 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning To Count Everything
Apr 16, 2021

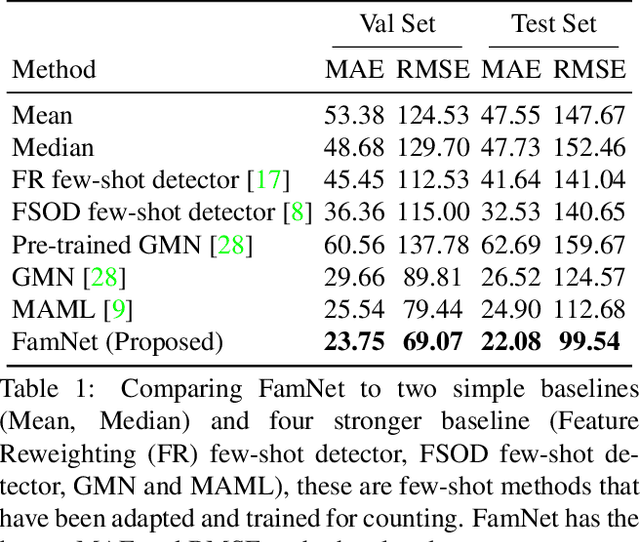
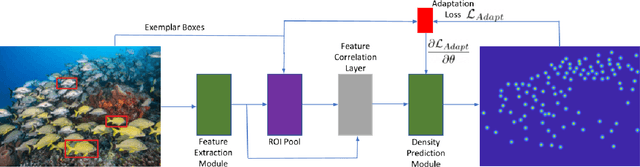
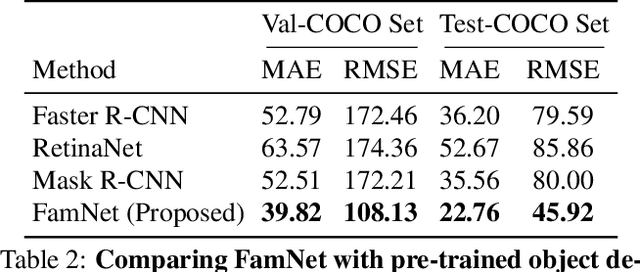
Existing works on visual counting primarily focus on one specific category at a time, such as people, animals, and cells. In this paper, we are interested in counting everything, that is to count objects from any category given only a few annotated instances from that category. To this end, we pose counting as a few-shot regression task. To tackle this task, we present a novel method that takes a query image together with a few exemplar objects from the query image and predicts a density map for the presence of all objects of interest in the query image. We also present a novel adaptation strategy to adapt our network to any novel visual category at test time, using only a few exemplar objects from the novel category. We also introduce a dataset of 147 object categories containing over 6000 images that are suitable for the few-shot counting task. The images are annotated with two types of annotation, dots and bounding boxes, and they can be used for developing few-shot counting models. Experiments on this dataset shows that our method outperforms several state-of-the-art object detectors and few-shot counting approaches. Our code and dataset can be found at https://github.com/cvlab-stonybrook/LearningToCountEverything.
Model reduction in acoustic inversion by artificial neural network
May 05, 2021
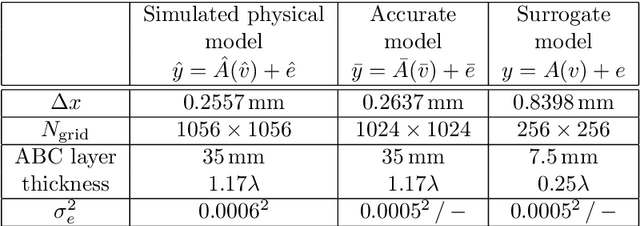
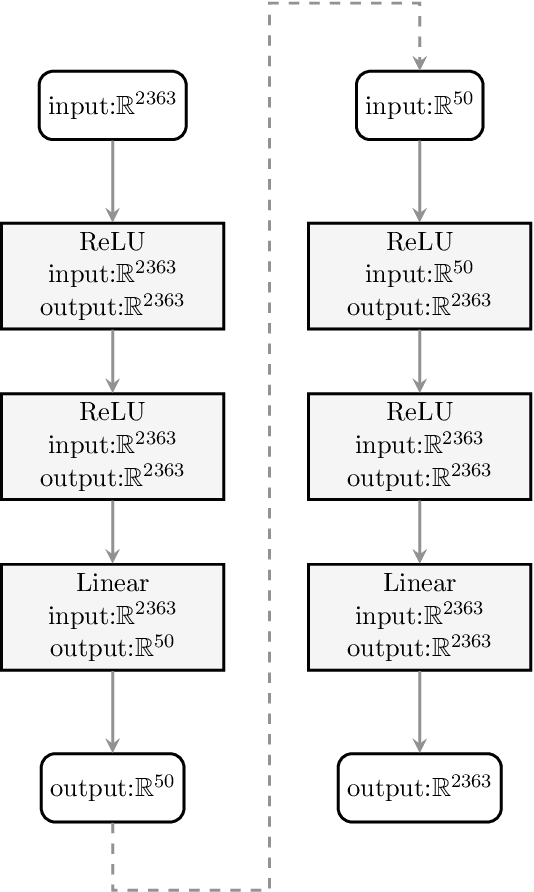
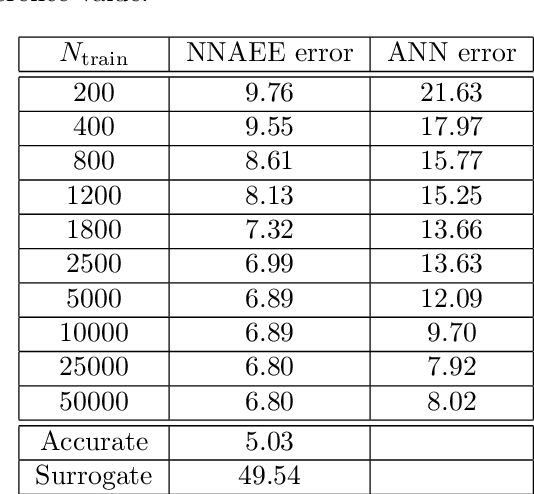
In ultrasound tomography, the speed of sound inside an object is estimated based on acoustic measurements carried out by sensors surrounding the object. An accurate forward model is a prominent factor for high-quality image reconstruction, but it can make computations far too time-consuming in many applications. Using approximate forward models, it is possible to speed up the computations, but the quality of the reconstruction may have to be compromised. In this paper, a neural network -based approach is proposed, that can compensate for modeling errors caused by the approximate forward models. The approach is tested with various different imaging scenarios in a simulated two-dimensional domain. The results show that with fairly small training data sets, the proposed approach can be utilized to approximate the modelling errors, and to significantly improve the image reconstruction quality in ultrasound tomography, compared to commonly used inversion algorithms.
Vulnerability of Appearance-based Gaze Estimation
Mar 24, 2021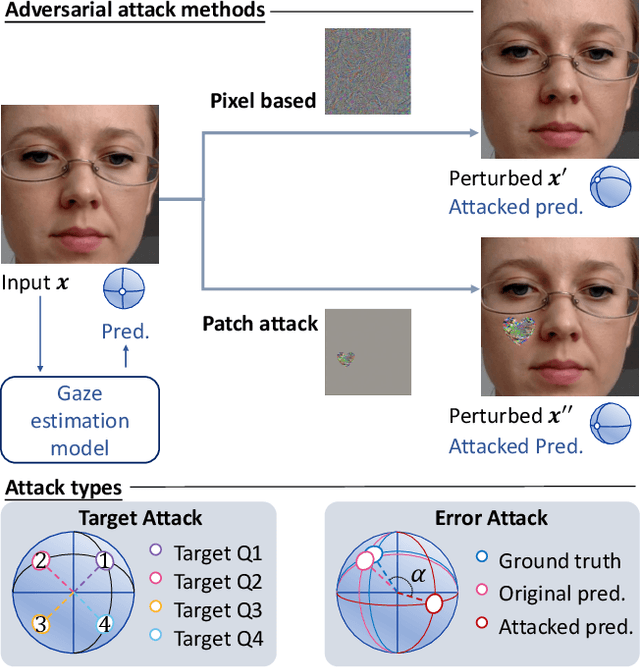
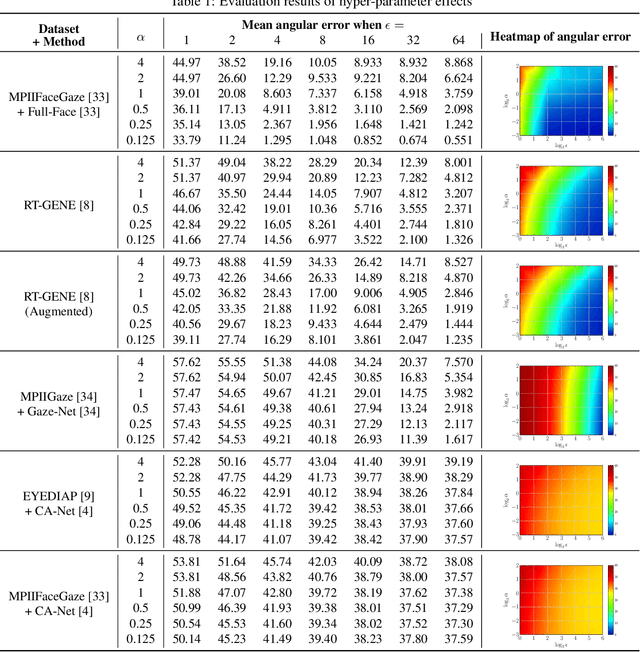
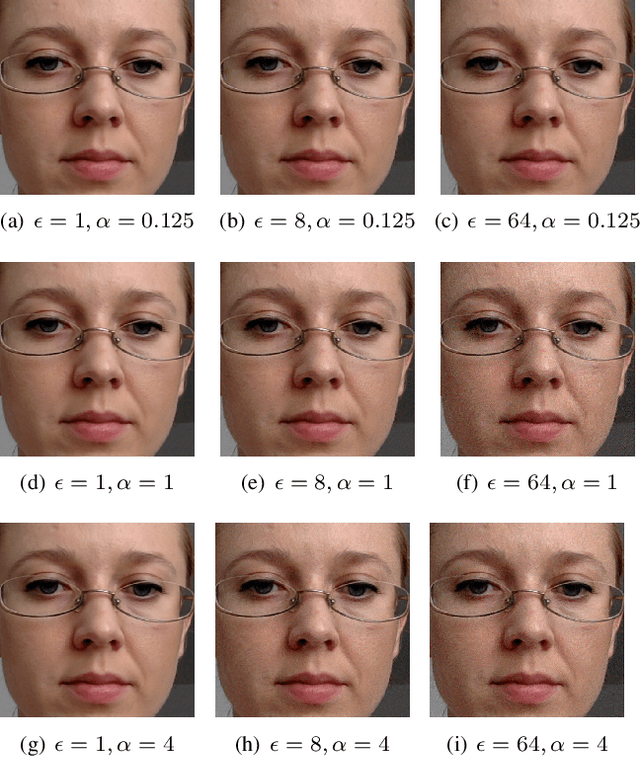
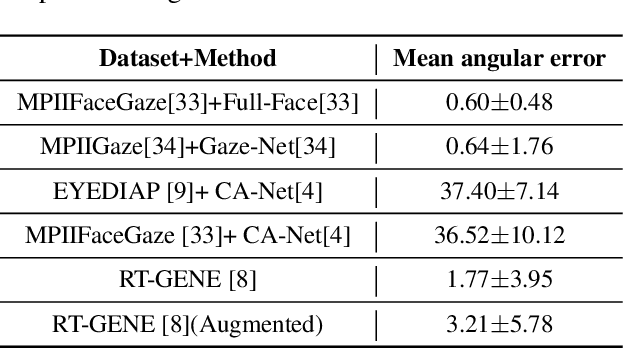
Appearance-based gaze estimation has achieved significant improvement by using deep learning. However, many deep learning-based methods suffer from the vulnerability property, i.e., perturbing the raw image using noise confuses the gaze estimation models. Although the perturbed image visually looks similar to the original image, the gaze estimation models output the wrong gaze direction. In this paper, we investigate the vulnerability of appearance-based gaze estimation. To our knowledge, this is the first time that the vulnerability of gaze estimation to be found. We systematically characterized the vulnerability property from multiple aspects, the pixel-based adversarial attack, the patch-based adversarial attack and the defense strategy. Our experimental results demonstrate that the CA-Net shows superior performance against attack among the four popular appearance-based gaze estimation networks, Full-Face, Gaze-Net, CA-Net and RT-GENE. This study draws the attention of researchers in the appearance-based gaze estimation community to defense from adversarial attacks.
Learning to Enhance Visual Quality via Hyperspectral Domain Mapping
Feb 10, 2021
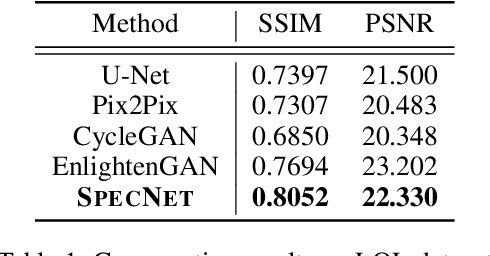
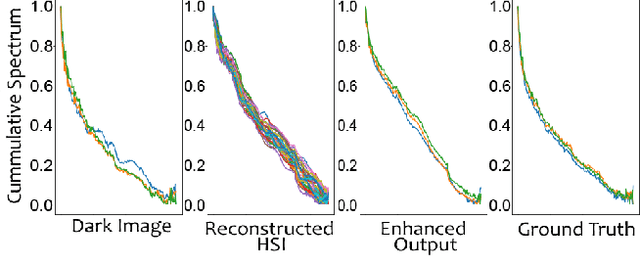

Deep learning based methods have achieved remarkable success in image restoration and enhancement, but most such methods rely on RGB input images. These methods fail to take into account the rich spectral distribution of natural images. We propose a deep architecture, SpecNet, which computes spectral profile to estimate pixel-wise dynamic range adjustment of a given image. First, we employ an unpaired cycle-consistent framework to generate hyperspectral images (HSI) from low-light input images. HSI is further used to generate a normal light image of the same scene. We incorporate a self-supervision and a spectral profile regularization network to infer a plausible HSI from an RGB image. We evaluate the benefits of optimizing the spectral profile for real and fake images in low-light conditions on the LOL Dataset.
Investigating Vulnerabilities of Deep Neural Policies
Aug 30, 2021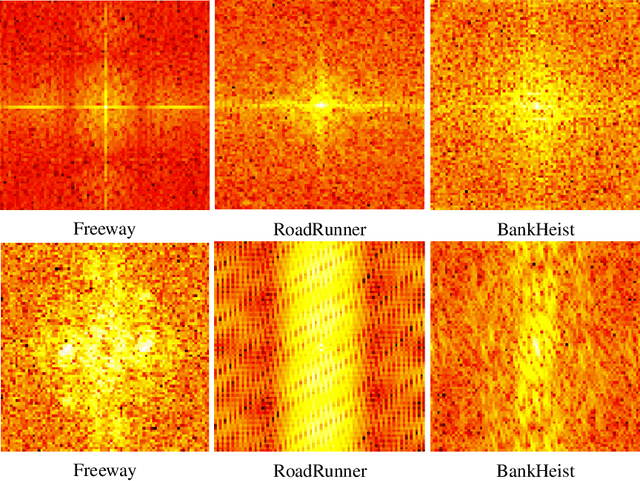

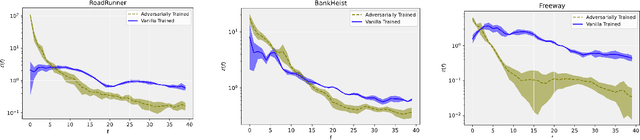
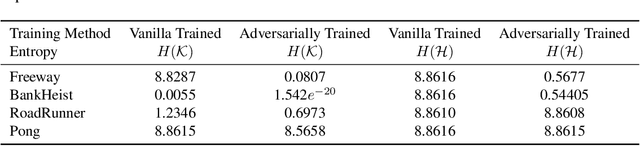
Reinforcement learning policies based on deep neural networks are vulnerable to imperceptible adversarial perturbations to their inputs, in much the same way as neural network image classifiers. Recent work has proposed several methods to improve the robustness of deep reinforcement learning agents to adversarial perturbations based on training in the presence of these imperceptible perturbations (i.e. adversarial training). In this paper, we study the effects of adversarial training on the neural policy learned by the agent. In particular, we follow two distinct parallel approaches to investigate the outcomes of adversarial training on deep neural policies based on worst-case distributional shift and feature sensitivity. For the first approach, we compare the Fourier spectrum of minimal perturbations computed for both adversarially trained and vanilla trained neural policies. Via experiments in the OpenAI Atari environments we show that minimal perturbations computed for adversarially trained policies are more focused on lower frequencies in the Fourier domain, indicating a higher sensitivity of these policies to low frequency perturbations. For the second approach, we propose a novel method to measure the feature sensitivities of deep neural policies and we compare these feature sensitivity differences in state-of-the-art adversarially trained deep neural policies and vanilla trained deep neural policies. We believe our results can be an initial step towards understanding the relationship between adversarial training and different notions of robustness for neural policies.
Video-Based Camera Localization Using Anchor View Detection and Recursive 3D Reconstruction
Jul 07, 2021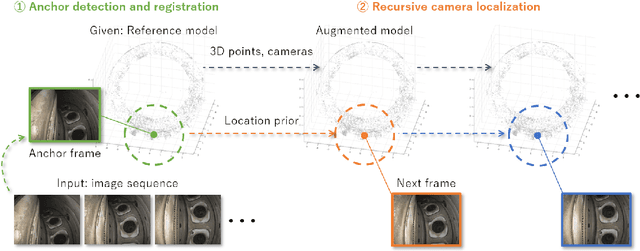
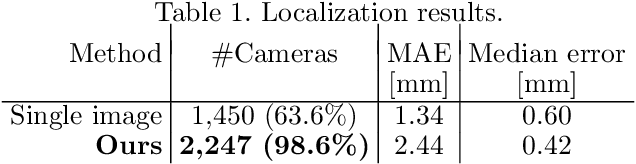
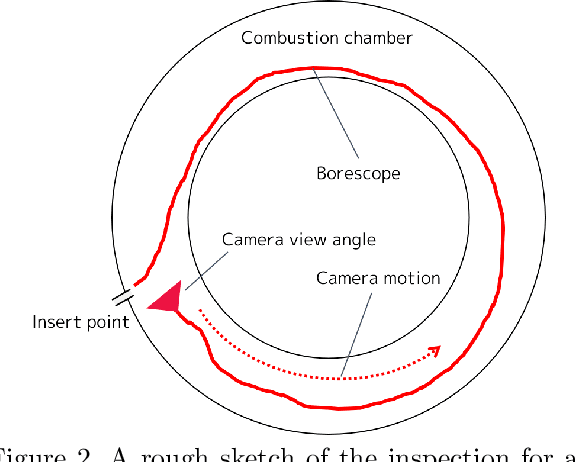
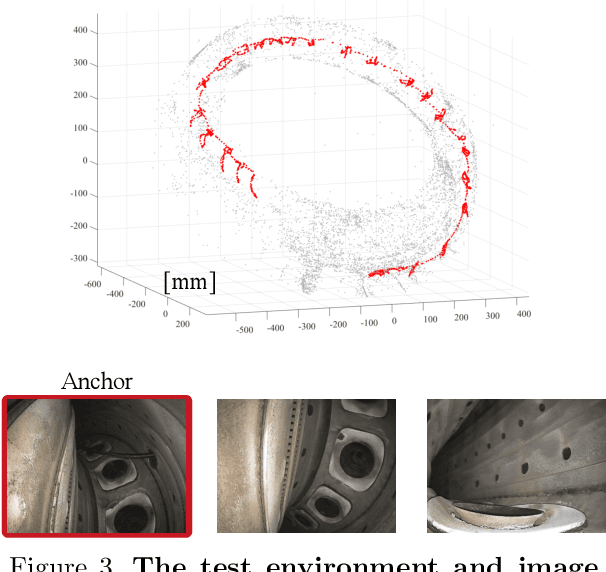
In this paper we introduce a new camera localization strategy designed for image sequences captured in challenging industrial situations such as industrial parts inspection. To deal with peculiar appearances that hurt standard 3D reconstruction pipeline, we exploit pre-knowledge of the scene by selecting key frames in the sequence (called as anchors) which are roughly connected to a certain location. Our method then seek the location of each frame in time-order, while recursively updating an augmented 3D model which can provide current camera location and surrounding 3D structure. In an experiment on a practical industrial situation, our method can localize over 99% frames in the input sequence, whereas standard localization methods fail to reconstruct a complete camera trajectory.
Photon-Starved Scene Inference using Single Photon Cameras
Aug 16, 2021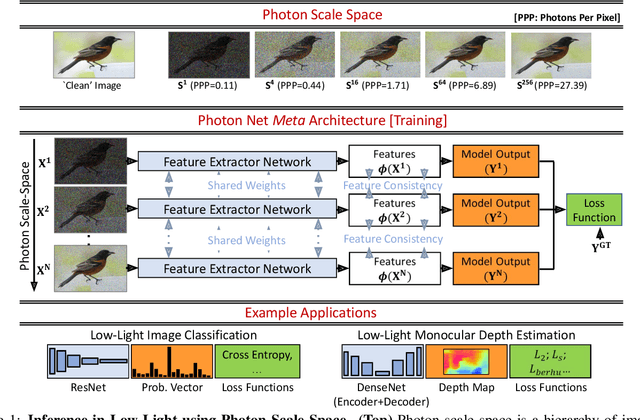



Scene understanding under low-light conditions is a challenging problem. This is due to the small number of photons captured by the camera and the resulting low signal-to-noise ratio (SNR). Single-photon cameras (SPCs) are an emerging sensing modality that are capable of capturing images with high sensitivity. Despite having minimal read-noise, images captured by SPCs in photon-starved conditions still suffer from strong shot noise, preventing reliable scene inference. We propose photon scale-space a collection of high-SNR images spanning a wide range of photons-per-pixel (PPP) levels (but same scene content) as guides to train inference model on low photon flux images. We develop training techniques that push images with different illumination levels closer to each other in feature representation space. The key idea is that having a spectrum of different brightness levels during training enables effective guidance, and increases robustness to shot noise even in extreme noise cases. Based on the proposed approach, we demonstrate, via simulations and real experiments with a SPAD camera, high-performance on various inference tasks such as image classification and monocular depth estimation under ultra low-light, down to < 1 PPP.
Safe Vessel Navigation Visually Aided by Autonomous Unmanned Aerial Vehicles in Congested Harbors and Waterways
Aug 09, 2021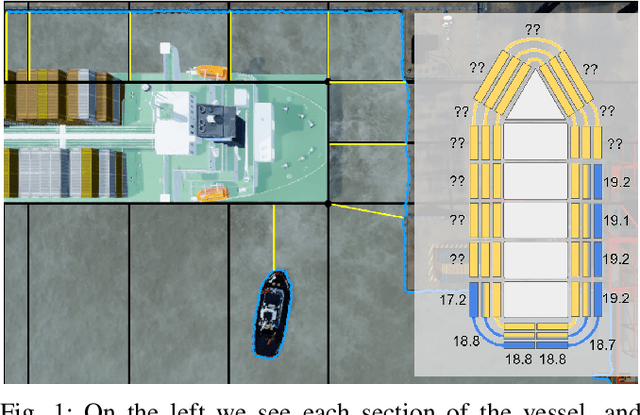
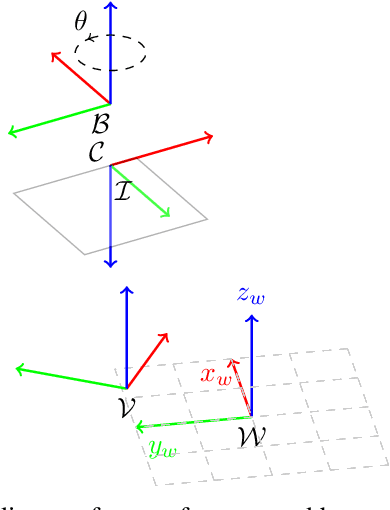
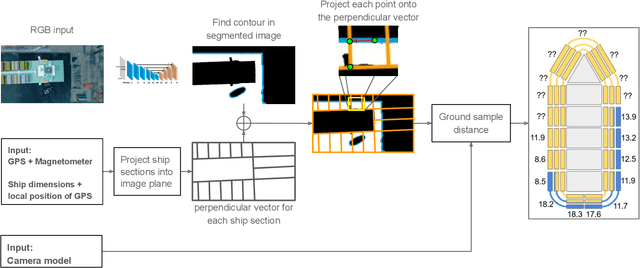

In the maritime sector, safe vessel navigation is of great importance, particularly in congested harbors and waterways. The focus of this work is to estimate the distance between an object of interest and potential obstacles using a companion UAV. The proposed approach fuses GPS data with long-range aerial images. First, we employ semantic segmentation DNN for discriminating the vessel of interest, water, and potential solid objects using raw image data. The network is trained with both real and images generated and automatically labeled from a realistic AirSim simulation environment. Then, the distances between the extracted vessel and non-water obstacle blobs are computed using a novel GSD estimation algorithm. To the best of our knowledge, this work is the first attempt to detect and estimate distances to unknown objects from long-range visual data captured with conventional RGB cameras and auxiliary absolute positioning systems (e.g. GPS). The simulation results illustrate the accuracy and efficacy of the proposed method for visually aided navigation of vessels assisted by UAV.
Hierarchical Attention Fusion for Geo-Localization
Feb 18, 2021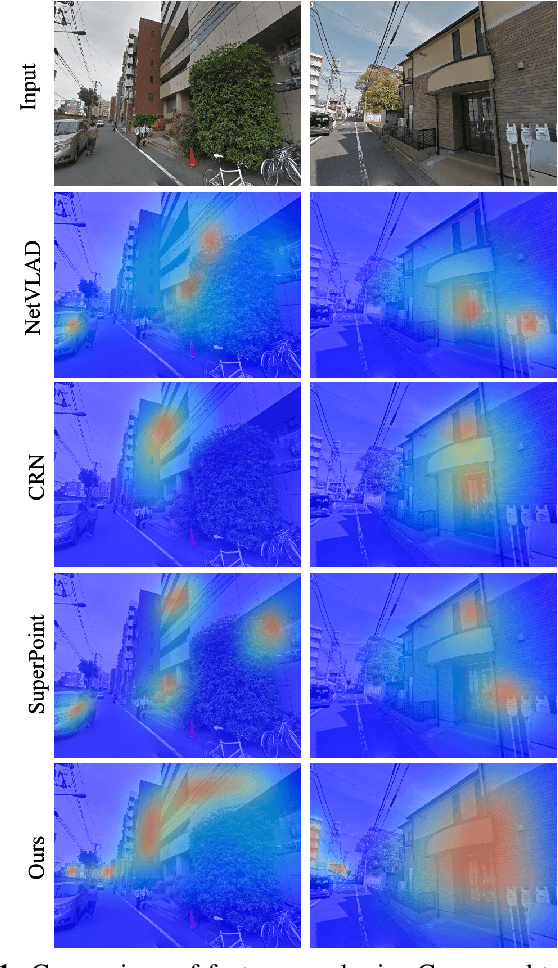
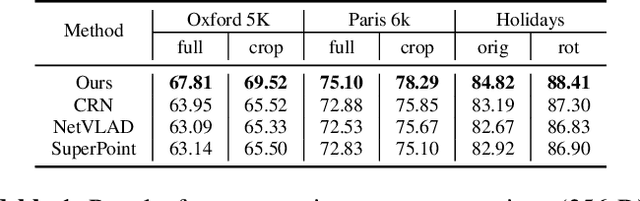
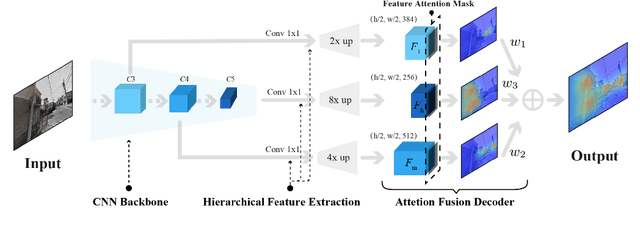

Geo-localization is a critical task in computer vision. In this work, we cast the geo-localization as a 2D image retrieval task. Current state-of-the-art methods for 2D geo-localization are not robust to locate a scene with drastic scale variations because they only exploit features from one semantic level for image representations. To address this limitation, we introduce a hierarchical attention fusion network using multi-scale features for geo-localization. We extract the hierarchical feature maps from a convolutional neural network (CNN) and organically fuse the extracted features for image representations. Our training is self-supervised using adaptive weights to control the attention of feature emphasis from each hierarchical level. Evaluation results on the image retrieval and the large-scale geo-localization benchmarks indicate that our method outperforms the existing state-of-the-art methods. Code is available here: \url{https://github.com/YanLiqi/HAF}.
KRADA: Known-region-aware Domain Alignment for Open World Semantic Segmentation
Jun 11, 2021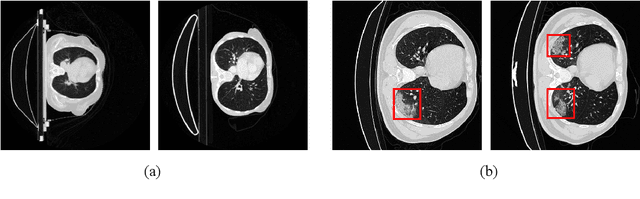
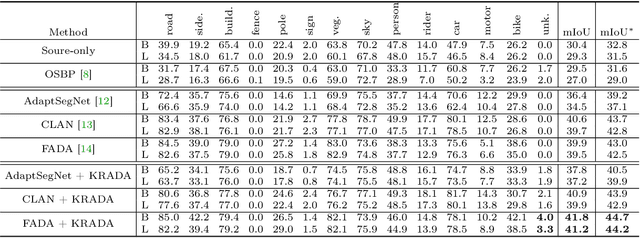
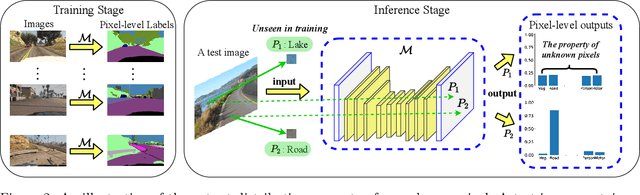
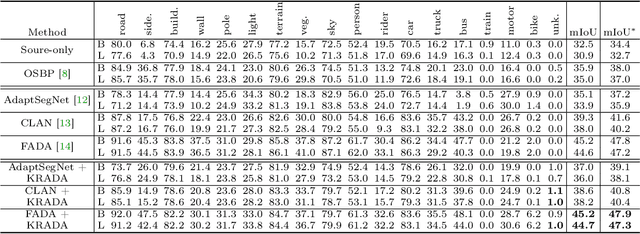
In semantic segmentation, we aim to train a pixel-level classifier to assign category labels to all pixels in an image, where labeled training images and unlabeled test images are from the same distribution and share the same label set. However, in an open world, the unlabeled test images probably contain unknown categories and have different distributions from the labeled images. Hence, in this paper, we consider a new, more realistic, and more challenging problem setting where the pixel-level classifier has to be trained with labeled images and unlabeled open-world images -- we name it open world semantic segmentation (OSS). In OSS, the trained classifier is expected to identify unknown-class pixels and classify known-class pixels well. To solve OSS, we first investigate which distribution that unknown-class pixels obey. Then, motivated by the goodness-of-fit test, we use statistical measurements to show how a pixel fits the distribution of an unknown class and select highly-fitted pixels to form the unknown region in each image. Eventually, we propose an end-to-end learning framework, known-region-aware domain alignment (KRADA), to distinguish unknown classes while aligning distributions of known classes in labeled and unlabeled open-world images. The effectiveness of KRADA has been verified on two synthetic tasks and one COVID-19 segmentation task.