 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SDL: New data generation tools for full-level annotated document layout
Jun 29, 2021
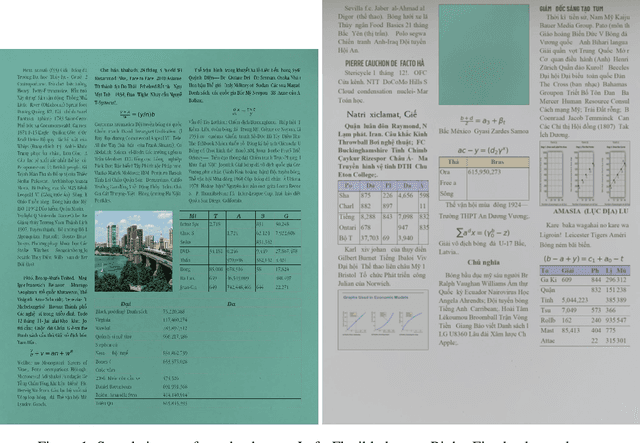
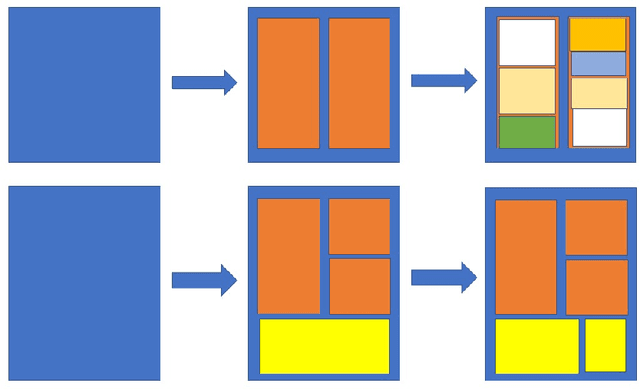
We present a novel data generation tool for document processing. The tool focuses on providing a maximal level of visual information in a normal type document, ranging from character position to paragraph-level position. It also enables working with a large dataset on low-resource languages as well as providing a mean of processing thorough full-level information of the documented text. The data generation tools come with a dataset of 320000 Vietnamese synthetic document images and an instruction to generate a dataset of similar size in other languages. The repository can be found at: https://github.com/tson1997/SDL-Document-Image-Generation
Multi-Label Gold Asymmetric Loss Correction with Single-Label Regulators
Aug 04, 2021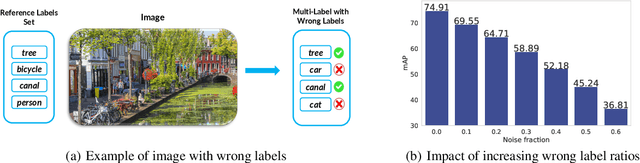
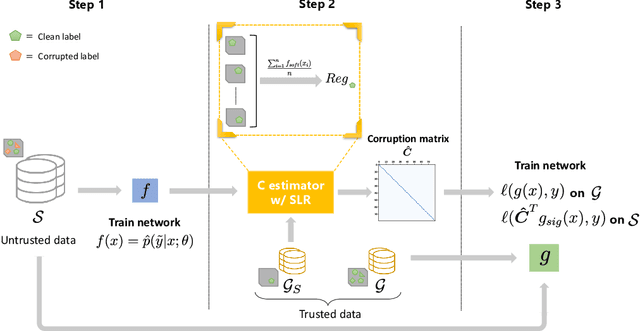
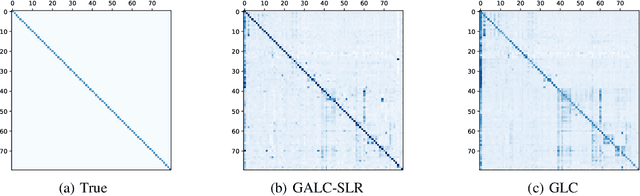
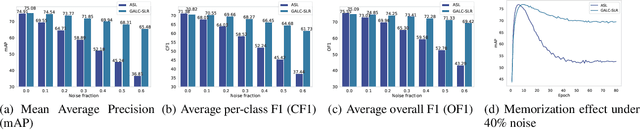
Multi-label learning is an emerging extension of the multi-class classification where an image contains multiple labels. Not only acquiring a clean and fully labeled dataset in multi-label learning is extremely expensive, but also many of the actual labels are corrupted or missing due to the automated or non-expert annotation techniques. Noisy label data decrease the prediction performance drastically. In this paper, we propose a novel Gold Asymmetric Loss Correction with Single-Label Regulators (GALC-SLR) that operates robust against noisy labels. GALC-SLR estimates the noise confusion matrix using single-label samples, then constructs an asymmetric loss correction via estimated confusion matrix to avoid overfitting to the noisy labels. Empirical results show that our method outperforms the state-of-the-art original asymmetric loss multi-label classifier under all corruption levels, showing mean average precision improvement up to 28.67% on a real world dataset of MS-COCO, yielding a better generalization of the unseen data and increased prediction performance.
Operational Learning-based Boundary Estimation in Electromagnetic Medical Imaging
Aug 04, 2021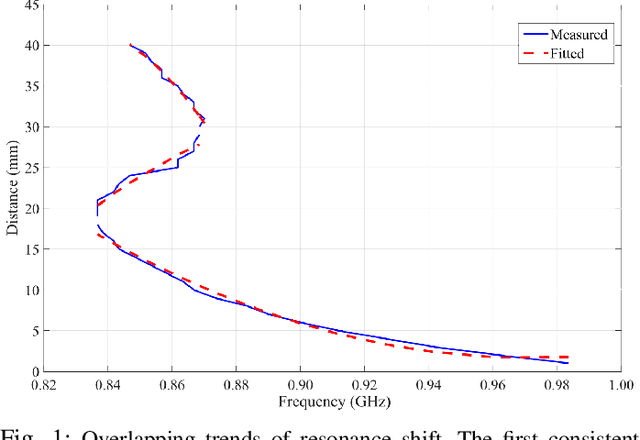
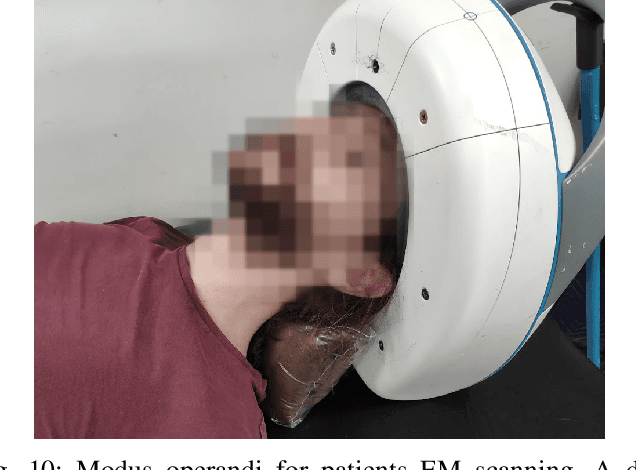
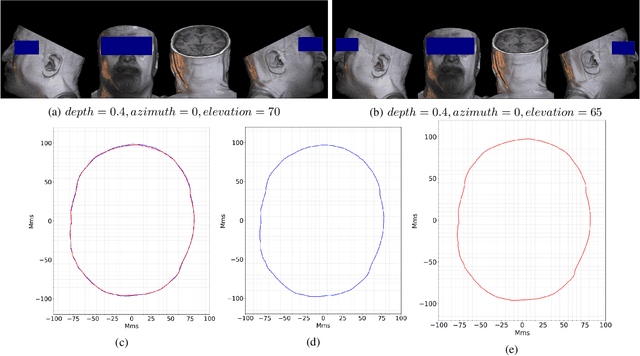
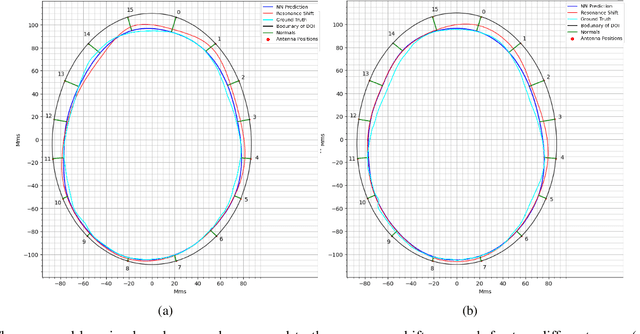
Incorporating boundaries of the imaging object as a priori information to imaging algorithms can significantly improve the performance of electromagnetic medical imaging systems. To avoid overly complicating the system by using different sensors and the adverse effect of the subject's movement, a learning-based method is proposed to estimate the boundary (external contour) of the imaged object using the same electromagnetic imaging data. While imaging techniques may discard the reflection coefficients for being dominant and uninformative for imaging, these parameters are made use of for boundary detection. The learned model is verified through independent clinical human trials by using a head imaging system with a 16-element antenna array that works across the band 0.7-1.6 GHz. The evaluation demonstrated that the model achieves average dissimilarity of 0.012 in Hu-moment while detecting head boundary. The model enables fast scan and image creation while eliminating the need for additional devices for accurate boundary estimation.
* Under Review
Progressive Transformer-Based Generation of Radiology Reports
Feb 19, 2021
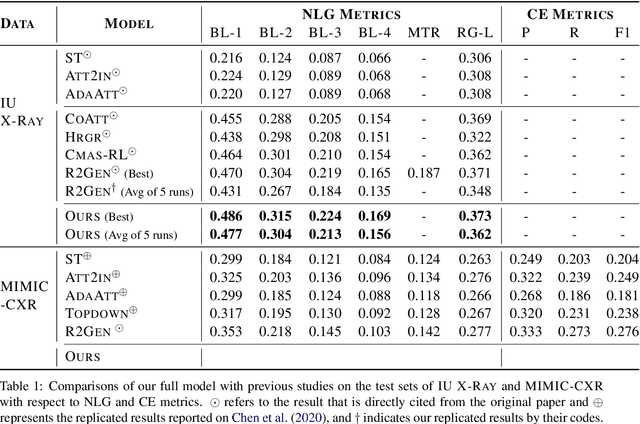
Inspired by Curriculum Learning, we propose a consecutive (i.e. image-to-text-to-text) generation framework where we divide the problem of radiology report generation into two steps. Contrary to generating the full radiology report from the image at once, the model generates global concepts from the image in the first step and then reforms them into finer and coherent texts using transformer-based architecture. We follow the transformer-based sequence-to-sequence paradigm at each step. We improve upon the state-of-the-art on two benchmark datasets.
CrypTen: Secure Multi-Party Computation Meets Machine Learning
Sep 02, 2021Secure multi-party computation (MPC) allows parties to perform computations on data while keeping that data private. This capability has great potential for machine-learning applications: it facilitates training of machine-learning models on private data sets owned by different parties, evaluation of one party's private model using another party's private data, etc. Although a range of studies implement machine-learning models via secure MPC, such implementations are not yet mainstream. Adoption of secure MPC is hampered by the absence of flexible software frameworks that "speak the language" of machine-learning researchers and engineers. To foster adoption of secure MPC in machine learning, we present CrypTen: a software framework that exposes popular secure MPC primitives via abstractions that are common in modern machine-learning frameworks, such as tensor computations, automatic differentiation, and modular neural networks. This paper describes the design of CrypTen and measure its performance on state-of-the-art models for text classification, speech recognition, and image classification. Our benchmarks show that CrypTen's GPU support and high-performance communication between (an arbitrary number of) parties allows it to perform efficient private evaluation of modern machine-learning models under a semi-honest threat model. For example, two parties using CrypTen can securely predict phonemes in speech recordings using Wav2Letter faster than real-time. We hope that CrypTen will spur adoption of secure MPC in the machine-learning community.
Hierarchical Neural Architecture Search for Single Image Super-Resolution
Mar 10, 2020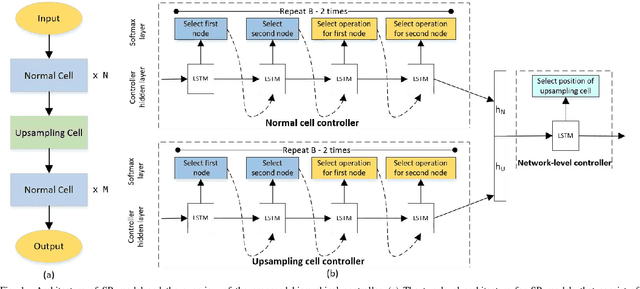
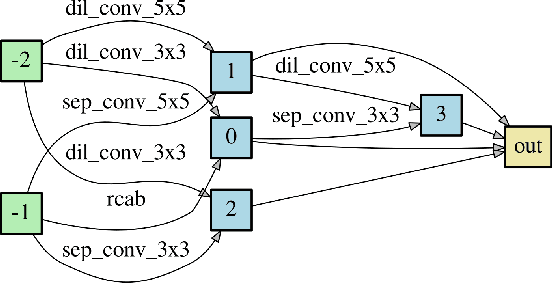

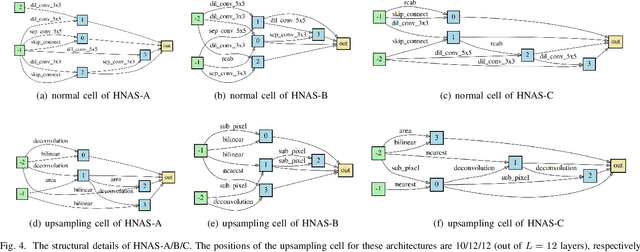
Deep neural networks have exhibited promising performance in image super-resolution (SR). Most SR models follow a hierarchical architecture that contains both the cell-level design of computational blocks and the network-level design of the positions of upsampling blocks. However, designing SR models heavily relies on human expertise and is very labor-intensive. More critically, these SR models often contain a huge number of parameters and may not meet the requirements of computation resources in real-world applications. To address the above issues, we propose a Hierarchical Neural Architecture Search (HNAS) method to automatically design promising architectures with different requirements of computation cost. To this end, we design a hierarchical SR search space and propose a hierarchical controller for architecture search. Such a hierarchical controller is able to simultaneously find promising cell-level blocks and network-level positions of upsampling layers. Moreover, to design compact architectures with promising performance, we build a joint reward by considering both the performance and computation cost to guide the search process. Extensive experiments on five benchmark datasets demonstrate the superiority of our method over existing methods.
IUPUI Driving Videos and Images in All Weather and Illumination Conditions
Apr 17, 2021This document describes an image and video dataset of driving views captured in all weather and illumination conditions. The data set has been submitted to CDVL.
Learning to Segment 3D Point Clouds in 2D Image Space
Mar 23, 2020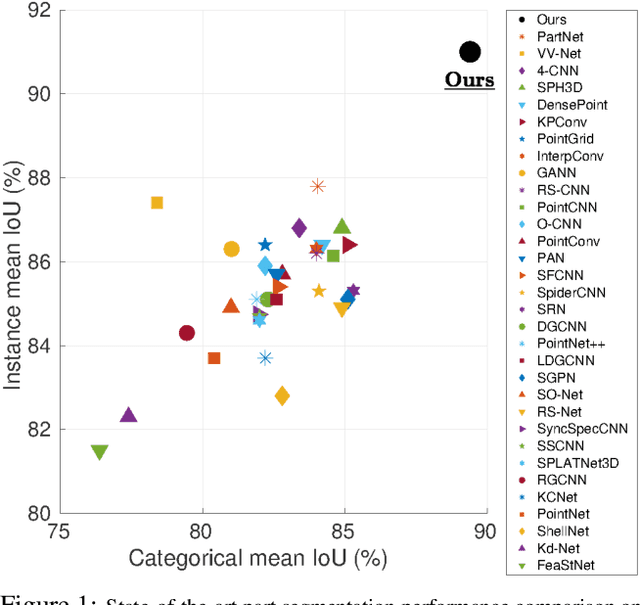
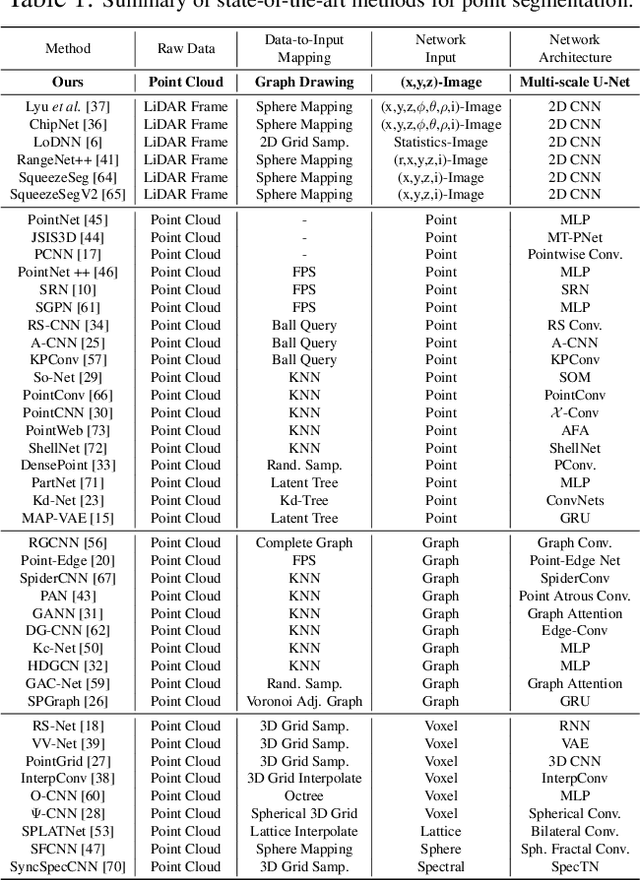
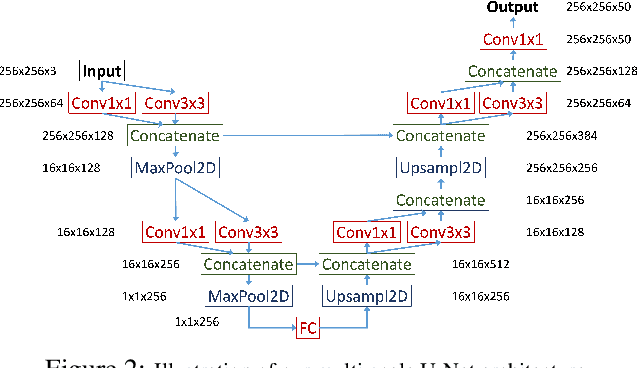
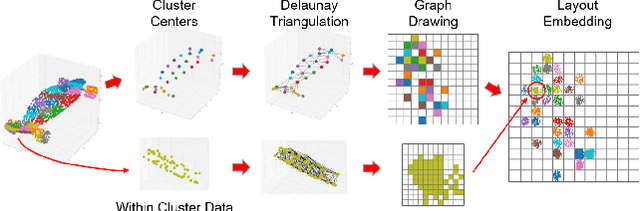
In contrast to the literature where local patterns in 3D point clouds are captured by customized convolutional operators, in this paper we study the problem of how to effectively and efficiently project such point clouds into a 2D image space so that traditional 2D convolutional neural networks (CNNs) such as U-Net can be applied for segmentation. To this end, we are motivated by graph drawing and reformulate it as an integer programming problem to learn the topology-preserving graph-to-grid mapping for each individual point cloud. To accelerate the computation in practice, we further propose a novel hierarchical approximate algorithm. With the help of the Delaunay triangulation for graph construction from point clouds and a multi-scale U-Net for segmentation, we manage to demonstrate the state-of-the-art performance on ShapeNet and PartNet, respectively, with significant improvement over the literature. Code is available at https://github.com/Zhang-VISLab.
Learning to Separate Multiple Illuminants in a Single Image
Nov 29, 2018



We present a method to separate a single image captured under two illuminants, with different spectra, into the two images corresponding to the appearance of the scene under each individual illuminant. We do this by training a deep neural network to predict the per-pixel reflectance chromaticity of the scene, which we use in conjunction with a previous flash/no-flash image-based separation algorithm to produce the final two output images. We design our reflectance chromaticity network and loss functions by incorporating intuitions from the physics of image formation. We show that this leads to significantly better performance than other single image techniques and even approaches the quality of the two image separation method.
An Operator-Splitting Method for the Gaussian Curvature Regularization Model with Applications in Surface Smoothing and Imaging
Aug 04, 2021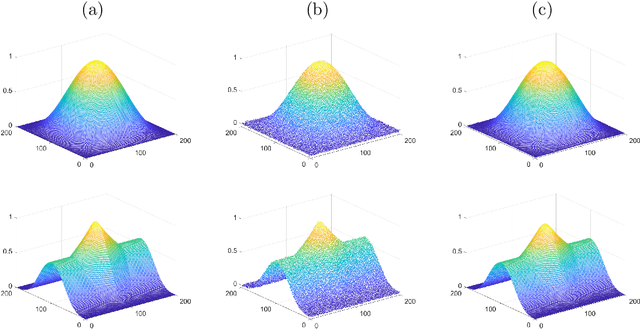

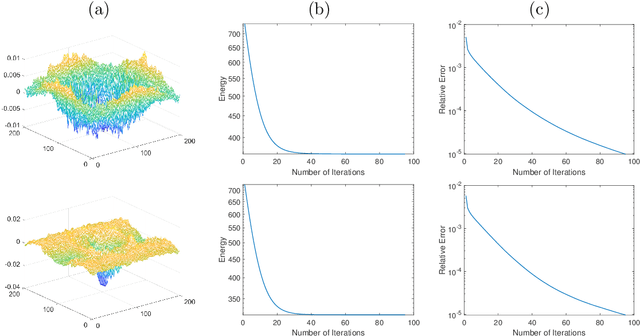
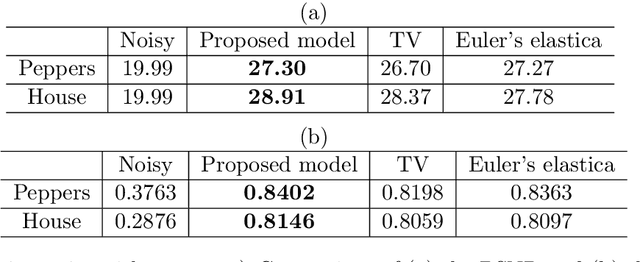
Gaussian curvature is an important geometric property of surfaces, which has been used broadly in mathematical modeling. Due to the full nonlinearity of the Gaussian curvature, efficient numerical methods for models based on it are uncommon in literature. In this article, we propose an operator-splitting method for a general Gaussian curvature model. In our method, we decouple the full nonlinearity of Gaussian curvature from differential operators by introducing two matrix- and vector-valued functions. The optimization problem is then converted into the search for the steady state solution of a time dependent PDE system. The above PDE system is well-suited to time discretization by operator splitting, the sub-problems encountered at each fractional step having either a closed form solution or being solvable by efficient algorithms. The proposed method is not sensitive to the choice of parameters, its efficiency and performances being demonstrated via systematic experiments on surface smoothing and image denoising.