 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning for Image Denoising: A Survey
Oct 11, 2018
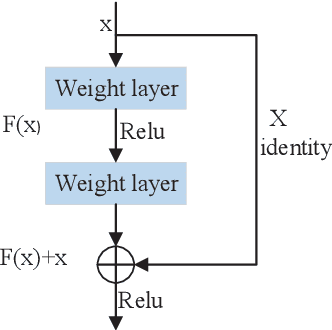
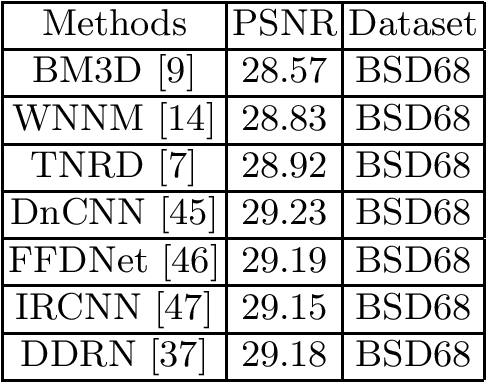
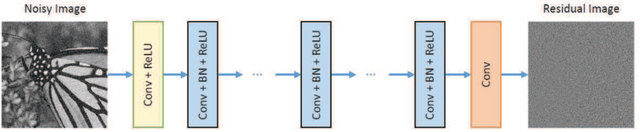

Since the proposal of big data analysis and Graphic Processing Unit (GPU), the deep learning technology has received a great deal of attention and has been widely applied in the field of imaging processing. In this paper, we have an aim to completely review and summarize the deep learning technologies for image denoising proposed in recent years. Morever, we systematically analyze the conventional machine learning methods for image denoising. Finally, we point out some research directions for the deep learning technologies in image denoising.
Chittron: An Automatic Bangla Image Captioning System
Sep 02, 2018

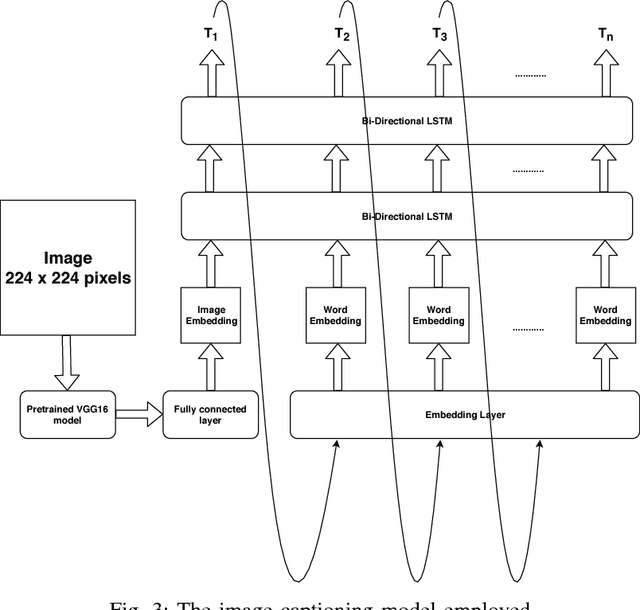

Automatic image caption generation aims to produce an accurate description of an image in natural language automatically. However, Bangla, the fifth most widely spoken language in the world, is lagging considerably in the research and development of such domain. Besides, while there are many established data sets to related to image annotation in English, no such resource exists for Bangla yet. Hence, this paper outlines the development of "Chittron", an automatic image captioning system in Bangla. Moreover, to address the data set availability issue, a collection of 16,000 Bangladeshi contextual images has been accumulated and manually annotated in Bangla. This data set is then used to train a model which integrates a pre-trained VGG16 image embedding model with stacked LSTM layers. The model is trained to predict the caption when the input is an image, one word at a time. The results show that the model has successfully been able to learn a working language model and to generate captions of images quite accurately in many cases. The results are evaluated mainly qualitatively. However, BLEU scores are also reported. It is expected that a better result can be obtained with a bigger and more varied data set.
Efficient Algorithms for Learning from Coarse Labels
Aug 22, 2021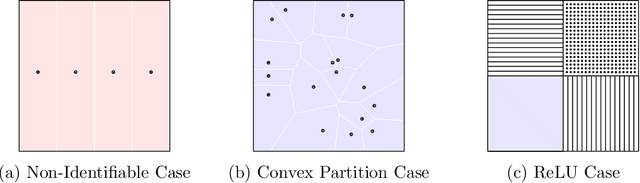
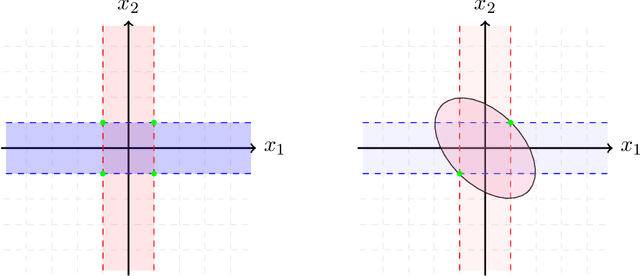
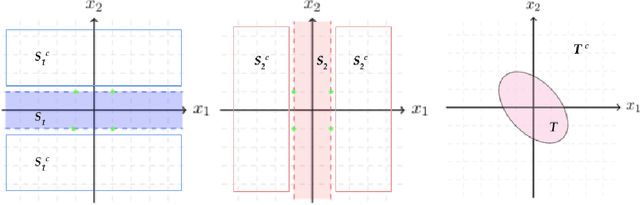
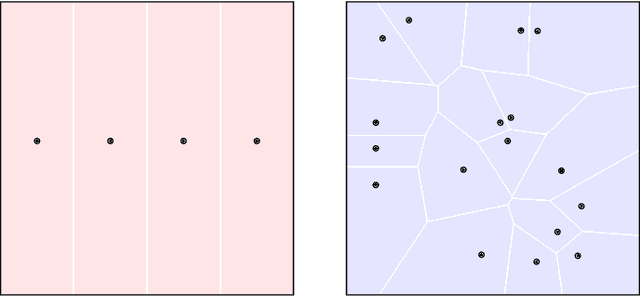
For many learning problems one may not have access to fine grained label information; e.g., an image can be labeled as husky, dog, or even animal depending on the expertise of the annotator. In this work, we formalize these settings and study the problem of learning from such coarse data. Instead of observing the actual labels from a set $\mathcal{Z}$, we observe coarse labels corresponding to a partition of $\mathcal{Z}$ (or a mixture of partitions). Our main algorithmic result is that essentially any problem learnable from fine grained labels can also be learned efficiently when the coarse data are sufficiently informative. We obtain our result through a generic reduction for answering Statistical Queries (SQ) over fine grained labels given only coarse labels. The number of coarse labels required depends polynomially on the information distortion due to coarsening and the number of fine labels $|\mathcal{Z}|$. We also investigate the case of (infinitely many) real valued labels focusing on a central problem in censored and truncated statistics: Gaussian mean estimation from coarse data. We provide an efficient algorithm when the sets in the partition are convex and establish that the problem is NP-hard even for very simple non-convex sets.
Generalization Error Analysis of Neural networks with Gradient Based Regularization
Jul 06, 2021
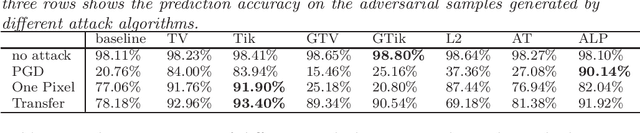

We study gradient-based regularization methods for neural networks. We mainly focus on two regularization methods: the total variation and the Tikhonov regularization. Applying these methods is equivalent to using neural networks to solve some partial differential equations, mostly in high dimensions in practical applications. In this work, we introduce a general framework to analyze the generalization error of regularized networks. The error estimate relies on two assumptions on the approximation error and the quadrature error. Moreover, we conduct some experiments on the image classification tasks to show that gradient-based methods can significantly improve the generalization ability and adversarial robustness of neural networks. A graphical extension of the gradient-based methods are also considered in the experiments.
Unsupervised Part Mining for Fine-grained Image Classification
Feb 26, 2019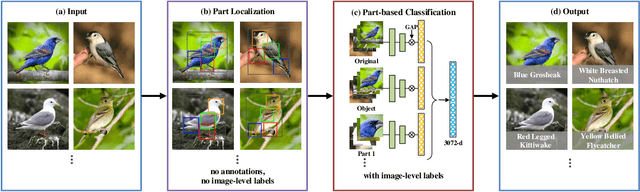
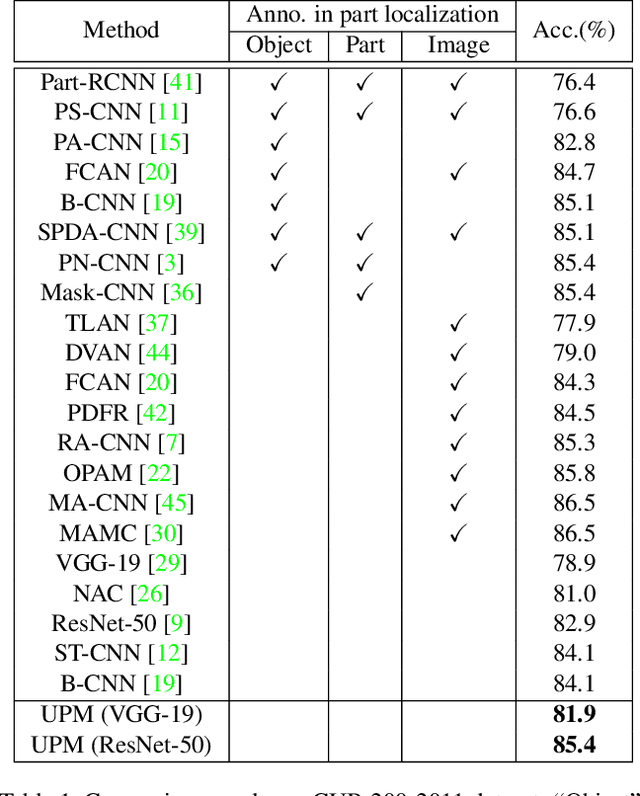
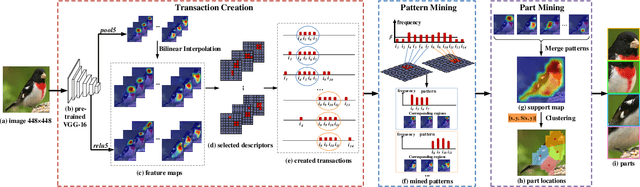
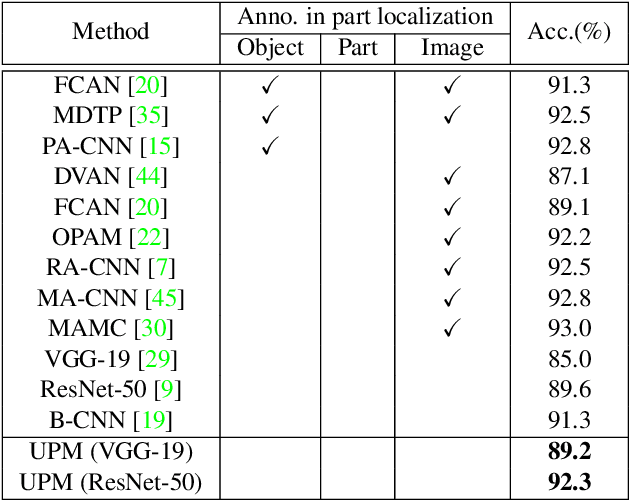
Fine-grained image classification remains challenging due to the large intra-class variance and small inter-class variance. Since the subtle visual differences are only in local regions of discriminative parts among subcategories, part localization is a key issue for fine-grained image classification. Most existing approaches localize object or parts in an image with object or part annotations, which are expensive and labor-consuming. To tackle this issue, we propose a fully unsupervised part mining (UPM) approach to localize the discriminative parts without even image-level annotations, which largely improves the fine-grained classification performance. We first utilize pattern mining techniques to discover frequent patterns, i.e., co-occurrence highlighted regions, in the feature maps extracted from a pre-trained convolutional neural network (CNN) model. Inspired by the fact that these relevant meaningful patterns typically hold appearance and spatial consistency, we then cluster the mined regions to obtain the cluster centers and the discriminative parts surrounding the cluster centers are generated. Importantly, any annotations and sophisticated training procedures are not used in our proposed part localization approach. Finally, a multi-stream classification network is built for aggregating the original, object-level and part-level features simultaneously. Compared with other state-of-the-art approaches, our UPM approach achieves the competitive performance.
Image Generation from Sketch Constraint Using Contextual GAN
Jul 26, 2018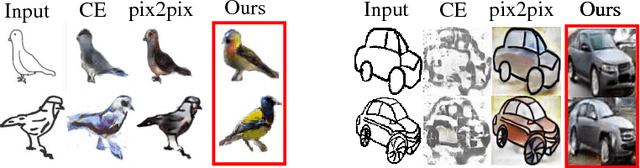



In this paper we investigate image generation guided by hand sketch. When the input sketch is badly drawn, the output of common image-to-image translation follows the input edges due to the hard condition imposed by the translation process. Instead, we propose to use sketch as weak constraint, where the output edges do not necessarily follow the input edges. We address this problem using a novel joint image completion approach, where the sketch provides the image context for completing, or generating the output image. We train a generated adversarial network, i.e, contextual GAN to learn the joint distribution of sketch and the corresponding image by using joint images. Our contextual GAN has several advantages. First, the simple joint image representation allows for simple and effective learning of joint distribution in the same image-sketch space, which avoids complicated issues in cross-domain learning. Second, while the output is related to its input overall, the generated features exhibit more freedom in appearance and do not strictly align with the input features as previous conditional GANs do. Third, from the joint image's point of view, image and sketch are of no difference, thus exactly the same deep joint image completion network can be used for image-to-sketch generation. Experiments evaluated on three different datasets show that our contextual GAN can generate more realistic images than state-of-the-art conditional GANs on challenging inputs and generalize well on common categories.
Improved Autoregressive Modeling with Distribution Smoothing
Mar 28, 2021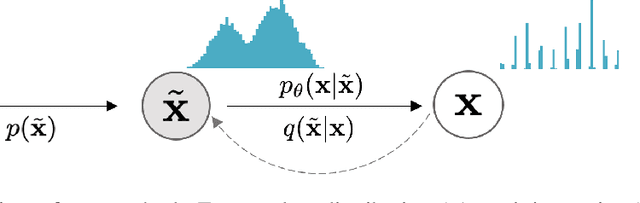


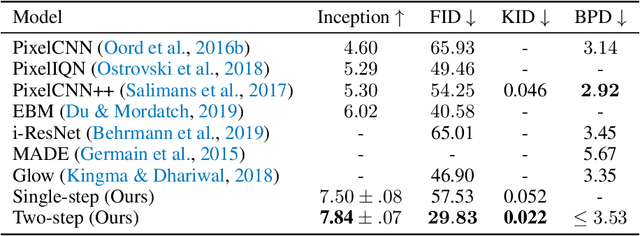
While autoregressive models excel at image compression, their sample quality is often lacking. Although not realistic, generated images often have high likelihood according to the model, resembling the case of adversarial examples. Inspired by a successful adversarial defense method, we incorporate randomized smoothing into autoregressive generative modeling. We first model a smoothed version of the data distribution, and then reverse the smoothing process to recover the original data distribution. This procedure drastically improves the sample quality of existing autoregressive models on several synthetic and real-world image datasets while obtaining competitive likelihoods on synthetic datasets.
Generating Patient-like Phantoms Using Fully Unsupervised Deformable Image Registration with Convolutional Neural Networks
Dec 06, 2019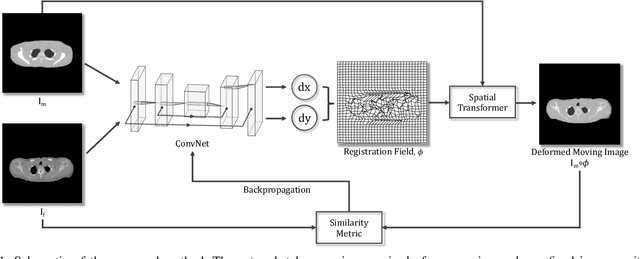
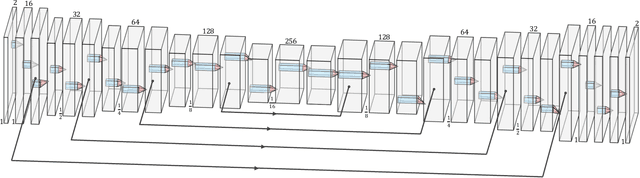

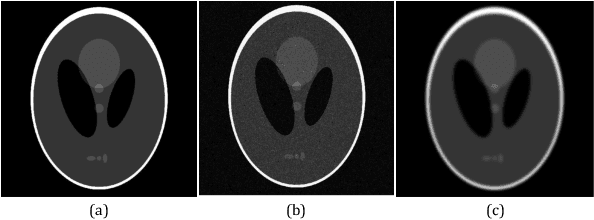
The use of Convolutional neural networks (ConvNets) in medical imaging research has become widespread in recent years. However, a major drawback of these methods is that they require a large number of annotated training images. Data augmentation has been proposed to alleviate this. One data augmentation strategy is to apply random deformation to existing image data, but the deformed images often will not follow exhibit realistic shape or intensity patterns. In this paper, we present a novel, ConvNet based image registration method for creating patient-like digital phantoms from the existing computerized phantoms. Unlike existing learning-based registration techniques, for which the performance predominantly depends on the domain-specific training images, the proposed method is fully unsupervised, meaning that it optimizes an objective function independently of training data for a given image pair. While classical methods registration also do not require training data, they work in lower-dimensional parameter space; the proposed approach operates directly in the high-dimensional parameter space without any training beforehand. In this paper, we show that the resulting deformed phantom competently matches the anatomy model of a real human while providing the "gold-standard" for the anatomies. Combined with simulation programs, the generated phantoms could potentially serve as a data augmentation tool in today's deep learning studies.
Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification
May 15, 2018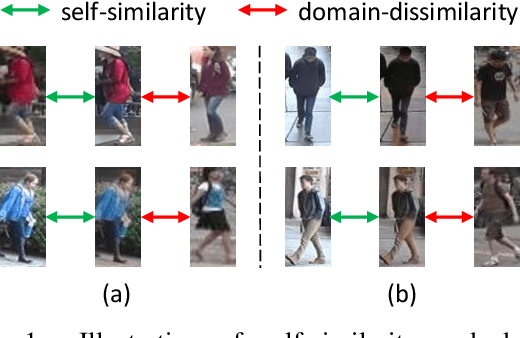
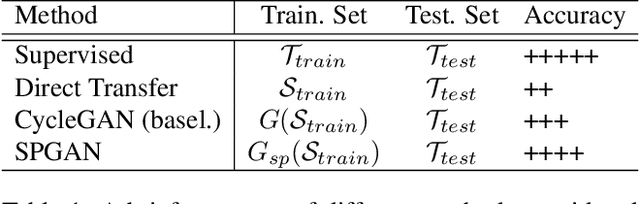

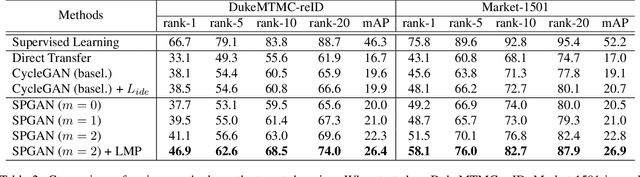
Person re-identification (re-ID) models trained on one domain often fail to generalize well to another. In our attempt, we present a "learning via translation" framework. In the baseline, we translate the labeled images from source to target domain in an unsupervised manner. We then train re-ID models with the translated images by supervised methods. Yet, being an essential part of this framework, unsupervised image-image translation suffers from the information loss of source-domain labels during translation. Our motivation is two-fold. First, for each image, the discriminative cues contained in its ID label should be maintained after translation. Second, given the fact that two domains have entirely different persons, a translated image should be dissimilar to any of the target IDs. To this end, we propose to preserve two types of unsupervised similarities, 1) self-similarity of an image before and after translation, and 2) domain-dissimilarity of a translated source image and a target image. Both constraints are implemented in the similarity preserving generative adversarial network (SPGAN) which consists of an Siamese network and a CycleGAN. Through domain adaptation experiment, we show that images generated by SPGAN are more suitable for domain adaptation and yield consistent and competitive re-ID accuracy on two large-scale datasets.
Semisupervised Manifold Alignment of Multimodal Remote Sensing Images
Apr 15, 2021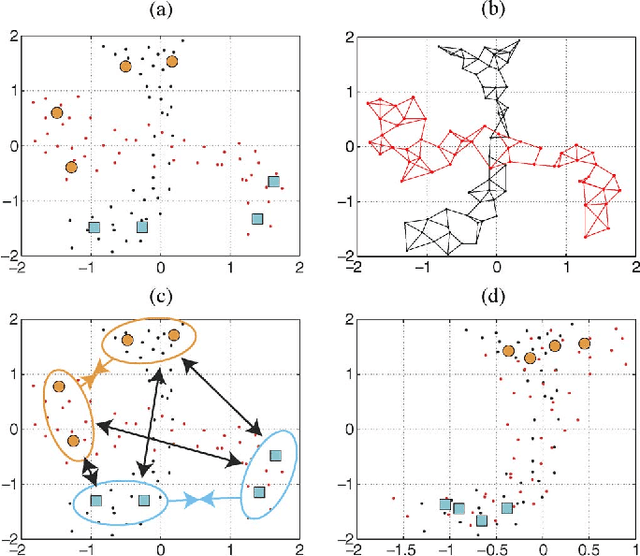
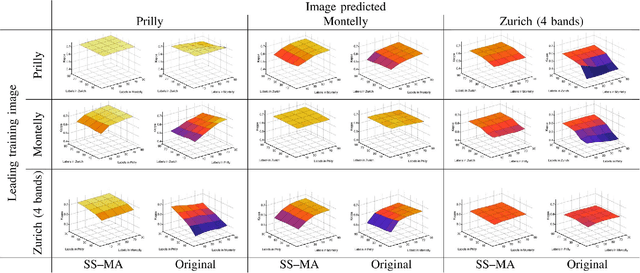
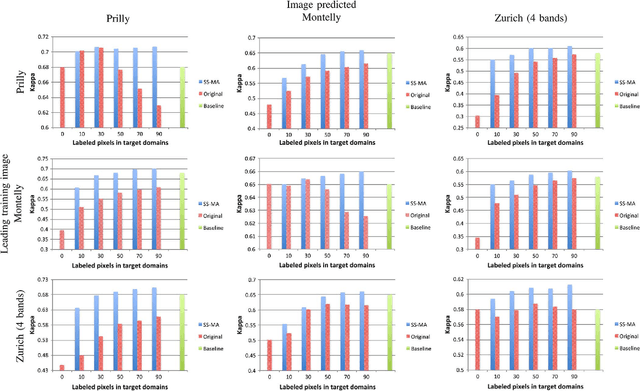

We introduce a method for manifold alignment of different modalities (or domains) of remote sensing images. The problem is recurrent when a set of multitemporal, multisource, multisensor and multiangular images is available. In these situations, images should ideally be spatially coregistred, corrected and compensated for differences in the image domains. Such procedures require the interaction of the user, involve tuning of many parameters and heuristics, and are usually applied separately. Changes of sensors and acquisition conditions translate into shifts, twists, warps and foldings of the image distributions (or manifolds). The proposed semisupervised manifold alignment (SS-MA) method aligns the images working directly on their manifolds, and is thus not restricted to images of the same resolutions, either spectral or spatial. SS-MA pulls close together samples of the same class while pushing those of different classes apart. At the same time, it preserves the geometry of each manifold along the transformation. The method builds a linear invertible transformation to a latent space where all images are alike, and reduces to solving a generalized eigenproblem of moderate size. We study the performance of SS-MA in toy examples and in real multiangular, multitemporal, and multisource image classification problems. The method performs well for strong deformations and leads to accurate classification for all domains.