 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The potential of self-supervised networks for random noise suppression in seismic data
Sep 15, 2021
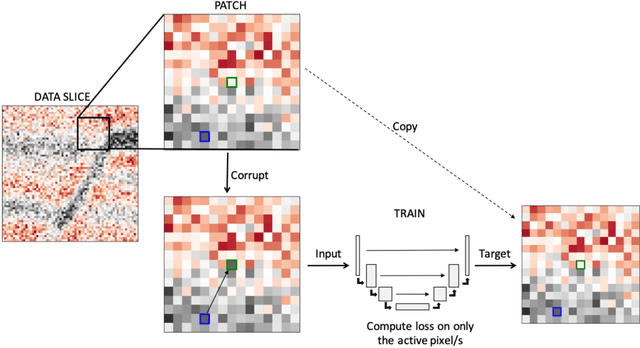
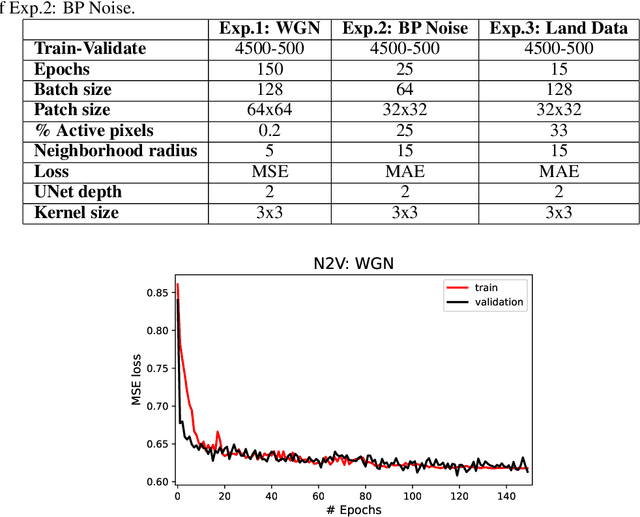
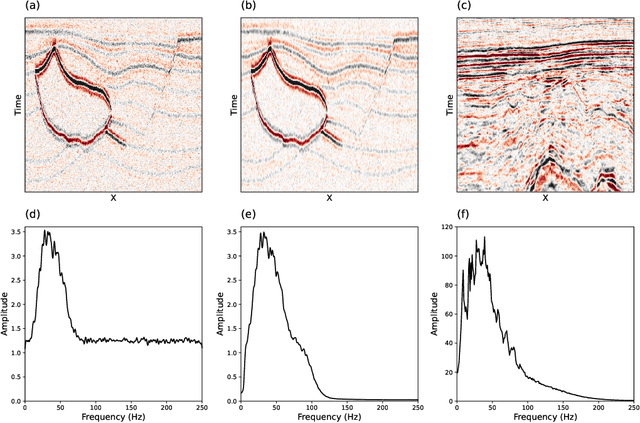
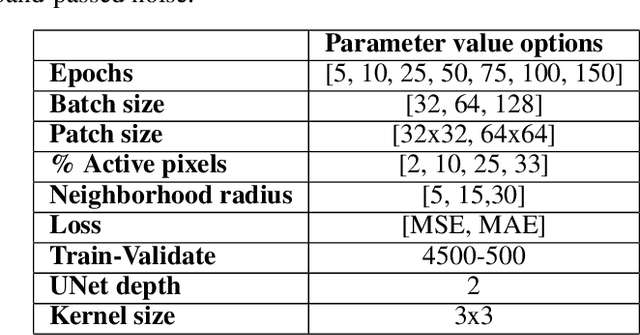
Noise suppression is an essential step in any seismic processing workflow. A portion of this noise, particularly in land datasets, presents itself as random noise. In recent years, neural networks have been successfully used to denoise seismic data in a supervised fashion. However, supervised learning always comes with the often unachievable requirement of having noisy-clean data pairs for training. Using blind-spot networks, we redefine the denoising task as a self-supervised procedure where the network uses the surrounding noisy samples to estimate the noise-free value of a central sample. Based on the assumption that noise is statistically independent between samples, the network struggles to predict the noise component of the sample due to its randomnicity, whilst the signal component is accurately predicted due to its spatio-temporal coherency. Illustrated on synthetic examples, the blind-spot network is shown to be an efficient denoiser of seismic data contaminated by random noise with minimal damage to the signal; therefore, providing improvements in both the image domain and down-the-line tasks, such as inversion. To conclude the study, the suggested approach is applied to field data and the results are compared with two commonly used random denoising techniques: FX-deconvolution and Curvelet transform. By demonstrating that blind-spot networks are an efficient suppressor of random noise, we believe this is just the beginning of utilising self-supervised learning in seismic applications.
Scene Graph Embeddings Using Relative Similarity Supervision
Apr 06, 2021
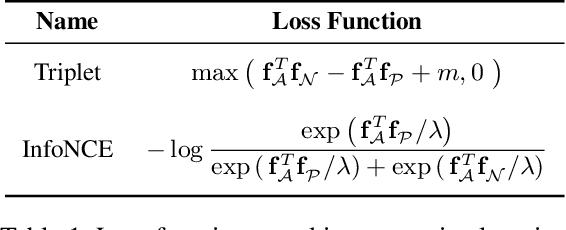
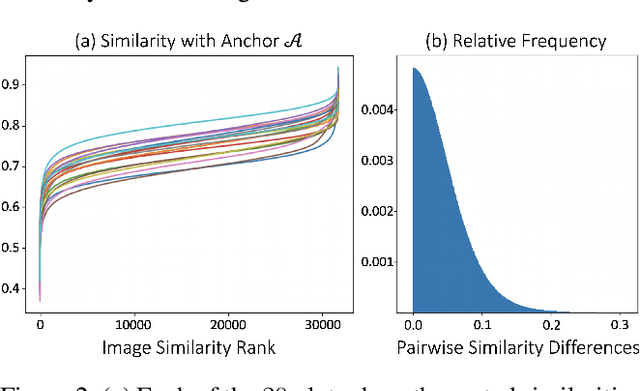
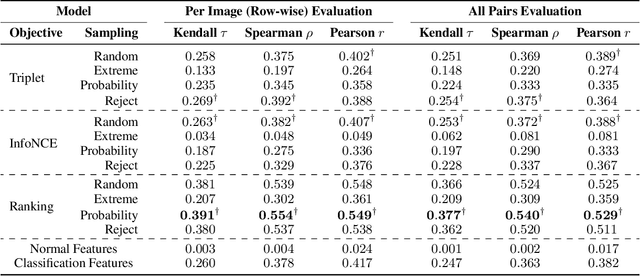
Scene graphs are a powerful structured representation of the underlying content of images, and embeddings derived from them have been shown to be useful in multiple downstream tasks. In this work, we employ a graph convolutional network to exploit structure in scene graphs and produce image embeddings useful for semantic image retrieval. Different from classification-centric supervision traditionally available for learning image representations, we address the task of learning from relative similarity labels in a ranking context. Rooted within the contrastive learning paradigm, we propose a novel loss function that operates on pairs of similar and dissimilar images and imposes relative ordering between them in embedding space. We demonstrate that this Ranking loss, coupled with an intuitive triple sampling strategy, leads to robust representations that outperform well-known contrastive losses on the retrieval task. In addition, we provide qualitative evidence of how retrieved results that utilize structured scene information capture the global context of the scene, different from visual similarity search.
Disentangled Person Image Generation
Jun 15, 2018
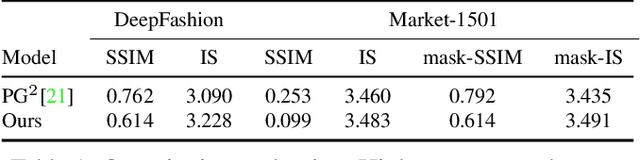
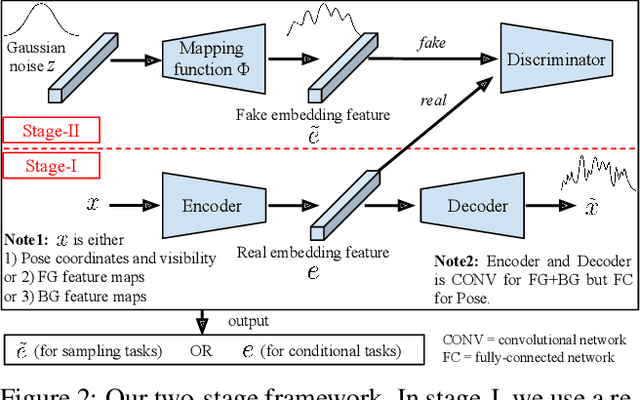
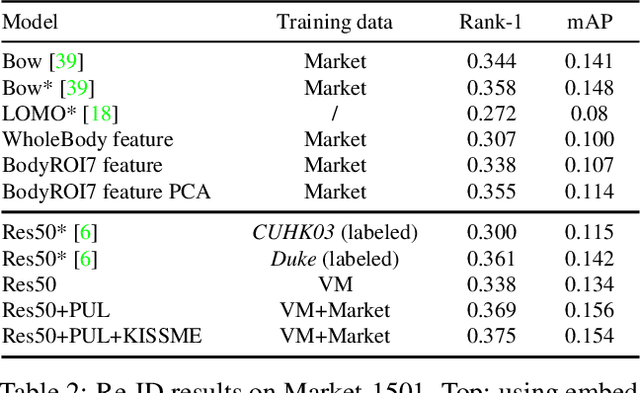
Generating novel, yet realistic, images of persons is a challenging task due to the complex interplay between the different image factors, such as the foreground, background and pose information. In this work, we aim at generating such images based on a novel, two-stage reconstruction pipeline that learns a disentangled representation of the aforementioned image factors and generates novel person images at the same time. First, a multi-branched reconstruction network is proposed to disentangle and encode the three factors into embedding features, which are then combined to re-compose the input image itself. Second, three corresponding mapping functions are learned in an adversarial manner in order to map Gaussian noise to the learned embedding feature space, for each factor respectively. Using the proposed framework, we can manipulate the foreground, background and pose of the input image, and also sample new embedding features to generate such targeted manipulations, that provide more control over the generation process. Experiments on Market-1501 and Deepfashion datasets show that our model does not only generate realistic person images with new foregrounds, backgrounds and poses, but also manipulates the generated factors and interpolates the in-between states. Another set of experiments on Market-1501 shows that our model can also be beneficial for the person re-identification task.
Y-net: Multi-scale feature aggregation network with wavelet structure similarity loss function for single image dehazing
Mar 31, 2020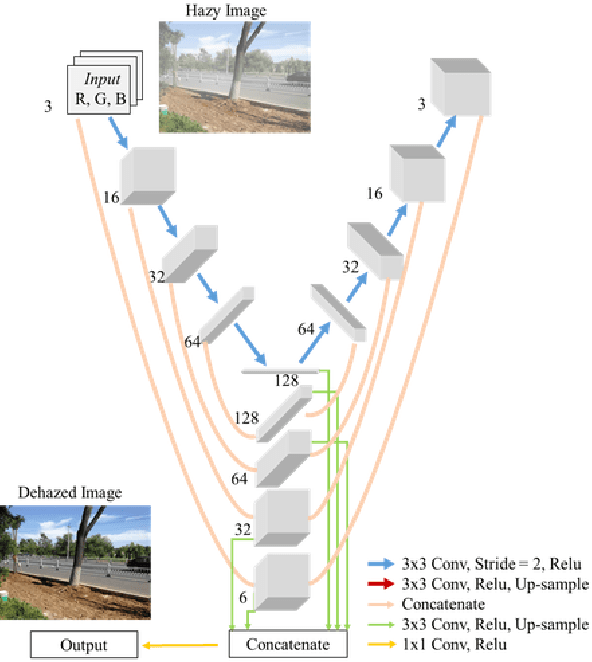
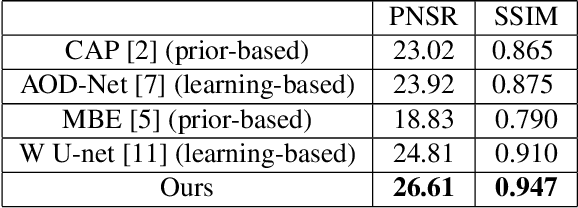
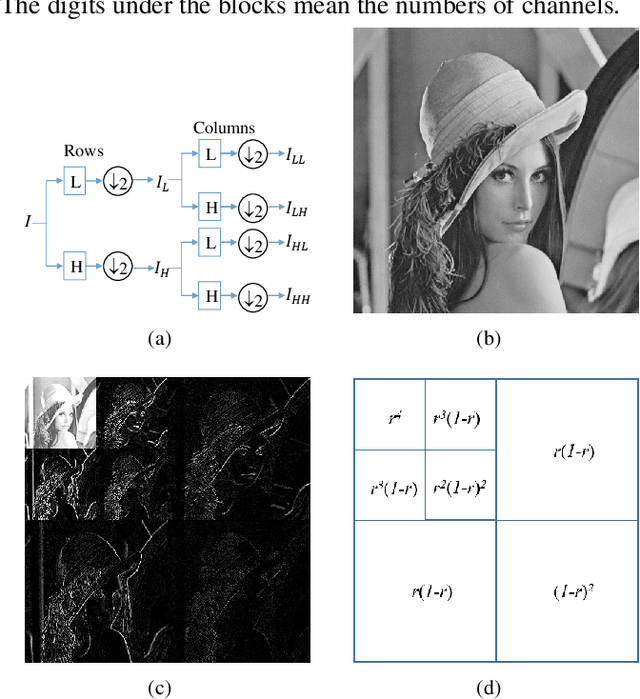
Single image dehazing is the ill-posed two-dimensional signal reconstruction problem. Recently, deep convolutional neural networks (CNN) have been successfully used in many computer vision problems. In this paper, we propose a Y-net that is named for its structure. This network reconstructs clear images by aggregating multi-scale features maps. Additionally, we propose a Wavelet Structure SIMilarity (W-SSIM) loss function in the training step. In the proposed loss function, discrete wavelet transforms are applied repeatedly to divide the image into differently sized patches with different frequencies and scales. The proposed loss function is the accumulation of SSIM loss of various patches with respective ratios. Extensive experimental results demonstrate that the proposed Y-net with the W-SSIM loss function restores high-quality clear images and outperforms state-of-the-art algorithms. Code and models are available at https://github.com/dectrfov/Y-net.
TextStyleBrush: Transfer of Text Aesthetics from a Single Example
Jun 15, 2021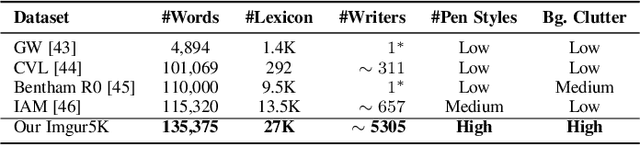

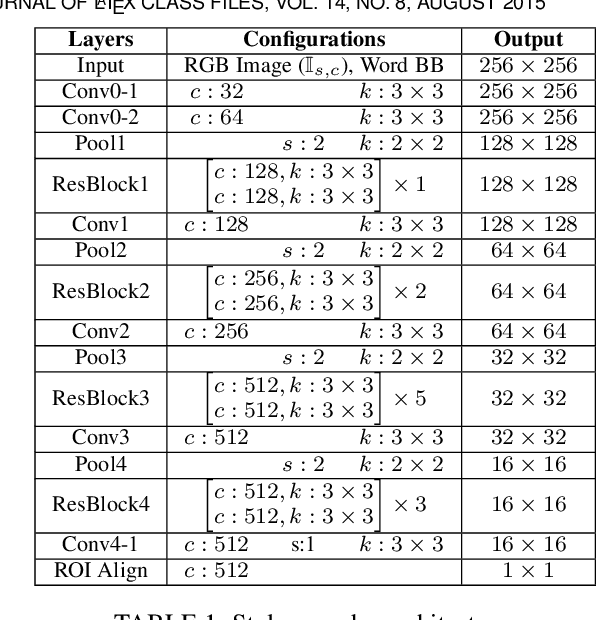
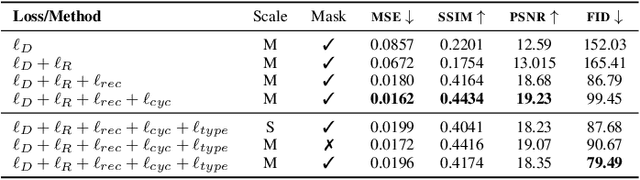
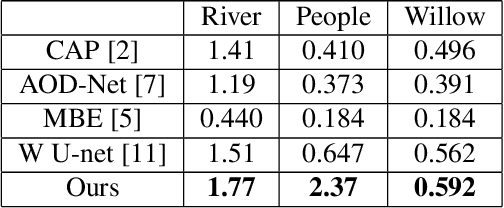
We present a novel approach for disentangling the content of a text image from all aspects of its appearance. The appearance representation we derive can then be applied to new content, for one-shot transfer of the source style to new content. We learn this disentanglement in a self-supervised manner. Our method processes entire word boxes, without requiring segmentation of text from background, per-character processing, or making assumptions on string lengths. We show results in different text domains which were previously handled by specialized methods, e.g., scene text, handwritten text. To these ends, we make a number of technical contributions: (1) We disentangle the style and content of a textual image into a non-parametric, fixed-dimensional vector. (2) We propose a novel approach inspired by StyleGAN but conditioned over the example style at different resolution and content. (3) We present novel self-supervised training criteria which preserve both source style and target content using a pre-trained font classifier and text recognizer. Finally, (4) we also introduce Imgur5K, a new challenging dataset for handwritten word images. We offer numerous qualitative photo-realistic results of our method. We further show that our method surpasses previous work in quantitative tests on scene text and handwriting datasets, as well as in a user study.
Controlled GAN-Based Creature Synthesis via a Challenging Game Art Dataset -- Addressing the Noise-Latent Trade-Off
Aug 19, 2021


The state-of-the-art StyleGAN2 network supports powerful methods to create and edit art, including generating random images, finding images "like" some query, and modifying content or style. Further, recent advancements enable training with small datasets. We apply these methods to synthesize card art, by training on a novel Yu-Gi-Oh dataset. While noise inputs to StyleGAN2 are essential for good synthesis, we find that, for small datasets, coarse-scale noise interferes with latent variables because both control long-scale image effects. We observe over-aggressive variation in art with changes in noise and weak content control via latent variable edits. Here, we demonstrate that training a modified StyleGAN2, where coarse-scale noise is suppressed, removes these unwanted effects. We obtain a superior FID; changes in noise result in local exploration of style; and identity control is markedly improved. These results and analysis lead towards a GAN-assisted art synthesis tool for digital artists of all skill levels, which can be used in film, games, or any creative industry for artistic ideation.
United We Learn Better: Harvesting Learning Improvements From Class Hierarchies Across Tasks
Jul 28, 2021


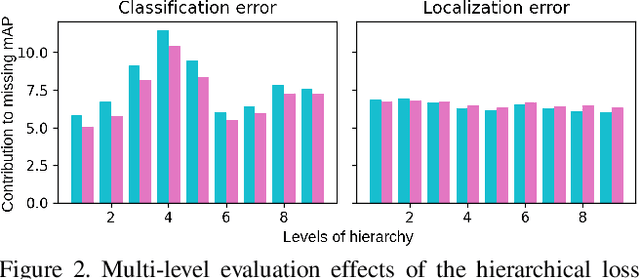
Attempts of learning from hierarchical taxonomies in computer vision have been mostly focusing on image classification. Though ways of best harvesting learning improvements from hierarchies in classification are far from being solved, there is a need to target these problems in other vision tasks such as object detection. As progress on the classification side is often dependent on hierarchical cross-entropy losses, novel detection architectures using sigmoid as an output function instead of softmax cannot easily apply these advances, requiring novel methods in detection. In this work we establish a theoretical framework based on probability and set theory for extracting parent predictions and a hierarchical loss that can be used across tasks, showing results across classification and detection benchmarks and opening up the possibility of hierarchical learning for sigmoid-based detection architectures.
Unconstrained Face Recognition using ASURF and Cloud-Forest Classifier optimized with VLAD
Apr 02, 2021



The paper posits a computationally-efficient algorithm for multi-class facial image classification in which images are constrained with translation, rotation, scale, color, illumination and affine distortion. The proposed method is divided into five main building blocks including Haar-Cascade for face detection, Bilateral Filter for image preprocessing to remove unwanted noise, Affine Speeded-Up Robust Features (ASURF) for keypoint detection and description, Vector of Locally Aggregated Descriptors (VLAD) for feature quantization and Cloud Forest for image classification. The proposed method aims at improving the accuracy and the time taken for face recognition systems. The usage of the Cloud Forest algorithm as a classifier on three benchmark datasets, namely the FACES95, FACES96 and ORL facial datasets, showed promising results. The proposed methodology using Cloud Forest algorithm successfully improves the recognition model by 2-12\% when differentiated against other ensemble techniques like the Random Forest classifier depending upon the dataset used.
* 8 Pages, 3 Figures
Divide and Contrast: Self-supervised Learning from Uncurated Data
May 17, 2021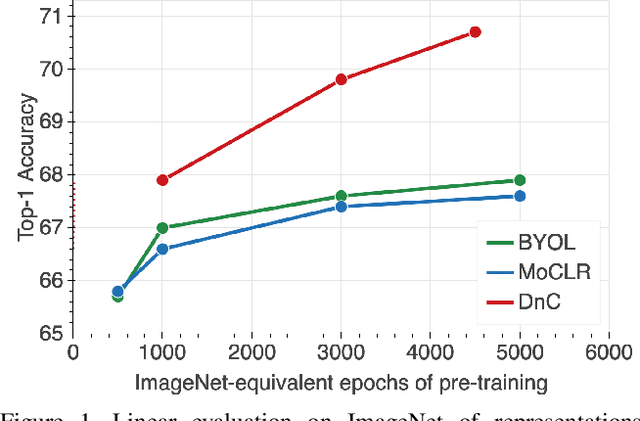
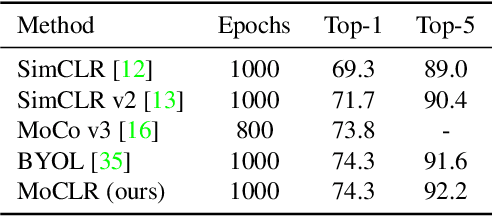
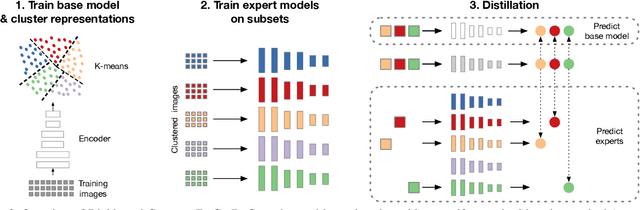
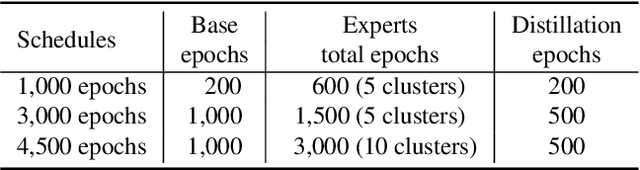
Self-supervised learning holds promise in leveraging large amounts of unlabeled data, however much of its progress has thus far been limited to highly curated pre-training data such as ImageNet. We explore the effects of contrastive learning from larger, less-curated image datasets such as YFCC, and find there is indeed a large difference in the resulting representation quality. We hypothesize that this curation gap is due to a shift in the distribution of image classes -- which is more diverse and heavy-tailed -- resulting in less relevant negative samples to learn from. We test this hypothesis with a new approach, Divide and Contrast (DnC), which alternates between contrastive learning and clustering-based hard negative mining. When pretrained on less curated datasets, DnC greatly improves the performance of self-supervised learning on downstream tasks, while remaining competitive with the current state-of-the-art on curated datasets.
BlinQS: Blind Quality Scalable Image Compression Algorithm without using PCRD Optimization
Apr 03, 2021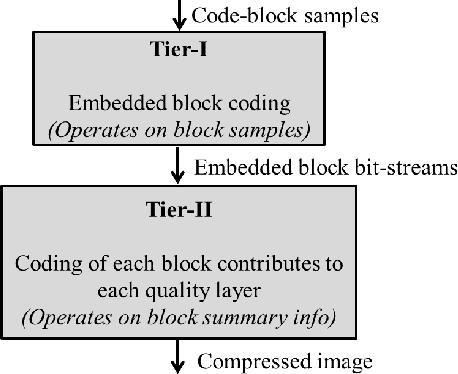



Quality Scalability is one of the important features of interactive imaging to obtain better perceptual quality at a specified target bit rate. In JPEG 2000, it is achieved using quality layers obtained by Rate-Distortion (R-D) optimization techniques in Tier-II coding. Some important concerns here are: (i) inefficient conventional Post-Compression Rate-Distortion (PCRD) optimization algorithms, (ii) lack of quality scalability for less or single quality layer string. This paper takes the above mentioned concerns into account and proposes a Blind Quality Scalable (BlinQS) algorithm that provides scalability with the least computational complexity. The novel part of this method is to eliminate the Tier-II coding and add a blind string selection algorithm through a normal distribution for efficient rate control. The results obtained suggest that the proposed method achieves better results than JPEG-2000 at single quality layer and achieves results close to JPEG-2000 without using PCRD optimization algorithms.