 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LiftPool: Bidirectional ConvNet Pooling
Apr 02, 2021
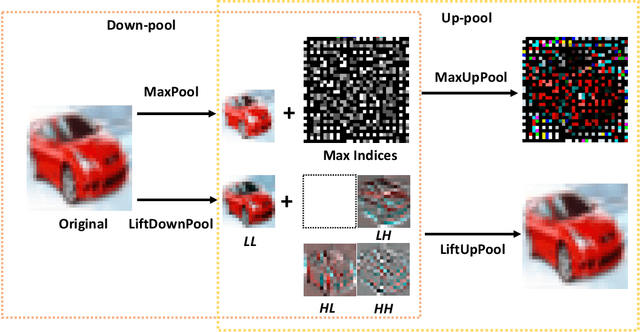
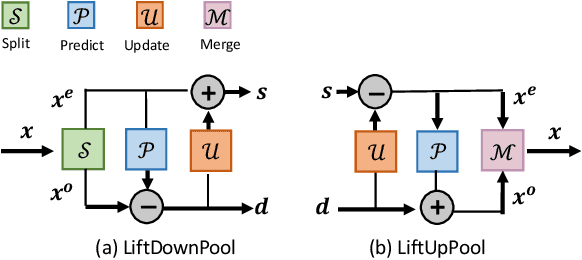
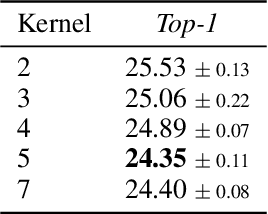
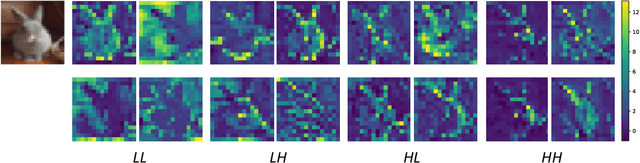
Pooling is a critical operation in convolutional neural networks for increasing receptive fields and improving robustness to input variations. Most existing pooling operations downsample the feature maps, which is a lossy process. Moreover, they are not invertible: upsampling a downscaled feature map can not recover the lost information in the downsampling. By adopting the philosophy of the classical Lifting Scheme from signal processing, we propose LiftPool for bidirectional pooling layers, including LiftDownPool and LiftUpPool. LiftDownPool decomposes a feature map into various downsized sub-bands, each of which contains information with different frequencies. As the pooling function in LiftDownPool is perfectly invertible, by performing LiftDownPool backward, a corresponding up-pooling layer LiftUpPool is able to generate a refined upsampled feature map using the detail sub-bands, which is useful for image-to-image translation challenges. Experiments show the proposed methods achieve better results on image classification and semantic segmentation, using various backbones. Moreover, LiftDownPool offers better robustness to input corruptions and perturbations.
Spike time displacement based error backpropagation in convolutional spiking neural networks
Aug 31, 2021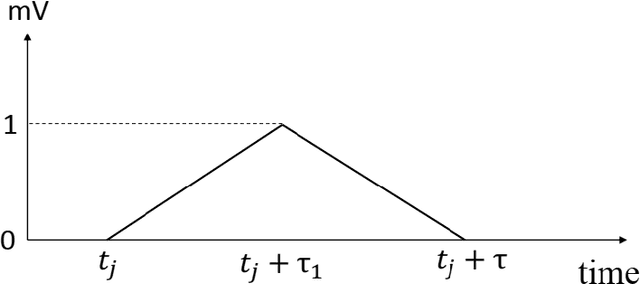
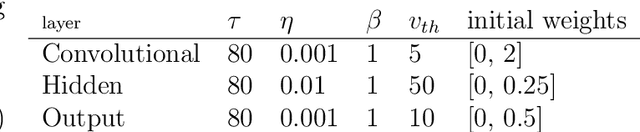
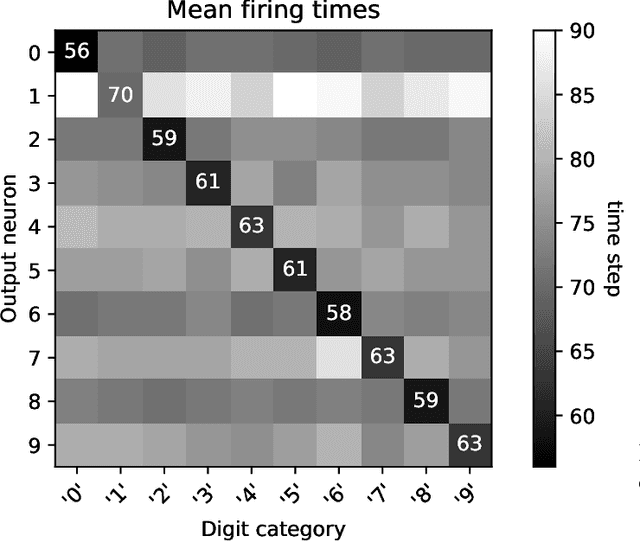

We recently proposed the STiDi-BP algorithm, which avoids backward recursive gradient computation, for training multi-layer spiking neural networks (SNNs) with single-spike-based temporal coding. The algorithm employs a linear approximation to compute the derivative of the spike latency with respect to the membrane potential and it uses spiking neurons with piecewise linear postsynaptic potential to reduce the computational cost and the complexity of neural processing. In this paper, we extend the STiDi-BP algorithm to employ it in deeper and convolutional architectures. The evaluation results on the image classification task based on two popular benchmarks, MNIST and Fashion-MNIST datasets with the accuracies of respectively 99.2% and 92.8%, confirm that this algorithm has been applicable in deep SNNs. Another issue we consider is the reduction of memory storage and computational cost. To do so, we consider a convolutional SNN (CSNN) with two sets of weights: real-valued weights that are updated in the backward pass and their signs, binary weights, that are employed in the feedforward process. We evaluate the binary CSNN on two datasets of MNIST and Fashion-MNIST and obtain acceptable performance with a negligible accuracy drop with respect to real-valued weights (about $0.6%$ and $0.8%$ drops, respectively).
Transfer Learning for Pose Estimation of Illustrated Characters
Aug 04, 2021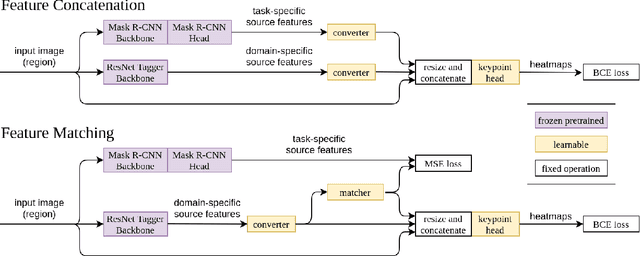
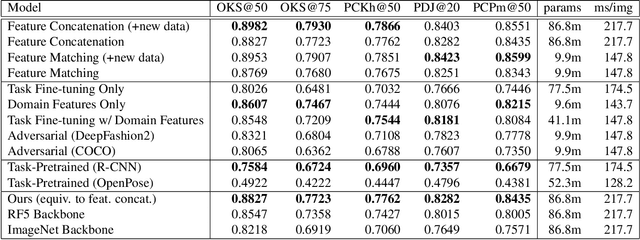
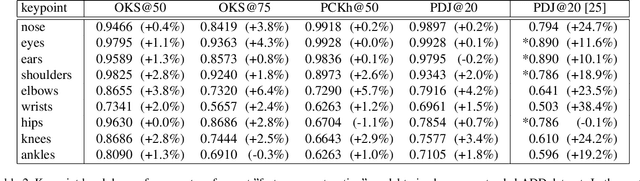

Human pose information is a critical component in many downstream image processing tasks, such as activity recognition and motion tracking. Likewise, a pose estimator for the illustrated character domain would provide a valuable prior for assistive content creation tasks, such as reference pose retrieval and automatic character animation. But while modern data-driven techniques have substantially improved pose estimation performance on natural images, little work has been done for illustrations. In our work, we bridge this domain gap by efficiently transfer-learning from both domain-specific and task-specific source models. Additionally, we upgrade and expand an existing illustrated pose estimation dataset, and introduce two new datasets for classification and segmentation subtasks. We then apply the resultant state-of-the-art character pose estimator to solve the novel task of pose-guided illustration retrieval. All data, models, and code will be made publicly available.
ADTrack: Target-Aware Dual Filter Learning for Real-Time Anti-Dark UAV Tracking
Jun 04, 2021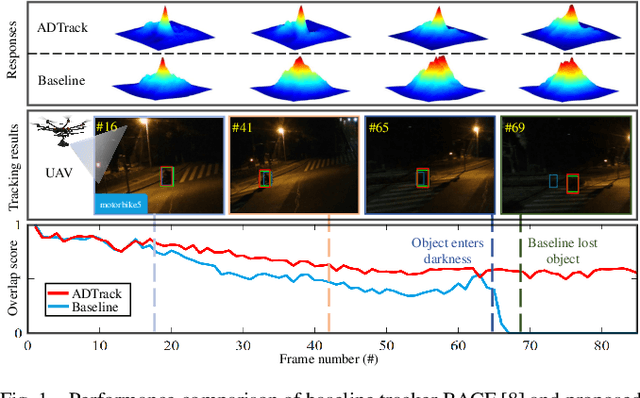
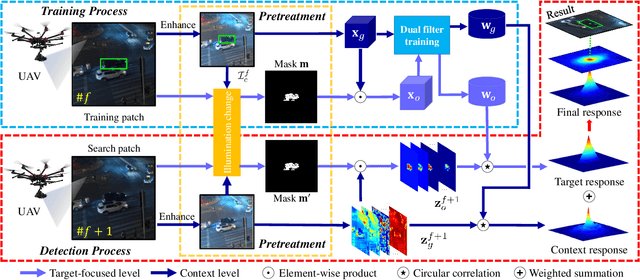
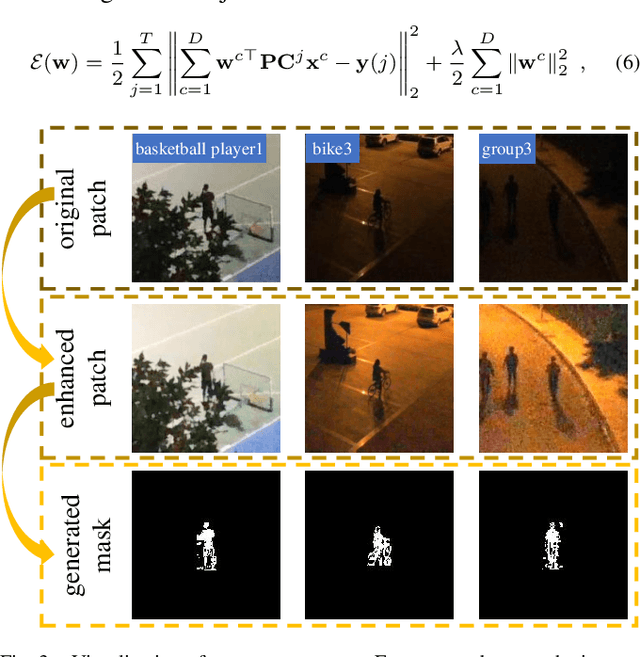
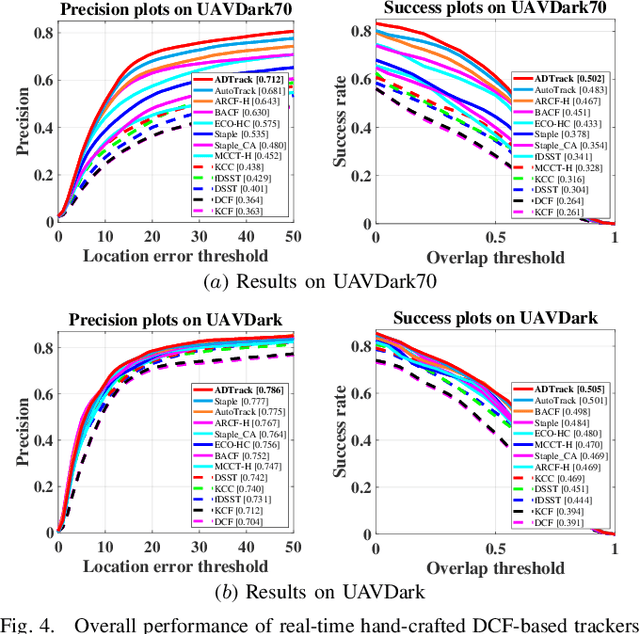
Prior correlation filter (CF)-based tracking methods for unmanned aerial vehicles (UAVs) have virtually focused on tracking in the daytime. However, when the night falls, the trackers will encounter more harsh scenes, which can easily lead to tracking failure. In this regard, this work proposes a novel tracker with anti-dark function (ADTrack). The proposed method integrates an efficient and effective low-light image enhancer into a CF-based tracker. Besides, a target-aware mask is simultaneously generated by virtue of image illumination variation. The target-aware mask can be applied to jointly train a target-focused filter that assists the context filter for robust tracking. Specifically, ADTrack adopts dual regression, where the context filter and the target-focused filter restrict each other for dual filter learning. Exhaustive experiments are conducted on typical dark sceneries benchmark, consisting of 37 typical night sequences from authoritative benchmarks, i.e., UAVDark, and our newly constructed benchmark UAVDark70. The results have shown that ADTrack favorably outperforms other state-of-the-art trackers and achieves a real-time speed of 34 frames/s on a single CPU, greatly extending robust UAV tracking to night scenes.
SERF: Towards better training of deep neural networks using log-Softplus ERror activation Function
Aug 24, 2021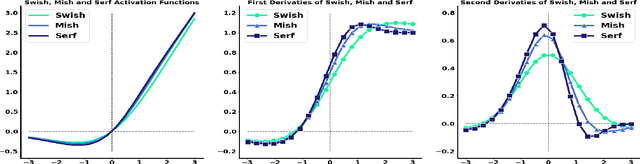
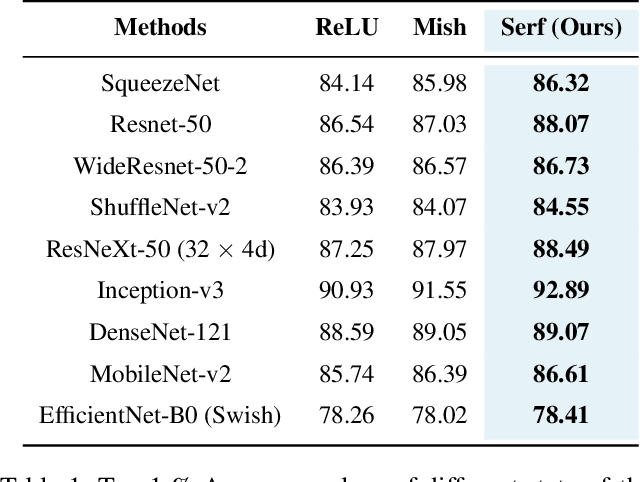
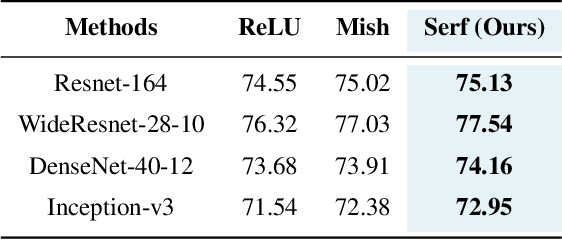
Activation functions play a pivotal role in determining the training dynamics and neural network performance. The widely adopted activation function ReLU despite being simple and effective has few disadvantages including the Dying ReLU problem. In order to tackle such problems, we propose a novel activation function called Serf which is self-regularized and nonmonotonic in nature. Like Mish, Serf also belongs to the Swish family of functions. Based on several experiments on computer vision (image classification and object detection) and natural language processing (machine translation, sentiment classification and multimodal entailment) tasks with different state-of-the-art architectures, it is observed that Serf vastly outperforms ReLU (baseline) and other activation functions including both Swish and Mish, with a markedly bigger margin on deeper architectures. Ablation studies further demonstrate that Serf based architectures perform better than those of Swish and Mish in varying scenarios, validating the effectiveness and compatibility of Serf with varying depth, complexity, optimizers, learning rates, batch sizes, initializers and dropout rates. Finally, we investigate the mathematical relation between Swish and Serf, thereby showing the impact of preconditioner function ingrained in the first derivative of Serf which provides a regularization effect making gradients smoother and optimization faster.
Relation Network for Multi-label Aerial Image Classification
Jul 16, 2019
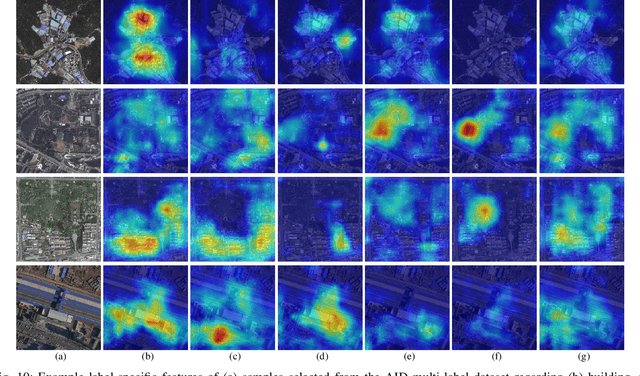
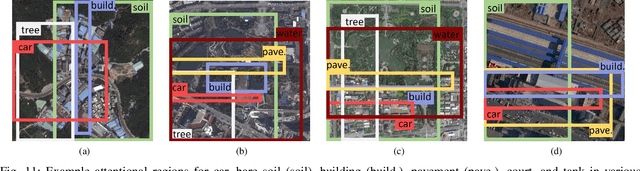
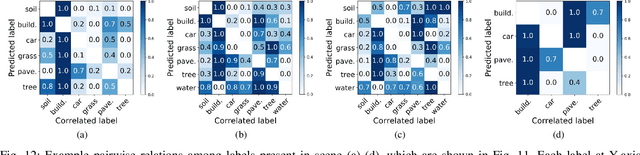
Multi-label classification plays a momentous role in perceiving intricate contents of an aerial image and triggers several related studies over the last years. However, most of them deploy few efforts in exploiting label relations, while such dependencies are crucial for making accurate predictions. Although an LSTM layer can be introduced to modeling such label dependencies in a chain propagation manner, the efficiency might be questioned when certain labels are improperly inferred. To address this, we propose a novel aerial image multi-label classification network, attention-aware label relational reasoning network. Particularly, our network consists of three elemental modules: 1) a label-wise feature parcel learning module, 2) an attentional region extraction module, and 3) a label relational inference module. To be more specific, the label-wise feature parcel learning module is designed for extracting high-level label-specific features. The attentional region extraction module aims at localizing discriminative regions in these features and yielding attentional label-specific features. The label relational inference module finally predicts label existences using label relations reasoned from outputs of the previous module. The proposed network is characterized by its capacities of extracting discriminative label-wise features in a proposal-free way and reasoning about label relations naturally and interpretably. In our experiments, we evaluate the proposed model on the UCM multi-label dataset and a newly produced dataset, AID multi-label dataset. Quantitative and qualitative results on these two datasets demonstrate the effectiveness of our model. To facilitate progress in the multi-label aerial image classification, the AID multi-label dataset will be made publicly available.
Learning Fuzzy Clustering for SPECT/CT Segmentation via Convolutional Neural Networks
Apr 17, 2021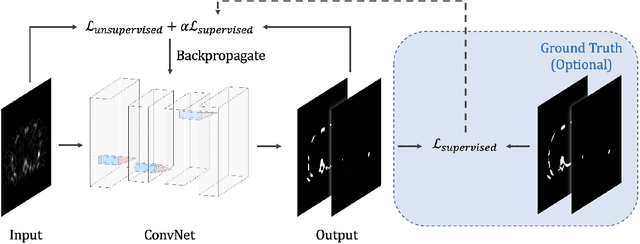
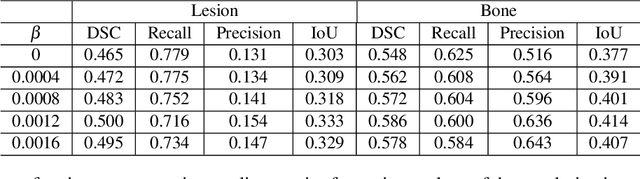
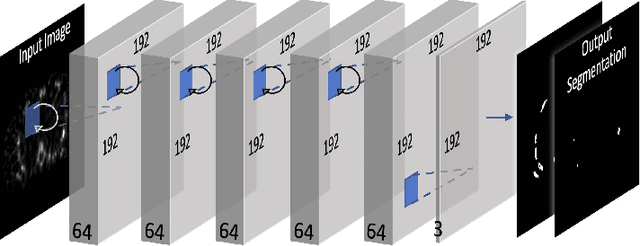
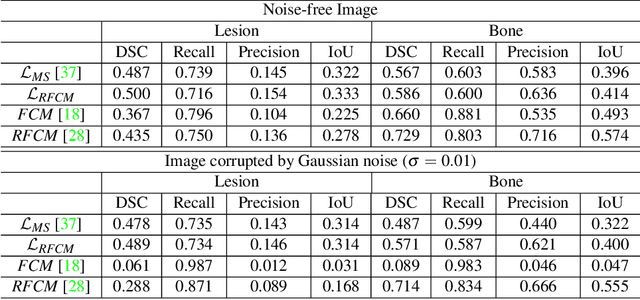
Quantitative bone single-photon emission computed tomography (QBSPECT) has the potential to provide a better quantitative assessment of bone metastasis than planar bone scintigraphy due to its ability to better quantify activity in overlapping structures. An important element of assessing response of bone metastasis is accurate image segmentation. However, limited by the properties of QBSPECT images, the segmentation of anatomical regions-of-interests (ROIs) still relies heavily on the manual delineation by experts. This work proposes a fast and robust automated segmentation method for partitioning a QBSPECT image into lesion, bone, and background. We present a new unsupervised segmentation loss function and its semi- and supervised variants for training a convolutional neural network (ConvNet). The loss functions were developed based on the objective function of the classical Fuzzy C-means (FCM) algorithm. We conducted a comprehensive study to compare our proposed methods with ConvNets trained using supervised loss functions and conventional clustering methods. The Dice similarity coefficient (DSC) and several other metrics were used as figures of merit as applied to the task of delineating lesion and bone in both simulated and clinical SPECT/CT images. We experimentally demonstrated that the proposed methods yielded good segmentation results on a clinical dataset even though the training was done using realistic simulated images. A ConvNet-based image segmentation method that uses novel loss functions was developed and evaluated. The method can operate in unsupervised, semi-supervised, or fully-supervised modes depending on the availability of annotated training data. The results demonstrated that the proposed method provides fast and robust lesion and bone segmentation for QBSPECT/CT. The method can potentially be applied to other medical image segmentation applications.
Spatially Consistent Representation Learning
Mar 10, 2021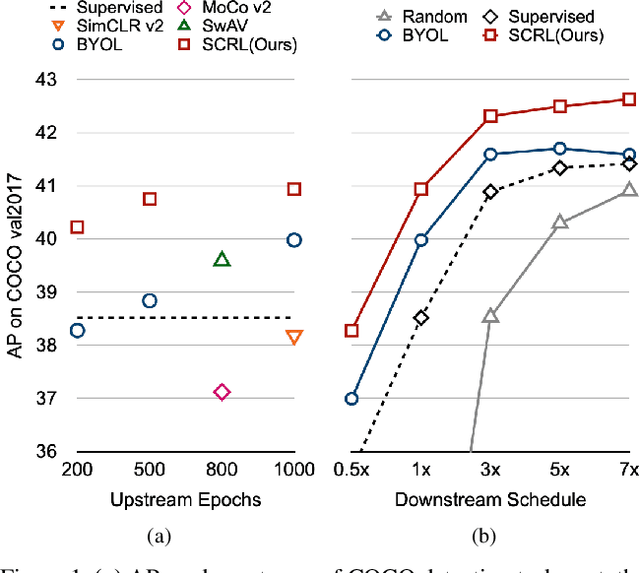

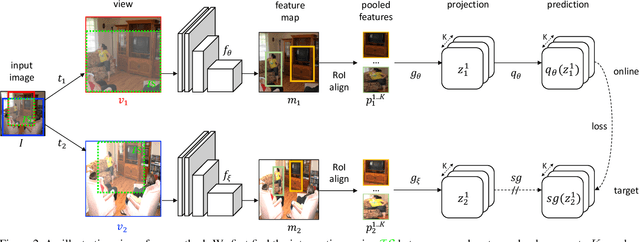
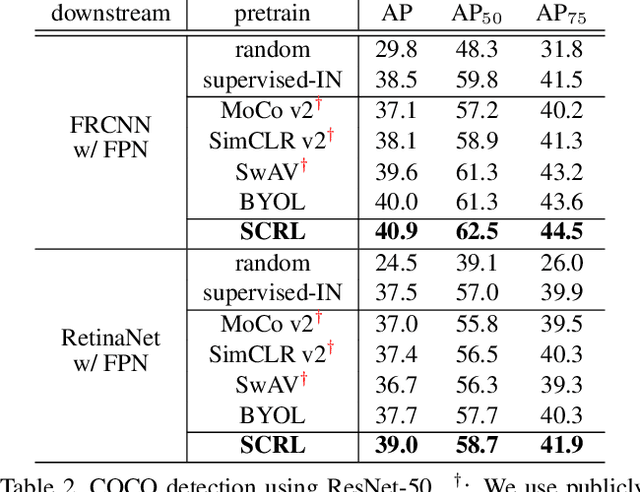
Self-supervised learning has been widely used to obtain transferrable representations from unlabeled images. Especially, recent contrastive learning methods have shown impressive performances on downstream image classification tasks. While these contrastive methods mainly focus on generating invariant global representations at the image-level under semantic-preserving transformations, they are prone to overlook spatial consistency of local representations and therefore have a limitation in pretraining for localization tasks such as object detection and instance segmentation. Moreover, aggressively cropped views used in existing contrastive methods can minimize representation distances between the semantically different regions of a single image. In this paper, we propose a spatially consistent representation learning algorithm (SCRL) for multi-object and location-specific tasks. In particular, we devise a novel self-supervised objective that tries to produce coherent spatial representations of a randomly cropped local region according to geometric translations and zooming operations. On various downstream localization tasks with benchmark datasets, the proposed SCRL shows significant performance improvements over the image-level supervised pretraining as well as the state-of-the-art self-supervised learning methods.
Improving Music Performance Assessment with Contrastive Learning
Aug 03, 2021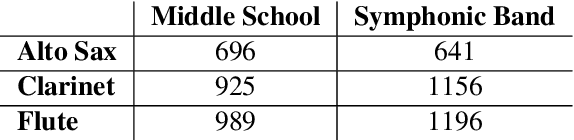
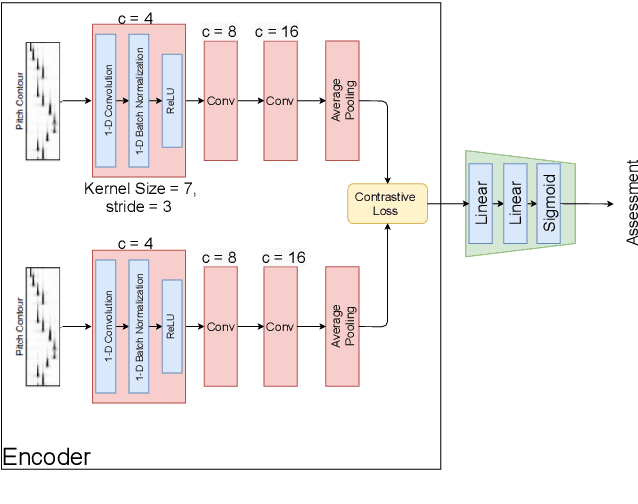
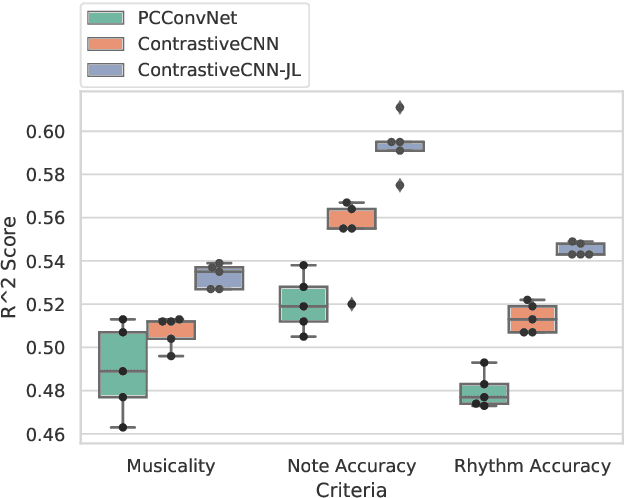
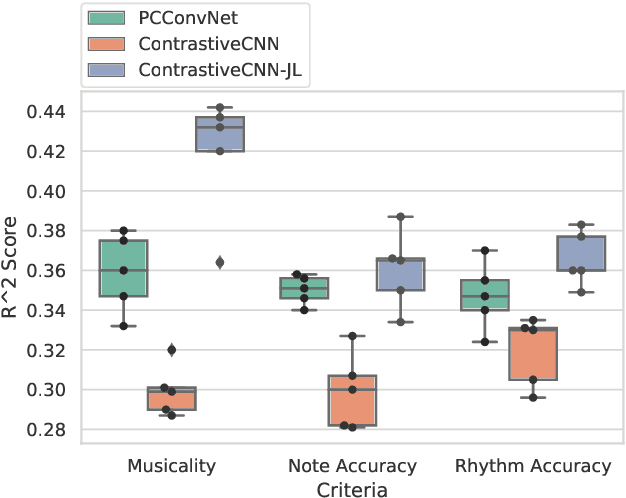
Several automatic approaches for objective music performance assessment (MPA) have been proposed in the past, however, existing systems are not yet capable of reliably predicting ratings with the same accuracy as professional judges. This study investigates contrastive learning as a potential method to improve existing MPA systems. Contrastive learning is a widely used technique in representation learning to learn a structured latent space capable of separately clustering multiple classes. It has been shown to produce state of the art results for image-based classification problems. We introduce a weighted contrastive loss suitable for regression tasks applied to a convolutional neural network and show that contrastive loss results in performance gains in regression tasks for MPA. Our results show that contrastive-based methods are able to match and exceed SoTA performance for MPA regression tasks by creating better class clusters within the latent space of the neural networks.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 17, 2021
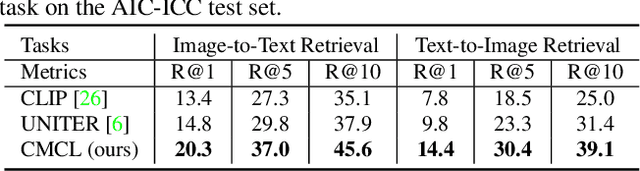
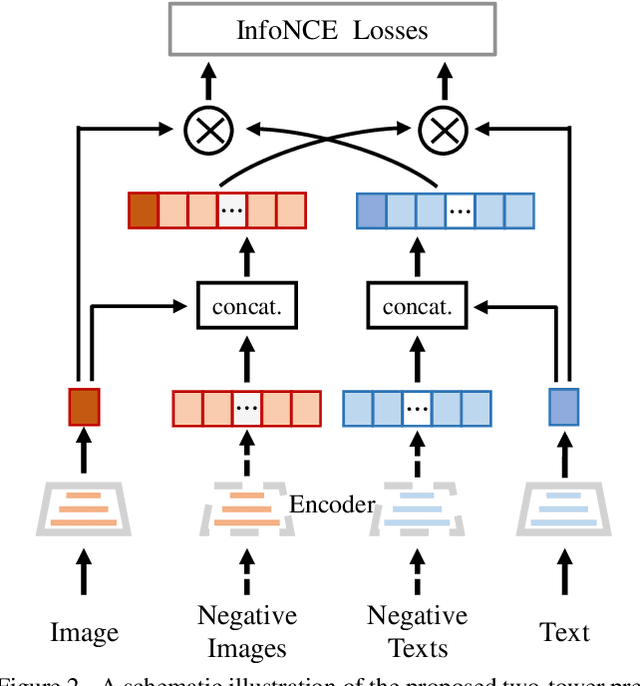
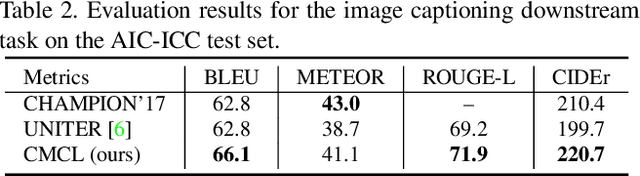
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.