 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InverseRenderNet: Learning single image inverse rendering
Nov 29, 2018
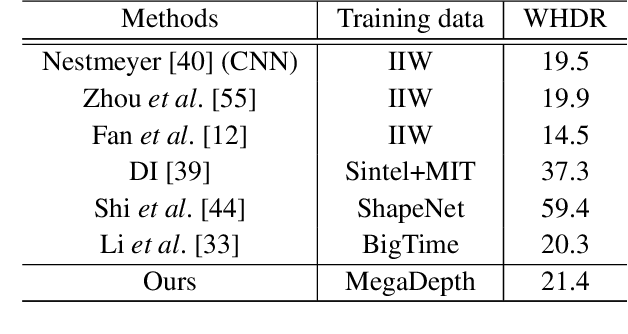
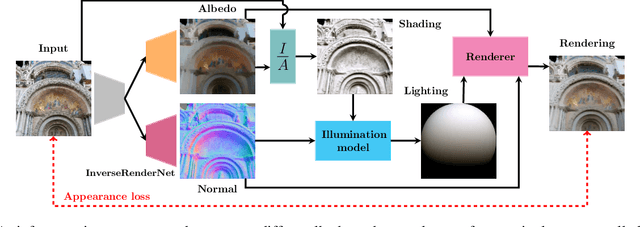
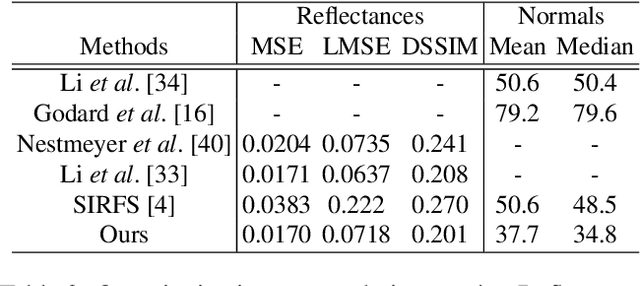
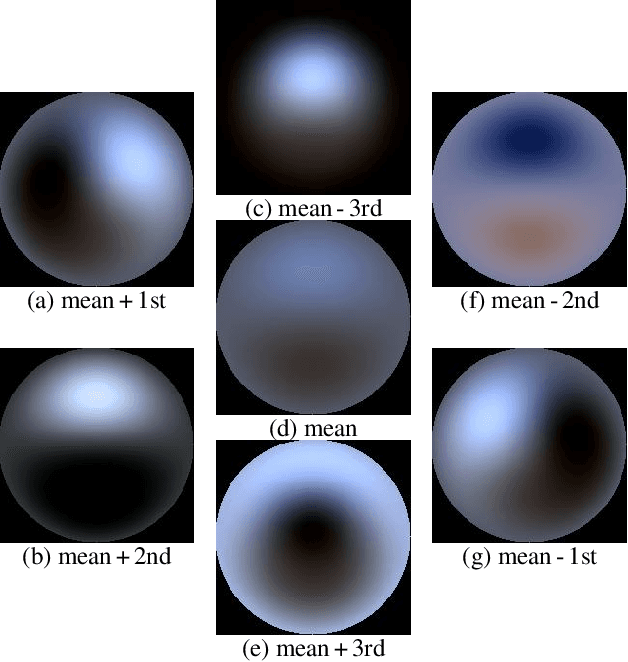
We show how to train a fully convolutional neural network to perform inverse rendering from a single, uncontrolled image. The network takes an RGB image as input, regresses albedo and normal maps from which we compute lighting coefficients. Our network is trained using large uncontrolled image collections without ground truth. By incorporating a differentiable renderer, our network can learn from self-supervision. Since the problem is ill-posed we introduce additional supervision: 1. We learn a statistical natural illumination prior, 2. Our key insight is to perform offline multiview stereo (MVS) on images containing rich illumination variation. From the MVS pose and depth maps, we can cross project between overlapping views such that Siamese training can be used to ensure consistent estimation of photometric invariants. MVS depth also provides direct coarse supervision for normal map estimation. We believe this is the first attempt to use MVS supervision for learning inverse rendering.
Leveraging Self-supervised Denoising for Image Segmentation
Nov 27, 2019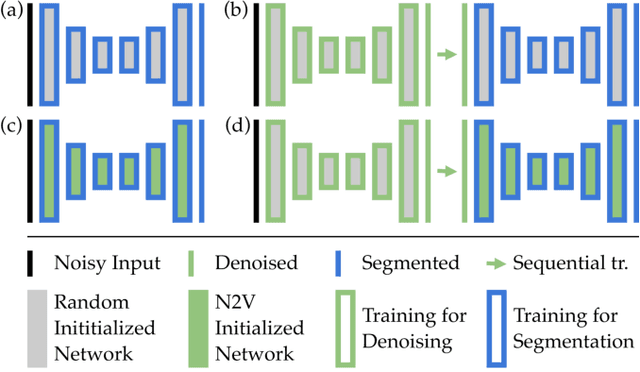
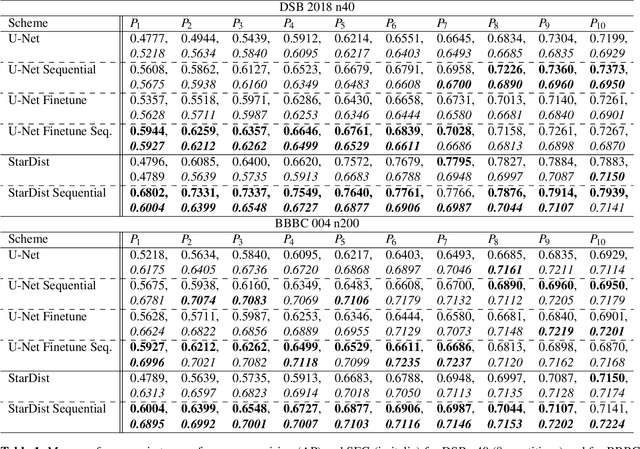
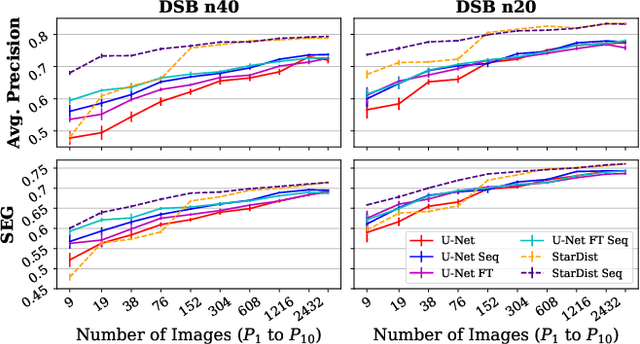
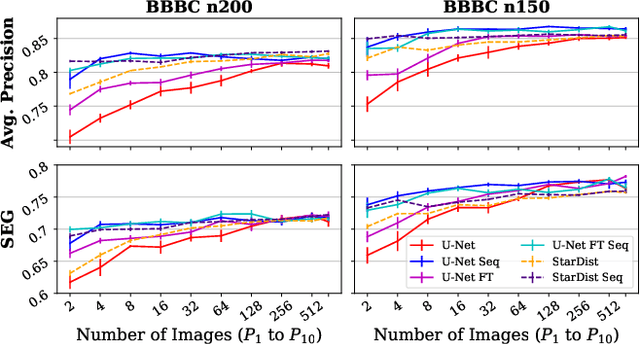
Deep learning (DL) has arguably emerged as the method of choice for the detection and segmentation of biological structures in microscopy images. However, DL typically needs copious amounts of annotated training data that is for biomedical projects typically not available and excessively expensive to generate. Additionally, tasks become harder in the presence of noise, requiring even more high-quality training data. Hence, we propose to use denoising networks to improve the performance of other DL-based image segmentation methods. More specifically, we present ideas on how state-of-the-art self-supervised CARE networks can improve cell/nuclei segmentation in microscopy data. Using two state-of-the-art baseline methods, U-Net and StarDist, we show that our ideas consistently improve the quality of resulting segmentations, especially when only limited training data for noisy micrographs are available.
Memory Guided Road Detection
Jun 27, 2021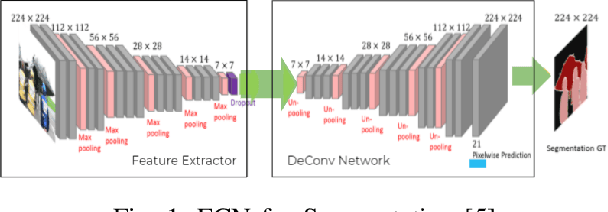


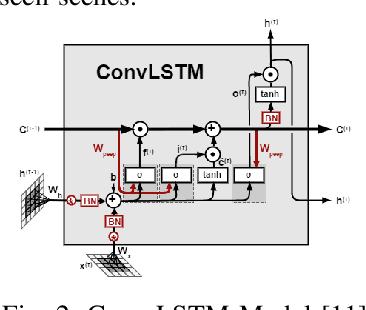
In self driving car applications, there is a requirement to predict the location of the lane given an input RGB front facing image. In this paper, we propose an architecture that allows us to increase the speed and robustness of road detection without a large hit in accuracy by introducing an underlying shared feature space that is propagated over time, which serves as a flowing dynamic memory. By utilizing the gist of previous frames, we train the network to predict the current road with a greater accuracy and lesser deviation from previous frames.
Intriguing Properties of Vision Transformers
May 21, 2021



Vision transformers (ViT) have demonstrated impressive performance across various machine vision problems. These models are based on multi-head self-attention mechanisms that can flexibly attend to a sequence of image patches to encode contextual cues. An important question is how such flexibility in attending image-wide context conditioned on a given patch can facilitate handling nuisances in natural images e.g., severe occlusions, domain shifts, spatial permutations, adversarial and natural perturbations. We systematically study this question via an extensive set of experiments encompassing three ViT families and comparisons with a high-performing convolutional neural network (CNN). We show and analyze the following intriguing properties of ViT: (a) Transformers are highly robust to severe occlusions, perturbations and domain shifts, e.g., retain as high as 60% top-1 accuracy on ImageNet even after randomly occluding 80% of the image content. (b) The robust performance to occlusions is not due to a bias towards local textures, and ViTs are significantly less biased towards textures compared to CNNs. When properly trained to encode shape-based features, ViTs demonstrate shape recognition capability comparable to that of human visual system, previously unmatched in the literature. (c) Using ViTs to encode shape representation leads to an interesting consequence of accurate semantic segmentation without pixel-level supervision. (d) Off-the-shelf features from a single ViT model can be combined to create a feature ensemble, leading to high accuracy rates across a range of classification datasets in both traditional and few-shot learning paradigms. We show effective features of ViTs are due to flexible and dynamic receptive fields possible via the self-attention mechanism.
Coarse-to-fine Semantic Segmentation from Image-level Labels
Dec 28, 2018
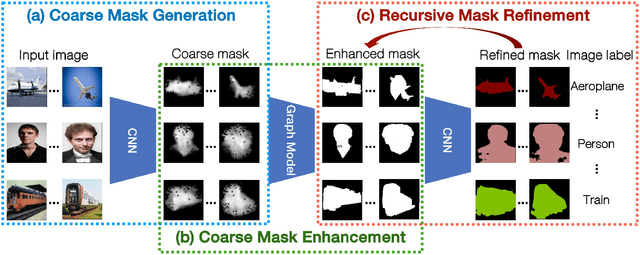
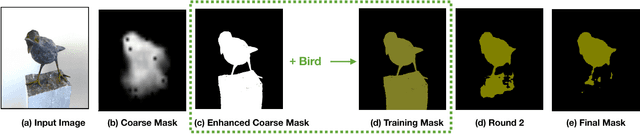

Deep neural network-based semantic segmentation generally requires large-scale cost extensive annotations for training to obtain better performance. To avoid pixel-wise segmentation annotations which are needed for most methods, recently some researchers attempted to use object-level labels (e.g. bounding boxes) or image-level labels (e.g. image categories). In this paper, we propose a novel recursive coarse-to-fine semantic segmentation framework based on only image-level category labels. For each image, an initial coarse mask is first generated by a convolutional neural network-based unsupervised foreground segmentation model and then is enhanced by a graph model. The enhanced coarse mask is fed to a fully convolutional neural network to be recursively refined. Unlike existing image-level label-based semantic segmentation methods which require to label all categories for images contain multiple types of objects, our framework only needs one label for each image and can handle images contains multi-category objects. With only trained on ImageNet, our framework achieves comparable performance on PASCAL VOC dataset as other image-level label-based state-of-the-arts of semantic segmentation. Furthermore, our framework can be easily extended to foreground object segmentation task and achieves comparable performance with the state-of-the-art supervised methods on the Internet Object dataset.
Self-Guided Instance-Aware Network for Depth Completion and Enhancement
May 27, 2021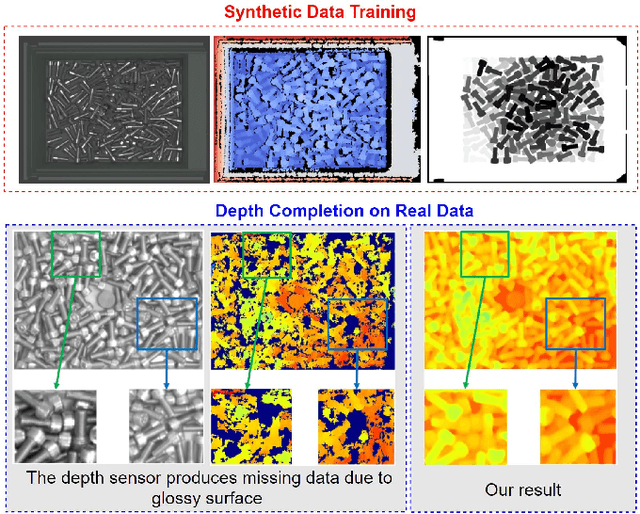
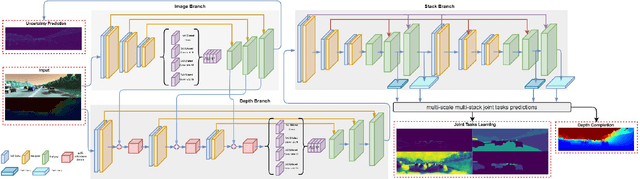
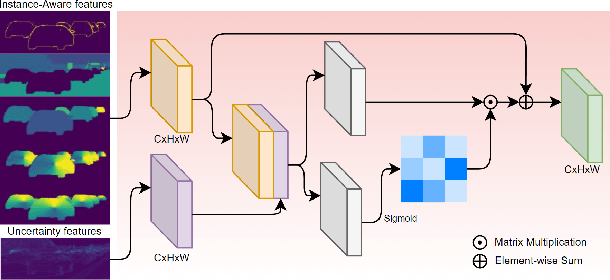
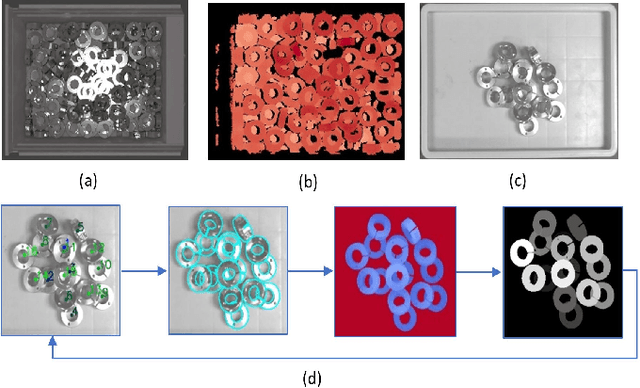
Depth completion aims at inferring a dense depth image from sparse depth measurement since glossy, transparent or distant surface cannot be scanned properly by the sensor. Most of existing methods directly interpolate the missing depth measurements based on pixel-wise image content and the corresponding neighboring depth values. Consequently, this leads to blurred boundaries or inaccurate structure of object. To address these problems, we propose a novel self-guided instance-aware network (SG-IANet) that: (1) utilize self-guided mechanism to extract instance-level features that is needed for depth restoration, (2) exploit the geometric and context information into network learning to conform to the underlying constraints for edge clarity and structure consistency, (3) regularize the depth estimation and mitigate the impact of noise by instance-aware learning, and (4) train with synthetic data only by domain randomization to bridge the reality gap. Extensive experiments on synthetic and real world dataset demonstrate that our proposed method outperforms previous works. Further ablation studies give more insights into the proposed method and demonstrate the generalization capability of our model.
XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
Jul 10, 2018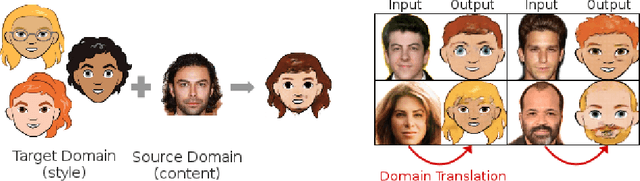

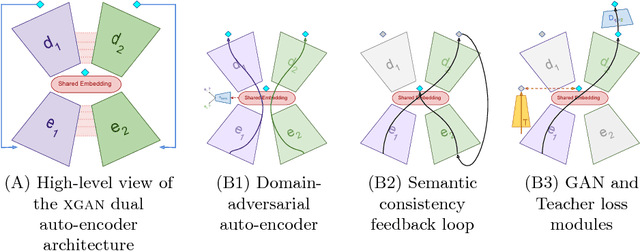

Style transfer usually refers to the task of applying color and texture information from a specific style image to a given content image while preserving the structure of the latter. Here we tackle the more generic problem of semantic style transfer: given two unpaired collections of images, we aim to learn a mapping between the corpus-level style of each collection, while preserving semantic content shared across the two domains. We introduce XGAN ("Cross-GAN"), a dual adversarial autoencoder, which captures a shared representation of the common domain semantic content in an unsupervised way, while jointly learning the domain-to-domain image translations in both directions. We exploit ideas from the domain adaptation literature and define a semantic consistency loss which encourages the model to preserve semantics in the learned embedding space. We report promising qualitative results for the task of face-to-cartoon translation. The cartoon dataset, CartoonSet, we collected for this purpose is publicly available at google.github.io/cartoonset/ as a new benchmark for semantic style transfer.
Contextual Convolutional Neural Networks
Aug 17, 2021
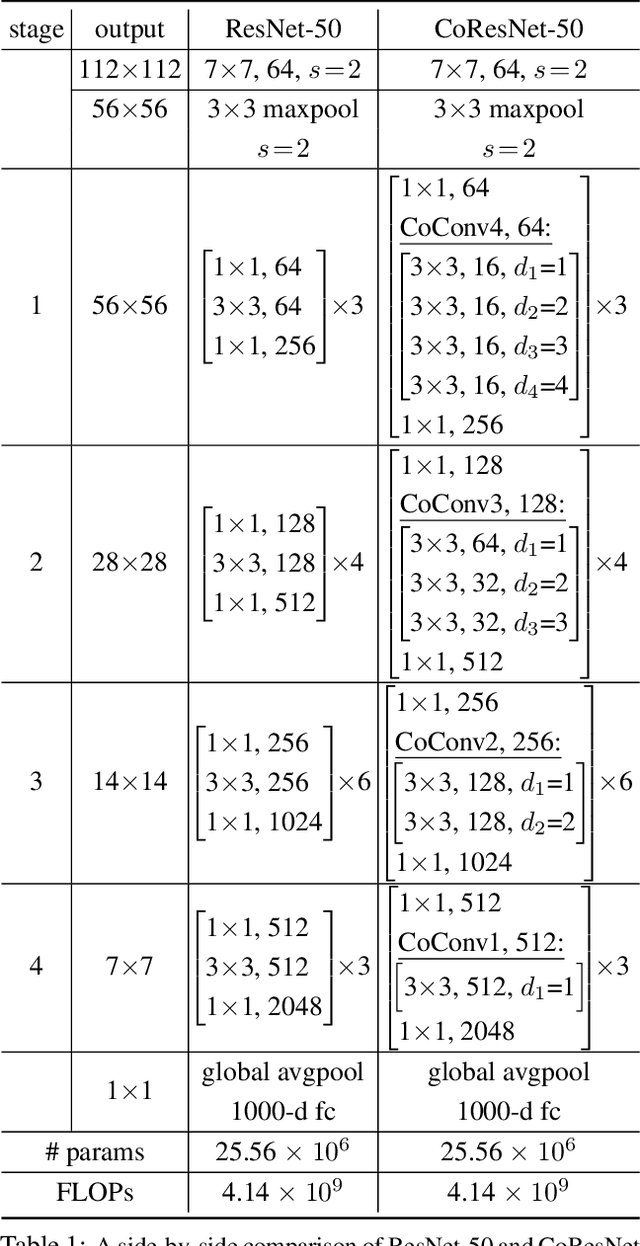
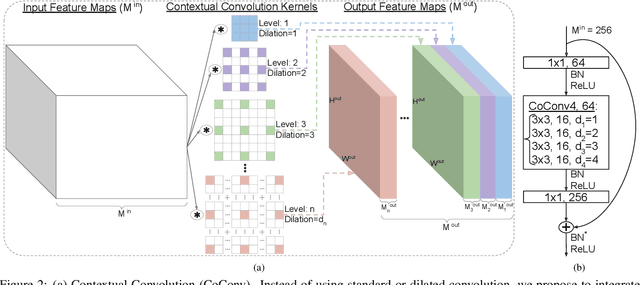

We propose contextual convolution (CoConv) for visual recognition. CoConv is a direct replacement of the standard convolution, which is the core component of convolutional neural networks. CoConv is implicitly equipped with the capability of incorporating contextual information while maintaining a similar number of parameters and computational cost compared to the standard convolution. CoConv is inspired by neuroscience studies indicating that (i) neurons, even from the primary visual cortex (V1 area), are involved in detection of contextual cues and that (ii) the activity of a visual neuron can be influenced by the stimuli placed entirely outside of its theoretical receptive field. On the one hand, we integrate CoConv in the widely-used residual networks and show improved recognition performance over baselines on the core tasks and benchmarks for visual recognition, namely image classification on the ImageNet data set and object detection on the MS COCO data set. On the other hand, we introduce CoConv in the generator of a state-of-the-art Generative Adversarial Network, showing improved generative results on CIFAR-10 and CelebA. Our code is available at https://github.com/iduta/coconv.
The Report on China-Spain Joint Clinical Testing for Rapid COVID-19 Risk Screening by Eye-region Manifestations
Sep 18, 2021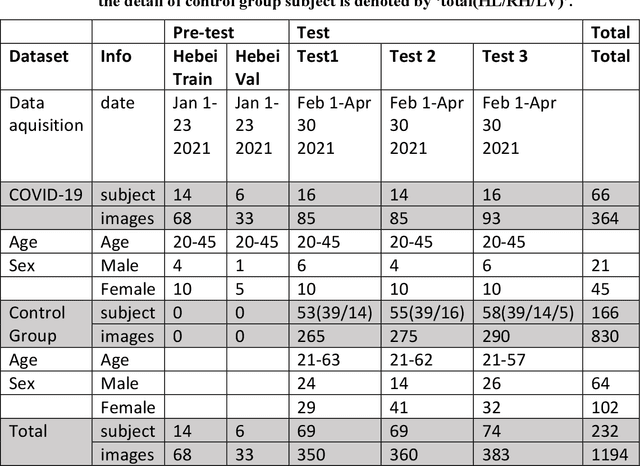

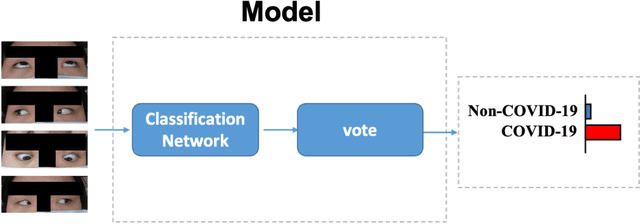
Background: The worldwide surge in coronavirus cases has led to the COVID-19 testing demand surge. Rapid, accurate, and cost-effective COVID-19 screening tests working at a population level are in imperative demand globally. Methods: Based on the eye symptoms of COVID-19, we developed and tested a COVID-19 rapid prescreening model using the eye-region images captured in China and Spain with cellphone cameras. The convolutional neural networks (CNNs)-based model was trained on these eye images to complete binary classification task of identifying the COVID-19 cases. The performance was measured using area under receiver-operating-characteristic curve (AUC), sensitivity, specificity, accuracy, and F1. The application programming interface was open access. Findings: The multicenter study included 2436 pictures corresponding to 657 subjects (155 COVID-19 infection, 23.6%) in development dataset (train and validation) and 2138 pictures corresponding to 478 subjects (64 COVID-19 infections, 13.4%) in test dataset. The image-level performance of COVID-19 prescreening model in the China-Spain multicenter study achieved an AUC of 0.913 (95% CI, 0.898-0.927), with a sensitivity of 0.695 (95% CI, 0.643-0.748), a specificity of 0.904 (95% CI, 0.891 -0.919), an accuracy of 0.875(0.861-0.889), and a F1 of 0.611(0.568-0.655). Interpretation: The CNN-based model for COVID-19 rapid prescreening has reliable specificity and sensitivity. This system provides a low-cost, fully self-performed, non-invasive, real-time feedback solution for continuous surveillance and large-scale rapid prescreening for COVID-19. Funding: This project is supported by Aimomics (Shanghai) Intelligent
Event-Based Feature Tracking in Continuous Time with Sliding Window Optimization
Jul 09, 2021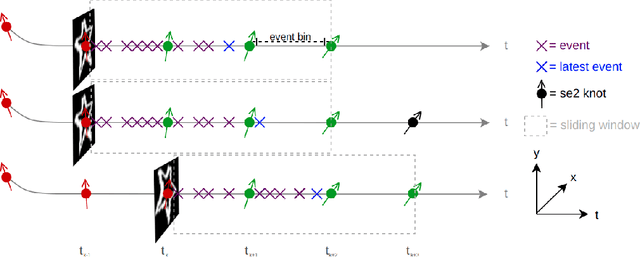
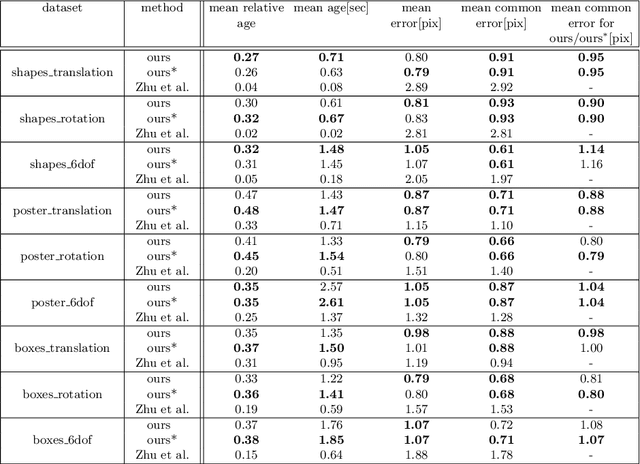
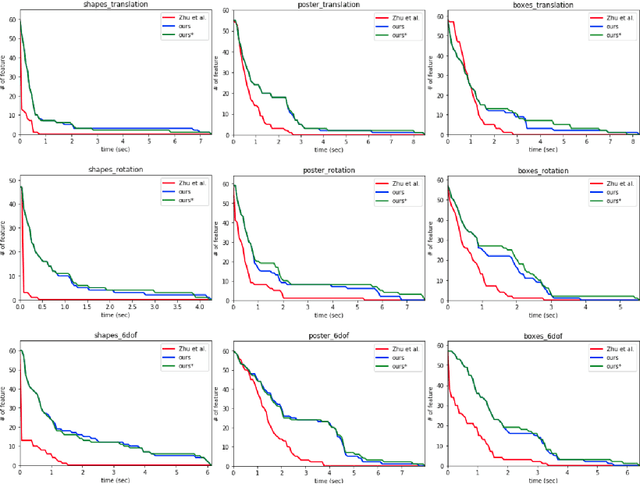

We propose a novel method for continuous-time feature tracking in event cameras. To this end, we track features by aligning events along an estimated trajectory in space-time such that the projection on the image plane results in maximally sharp event patch images. The trajectory is parameterized by $n^{th}$ order B-splines, which are continuous up to $(n-2)^{th}$ derivative. In contrast to previous work, we optimize the curve parameters in a sliding window fashion. On a public dataset we experimentally confirm that the proposed sliding-window B-spline optimization leads to longer and more accurate feature tracks than in previous work.