial retrieval. An indexing structure called Dissimilarity Tree is proposed which can significantly accelerate searching the large space of local descriptors; this is applicable to QUICCI and other binary descriptors. The index exploits the distribution of bits within descriptors for efficient retrieval. The retrieval pipeline is tested on the artificial part of SHREC'16 dataset with near-ideal retrieval results.
BezierSeg: Parametric Shape Representation for Fast Object Segmentation in Medical Images
Aug 02, 2021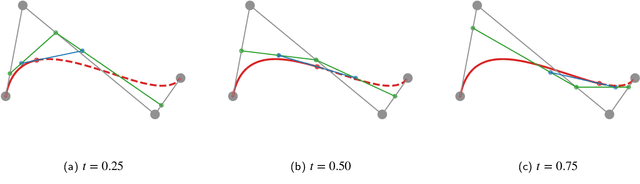
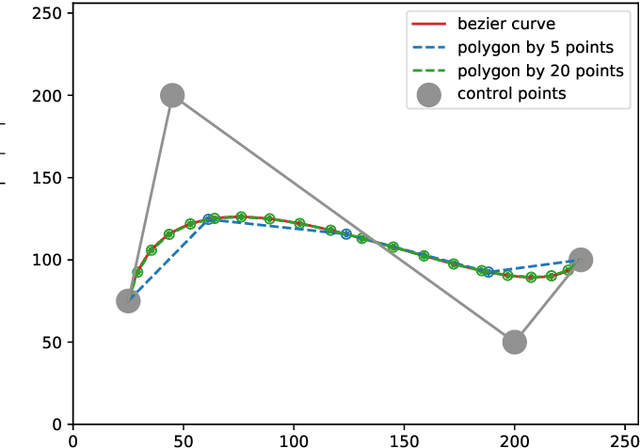
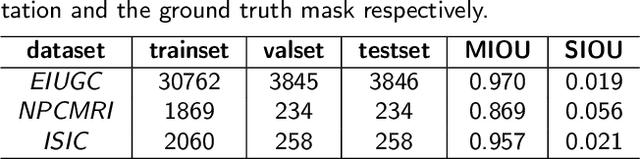
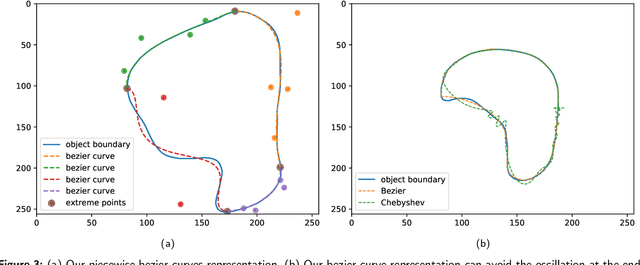
Delineating the lesion area is an important task in image-based diagnosis. Pixel-wise classification is a popular approach to segmenting the region of interest. However, at fuzzy boundaries such methods usually result in glitches, discontinuity, or disconnection, inconsistent with the fact that lesions are solid and smooth. To overcome these undesirable artifacts, we propose the BezierSeg model which outputs bezier curves encompassing the region of interest. Directly modelling the contour with analytic equations ensures that the segmentation is connected, continuous, and the boundary is smooth. In addition, it offers sub-pixel accuracy. Without loss of accuracy, the bezier contour can be resampled and overlaid with images of any resolution. Moreover, a doctor can conveniently adjust the curve's control points to refine the result. Our experiments show that the proposed method runs in real time and achieves accuracy competitive with pixel-wise segmentation models.
Dam Burst: A region-merging-based image segmentation method
Feb 26, 2020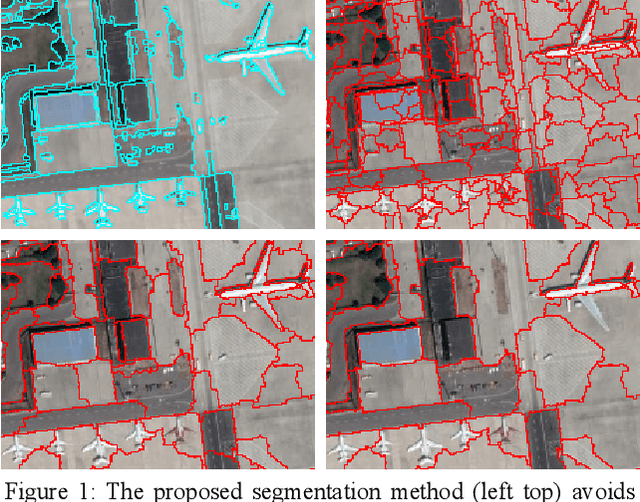
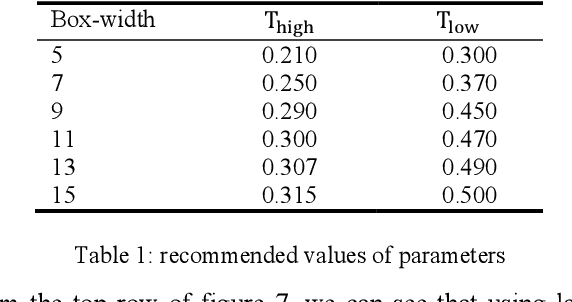

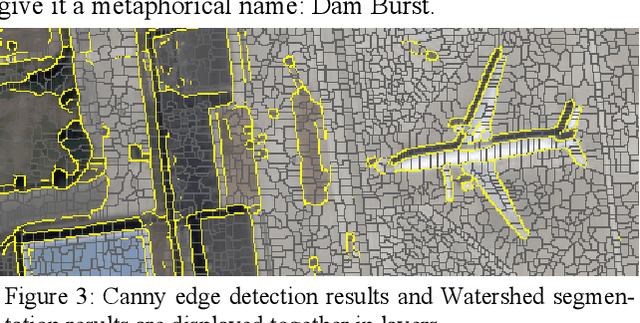
Until now, all single level segmentation algorithms except CNN-based ones lead to over segmentation. And CNN-based segmentation algorithms have their own problems. To avoid over segmentation, multiple thresholds of criteria are adopted in region merging process to produce hierarchical segmentation results. However, there still has extreme over segmentation in the low level of the hierarchy, and outstanding tiny objects are merged to their large adjacencies in the high level of the hierarchy. This paper proposes a region-merging-based image segmentation method that we call it Dam Burst. As a single level segmentation algorithm, this method avoids over segmentation and retains details by the same time. It is named because of that it simulates a flooding from underground destroys dams between water-pools. We treat edge detection results as strengthening structure of a dam if it is on the dam. To simulate a flooding from underground, regions are merged by ascending order of the average gra-dient inside the region.
Exact Adversarial Attack to Image Captioning via Structured Output Learning with Latent Variables
May 10, 2019
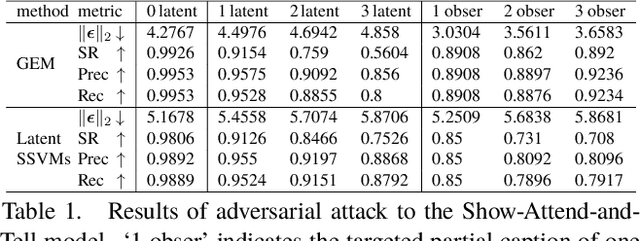

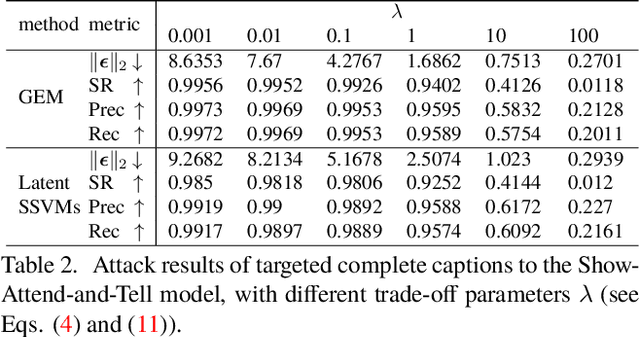
In this work, we study the robustness of a CNN+RNN based image captioning system being subjected to adversarial noises. We propose to fool an image captioning system to generate some targeted partial captions for an image polluted by adversarial noises, even the targeted captions are totally irrelevant to the image content. A partial caption indicates that the words at some locations in this caption are observed, while words at other locations are not restricted.It is the first work to study exact adversarial attacks of targeted partial captions. Due to the sequential dependencies among words in a caption, we formulate the generation of adversarial noises for targeted partial captions as a structured output learning problem with latent variables. Both the generalized expectation maximization algorithm and structural SVMs with latent variables are then adopted to optimize the problem. The proposed methods generate very successful at-tacks to three popular CNN+RNN based image captioning models. Furthermore, the proposed attack methods are used to understand the inner mechanism of image captioning systems, providing the guidance to further improve automatic image captioning systems towards human captioning.