 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Algorithms for Learning from Coarse Labels
Aug 22, 2021
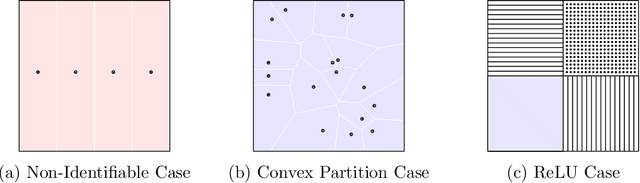
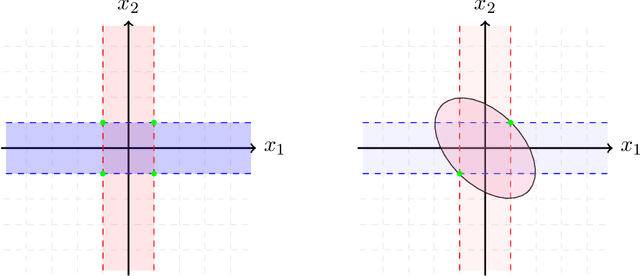
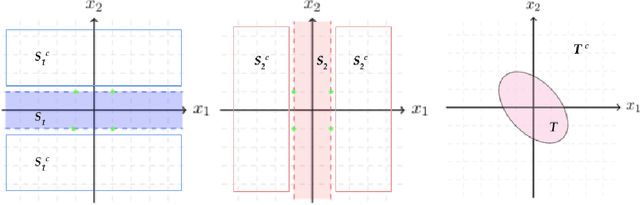
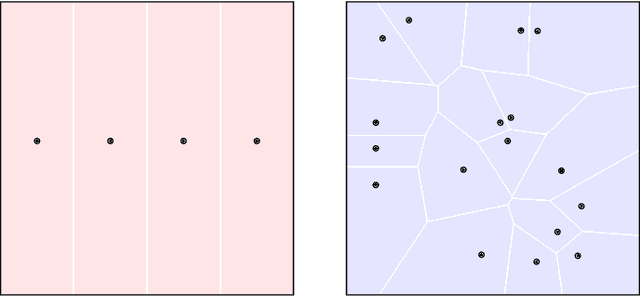
For many learning problems one may not have access to fine grained label information; e.g., an image can be labeled as husky, dog, or even animal depending on the expertise of the annotator. In this work, we formalize these settings and study the problem of learning from such coarse data. Instead of observing the actual labels from a set $\mathcal{Z}$, we observe coarse labels corresponding to a partition of $\mathcal{Z}$ (or a mixture of partitions). Our main algorithmic result is that essentially any problem learnable from fine grained labels can also be learned efficiently when the coarse data are sufficiently informative. We obtain our result through a generic reduction for answering Statistical Queries (SQ) over fine grained labels given only coarse labels. The number of coarse labels required depends polynomially on the information distortion due to coarsening and the number of fine labels $|\mathcal{Z}|$. We also investigate the case of (infinitely many) real valued labels focusing on a central problem in censored and truncated statistics: Gaussian mean estimation from coarse data. We provide an efficient algorithm when the sets in the partition are convex and establish that the problem is NP-hard even for very simple non-convex sets.
Simple, Fast, and Flexible Framework for Matrix Completion with Infinite Width Neural Networks
Jul 31, 2021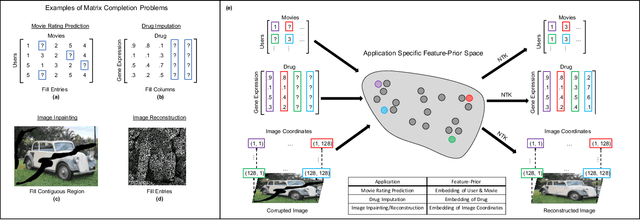
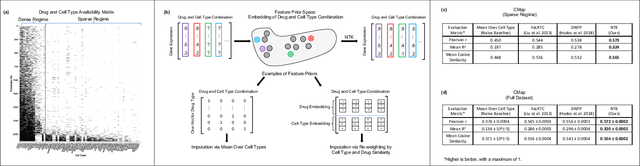

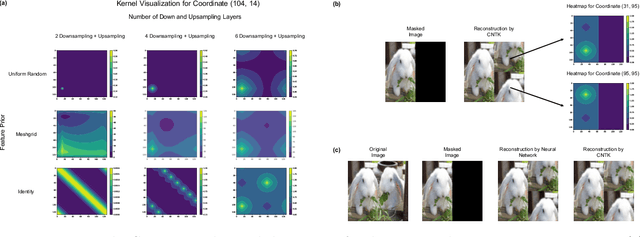
Matrix completion problems arise in many applications including recommendation systems, computer vision, and genomics. Increasingly larger neural networks have been successful in many of these applications, but at considerable computational costs. Remarkably, taking the width of a neural network to infinity allows for improved computational performance. In this work, we develop an infinite width neural network framework for matrix completion that is simple, fast, and flexible. Simplicity and speed come from the connection between the infinite width limit of neural networks and kernels known as neural tangent kernels (NTK). In particular, we derive the NTK for fully connected and convolutional neural networks for matrix completion. The flexibility stems from a feature prior, which allows encoding relationships between coordinates of the target matrix, akin to semi-supervised learning. The effectiveness of our framework is demonstrated through competitive results for virtual drug screening and image inpainting/reconstruction. We also provide an implementation in Python to make our framework accessible on standard hardware to a broad audience.
Matching Disparate Image Pairs Using Shape-Aware ConvNets
Nov 24, 2018



An end-to-end trainable ConvNet architecture, that learns to harness the power of shape representation for matching disparate image pairs, is proposed. Disparate image pairs are deemed those that exhibit strong affine variations in scale, viewpoint and projection parameters accompanied by the presence of partial or complete occlusion of objects and extreme variations in ambient illumination. Under these challenging conditions, neither local nor global feature-based image matching methods, when used in isolation, have been observed to be effective. The proposed correspondence determination scheme for matching disparate images exploits high-level shape cues that are derived from low-level local feature descriptors, thus combining the best of both worlds. A graph-based representation for the disparate image pair is generated by constructing an affinity matrix that embeds the distances between feature points in two images, thus modeling the correspondence determination problem as one of graph matching. The eigenspectrum of the affinity matrix, i.e., the learned global shape representation, is then used to further regress the transformation or homography that defines the correspondence between the source image and target image. The proposed scheme is shown to yield state-of-the-art results for both, coarse-level shape matching as well as fine point-wise correspondence determination.
Model reduction in acoustic inversion by artificial neural network
May 05, 2021
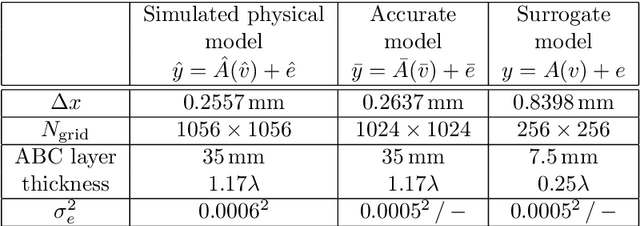
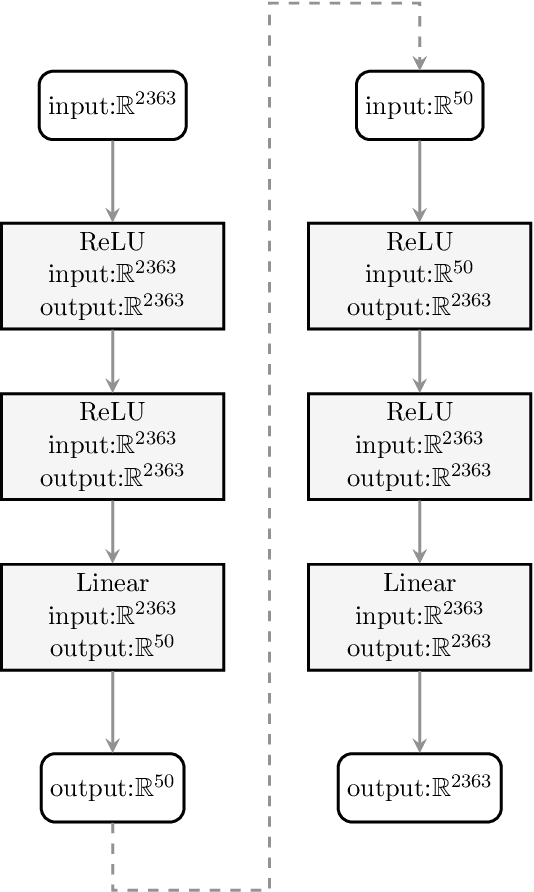
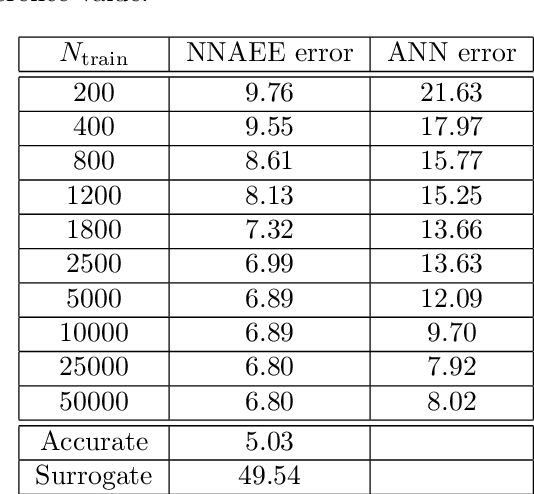
In ultrasound tomography, the speed of sound inside an object is estimated based on acoustic measurements carried out by sensors surrounding the object. An accurate forward model is a prominent factor for high-quality image reconstruction, but it can make computations far too time-consuming in many applications. Using approximate forward models, it is possible to speed up the computations, but the quality of the reconstruction may have to be compromised. In this paper, a neural network -based approach is proposed, that can compensate for modeling errors caused by the approximate forward models. The approach is tested with various different imaging scenarios in a simulated two-dimensional domain. The results show that with fairly small training data sets, the proposed approach can be utilized to approximate the modelling errors, and to significantly improve the image reconstruction quality in ultrasound tomography, compared to commonly used inversion algorithms.
Learning to Separate Multiple Illuminants in a Single Image
Nov 29, 2018



We present a method to separate a single image captured under two illuminants, with different spectra, into the two images corresponding to the appearance of the scene under each individual illuminant. We do this by training a deep neural network to predict the per-pixel reflectance chromaticity of the scene, which we use in conjunction with a previous flash/no-flash image-based separation algorithm to produce the final two output images. We design our reflectance chromaticity network and loss functions by incorporating intuitions from the physics of image formation. We show that this leads to significantly better performance than other single image techniques and even approaches the quality of the two image separation method.
A Global Appearance and Local Coding Distortion based Fusion Framework for CNN based Filtering in Video Coding
Jun 24, 2021

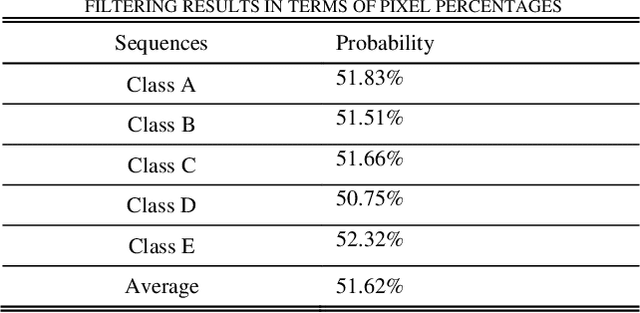
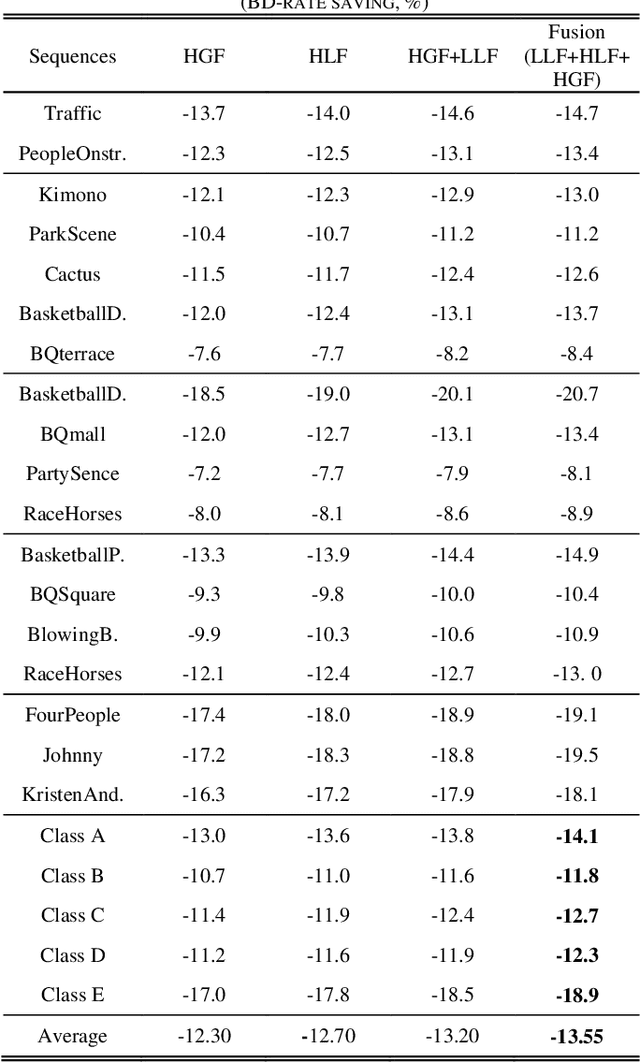
In-loop filtering is used in video coding to process the reconstructed frame in order to remove blocking artifacts. With the development of convolutional neural networks (CNNs), CNNs have been explored for in-loop filtering considering it can be treated as an image de-noising task. However, in addition to being a distorted image, the reconstructed frame is also obtained by a fixed line of block based encoding operations in video coding. It carries coding-unit based coding distortion of some similar characteristics. Therefore, in this paper, we address the filtering problem from two aspects, global appearance restoration for disrupted texture and local coding distortion restoration caused by fixed pipeline of coding. Accordingly, a three-stream global appearance and local coding distortion based fusion network is developed with a high-level global feature stream, a high-level local feature stream and a low-level local feature stream. Ablation study is conducted to validate the necessity of different features, demonstrating that the global features and local features can complement each other in filtering and achieve better performance when combined. To the best of our knowledge, we are the first one that clearly characterizes the video filtering process from the above global appearance and local coding distortion restoration aspects with experimental verification, providing a clear pathway to developing filter techniques. Experimental results demonstrate that the proposed method significantly outperforms the existing single-frame based methods and achieves 13.5%, 11.3%, 11.7% BD-Rate saving on average for AI, LDP and RA configurations, respectively, compared with the HEVC reference software.
Perceptually Guided Adversarial Perturbations
Jun 24, 2021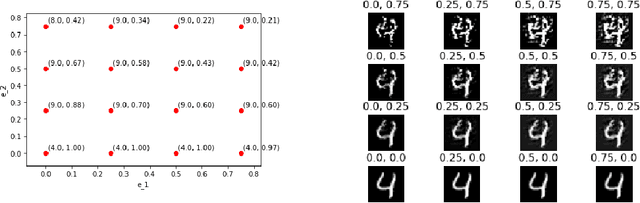

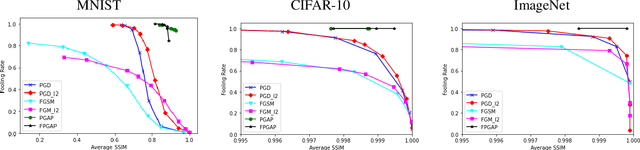
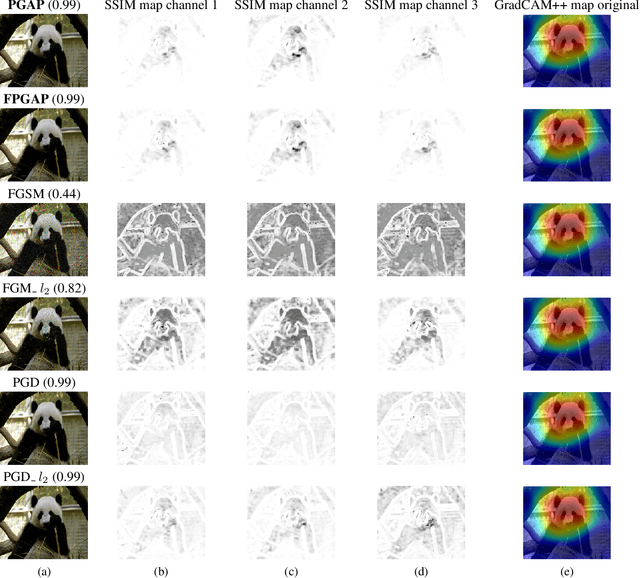
It is well known that carefully crafted imperceptible perturbations can cause state-of-the-art deep learning classification models to misclassify. Understanding and analyzing these adversarial perturbations play a crucial role in the design of robust convolutional neural networks. However, the reasons for the existence of adversarial perturbations and their mechanics are not well understood. In this work, we attempt to systematically answer the following question: do imperceptible adversarial perturbations focus on changing the regions of the image that are important for classification? Most current methods use $l_p$ distance to generate and characterize the imperceptibility of the adversarial perturbations. However, since $l_p$ distances only measure the pixel to pixel distances and do not consider the structure in the image, these methods do not provide a satisfactory answer to the above question. To address this issue, we propose a novel framework for generating adversarial perturbations by explicitly incorporating a ``perceptual quality ball" constraint in our formulation. Specifically, we pose the adversarial example generation problem as a tractable convex optimization problem, with constraints taken from a mathematically amenable variant of the popular SSIM index. We show that the perturbations generated by the proposed method result in a high fooling rate with minimal impact on perceptual quality compared to the norm bounded adversarial perturbations. Further, through SSIM maps, we show that the perceptually guided perturbations introduce changes specifically in the regions that contribute to classification decisions. We use networks trained on MNIST and CIFAR-10 datasets quantitative analysis, and MobileNetV2 trained on the ImageNet dataset for further qualitative analysis.
Theoretical Analysis of Image-to-Image Translation with Adversarial Learning
Jun 19, 2018Recently, a unified model for image-to-image translation tasks within adversarial learning framework has aroused widespread research interests in computer vision practitioners. Their reported empirical success however lacks solid theoretical interpretations for its inherent mechanism. In this paper, we reformulate their model from a brand-new geometrical perspective and have eventually reached a full interpretation on some interesting but unclear empirical phenomenons from their experiments. Furthermore, by extending the definition of generalization for generative adversarial nets to a broader sense, we have derived a condition to control the generalization capability of their model. According to our derived condition, several practical suggestions have also been proposed on model design and dataset construction as a guidance for further empirical researches.
Robustness-via-Synthesis: Robust Training with Generative Adversarial Perturbations
Aug 22, 2021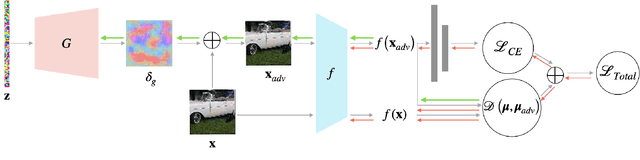
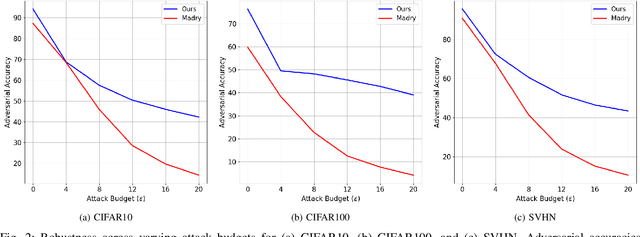
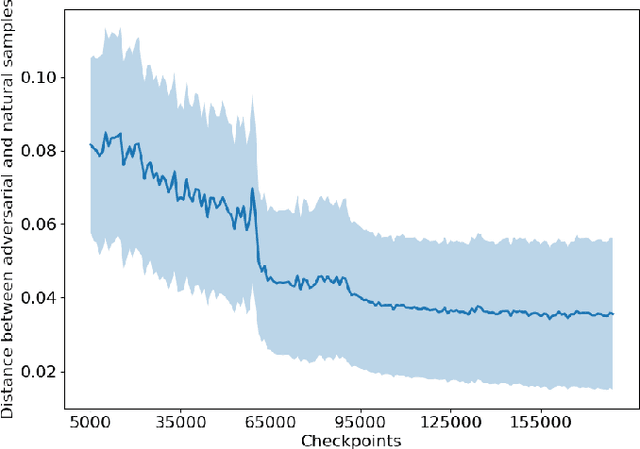
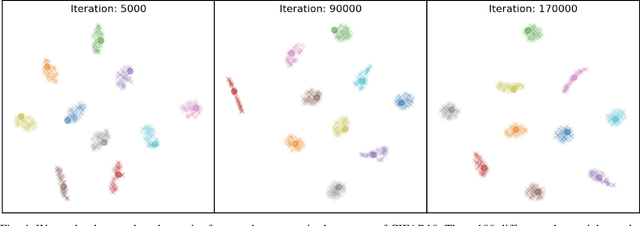
Upon the discovery of adversarial attacks, robust models have become obligatory for deep learning-based systems. Adversarial training with first-order attacks has been one of the most effective defenses against adversarial perturbations to this day. The majority of the adversarial training approaches focus on iteratively perturbing each pixel with the gradient of the loss function with respect to the input image. However, the adversarial training with gradient-based attacks lacks diversity and does not generalize well to natural images and various attacks. This study presents a robust training algorithm where the adversarial perturbations are automatically synthesized from a random vector using a generator network. The classifier is trained with cross-entropy loss regularized with the optimal transport distance between the representations of the natural and synthesized adversarial samples. Unlike prevailing generative defenses, the proposed one-step attack generation framework synthesizes diverse perturbations without utilizing gradient of the classifier's loss. Experimental results show that the proposed approach attains comparable robustness with various gradient-based and generative robust training techniques on CIFAR10, CIFAR100, and SVHN datasets. In addition, compared to the baselines, the proposed robust training framework generalizes well to the natural samples. Code and trained models will be made publicly available.
Bilinear Supervised Hashing Based on 2D Image Features
Jan 05, 2019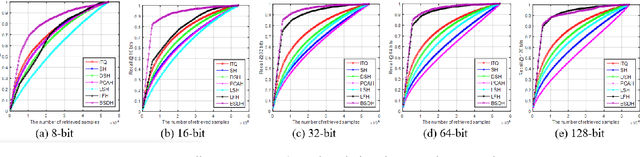
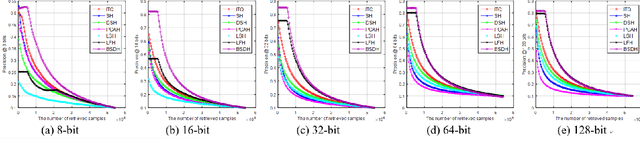
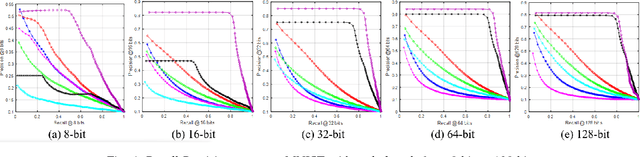
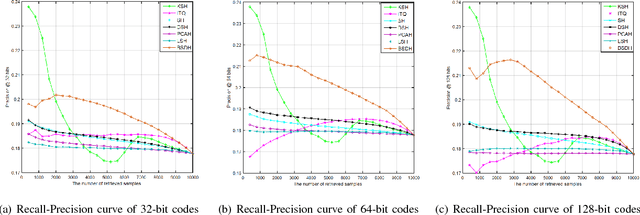
Hashing has been recognized as an efficient representation learning method to effectively handle big data due to its low computational complexity and memory cost. Most of the existing hashing methods focus on learning the low-dimensional vectorized binary features based on the high-dimensional raw vectorized features. However, studies on how to obtain preferable binary codes from the original 2D image features for retrieval is very limited. This paper proposes a bilinear supervised discrete hashing (BSDH) method based on 2D image features which utilizes bilinear projections to binarize the image matrix features such that the intrinsic characteristics in the 2D image space are preserved in the learned binary codes. Meanwhile, the bilinear projection approximation and vectorization binary codes regression are seamlessly integrated together to formulate the final robust learning framework. Furthermore, a discrete optimization strategy is developed to alternatively update each variable for obtaining the high-quality binary codes. In addition, two 2D image features, traditional SURF-based FVLAD feature and CNN-based AlexConv5 feature are designed for further improving the performance of the proposed BSDH method. Results of extensive experiments conducted on four benchmark datasets show that the proposed BSDH method almost outperforms all competing hashing methods with different input features by different evaluation protocols.