 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Align2Ground: Weakly Supervised Phrase Grounding Guided by Image-Caption Alignment
Mar 27, 2019
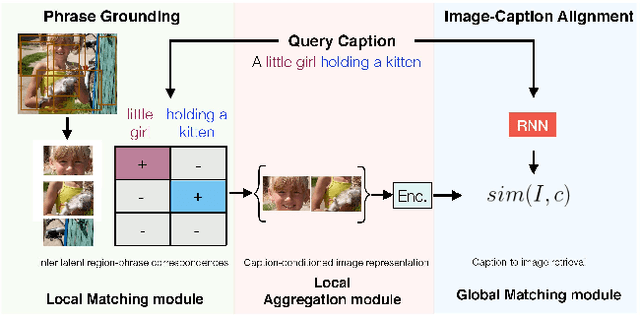
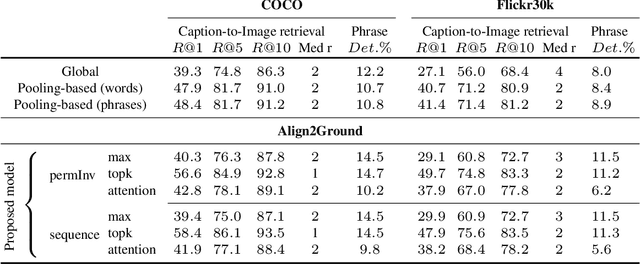

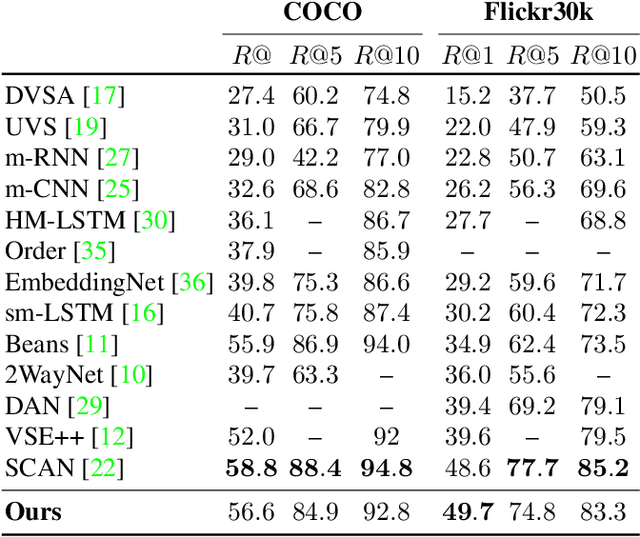
We address the problem of grounding free-form textual phrases by using weak supervision from image-caption pairs. We propose a novel end-to-end model that uses caption-to-image retrieval as a `downstream' task to guide the process of phrase localization. Our method, as a first step, infers the latent correspondences between regions-of-interest (RoIs) and phrases in the caption and creates a discriminative image representation using these matched RoIs. In a subsequent step, this (learned) representation is aligned with the caption. Our key contribution lies in building this `caption-conditioned' image encoding which tightly couples both the tasks and allows the weak supervision to effectively guide visual grounding. We provide an extensive empirical and qualitative analysis to investigate the different components of our proposed model and compare it with competitive baselines. For phrase localization, we report an improvement of 4.9% (absolute) over the prior state-of-the-art on the VisualGenome dataset. We also report results that are at par with the state-of-the-art on the downstream caption-to-image retrieval task on COCO and Flickr30k datasets.
Learning Fuzzy Clustering for SPECT/CT Segmentation via Convolutional Neural Networks
Apr 17, 2021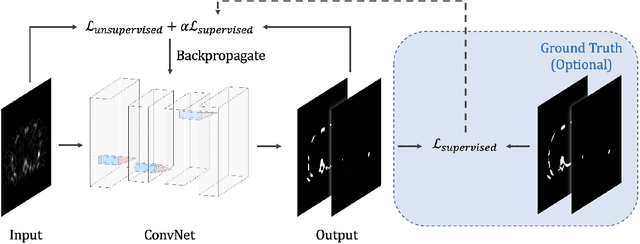
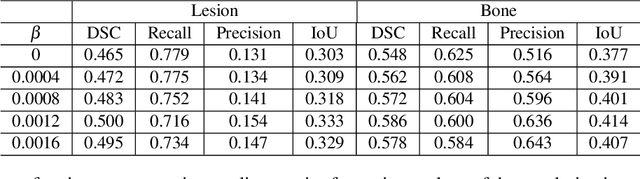
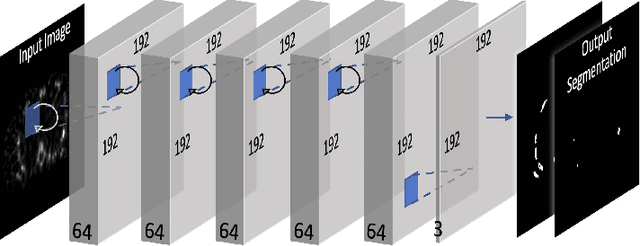
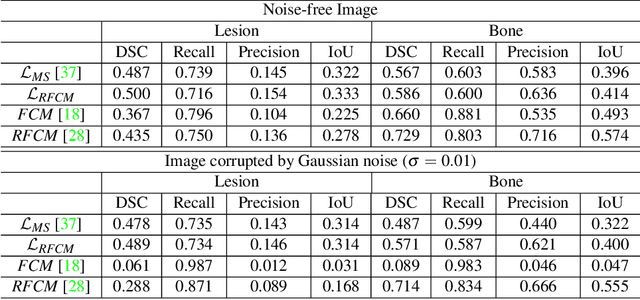
Quantitative bone single-photon emission computed tomography (QBSPECT) has the potential to provide a better quantitative assessment of bone metastasis than planar bone scintigraphy due to its ability to better quantify activity in overlapping structures. An important element of assessing response of bone metastasis is accurate image segmentation. However, limited by the properties of QBSPECT images, the segmentation of anatomical regions-of-interests (ROIs) still relies heavily on the manual delineation by experts. This work proposes a fast and robust automated segmentation method for partitioning a QBSPECT image into lesion, bone, and background. We present a new unsupervised segmentation loss function and its semi- and supervised variants for training a convolutional neural network (ConvNet). The loss functions were developed based on the objective function of the classical Fuzzy C-means (FCM) algorithm. We conducted a comprehensive study to compare our proposed methods with ConvNets trained using supervised loss functions and conventional clustering methods. The Dice similarity coefficient (DSC) and several other metrics were used as figures of merit as applied to the task of delineating lesion and bone in both simulated and clinical SPECT/CT images. We experimentally demonstrated that the proposed methods yielded good segmentation results on a clinical dataset even though the training was done using realistic simulated images. A ConvNet-based image segmentation method that uses novel loss functions was developed and evaluated. The method can operate in unsupervised, semi-supervised, or fully-supervised modes depending on the availability of annotated training data. The results demonstrated that the proposed method provides fast and robust lesion and bone segmentation for QBSPECT/CT. The method can potentially be applied to other medical image segmentation applications.
Learning Category Correlations for Multi-label Image Recognition with Graph Networks
Sep 28, 2019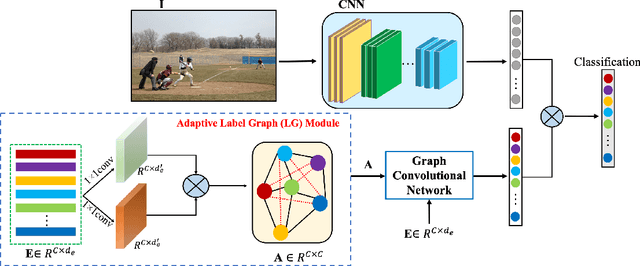
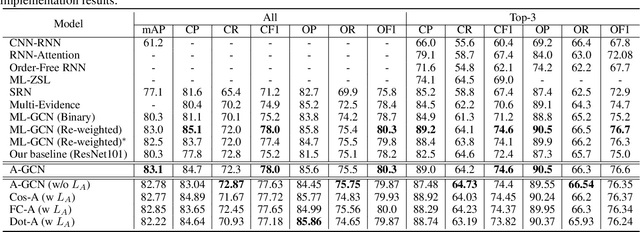
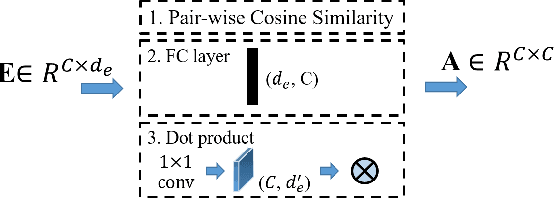
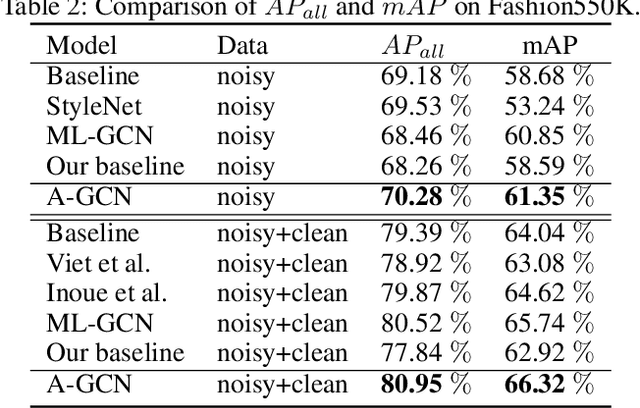
Multi-label image recognition is a task that predicts a set of object labels in an image. As the objects co-occur in the physical world, it is desirable to model label dependencies. Previous existing methods resort to either recurrent networks or pre-defined label correlation graphs for this purpose. In this paper, instead of using a pre-defined graph which is inflexible and may be sub-optimal for multi-label classification, we propose the A-GCN, which leverages the popular Graph Convolutional Networks with an Adaptive label correlation graph to model label dependencies. Specifically, we introduce a plug-and-play Label Graph (LG) module to learn label correlations with word embeddings, and then utilize traditional GCN to map this graph into label-dependent object classifiers which are further applied to image features. The basic LG module incorporates two 1x1 convolutional layers and uses the dot product to generate label graphs. In addition, we propose a sparse correlation constraint to enhance the LG module and also explore different LG architectures. We validate our method on two diverse multi-label datasets: MS-COCO and Fashion550K. Experimental results show that our A-GCN significantly improves baseline methods and achieves performance superior or comparable to the state of the art.
NLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising
Aug 04, 2019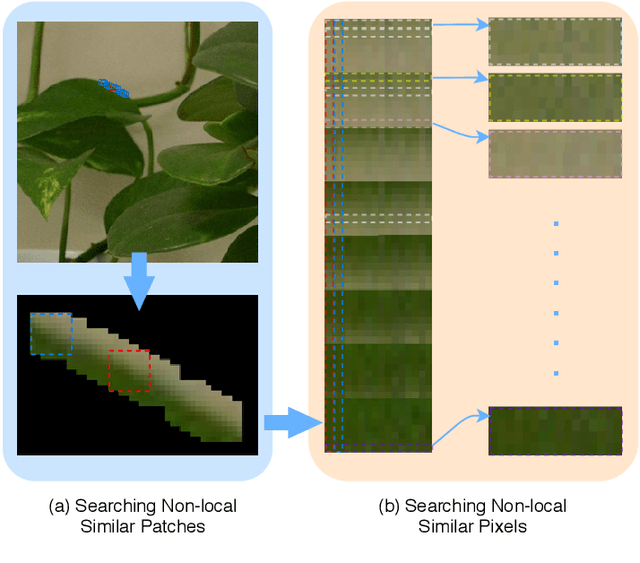
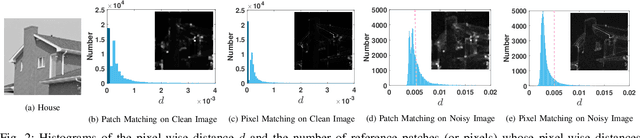
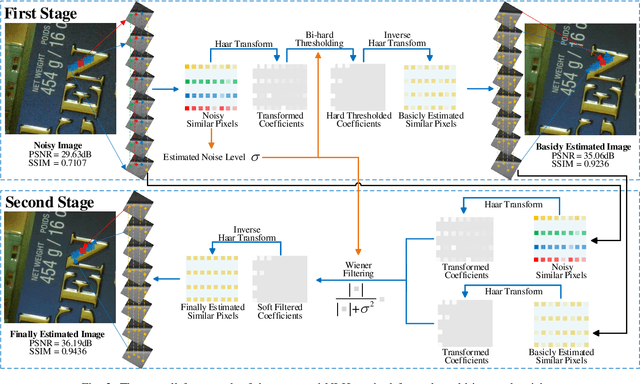

Non-local self similarity (NSS) is a powerful prior of natural images for image denoising. Most of existing denoising methods employ similar patches, which is a patch-level NSS prior. In this paper, we take one step forward by introducing a pixel-level NSS prior, i.e., searching similar pixels across a non-local region. This is motivated by the fact that finding closely similar pixels is more feasible than similar patches in natural images, which can be used to enhance image denoising performance. With the introduced pixel-level NSS prior, we propose an accurate noise level estimation method, and then develop a blind image denoising method based on the lifting Haar transform and Wiener filtering techniques. Experiments on benchmark datasets demonstrate that, the proposed method achieves much better performance than state-of-the-art methods on real-world image denoising. The code will be released.
Leveraging Self-supervised Denoising for Image Segmentation
Nov 27, 2019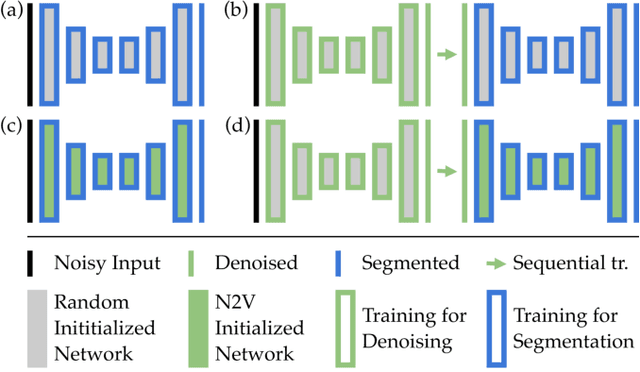
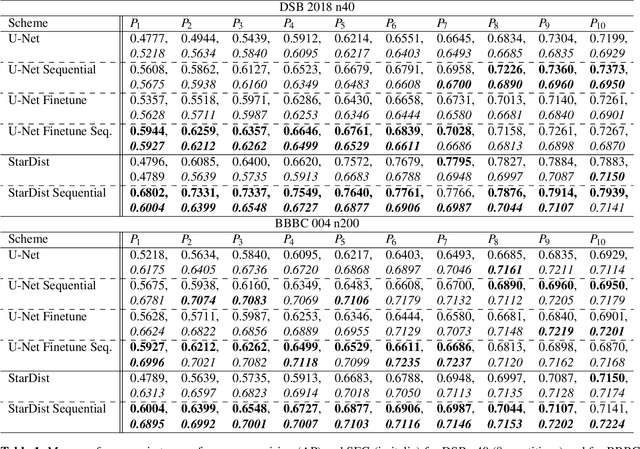
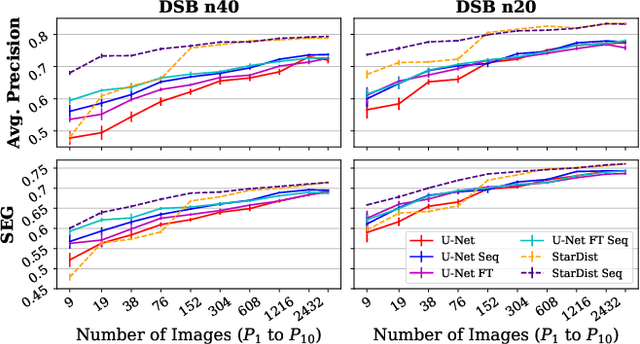
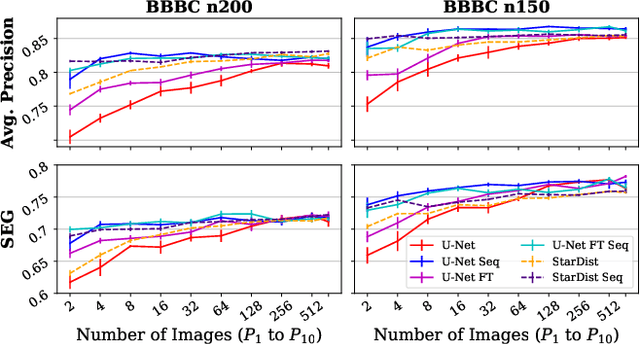
Deep learning (DL) has arguably emerged as the method of choice for the detection and segmentation of biological structures in microscopy images. However, DL typically needs copious amounts of annotated training data that is for biomedical projects typically not available and excessively expensive to generate. Additionally, tasks become harder in the presence of noise, requiring even more high-quality training data. Hence, we propose to use denoising networks to improve the performance of other DL-based image segmentation methods. More specifically, we present ideas on how state-of-the-art self-supervised CARE networks can improve cell/nuclei segmentation in microscopy data. Using two state-of-the-art baseline methods, U-Net and StarDist, we show that our ideas consistently improve the quality of resulting segmentations, especially when only limited training data for noisy micrographs are available.
Describing like humans: on diversity in image captioning
Apr 01, 2019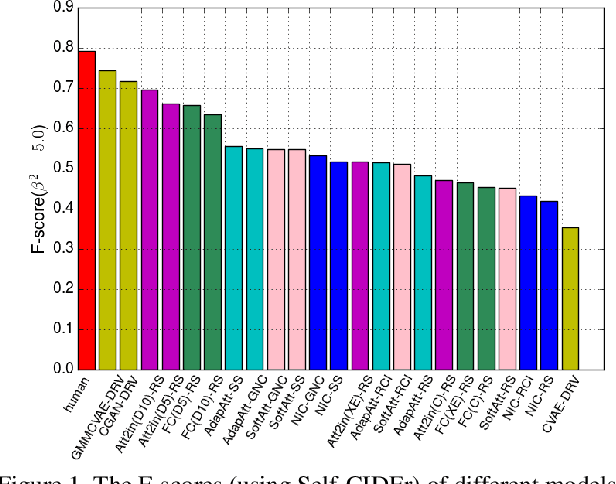
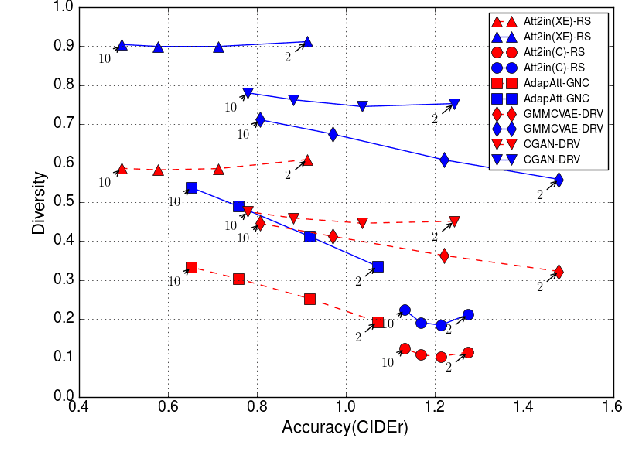
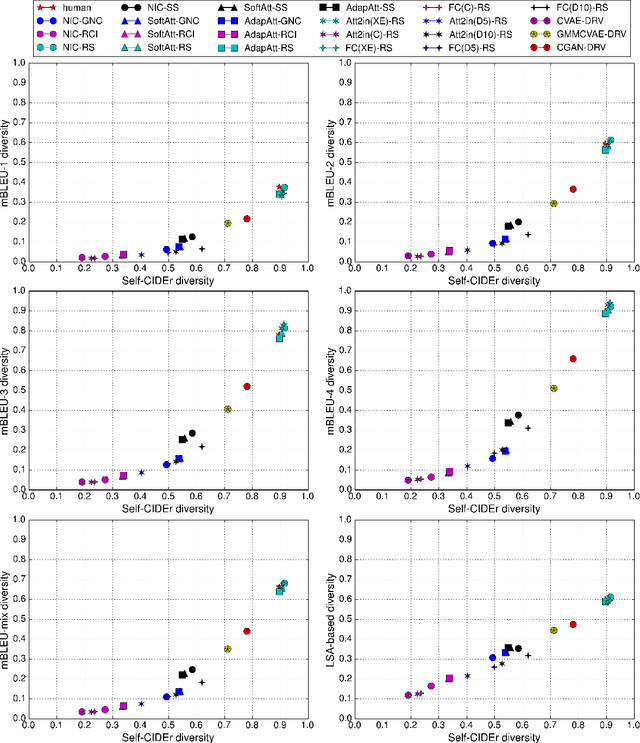
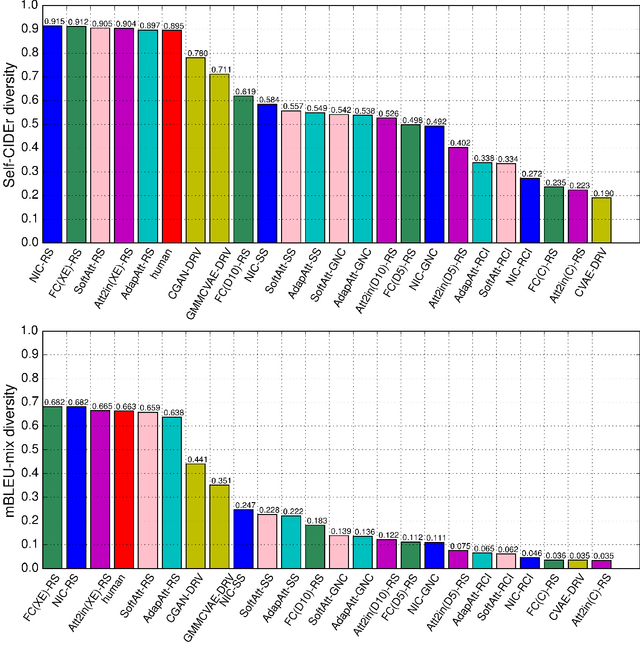
Recently, the state-of-the-art models for image captioning have overtaken human performance based on the most popular metrics, such as BLEU, METEOR, ROUGE, and CIDEr. Does this mean we have solved the task of image captioning? The above metrics only measure the similarity of the generated caption to the human annotations, which reflects its accuracy. However, an image contains many concepts and multiple levels of detail, and thus there is a variety of captions that express different concepts and details that might be interesting for different humans. Therefore only evaluating accuracy is not sufficient for measuring the performance of captioning models --- the diversity of the generated captions should also be considered. In this paper, we proposed a new metric for measuring the diversity of image captions, which is derived from latent semantic analysis and kernelized to use CIDEr similarity. We conduct extensive experiments to re-evaluate recent captioning models in the context of both diversity and accuracy. We find that there is still a large gap between the model and human performance in terms of both accuracy and diversity and the models that have optimized accuracy (CIDEr) have low diversity. We also show that balancing the cross-entropy loss and CIDEr reward in reinforcement learning during training can effectively control the tradeoff between diversity and accuracy of the generated captions.
Self-Adaptive 2D-3D Ensemble of Fully Convolutional Networks for Medical Image Segmentation
Jul 26, 2019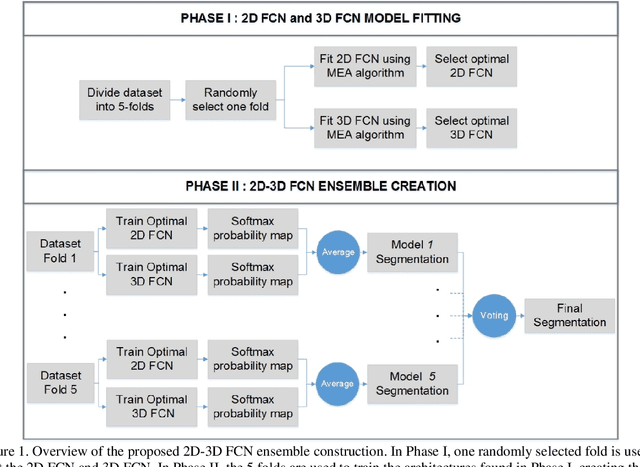

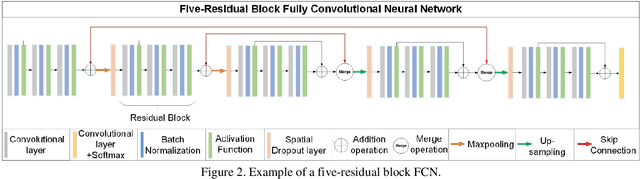
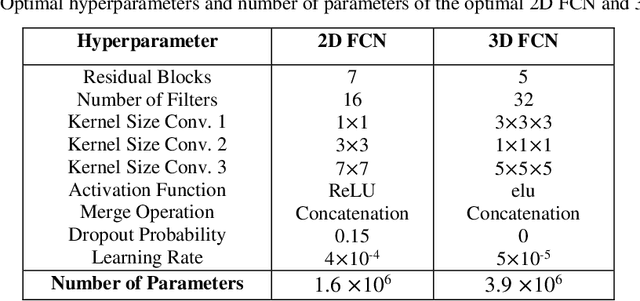
Segmentation is a critical step in medical image analysis. Fully Convolutional Networks (FCNs) have emerged as powerful segmentation models achieving state-of-the-art results in various medical image datasets. Network architectures are usually designed manually for a specific segmentation task so applying them to other medical datasets requires extensive experience and time. Moreover, the segmentation requires handling large volumetric data that results in big and complex architectures. Recently, methods that automatically design neural networks for medical image segmentation have been presented; however, most approaches either do not fully consider volumetric information or do not optimize the size of the network. In this paper, we propose a novel self-adaptive 2D-3D ensemble of FCNs for medical image segmentation that incorporates volumetric information and optimizes both the model's performance and size. The model is composed of an ensemble of a 2D FCN that extracts intra-slice information, and a 3D FCN that exploits inter-slice information. The architectures of the 2D and 3D FCNs are automatically adapted to a medical image dataset using a multiobjective evolutionary based algorithm that minimizes both the segmentation error and number of parameters in the network. The proposed 2D-3D FCN ensemble was tested on the task of prostate segmentation on the image dataset from the PROMISE12 Grand Challenge. The resulting network is ranked in the top 10 submissions, surpassing the performance of other automatically-designed architectures while being considerably smaller in size.
Spatially Consistent Representation Learning
Mar 10, 2021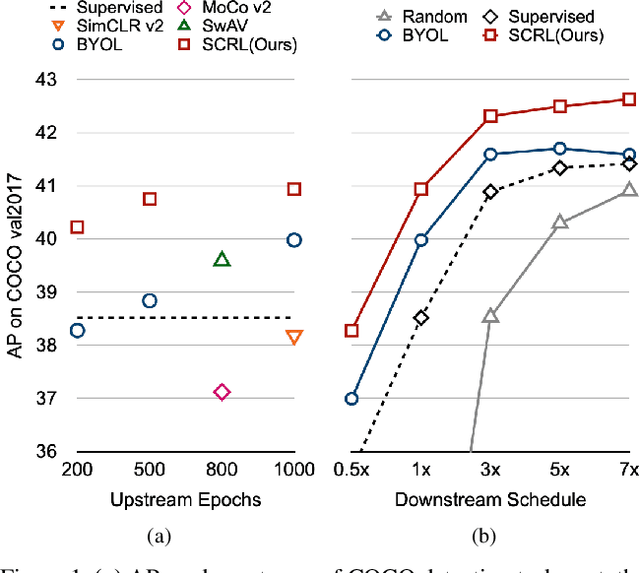

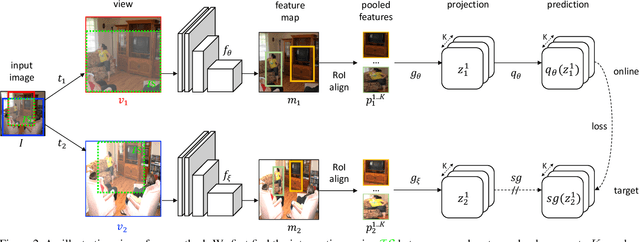
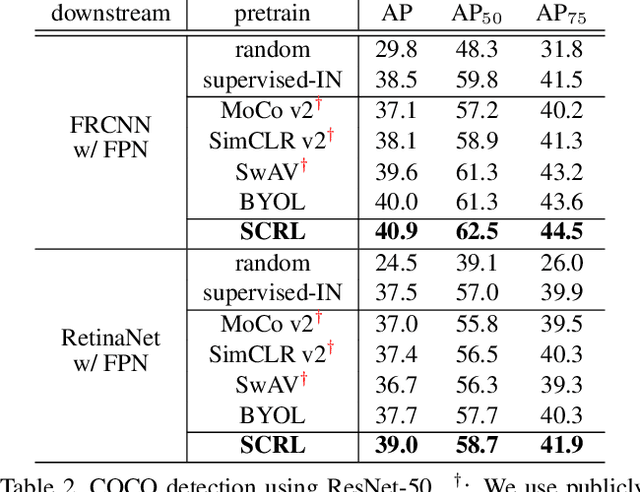
Self-supervised learning has been widely used to obtain transferrable representations from unlabeled images. Especially, recent contrastive learning methods have shown impressive performances on downstream image classification tasks. While these contrastive methods mainly focus on generating invariant global representations at the image-level under semantic-preserving transformations, they are prone to overlook spatial consistency of local representations and therefore have a limitation in pretraining for localization tasks such as object detection and instance segmentation. Moreover, aggressively cropped views used in existing contrastive methods can minimize representation distances between the semantically different regions of a single image. In this paper, we propose a spatially consistent representation learning algorithm (SCRL) for multi-object and location-specific tasks. In particular, we devise a novel self-supervised objective that tries to produce coherent spatial representations of a randomly cropped local region according to geometric translations and zooming operations. On various downstream localization tasks with benchmark datasets, the proposed SCRL shows significant performance improvements over the image-level supervised pretraining as well as the state-of-the-art self-supervised learning methods.
Single Image Reflection Removal with Physically-based Rendering
Apr 26, 2019

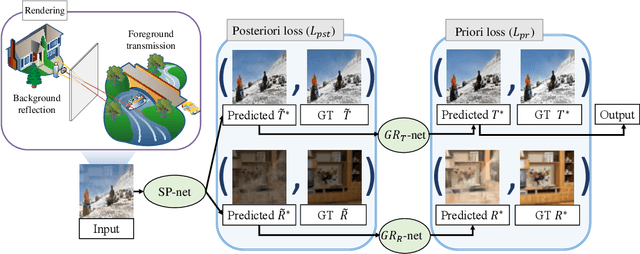
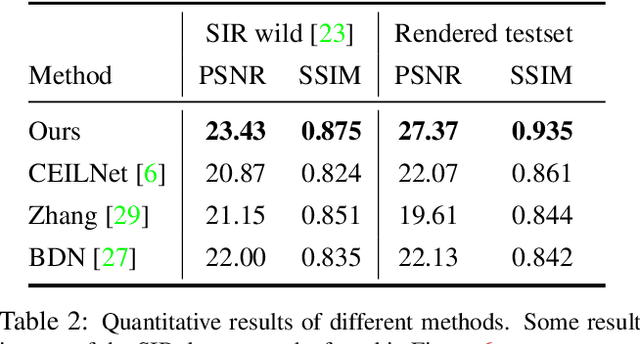
Recently, deep learning based single image reflection separation methods have been exploited widely. To benefit the learning approach, a large number of training image pairs (i.e., with and without reflections) were synthesized in various ways, yet they are away from a physically-based direction. In this paper, physically based rendering is used for faithfully synthesizing the required training images, and corresponding network structure is proposed. We utilize existing image data to estimate mesh, then physically simulate the depth-dependent light transportation between mesh, glass, and lens with path tracing. For guiding the separation better, we additionally consider a module of removing complicated ghosting and blurring glass-effects, which allows obtaining priori information before having the glass distortion. This module is easily accommodated within our approach, since that prior information can be physically generated by our rendering process. The proposed method considering the priori information as well as the existing posterior information is validated with various real reflection images, and is demonstrated to show visually pleasant and numerically better results compared to the state-of-theart techniques.
Toward Accurate and Realistic Outfits Visualization with Attention to Details
Jun 11, 2021
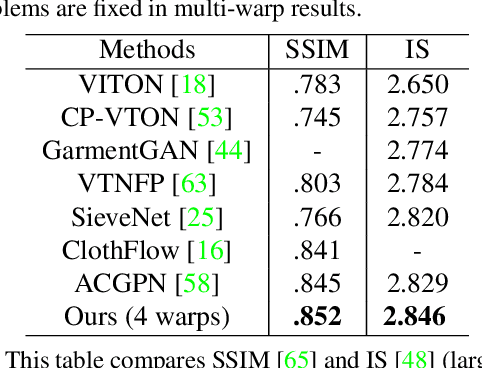


Virtual try-on methods aim to generate images of fashion models wearing arbitrary combinations of garments. This is a challenging task because the generated image must appear realistic and accurately display the interaction between garments. Prior works produce images that are filled with artifacts and fail to capture important visual details necessary for commercial applications. We propose Outfit Visualization Net (OVNet) to capture these important details (e.g. buttons, shading, textures, realistic hemlines, and interactions between garments) and produce high quality multiple-garment virtual try-on images. OVNet consists of 1) a semantic layout generator and 2) an image generation pipeline using multiple coordinated warps. We train the warper to output multiple warps using a cascade loss, which refines each successive warp to focus on poorly generated regions of a previous warp and yields consistent improvements in detail. In addition, we introduce a method for matching outfits with the most suitable model and produce significant improvements for both our and other previous try-on methods. Through quantitative and qualitative analysis, we demonstrate our method generates substantially higher-quality studio images compared to prior works for multi-garment outfits. An interactive interface powered by this method has been deployed on fashion e-commerce websites and received overwhelmingly positive feedback.