 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Performance analysis of weighted low rank model with sparse image histograms for face recognition under lowlevel illumination and occlusion
Jul 24, 2020
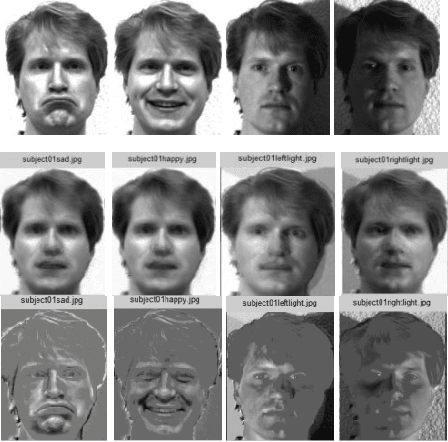
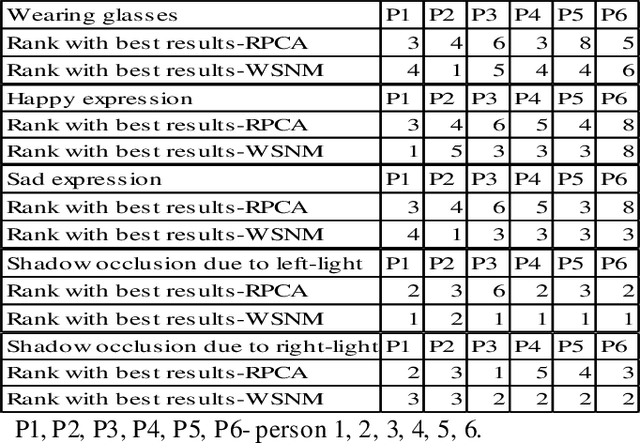
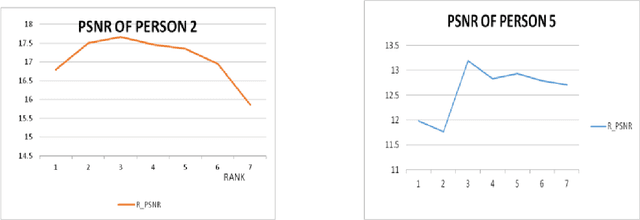
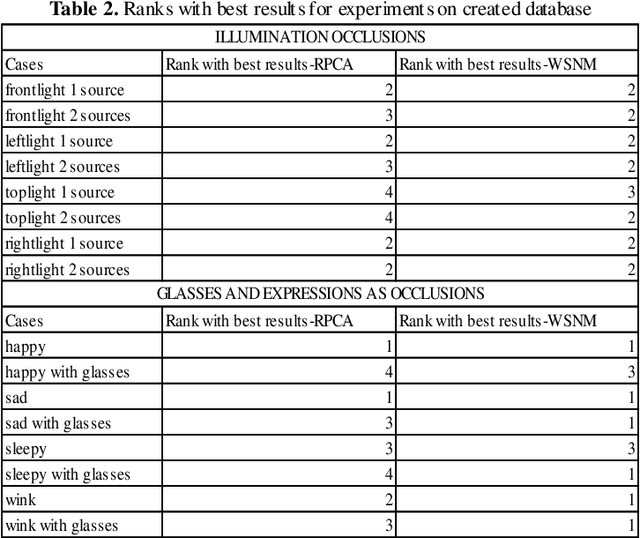
In a broad range of computer vision applications, the purpose of Low-rank matrix approximation (LRMA) models is to recover the underlying low-rank matrix from its degraded observation. The latest LRMA methods - Robust Principal Component Analysis (RPCA) resort to using the nuclear norm minimization (NNM) as a convex relaxation of the non-convex rank minimization. However, NNM tends to over-shrink the rank components and treats the different rank components equally, limiting its flexibility in practical applications. We use a more flexible model, namely the Weighted Schatten p-Norm Minimization (WSNM), to generalize the NNM to the Schatten p-norm minimization with weights assigned to different singular values. The proposed WSNM not only gives a better approximation to the original low-rank assumption but also considers the importance of different rank components. In this paper, a comparison of the low-rank recovery performance of two LRMA algorithms- RPCA and WSNM is brought out on occluded human facial images. The analysis is performed on facial images from the Yale database and over own database , where different facial expressions, spectacles, varying illumination account for the facial occlusions. The paper also discusses the prominent trends observed from the experimental results performed through the application of these algorithms. As low-rank images sometimes might fail to capture the details of a face adequately, we further propose a novel method to use the image-histogram of the sparse images thus obtained to identify the individual in any given image. Extensive experimental results show, both qualitatively and quantitatively, that WSNM surpasses RPCA in its performance more effectively by removing facial occlusions, thus giving recovered low-rank images of higher PSNR and SSIM.
Exploring Cross-Image Pixel Contrast for Semantic Segmentation
Jan 28, 2021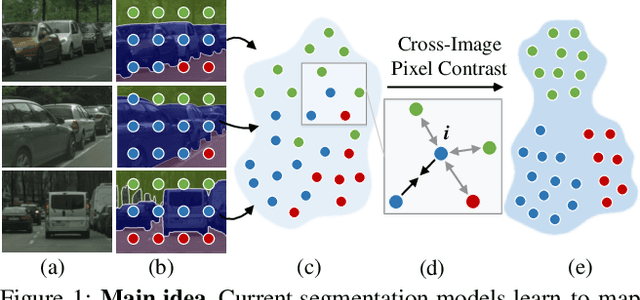
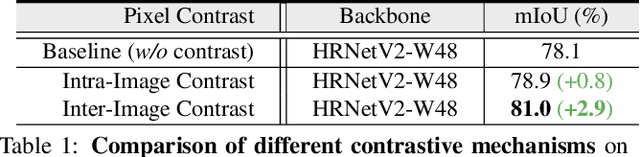
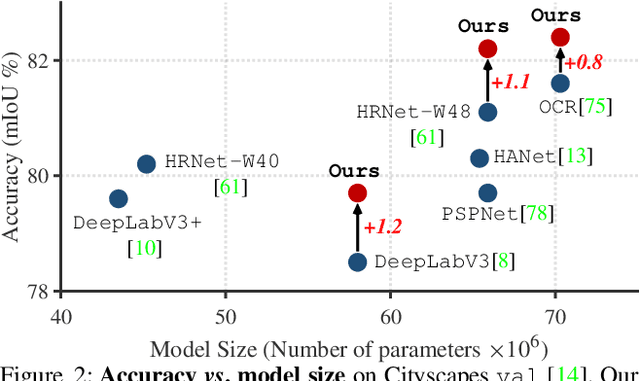

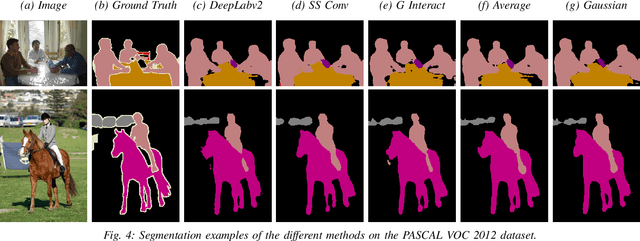
Current semantic segmentation methods focus only on mining "local" context, i.e., dependencies between pixels within individual images, by context-aggregation modules (e.g., dilated convolution, neural attention) or structure-aware optimization criteria (e.g., IoU-like loss). However, they ignore "global" context of the training data, i.e., rich semantic relations between pixels across different images. Inspired by the recent advance in unsupervised contrastive representation learning, we propose a pixel-wise contrastive framework for semantic segmentation in the fully supervised setting. The core idea is to enforce pixel embeddings belonging to a same semantic class to be more similar than embeddings from different classes. It raises a pixel-wise metric learning paradigm for semantic segmentation, by explicitly exploring the structures of labeled pixels, which are long ignored in the field. Our method can be effortlessly incorporated into existing segmentation frameworks without extra overhead during testing. We experimentally show that, with famous segmentation models (i.e., DeepLabV3, HRNet, OCR) and backbones (i.e., ResNet, HR-Net), our method brings consistent performance improvements across diverse datasets (i.e., Cityscapes, PASCAL-Context, COCO-Stuff). We expect this work will encourage our community to rethink the current de facto training paradigm in fully supervised semantic segmentation.
Abnormal Colon Polyp Image Synthesis Using Conditional Adversarial Networks for Improved Detection Performance
Jun 27, 2019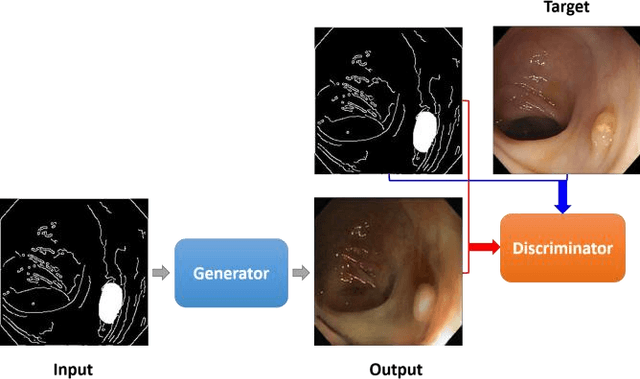
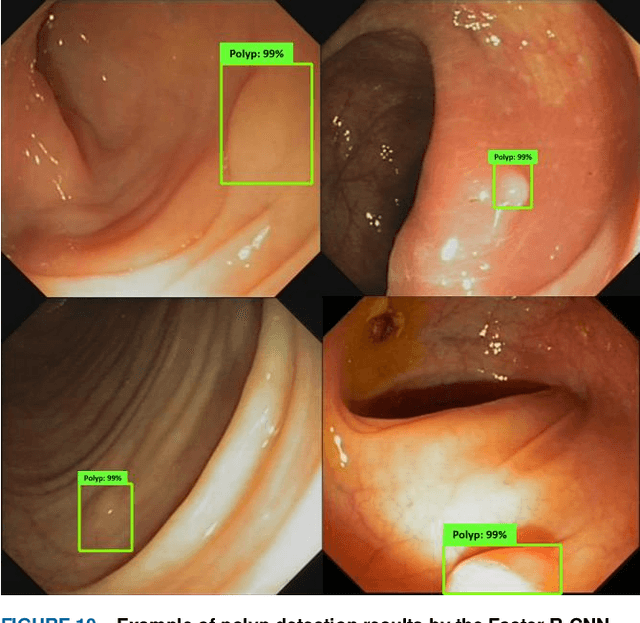
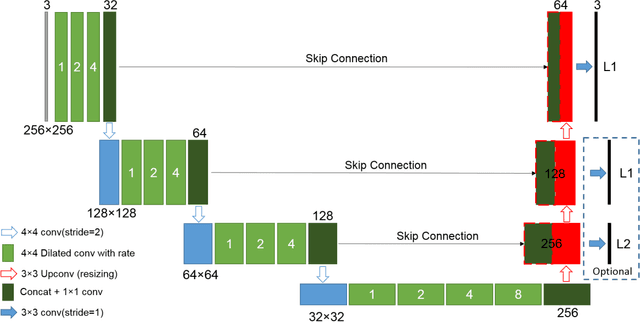
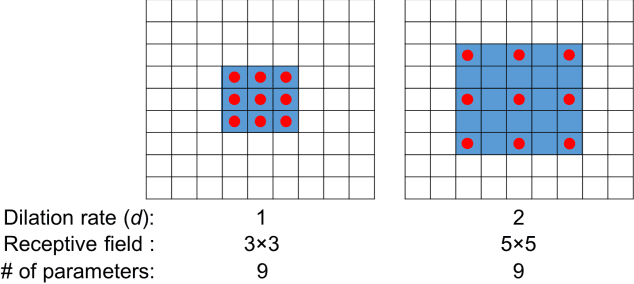
One of the major obstacles in automatic polyp detection during colonoscopy is the lack of labeled polyp training images. In this paper, we propose a framework of conditional adversarial networks to increase the number of training samples by generating synthetic polyp images. Using a normal binary form of polyp mask which represents only the polyp position as an input conditioned image, realistic polyp image generation is a difficult task in a generative adversarial networks approach. We propose an edge filtering-based combined input conditioned image to train our proposed networks. This enables realistic polyp image generations while maintaining the original structures of the colonoscopy image frames. More importantly, our proposed framework generates synthetic polyp images from normal colonoscopy images which have the advantage of being relatively easy to obtain. The network architecture is based on the use of multiple dilated convolutions in each encoding part of our generator network to consider large receptive fields and avoid many contractions of a feature map size. An image resizing with convolution for upsampling in the decoding layers is considered to prevent artifacts on generated images. We show that the generated polyp images are not only qualitatively realistic but also help to improve polyp detection performance.
* 10 pages
Offline and Online Deep Learning for Image Recognition
Mar 18, 2019
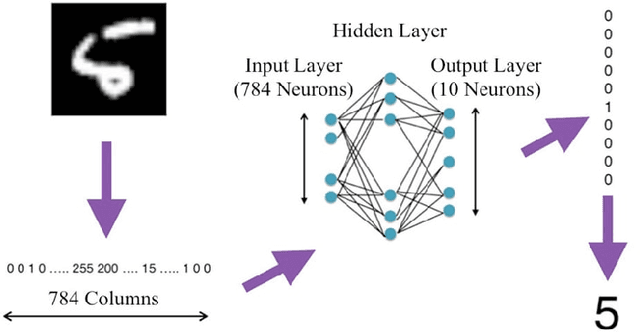
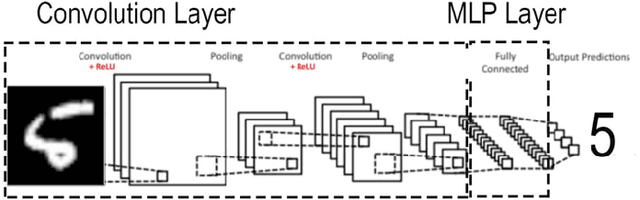
Image recognition using Deep Learning has been evolved for decades though advances in the field through different settings is still a challenge. In this paper, we present our findings in searching for better image classifiers in offline and online environments. We resort to Convolutional Neural Network and its variations of fully connected Multi-layer Perceptron. Though still preliminary, these results are encouraging and may provide a better understanding about the field and directions toward future works.
* 5 pages
Scene Text Image Super-Resolution in the Wild
May 07, 2020
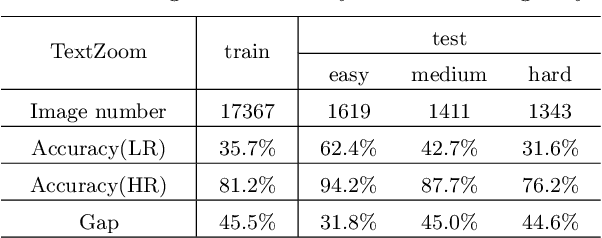
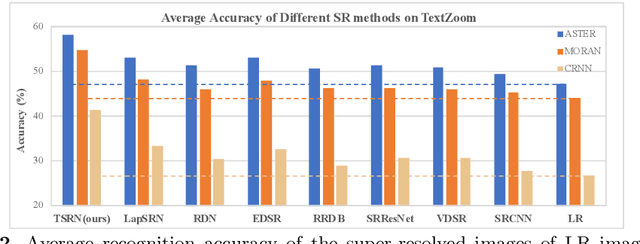
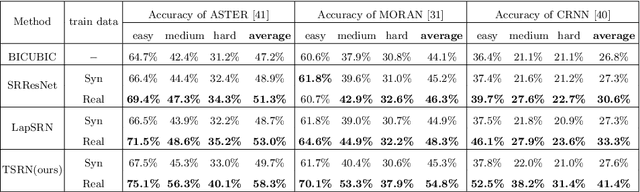
Low-resolution text images are often seen in natural scenes such as documents captured by mobile phones. Recognizing low-resolution text images is challenging because they lose detailed content information, leading to poor recognition accuracy. An intuitive solution is to introduce super-resolution (SR) techniques as pre-processing. However, previous single image super-resolution (SISR) methods are trained on synthetic low-resolution images (e.g.Bicubic down-sampling), which is simple and not suitable for real low-resolution text recognition. To this end, we pro-pose a real scene text SR dataset, termed TextZoom. It contains paired real low-resolution and high-resolution images which are captured by cameras with different focal length in the wild. It is more authentic and challenging than synthetic data, as shown in Fig. 1. We argue improv-ing the recognition accuracy is the ultimate goal for Scene Text SR. In this purpose, a new Text Super-Resolution Network termed TSRN, with three novel modules is developed. (1) A sequential residual block is proposed to extract the sequential information of the text images. (2) A boundary-aware loss is designed to sharpen the character boundaries. (3) A central alignment module is proposed to relieve the misalignment problem in TextZoom. Extensive experiments on TextZoom demonstrate that our TSRN largely improves the recognition accuracy by over 13%of CRNN, and by nearly 9.0% of ASTER and MORAN compared to synthetic SR data. Furthermore, our TSRN clearly outperforms 7 state-of-the-art SR methods in boosting the recognition accuracy of LR images in TextZoom. For example, it outperforms LapSRN by over 5% and 8%on the recognition accuracy of ASTER and CRNN. Our results suggest that low-resolution text recognition in the wild is far from being solved, thus more research effort is needed.
Splitfed learning without client-side synchronization: Analyzing client-side split network portion size to overall performance
Sep 19, 2021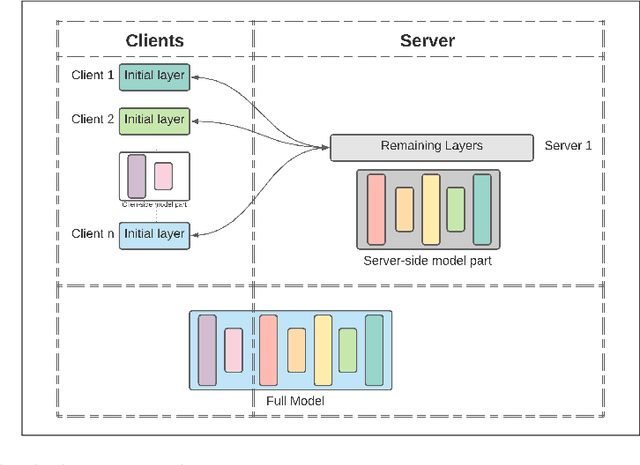
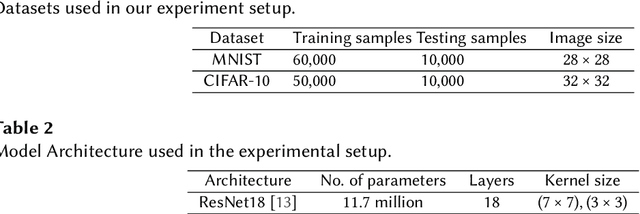
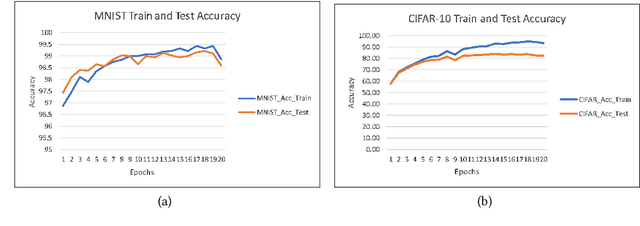
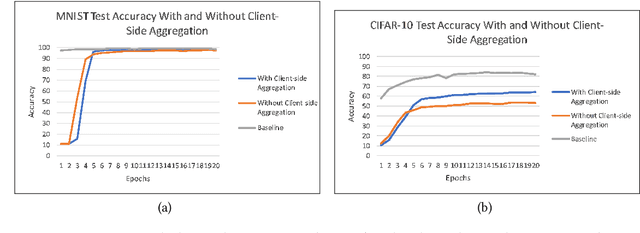
Federated Learning (FL), Split Learning (SL), and SplitFed Learning (SFL) are three recent developments in distributed machine learning that are gaining attention due to their ability to preserve the privacy of raw data. Thus, they are widely applicable in various domains where data is sensitive, such as large-scale medical image classification, internet-of-medical-things, and cross-organization phishing email detection. SFL is developed on the confluence point of FL and SL. It brings the best of FL and SL by providing parallel client-side machine learning model updates from the FL paradigm and a higher level of model privacy (while training) by splitting the model between the clients and server coming from SL. However, SFL has communication and computation overhead at the client-side due to the requirement of client-side model synchronization. For the resource-constrained client-side, removal of such requirements is required to gain efficiency in the learning. In this regard, this paper studies SFL without client-side model synchronization. The resulting architecture is known as Multi-head Split Learning. Our empirical studies considering the ResNet18 model on MNIST data under IID data distribution among distributed clients find that Multi-head Split Learning is feasible. Its performance is comparable to the SFL. Moreover, SFL provides only 1%-2% better accuracy than Multi-head Split Learning on the MNIST test set. To further strengthen our results, we study the Multi-head Split Learning with various client-side model portions and its impact on the overall performance. To this end, our results find a minimal impact on the overall performance of the model.
Fully Neural Network Mode Based Intra Prediction of Variable Block Size
Aug 05, 2021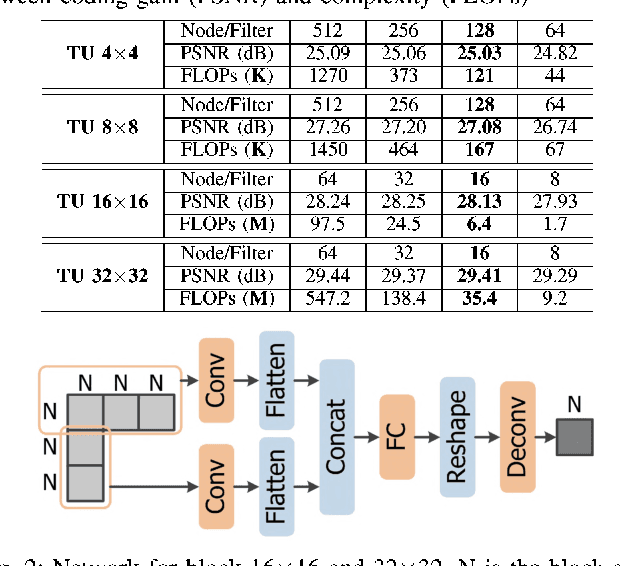

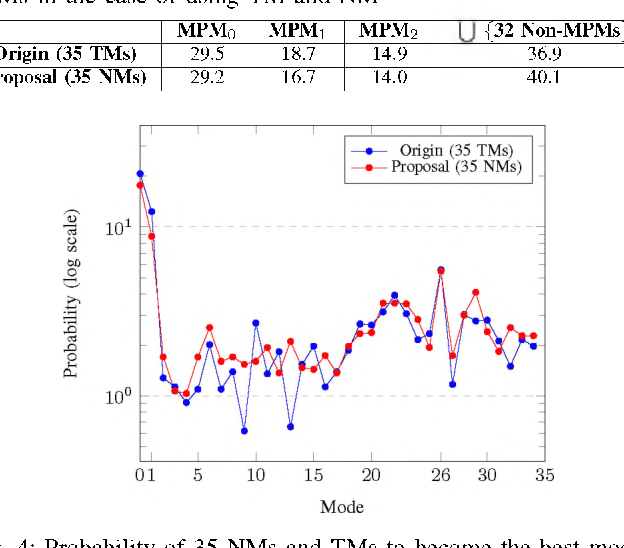
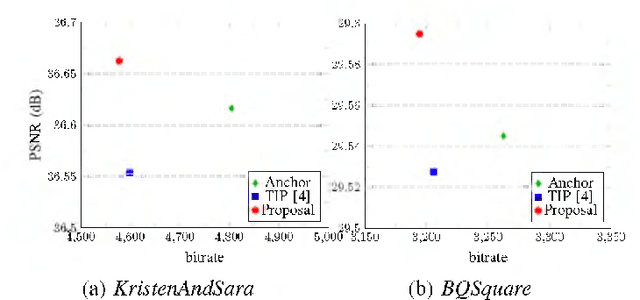
Intra prediction is an essential component in the image coding. This paper gives an intra prediction framework completely based on neural network modes (NM). Each NM can be regarded as a regression from the neighboring reference blocks to the current coding block. (1) For variable block size, we utilize different network structures. For small blocks 4x4 and 8x8, fully connected networks are used, while for large blocks 16x16 and 32x32, convolutional neural networks are exploited. (2) For each prediction mode, we develop a specific pre-trained network to boost the regression accuracy. When integrating into HEVC test model, we can save 3.55%, 3.03% and 3.27% BD-rate for Y, U, V components compared with the anchor. As far as we know, this is the first work to explore a fully NM based framework for intra prediction, and we reach a better coding gain with a lower complexity compared with the previous work.
No-Reference Light Field Image Quality Assessment Based on Spatial-Angular Measurement
Aug 17, 2019
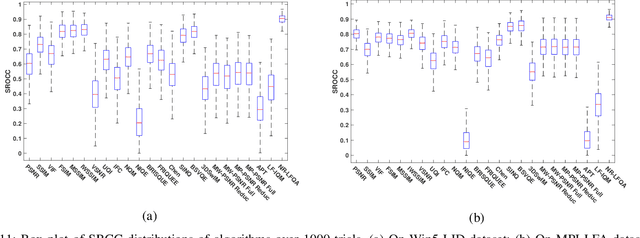

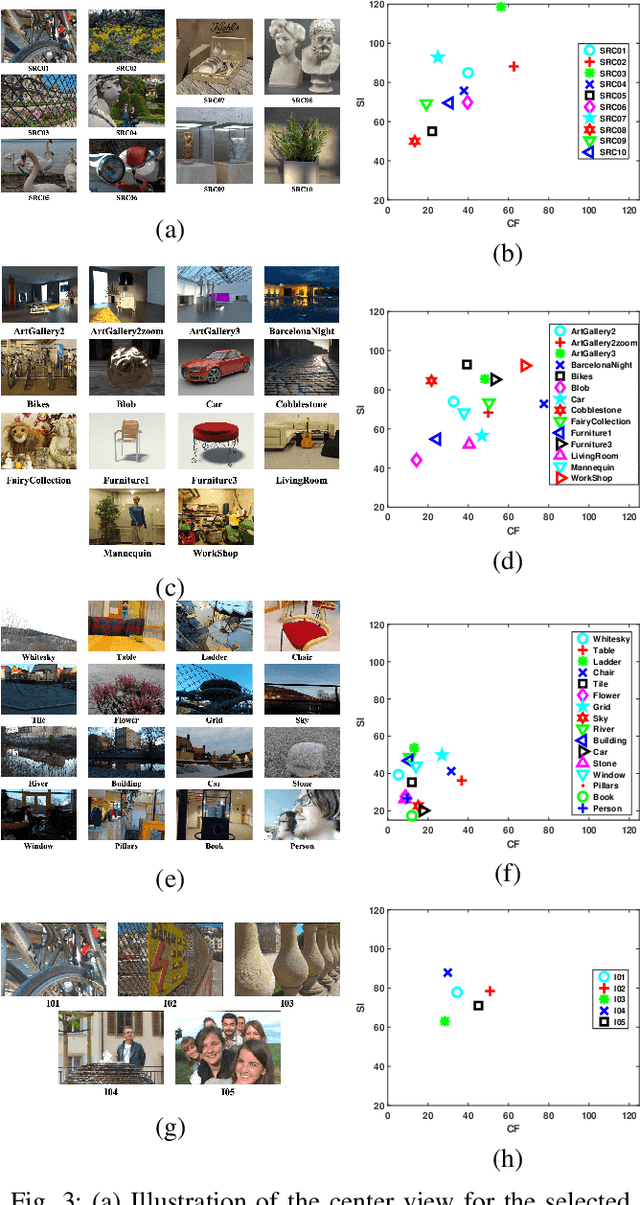
Light field image quality assessment (LFI-QA) is a significant and challenging research problem. It helps to better guide light field acquisition, processing and applications. However, only a few objective models have been proposed and none of them completely consider intrinsic factors affecting the LFI quality. In this paper, we propose a No-Reference Light Field image Quality Assessment (NR-LFQA) scheme, where the main idea is to quantify the LFI quality degradation through evaluating the spatial quality and angular consistency. We first measure the spatial quality deterioration by capturing the naturalness distribution of the light field cyclopean image array, which is formed when human observes the LFI. Then, as a transformed representation of LFI, the Epipolar Plane Image (EPI) contains the slopes of lines and involves the angular information. Therefore, EPI is utilized to extract the global and local features from LFI to measure angular consistency degradation. Specifically, the distribution of gradient direction map of EPI is proposed to measure the global angular consistency distortion in the LFI. We further propose the weighted local binary pattern to capture the characteristics of local angular consistency degradation. Extensive experimental results on four publicly available LFI quality datasets demonstrate that the proposed method outperforms state-of-the-art 2D, 3D, multi-view, and LFI quality assessment algorithms.
Efficient Smoothing of Dilated Convolutions for Image Segmentation
Mar 19, 2019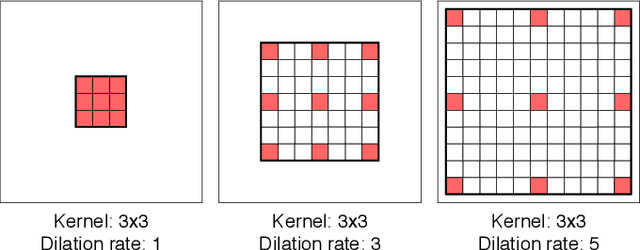
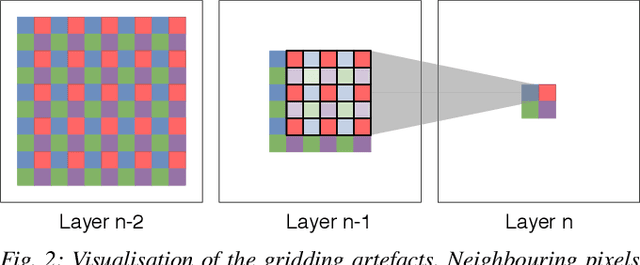
Dilated Convolutions have been shown to be highly useful for the task of image segmentation. By introducing gaps into convolutional filters, they enable the use of larger receptive fields without increasing the original kernel size. Even though this allows for the inexpensive capturing of features at different scales, the structure of the dilated convolutional filter leads to a loss of information. We hypothesise that inexpensive modifications to Dilated Convolutional Neural Networks, such as additional averaging layers, could overcome this limitation. In this project we test this hypothesis by evaluating the effect of these modifications for a state-of-the art image segmentation system and compare them to existing approaches with the same objective. Our experiments show that our proposed methods improve the performance of dilated convolutions for image segmentation. Crucially, our modifications achieve these results at a much lower computational cost than previous smoothing approaches.
Learning Parallax Attention for Stereo Image Super-Resolution
Mar 19, 2019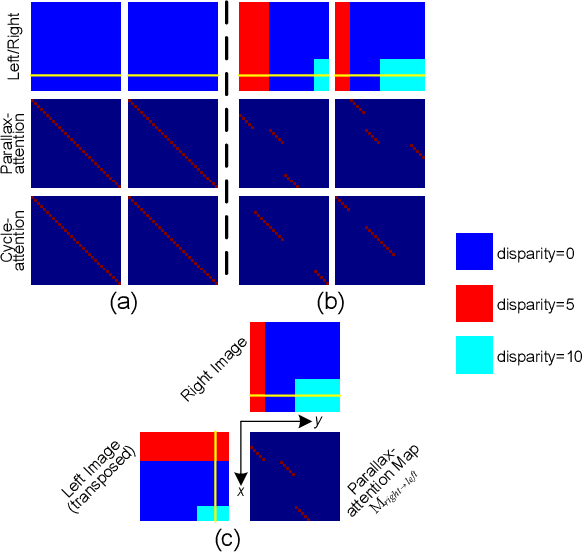
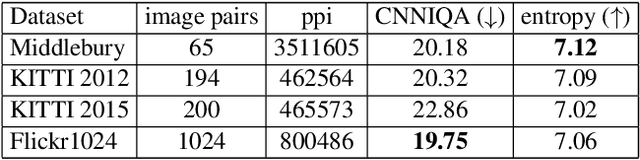
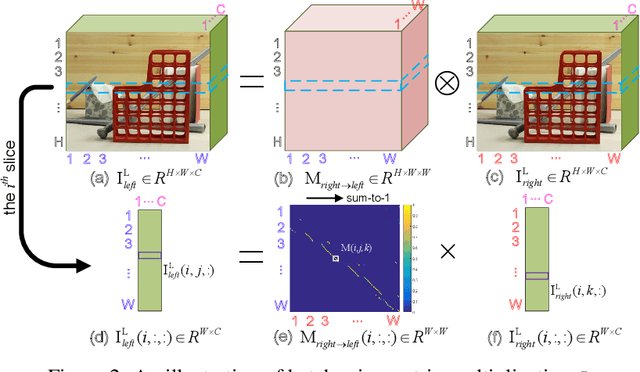
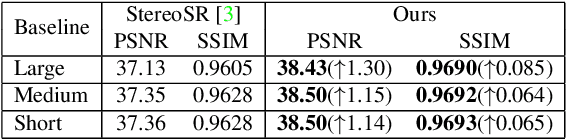
Stereo image pairs can be used to improve the performance of super-resolution (SR) since additional information is provided from a second viewpoint. However, it is challenging to incorporate this information for SR since disparities between stereo images vary significantly. In this paper, we propose a parallax-attention stereo superresolution network (PASSRnet) to integrate the information from a stereo image pair for SR. Specifically, we introduce a parallax-attention mechanism with a global receptive field along the epipolar line to handle different stereo images with large disparity variations. We also propose a new and the largest dataset for stereo image SR (namely, Flickr1024). Extensive experiments demonstrate that the parallax-attention mechanism can capture correspondence between stereo images to improve SR performance with a small computational and memory cost. Comparative results show that our PASSRnet achieves the state-of-the-art performance on the Middlebury, KITTI 2012 and KITTI 2015 datasets.