 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Style-Restricted GAN: Multi-Modal Translation with Style Restriction Using Generative Adversarial Networks
May 17, 2021
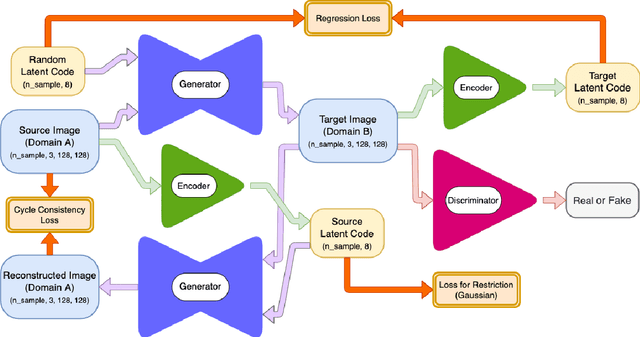
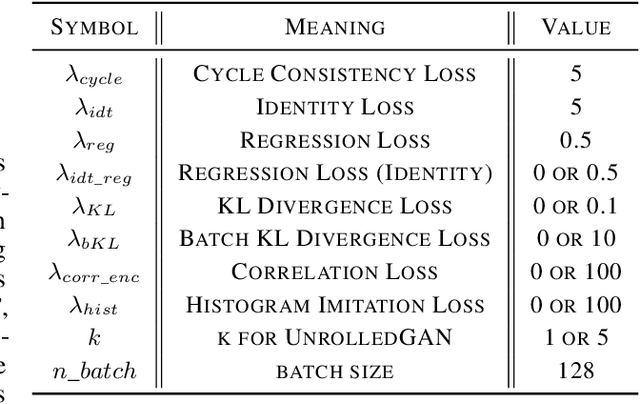
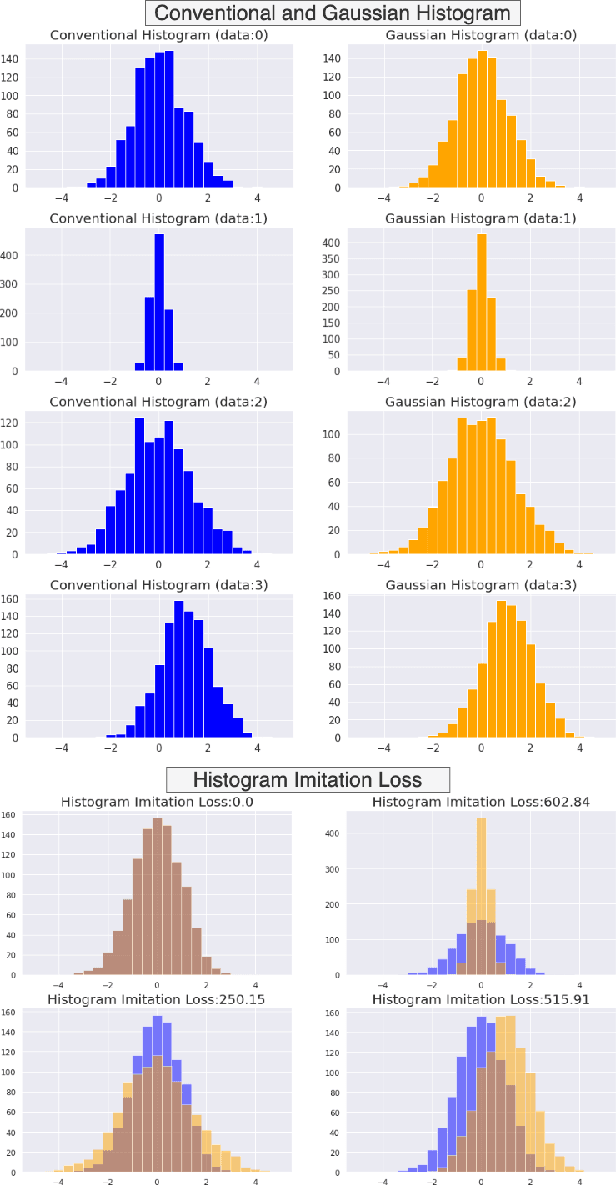
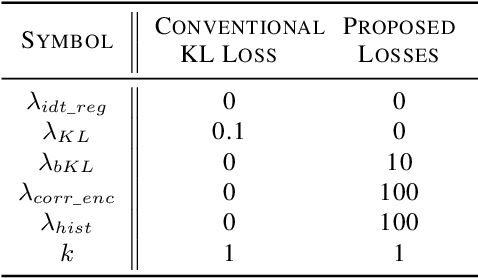
Unpaired image-to-image translation using Generative Adversarial Networks (GAN) is successful in converting images among multiple domains. Moreover, recent studies have shown a way to diversify the outputs of the generator. However, since there are no restrictions on how the generator diversifies the results, it is likely to translate some unexpected features. In this paper, we propose Style-Restricted GAN (SRGAN), a novel approach to transfer input images into different domains' with different styles, changing the exclusively class-related features. Additionally, instead of KL divergence loss, we adopt 3 new losses to restrict the distribution of the encoded features: batch KL divergence loss, correlation loss, and histogram imitation loss. The study reports quantitative as well as qualitative results with Precision, Recall, Density, and Coverage. The proposed 3 losses lead to the enhancement of the level of diversity compared to the conventional KL loss. In particular, SRGAN is found to be successful in translating with higher diversity and without changing the class-unrelated features in the CelebA face dataset. Our implementation is available at https://github.com/shinshoji01/Style-Restricted_GAN.
Classifying Image Sequences of Astronomical Transients with Deep Neural Networks
Apr 28, 2020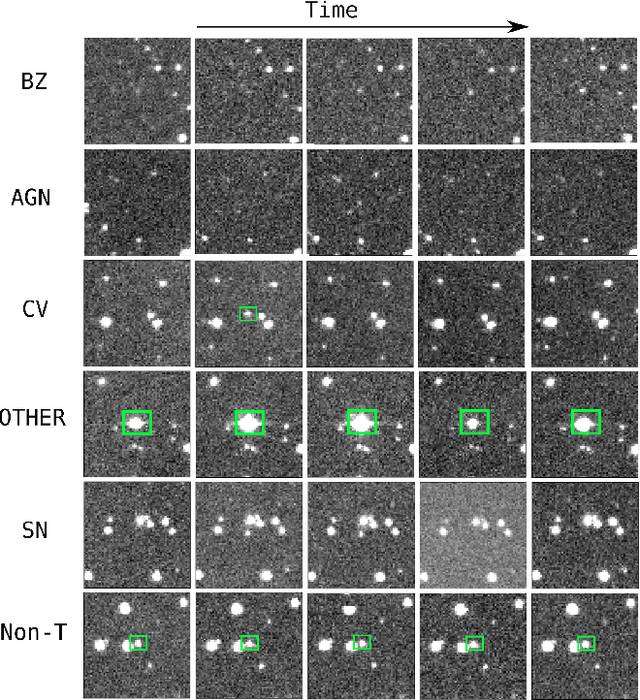


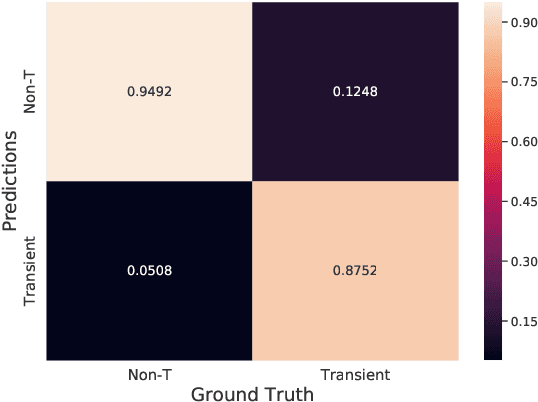
Supervised classification of temporal sequences of astronomical images into meaningful transient astrophysical phenomena has been considered a hard problem because it requires the intervention of human experts. The classifier uses the expert's knowledge to find heuristic features to process the images, for instance, by performing image subtraction or by extracting sparse information such as flux time series in the form of light curves. We present a successful deep learning approach that learns directly from imaging data. Our method models explicitly the spatio-temporal patterns with Deep Convolutional Neural Networks and Gated Recurrent Units. We train these deep neural networks using 1.3 million real astronomical images from the Catalina Real-Time Transient Survey to classify the sequences into five different types of astronomical transient classes. The TAO-Net (for Transient Astronomical Objects Network) architecture achieves on the five-type classification task an average F1-score of 54.58$\pm$13.32, almost nine points higher than the F1-score of 45.49 $\pm$ 13.75 from the random forest classification on light curves. The achievement TAO-Net opens the possibility to develop new deep-learning architectures for early transient detection. We make available the training dataset and trained models of TAO-Net to allow for future extensions of this work.
Synth-by-Reg (SbR): Contrastive learning for synthesis-based registration of paired images
Jul 30, 2021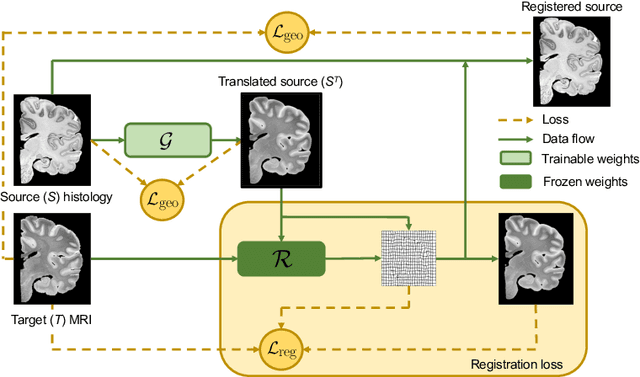
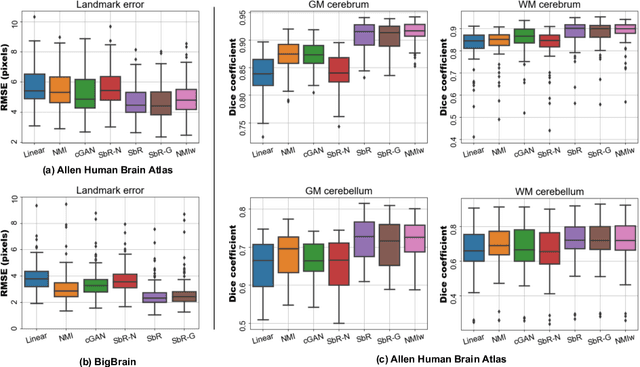
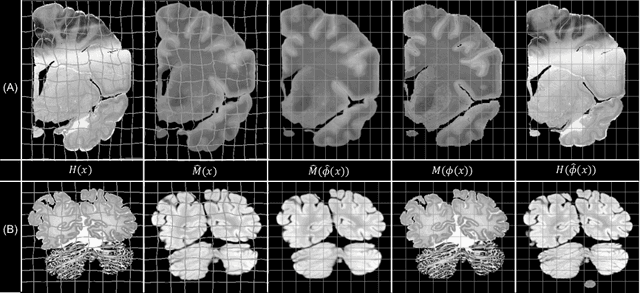
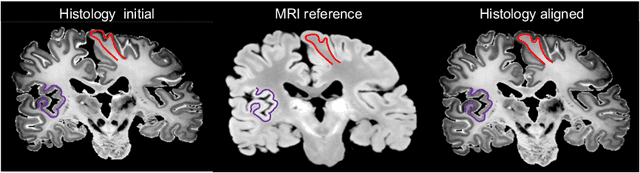
Nonlinear inter-modality registration is often challenging due to the lack of objective functions that are good proxies for alignment. Here we propose a synthesis-by-registration method to convert this problem into an easier intra-modality task. We introduce a registration loss for weakly supervised image translation between domains that does not require perfectly aligned training data. This loss capitalises on a registration U-Net with frozen weights, to drive a synthesis CNN towards the desired translation. We complement this loss with a structure preserving constraint based on contrastive learning, which prevents blurring and content shifts due to overfitting. We apply this method to the registration of histological sections to MRI slices, a key step in 3D histology reconstruction. Results on two different public datasets show improvements over registration based on mutual information (13% reduction in landmark error) and synthesis-based algorithms such as CycleGAN (11% reduction), and are comparable to a registration CNN with label supervision.
Stereo Waterdrop Removal with Row-wise Dilated Attention
Aug 07, 2021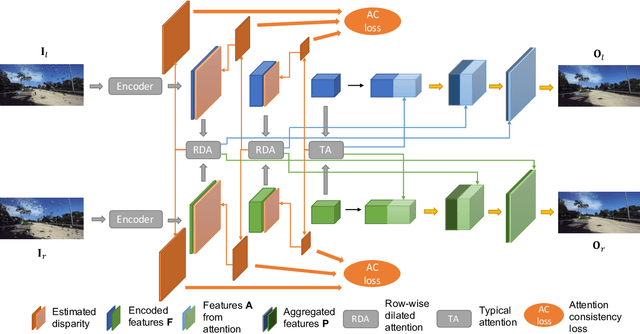
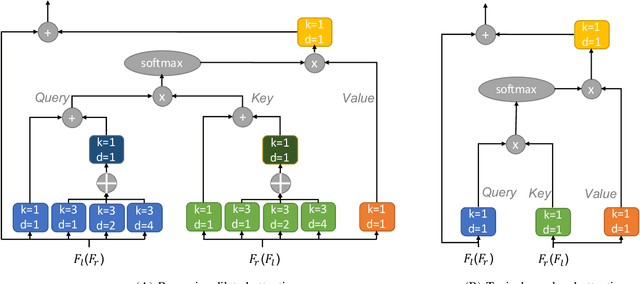


Existing vision systems for autonomous driving or robots are sensitive to waterdrops adhered to windows or camera lenses. Most recent waterdrop removal approaches take a single image as input and often fail to recover the missing content behind waterdrops faithfully. Thus, we propose a learning-based model for waterdrop removal with stereo images. To better detect and remove waterdrops from stereo images, we propose a novel row-wise dilated attention module to enlarge attention's receptive field for effective information propagation between the two stereo images. In addition, we propose an attention consistency loss between the ground-truth disparity map and attention scores to enhance the left-right consistency in stereo images. Because of related datasets' unavailability, we collect a real-world dataset that contains stereo images with and without waterdrops. Extensive experiments on our dataset suggest that our model outperforms state-of-the-art methods both quantitatively and qualitatively. Our source code and the stereo waterdrop dataset are available at \href{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}
MetH: A family of high-resolution and variable-shape image challenges
Nov 29, 2019
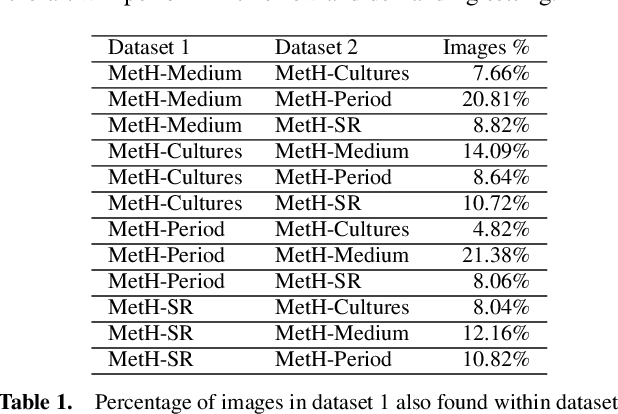
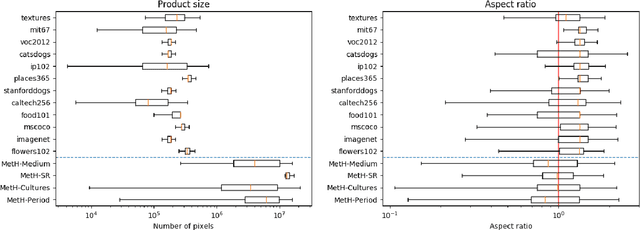
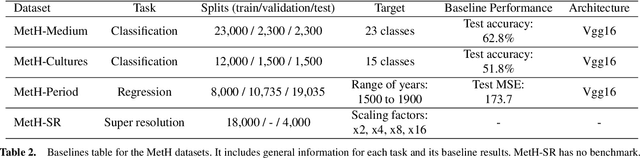
High-resolution and variable-shape images have not yet been properly addressed by the AI community. The approach of down-sampling data often used with convolutional neural networks is sub-optimal for many tasks, and has too many drawbacks to be considered a sustainable alternative. In sight of the increasing importance of problems that can benefit from exploiting high-resolution (HR) and variable-shape, and with the goal of promoting research in that direction, we introduce a new family of datasets (MetH). The four proposed problems include two image classification, one image regression and one super resolution task. Each of these datasets contains thousands of art pieces captured by HR and variable-shape images, labeled by experts at the Metropolitan Museum of Art. We perform an analysis, which shows how the proposed tasks go well beyond current public alternatives in both pixel size and aspect ratio variance. At the same time, the performance obtained by popular architectures on these tasks shows that there is ample room for improvement. To wrap up the relevance of the contribution we review the fields, both in AI and high-performance computing, that could benefit from the proposed challenges.
Gastric histopathology image segmentation using a hierarchical conditional random field
Mar 04, 2020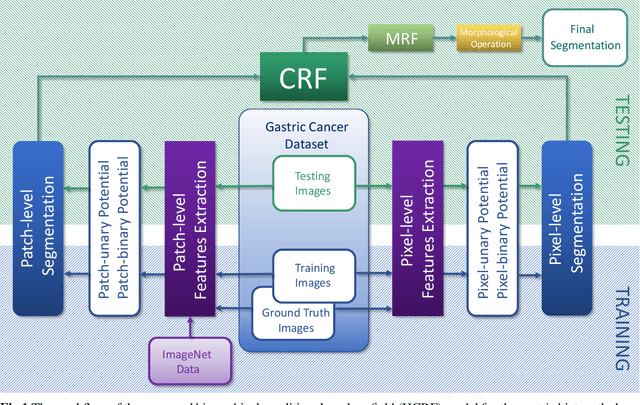

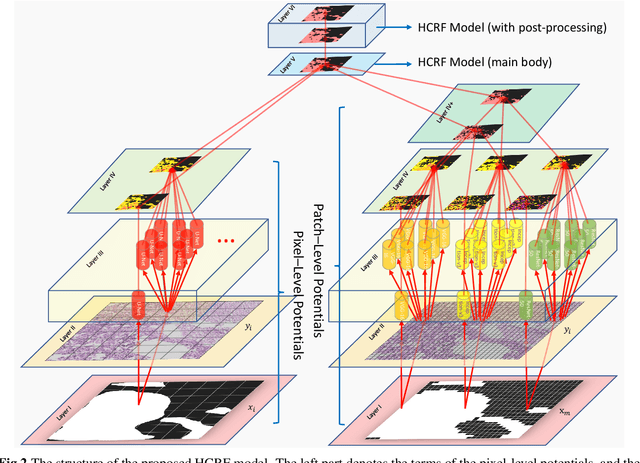

In this paper, a Hierarchical Conditional Random Field (HCRF) model based Gastric Histopathology Image Segmentation (GHIS) method is proposed, which can localize abnormal (cancer) regions in gastric histopathology images obtained by optical microscope to assist histopathologists in medical work. First, to obtain pixel-level segmentation information, we retrain a Convolutional Neural Network (CNN) to build up our pixel-level potentials. Then, in order to obtain abundant spatial segmentation information in patch-level, we fine-tune another three CNNs to build up our patch-level potentials. Thirdly, based on the pixel- and patch-level potentials, our HCRF model is structured. Finally, graph-based post-processing is applied to further improve our segmentation performance. In the experiment, a segmentation accuracy of 78.91% is achieved on a Hematoxylin and Eosin (H&E) stained gastric histopathological dataset with 560 images, showing the effectiveness and future potential of the proposed GHIS method.
A comprehensive evaluation of full-reference image quality assessment algorithms on KADID-10k
Jul 03, 2019

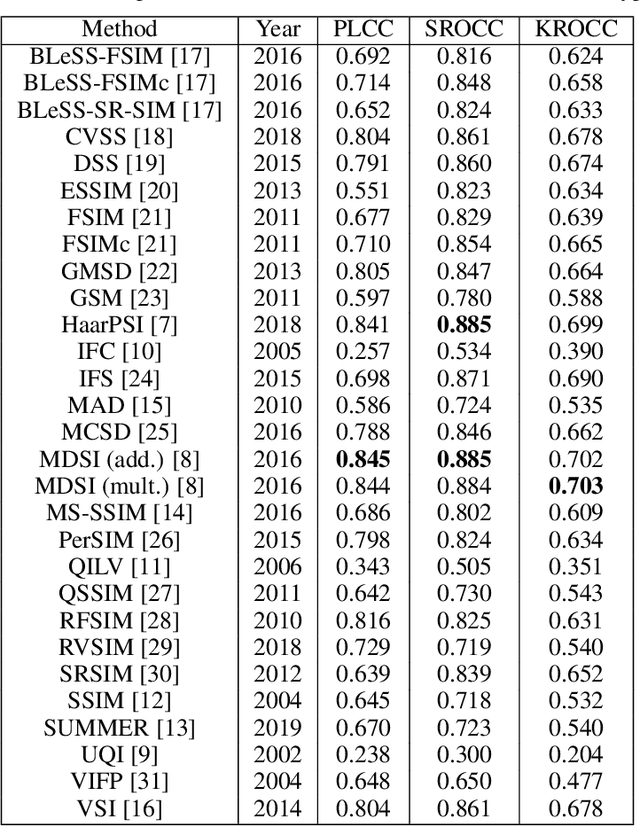
Significant progress has been made in the past decade for full-reference image quality assessment (FR-IQA). However, new large scale image quality databases have been released for evaluating image quality assessment algorithms. In this study, our goal is to give a comprehensive evaluation of state-of-the-art FR-IQA metrics using the recently published KADID-10k database which is largest available one at the moment. Our evaluation results and the associated discussions is very helpful to obtain a clear understanding about the status of state-of-the-art FR-IQA metrics.
Generating Unrestricted Adversarial Examples via Three Parameters
Mar 13, 2021
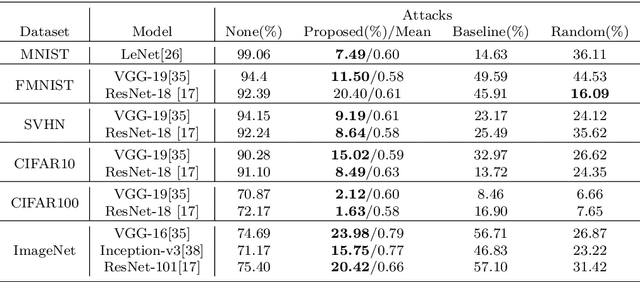
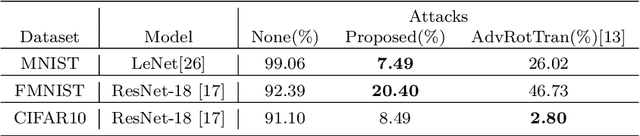
Deep neural networks have been shown to be vulnerable to adversarial examples deliberately constructed to misclassify victim models. As most adversarial examples have restricted their perturbations to $L_{p}$-norm, existing defense methods have focused on these types of perturbations and less attention has been paid to unrestricted adversarial examples; which can create more realistic attacks, able to deceive models without affecting human predictions. To address this problem, the proposed adversarial attack generates an unrestricted adversarial example with a limited number of parameters. The attack selects three points on the input image and based on their locations transforms the image into an adversarial example. By limiting the range of movement and location of these three points and using a discriminatory network, the proposed unrestricted adversarial example preserves the image appearance. Experimental results show that the proposed adversarial examples obtain an average success rate of 93.5% in terms of human evaluation on the MNIST and SVHN datasets. It also reduces the model accuracy by an average of 73% on six datasets MNIST, FMNIST, SVHN, CIFAR10, CIFAR100, and ImageNet. It should be noted that, in the case of attacks, lower accuracy in the victim model denotes a more successful attack. The adversarial train of the attack also improves model robustness against a randomly transformed image.
A novel text representation which enables image classifiers to perform text classification, applied to name disambiguation
Aug 19, 2019
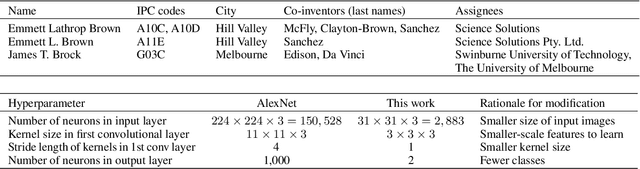


Patent data are often used to study the process of innovation and research, but patent databases lack unique identifiers for individual inventors, making it difficult to study innovation processes at the individual level. Here we introduce an algorithm that performs highly accurate disambiguation of inventors (named entities) in US patent data (F1: 99.09%, precision: 99.41%, recall: 98.76%). The algorithm involves a novel method for converting text-based record data into abstract image representations, in which text from a given pairwise comparison between two inventor name records is converted into a 2D RGB (stacked) image representation. We train an image classification neural network to discriminate between such pairwise comparison images, and then use the trained network to label each pair of records as either matched (same inventor) or non-matched (different inventors). The resulting disambiguation algorithm produces highly accurate results, out-performing other inventor name disambiguation studies on US patent data. Our new text-to-image representation method could potentially be used more broadly for other NLP comparison problems, as it allows image-based processing techniques (e.g. image classification networks) to be applied to text-based comparison problems (such as disambiguation of academic publications, or data linkage problems).
Neural Lumigraph Rendering
Mar 22, 2021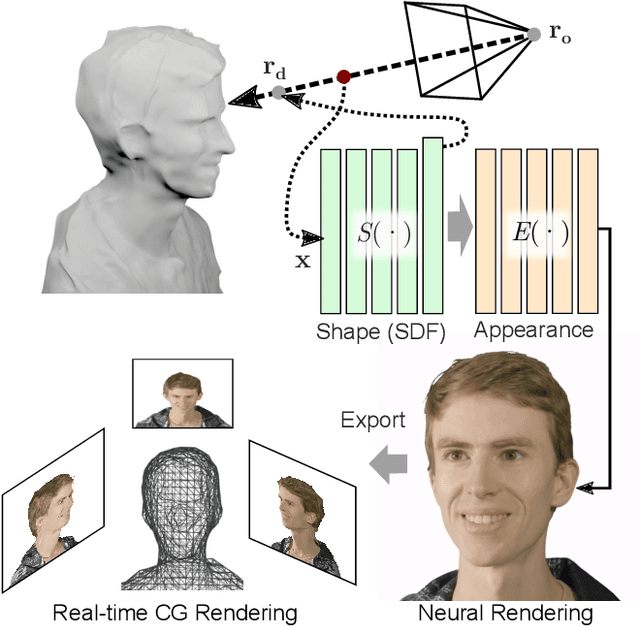


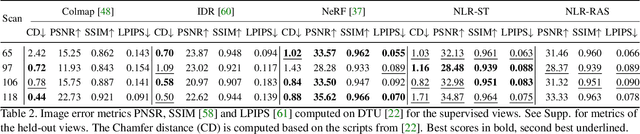
Novel view synthesis is a challenging and ill-posed inverse rendering problem. Neural rendering techniques have recently achieved photorealistic image quality for this task. State-of-the-art (SOTA) neural volume rendering approaches, however, are slow to train and require minutes of inference (i.e., rendering) time for high image resolutions. We adopt high-capacity neural scene representations with periodic activations for jointly optimizing an implicit surface and a radiance field of a scene supervised exclusively with posed 2D images. Our neural rendering pipeline accelerates SOTA neural volume rendering by about two orders of magnitude and our implicit surface representation is unique in allowing us to export a mesh with view-dependent texture information. Thus, like other implicit surface representations, ours is compatible with traditional graphics pipelines, enabling real-time rendering rates, while achieving unprecedented image quality compared to other surface methods. We assess the quality of our approach using existing datasets as well as high-quality 3D face data captured with a custom multi-camera rig.