 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generalized People Diversity: Learning a Human Perception-Aligned Diversity Representation for People Images
Jan 25, 2024
Capturing the diversity of people in images is challenging: recent literature tends to focus on diversifying one or two attributes, requiring expensive attribute labels or building classifiers. We introduce a diverse people image ranking method which more flexibly aligns with human notions of people diversity in a less prescriptive, label-free manner. The Perception-Aligned Text-derived Human representation Space (PATHS) aims to capture all or many relevant features of people-related diversity, and, when used as the representation space in the standard Maximal Marginal Relevance (MMR) ranking algorithm, is better able to surface a range of types of people-related diversity (e.g. disability, cultural attire). PATHS is created in two stages. First, a text-guided approach is used to extract a person-diversity representation from a pre-trained image-text model. Then this representation is fine-tuned on perception judgments from human annotators so that it captures the aspects of people-related similarity that humans find most salient. Empirical results show that the PATHS method achieves diversity better than baseline methods, according to side-by-side ratings from human annotators.
Zero-shot Classification using Hyperdimensional Computing
Jan 30, 2024Classification based on Zero-shot Learning (ZSL) is the ability of a model to classify inputs into novel classes on which the model has not previously seen any training examples. Providing an auxiliary descriptor in the form of a set of attributes describing the new classes involved in the ZSL-based classification is one of the favored approaches to solving this challenging task. In this work, inspired by Hyperdimensional Computing (HDC), we propose the use of stationary binary codebooks of symbol-like distributed representations inside an attribute encoder to compactly represent a computationally simple end-to-end trainable model, which we name Hyperdimensional Computing Zero-shot Classifier~(HDC-ZSC). It consists of a trainable image encoder, an attribute encoder based on HDC, and a similarity kernel. We show that HDC-ZSC can be used to first perform zero-shot attribute extraction tasks and, can later be repurposed for Zero-shot Classification tasks with minimal architectural changes and minimal model retraining. HDC-ZSC achieves Pareto optimal results with a 63.8% top-1 classification accuracy on the CUB-200 dataset by having only 26.6 million trainable parameters. Compared to two other state-of-the-art non-generative approaches, HDC-ZSC achieves 4.3% and 9.9% better accuracy, while they require more than 1.85x and 1.72x parameters compared to HDC-ZSC, respectively.
Study of the gOMP Algorithm for Recovery of Compressed Sensed Hyperspectral Images
Jan 26, 2024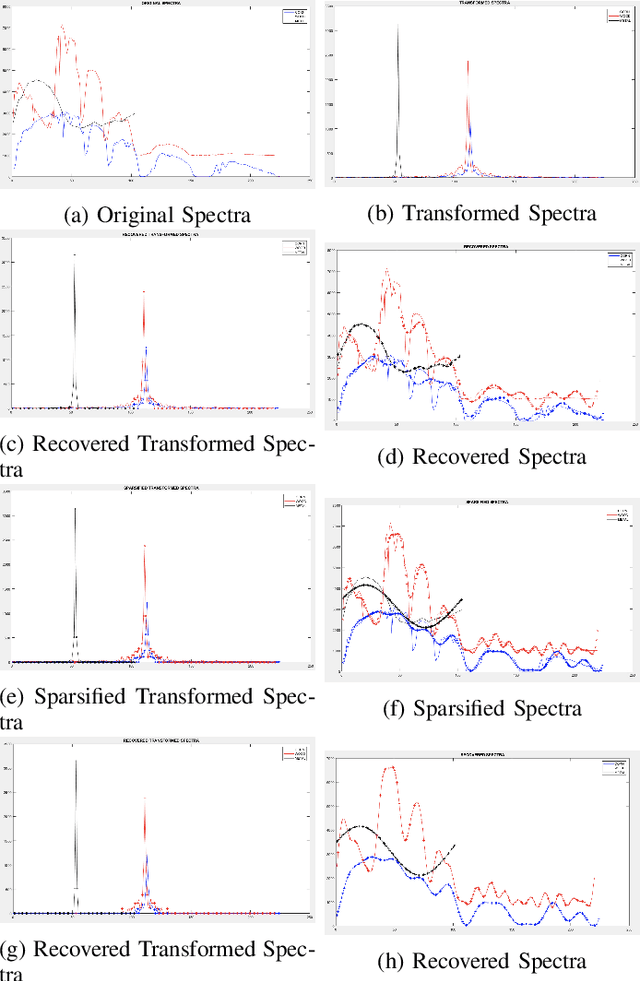


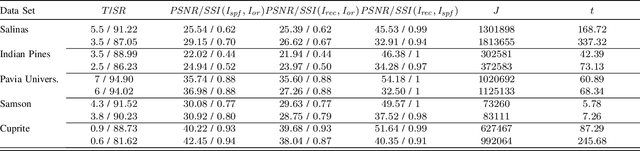
Hyperspectral Imaging (HSI) is used in a wide range of applications such as remote sensing, yet the transmission of the HS images by communication data links becomes challenging due to the large number of spectral bands that the HS images contain together with the limited data bandwidth available in real applications. Compressive Sensing reduces the images by randomly subsampling the spectral bands of each spatial pixel and then it performs the image reconstruction of all the bands using recovery algorithms which impose sparsity in a certain transform domain. Since the image pixels are not strictly sparse, this work studies a data sparsification pre-processing stage prior to compression to ensure the sparsity of the pixels. The sparsified images are compressed $2.5\times$ and then recovered using the Generalized Orthogonal Matching Pursuit algorithm (gOMP) characterized by high accuracy, low computational requirements and fast convergence. The experiments are performed in five conventional hyperspectral images where the effect of different sparsification levels in the quality of the uncompressed as well as the recovered images is studied. It is concluded that the gOMP algorithm reconstructs the hyperspectral images with higher accuracy as well as faster convergence when the pixels are highly sparsified and hence at the expense of reducing the quality of the recovered images with respect to the original images.
Bilateral Reference for High-Resolution Dichotomous Image Segmentation
Jan 07, 2024We introduce a novel bilateral reference framework (***BiRefNet***) for high-resolution dichotomous image segmentation (DIS). It comprises two essential components: the localization module (LM) and the reconstruction module (RM) with our proposed bilateral reference (BiRef). The LM aids in object localization using global semantic information. Within the RM, we utilize BiRef for the reconstruction process, where hierarchical patches of images provide the source reference and gradient maps serve as the target reference. These components collaborate to generate the final predicted maps. We also introduce auxiliary gradient supervision to enhance focus on regions with finer details. Furthermore, we outline practical training strategies tailored for DIS to improve map quality and training process. To validate the general applicability of our approach, we conduct extensive experiments on four tasks to evince that *BiRefNet* exhibits remarkable performance, outperforming task-specific cutting-edge methods across all benchmarks.
CycleGAN Models for MRI Image Translation
Dec 28, 2023Image-to-image translation has gained popularity in the medical field to transform images from one domain to another. Medical image synthesis via domain transformation is advantageous in its ability to augment an image dataset where images for a given class is limited. From the learning perspective, this process contributes to data-oriented robustness of the model by inherently broadening the model's exposure to more diverse visual data and enabling it to learn more generalized features. In the case of generating additional neuroimages, it is advantageous to obtain unidentifiable medical data and augment smaller annotated datasets. This study proposes the development of a CycleGAN model for translating neuroimages from one field strength to another (e.g., 3 Tesla to 1.5). This model was compared to a model based on DCGAN architecture. CycleGAN was able to generate the synthetic and reconstructed images with reasonable accuracy. The mapping function from the source (3 Tesla) to target domain (1.5 Tesla) performed optimally with an average PSNR value of 25.69 $\pm$ 2.49 dB and an MAE value of 2106.27 +/- 1218.37.
Do You Guys Want to Dance: Zero-Shot Compositional Human Dance Generation with Multiple Persons
Jan 24, 2024Human dance generation (HDG) aims to synthesize realistic videos from images and sequences of driving poses. Despite great success, existing methods are limited to generating videos of a single person with specific backgrounds, while the generalizability for real-world scenarios with multiple persons and complex backgrounds remains unclear. To systematically measure the generalizability of HDG models, we introduce a new task, dataset, and evaluation protocol of compositional human dance generation (cHDG). Evaluating the state-of-the-art methods on cHDG, we empirically find that they fail to generalize to real-world scenarios. To tackle the issue, we propose a novel zero-shot framework, dubbed MultiDance-Zero, that can synthesize videos consistent with arbitrary multiple persons and background while precisely following the driving poses. Specifically, in contrast to straightforward DDIM or null-text inversion, we first present a pose-aware inversion method to obtain the noisy latent code and initialization text embeddings, which can accurately reconstruct the composed reference image. Since directly generating videos from them will lead to severe appearance inconsistency, we propose a compositional augmentation strategy to generate augmented images and utilize them to optimize a set of generalizable text embeddings. In addition, consistency-guided sampling is elaborated to encourage the background and keypoints of the estimated clean image at each reverse step to be close to those of the reference image, further improving the temporal consistency of generated videos. Extensive qualitative and quantitative results demonstrate the effectiveness and superiority of our approach.
Dual-modal Dynamic Traceback Learning for Medical Report Generation
Jan 24, 2024With increasing reliance on medical imaging in clinical practices, automated report generation from medical images is in great demand. Existing report generation methods typically adopt an encoder-decoder deep learning framework to build a uni-directional image-to-report mapping. However, such a framework ignores the bi-directional mutual associations between images and reports, thus incurring difficulties in associating the intrinsic medical meanings between them. Recent generative representation learning methods have demonstrated the benefits of dual-modal learning from both image and text modalities. However, these methods exhibit two major drawbacks for medical report generation: 1) they tend to capture morphological information and have difficulties in capturing subtle pathological semantic information, and 2) they predict masked text rely on both unmasked images and text, inevitably degrading performance when inference is based solely on images. In this study, we propose a new report generation framework with dual-modal dynamic traceback learning (DTrace) to overcome the two identified drawbacks and enable dual-modal learning for medical report generation. To achieve this, our DTrace introduces a traceback mechanism to control the semantic validity of generated content via self-assessment. Further, our DTrace introduces a dynamic learning strategy to adapt to various proportions of image and text input, enabling report generation without reliance on textual input during inference. Extensive experiments on two well-benchmarked datasets (IU-Xray and MIMIC-CXR) show that our DTrace outperforms state-of-the-art medical report generation methods.
Optimizing contrastive learning for cortical folding pattern detection
Jan 31, 2024The human cerebral cortex has many bumps and grooves called gyri and sulci. Even though there is a high inter-individual consistency for the main cortical folds, this is not the case when we examine the exact shapes and details of the folding patterns. Because of this complexity, characterizing the cortical folding variability and relating them to subjects' behavioral characteristics or pathologies is still an open scientific problem. Classical approaches include labeling a few specific patterns, either manually or semi-automatically, based on geometric distances, but the recent availability of MRI image datasets of tens of thousands of subjects makes modern deep-learning techniques particularly attractive. Here, we build a self-supervised deep-learning model to detect folding patterns in the cingulate region. We train a contrastive self-supervised model (SimCLR) on both Human Connectome Project (1101 subjects) and UKBioBank (21070 subjects) datasets with topological-based augmentations on the cortical skeletons, which are topological objects that capture the shape of the folds. We explore several backbone architectures (convolutional network, DenseNet, and PointNet) for the SimCLR. For evaluation and testing, we perform a linear classification task on a database manually labeled for the presence of the "double-parallel" folding pattern in the cingulate region, which is related to schizophrenia characteristics. The best model, giving a test AUC of 0.76, is a convolutional network with 6 layers, a 10-dimensional latent space, a linear projection head, and using the branch-clipping augmentation. This is the first time that a self-supervised deep learning model has been applied to cortical skeletons on such a large dataset and quantitatively evaluated. We can now envisage the next step: applying it to other brain regions to detect other biomarkers.
New Job, New Gender? Measuring the Social Bias in Image Generation Models
Jan 01, 2024Image generation models can generate or edit images from a given text. Recent advancements in image generation technology, exemplified by DALL-E and Midjourney, have been groundbreaking. These advanced models, despite their impressive capabilities, are often trained on massive Internet datasets, making them susceptible to generating content that perpetuates social stereotypes and biases, which can lead to severe consequences. Prior research on assessing bias within image generation models suffers from several shortcomings, including limited accuracy, reliance on extensive human labor, and lack of comprehensive analysis. In this paper, we propose BiasPainter, a novel metamorphic testing framework that can accurately, automatically and comprehensively trigger social bias in image generation models. BiasPainter uses a diverse range of seed images of individuals and prompts the image generation models to edit these images using gender, race, and age-neutral queries. These queries span 62 professions, 39 activities, 57 types of objects, and 70 personality traits. The framework then compares the edited images to the original seed images, focusing on any changes related to gender, race, and age. BiasPainter adopts a testing oracle that these characteristics should not be modified when subjected to neutral prompts. Built upon this design, BiasPainter can trigger the social bias and evaluate the fairness of image generation models. To evaluate the effectiveness of BiasPainter, we use BiasPainter to test five widely-used commercial image generation software and models, such as stable diffusion and Midjourney. Experimental results show that 100\% of the generated test cases can successfully trigger social bias in image generation models.
HiCD: Change Detection in Quality-Varied Images via Hierarchical Correlation Distillation
Jan 19, 2024Advanced change detection techniques primarily target image pairs of equal and high quality. However, variations in imaging conditions and platforms frequently lead to image pairs with distinct qualities: one image being high-quality, while the other being low-quality. These disparities in image quality present significant challenges for understanding image pairs semantically and extracting change features, ultimately resulting in a notable decline in performance. To tackle this challenge, we introduce an innovative training strategy grounded in knowledge distillation. The core idea revolves around leveraging task knowledge acquired from high-quality image pairs to guide the model's learning process when dealing with image pairs that exhibit differences in quality. Additionally, we develop a hierarchical correlation distillation approach (involving self-correlation, cross-correlation, and global correlation). This approach compels the student model to replicate the correlations inherent in the teacher model, rather than focusing solely on individual features. This ensures effective knowledge transfer while maintaining the student model's training flexibility.