 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Defining Image Memorability using the Visual Memory Schema
Mar 05, 2019


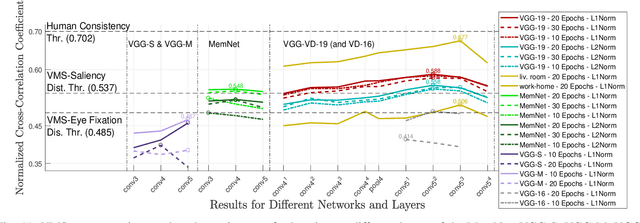

Memorability of an image is a characteristic determined by the human observers' ability to remember images they have seen. Yet recent work on image memorability defines it as an intrinsic property that can be obtained independent of the observer. {The current study aims to enhance our understanding and prediction of image memorability, improving upon existing approaches by incorporating the properties of cumulative human annotations.} We propose a new concept called the Visual Memory Schema (VMS) referring to an organisation of image components human observers share when encoding and recognising images. The concept of VMS is operationalised by asking human observers to define memorable regions of images they were asked to remember during an episodic memory test. We then statistically assess the consistency of VMSs across observers for either correctly or incorrectly recognised images. The associations of the VMSs with eye fixations and saliency are analysed separately as well. Lastly, we adapt various deep learning architectures for the reconstruction and prediction of memorable regions in images and analyse the results when using transfer learning at the outputs of different convolutional network layers.
Dual Adversarial Inference for Text-to-Image Synthesis
Aug 14, 2019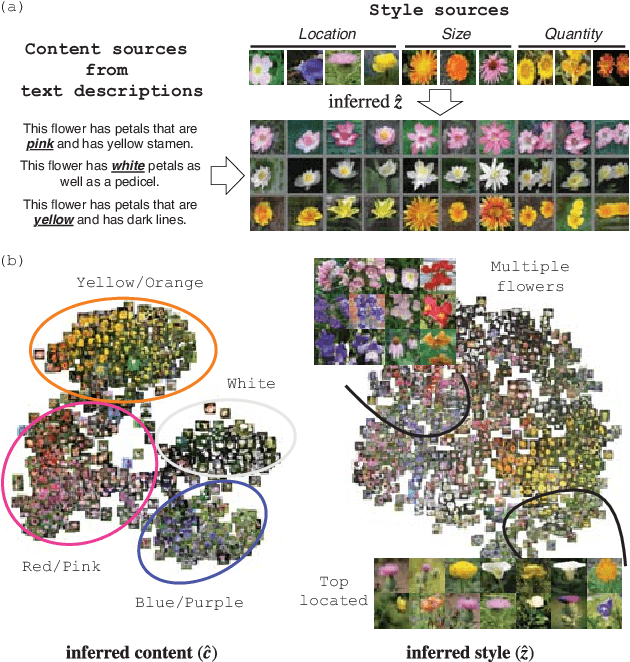
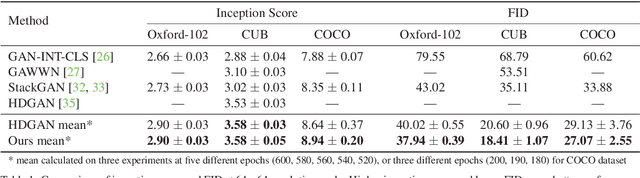
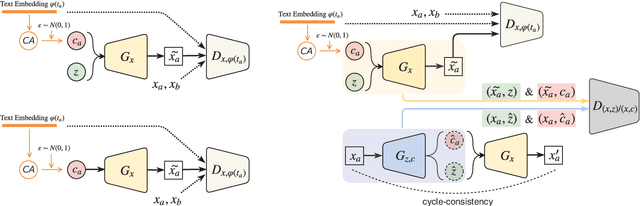
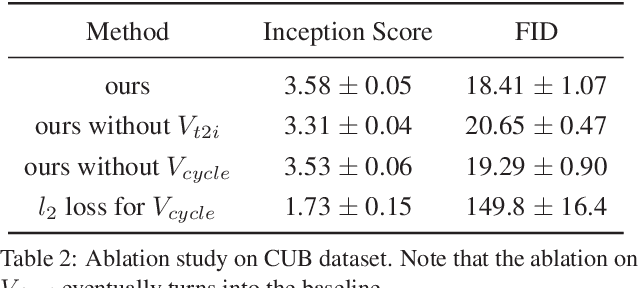
Synthesizing images from a given text description involves engaging two types of information: the content, which includes information explicitly described in the text (e.g., color, composition, etc.), and the style, which is usually not well described in the text (e.g., location, quantity, size, etc.). However, in previous works, it is typically treated as a process of generating images only from the content, i.e., without considering learning meaningful style representations. In this paper, we aim to learn two variables that are disentangled in the latent space, representing content and style respectively. We achieve this by augmenting current text-to-image synthesis frameworks with a dual adversarial inference mechanism. Through extensive experiments, we show that our model learns, in an unsupervised manner, style representations corresponding to certain meaningful information present in the image that are not well described in the text. The new framework also improves the quality of synthesized images when evaluated on Oxford-102, CUB and COCO datasets.
Quantized convolutional neural networks through the lens of partial differential equations
Aug 31, 2021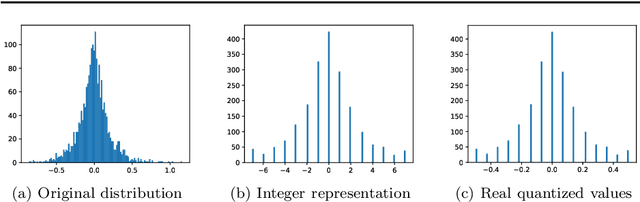


Quantization of Convolutional Neural Networks (CNNs) is a common approach to ease the computational burden involved in the deployment of CNNs, especially on low-resource edge devices. However, fixed-point arithmetic is not natural to the type of computations involved in neural networks. In this work, we explore ways to improve quantized CNNs using PDE-based perspective and analysis. First, we harness the total variation (TV) approach to apply edge-aware smoothing to the feature maps throughout the network. This aims to reduce outliers in the distribution of values and promote piece-wise constant maps, which are more suitable for quantization. Secondly, we consider symmetric and stable variants of common CNNs for image classification, and Graph Convolutional Networks (GCNs) for graph node-classification. We demonstrate through several experiments that the property of forward stability preserves the action of a network under different quantization rates. As a result, stable quantized networks behave similarly to their non-quantized counterparts even though they rely on fewer parameters. We also find that at times, stability even aids in improving accuracy. These properties are of particular interest for sensitive, resource-constrained, low-power or real-time applications like autonomous driving.
Data, Assemble: Leveraging Multiple Datasets with Heterogeneous and Partial Labels
Sep 25, 2021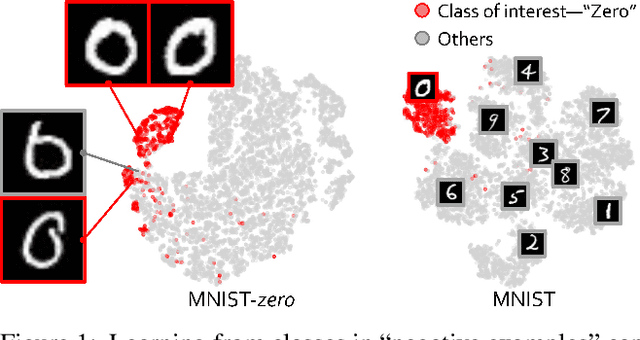
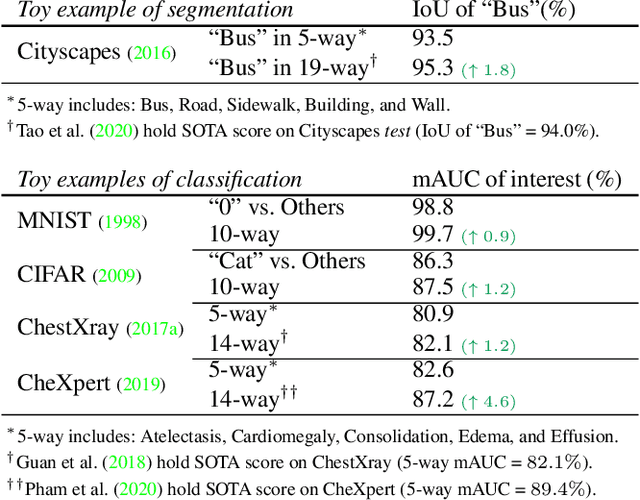
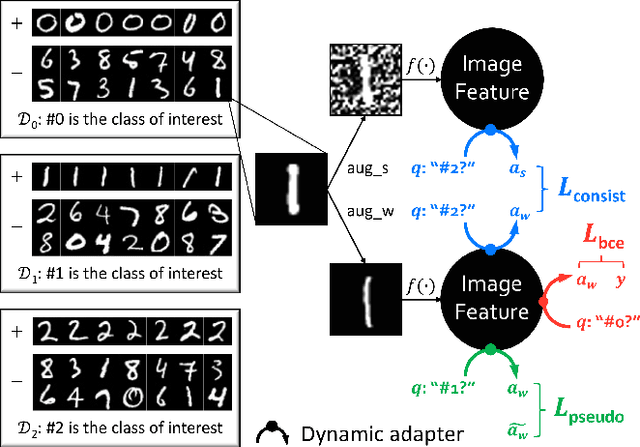

The success of deep learning relies heavily on large datasets with extensive labels, but we often only have access to several small, heterogeneous datasets associated with partial labels, particularly in the field of medical imaging. When learning from multiple datasets, existing challenges include incomparable, heterogeneous, or even conflicting labeling protocols across datasets. In this paper, we propose a new initiative--"data, assemble"--which aims to unleash the full potential of partially labeled data and enormous unlabeled data from an assembly of datasets. To accommodate the supervised learning paradigm to partial labels, we introduce a dynamic adapter that encodes multiple visual tasks and aggregates image features in a question-and-answer manner. Furthermore, we employ pseudo-labeling and consistency constraints to harness images with missing labels and to mitigate the domain gap across datasets. From proof-of-concept studies on three natural imaging datasets and rigorous evaluations on two large-scale thorax X-ray benchmarks, we discover that learning from "negative examples" facilitates both classification and segmentation of classes of interest. This sheds new light on the computer-aided diagnosis of rare diseases and emerging pandemics, wherein "positive examples" are hard to collect, yet "negative examples" are relatively easier to assemble. As a result, besides exceeding the prior art in the NIH ChestXray benchmark, our model is particularly strong in identifying diseases of minority classes, yielding over 3-point improvement on average. Remarkably, when using existing partial labels, our model performance is on-par (p>0.05) with that using a fully curated dataset with exhaustive labels, eliminating the need for additional 40% annotation costs.
Towards Better Adversarial Synthesis of Human Images from Text
Jul 05, 2021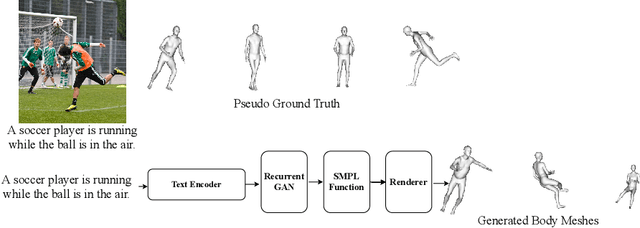
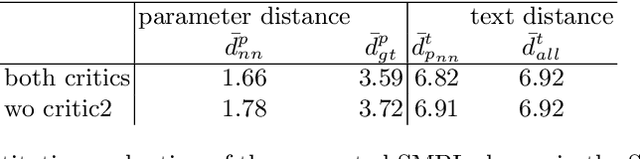

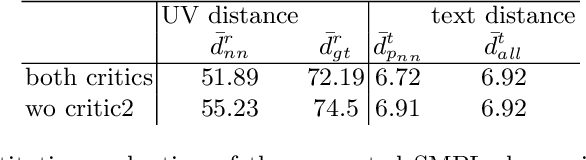
This paper proposes an approach that generates multiple 3D human meshes from text. The human shapes are represented by 3D meshes based on the SMPL model. The model's performance is evaluated on the COCO dataset, which contains challenging human shapes and intricate interactions between individuals. The model is able to capture the dynamics of the scene and the interactions between individuals based on text. We further show how using such a shape as input to image synthesis frameworks helps to constrain the network to synthesize humans with realistic human shapes.
DensePose 3D: Lifting Canonical Surface Maps of Articulated Objects to the Third Dimension
Aug 31, 2021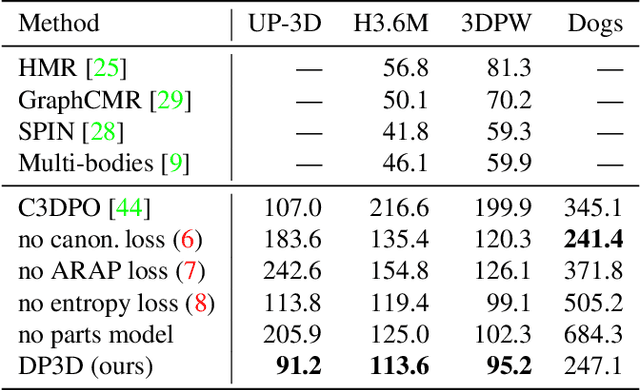
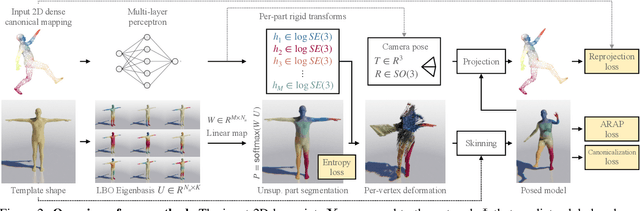
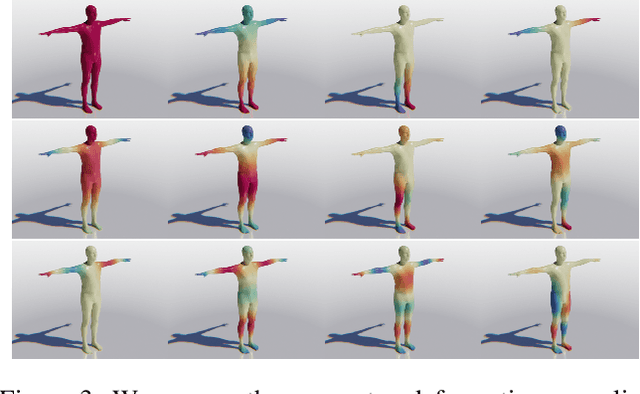

We tackle the problem of monocular 3D reconstruction of articulated objects like humans and animals. We contribute DensePose 3D, a method that can learn such reconstructions in a weakly supervised fashion from 2D image annotations only. This is in stark contrast with previous deformable reconstruction methods that use parametric models such as SMPL pre-trained on a large dataset of 3D object scans. Because it does not require 3D scans, DensePose 3D can be used for learning a wide range of articulated categories such as different animal species. The method learns, in an end-to-end fashion, a soft partition of a given category-specific 3D template mesh into rigid parts together with a monocular reconstruction network that predicts the part motions such that they reproject correctly onto 2D DensePose-like surface annotations of the object. The decomposition of the object into parts is regularized by expressing part assignments as a combination of the smooth eigenfunctions of the Laplace-Beltrami operator. We show significant improvements compared to state-of-the-art non-rigid structure-from-motion baselines on both synthetic and real data on categories of humans and animals.
Instagram Filter Removal on Fashionable Images
Apr 11, 2021
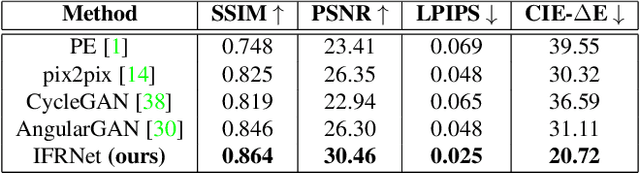

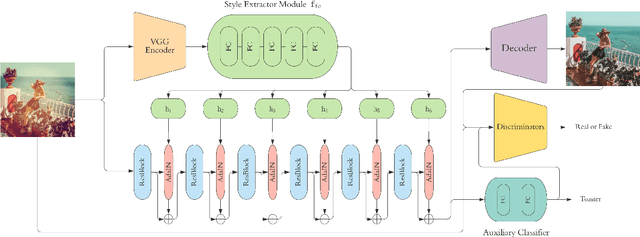
Social media images are generally transformed by filtering to obtain aesthetically more pleasing appearances. However, CNNs generally fail to interpret both the image and its filtered version as the same in the visual analysis of social media images. We introduce Instagram Filter Removal Network (IFRNet) to mitigate the effects of image filters for social media analysis applications. To achieve this, we assume any filter applied to an image substantially injects a piece of additional style information to it, and we consider this problem as a reverse style transfer problem. The visual effects of filtering can be directly removed by adaptively normalizing external style information in each level of the encoder. Experiments demonstrate that IFRNet outperforms all compared methods in quantitative and qualitative comparisons, and has the ability to remove the visual effects to a great extent. Additionally, we present the filter classification performance of our proposed model, and analyze the dominant color estimation on the images unfiltered by all compared methods.
Morphence: Moving Target Defense Against Adversarial Examples
Aug 31, 2021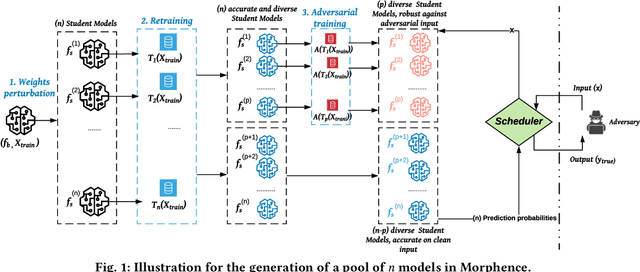
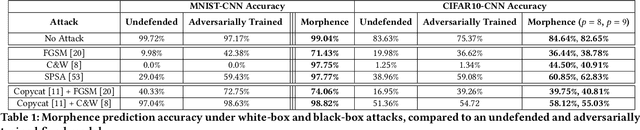
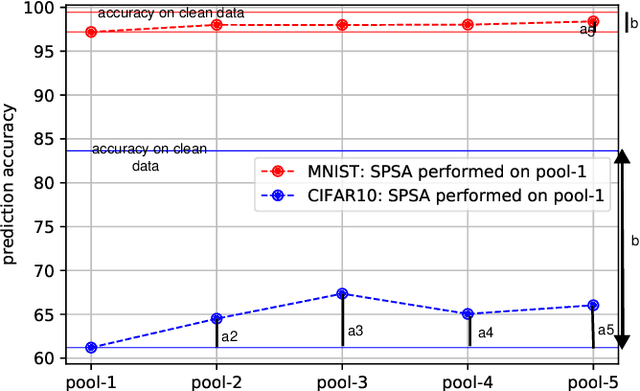
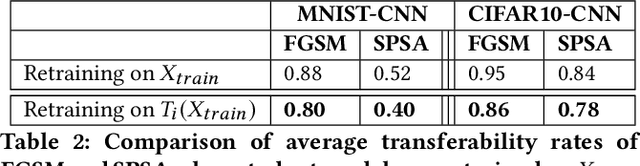
Robustness to adversarial examples of machine learning models remains an open topic of research. Attacks often succeed by repeatedly probing a fixed target model with adversarial examples purposely crafted to fool it. In this paper, we introduce Morphence, an approach that shifts the defense landscape by making a model a moving target against adversarial examples. By regularly moving the decision function of a model, Morphence makes it significantly challenging for repeated or correlated attacks to succeed. Morphence deploys a pool of models generated from a base model in a manner that introduces sufficient randomness when it responds to prediction queries. To ensure repeated or correlated attacks fail, the deployed pool of models automatically expires after a query budget is reached and the model pool is seamlessly replaced by a new model pool generated in advance. We evaluate Morphence on two benchmark image classification datasets (MNIST and CIFAR10) against five reference attacks (2 white-box and 3 black-box). In all cases, Morphence consistently outperforms the thus-far effective defense, adversarial training, even in the face of strong white-box attacks, while preserving accuracy on clean data.
Axial-to-lateral super-resolution for 3D fluorescence microscopy using unsupervised deep learning
Apr 19, 2021
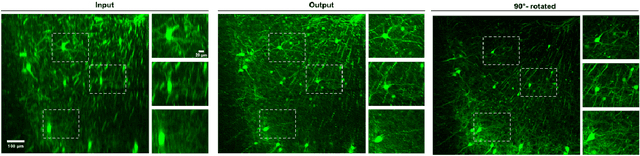
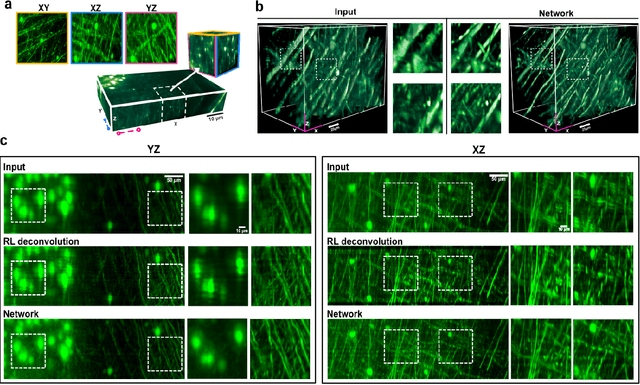
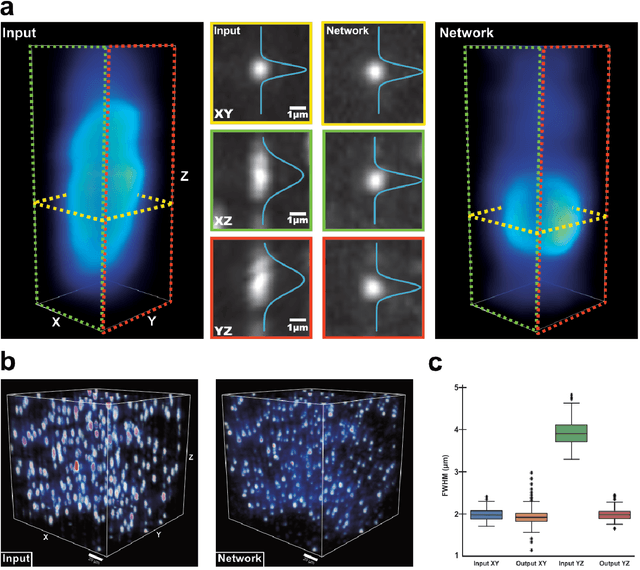
Volumetric imaging by fluorescence microscopy is often limited by anisotropic spatial resolution from inferior axial resolution compared to the lateral resolution. To address this problem, here we present a deep-learning-enabled unsupervised super-resolution technique that enhances anisotropic images in volumetric fluorescence microscopy. In contrast to the existing deep learning approaches that require matched high-resolution target volume images, our method greatly reduces the effort to put into practice as the training of a network requires as little as a single 3D image stack, without a priori knowledge of the image formation process, registration of training data, or separate acquisition of target data. This is achieved based on the optimal transport driven cycle-consistent generative adversarial network that learns from an unpaired matching between high-resolution 2D images in lateral image plane and low-resolution 2D images in the other planes. Using fluorescence confocal microscopy and light-sheet microscopy, we demonstrate that the trained network not only enhances axial resolution beyond the diffraction limit, but also enhances suppressed visual details between the imaging planes and removes imaging artifacts.
DiaRet: A browser-based application for the grading of Diabetic Retinopathy with Integrated Gradients
Apr 11, 2021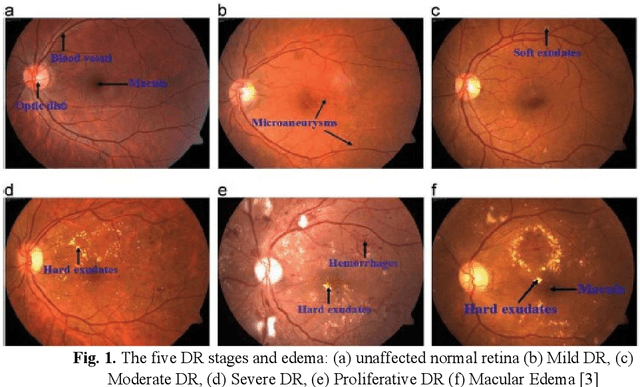



Patients with long-standing diabetes often fall prey to Diabetic Retinopathy (DR) resulting in changes in the retina of the human eye, which may lead to loss of vision in extreme cases. The aim of this study is two-fold: (a) create deep learning models that were trained to grade degraded retinal fundus images and (b) to create a browser-based application that will aid in diagnostic procedures by highlighting the key features of the fundus image. In this research work, we have emulated the images plagued by distortions by degrading the images based on multiple different combinations of Light Transmission Disturbance, Image Blurring and insertion of Retinal Artifacts. InceptionV3, ResNet-50 and InceptionResNetV2 were trained and used to classify retinal fundus images based on their severity level and then further used in the creation of a browser-based application, which implements the Integration Gradient (IG) Attribution Mask on the input image and demonstrates the predictions made by the model and the probability associated with each class.