 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Robust Disentangling of Latent Characteristics for Image Synthesis
Oct 22, 2019
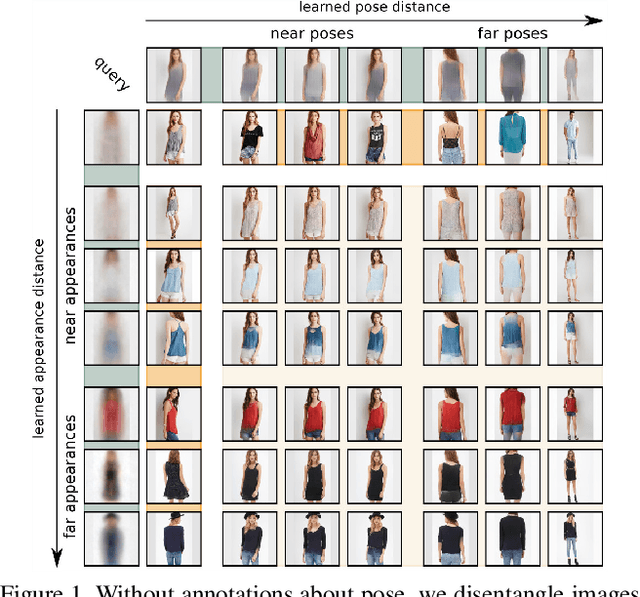



Deep generative models come with the promise to learn an explainable representation for visual objects that allows image sampling, synthesis, and selective modification. The main challenge is to learn to properly model the independent latent characteristics of an object, especially its appearance and pose. We present a novel approach that learns disentangled representations of these characteristics and explains them individually. Training requires only pairs of images depicting the same object appearance, but no pose annotations. We propose an additional classifier that estimates the minimal amount of regularization required to enforce disentanglement. Thus both representations together can completely explain an image while being independent of each other. Previous methods based on adversarial approaches fail to enforce this independence, while methods based on variational approaches lead to uninformative representations. In experiments on diverse object categories, the approach successfully recombines pose and appearance to reconstruct and retarget novel synthesized images. We achieve significant improvements over state-of-the-art methods which utilize the same level of supervision, and reach performances comparable to those of pose-supervised approaches. However, we can handle the vast body of articulated object classes for which no pose models/annotations are available.
UNIQUE: Unsupervised Image Quality Estimation
Oct 15, 2018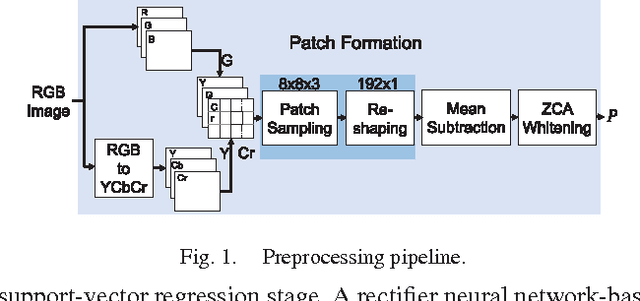
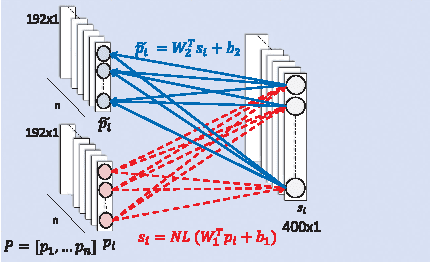
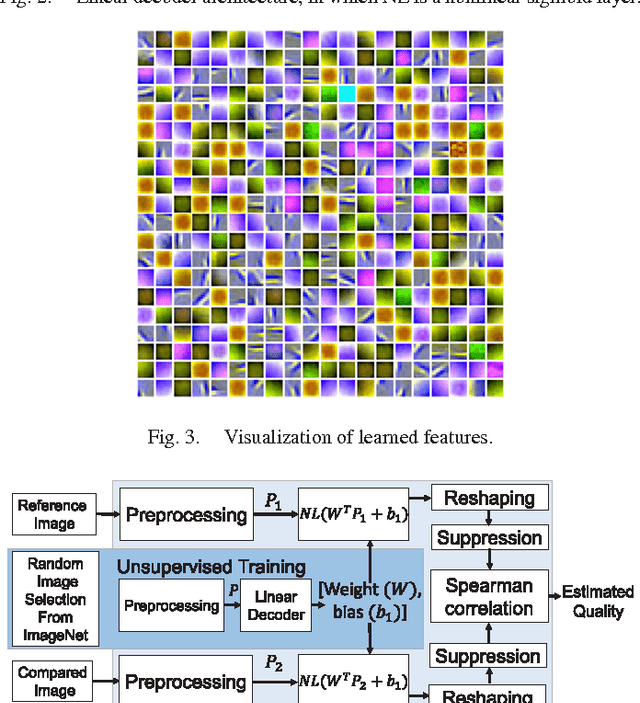
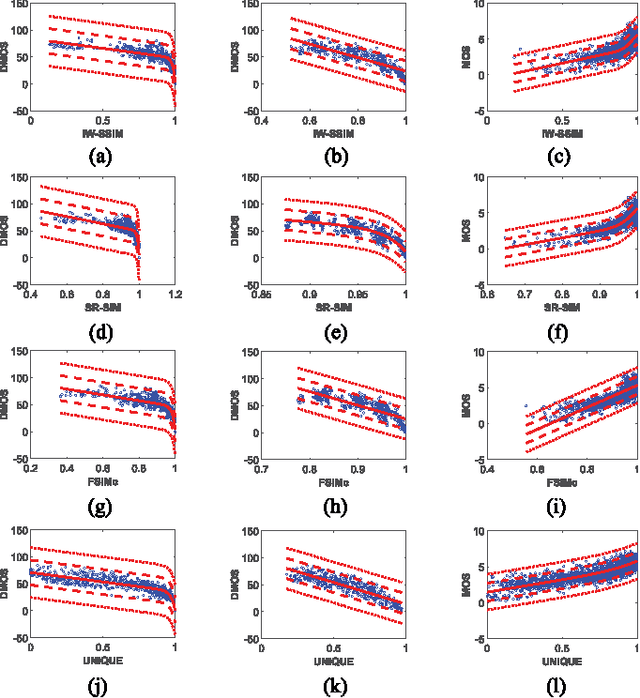
In this paper, we estimate perceived image quality using sparse representations obtained from generic image databases through an unsupervised learning approach. A color space transformation, a mean subtraction, and a whitening operation are used to enhance descriptiveness of images by reducing spatial redundancy; a linear decoder is used to obtain sparse representations; and a thresholding stage is used to formulate suppression mechanisms in a visual system. A linear decoder is trained with 7 GB worth of data, which corresponds to 100,000 8x8 image patches randomly obtained from nearly 1,000 images in the ImageNet 2013 database. A patch-wise training approach is preferred to maintain local information. The proposed quality estimator UNIQUE is tested on the LIVE, the Multiply Distorted LIVE, and the TID 2013 databases and compared with thirteen quality estimators. Experimental results show that UNIQUE is generally a top performing quality estimator in terms of accuracy, consistency, linearity, and monotonic behavior.
* 12 pages, 5 figures, 2 tables
Multi-Path Learnable Wavelet Neural Network for Image Classification
Aug 26, 2019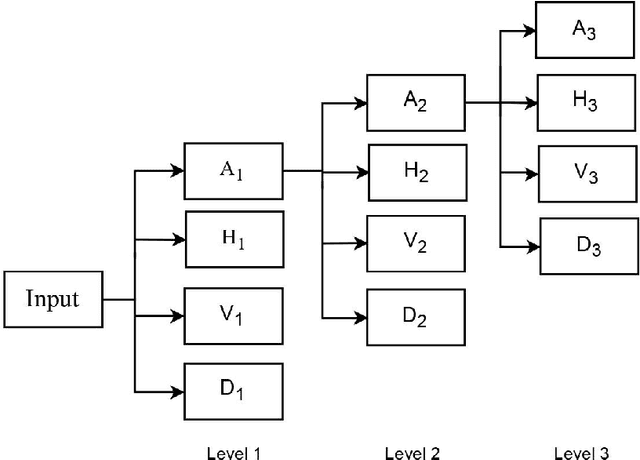
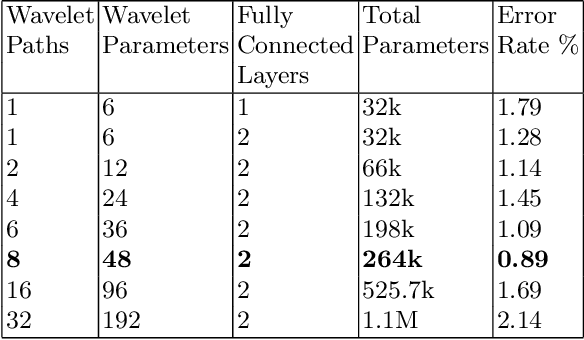
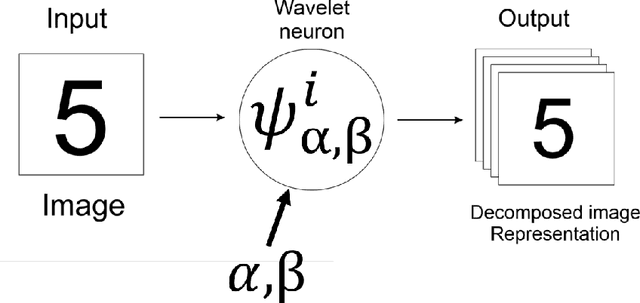
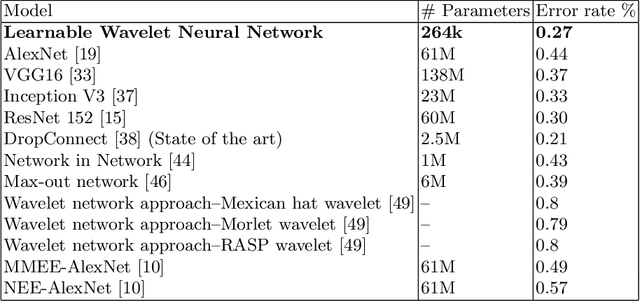
Despite the remarkable success of deep learning in pattern recognition, deep network models face the problem of training a large number of parameters. In this paper, we propose and evaluate a novel multi-path wavelet neural network architecture for image classification with far less number of trainable parameters. The model architecture consists of a multi-path layout with several levels of wavelet decompositions performed in parallel followed by fully connected layers. These decomposition operations comprise wavelet neurons with learnable parameters, which are updated during the training phase using the back-propagation algorithm. We evaluate the performance of the introduced network using common image datasets without data augmentation except for SVHN and compare the results with influential deep learning models. Our findings support the possibility of reducing the number of parameters significantly in deep neural networks without compromising its accuracy.
Transfer Learning for Pose Estimation of Illustrated Characters
Aug 04, 2021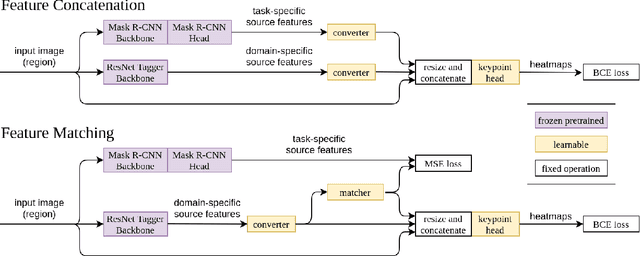
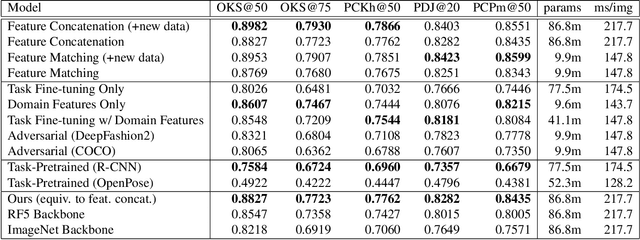
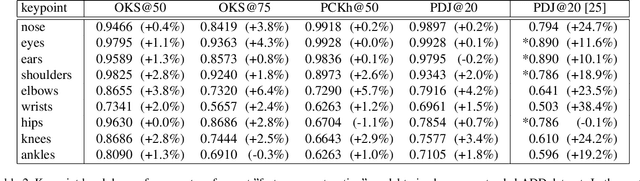

Human pose information is a critical component in many downstream image processing tasks, such as activity recognition and motion tracking. Likewise, a pose estimator for the illustrated character domain would provide a valuable prior for assistive content creation tasks, such as reference pose retrieval and automatic character animation. But while modern data-driven techniques have substantially improved pose estimation performance on natural images, little work has been done for illustrations. In our work, we bridge this domain gap by efficiently transfer-learning from both domain-specific and task-specific source models. Additionally, we upgrade and expand an existing illustrated pose estimation dataset, and introduce two new datasets for classification and segmentation subtasks. We then apply the resultant state-of-the-art character pose estimator to solve the novel task of pose-guided illustration retrieval. All data, models, and code will be made publicly available.
Apricot variety classification using image processing and machine learning approaches
Dec 27, 2019
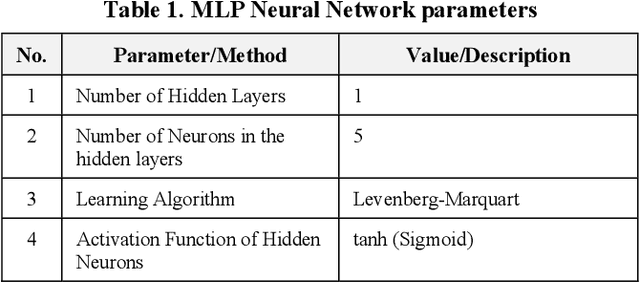
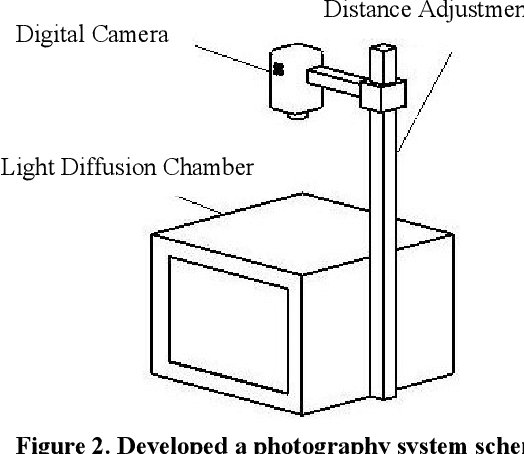
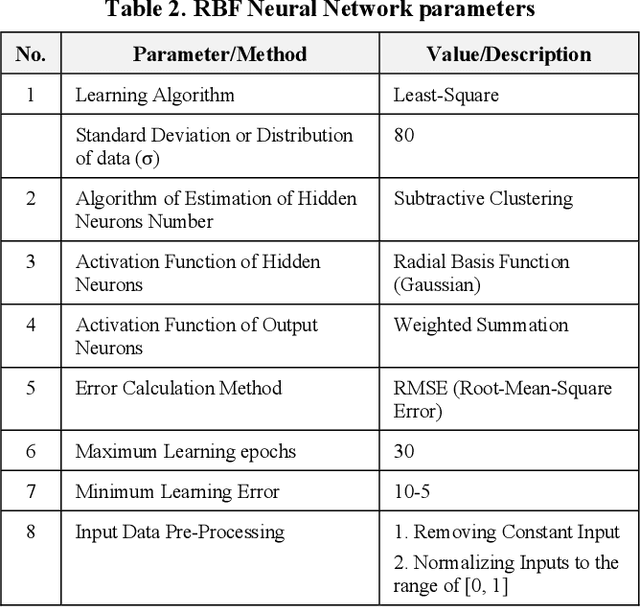
Apricot which is a cultivated type of Zerdali (wild apricot) has an important place in human nutrition and its medical properties are essential for human health. The objective of this research was to obtain a model for apricot mass and separate apricot variety with image processing technology using external features of apricot fruit. In this study, five verities of apricot were used. In order to determine the size of the fruits, three mutually perpendicular axes were defined, length, width, and thickness. Measurements show that the effect of variety on all properties was statistically significant at the 1% probability level. Furthermore, there is no significant difference between the estimated dimensions by image processing approach and the actual dimensions. The developed system consists of a digital camera, a light diffusion chamber, a distance adjustment pedestal, and a personal computer. Images taken by the digital camera were stored as (RGB) for further analysis. The images were taken for a number of 49 samples of each cultivar in three directions. A linear equation is recommended to calculate the apricot mass based on the length and the width with R 2 = 0.97. In addition, ANFIS model with C-means was the best model for classifying the apricot varieties based on the physical features including length, width, thickness, mass, and projected area of three perpendicular surfaces. The accuracy of the model was 87.7.
Deep Monocular 3D Human Pose Estimation via Cascaded Dimension-Lifting
Apr 08, 2021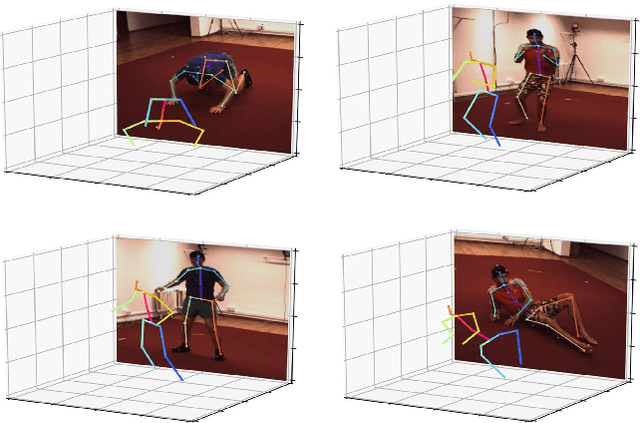
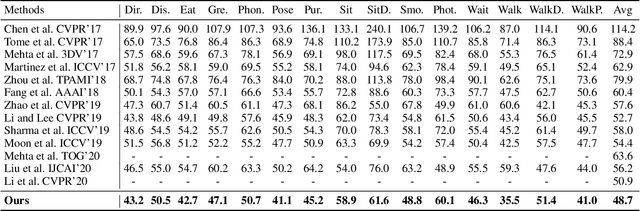
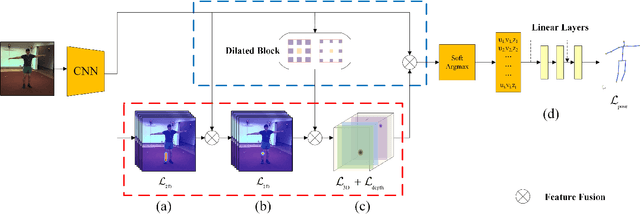
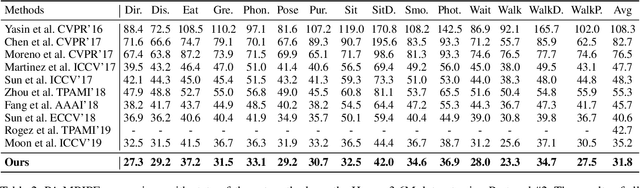
The 3D pose estimation from a single image is a challenging problem due to depth ambiguity. One type of the previous methods lifts 2D joints, obtained by resorting to external 2D pose detectors, to the 3D space. However, this type of approaches discards the contextual information of images which are strong cues for 3D pose estimation. Meanwhile, some other methods predict the joints directly from monocular images but adopt a 2.5D output representation $P^{2.5D} = (u,v,z^{r}) $ where both $u$ and $v$ are in the image space but $z^{r}$ in root-relative 3D space. Thus, the ground-truth information (e.g., the depth of root joint from the camera) is normally utilized to transform the 2.5D output to the 3D space, which limits the applicability in practice. In this work, we propose a novel end-to-end framework that not only exploits the contextual information but also produces the output directly in the 3D space via cascaded dimension-lifting. Specifically, we decompose the task of lifting pose from 2D image space to 3D spatial space into several sequential sub-tasks, 1) kinematic skeletons \& individual joints estimation in 2D space, 2) root-relative depth estimation, and 3) lifting to the 3D space, each of which employs direct supervisions and contextual image features to guide the learning process. Extensive experiments show that the proposed framework achieves state-of-the-art performance on two widely used 3D human pose datasets (Human3.6M, MuPoTS-3D).
Unsupervised learning of text line segmentationby differentiating coarse patterns
May 19, 2021
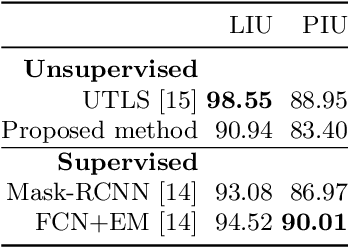

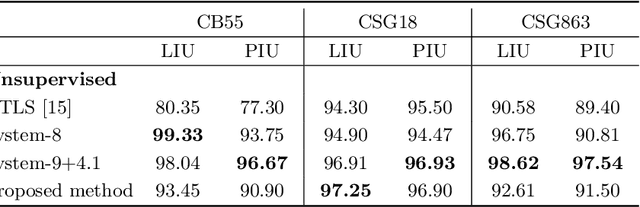
Despite recent advances in the field of supervised deep learning for text line segmentation, unsupervised deep learning solutions are beginning to gain popularity. In this paper, we present an unsupervised deep learning method that embeds document image patches to a compact Euclidean space where distances correspond to a coarse text line pattern similarity. Once this space has been produced, text line segmentation can be easily implemented using standard techniques with the embedded feature vectors. To train the model, we extract random pairs of document image patches with the assumption that neighbour patches contain a similar coarse trend of text lines, whereas if one of them is rotated, they contain different coarse trends of text lines. Doing well on this task requires the model to learn to recognize the text lines and their salient parts. The benefit of our approach is zero manual labelling effort. We evaluate the method qualitatively and quantitatively on several variants of text line segmentation datasets to demonstrate its effectivity.
A Weighted Multi-Criteria Decision Making Approach for Image Captioning
Mar 17, 2019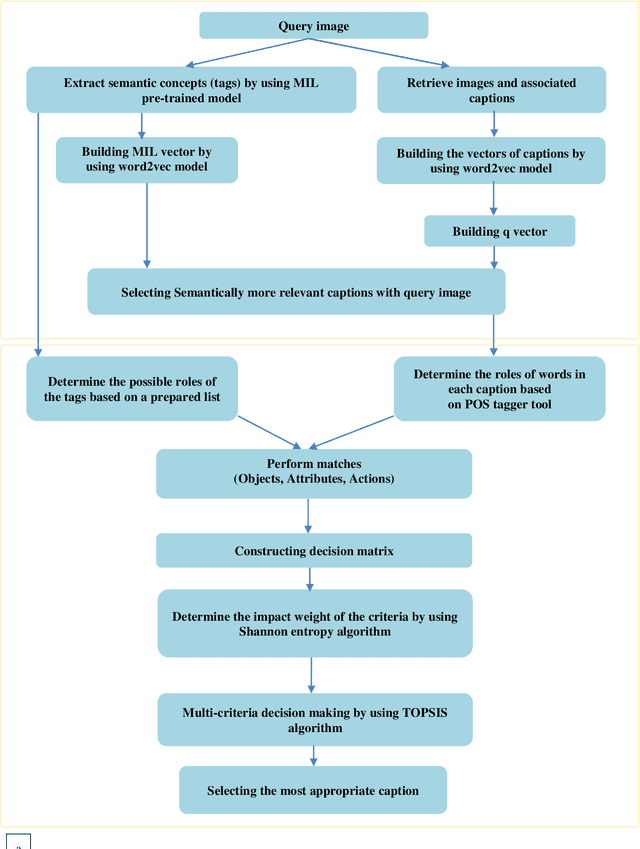
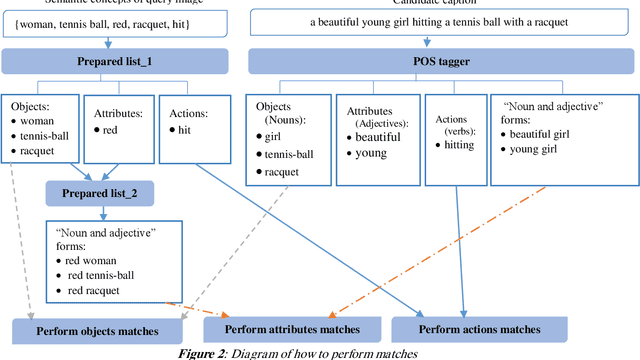
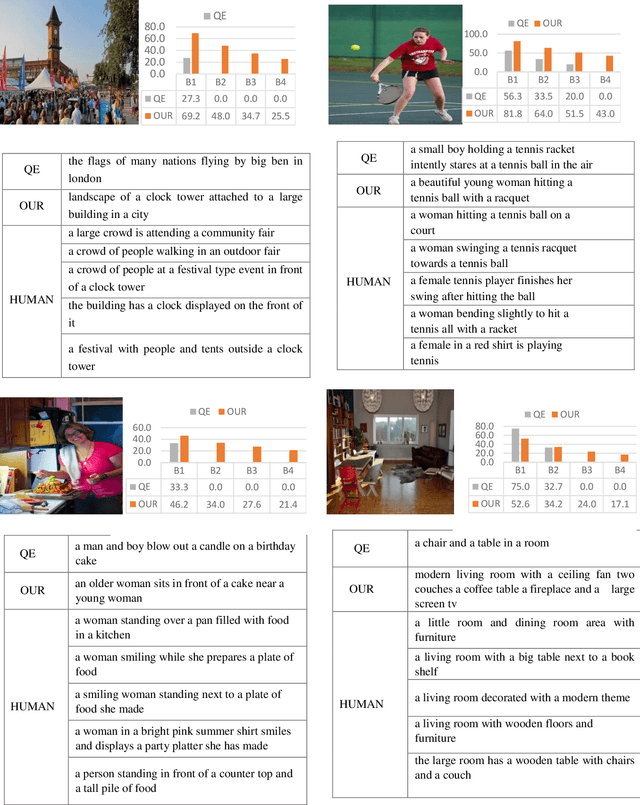
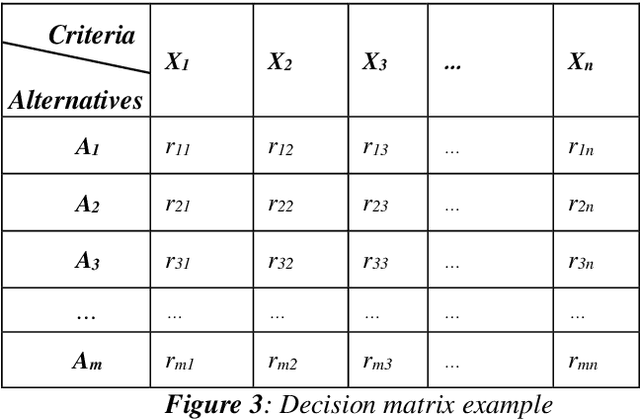
Image captioning aims at automatically generating descriptions of an image in natural language. This is a challenging problem in the field of artificial intelligence that has recently received significant attention in the computer vision and natural language processing. Among the existing approaches, visual retrieval based methods have been proven to be highly effective. These approaches search for similar images, then build a caption for the query image based on the captions of the retrieved images. In this study, we present a method for visual retrieval based image captioning, in which we use a multi criteria decision making algorithm to effectively combine several criteria with proportional impact weights to retrieve the most relevant caption for the query image. The main idea of the proposed approach is to design a mechanism to retrieve more semantically relevant captions with the query image and then selecting the most appropriate caption by imitation of the human act based on a weighted multi-criteria decision making algorithm. Experiments conducted on MS COCO benchmark dataset have shown that proposed method provides much more effective results in compare to the state-of-the-art models by using criteria with proportional impact weights .
Event-Based Feature Tracking in Continuous Time with Sliding Window Optimization
Jul 09, 2021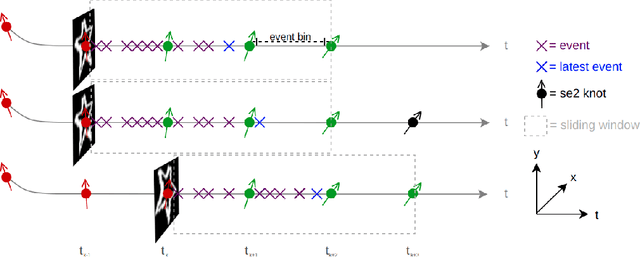
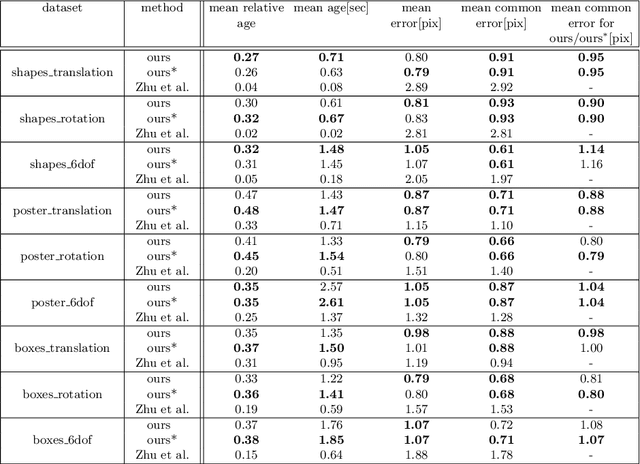
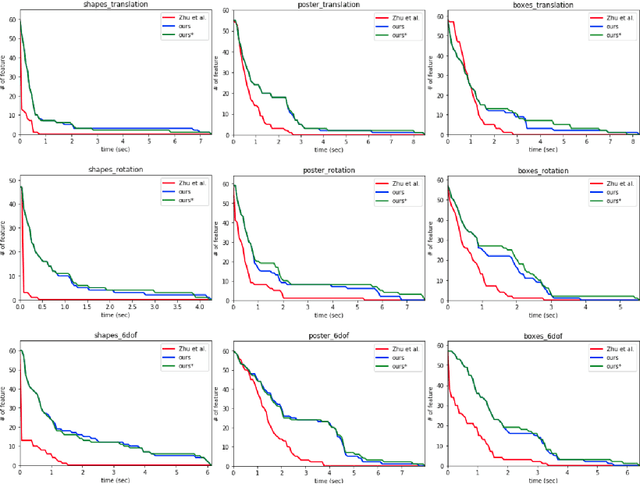

We propose a novel method for continuous-time feature tracking in event cameras. To this end, we track features by aligning events along an estimated trajectory in space-time such that the projection on the image plane results in maximally sharp event patch images. The trajectory is parameterized by $n^{th}$ order B-splines, which are continuous up to $(n-2)^{th}$ derivative. In contrast to previous work, we optimize the curve parameters in a sliding window fashion. On a public dataset we experimentally confirm that the proposed sliding-window B-spline optimization leads to longer and more accurate feature tracks than in previous work.
DerainCycleGAN: An Attention-guided Unsupervised Benchmark for Single Image Deraining and Rainmaking
Dec 15, 2019
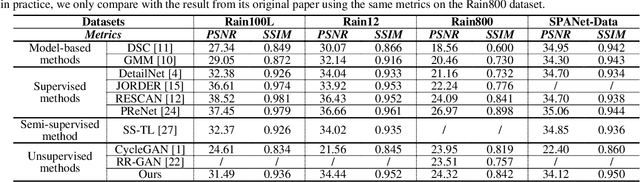


Single image deraining (SID) is an important and challenging topic in emerging vision applications, and most of emerged deraining methods are supervised relying on the ground truth (i.e., paired images) in recent years. However, in practice it is rather common to have no un-paired images in real deraining task, in such cases how to remove the rain streaks in an unsupervised way will be a very challenging task due to lack of constraints between images and hence suffering from low-quality recovery results. In this paper, we explore the unsupervised SID task using unpaired data and propose a novel net called Attention-guided Deraining by Constrained CycleGAN (or shortly, DerainCycleGAN), which can fully utilize the constrained transfer learning abilitiy and circulatory structure of CycleGAN. Specifically, we design an unsu-pervised attention guided rain streak extractor (U-ARSE) that utilizes a memory to extract the rain streak masks with two constrained cycle-consistency branches jointly by paying attention to both the rainy and rain-free image domains. As a by-product, we also contribute a new paired rain image dataset called Rain200A, which is constructed by our network automatically. Compared with existing synthesis datasets, the rainy streaks in Rain200A contains more obvious and diverse shapes and directions. As a result, existing supervised methods trained on Rain200A can perform much better for processing real rainy images. Extensive experiments on synthesis and real datasets show that our net is superior to existing unsupervised deraining networks, and is also very competitive to other related supervised networks.