 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using Synthetic Corruptions to Measure Robustness to Natural Distribution Shifts
Jul 26, 2021

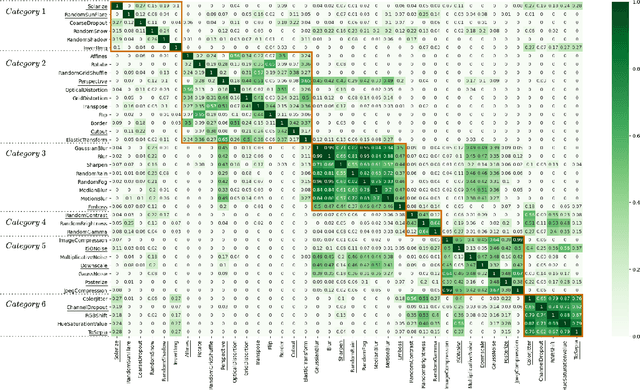

Synthetic corruptions gathered into a benchmark are frequently used to measure neural network robustness to distribution shifts. However, robustness to synthetic corruption benchmarks is not always predictive of robustness to distribution shifts encountered in real-world applications. In this paper, we propose a methodology to build synthetic corruption benchmarks that make robustness estimations more correlated with robustness to real-world distribution shifts. Using the overlapping criterion, we split synthetic corruptions into categories that help to better understand neural network robustness. Based on these categories, we identify three parameters that are relevant to take into account when constructing a corruption benchmark: number of represented categories, balance among categories and size of benchmarks. Applying the proposed methodology, we build a new benchmark called ImageNet-Syn2Nat to predict image classifier robustness.
Semi-supervised Image Attribute Editing using Generative Adversarial Networks
Jul 03, 2019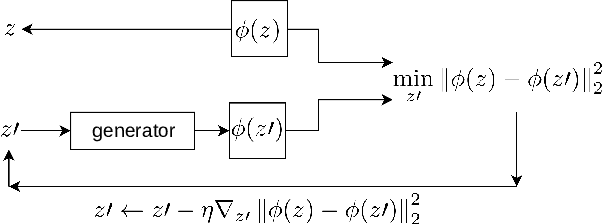
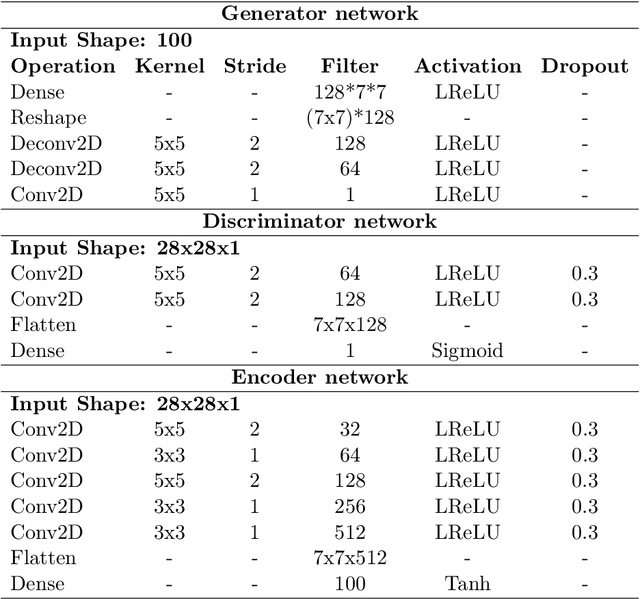
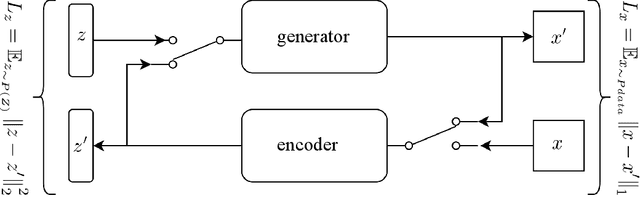
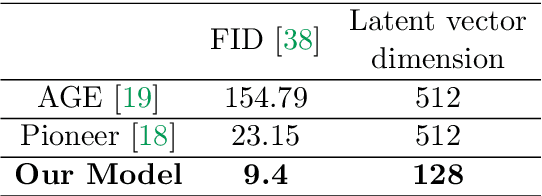
Image attribute editing is a challenging problem that has been recently studied by many researchers using generative networks. The challenge is in the manipulation of selected attributes of images while preserving the other details. The method to achieve this goal is to find an accurate latent vector representation of an image and a direction corresponding to the attribute. Almost all the works in the literature use labeled datasets in a supervised setting for this purpose. In this study, we introduce an architecture called Cyclic Reverse Generator (CRG), which allows learning the inverse function of the generator accurately via an encoder in an unsupervised setting by utilizing cyclic cost minimization. Attribute editing is then performed using the CRG models for finding desired attribute representations in the latent space. In this work, we use two arbitrary reference images, with and without desired attributes, to compute an attribute direction for editing. We show that the proposed approach performs better in terms of image reconstruction compared to the existing end-to-end generative models both quantitatively and qualitatively. We demonstrate state-of-the-art results on both real images and generated images in MNIST and CelebA datasets.
Regional Image Perturbation Reduces $L_p$ Norms of Adversarial Examples While Maintaining Model-to-model Transferability
Jul 07, 2020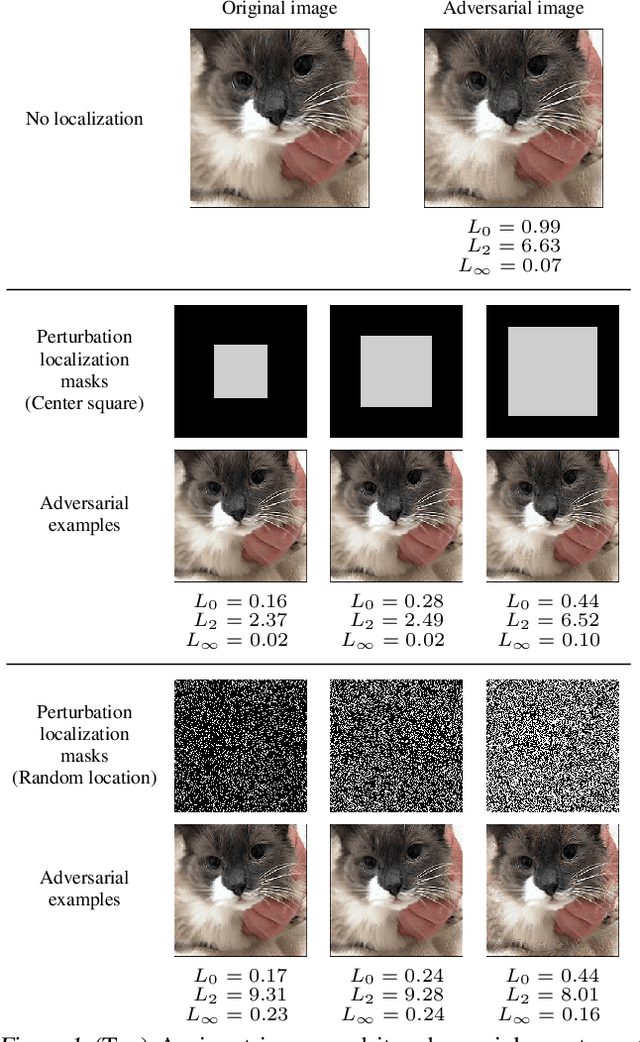
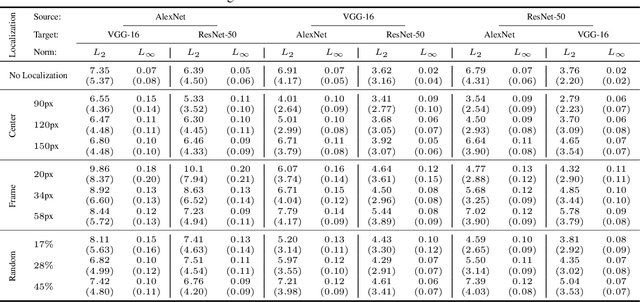

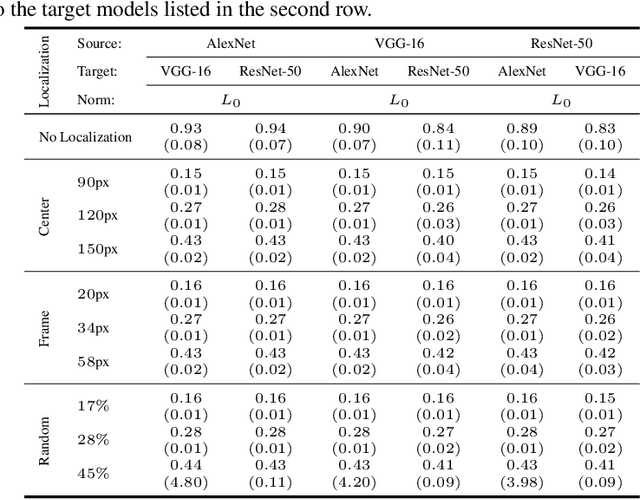
Regional adversarial attacks often rely on complicated methods for generating adversarial perturbations, making it hard to compare their efficacy against well-known attacks. In this study, we show that effective regional perturbations can be generated without resorting to complex methods. We develop a very simple regional adversarial perturbation attack method using cross-entropy sign, one of the most commonly used losses in adversarial machine learning. Our experiments on ImageNet with multiple models reveal that, on average, $76\%$ of the generated adversarial examples maintain model-to-model transferability when the perturbation is applied to local image regions. Depending on the selected region, these localized adversarial examples require significantly less $L_p$ norm distortion (for $p \in \{0, 2, \infty\}$) compared to their non-local counterparts. These localized attacks therefore have the potential to undermine defenses that claim robustness under the aforementioned norms.
MV-TON: Memory-based Video Virtual Try-on network
Aug 17, 2021
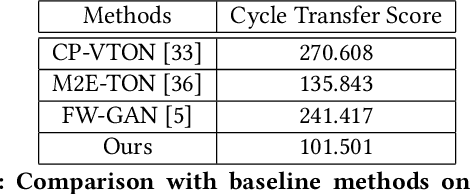
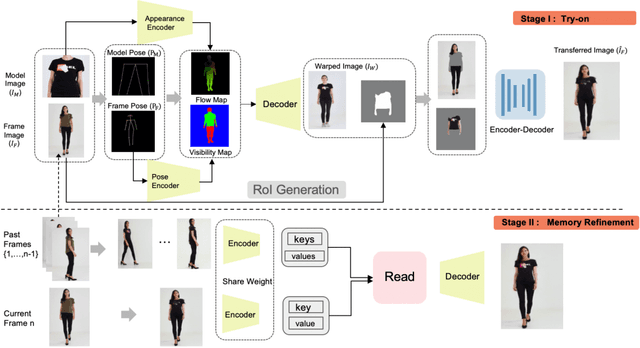
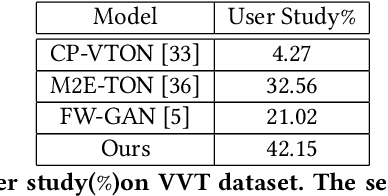
With the development of Generative Adversarial Network, image-based virtual try-on methods have made great progress. However, limited work has explored the task of video-based virtual try-on while it is important in real-world applications. Most existing video-based virtual try-on methods usually require clothing templates and they can only generate blurred and low-resolution results. To address these challenges, we propose a Memory-based Video virtual Try-On Network (MV-TON), which seamlessly transfers desired clothes to a target person without using any clothing templates and generates high-resolution realistic videos. Specifically, MV-TON consists of two modules: 1) a try-on module that transfers the desired clothes from model images to frame images by pose alignment and region-wise replacing of pixels; 2) a memory refinement module that learns to embed the existing generated frames into the latent space as external memory for the following frame generation. Experimental results show the effectiveness of our method in the video virtual try-on task and its superiority over other existing methods.
A Compression Objective and a Cycle Loss for Neural Image Compression
May 24, 2019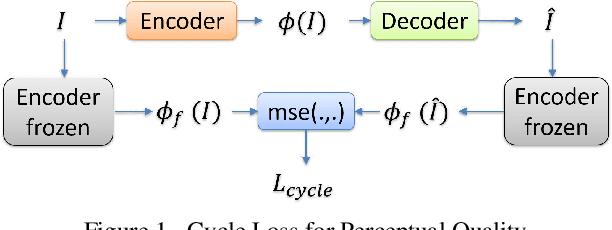
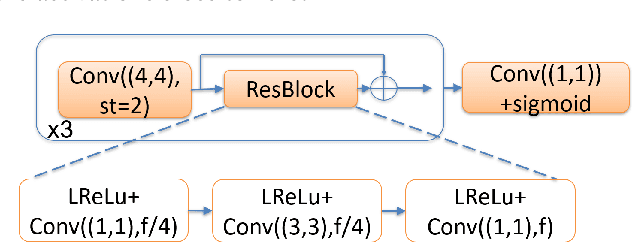
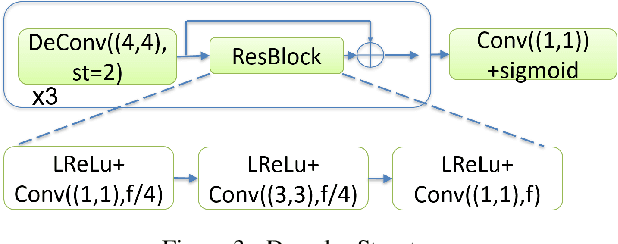

In this manuscript we propose two objective terms for neural image compression: a compression objective and a cycle loss. These terms are applied on the encoder output of an autoencoder and are used in combination with reconstruction losses. The compression objective encourages sparsity and low entropy in the activations. The cycle loss term represents the distortion between encoder outputs computed from the original image and from the reconstructed image (code-domain distortion). We train different autoencoders by using the compression objective in combination with different losses: a) MSE, b) MSE and MSSSIM, c) MSE, MS-SSIM and cycle loss. We observe that images encoded by these differently-trained autoencoders fall into different points of the perception-distortion curve (while having similar bit-rates). In particular, MSE-only training favors low image-domain distortion, whereas cycle loss training favors high perceptual quality.
Multi-Stage Pathological Image Classification using Semantic Segmentation
Oct 10, 2019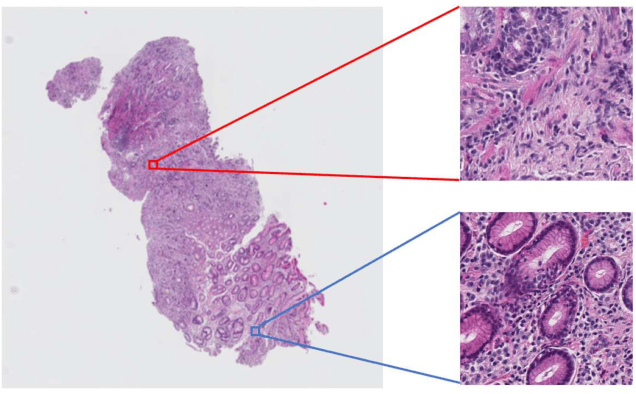
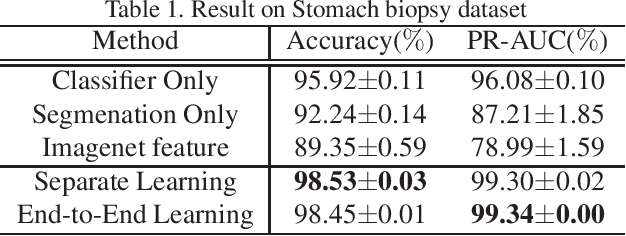
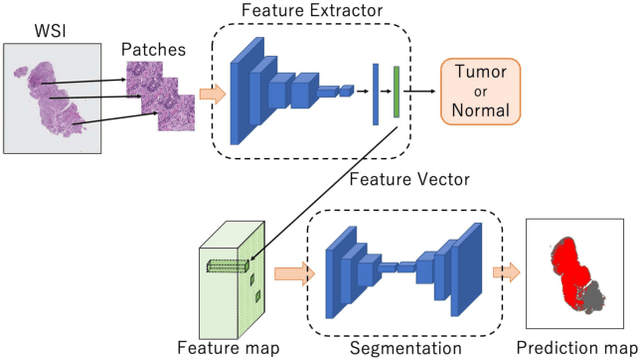
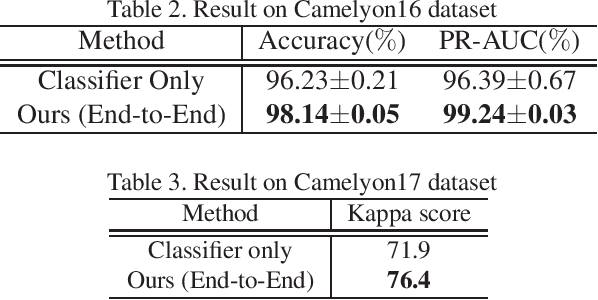
Histopathological image analysis is an essential process for the discovery of diseases such as cancer. However, it is challenging to train CNN on whole slide images (WSIs) of gigapixel resolution considering the available memory capacity. Most of the previous works divide high resolution WSIs into small image patches and separately input them into the model to classify it as a tumor or a normal tissue. However, patch-based classification uses only patch-scale local information but ignores the relationship between neighboring patches. If we consider the relationship of neighboring patches and global features, we can improve the classification performance. In this paper, we propose a new model structure combining the patch-based classification model and whole slide-scale segmentation model in order to improve the prediction performance of automatic pathological diagnosis. We extract patch features from the classification model and input them into the segmentation model to obtain a whole slide tumor probability heatmap. The classification model considers patch-scale local features, and the segmentation model can take global information into account. We also propose a new optimization method that retains gradient information and trains the model partially for end-to-end learning with limited GPU memory capacity. We apply our method to the tumor/normal prediction on WSIs and the classification performance is improved compared with the conventional patch-based method.
Image Completion on CIFAR-10
Oct 07, 2018
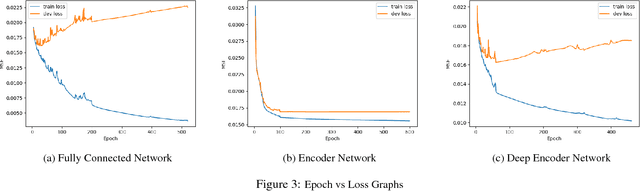

This project performed image completion on CIFAR-10, a dataset of 60,000 32x32 RGB images, using three different neural network architectures: fully convolutional networks, convolutional networks with fully connected layers, and encoder-decoder convolutional networks. The highest performing model was a deep fully convolutional network, which was able to achieve a mean squared error of .015 when comparing the original image pixel values with the predicted pixel values. As well, this network was able to output in-painted images which appeared real to the human eye.
MULTICAST: MULTI Confirmation-level Alarm SysTem based on CNN and LSTM to mitigate false alarms for handgun detection in video-surveillance
May 03, 2021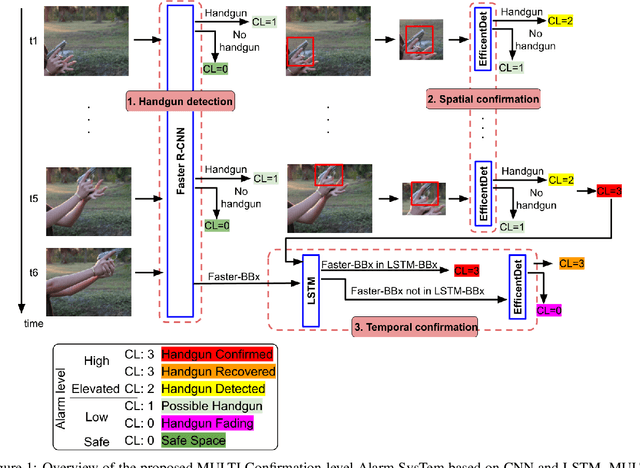
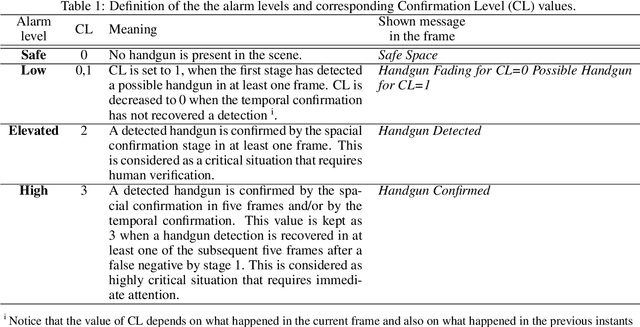
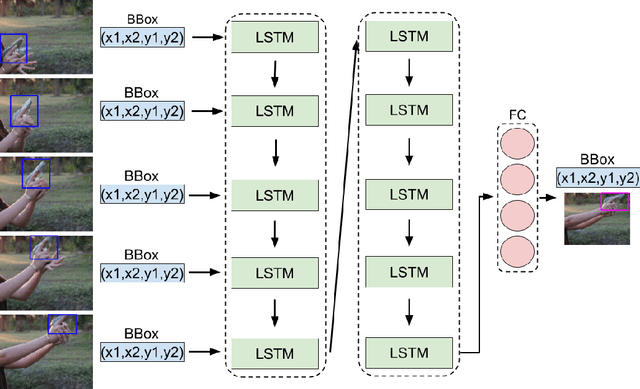
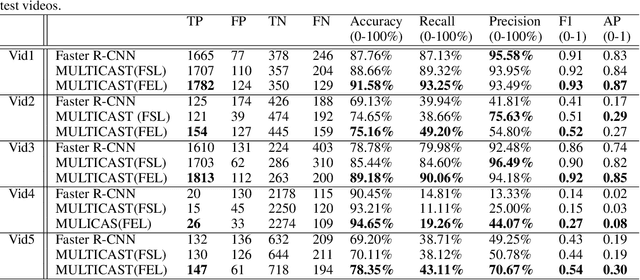
Despite the constant advances in computer vision, integrating modern single-image detectors in real-time handgun alarm systems in video-surveillance is still debatable. Using such detectors still implies a high number of false alarms and false negatives. In this context, most existent studies select one of the latest single-image detectors and train it on a better dataset or use some pre-processing, post-processing or data-fusion approach to further reduce false alarms. However, none of these works tried to exploit the temporal information present in the videos to mitigate false detections. This paper presents a new system, called MULTI Confirmation-level Alarm SysTem based on Convolutional Neural Networks (CNN) and Long Short Term Memory networks (LSTM) (MULTICAST), that leverages not only the spacial information but also the temporal information existent in the videos for a more reliable handgun detection. MULTICAST consists of three stages, i) a handgun detection stage, ii) a CNN-based spacial confirmation stage and iii) LSTM-based temporal confirmation stage. The temporal confirmation stage uses the positions of the detected handgun in previous instants to predict its trajectory in the next frame. Our experiments show that MULTICAST reduces by 80% the number of false alarms with respect to Faster R-CNN based-single-image detector, which makes it more useful in providing more effective and rapid security responses.
Constrained Linear Data-feature Mapping for Image Classification
Nov 23, 2019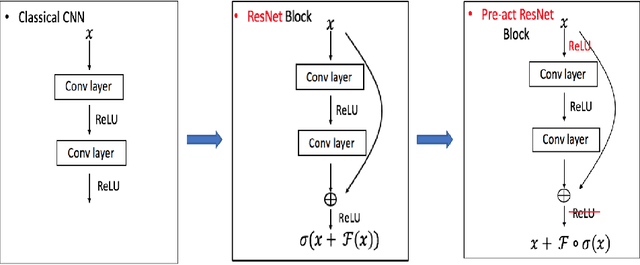
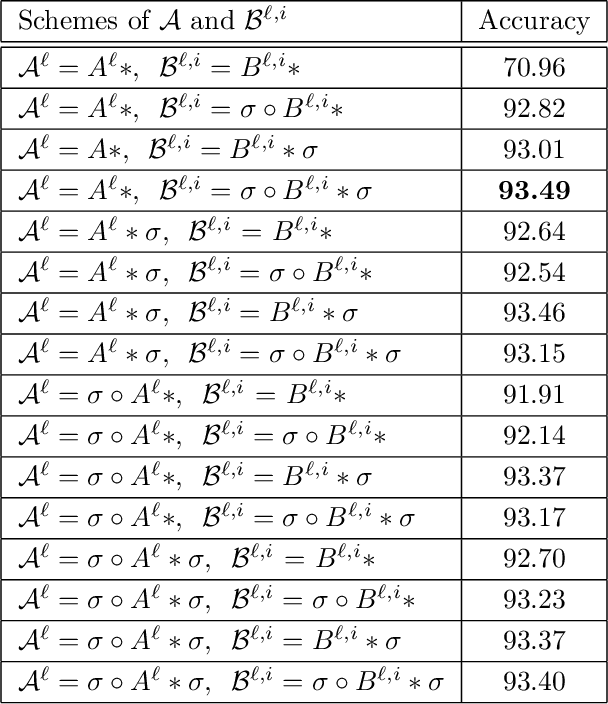
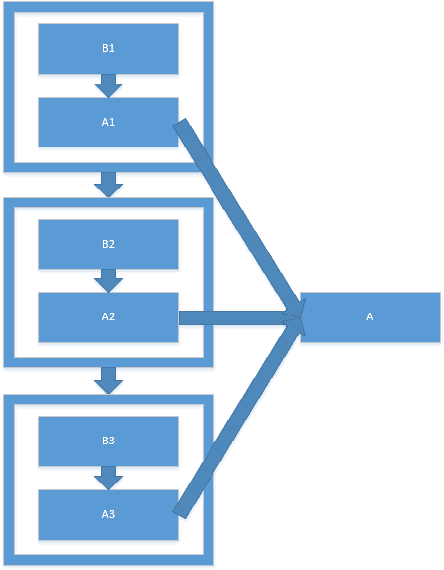
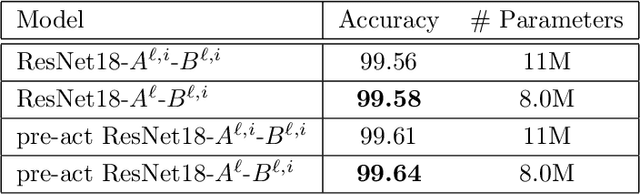
In this paper, we propose a constrained linear data-feature mapping model as an interpretable mathematical model for image classification using convolutional neural network (CNN) such as the ResNet. From this viewpoint, we establish the detailed connections in a technical level between the traditional iterative schemes for constrained linear system and the architecture for the basic block of ResNet. Under these connections, we propose some natural modifications of ResNet type models which will have less parameters but can keep almost the same accuracy as these original models. Some numerical experiments are shown to demonstrate the validity of this constrained learning data-feature mapping assumption.
An Approach Towards Physics Informed Lung Ultrasound Image Scoring Neural Network for Diagnostic Assistance in COVID-19
Jun 13, 2021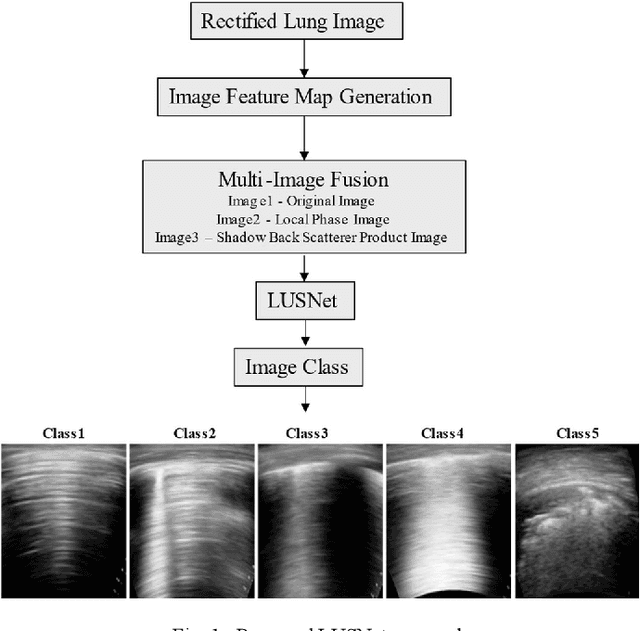
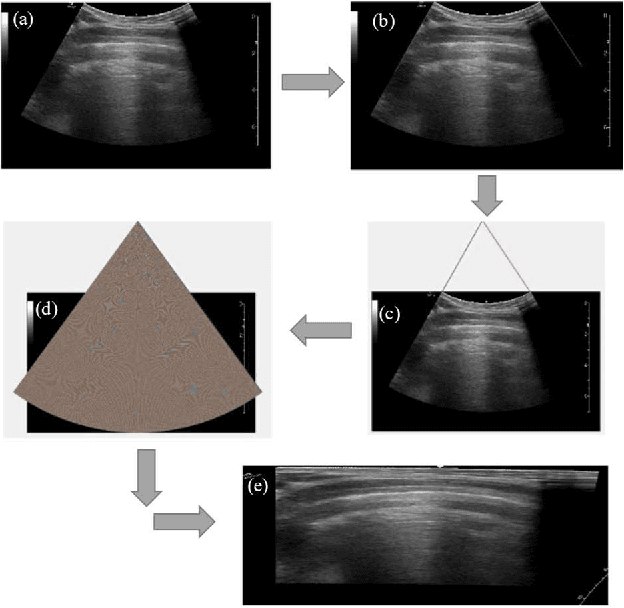
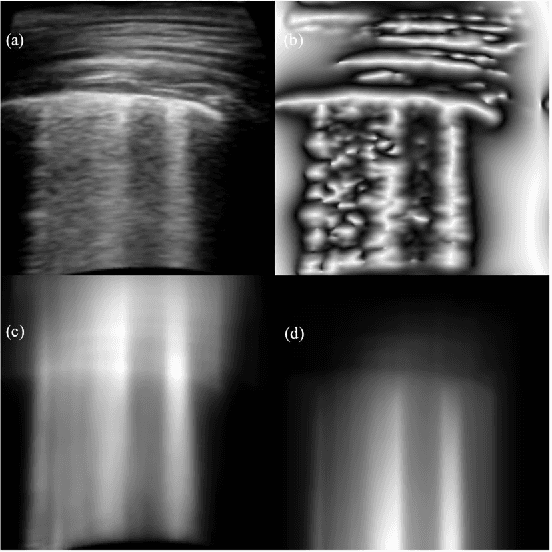
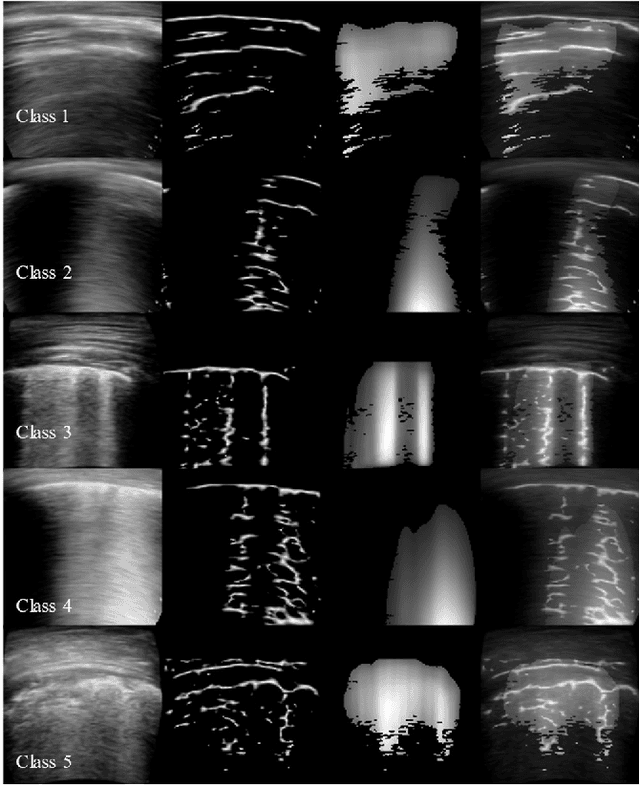
Ultrasound is fast becoming an inevitable diagnostic tool for regular and continuous monitoring of the lung with the recent outbreak of COVID-19. In this work, a novel approach is presented to extract acoustic propagation-based features to automatically highlight the region below pleura, which is an important landmark in lung ultrasound (LUS). Subsequently, a multichannel input formed by using the acoustic physics-based feature maps is fused to train a neural network, referred to as LUSNet, to classify the LUS images into five classes of varying severity of lung infection to track the progression of COVID-19. In order to ensure that the proposed approach is agnostic to the type of acquisition, the LUSNet, which consists of a U-net architecture is trained in an unsupervised manner with the acoustic feature maps to ensure that the encoder-decoder architecture is learning features in the pleural region of interest. A novel combination of the U-net output and the U-net encoder output is employed for the classification of severity of infection in the lung. A detailed analysis of the proposed approach on LUS images over the infection to full recovery period of ten confirmed COVID-19 subjects shows an average five-fold cross-validation accuracy, sensitivity, and specificity of 97%, 93%, and 98% respectively over 5000 frames of COVID-19 videos. The analysis also shows that, when the input dataset is limited and diverse as in the case of COVID-19 pandemic, an aided effort of combining acoustic propagation-based features along with the gray scale images, as proposed in this work, improves the performance of the neural network significantly and also aids the labelling and triaging process.