 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MFEViT: A Robust Lightweight Transformer-based Network for Multimodal 2D+3D Facial Expression Recognition
Sep 20, 2021

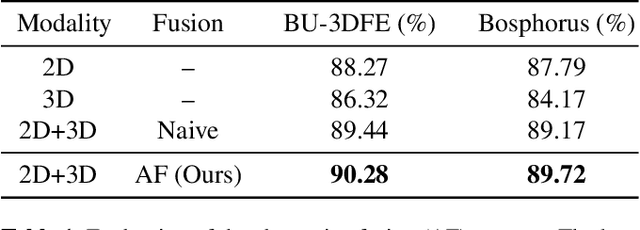
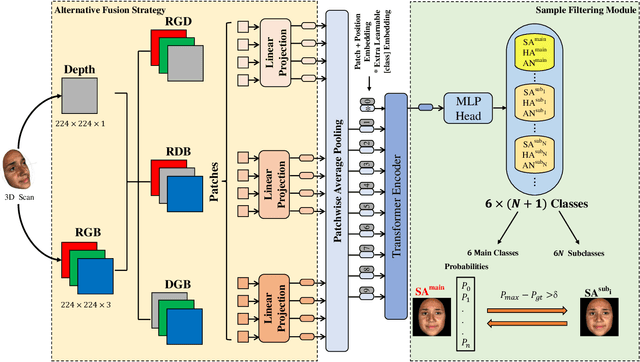
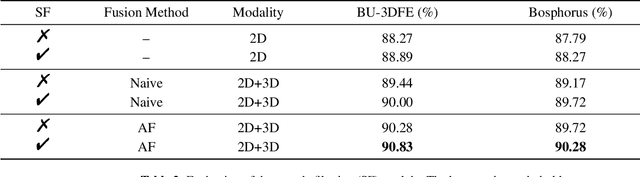
Vision transformer (ViT) has been widely applied in many areas due to its self-attention mechanism that help obtain the global receptive field since the first layer. It even achieves surprising performance exceeding CNN in some vision tasks. However, there exists an issue when leveraging vision transformer into 2D+3D facial expression recognition (FER), i.e., ViT training needs mass data. Nonetheless, the number of samples in public 2D+3D FER datasets is far from sufficient for evaluation. How to utilize the ViT pre-trained on RGB images to handle 2D+3D data becomes a challenge. To solve this problem, we propose a robust lightweight pure transformer-based network for multimodal 2D+3D FER, namely MFEViT. For narrowing the gap between RGB and multimodal data, we devise an alternative fusion strategy, which replaces each of the three channels of an RGB image with the depth-map channel and fuses them before feeding them into the transformer encoder. Moreover, the designed sample filtering module adds several subclasses for each expression and move the noisy samples to their corresponding subclasses, thus eliminating their disturbance on the network during the training stage. Extensive experiments demonstrate that our MFEViT outperforms state-of-the-art approaches with an accuracy of 90.83% on BU-3DFE and 90.28% on Bosphorus. Specifically, the proposed MFEViT is a lightweight model, requiring much fewer parameters than multi-branch CNNs. To the best of our knowledge, this is the first work to introduce vision transformer into multimodal 2D+3D FER. The source code of our MFEViT will be publicly available online.
Matchable Image Retrieval by Learning from Surface Reconstruction
Dec 10, 2018

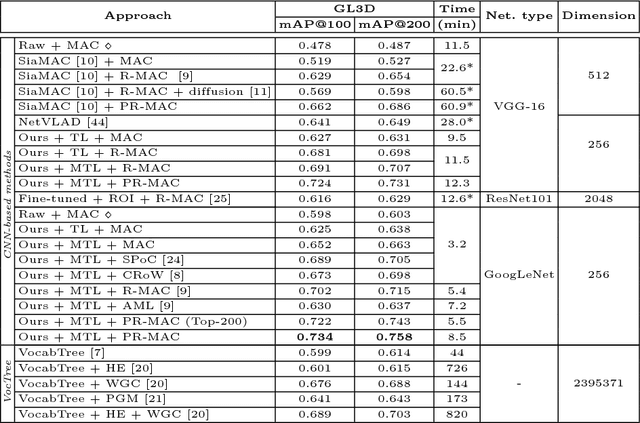
Convolutional Neural Networks (CNNs) have achieved superior performance on object image retrieval, while Bag-of-Words (BoW) models with handcrafted local features still dominate the retrieval of overlapping images in 3D reconstruction. In this paper, we narrow down this gap by presenting an efficient CNN-based method to retrieve images with overlaps, which we refer to as the matchable image retrieval problem. Different from previous methods that generates training data based on sparse reconstruction, we create a large-scale image database with rich 3D geometrics and exploit information from surface reconstruction to obtain fine-grained training data. We propose a batched triplet-based loss function combined with mesh re-projection to effectively learn the CNN representation. The proposed method significantly accelerates the image retrieval process in 3D reconstruction and outperforms the state-of-the-art CNN-based and BoW methods for matchable image retrieval. The code and data are available at https://github.com/hlzz/mirror.
Device-based Image Matching with Similarity Learning by Convolutional Neural Networks that Exploit the Underlying Camera Sensor Pattern Noise
Apr 23, 2020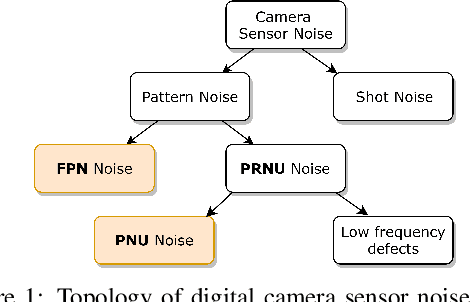
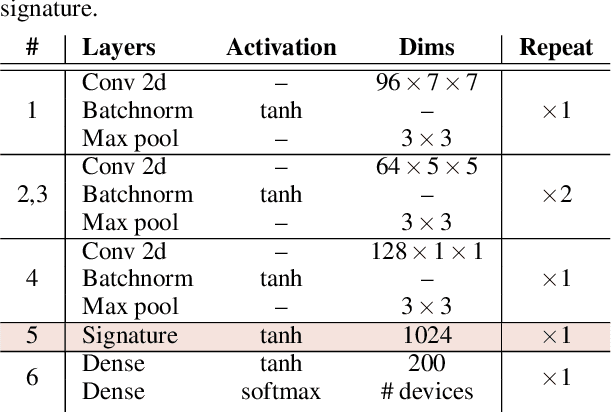
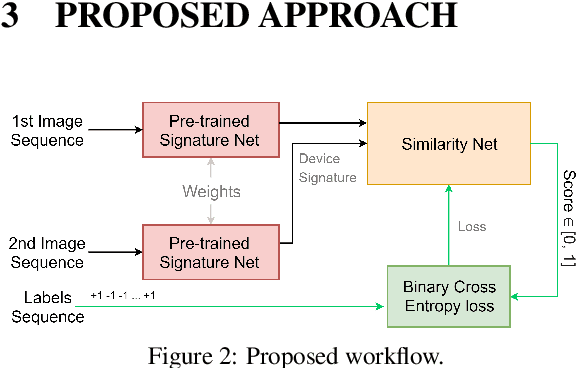
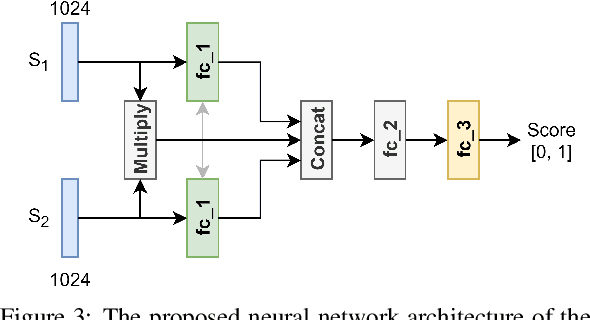
One of the challenging problems in digital image forensics is the capability to identify images that are captured by the same camera device. This knowledge can help forensic experts in gathering intelligence about suspects by analyzing digital images. In this paper, we propose a two-part network to quantify the likelihood that a given pair of images have the same source camera, and we evaluated it on the benchmark Dresden data set containing 1851 images from 31 different cameras. To the best of our knowledge, we are the first ones addressing the challenge of device-based image matching. Though the proposed approach is not yet forensics ready, our experiments show that this direction is worth pursuing, achieving at this moment 85 percent accuracy. This ongoing work is part of the EU-funded project 4NSEEK concerned with forensics against child sexual abuse.
* 7 pages, 4 figures, conference paper
P2T: Pyramid Pooling Transformer for Scene Understanding
Jun 22, 2021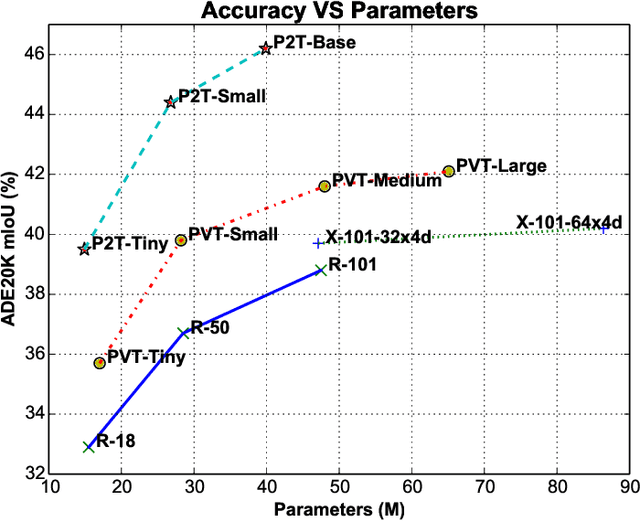
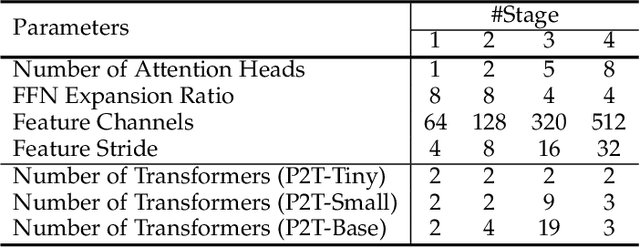
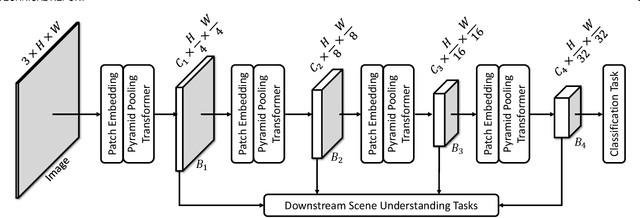
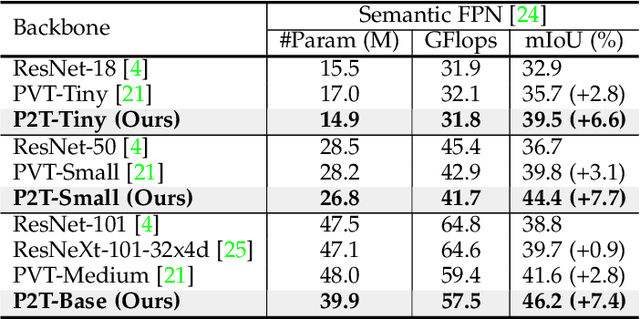
This paper jointly resolves two problems in vision transformer: i) the computation of Multi-Head Self-Attention (MHSA) has high computational/space complexity; ii) recent vision transformer networks are overly tuned for image classification, ignoring the difference between image classification (simple scenarios, more similar to NLP) and downstream scene understanding tasks (complicated scenarios, rich structural and contextual information). To this end, we note that pyramid pooling has been demonstrated to be effective in various vision tasks owing to its powerful context abstraction, and its natural property of spatial invariance is suitable to address the loss of structural information (problem ii)). Hence, we propose to adapt pyramid pooling to MHSA for alleviating its high requirement on computational resources (problem i)). In this way, this pooling-based MHSA can well address the above two problems and is thus flexible and powerful for downstream scene understanding tasks. Plugged with our pooling-based MHSA, we build a downstream-task-oriented transformer network, dubbed Pyramid Pooling Transformer (P2T). Extensive experiments demonstrate that, when applied P2T as the backbone network, it shows substantial superiority in various downstream scene understanding tasks such as semantic segmentation, object detection, instance segmentation, and visual saliency detection, compared to previous CNN- and transformer-based networks. The code will be released at https://github.com/yuhuan-wu/P2T. Note that this technical report will keep updating.
Densely-Populated Traffic Detection using YOLOv5 and Non-Maximum Suppression Ensembling
Aug 27, 2021Vehicular object detection is the heart of any intelligent traffic system. It is essential for urban traffic management. R-CNN, Fast R-CNN, Faster R-CNN and YOLO were some of the earlier state-of-the-art models. Region based CNN methods have the problem of higher inference time which makes it unrealistic to use the model in real-time. YOLO on the other hand struggles to detect small objects that appear in groups. In this paper, we propose a method that can locate and classify vehicular objects from a given densely crowded image using YOLOv5. The shortcoming of YOLO was solved my ensembling 4 different models. Our proposed model performs well on images taken from both top view and side view of the street in both day and night. The performance of our proposed model was measured on Dhaka AI dataset which contains densely crowded vehicular images. Our experiment shows that our model achieved mAP@0.5 of 0.458 with inference time of 0.75 sec which outperforms other state-of-the-art models on performance. Hence, the model can be implemented in the street for real-time traffic detection which can be used for traffic control and data collection.
Semi-supervised learning of images with strong rotational disorder: assembling nanoparticle libraries
May 24, 2021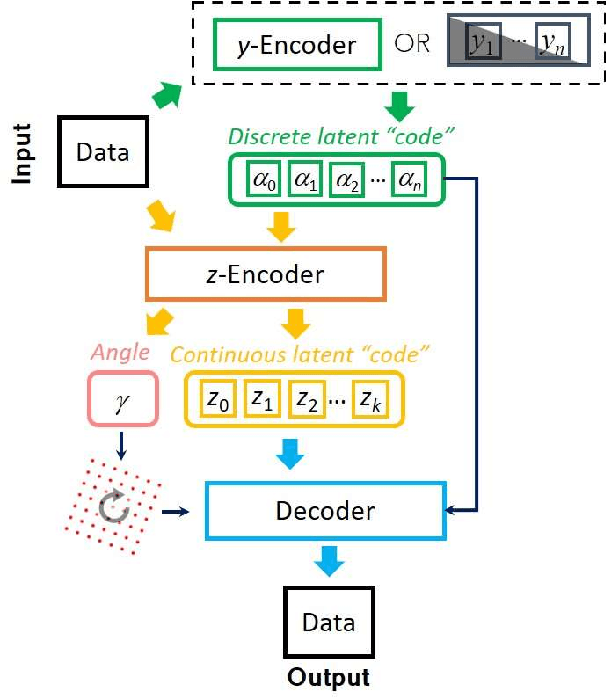
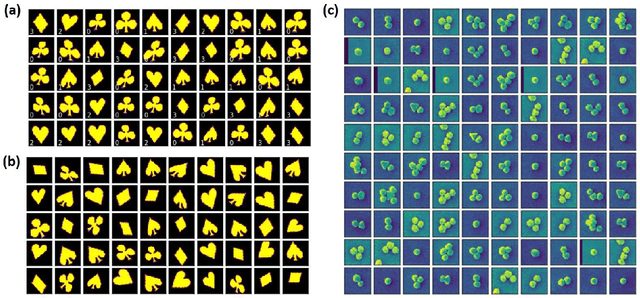
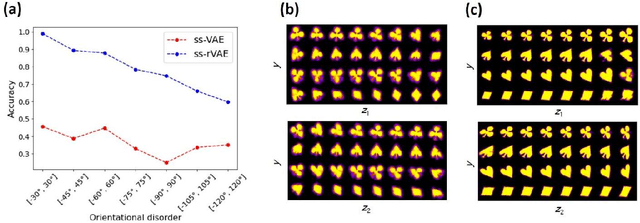
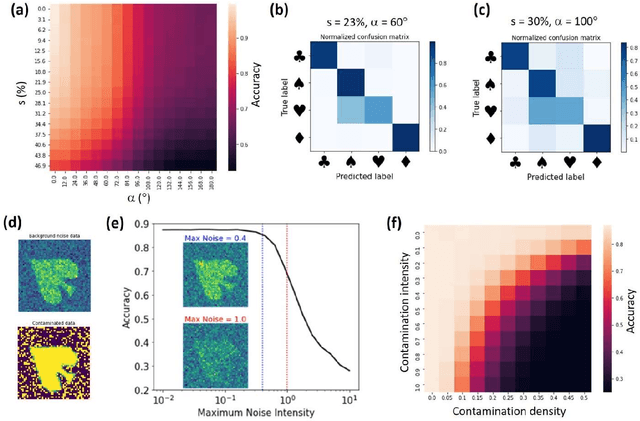
The proliferation of optical, electron, and scanning probe microscopies gives rise to large volumes of imaging data of objects as diversified as cells, bacteria, pollen, to nanoparticles and atoms and molecules. In most cases, the experimental data streams contain images having arbitrary rotations and translations within the image. At the same time, for many cases, small amounts of labeled data are available in the form of prior published results, image collections, and catalogs, or even theoretical models. Here we develop an approach that allows generalizing from a small subset of labeled data with a weak orientational disorder to a large unlabeled dataset with a much stronger orientational (and positional) disorder, i.e., it performs a classification of image data given a small number of examples even in the presence of a distribution shift between the labeled and unlabeled parts. This approach is based on the semi-supervised rotationally invariant variational autoencoder (ss-rVAE) model consisting of the encoder-decoder "block" that learns a rotationally (and translationally) invariant continuous latent representation of data and a classifier that encodes data into a finite number of discrete classes. The classifier part of the trained ss-rVAE inherits the rotational (and translational) invariances and can be deployed independently of the other parts of the model. The performance of the ss-rVAE is illustrated using the synthetic data sets with known factors of variation. We further demonstrate its application for experimental data sets of nanoparticles, creating nanoparticle libraries and disentangling the representations defining the physical factors of variation in the data. The code reproducing the results is available at https://github.com/ziatdinovmax/Semi-Supervised-VAE-nanoparticles.
Adversarial Framing for Image and Video Classification
Dec 11, 2018



Neural networks are prone to adversarial attacks. In general, such attacks deteriorate the quality of the input by either slightly modifying most of its pixels, or by occluding it with a patch. In this paper, we propose a method that keeps the image unchanged and only adds an adversarial framing on the border of the image. We show empirically that our method is able to successfully attack state-of-the-art methods on both image and video classification problems. Notably, the proposed method results in a universal attack which is very fast at test time. Source code can be found at https://github.com/zajaczajac/adv_framing .
Towards Robust Object Detection: Bayesian RetinaNet for Homoscedastic Aleatoric Uncertainty Modeling
Aug 02, 2021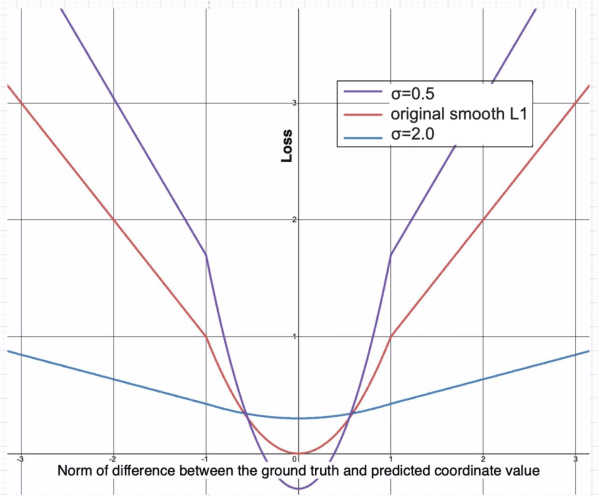
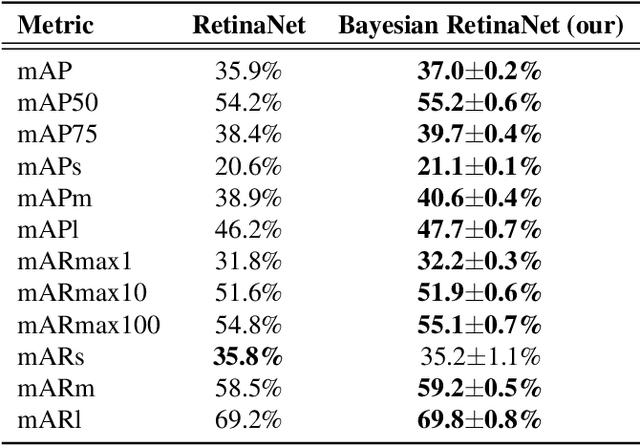
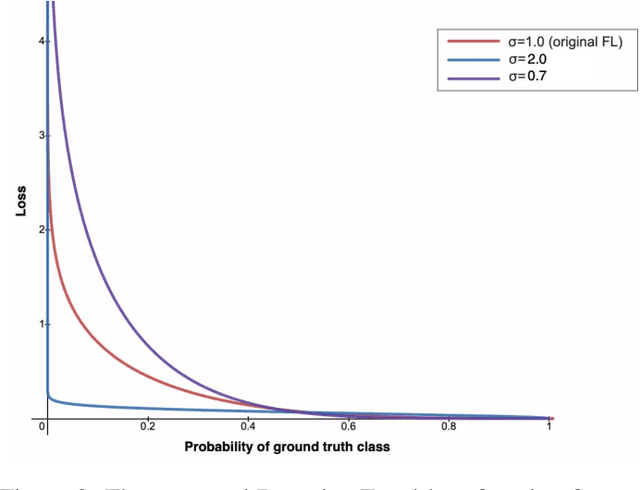
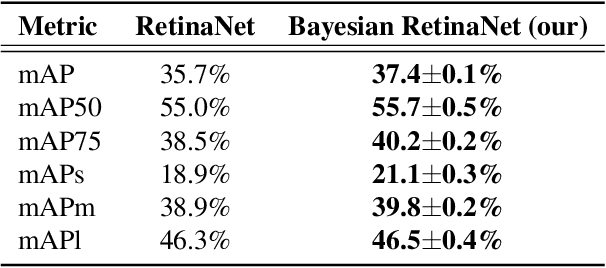
According to recent studies, commonly used computer vision datasets contain about 4% of label errors. For example, the COCO dataset is known for its high level of noise in data labels, which limits its use for training robust neural deep architectures in a real-world scenario. To model such a noise, in this paper we have proposed the homoscedastic aleatoric uncertainty estimation, and present a series of novel loss functions to address the problem of image object detection at scale. Specifically, the proposed functions are based on Bayesian inference and we have incorporated them into the common community-adopted object detection deep learning architecture RetinaNet. We have also shown that modeling of homoscedastic aleatoric uncertainty using our novel functions allows to increase the model interpretability and to improve the object detection performance being evaluated on the COCO dataset.
Self-Supervised Intrinsic Image Decomposition
Feb 05, 2018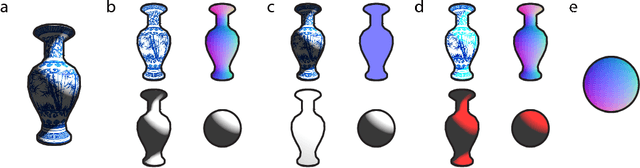
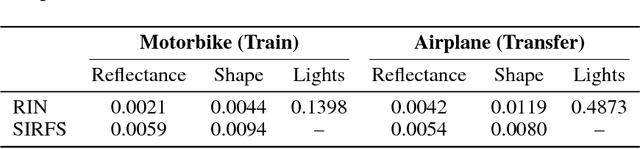
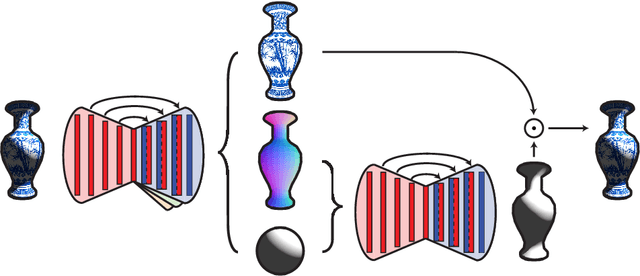

Intrinsic decomposition from a single image is a highly challenging task, due to its inherent ambiguity and the scarcity of training data. In contrast to traditional fully supervised learning approaches, in this paper we propose learning intrinsic image decomposition by explaining the input image. Our model, the Rendered Intrinsics Network (RIN), joins together an image decomposition pipeline, which predicts reflectance, shape, and lighting conditions given a single image, with a recombination function, a learned shading model used to recompose the original input based off of intrinsic image predictions. Our network can then use unsupervised reconstruction error as an additional signal to improve its intermediate representations. This allows large-scale unlabeled data to be useful during training, and also enables transferring learned knowledge to images of unseen object categories, lighting conditions, and shapes. Extensive experiments demonstrate that our method performs well on both intrinsic image decomposition and knowledge transfer.
JSSR: A Joint Synthesis, Segmentation, and Registration System for 3D Multi-Modal Image Alignment of Large-scale Pathological CT Scans
May 27, 2020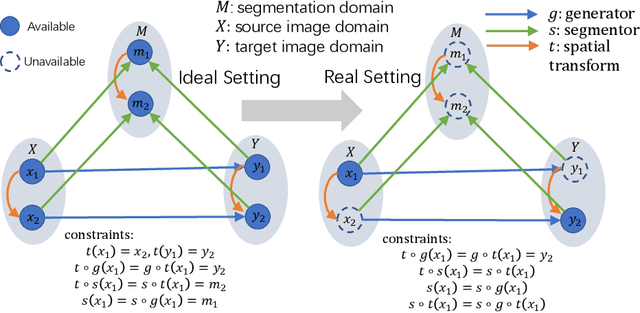
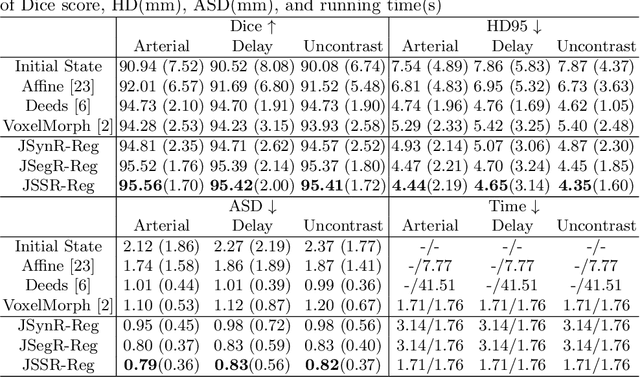
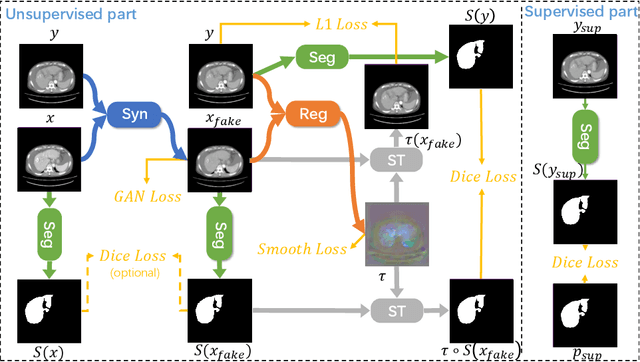
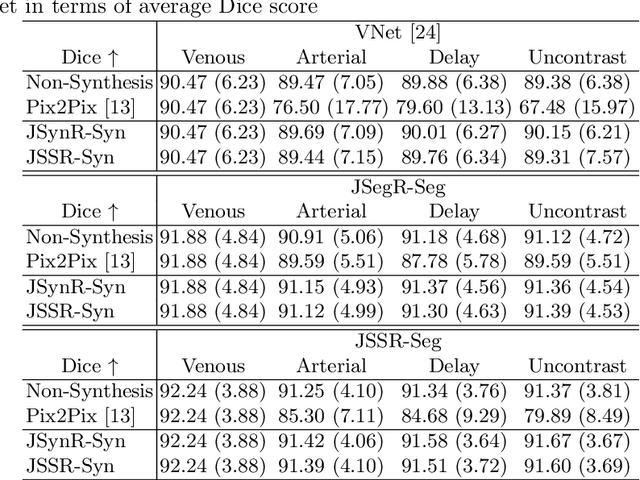
Multi-modal image registration is a challenging problem yet important clinical task in many real applications and scenarios. For medical imaging based diagnosis, deformable registration among different image modalities is often required in order to provide complementary visual information, as the first step. During the registration, the semantic information is the key to match homologous points and pixels. Nevertheless, many conventional registration methods are incapable to capture the high-level semantic anatomical dense correspondences. In this work, we propose a novel multi-task learning system, JSSR, based on an end-to-end 3D convolutional neural network that is composed of a generator, a register and a segmentor, for the tasks of synthesis, registration and segmentation, respectively. This system is optimized to satisfy the implicit constraints between different tasks unsupervisedly. It first synthesizes the source domain images into the target domain, then an intra-modal registration is applied on the synthesized images and target images. Then we can get the semantic segmentation by applying segmentors on the synthesized images and target images, which are aligned by the same deformation field generated by the registers. The supervision from another fully-annotated dataset is used to regularize the segmentors. We extensively evaluate our JSSR system on a large-scale medical image dataset containing 1,485 patient CT imaging studies of four different phases (i.e., 5,940 3D CT scans with pathological livers) on the registration, segmentation and synthesis tasks. The performance is improved after joint training on the registration and segmentation tasks by 0.9% and 1.9% respectively from a highly competitive and accurate baseline. The registration part also consistently outperforms the conventional state-of-the-art multi-modal registration methods.