 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Non-Parametric Neural Style Transfer
Aug 29, 2021



It seems easy to imagine a photograph of the Eiffel Tower painted in the style of Vincent van Gogh's 'The Starry Night', but upon introspection it is difficult to precisely define what this would entail. What visual elements must an image contain to represent the 'content' of the Eiffel Tower? What visual elements of 'The Starry Night' are caused by van Gogh's 'style' rather than his decision to depict a village under the night sky? Precisely defining 'content' and 'style' is a central challenge of designing algorithms for artistic style transfer, algorithms which can recreate photographs using an artwork's style. My efforts defining these terms, and designing style transfer algorithms themselves, are the focus of this thesis. I will begin by proposing novel definitions of style and content based on optimal transport and self-similarity, and demonstrating how a style transfer algorithm based on these definitions generates outputs with improved visual quality. Then I will describe how the traditional texture-based definition of style can be expanded to include elements of geometry and proportion by jointly optimizing a keypoint-guided deformation field alongside the stylized output's pixels. Finally I will describe a framework inspired by both modern neural style transfer algorithms and traditional patch-based synthesis approaches which is fast, general, and offers state-of-the-art visual quality.
6D Object Pose Estimation using Keypoints and Part Affinity Fields
Jul 22, 2021



The task of 6D object pose estimation from RGB images is an important requirement for autonomous service robots to be able to interact with the real world. In this work, we present a two-step pipeline for estimating the 6 DoF translation and orientation of known objects. Keypoints and Part Affinity Fields (PAFs) are predicted from the input image adopting the OpenPose CNN architecture from human pose estimation. Object poses are then calculated from 2D-3D correspondences between detected and model keypoints via the PnP-RANSAC algorithm. The proposed approach is evaluated on the YCB-Video dataset and achieves accuracy on par with recent methods from the literature. Using PAFs to assemble detected keypoints into object instances proves advantageous over only using heatmaps. Models trained to predict keypoints of a single object class perform significantly better than models trained for several classes.
* In: Proceedings of 24th RoboCup International Symposium, June 2021, 12 pages, 6 figures
F-Drop&Match: GANs with a Dead Zone in the High-Frequency Domain
Jun 04, 2021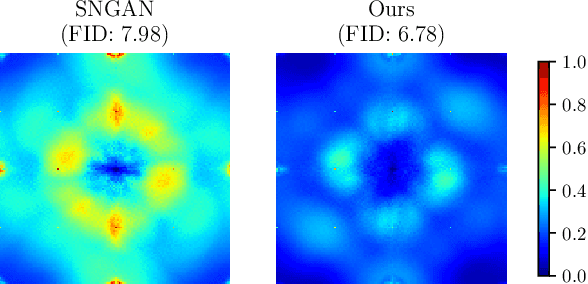
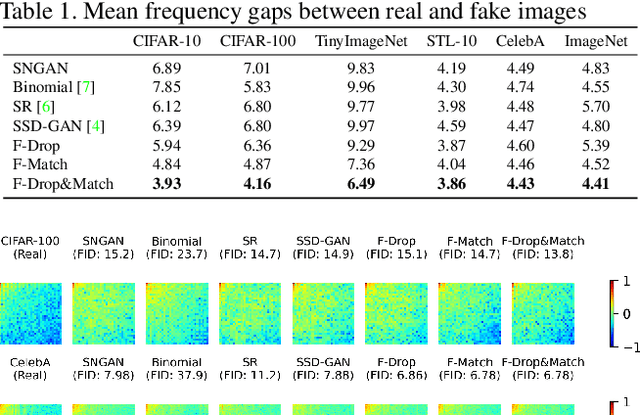
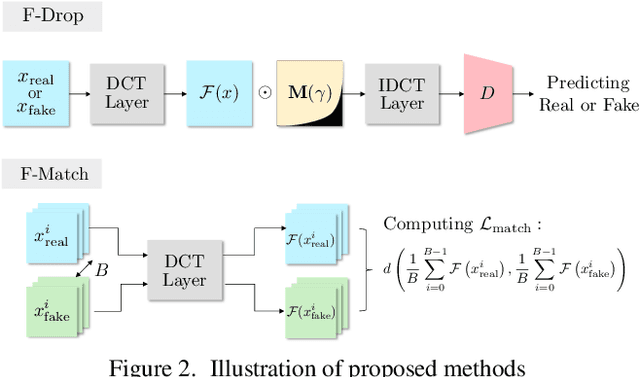

Generative adversarial networks built from deep convolutional neural networks (GANs) lack the ability to exactly replicate the high-frequency components of natural images. To alleviate this issue, we introduce two novel training techniques called frequency dropping (F-Drop) and frequency matching (F-Match). The key idea of F-Drop is to filter out unnecessary high-frequency components from the input images of the discriminators. This simple modification prevents the discriminators from being confused by perturbations of the high-frequency components. In addition, F-Drop makes the GANs focus on fitting in the low-frequency domain, in which there are the dominant components of natural images. F-Match minimizes the difference between real and fake images in the frequency domain for generating more realistic images. F-Match is implemented as a regularization term in the objective functions of the generators; it penalizes the batch mean error in the frequency domain. F-Match helps the generators to fit in the high-frequency domain filtered out by F-Drop to the real image. We experimentally demonstrate that the combination of F-Drop and F-Match improves the generative performance of GANs in both the frequency and spatial domain on multiple image benchmarks (CIFAR, TinyImageNet, STL-10, CelebA, and ImageNet).
Application of Monte Carlo algorithms to cardiac imaging reconstruction
May 27, 2021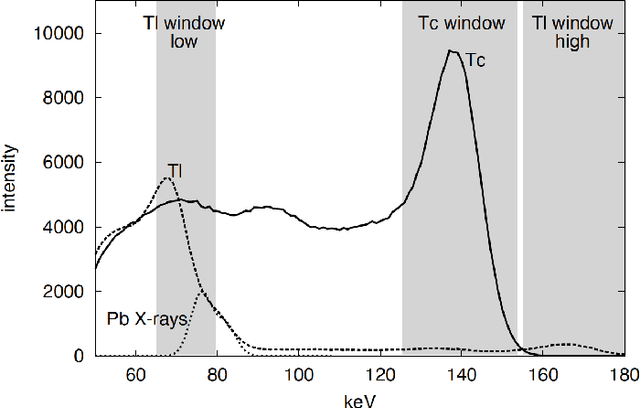
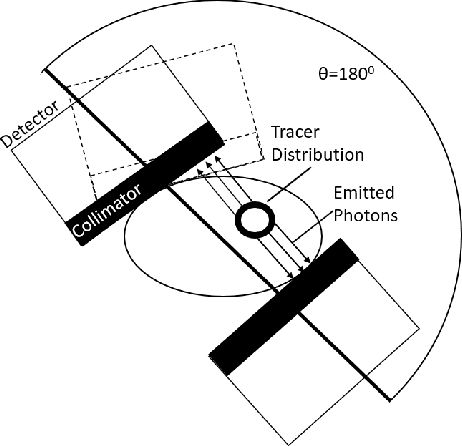
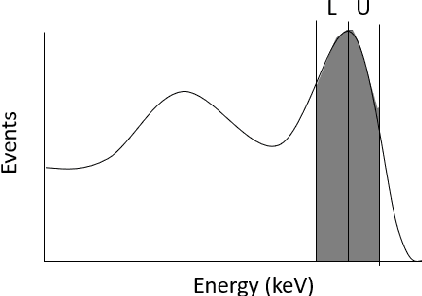
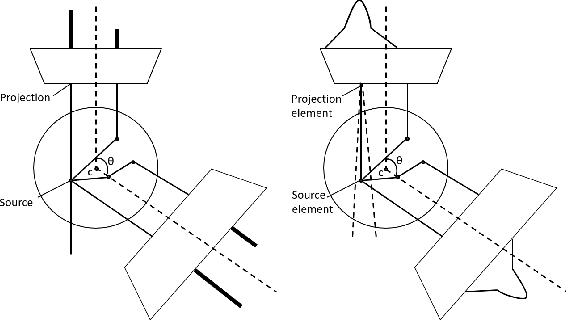
Monte Carlo algorithms have a growing impact on nuclear medicine reconstruction processes. One of the main limitations of myocardial perfusion imaging (MPI) is the effective mitigation of the scattering component, which is particularly challenging in Single Photon Emission Computed Tomography (SPECT). In SPECT, no timing information can be retrieved to locate the primary source photons. Monte Carlo methods allow an event-by-event simulation of the scattering kinematics, which can be incorporated into a model of the imaging system response. This approach was adopted since the late Nineties by several authors, and recently took advantage of the increased computational power made available by high-performance CPUs and GPUs. These recent developments enable a fast image reconstruction with an improved image quality, compared to deterministic approaches. Deterministic approaches are based on energy-windowing of the detector response, and on the cumulative estimate and subtraction of the scattering component. In this paper, we review the main strategies and algorithms to correct for the scattering effect in SPECT and focus on Monte Carlo developments, which nowadays allow the three-dimensional reconstruction of SPECT cardiac images in a few seconds.
Event-driven Vision and Control for UAVs on a Neuromorphic Chip
Aug 08, 2021
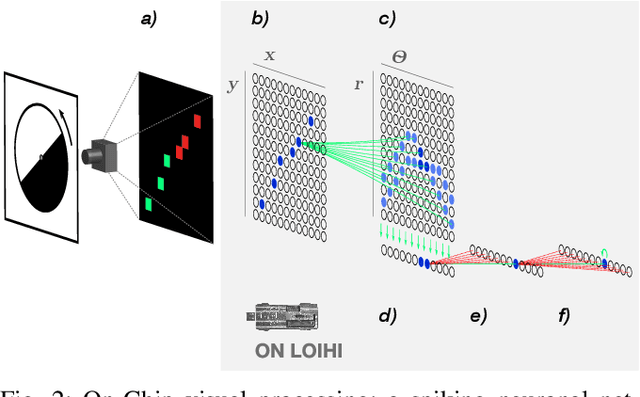
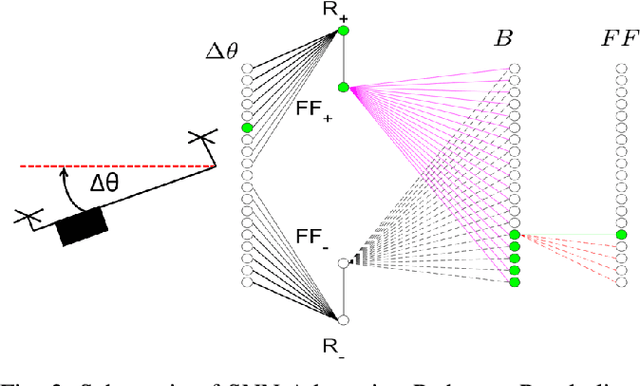
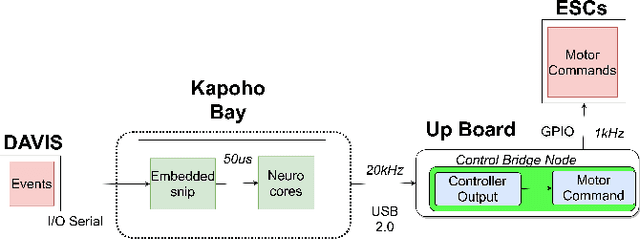
Event-based vision sensors achieve up to three orders of magnitude better speed vs. power consumption trade off in high-speed control of UAVs compared to conventional image sensors. Event-based cameras produce a sparse stream of events that can be processed more efficiently and with a lower latency than images, enabling ultra-fast vision-driven control. Here, we explore how an event-based vision algorithm can be implemented as a spiking neuronal network on a neuromorphic chip and used in a drone controller. We show how seamless integration of event-based perception on chip leads to even faster control rates and lower latency. In addition, we demonstrate how online adaptation of the SNN controller can be realised using on-chip learning. Our spiking neuronal network on chip is the first example of a neuromorphic vision-based controller solving a high-speed UAV control task. The excellent scalability of processing in neuromorphic hardware opens the possibility to solve more challenging visual tasks in the future and integrate visual perception in fast control loops.
Stimuli-Aware Visual Emotion Analysis
Sep 04, 2021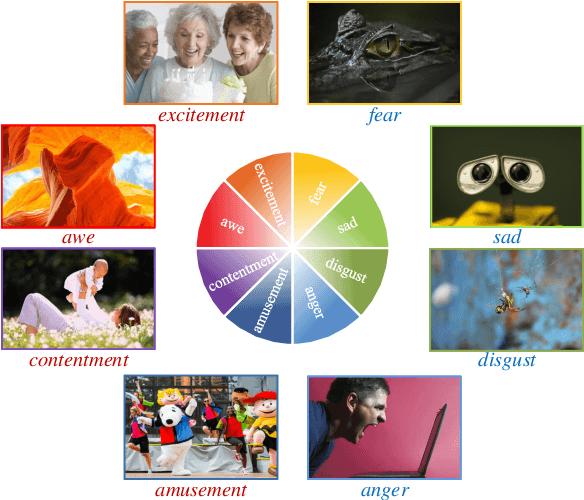

Visual emotion analysis (VEA) has attracted great attention recently, due to the increasing tendency of expressing and understanding emotions through images on social networks. Different from traditional vision tasks, VEA is inherently more challenging since it involves a much higher level of complexity and ambiguity in human cognitive process. Most of the existing methods adopt deep learning techniques to extract general features from the whole image, disregarding the specific features evoked by various emotional stimuli. Inspired by the \textit{Stimuli-Organism-Response (S-O-R)} emotion model in psychological theory, we proposed a stimuli-aware VEA method consisting of three stages, namely stimuli selection (S), feature extraction (O) and emotion prediction (R). First, specific emotional stimuli (i.e., color, object, face) are selected from images by employing the off-the-shelf tools. To the best of our knowledge, it is the first time to introduce stimuli selection process into VEA in an end-to-end network. Then, we design three specific networks, i.e., Global-Net, Semantic-Net and Expression-Net, to extract distinct emotional features from different stimuli simultaneously. Finally, benefiting from the inherent structure of Mikel's wheel, we design a novel hierarchical cross-entropy loss to distinguish hard false examples from easy ones in an emotion-specific manner. Experiments demonstrate that the proposed method consistently outperforms the state-of-the-art approaches on four public visual emotion datasets. Ablation study and visualizations further prove the validity and interpretability of our method.
* Accepted by TIP
Matching Disparate Image Pairs Using Shape-Aware ConvNets
Nov 24, 2018



An end-to-end trainable ConvNet architecture, that learns to harness the power of shape representation for matching disparate image pairs, is proposed. Disparate image pairs are deemed those that exhibit strong affine variations in scale, viewpoint and projection parameters accompanied by the presence of partial or complete occlusion of objects and extreme variations in ambient illumination. Under these challenging conditions, neither local nor global feature-based image matching methods, when used in isolation, have been observed to be effective. The proposed correspondence determination scheme for matching disparate images exploits high-level shape cues that are derived from low-level local feature descriptors, thus combining the best of both worlds. A graph-based representation for the disparate image pair is generated by constructing an affinity matrix that embeds the distances between feature points in two images, thus modeling the correspondence determination problem as one of graph matching. The eigenspectrum of the affinity matrix, i.e., the learned global shape representation, is then used to further regress the transformation or homography that defines the correspondence between the source image and target image. The proposed scheme is shown to yield state-of-the-art results for both, coarse-level shape matching as well as fine point-wise correspondence determination.
Robust Place Recognition using an Imaging Lidar
Mar 03, 2021

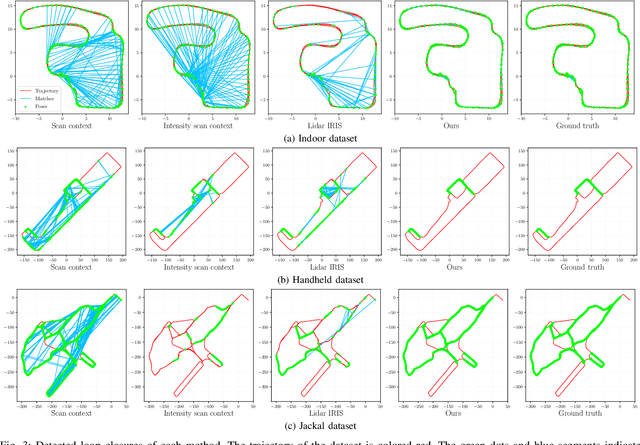

We propose a methodology for robust, real-time place recognition using an imaging lidar, which yields image-quality high-resolution 3D point clouds. Utilizing the intensity readings of an imaging lidar, we project the point cloud and obtain an intensity image. ORB feature descriptors are extracted from the image and encoded into a bag-of-words vector. The vector, used to identify the point cloud, is inserted into a database that is maintained by DBoW for fast place recognition queries. The returned candidate is further validated by matching visual feature descriptors. To reject matching outliers, we apply PnP, which minimizes the reprojection error of visual features' positions in Euclidean space with their correspondences in 2D image space, using RANSAC. Combining the advantages from both camera and lidar-based place recognition approaches, our method is truly rotation-invariant and can tackle reverse revisiting and upside-down revisiting. The proposed method is evaluated on datasets gathered from a variety of platforms over different scales and environments. Our implementation is available at https://git.io/imaging-lidar-place-recognition
KRADA: Known-region-aware Domain Alignment for Open World Semantic Segmentation
Jun 11, 2021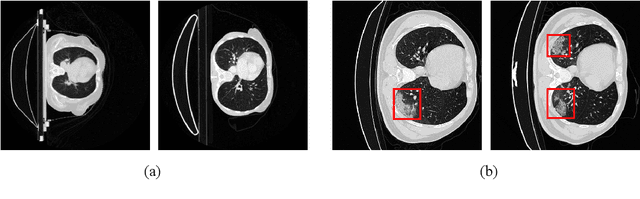
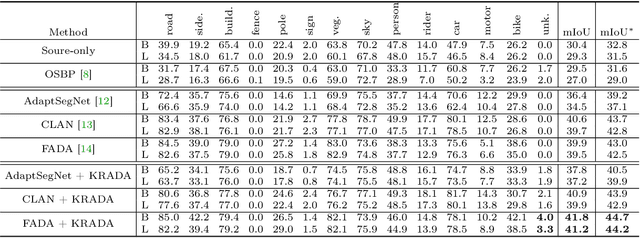
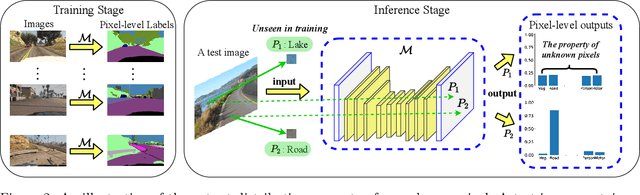
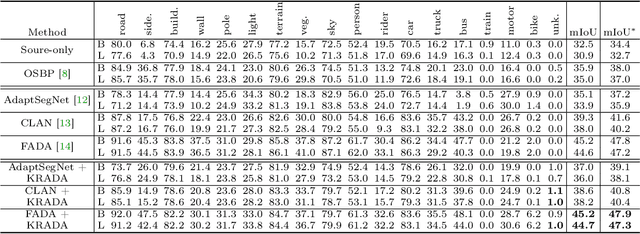
In semantic segmentation, we aim to train a pixel-level classifier to assign category labels to all pixels in an image, where labeled training images and unlabeled test images are from the same distribution and share the same label set. However, in an open world, the unlabeled test images probably contain unknown categories and have different distributions from the labeled images. Hence, in this paper, we consider a new, more realistic, and more challenging problem setting where the pixel-level classifier has to be trained with labeled images and unlabeled open-world images -- we name it open world semantic segmentation (OSS). In OSS, the trained classifier is expected to identify unknown-class pixels and classify known-class pixels well. To solve OSS, we first investigate which distribution that unknown-class pixels obey. Then, motivated by the goodness-of-fit test, we use statistical measurements to show how a pixel fits the distribution of an unknown class and select highly-fitted pixels to form the unknown region in each image. Eventually, we propose an end-to-end learning framework, known-region-aware domain alignment (KRADA), to distinguish unknown classes while aligning distributions of known classes in labeled and unlabeled open-world images. The effectiveness of KRADA has been verified on two synthetic tasks and one COVID-19 segmentation task.
Reducing the Communication Cost of Federated Learning through Multistage Optimization
Aug 16, 2021
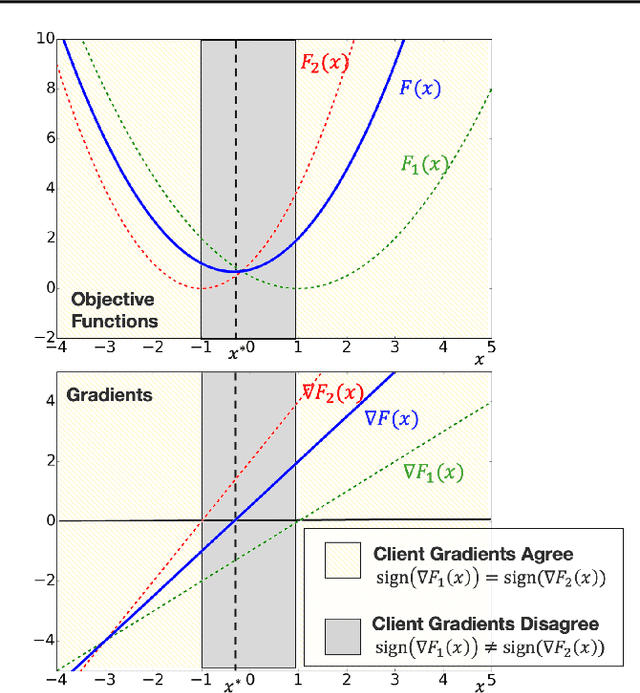

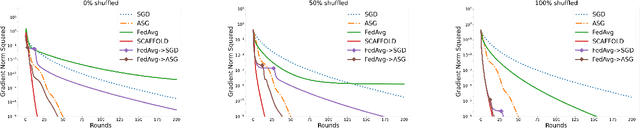
A central question in federated learning (FL) is how to design optimization algorithms that minimize the communication cost of training a model over heterogeneous data distributed across many clients. A popular technique for reducing communication is the use of local steps, where clients take multiple optimization steps over local data before communicating with the server (e.g., FedAvg, SCAFFOLD). This contrasts with centralized methods, where clients take one optimization step per communication round (e.g., Minibatch SGD). A recent lower bound on the communication complexity of first-order methods shows that centralized methods are optimal over highly-heterogeneous data, whereas local methods are optimal over purely homogeneous data [Woodworth et al., 2020]. For intermediate heterogeneity levels, no algorithm is known to match the lower bound. In this paper, we propose a multistage optimization scheme that nearly matches the lower bound across all heterogeneity levels. The idea is to first run a local method up to a heterogeneity-induced error floor; next, we switch to a centralized method for the remaining steps. Our analysis may help explain empirically-successful stepsize decay methods in FL [Charles et al., 2020; Reddi et al., 2020]. We demonstrate the scheme's practical utility in image classification tasks.