 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Network-Agnostic Knowledge Transfer for Medical Image Segmentation
Jan 23, 2021

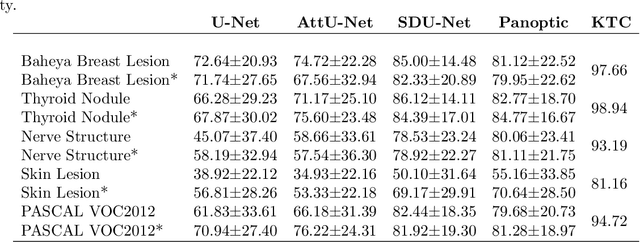
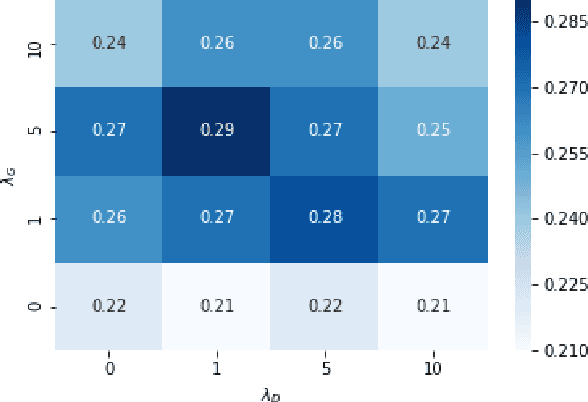
Conventional transfer learning leverages weights of pre-trained networks, but mandates the need for similar neural architectures. Alternatively, knowledge distillation can transfer knowledge between heterogeneous networks but often requires access to the original training data or additional generative networks. Knowledge transfer between networks can be improved by being agnostic to the choice of network architecture and reducing the dependence on original training data. We propose a knowledge transfer approach from a teacher to a student network wherein we train the student on an independent transferal dataset, whose annotations are generated by the teacher. Experiments were conducted on five state-of-the-art networks for semantic segmentation and seven datasets across three imaging modalities. We studied knowledge transfer from a single teacher, combination of knowledge transfer and fine-tuning, and knowledge transfer from multiple teachers. The student model with a single teacher achieved similar performance as the teacher; and the student model with multiple teachers achieved better performance than the teachers. The salient features of our algorithm include: 1)no need for original training data or generative networks, 2) knowledge transfer between different architectures, 3) ease of implementation for downstream tasks by using the downstream task dataset as the transferal dataset, 4) knowledge transfer of an ensemble of models, trained independently, into one student model. Extensive experiments demonstrate that the proposed algorithm is effective for knowledge transfer and easily tunable.
I Want This Product but Different : Multimodal Retrieval with Synthetic Query Expansion
Feb 17, 2021


This paper addresses the problem of media retrieval using a multimodal query (a query which combines visual input with additional semantic information in natural language feedback). We propose a SynthTriplet GAN framework which resolves this task by expanding the multimodal query with a synthetically generated image that captures semantic information from both image and text input. We introduce a novel triplet mining method that uses a synthetic image as an anchor to directly optimize for embedding distances of generated and target images. We demonstrate that apart from the added value of retrieval illustration with synthetic image with the focus on customization and user feedback, the proposed method greatly surpasses other multimodal generation methods and achieves state of the art results in the multimodal retrieval task. We also show that in contrast to other retrieval methods, our method provides explainable embeddings.
Offline and Online Deep Learning for Image Recognition
Mar 18, 2019
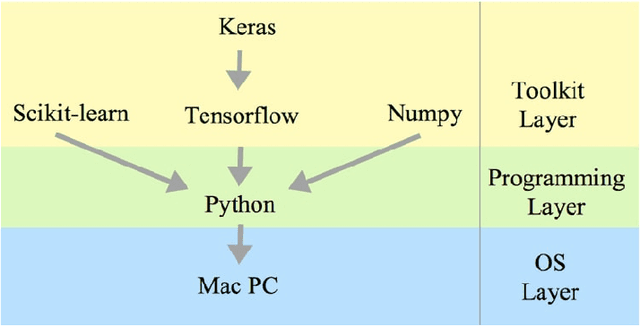
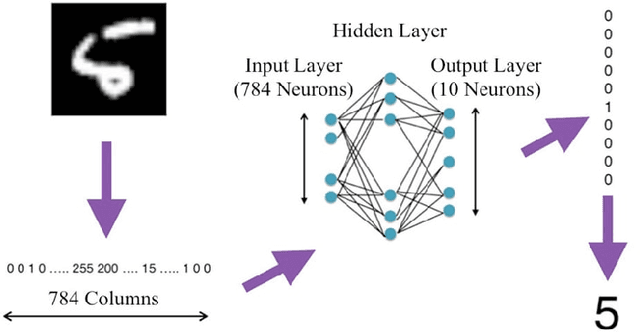
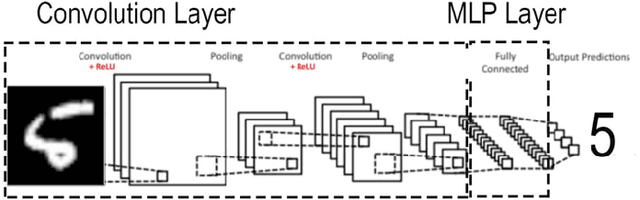
Image recognition using Deep Learning has been evolved for decades though advances in the field through different settings is still a challenge. In this paper, we present our findings in searching for better image classifiers in offline and online environments. We resort to Convolutional Neural Network and its variations of fully connected Multi-layer Perceptron. Though still preliminary, these results are encouraging and may provide a better understanding about the field and directions toward future works.
* 5 pages
BIRL: Benchmark on Image Registration methods with Landmark validation
Dec 31, 2019
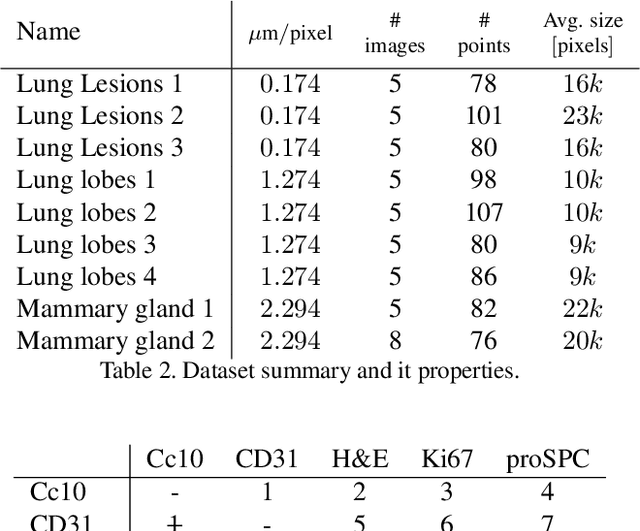
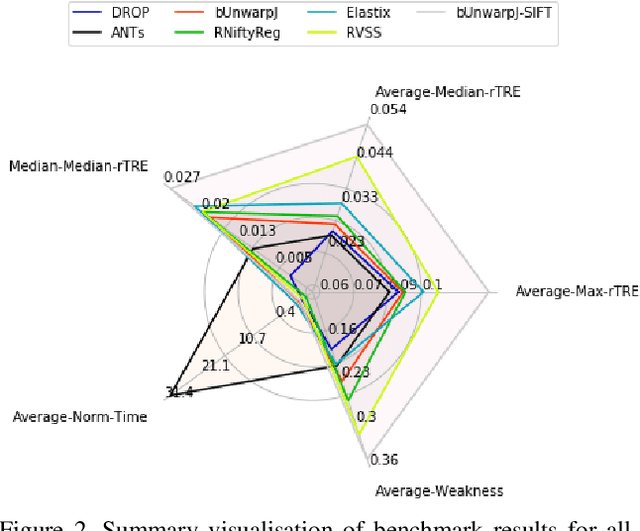
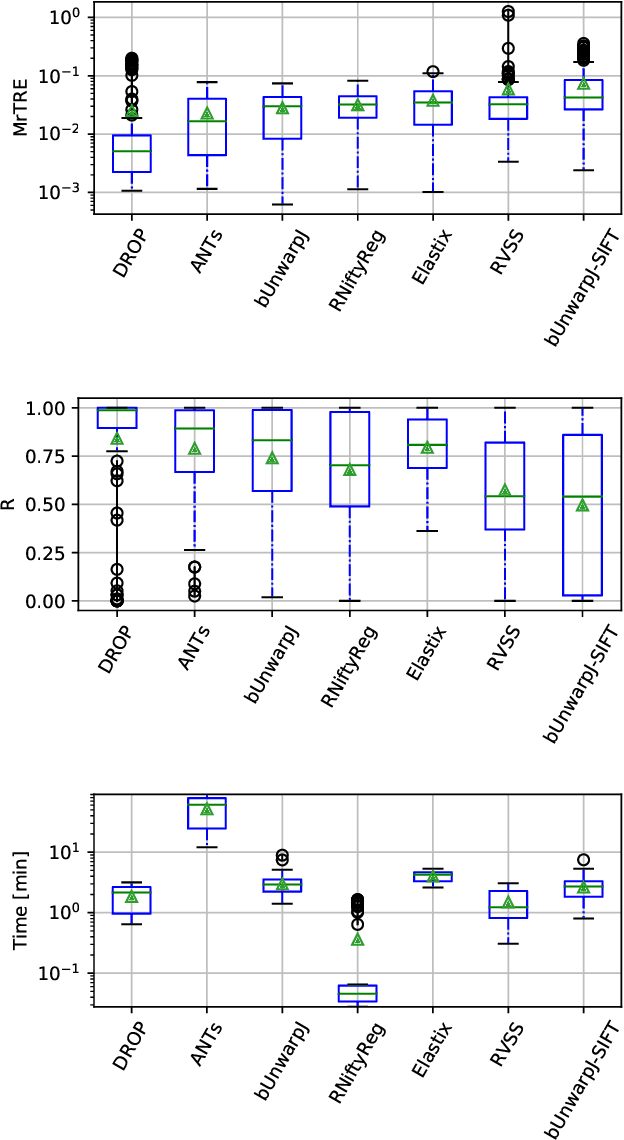
This report presents a generic image registration benchmark with automatic evaluation using landmark annotations. The BIRL framework has a few key features, such as: easily extendable, performance evaluation, parallel experimenting, simple visualisations, experiment's time-out limit, pause/resume experiments. The main use-cases are (a) compare your (newly developed) method with some State-of-the-Art (SOTA) methods on a common dataset and (b) experiment SOTA methods on your custom dataset (which should contain landmark annotation). In this paper, we present mixed-methods aiming at bio-medical imaging and experimental result on CIMA dataset. However, any other methods for other domain can be added or costume dataset to be used. https://borda.github.io/BIRL
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 11, 2021
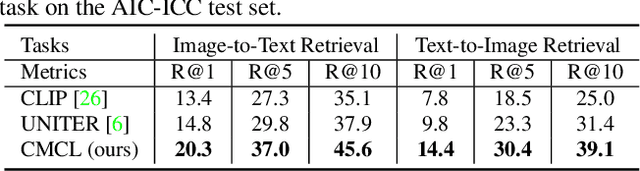
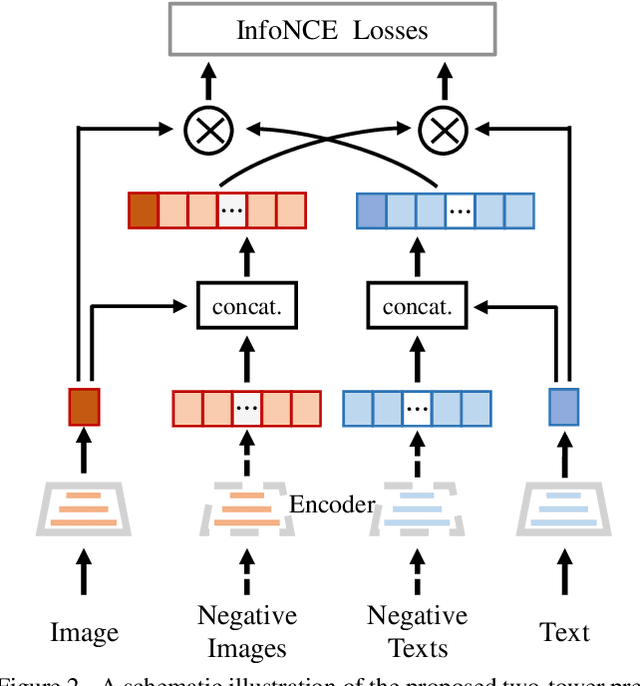
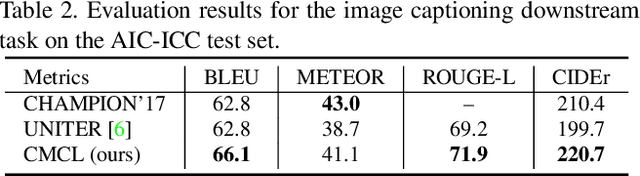
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model within the cross-modal contrastive learning (CMCL) framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our CMCL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our CMCL model. Extensive experiments demonstrate that the pre-trained CMCL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
DCL: Differential Contrastive Learning for Geometry-Aware Depth Synthesis
Jul 27, 2021
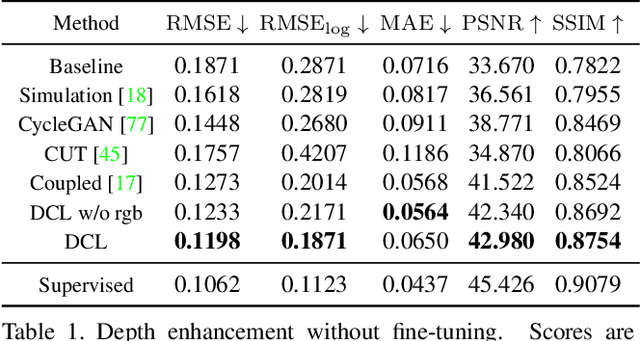
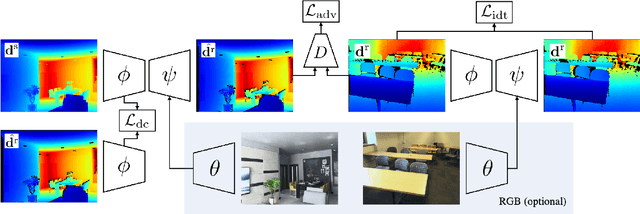
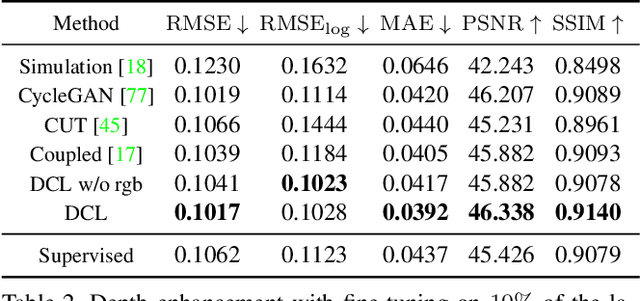
We describe a method for realistic depth synthesis that learns diverse variations from the real depth scans and ensures geometric consistency for effective synthetic-to-real transfer. Unlike general image synthesis pipelines, where geometries are mostly ignored, we treat geometries carried by the depth based on their own existence. We propose differential contrastive learning that explicitly enforces the underlying geometric properties to be invariant regarding the real variations been learned. The resulting depth synthesis method is task-agnostic and can be used for training any task-specific networks with synthetic labels. We demonstrate the effectiveness of the proposed method by extensive evaluations on downstream real-world geometric reasoning tasks. We show our method achieves better synthetic-to-real transfer performance than the other state-of-the-art. When fine-tuned on a small number of real-world annotations, our method can even surpass the fully supervised baselines.
Efficient Smoothing of Dilated Convolutions for Image Segmentation
Mar 19, 2019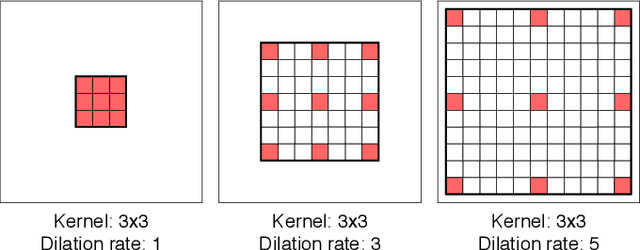
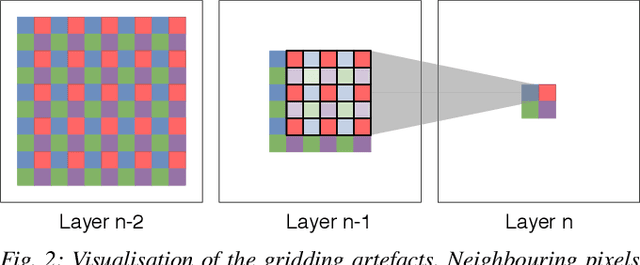
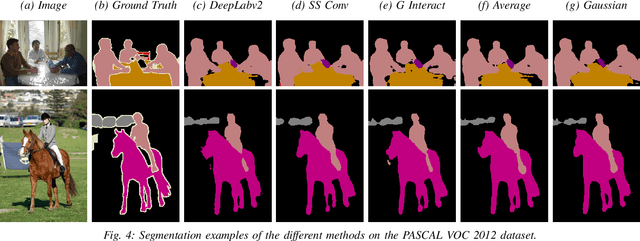
Dilated Convolutions have been shown to be highly useful for the task of image segmentation. By introducing gaps into convolutional filters, they enable the use of larger receptive fields without increasing the original kernel size. Even though this allows for the inexpensive capturing of features at different scales, the structure of the dilated convolutional filter leads to a loss of information. We hypothesise that inexpensive modifications to Dilated Convolutional Neural Networks, such as additional averaging layers, could overcome this limitation. In this project we test this hypothesis by evaluating the effect of these modifications for a state-of-the art image segmentation system and compare them to existing approaches with the same objective. Our experiments show that our proposed methods improve the performance of dilated convolutions for image segmentation. Crucially, our modifications achieve these results at a much lower computational cost than previous smoothing approaches.
Photon-Starved Scene Inference using Single Photon Cameras
Aug 16, 2021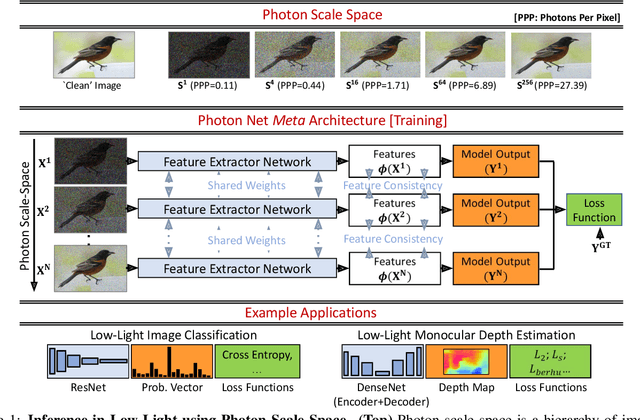



Scene understanding under low-light conditions is a challenging problem. This is due to the small number of photons captured by the camera and the resulting low signal-to-noise ratio (SNR). Single-photon cameras (SPCs) are an emerging sensing modality that are capable of capturing images with high sensitivity. Despite having minimal read-noise, images captured by SPCs in photon-starved conditions still suffer from strong shot noise, preventing reliable scene inference. We propose photon scale-space a collection of high-SNR images spanning a wide range of photons-per-pixel (PPP) levels (but same scene content) as guides to train inference model on low photon flux images. We develop training techniques that push images with different illumination levels closer to each other in feature representation space. The key idea is that having a spectrum of different brightness levels during training enables effective guidance, and increases robustness to shot noise even in extreme noise cases. Based on the proposed approach, we demonstrate, via simulations and real experiments with a SPAD camera, high-performance on various inference tasks such as image classification and monocular depth estimation under ultra low-light, down to < 1 PPP.
Learning Parallax Attention for Stereo Image Super-Resolution
Mar 19, 2019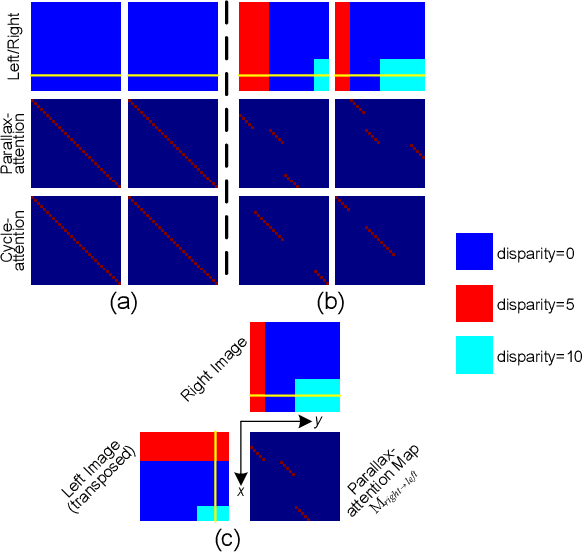
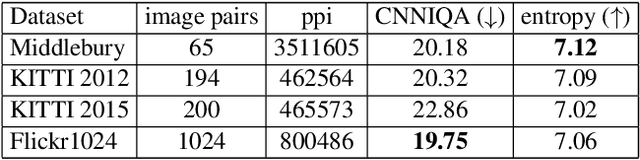
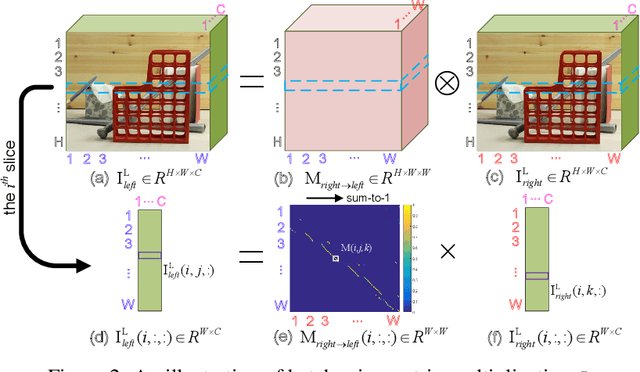
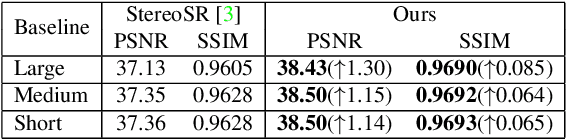
Stereo image pairs can be used to improve the performance of super-resolution (SR) since additional information is provided from a second viewpoint. However, it is challenging to incorporate this information for SR since disparities between stereo images vary significantly. In this paper, we propose a parallax-attention stereo superresolution network (PASSRnet) to integrate the information from a stereo image pair for SR. Specifically, we introduce a parallax-attention mechanism with a global receptive field along the epipolar line to handle different stereo images with large disparity variations. We also propose a new and the largest dataset for stereo image SR (namely, Flickr1024). Extensive experiments demonstrate that the parallax-attention mechanism can capture correspondence between stereo images to improve SR performance with a small computational and memory cost. Comparative results show that our PASSRnet achieves the state-of-the-art performance on the Middlebury, KITTI 2012 and KITTI 2015 datasets.
Computed Tomography Reconstruction Using Deep Image Prior and Learned Reconstruction Methods
Mar 12, 2020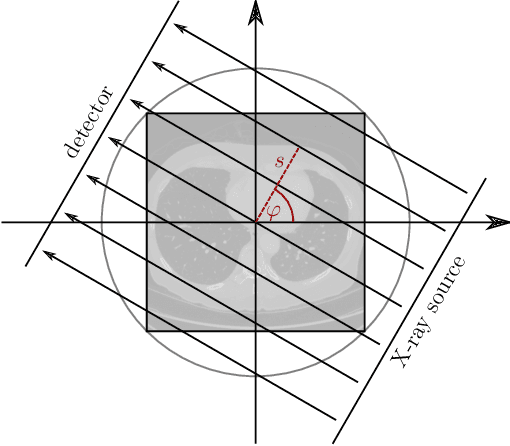


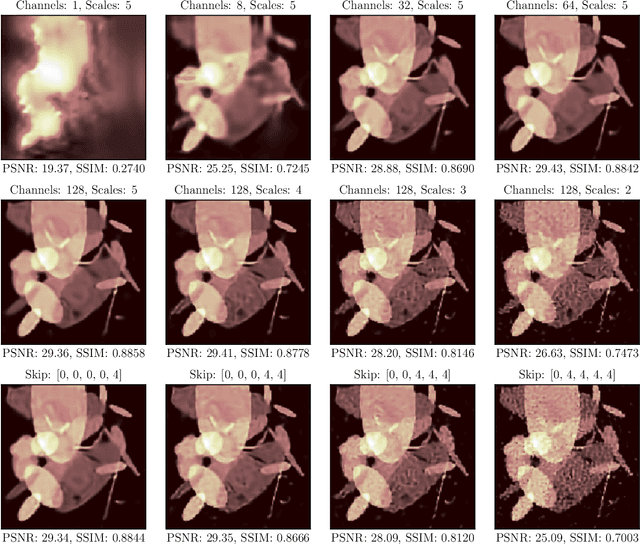
In this work, we investigate the application of deep learning methods for computed tomography in the context of having a low-data regime. As motivation, we review some of the existing approaches and obtain quantitative results after training them with different amounts of data. We find that the learned primal-dual has an outstanding performance in terms of reconstruction quality and data efficiency. However, in general, end-to-end learned methods have two issues: a) lack of classical guarantees in inverse problems and b) lack of generalization when not trained with enough data. To overcome these issues, we bring in the deep image prior approach in combination with classical regularization. The proposed methods improve the state-of-the-art results in the low data-regime.