 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Very Compact Clusters with Structural Regularization via Similarity and Connectivity
Jun 14, 2021

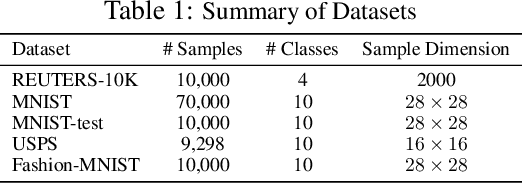
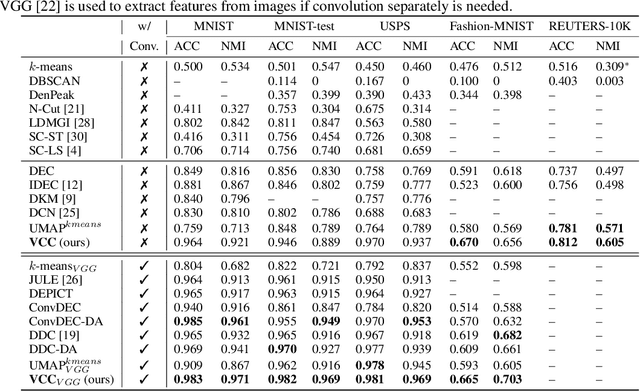
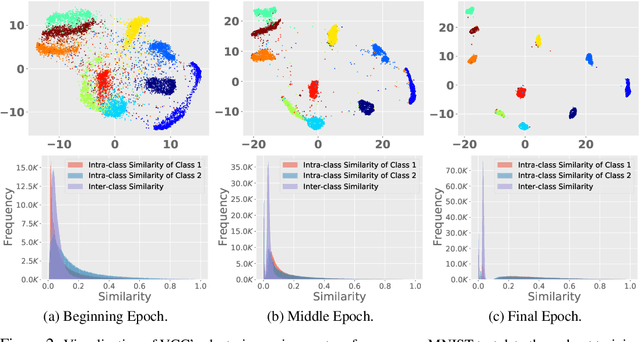
Clustering algorithms have significantly improved along with Deep Neural Networks which provide effective representation of data. Existing methods are built upon deep autoencoder and self-training process that leverages the distribution of cluster assignments of samples. However, as the fundamental objective of the autoencoder is focused on efficient data reconstruction, the learnt space may be sub-optimal for clustering. Moreover, it requires highly effective codes (i.e., representation) of data, otherwise the initial cluster centers often cause stability issues during self-training. Many state-of-the-art clustering algorithms use convolution operation to extract efficient codes but their applications are limited to image data. In this regard, we propose an end-to-end deep clustering algorithm, i.e., Very Compact Clusters (VCC), for the general datasets, which takes advantage of distributions of local relationships of samples near the boundary of clusters, so that they can be properly separated and pulled to cluster centers to form compact clusters. Experimental results on various datasets illustrate that our proposed approach achieves better clustering performance over most of the state-of-the-art clustering methods, and the data embeddings learned by VCC without convolution for image data are even comparable with specialized convolutional methods.
Endless Loops: Detecting and Animating Periodic Patterns in Still Images
May 19, 2021
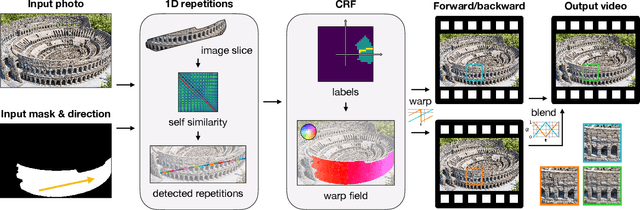

We present an algorithm for producing a seamless animated loop from a single image. The algorithm detects periodic structures, such as the windows of a building or the steps of a staircase, and generates a non-trivial displacement vector field that maps each segment of the structure onto a neighboring segment along a user- or auto-selected main direction of motion. This displacement field is used, together with suitable temporal and spatial smoothing, to warp the image and produce the frames of a continuous animation loop. Our cinemagraphs are created in under a second on a mobile device. Over 140,000 users downloaded our app and exported over 350,000 cinemagraphs. Moreover, we conducted two user studies that show that users prefer our method for creating surreal and structured cinemagraphs compared to more manual approaches and compared to previous methods.
* SIGGRAPH 2021. Project page: https://pub.res.lightricks.com/endless-loops/ . Video: https://youtu.be/8ZYUvxWuD2Y
A Unified Efficient Pyramid Transformer for Semantic Segmentation
Jul 29, 2021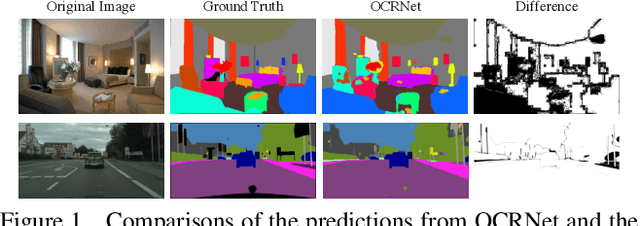
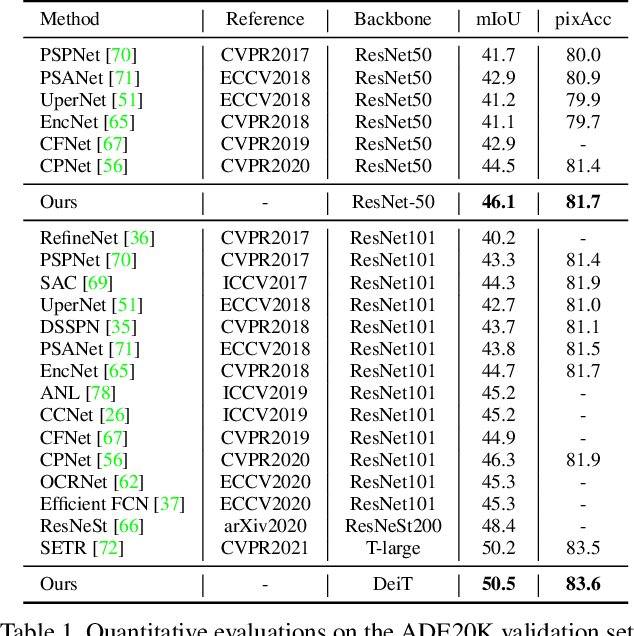
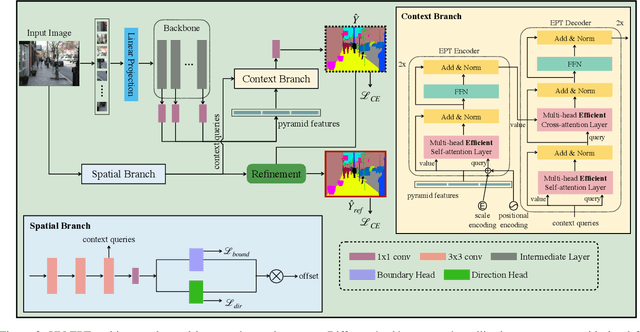
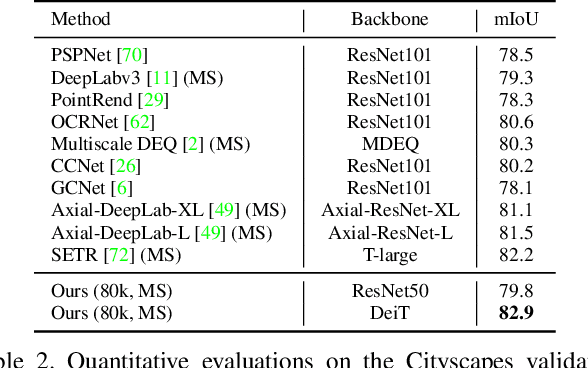
Semantic segmentation is a challenging problem due to difficulties in modeling context in complex scenes and class confusions along boundaries. Most literature either focuses on context modeling or boundary refinement, which is less generalizable in open-world scenarios. In this work, we advocate a unified framework(UN-EPT) to segment objects by considering both context information and boundary artifacts. We first adapt a sparse sampling strategy to incorporate the transformer-based attention mechanism for efficient context modeling. In addition, a separate spatial branch is introduced to capture image details for boundary refinement. The whole model can be trained in an end-to-end manner. We demonstrate promising performance on three popular benchmarks for semantic segmentation with low memory footprint. Code will be released soon.
Improved Hybrid Layered Image Compression using Deep Learning and Traditional Codecs
Jul 15, 2019
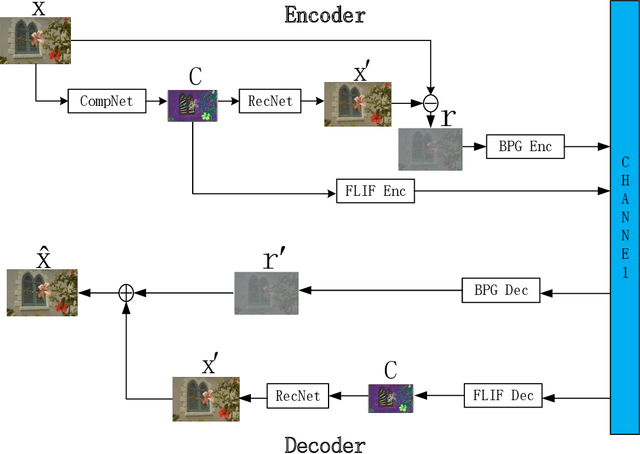
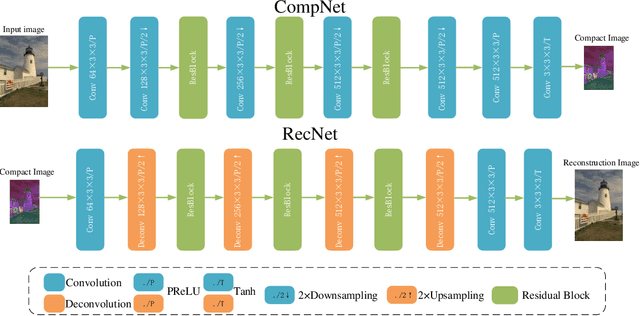
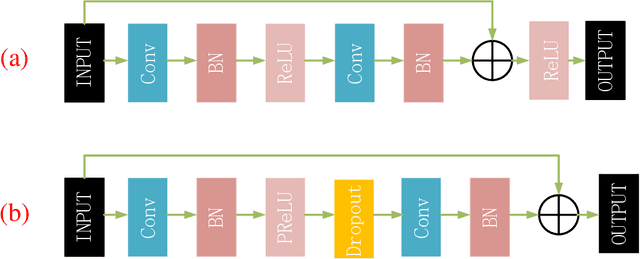
Recently deep learning-based methods have been applied in image compression and achieved many promising results. In this paper, we propose an improved hybrid layered image compression framework by combining deep learning and the traditional image codecs. At the encoder, we first use a convolutional neural network (CNN) to obtain a compact representation of the input image, which is losslessly encoded by the FLIF codec as the base layer of the bit stream. A coarse reconstruction of the input is obtained by another CNN from the reconstructed compact representation. The residual between the input and the coarse reconstruction is then obtained and encoded by the H.265/HEVC-based BPG codec as the enhancement layer of the bit stream. Experimental results using the Kodak and Tecnick datasets show that the proposed scheme outperforms the state-of-the-art deep learning-based layered coding scheme and traditional codecs including BPG in both PSNR and MS-SSIM metrics across a wide range of bit rates, when the images are coded in the RGB444 domain.
Pixel Sampling for Style Preserving Face Pose Editing
Jun 14, 2021


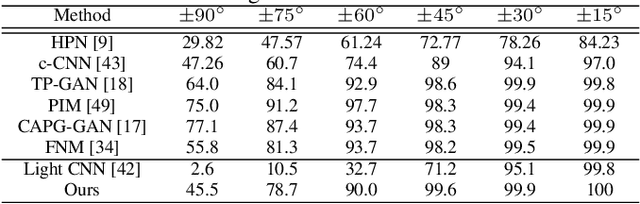
The existing auto-encoder based face pose editing methods primarily focus on modeling the identity preserving ability during pose synthesis, but are less able to preserve the image style properly, which refers to the color, brightness, saturation, etc. In this paper, we take advantage of the well-known frontal/profile optical illusion and present a novel two-stage approach to solve the aforementioned dilemma, where the task of face pose manipulation is cast into face inpainting. By selectively sampling pixels from the input face and slightly adjust their relative locations with the proposed ``Pixel Attention Sampling" module, the face editing result faithfully keeps the identity information as well as the image style unchanged. By leveraging high-dimensional embedding at the inpainting stage, finer details are generated. Further, with the 3D facial landmarks as guidance, our method is able to manipulate face pose in three degrees of freedom, i.e., yaw, pitch, and roll, resulting in more flexible face pose editing than merely controlling the yaw angle as usually achieved by the current state-of-the-art. Both the qualitative and quantitative evaluations validate the superiority of the proposed approach.
Image Inpainting by Adaptive Fusion of Variable Spline Interpolations
Nov 03, 2019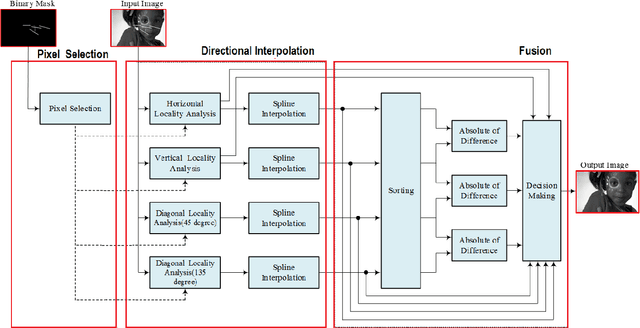
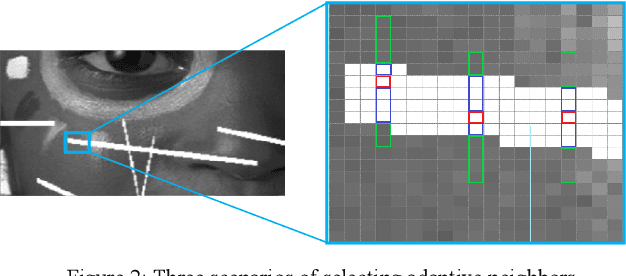

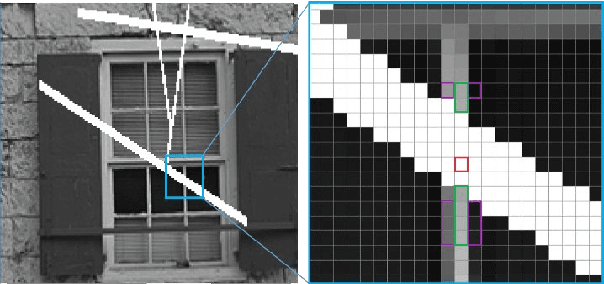
There are many methods for image enhancement. Image inpainting is one of them which could be used in reconstruction and restoration of scratch images or editing images by adding or removing objects. According to its application, different algorithmic and learning methods are proposed. In this paper, the focus is on applications, which enhance the old and historical scratched images. For this purpose, we proposed an adaptive spline interpolation. In this method, a different number of neighbors in four directions are considered for each pixel in the lost block. In the previous methods, predicting the lost pixels that are on edges is the problem. To address this problem, we consider horizontal and vertical edge information. If the pixel is located on an edge, then we use the predicted value in that direction. In other situations, irrelevant predicted values are omitted, and the average of rest values is used as the value of the missing pixel. The method evaluates by PSNR and SSIM metrics on the Kodak dataset. The results show improvement in PSNR and SSIM compared to similar procedures. Also, the run time of the proposed method outperforms others.
Identification of Social-Media Platform of Videos through the Use of Shared Features
Sep 08, 2021
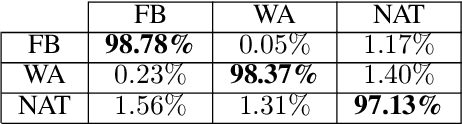
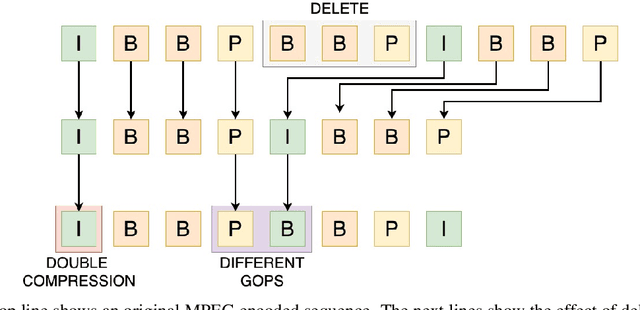
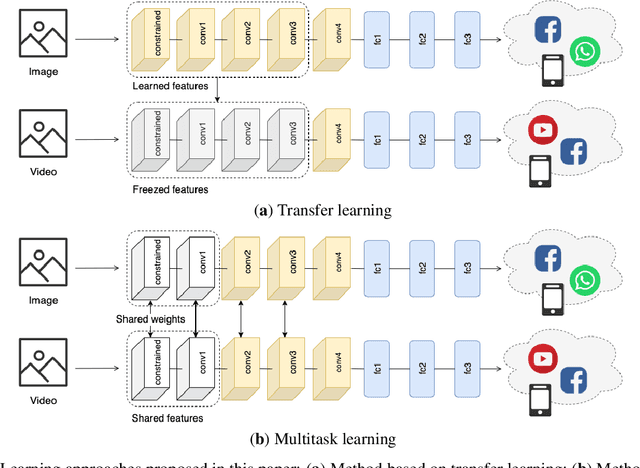
Videos have become a powerful tool for spreading illegal content such as military propaganda, revenge porn, or bullying through social networks. To counter these illegal activities, it has become essential to try new methods to verify the origin of videos from these platforms. However, collecting datasets large enough to train neural networks for this task has become difficult because of the privacy regulations that have been enacted in recent years. To mitigate this limitation, in this work we propose two different solutions based on transfer learning and multitask learning to determine whether a video has been uploaded from or downloaded to a specific social platform through the use of shared features with images trained on the same task. By transferring features from the shallowest to the deepest levels of the network from the image task to videos, we measure the amount of information shared between these two tasks. Then, we introduce a model based on multitask learning, which learns from both tasks simultaneously. The promising experimental results show, in particular, the effectiveness of the multitask approach. According to our knowledge, this is the first work that addresses the problem of social media platform identification of videos through the use of shared features.
Robust 1-bit Compressive Sensing with Partial Gaussian Circulant Matrices and Generative Priors
Aug 08, 2021

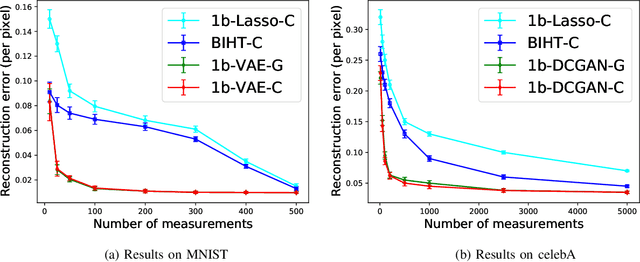

In 1-bit compressive sensing, each measurement is quantized to a single bit, namely the sign of a linear function of an unknown vector, and the goal is to accurately recover the vector. While it is most popular to assume a standard Gaussian sensing matrix for 1-bit compressive sensing, using structured sensing matrices such as partial Gaussian circulant matrices is of significant practical importance due to their faster matrix operations. In this paper, we provide recovery guarantees for a correlation-based optimization algorithm for robust 1-bit compressive sensing with randomly signed partial Gaussian circulant matrices and generative models. Under suitable assumptions, we match guarantees that were previously only known to hold for i.i.d.~Gaussian matrices that require significantly more computation. We make use of a practical iterative algorithm, and perform numerical experiments on image datasets to corroborate our theoretical results.
$μ$DARTS: Model Uncertainty-Aware Differentiable Architecture Search
Jul 24, 2021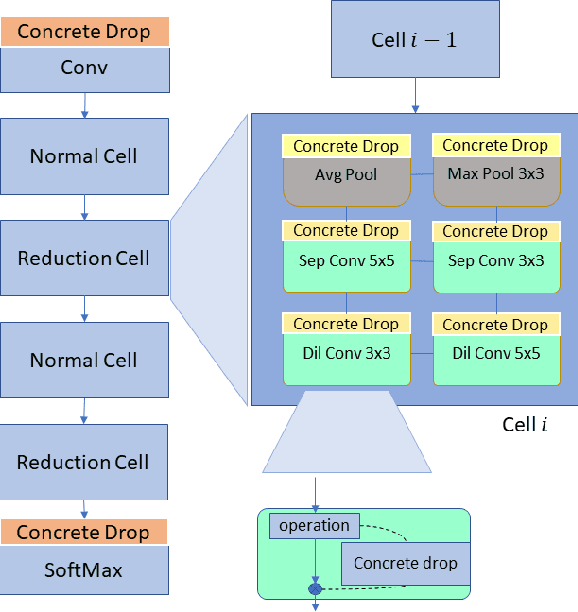
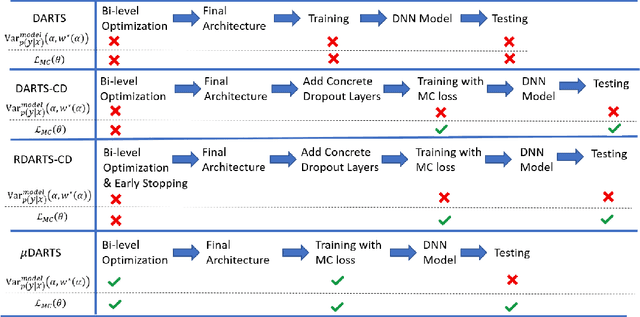
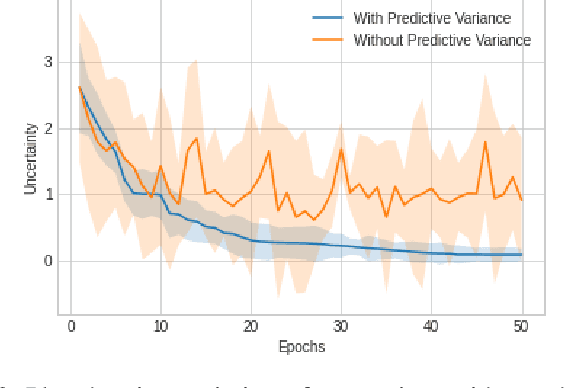
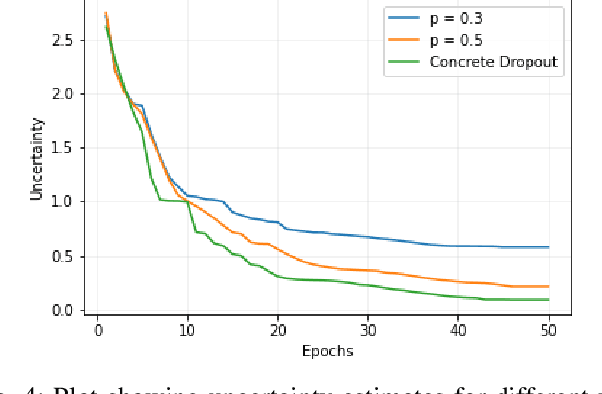
We present a Model Uncertainty-aware Differentiable ARchiTecture Search ($\mu$DARTS) that optimizes neural networks to simultaneously achieve high accuracy and low uncertainty. We introduce concrete dropout within DARTS cells and include a Monte-Carlo regularizer within the training loss to optimize the concrete dropout probabilities. A predictive variance term is introduced in the validation loss to enable searching for architecture with minimal model uncertainty. The experiments on CIFAR10, CIFAR100, SVHN, and ImageNet verify the effectiveness of $\mu$DARTS in improving accuracy and reducing uncertainty compared to existing DARTS methods. Moreover, the final architecture obtained from $\mu$DARTS shows higher robustness to noise at the input image and model parameters compared to the architecture obtained from existing DARTS methods.
Deep Learning based HEp-2 Image Classification: A Comprehensive Review
Nov 20, 2019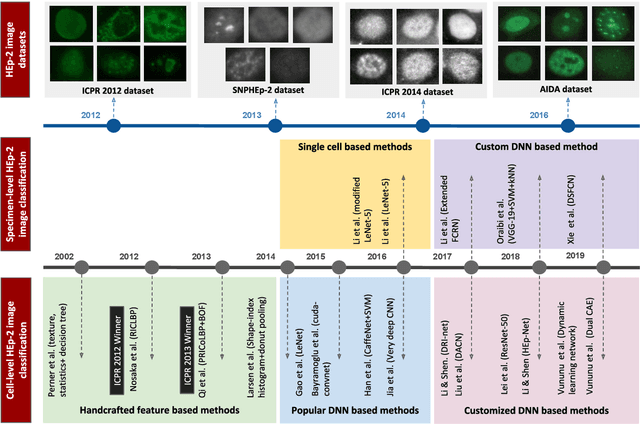

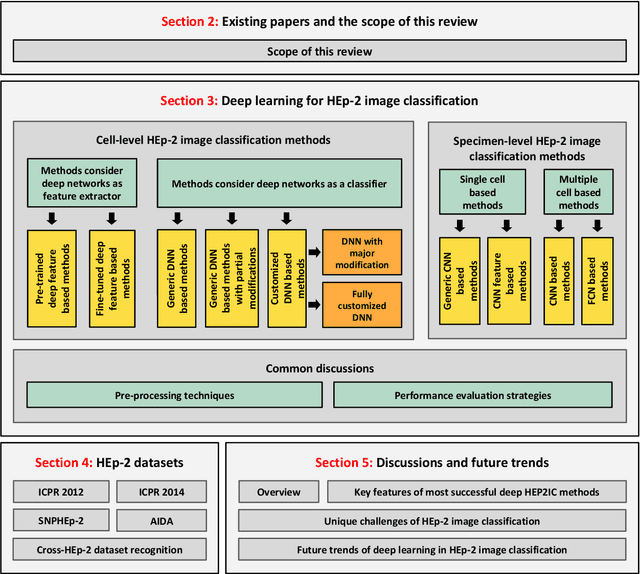
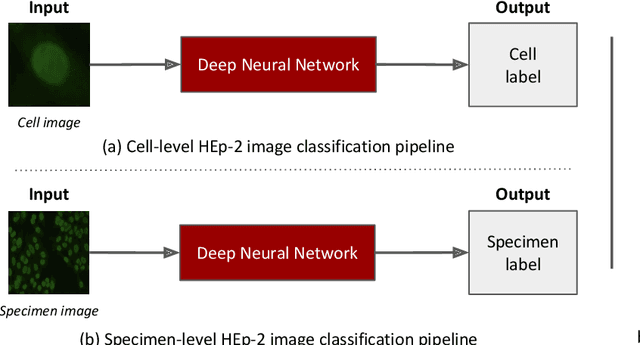
Classification of HEp-2 cell patterns plays a significant role in the indirect immunofluorescence test for identifying autoimmune diseases in the human body. Many automatic HEp-2 cell classification methods have been proposed in recent years, amongst which deep learning based methods have shown impressive performance. This paper provides a comprehensive review of the existing deep learning based HEp-2 cell image classification methods. These methods perform HEp-2 image classification in two levels, namely, cell-level and specimen-level. Both levels are covered in this review. In each level, the methods are organized with a deep network usage based taxonomy. The core idea, notable achievements, and key advantages and weakness of each method are critically analyzed. Furthermore, a concise review of the existing HEp-2 datasets that are commonly used in the literature is given. The paper ends with an overview of the current state-of-the-arts and a discussion on novel opportunities and future research directions in this field. It is hoped that this paper would give readers a comprehensive reference of this novel, challenging, and thriving field.