 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Variational Hetero-Encoder Randomized Generative Adversarial Networks for Joint Image-Text Modeling
May 18, 2019
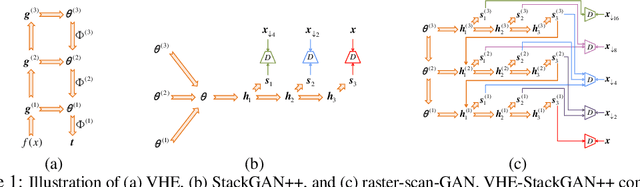
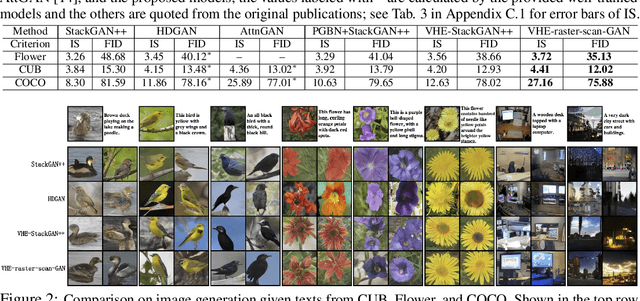
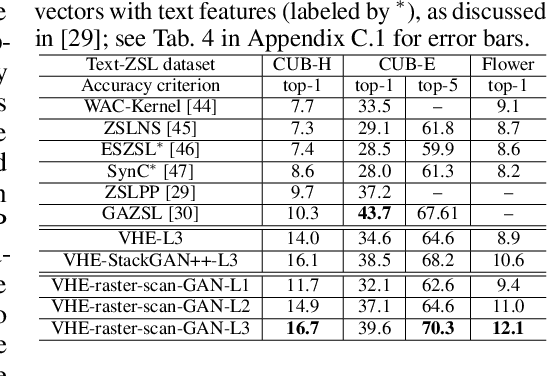

For bidirectional joint image-text modeling, we develop variational hetero-encoder (VHE) randomized generative adversarial network (GAN) that integrates a probabilistic text decoder, probabilistic image encoder, and GAN into a coherent end-to-end multi-modality learning framework. VHE randomized GAN (VHE-GAN) encodes an image to decode its associated text, and feeds the variational posterior as the source of randomness into the GAN image generator. We plug three off-the-shelf modules, including a deep topic model, a ladder-structured image encoder, and StackGAN++, into VHE-GAN, which already achieves competitive performance. This further motivates the development of VHE-raster-scan-GAN that generates photo-realistic images in not only a multi-scale low-to-high-resolution manner, but also a hierarchical-semantic coarse-to-fine fashion. By capturing and relating hierarchical semantic and visual concepts with end-to-end training, VHE-raster-scan-GAN achieves state-of-the-art performance in a wide variety of image-text multi-modality learning and generation tasks. PyTorch code is provided.
Efficient Pairwise Neuroimage Analysis using the Soft Jaccard Index and 3D Keypoint Sets
Mar 11, 2021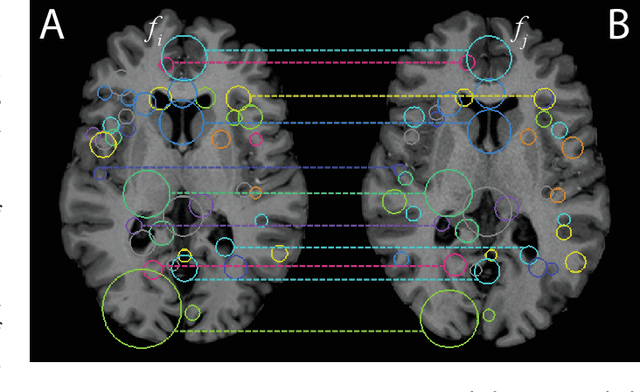
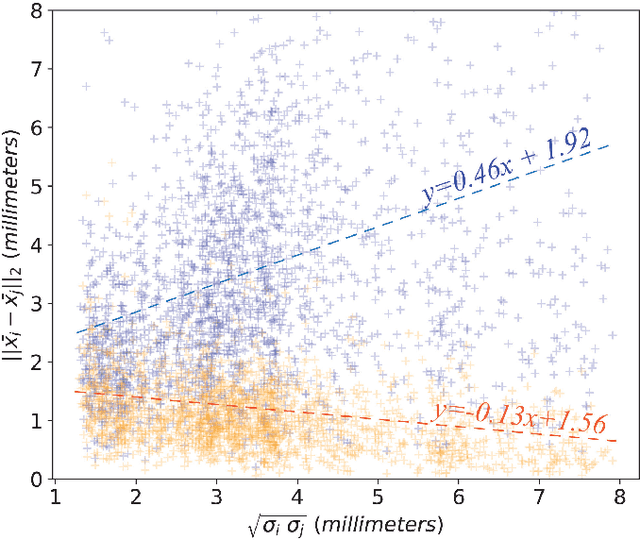
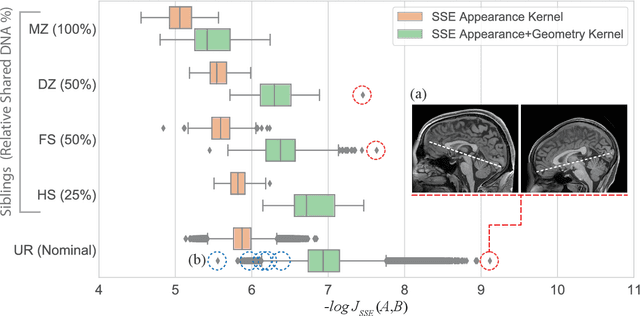
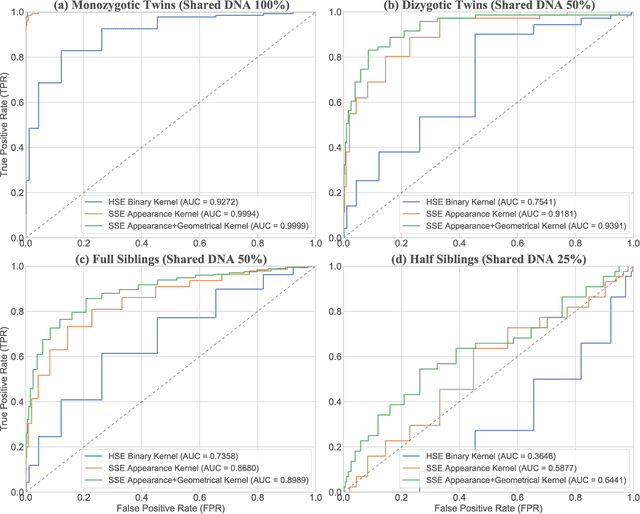
We propose a novel pairwise distance measure between variable sized sets of image keypoints for the purpose of large-scale medical image indexing. Our measure generalizes the Jaccard distance to account for soft set equivalence (SSE) between set elements, via an adaptive kernel framework accounting for uncertainty in keypoint appearance and geometry. Novel kernels are proposed to quantify variability of keypoint geometry in location and scale. Our distance measure may be estimated between $N^2$ image pairs in $O(N~log~N)$ operations via keypoint indexing. Experiments validate our method in predicting 509,545 pairwise relationships from T1-weighted MRI brain volumes of monozygotic and dizygotic twins, siblings and half-siblings sharing 100%-25% of their polymorphic genes. Soft set equivalence and keypoint geometry kernels outperform standard hard set equivalence (HSE) in predicting family relationships. High accuracy is achieved, with monozygotic twin identification near 100% and several cases of unknown family labels, due to errors in the genotyping process, are correctly paired with family members. Software is provided for efficient fine-grained curation of large, generic image datasets.
Regional Image Perturbation Reduces $L_p$ Norms of Adversarial Examples While Maintaining Model-to-model Transferability
Jul 07, 2020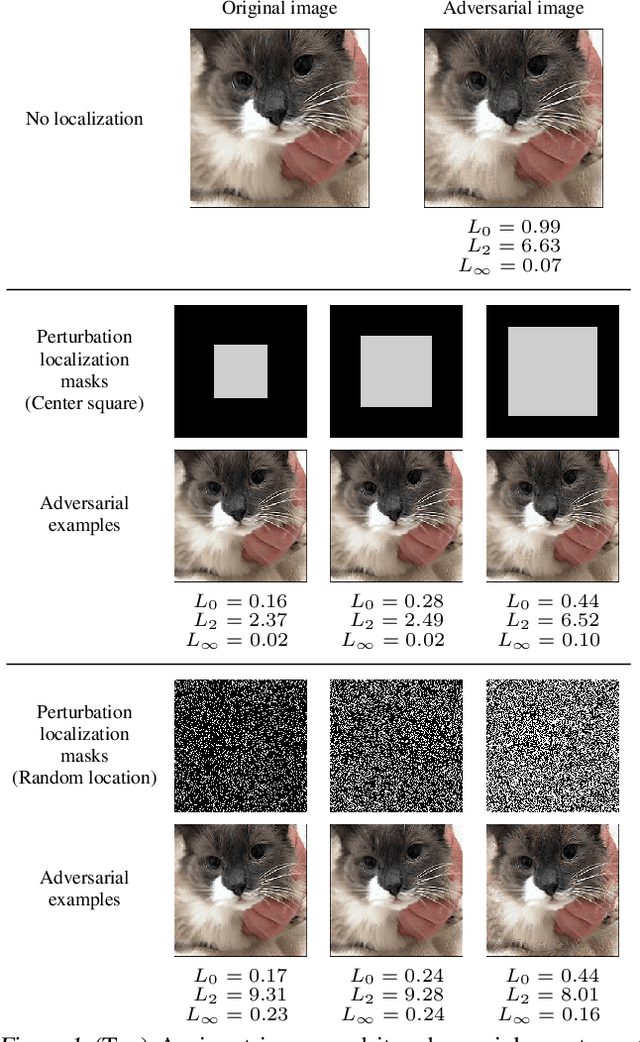
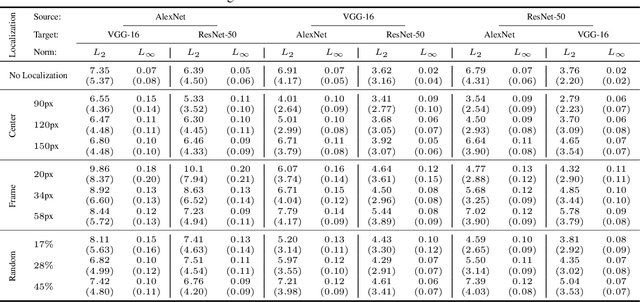

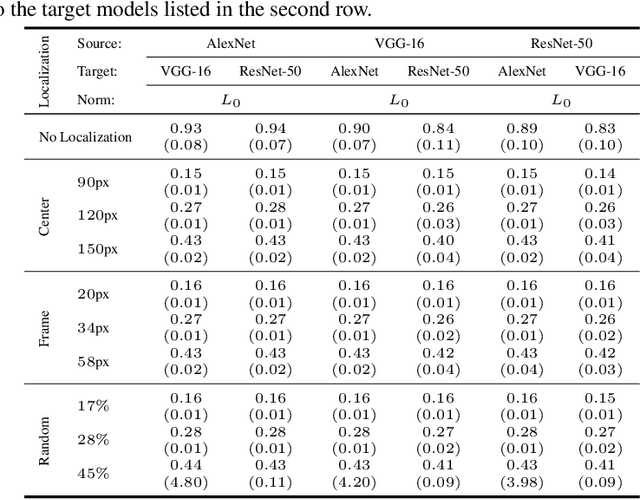
Regional adversarial attacks often rely on complicated methods for generating adversarial perturbations, making it hard to compare their efficacy against well-known attacks. In this study, we show that effective regional perturbations can be generated without resorting to complex methods. We develop a very simple regional adversarial perturbation attack method using cross-entropy sign, one of the most commonly used losses in adversarial machine learning. Our experiments on ImageNet with multiple models reveal that, on average, $76\%$ of the generated adversarial examples maintain model-to-model transferability when the perturbation is applied to local image regions. Depending on the selected region, these localized adversarial examples require significantly less $L_p$ norm distortion (for $p \in \{0, 2, \infty\}$) compared to their non-local counterparts. These localized attacks therefore have the potential to undermine defenses that claim robustness under the aforementioned norms.
Automating Defense Against Adversarial Attacks: Discovery of Vulnerabilities and Application of Multi-INT Imagery to Protect Deployed Models
Mar 29, 2021
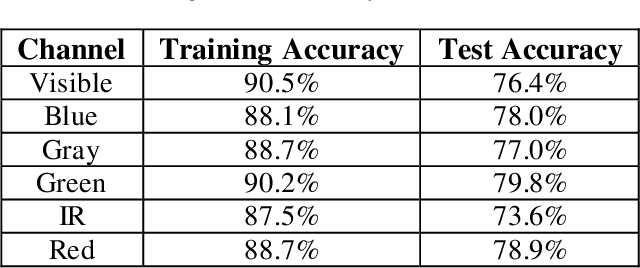


Image classification is a common step in image recognition for machine learning in overhead applications. When applying popular model architectures like MobileNetV2, known vulnerabilities expose the model to counter-attacks, either mislabeling a known class or altering box location. This work proposes an automated approach to defend these models. We evaluate the use of multi-spectral image arrays and ensemble learners to combat adversarial attacks. The original contribution demonstrates the attack, proposes a remedy, and automates some key outcomes for protecting the model's predictions against adversaries. In rough analogy to defending cyber-networks, we combine techniques from both offensive ("red team") and defensive ("blue team") approaches, thus generating a hybrid protective outcome ("green team"). For machine learning, we demonstrate these methods with 3-color channels plus infrared for vehicles. The outcome uncovers vulnerabilities and corrects them with supplemental data inputs commonly found in overhead cases particularly.
HumanGAN: A Generative Model of Humans Images
Mar 11, 2021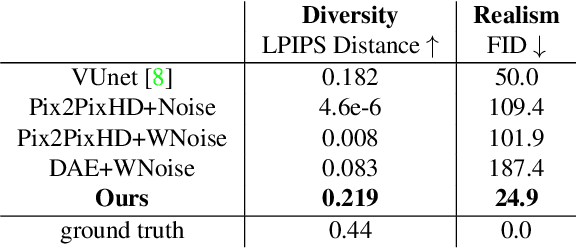
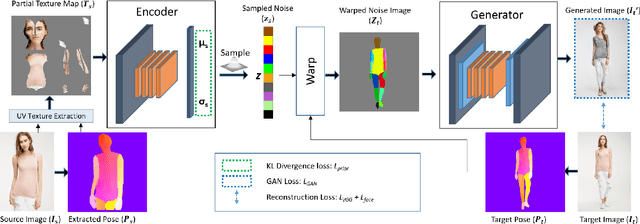


Generative adversarial networks achieve great performance in photorealistic image synthesis in various domains, including human images. However, they usually employ latent vectors that encode the sampled outputs globally. This does not allow convenient control of semantically-relevant individual parts of the image, and is not able to draw samples that only differ in partial aspects, such as clothing style. We address these limitations and present a generative model for images of dressed humans offering control over pose, local body part appearance and garment style. This is the first method to solve various aspects of human image generation such as global appearance sampling, pose transfer, parts and garment transfer, and parts sampling jointly in a unified framework. As our model encodes part-based latent appearance vectors in a normalized pose-independent space and warps them to different poses, it preserves body and clothing appearance under varying posture. Experiments show that our flexible and general generative method outperforms task-specific baselines for pose-conditioned image generation, pose transfer and part sampling in terms of realism and output resolution.
Residual Contrastive Learning for Joint Demosaicking and Denoising
Jun 18, 2021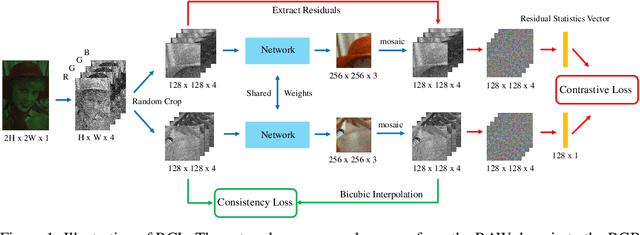
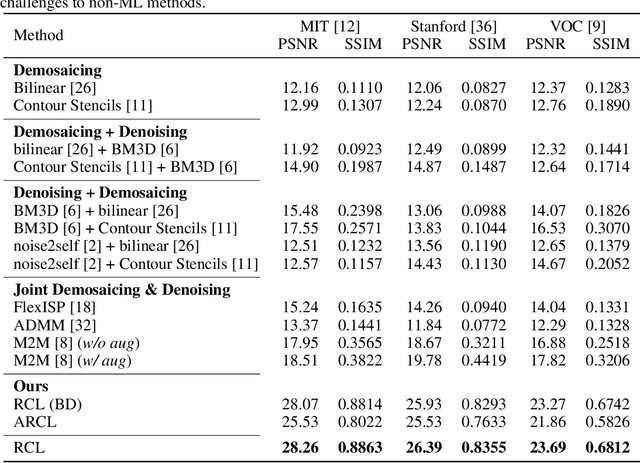

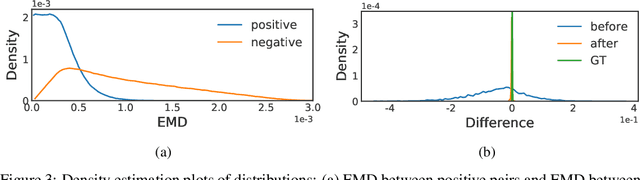
The breakthrough of contrastive learning (CL) has fueled the recent success of self-supervised learning (SSL) in high-level vision tasks on RGB images. However, CL is still ill-defined for low-level vision tasks, such as joint demosaicking and denoising (JDD), in the RAW domain. To bridge this methodological gap, we present a novel CL approach on RAW images, residual contrastive learning (RCL), which aims to learn meaningful representations for JDD. Our work is built on the assumption that noise contained in each RAW image is signal-dependent, thus two crops from the same RAW image should have more similar noise distribution than two crops from different RAW images. We use residuals as a discriminative feature and the earth mover's distance to measure the distribution divergence for the contrastive loss. To evaluate the proposed CL strategy, we simulate a series of unsupervised JDD experiments with large-scale data corrupted by synthetic signal-dependent noise, where we set a new benchmark for unsupervised JDD tasks with unknown (random) noise variance. Our empirical study not only validates that CL can be applied on distributions (c.f. features), but also exposes the lack of robustness of previous non-ML and SSL JDD methods when the statistics of the noise are unknown, thus providing some further insight into signal-dependent noise problems.
Estimating permeability of 3D micro-CT images by physics-informed CNNs based on DNS
Sep 04, 2021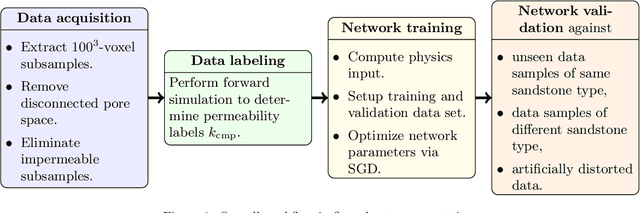

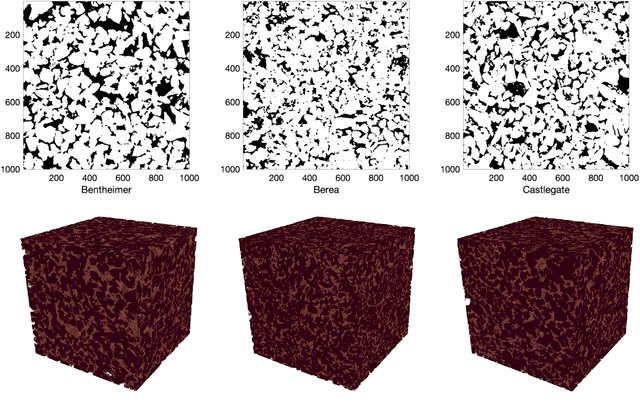
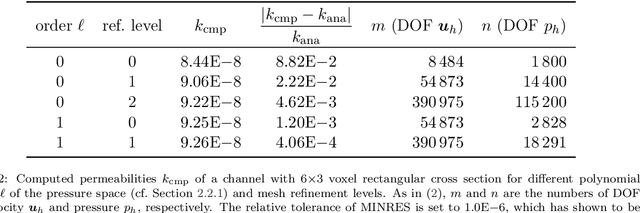
In recent years, convolutional neural networks (CNNs) have experienced an increasing interest for their ability to perform fast approximation of effective hydrodynamic parameters in porous media research and applications. This paper presents a novel methodology for permeability prediction from micro-CT scans of geological rock samples. The training data set for CNNs dedicated to permeability prediction consists of permeability labels that are typically generated by classical lattice Boltzmann methods (LBM) that simulate the flow through the pore space of the segmented image data. We instead perform direct numerical simulation (DNS) by solving the stationary Stokes equation in an efficient and distributed-parallel manner. As such, we circumvent the convergence issues of LBM that frequently are observed on complex pore geometries, and therefore, improve on the generality and accuracy of our training data set. Using the DNS-computed permeabilities, a physics-informed CNN PhyCNN) is trained by additionally providing a tailored characteristic quantity of the pore space. More precisely, by exploiting the connection to flow problems on a graph representation of the pore space, additional information about confined structures is provided to the network in terms of the maximum flow value, which is the key innovative component of our workflow. As a result, unprecedented prediction accuracy and robustness are observed for a variety of sandstone samples from archetypal rock formations.
BezierSeg: Parametric Shape Representation for Fast Object Segmentation in Medical Images
Aug 02, 2021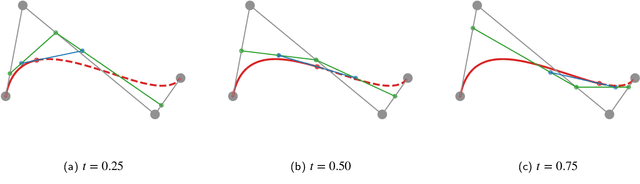
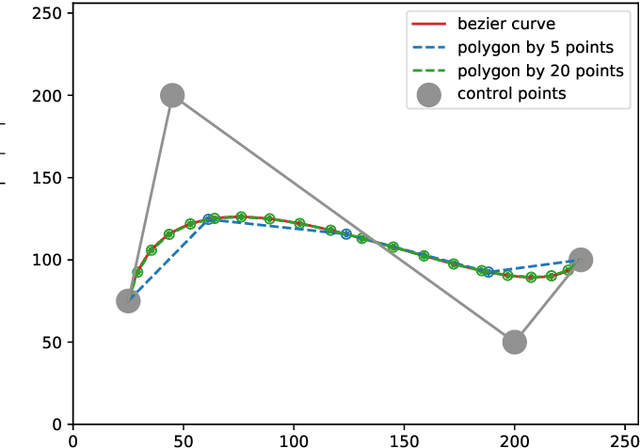
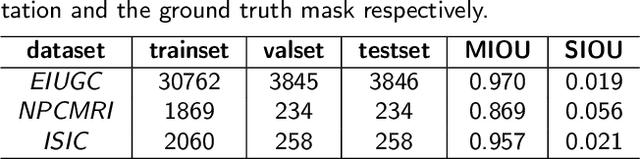
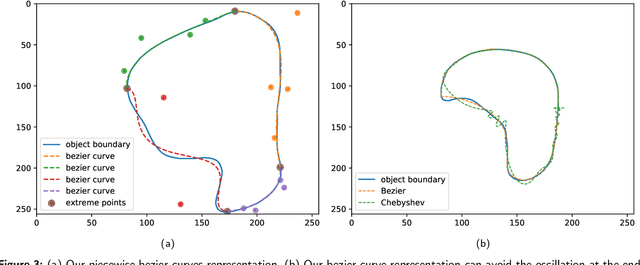
Delineating the lesion area is an important task in image-based diagnosis. Pixel-wise classification is a popular approach to segmenting the region of interest. However, at fuzzy boundaries such methods usually result in glitches, discontinuity, or disconnection, inconsistent with the fact that lesions are solid and smooth. To overcome these undesirable artifacts, we propose the BezierSeg model which outputs bezier curves encompassing the region of interest. Directly modelling the contour with analytic equations ensures that the segmentation is connected, continuous, and the boundary is smooth. In addition, it offers sub-pixel accuracy. Without loss of accuracy, the bezier contour can be resampled and overlaid with images of any resolution. Moreover, a doctor can conveniently adjust the curve's control points to refine the result. Our experiments show that the proposed method runs in real time and achieves accuracy competitive with pixel-wise segmentation models.
Color naming guided intrinsic image decomposition
Oct 23, 2018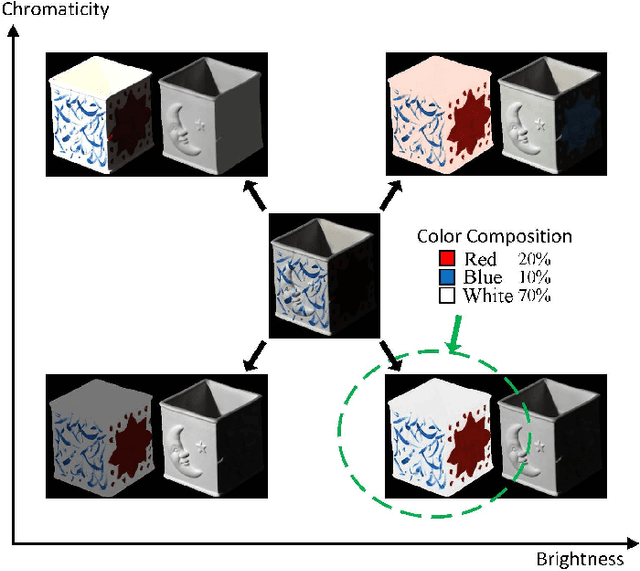
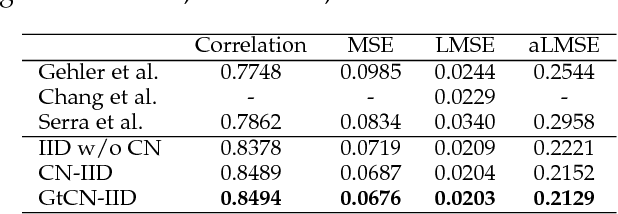
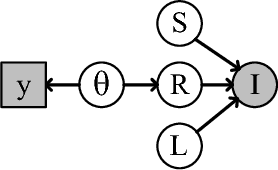
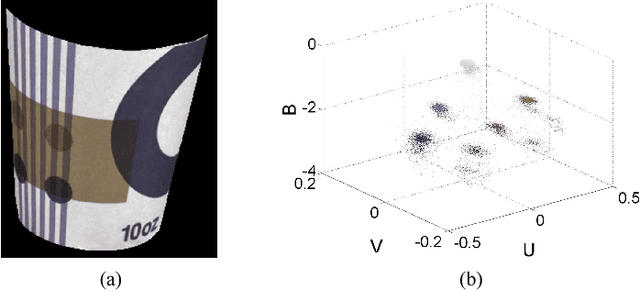
Intrinsic image decomposition is a severely under-constrained problem. User interactions can help to reduce the ambiguity of the decomposition considerably. The traditional way of user interaction is to draw scribbles that indicate regions with constant reflectance or shading. However the effect scopes of the scribbles are quite limited, so dozens of scribbles are often needed to rectify the whole decomposition, which is time consuming. In this paper we propose an efficient way of user interaction that users need only to annotate the color composition of the image. Color composition reveals the global distribution of reflectance, so it can help to adapt the whole decomposition directly. We build a generative model of the process that the albedo of the material produces both the reflectance through imaging and the color labels by color naming. Our model fuses effectively the physical properties of image formation and the top-down information from human color perception. Experimental results show that color naming can improve the performance of intrinsic image decomposition, especially in cleaning the shadows left in reflectance and solving the color constancy problem.
Bayesian Eye Tracking
Jun 25, 2021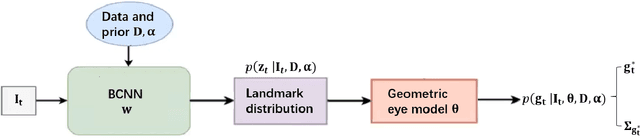
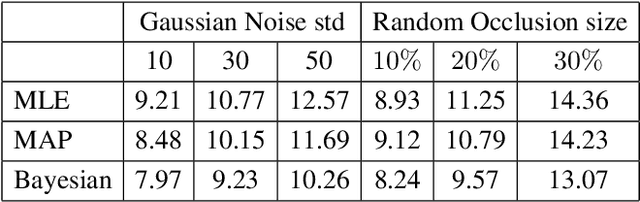
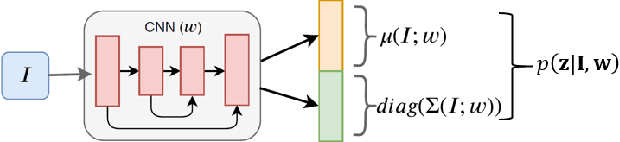
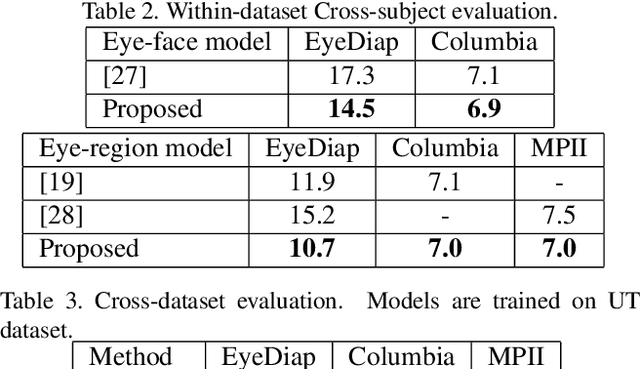
Model-based eye tracking has been a dominant approach for eye gaze tracking because of its ability to generalize to different subjects, without the need of any training data and eye gaze annotations. Model-based eye tracking, however, is susceptible to eye feature detection errors, in particular for eye tracking in the wild. To address this issue, we propose a Bayesian framework for model-based eye tracking. The proposed system consists of a cascade-Bayesian Convolutional Neural Network (c-BCNN) to capture the probabilistic relationships between eye appearance and its landmarks, and a geometric eye model to estimate eye gaze from the eye landmarks. Given a testing eye image, the Bayesian framework can generate, through Bayesian inference, the eye gaze distribution without explicit landmark detection and model training, based on which it not only estimates the most likely eye gaze but also its uncertainty. Furthermore, with Bayesian inference instead of point-based inference, our model can not only generalize better to different sub-jects, head poses, and environments but also is robust to image noise and landmark detection errors. Finally, with the estimated gaze uncertainty, we can construct a cascade architecture that allows us to progressively improve gaze estimation accuracy. Compared to state-of-the-art model-based and learning-based methods, the proposed Bayesian framework demonstrates significant improvement in generalization capability across several benchmark datasets and in accuracy and robustness under challenging real-world conditions.