 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inverting Generative Adversarial Renderer for Face Reconstruction
May 08, 2021


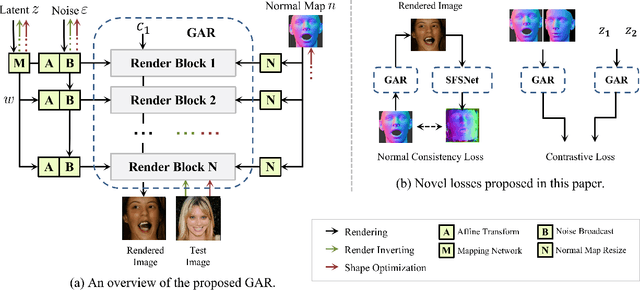
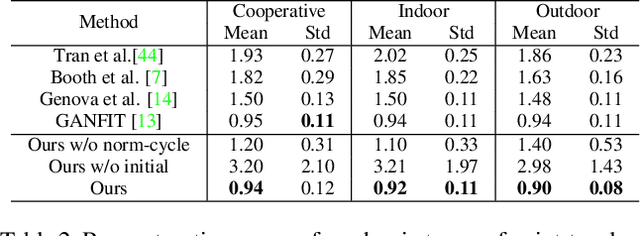
Given a monocular face image as input, 3D face geometry reconstruction aims to recover a corresponding 3D face mesh. Recently, both optimization-based and learning-based face reconstruction methods have taken advantage of the emerging differentiable renderer and shown promising results. However, the differentiable renderer, mainly based on graphics rules, simplifies the realistic mechanism of the illumination, reflection, \etc, of the real world, thus cannot produce realistic images. This brings a lot of domain-shift noise to the optimization or training process. In this work, we introduce a novel Generative Adversarial Renderer (GAR) and propose to tailor its inverted version to the general fitting pipeline, to tackle the above problem. Specifically, the carefully designed neural renderer takes a face normal map and a latent code representing other factors as inputs and renders a realistic face image. Since the GAR learns to model the complicated real-world image, instead of relying on the simplified graphics rules, it is capable of producing realistic images, which essentially inhibits the domain-shift noise in training and optimization. Equipped with the elaborated GAR, we further proposed a novel approach to predict 3D face parameters, in which we first obtain fine initial parameters via Renderer Inverting and then refine it with gradient-based optimizers. Extensive experiments have been conducted to demonstrate the effectiveness of the proposed generative adversarial renderer and the novel optimization-based face reconstruction framework. Our method achieves state-of-the-art performances on multiple face reconstruction datasets.
Exploring Cross-Image Pixel Contrast for Semantic Segmentation
Jan 30, 2021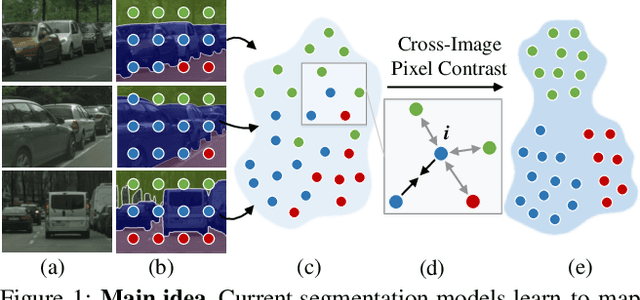
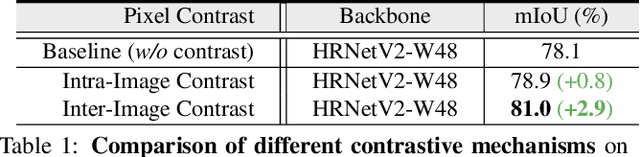
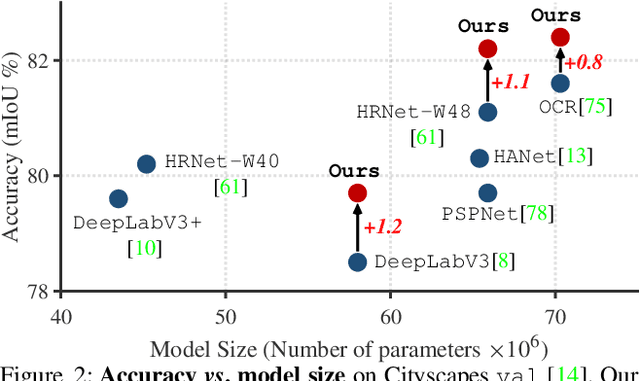

Current semantic segmentation methods focus only on mining "local" context, i.e., dependencies between pixels within individual images, by context-aggregation modules (e.g., dilated convolution, neural attention) or structure-aware optimization criteria (e.g., IoU-like loss). However, they ignore "global" context of the training data, i.e., rich semantic relations between pixels across different images. Inspired by the recent advance in unsupervised contrastive representation learning, we propose a pixel-wise contrastive framework for semantic segmentation in the fully supervised setting. The core idea is to enforce pixel embeddings belonging to a same semantic class to be more similar than embeddings from different classes. It raises a pixel-wise metric learning paradigm for semantic segmentation, by explicitly exploring the structures of labeled pixels, which are long ignored in the field. Our method can be effortlessly incorporated into existing segmentation frameworks without extra overhead during testing. We experimentally show that, with famous segmentation models (i.e., DeepLabV3, HRNet, OCR) and backbones (i.e., ResNet, HR-Net), our method brings consistent performance improvements across diverse datasets (i.e., Cityscapes, PASCAL-Context, COCO-Stuff). We expect this work will encourage our community to rethink the current de facto training paradigm in fully supervised semantic segmentation.
Image Synthesis From Reconfigurable Layout and Style
Aug 20, 2019
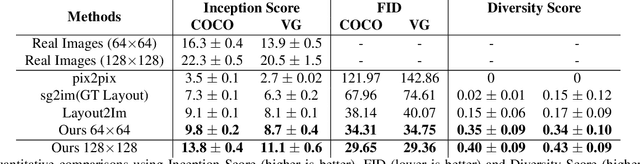
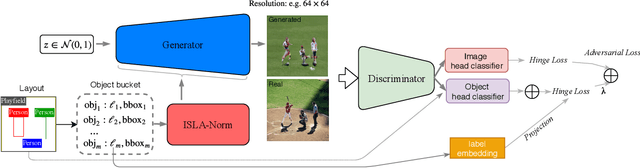
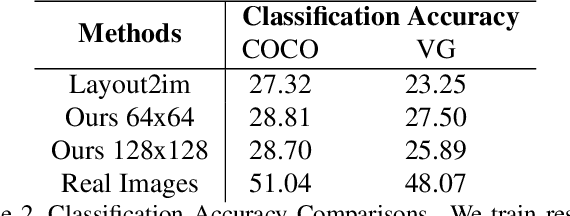
Despite remarkable recent progress on both unconditional and conditional image synthesis, it remains a long-standing problem to learn generative models that are capable of synthesizing realistic and sharp images from reconfigurable spatial layout (i.e., bounding boxes + class labels in an image lattice) and style (i.e., structural and appearance variations encoded by latent vectors), especially at high resolution. By reconfigurable, it means that a model can preserve the intrinsic one-to-many mapping from a given layout to multiple plausible images with different styles, and is adaptive with respect to perturbations of a layout and style latent code. In this paper, we present a layout- and style-based architecture for generative adversarial networks (termed LostGANs) that can be trained end-to-end to generate images from reconfigurable layout and style. Inspired by the vanilla StyleGAN, the proposed LostGAN consists of two new components: (i) learning fine-grained mask maps in a weakly-supervised manner to bridge the gap between layouts and images, and (ii) learning object instance-specific layout-aware feature normalization (ISLA-Norm) in the generator to realize multi-object style generation. In experiments, the proposed method is tested on the COCO-Stuff dataset and the Visual Genome dataset with state-of-the-art performance obtained. The code and pretrained models are available at \url{https://github.com/iVMCL/LostGANs}.
Adversarial training may be a double-edged sword
Jul 24, 2021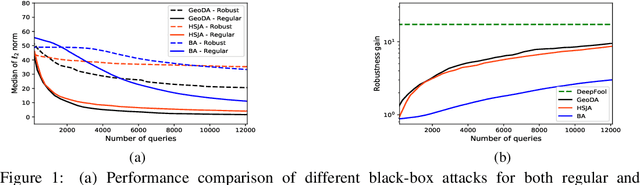

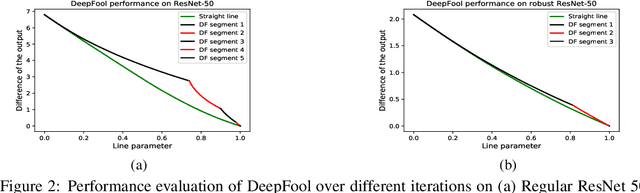
Adversarial training has been shown as an effective approach to improve the robustness of image classifiers against white-box attacks. However, its effectiveness against black-box attacks is more nuanced. In this work, we demonstrate that some geometric consequences of adversarial training on the decision boundary of deep networks give an edge to certain types of black-box attacks. In particular, we define a metric called robustness gain to show that while adversarial training is an effective method to dramatically improve the robustness in white-box scenarios, it may not provide such a good robustness gain against the more realistic decision-based black-box attacks. Moreover, we show that even the minimal perturbation white-box attacks can converge faster against adversarially-trained neural networks compared to the regular ones.
Impact of Aliasing on Generalization in Deep Convolutional Networks
Aug 07, 2021

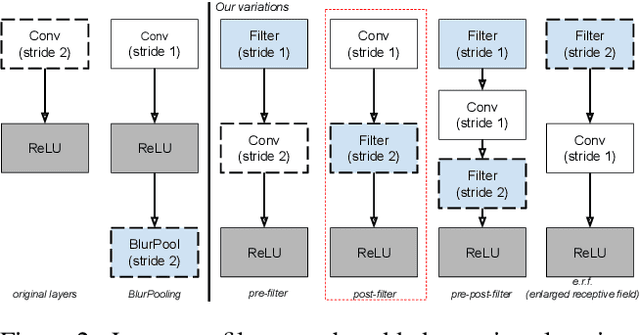
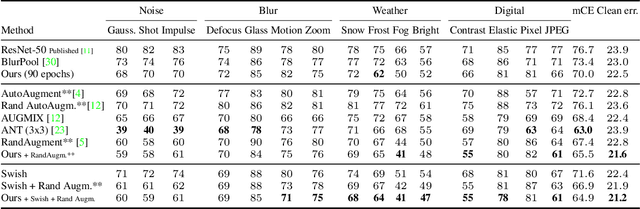
We investigate the impact of aliasing on generalization in Deep Convolutional Networks and show that data augmentation schemes alone are unable to prevent it due to structural limitations in widely used architectures. Drawing insights from frequency analysis theory, we take a closer look at ResNet and EfficientNet architectures and review the trade-off between aliasing and information loss in each of their major components. We show how to mitigate aliasing by inserting non-trainable low-pass filters at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in generalization on i.i.d. and even more on out-of-distribution conditions, such as image classification under natural corruptions on ImageNet-C [11] and few-shot learning on Meta-Dataset [26]. State-of-the art results are achieved on both datasets without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Residual Contrastive Learning for Joint Demosaicking and Denoising
Jun 18, 2021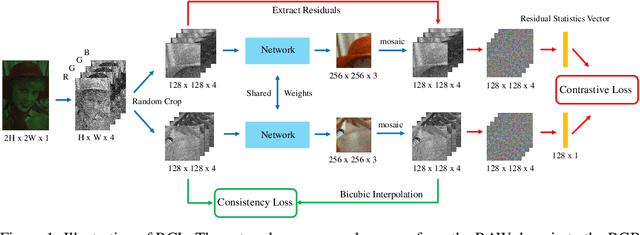
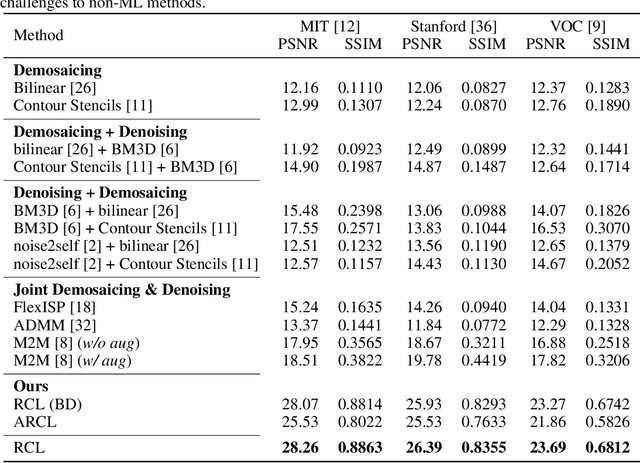

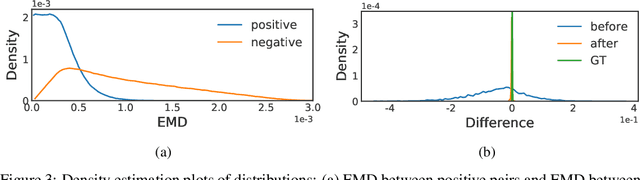
The breakthrough of contrastive learning (CL) has fueled the recent success of self-supervised learning (SSL) in high-level vision tasks on RGB images. However, CL is still ill-defined for low-level vision tasks, such as joint demosaicking and denoising (JDD), in the RAW domain. To bridge this methodological gap, we present a novel CL approach on RAW images, residual contrastive learning (RCL), which aims to learn meaningful representations for JDD. Our work is built on the assumption that noise contained in each RAW image is signal-dependent, thus two crops from the same RAW image should have more similar noise distribution than two crops from different RAW images. We use residuals as a discriminative feature and the earth mover's distance to measure the distribution divergence for the contrastive loss. To evaluate the proposed CL strategy, we simulate a series of unsupervised JDD experiments with large-scale data corrupted by synthetic signal-dependent noise, where we set a new benchmark for unsupervised JDD tasks with unknown (random) noise variance. Our empirical study not only validates that CL can be applied on distributions (c.f. features), but also exposes the lack of robustness of previous non-ML and SSL JDD methods when the statistics of the noise are unknown, thus providing some further insight into signal-dependent noise problems.
Graph Laplacian for Image Anomaly Detection
Oct 19, 2018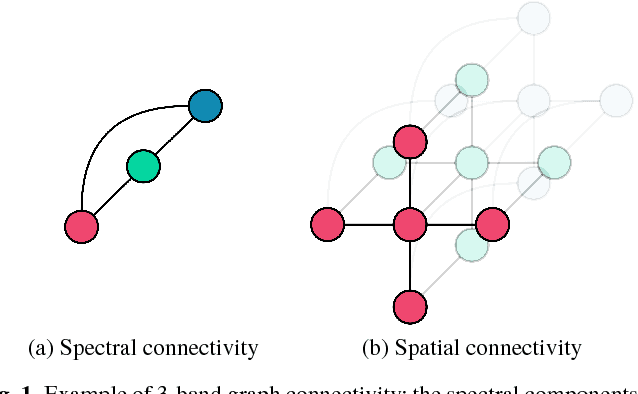
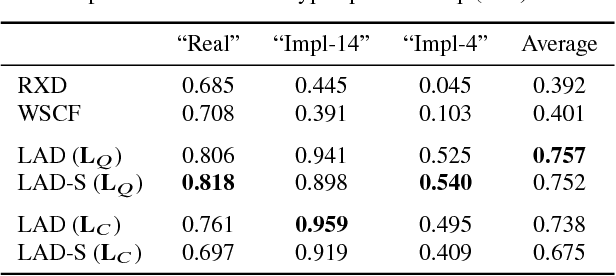

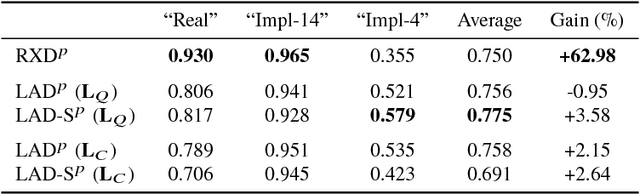
Reed-Xiaoli Detector (RXD) is recognized as the benchmark algorithm for image anomaly detection, however it presents known limitations, namely the dependence over the image following a multivariate Gaussian model, the estimation and inversion of a high dimensional covariance matrix and the inability to effectively include spatial awareness in its evaluation. In this work a novel graph-based solution to the image anomaly detection problem is proposed; leveraging on the Graph Fourier Transform, we are able to overcome some of RXD's limitations while reducing computational cost at the same time. Tests over both hyperspectral and medical images, using both synthetic and real anomalies, prove the proposed technique is able to obtain significant gains over performance by other algorithms in the state-of-the-art.
Adversarial purification with Score-based generative models
Jun 11, 2021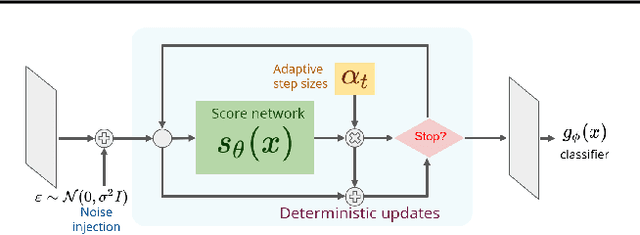

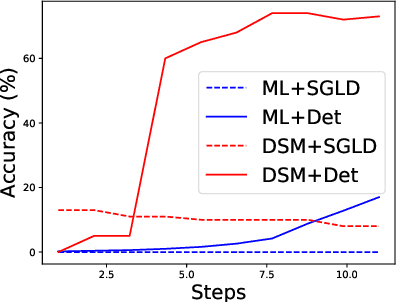
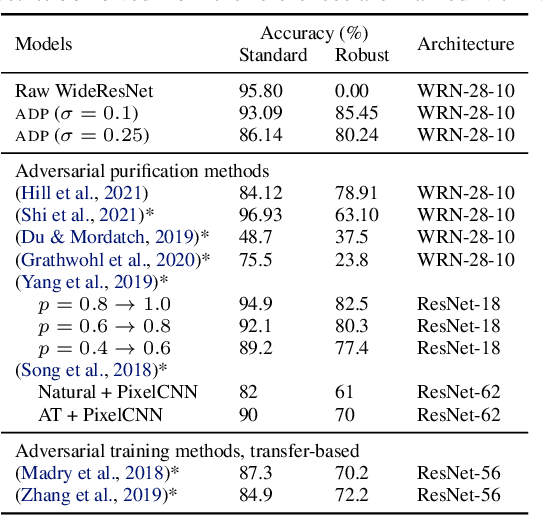
While adversarial training is considered as a standard defense method against adversarial attacks for image classifiers, adversarial purification, which purifies attacked images into clean images with a standalone purification model, has shown promises as an alternative defense method. Recently, an Energy-Based Model (EBM) trained with Markov-Chain Monte-Carlo (MCMC) has been highlighted as a purification model, where an attacked image is purified by running a long Markov-chain using the gradients of the EBM. Yet, the practicality of the adversarial purification using an EBM remains questionable because the number of MCMC steps required for such purification is too large. In this paper, we propose a novel adversarial purification method based on an EBM trained with Denoising Score-Matching (DSM). We show that an EBM trained with DSM can quickly purify attacked images within a few steps. We further introduce a simple yet effective randomized purification scheme that injects random noises into images before purification. This process screens the adversarial perturbations imposed on images by the random noises and brings the images to the regime where the EBM can denoise well. We show that our purification method is robust against various attacks and demonstrate its state-of-the-art performances.
Automatic prior selection for meta Bayesian optimization with a case study on tuning deep neural network optimizers
Sep 16, 2021
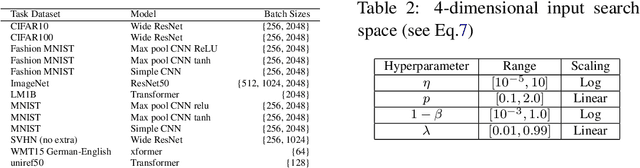
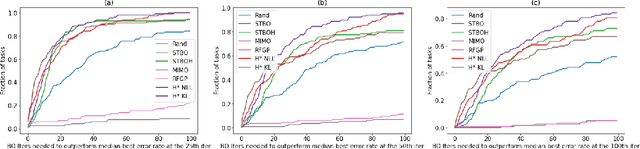
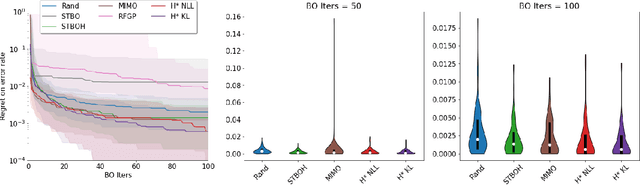
The performance of deep neural networks can be highly sensitive to the choice of a variety of meta-parameters, such as optimizer parameters and model hyperparameters. Tuning these well, however, often requires extensive and costly experimentation. Bayesian optimization (BO) is a principled approach to solve such expensive hyperparameter tuning problems efficiently. Key to the performance of BO is specifying and refining a distribution over functions, which is used to reason about the optima of the underlying function being optimized. In this work, we consider the scenario where we have data from similar functions that allows us to specify a tighter distribution a priori. Specifically, we focus on the common but potentially costly task of tuning optimizer parameters for training neural networks. Building on the meta BO method from Wang et al. (2018), we develop practical improvements that (a) boost its performance by leveraging tuning results on multiple tasks without requiring observations for the same meta-parameter points across all tasks, and (b) retain its regret bound for a special case of our method. As a result, we provide a coherent BO solution for iterative optimization of continuous optimizer parameters. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
Automatic Gaze Analysis: A Survey of Deep Learning based Approaches
Aug 30, 2021
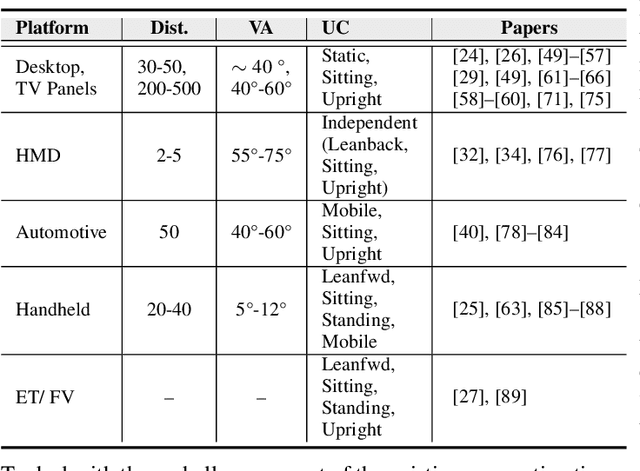
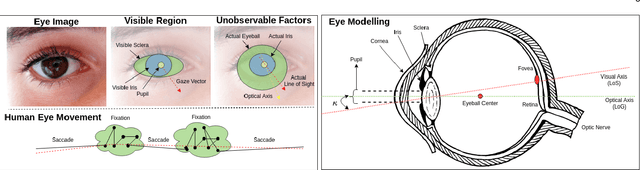
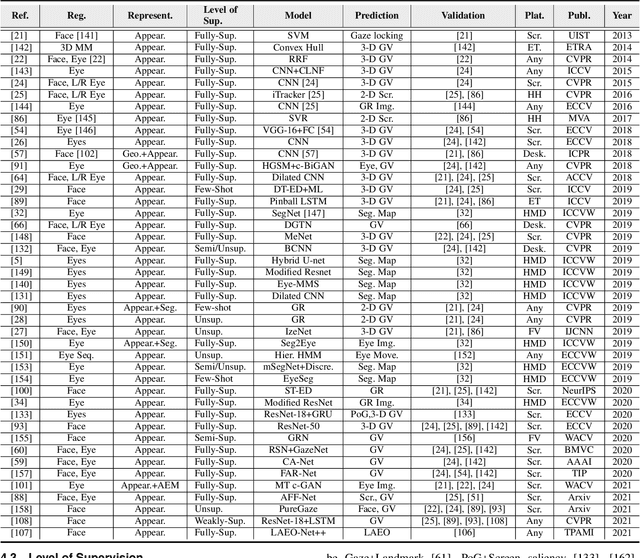
Eye gaze analysis is an important research problem in the field of Computer Vision and Human-Computer Interaction. Even with notable progress in the last 10 years, automatic gaze analysis still remains challenging due to the uniqueness of eye appearance, eye-head interplay, occlusion, image quality, and illumination conditions. There are several open questions including what are the important cues to interpret gaze direction in an unconstrained environment without prior knowledge and how to encode them in real-time. We review the progress across a range of gaze analysis tasks and applications to elucidate these fundamental questions; identify effective methods in gaze analysis and provide possible future directions. We analyze recent gaze estimation and segmentation methods, especially in the unsupervised and weakly supervised domain, based on their advantages and reported evaluation metrics. Our analysis shows that the development of a robust and generic gaze analysis method still needs to address real-world challenges such as unconstrained setup and learning with less supervision. We conclude by discussing future research directions for designing a real-world gaze analysis system that can propagate to other domains including Computer Vision, Augmented Reality (AR), Virtual Reality (VR), and Human Computer Interaction (HCI). Project Page: https://github.com/i-am-shreya/EyeGazeSurvey}{https://github.com/i-am-shreya/EyeGazeSurvey