 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic Palette: Guiding Scene Generation with Class Proportions
Jun 03, 2021
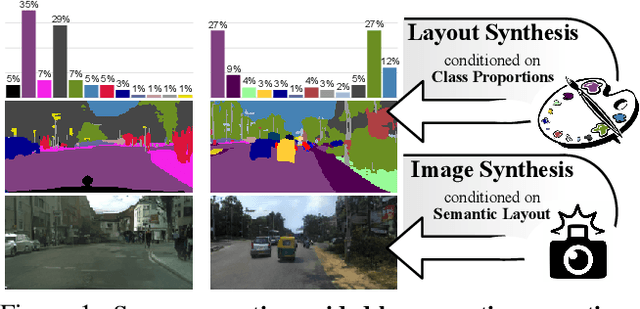
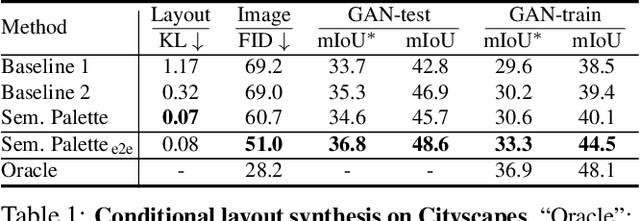
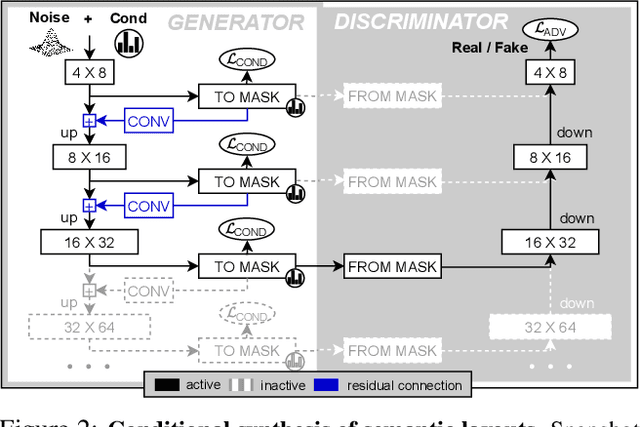
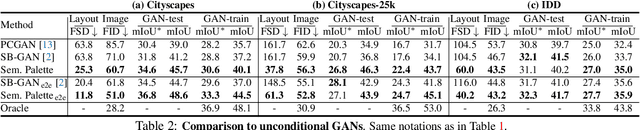
Despite the recent progress of generative adversarial networks (GANs) at synthesizing photo-realistic images, producing complex urban scenes remains a challenging problem. Previous works break down scene generation into two consecutive phases: unconditional semantic layout synthesis and image synthesis conditioned on layouts. In this work, we propose to condition layout generation as well for higher semantic control: given a vector of class proportions, we generate layouts with matching composition. To this end, we introduce a conditional framework with novel architecture designs and learning objectives, which effectively accommodates class proportions to guide the scene generation process. The proposed architecture also allows partial layout editing with interesting applications. Thanks to the semantic control, we can produce layouts close to the real distribution, helping enhance the whole scene generation process. On different metrics and urban scene benchmarks, our models outperform existing baselines. Moreover, we demonstrate the merit of our approach for data augmentation: semantic segmenters trained on real layout-image pairs along with additional ones generated by our approach outperform models only trained on real pairs.
An Asymetric Cycle-Consistency Loss for Dealing with Many-to-One Mappings in Image Translation: A Study on Thigh MR Scans
May 19, 2020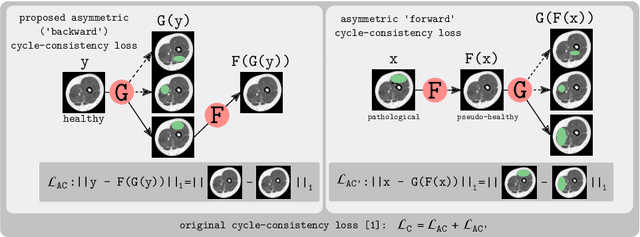
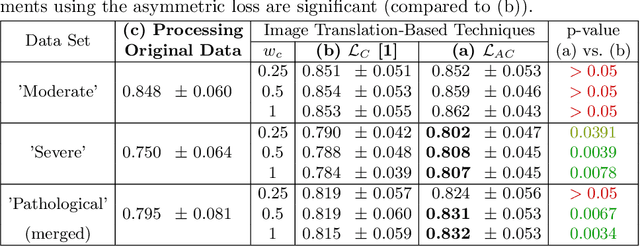
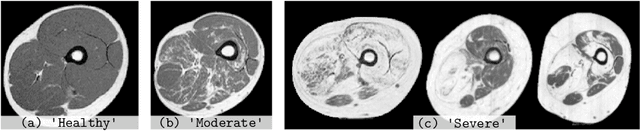
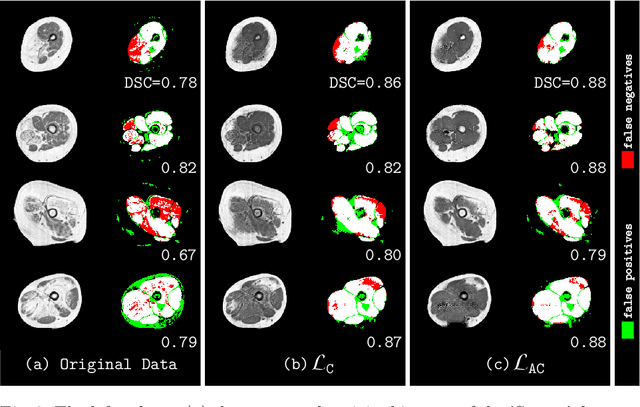
Generative adversarial networks using a cycle-consistency loss facilitate unpaired training of image-translation models and thereby exhibit a very high potential in manifold medical applications. However, the fact that images in one domain potentially map to more than one image in another domain (e.g. in case of pathological changes) exhibits a major challenge for training the networks. In this work, we offer a solution to improve the training process in case of many-to-one mappings by modifying the cycle-consistency loss. We show formally and empirically that the proposed method improves the performance significantly without radically changing the architecture and without increasing the overall complexity. We evaluate our method on thigh MRI scans with the final goal of segmenting the muscle in fat-infiltrated patients' data.
Semi-Supervised Classification and Segmentation on High Resolution Aerial Images
May 16, 2021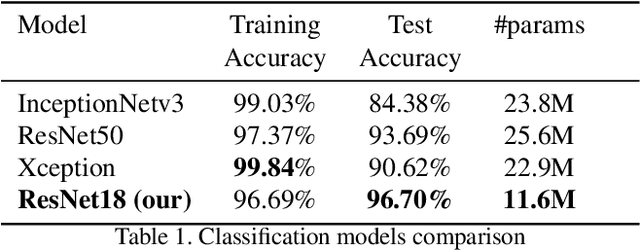
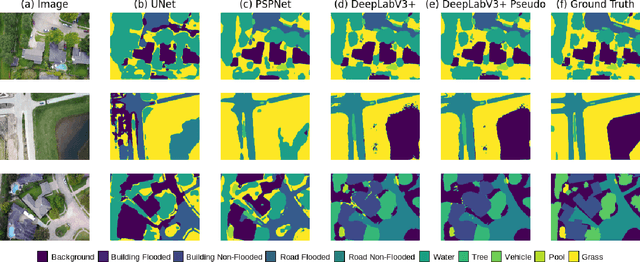

FloodNet is a high-resolution image dataset acquired by a small UAV platform, DJI Mavic Pro quadcopters, after Hurricane Harvey. The dataset presents a unique challenge of advancing the damage assessment process for post-disaster scenarios using unlabeled and limited labeled dataset. We propose a solution to address their classification and semantic segmentation challenge. We approach this problem by generating pseudo labels for both classification and segmentation during training and slowly incrementing the amount by which the pseudo label loss affects the final loss. Using this semi-supervised method of training helped us improve our baseline supervised loss by a huge margin for classification, allowing the model to generalize and perform better on the validation and test splits of the dataset. In this paper, we compare and contrast the various methods and models for image classification and semantic segmentation on the FloodNet dataset.
Knowledge driven Description Synthesis for Floor Plan Interpretation
Mar 15, 2021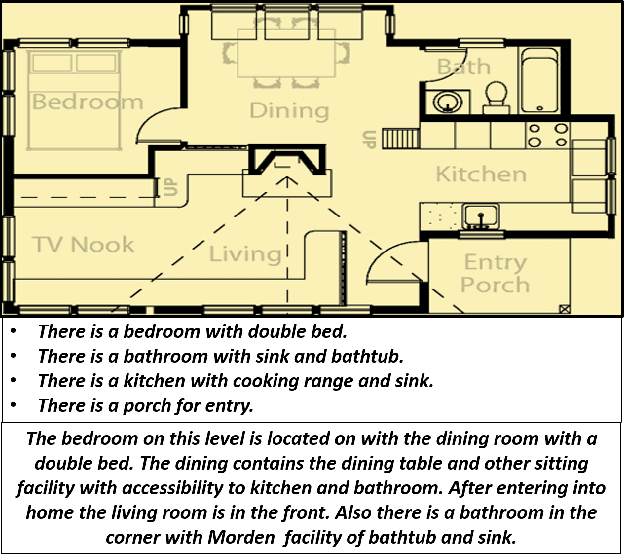
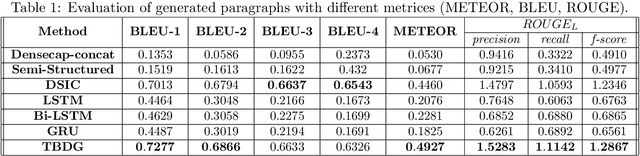
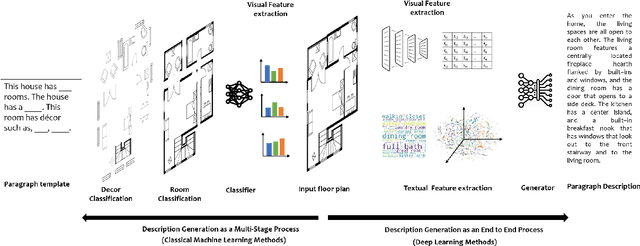
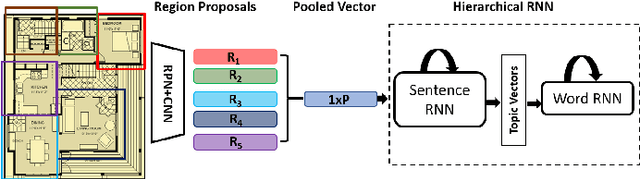
Image captioning is a widely known problem in the area of AI. Caption generation from floor plan images has applications in indoor path planning, real estate, and providing architectural solutions. Several methods have been explored in literature for generating captions or semi-structured descriptions from floor plan images. Since only the caption is insufficient to capture fine-grained details, researchers also proposed descriptive paragraphs from images. However, these descriptions have a rigid structure and lack flexibility, making it difficult to use them in real-time scenarios. This paper offers two models, Description Synthesis from Image Cue (DSIC) and Transformer Based Description Generation (TBDG), for the floor plan image to text generation to fill the gaps in existing methods. These two models take advantage of modern deep neural networks for visual feature extraction and text generation. The difference between both models is in the way they take input from the floor plan image. The DSIC model takes only visual features automatically extracted by a deep neural network, while the TBDG model learns textual captions extracted from input floor plan images with paragraphs. The specific keywords generated in TBDG and understanding them with paragraphs make it more robust in a general floor plan image. Experiments were carried out on a large-scale publicly available dataset and compared with state-of-the-art techniques to show the proposed model's superiority.
Image Quality Assessment for Omnidirectional Cross-reference Stitching
Apr 23, 2019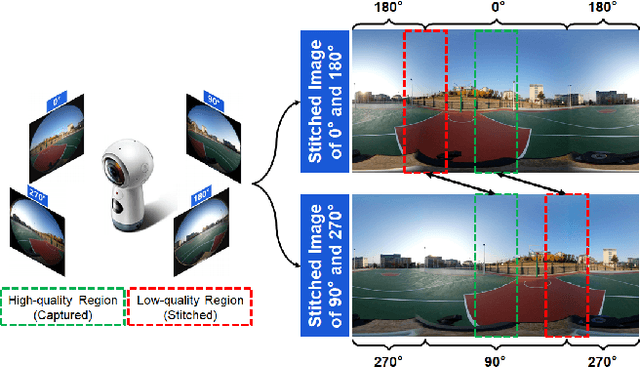
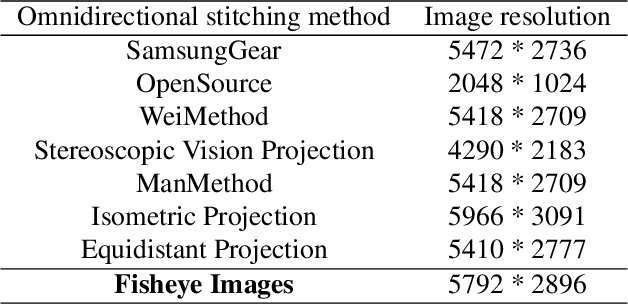

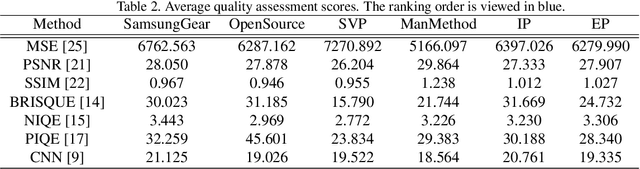
Along with the development of virtual reality (VR), omnidirectional images play an important role in producing multimedia content with immersive experience. However, despite various existing approaches for omnidirectional image stitching, how to quantitatively assess the quality of stitched images is still insufficiently explored. To address this problem, we establish a novel omnidirectional image dataset containing stitched images as well as dual-fisheye images captured from standard quarters of 0$^\circ$, 90$^\circ$, 180$^\circ$ and 270$^\circ$. In this manner, when evaluating the quality of an image stitched from a pair of fisheye images (e.g., 0$^\circ$ and 180$^\circ$), the other pair of fisheye images (e.g., 90$^\circ$ and 270$^\circ$) can be used as the cross-reference to provide ground-truth observations of the stitching regions. Based on this dataset, we further benchmark six widely used stitching models with seven evaluation metrics for IQA. To the best of our knowledge, it is the first dataset that focuses on assessing the stitching quality of omnidirectional images.
Progressive Domain-Independent Feature Decomposition Network for Zero-Shot Sketch-Based Image Retrieval
Mar 22, 2020
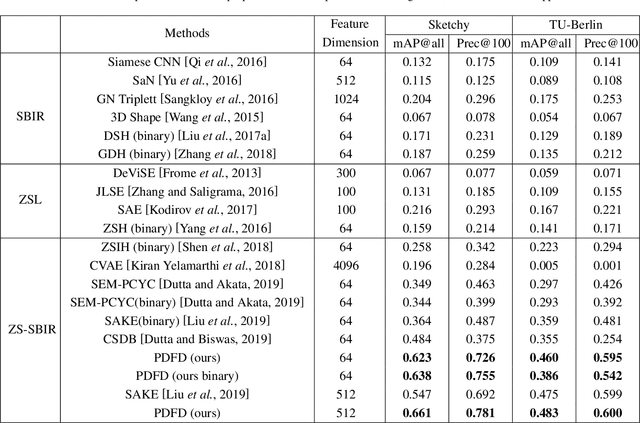
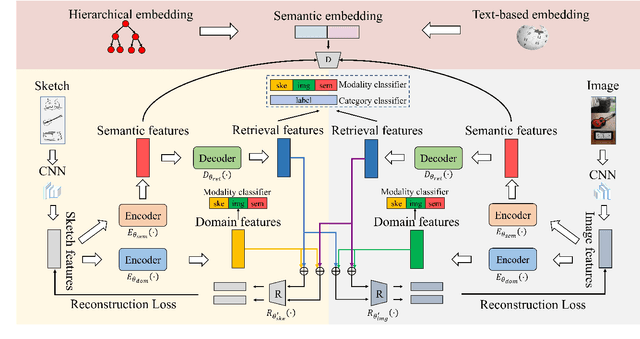

Zero-shot sketch-based image retrieval (ZS-SBIR) is a specific cross-modal retrieval task for searching natural images given free-hand sketches under the zero-shot scenario. Most existing methods solve this problem by simultaneously projecting visual features and semantic supervision into a low-dimensional common space for efficient retrieval. However, such low-dimensional projection destroys the completeness of semantic knowledge in original semantic space, so that it is unable to transfer useful knowledge well when learning semantic from different modalities. Moreover, the domain information and semantic information are entangled in visual features, which is not conducive for cross-modal matching since it will hinder the reduction of domain gap between sketch and image. In this paper, we propose a Progressive Domain-independent Feature Decomposition (PDFD) network for ZS-SBIR. Specifically, with the supervision of original semantic knowledge, PDFD decomposes visual features into domain features and semantic ones, and then the semantic features are projected into common space as retrieval features for ZS-SBIR. The progressive projection strategy maintains strong semantic supervision. Besides, to guarantee the retrieval features to capture clean and complete semantic information, the cross-reconstruction loss is introduced to encourage that any combinations of retrieval features and domain features can reconstruct the visual features. Extensive experiments demonstrate the superiority of our PDFD over state-of-the-art competitors.
Digging into Uncertainty in Self-supervised Multi-view Stereo
Aug 30, 2021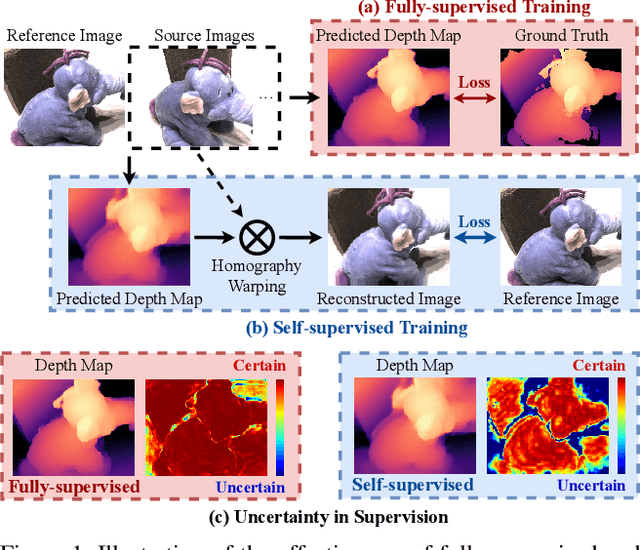
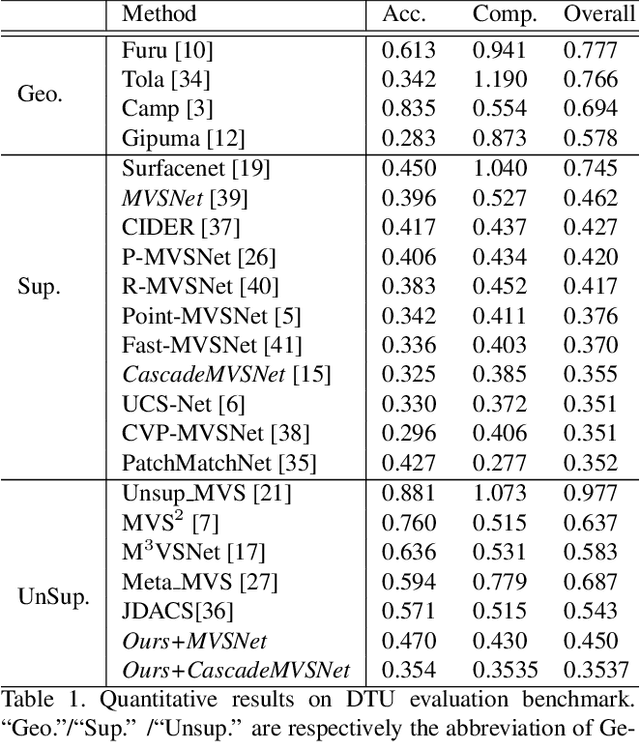
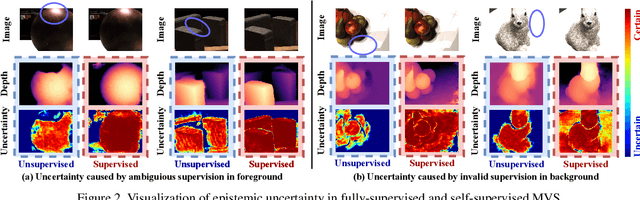
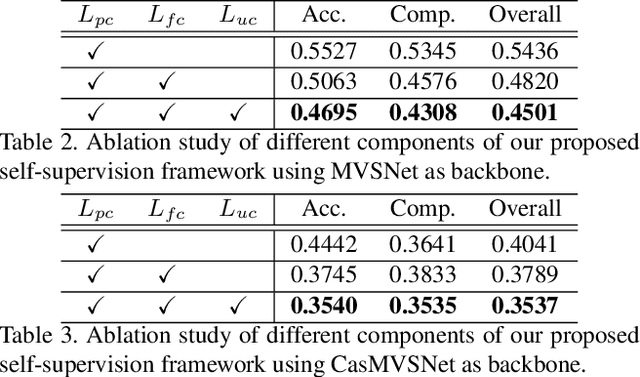
Self-supervised Multi-view stereo (MVS) with a pretext task of image reconstruction has achieved significant progress recently. However, previous methods are built upon intuitions, lacking comprehensive explanations about the effectiveness of the pretext task in self-supervised MVS. To this end, we propose to estimate epistemic uncertainty in self-supervised MVS, accounting for what the model ignores. Specially, the limitations can be categorized into two types: ambiguious supervision in foreground and invalid supervision in background. To address these issues, we propose a novel Uncertainty reduction Multi-view Stereo (UMVS) framework for self-supervised learning. To alleviate ambiguous supervision in foreground, we involve extra correspondence prior with a flow-depth consistency loss. The dense 2D correspondence of optical flows is used to regularize the 3D stereo correspondence in MVS. To handle the invalid supervision in background, we use Monte-Carlo Dropout to acquire the uncertainty map and further filter the unreliable supervision signals on invalid regions. Extensive experiments on DTU and Tank&Temples benchmark show that our U-MVS framework achieves the best performance among unsupervised MVS methods, with competitive performance with its supervised opponents.
Small and large scale critical infrastructures detection based on deep learning using high resolution orthogonal images
May 25, 2021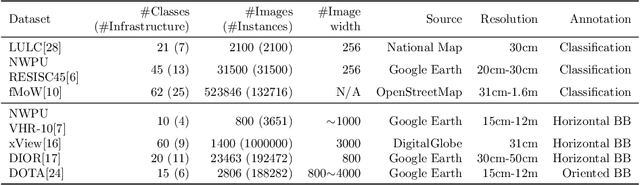
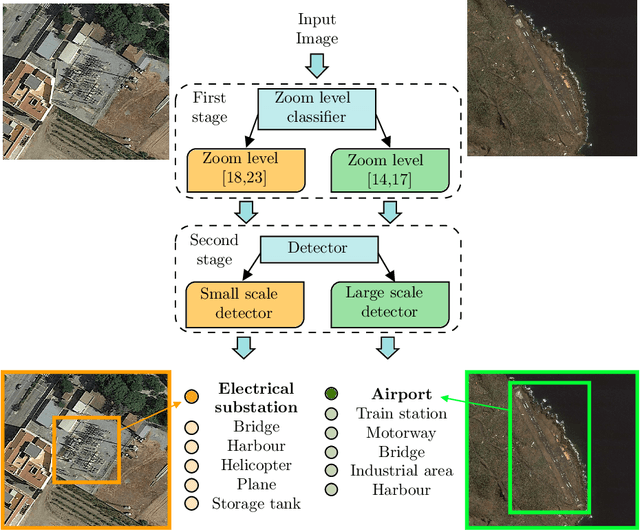
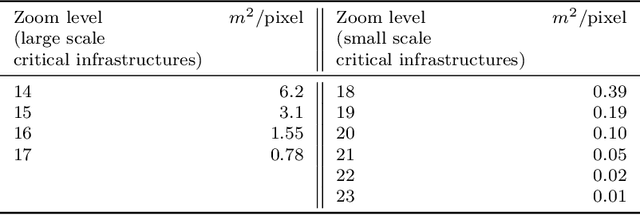
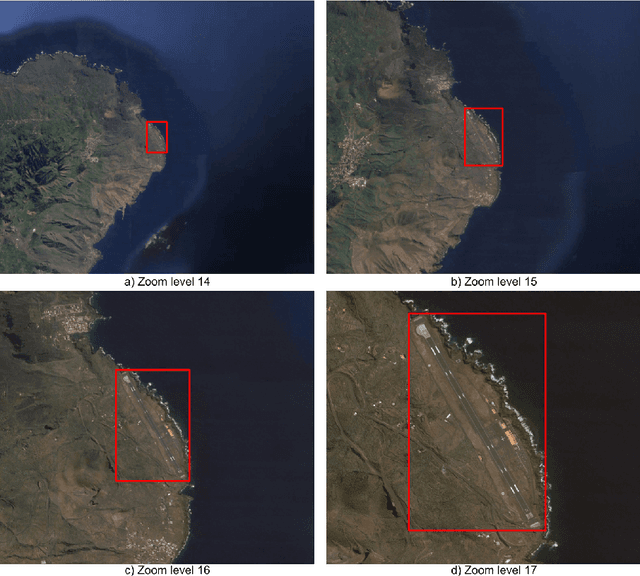
The detection of critical infrastructures is of high importance in several fields such as security, anomaly detection, land use planning and land use change detection. However, critical infrastructures detection in aerial and satellite images is still a challenge as each one has completely different size and requires different spacial resolution to be identified correctly. Heretofore, there are no special datasets for training critical infrastructures detectors. This paper presents a smart dataset as well as a resolution-independent critical infrastructure detection system. In particular, guided by the performance of the detection model, we built a dataset organized into two scales, small and large scale, and designed a two-stage deep learning detection of different scale critical infrastructures (DetDSCI) methodology in ortho-images. DetDSCI methodology first determines the input image zoom level using a classification model, then analyses the input image with the appropriate scale detection model. Our experiments show that DetDSCI methodology achieves up to 37,53% F1 improvement with respect to the baseline detector.
Visual resemblance and communicative context constrain the emergence of graphical conventions
Sep 17, 2021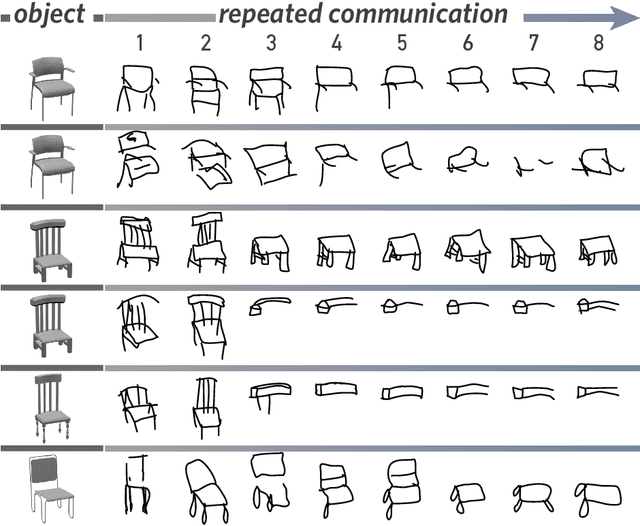
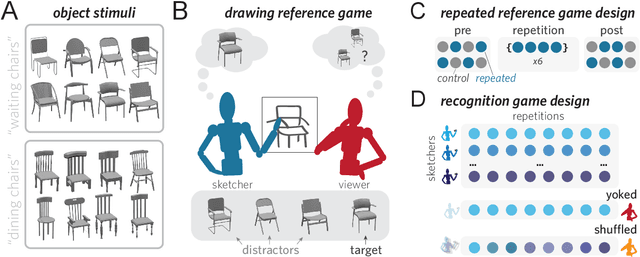
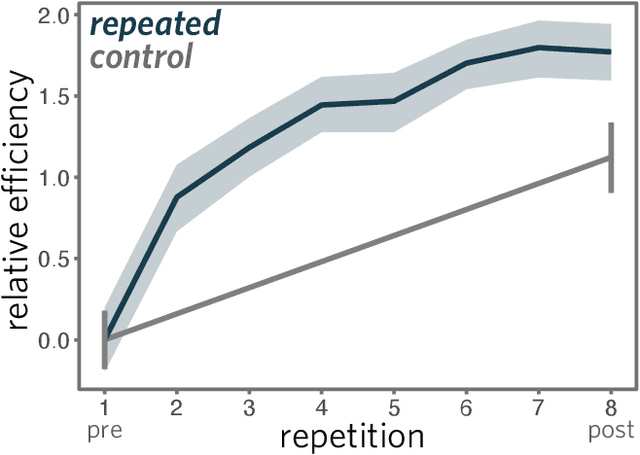
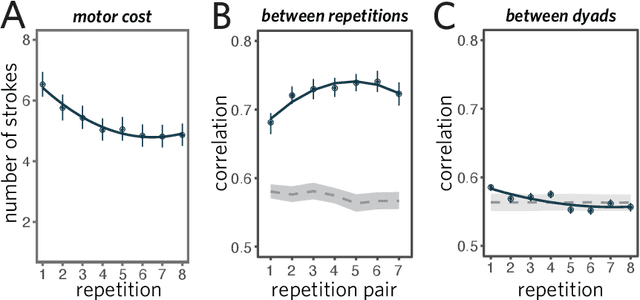
From photorealistic sketches to schematic diagrams, drawing provides a versatile medium for communicating about the visual world. How do images spanning such a broad range of appearances reliably convey meaning? Do viewers understand drawings based solely on their ability to resemble the entities they refer to (i.e., as images), or do they understand drawings based on shared but arbitrary associations with these entities (i.e., as symbols)? In this paper, we provide evidence for a cognitive account of pictorial meaning in which both visual and social information is integrated to support effective visual communication. To evaluate this account, we used a communication task where pairs of participants used drawings to repeatedly communicate the identity of a target object among multiple distractor objects. We manipulated social cues across three experiments and a full internal replication, finding pairs of participants develop referent-specific and interaction-specific strategies for communicating more efficiently over time, going beyond what could be explained by either task practice or a pure resemblance-based account alone. Using a combination of model-based image analyses and crowdsourced sketch annotations, we further determined that drawings did not drift toward arbitrariness, as predicted by a pure convention-based account, but systematically preserved those visual features that were most distinctive of the target object. Taken together, these findings advance theories of pictorial meaning and have implications for how successful graphical conventions emerge via complex interactions between visual perception, communicative experience, and social context.
Spatial Transformer Networks for Curriculum Learning
Aug 22, 2021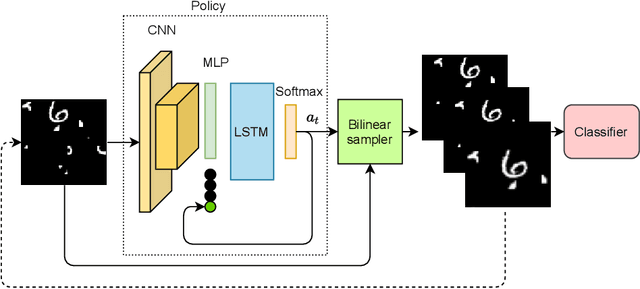



Curriculum learning is a bio-inspired training technique that is widely adopted to machine learning for improved optimization and better training of neural networks regarding the convergence rate or obtained accuracy. The main concept in curriculum learning is to start the training with simpler tasks and gradually increase the level of difficulty. Therefore, a natural question is how to determine or generate these simpler tasks. In this work, we take inspiration from Spatial Transformer Networks (STNs) in order to form an easy-to-hard curriculum. As STNs have been proven to be capable of removing the clutter from the input images and obtaining higher accuracy in image classification tasks, we hypothesize that images processed by STNs can be seen as easier tasks and utilized in the interest of curriculum learning. To this end, we study multiple strategies developed for shaping the training curriculum, using the data generated by STNs. We perform various experiments on cluttered MNIST and Fashion-MNIST datasets, where on the former, we obtain an improvement of $3.8$pp in classification accuracy compared to the baseline.