 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Capturing Localized Image Artifacts through a CNN-based Hyper-image Representation
Nov 14, 2017

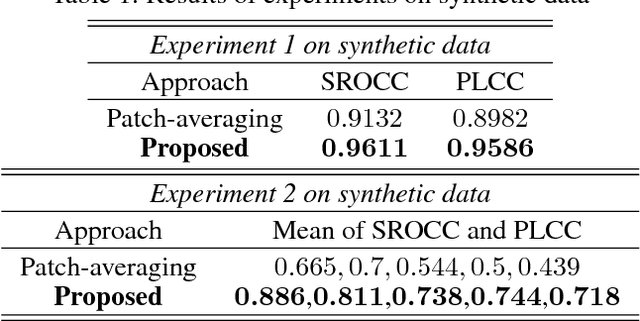
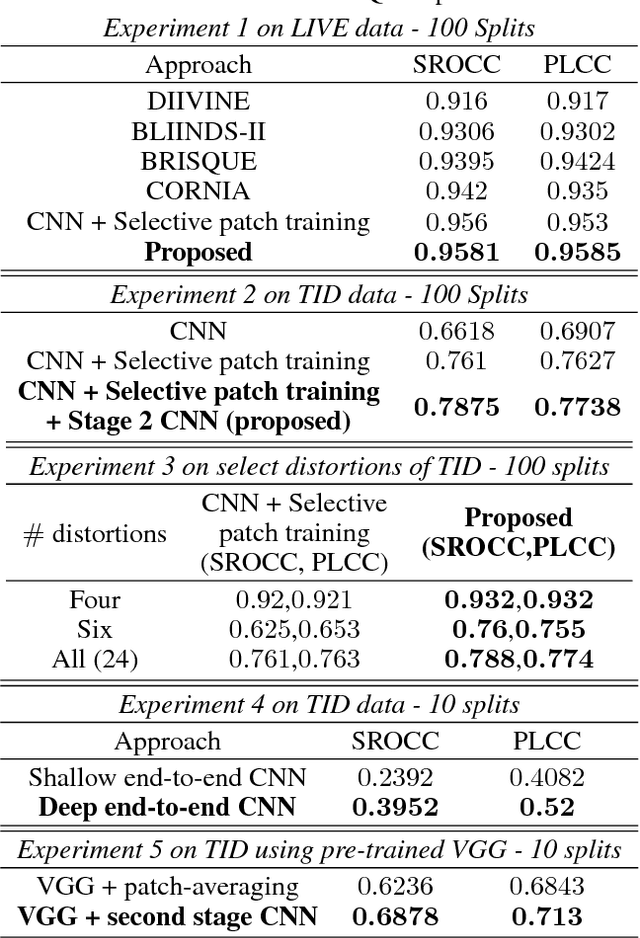

Training deep CNNs to capture localized image artifacts on a relatively small dataset is a challenging task. With enough images at hand, one can hope that a deep CNN characterizes localized artifacts over the entire data and their effect on the output. However, on smaller datasets, such deep CNNs may overfit and shallow ones find it hard to capture local artifacts. Thus some image-based small-data applications first train their framework on a collection of patches (instead of the entire image) to better learn the representation of localized artifacts. Then the output is obtained by averaging the patch-level results. Such an approach ignores the spatial correlation among patches and how various patch locations affect the output. It also fails in cases where few patches mainly contribute to the image label. To combat these scenarios, we develop the notion of hyper-image representations. Our CNN has two stages. The first stage is trained on patches. The second stage utilizes the last layer representation developed in the first stage to form a hyper-image, which is used to train the second stage. We show that this approach is able to develop a better mapping between the image and its output. We analyze additional properties of our approach and show its effectiveness on one synthetic and two real-world vision tasks - no-reference image quality estimation and image tampering detection - by its performance improvement over existing strong baselines.
CloudSegNet: A Deep Network for Nychthemeron Cloud Image Segmentation
Apr 16, 2019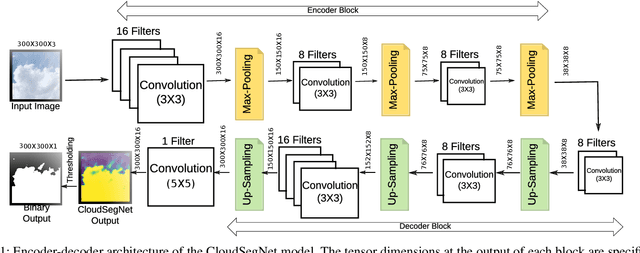
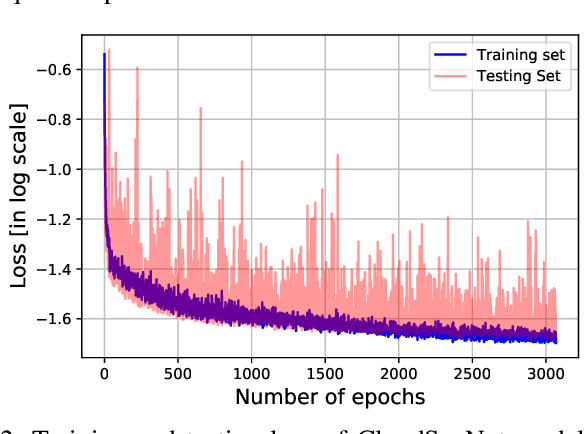
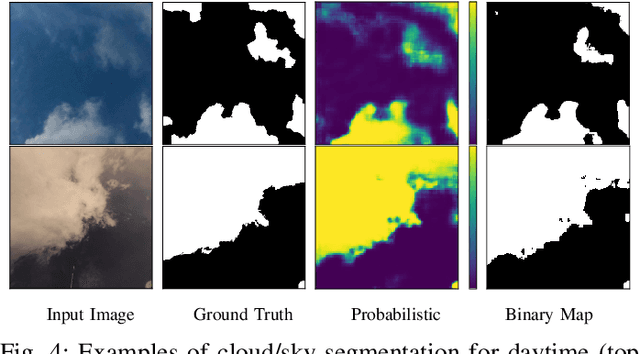
We analyze clouds in the earth's atmosphere using ground-based sky cameras. An accurate segmentation of clouds in the captured sky/cloud image is difficult, owing to the fuzzy boundaries of clouds. Several techniques have been proposed that use color as the discriminatory feature for cloud detection. In the existing literature, however, analysis of daytime and nighttime images is considered separately, mainly because of differences in image characteristics and applications. In this paper, we propose a light-weight deep-learning architecture called CloudSegNet. It is the first that integrates daytime and nighttime (also known as nychthemeron) image segmentation in a single framework, and achieves state-of-the-art results on public databases.
Sejong Face Database: A Multi-Modal Disguise Face Database
Jun 14, 2021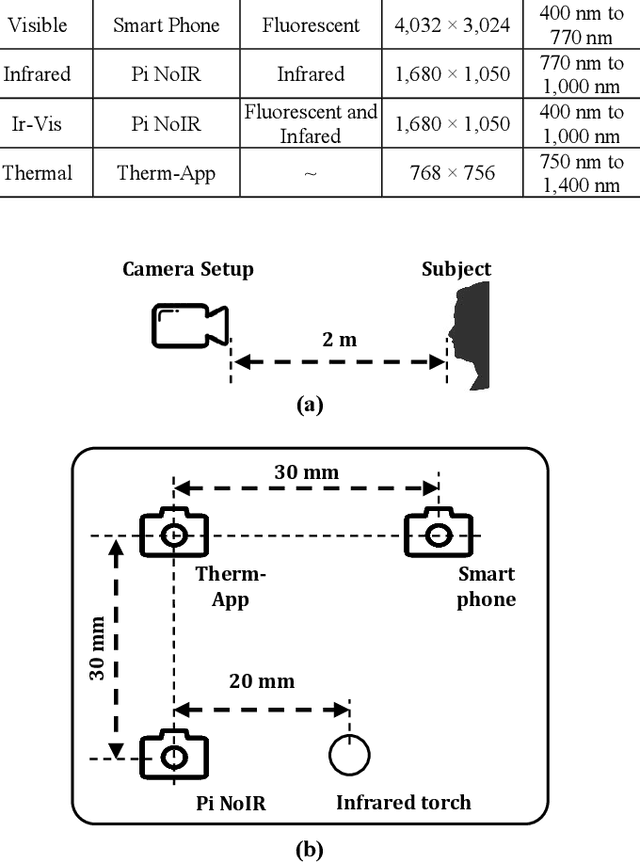
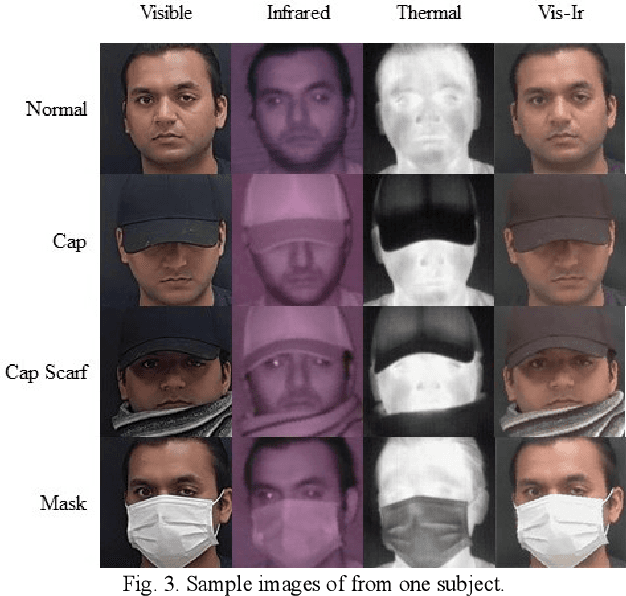
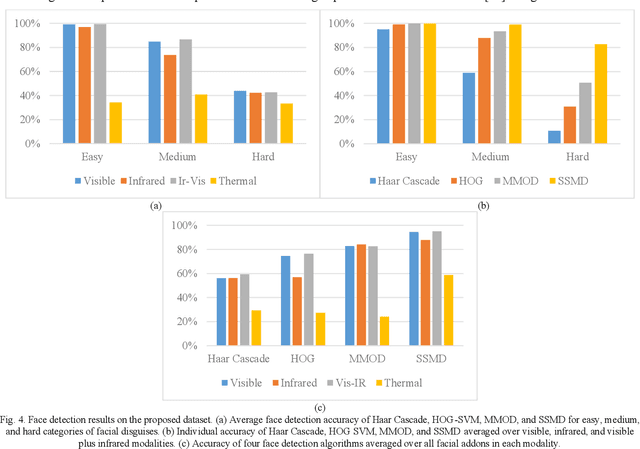

Commercial application of facial recognition demands robustness to a variety of challenges such as illumination, occlusion, spoofing, disguise, etc. Disguised face recognition is one of the emerging issues for access control systems, such as security checkpoints at the borders. However, the lack of availability of face databases with a variety of disguise addons limits the development of academic research in the area. In this paper, we present a multimodal disguised face dataset to facilitate the disguised face recognition research. The presented database contains 8 facial add-ons and 7 additional combinations of these add-ons to create a variety of disguised face images. Each facial image is captured in visible, visible plus infrared, infrared, and thermal spectra. Specifically, the database contains 100 subjects divided into subset-A (30 subjects, 1 image per modality) and subset-B (70 subjects, 5 plus images per modality). We also present baseline face detection results performed on the proposed database to provide reference results and compare the performance in different modalities. Qualitative and quantitative analysis is performed to evaluate the challenging nature of disguise addons. The dataset will be publicly available with the acceptance of the research article. The database is available at: https://github.com/usmancheema89/SejongFaceDatabase.
* Database Access Link: https://github.com/usmancheema89/SejongFaceDatabase
Greedy Gradient Ensemble for Robust Visual Question Answering
Aug 09, 2021
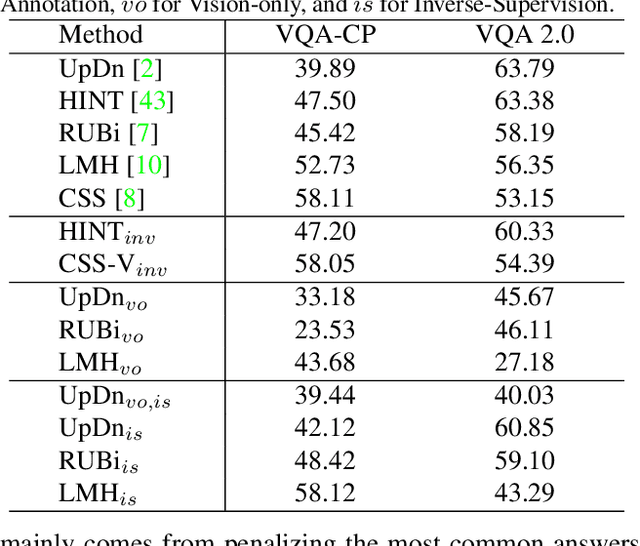
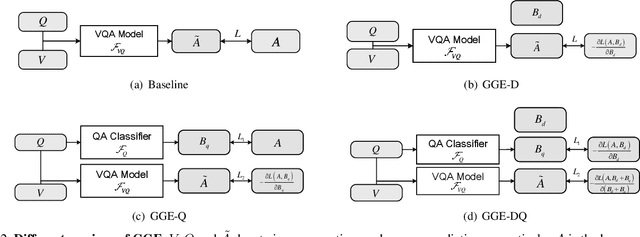
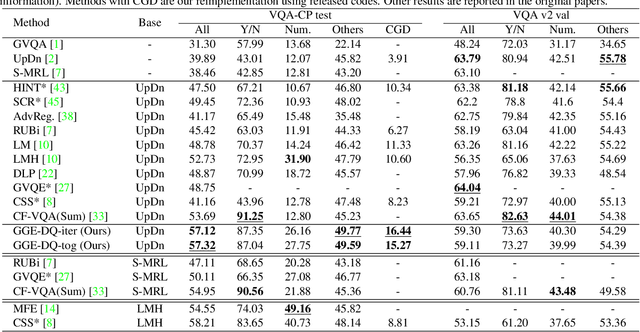
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.
CycleDRUMS: Automatic Drum Arrangement For Bass Lines Using CycleGAN
Apr 09, 2021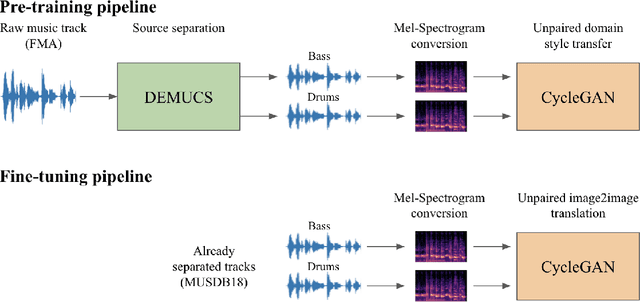
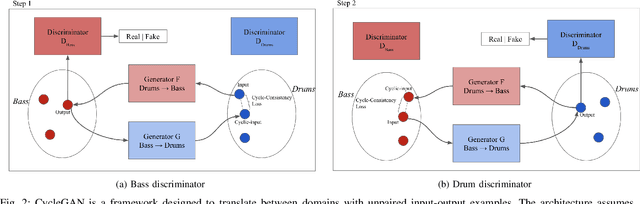
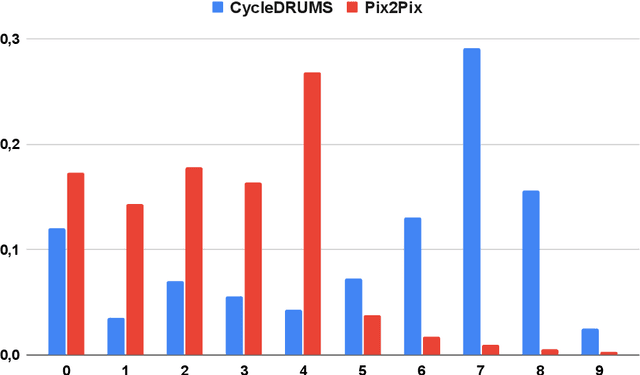
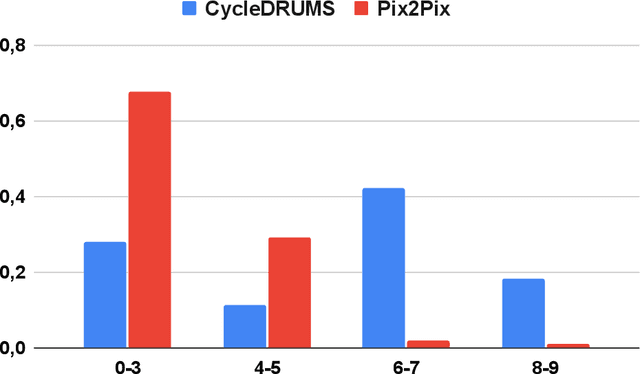
The two main research threads in computer-based music generation are: the construction of autonomous music-making systems, and the design of computer-based environments to assist musicians. In the symbolic domain, the key problem of automatically arranging a piece music was extensively studied, while relatively fewer systems tackled this challenge in the audio domain. In this contribution, we propose CycleDRUMS, a novel method for generating drums given a bass line. After converting the waveform of the bass into a mel-spectrogram, we are able to automatically generate original drums that follow the beat, sound credible and can be directly mixed with the input bass. We formulated this task as an unpaired image-to-image translation problem, and we addressed it with CycleGAN, a well-established unsupervised style transfer framework, originally designed for treating images. The choice to deploy raw audio and mel-spectrograms enabled us to better represent how humans perceive music, and to potentially draw sounds for new arrangements from the vast collection of music recordings accumulated in the last century. In absence of an objective way of evaluating the output of both generative adversarial networks and music generative systems, we further defined a possible metric for the proposed task, partially based on human (and expert) judgement. Finally, as a comparison, we replicated our results with Pix2Pix, a paired image-to-image translation network, and we showed that our approach outperforms it.
Inertial nonconvex alternating minimizations for the image deblurring
Jul 27, 2019
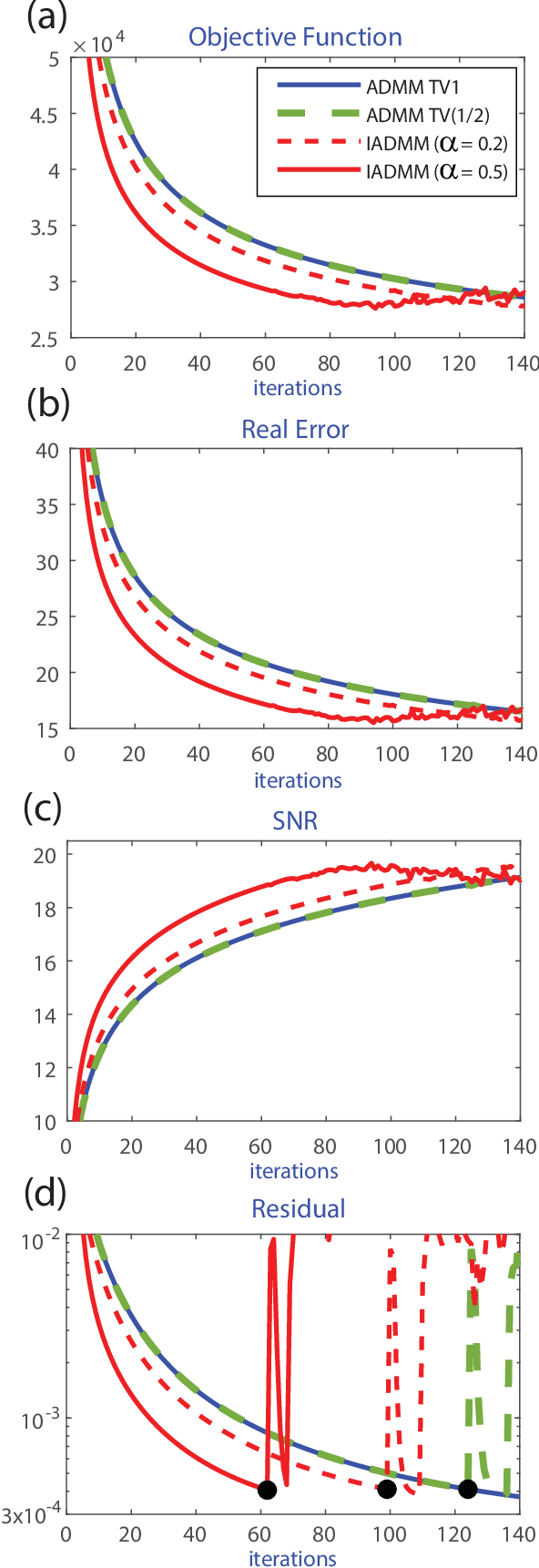
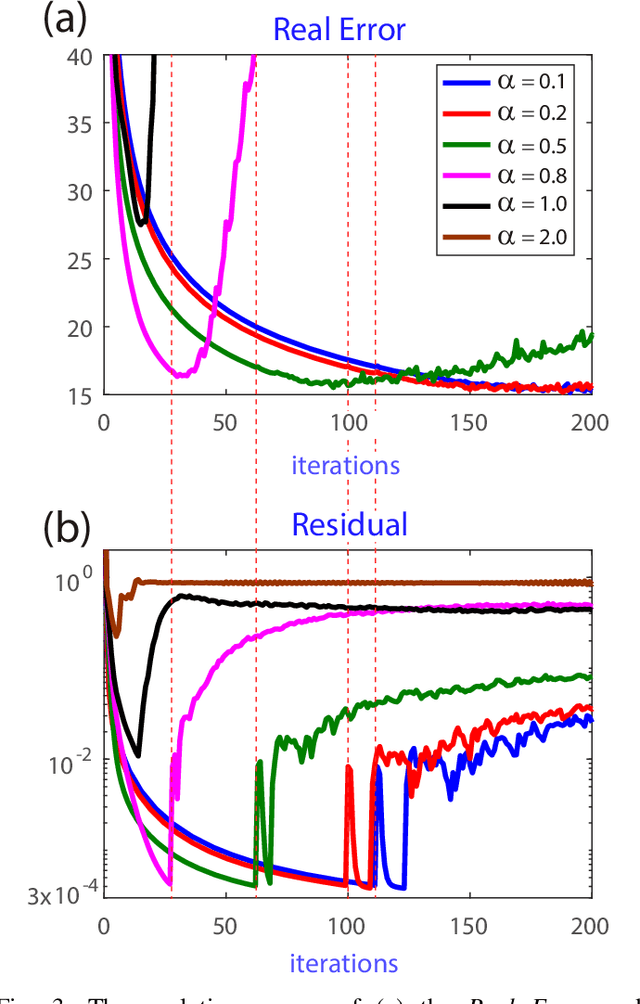
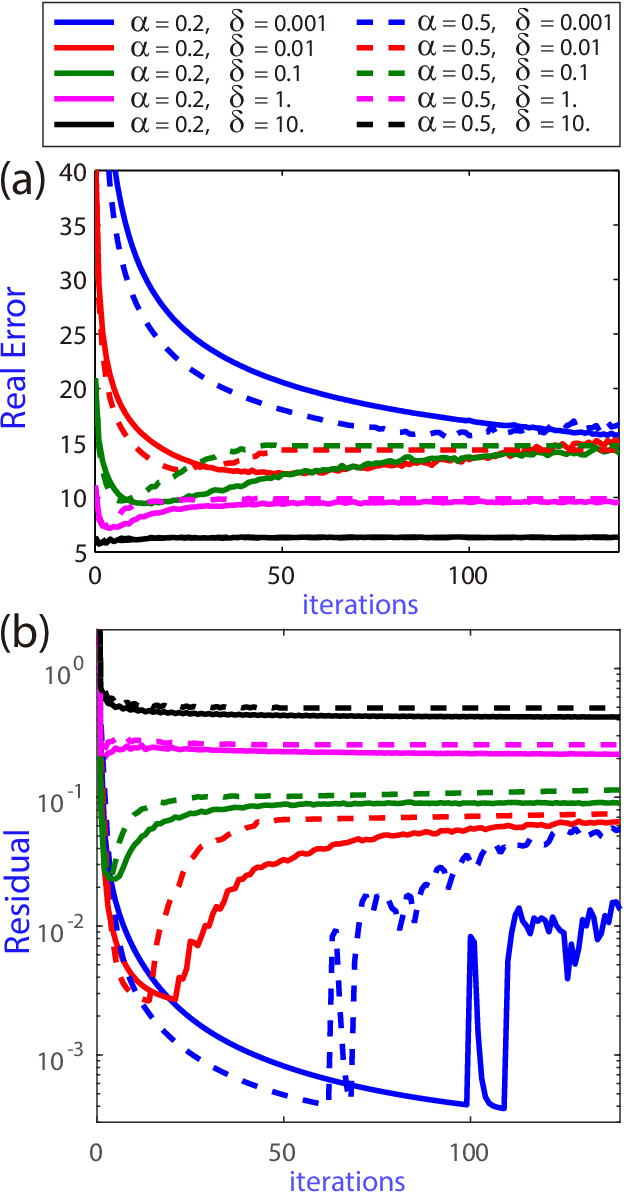
In image processing, Total Variation (TV) regularization models are commonly used to recover blurred images. One of the most efficient and popular methods to solve the convex TV problem is the Alternating Direction Method of Multipliers (ADMM) algorithm, recently extended using the inertial proximal point method. Although all the classical studies focus on only a convex formulation, recent articles are paying increasing attention to the nonconvex methodology due to its good numerical performance and properties. In this paper, we propose to extend the classical formulation with a novel nonconvex Alternating Direction Method of Multipliers with the Inertial technique (IADMM). Under certain assumptions on the parameters, we prove the convergence of the algorithm with the help of the Kurdyka-{\L}ojasiewicz property. We also present numerical simulations on classical TV image reconstruction problems to illustrate the efficiency of the new algorithm and its behavior compared with the well established ADMM method.
Mutual information neural estimation in CNN-based end-to-end medical image registration
Aug 23, 2019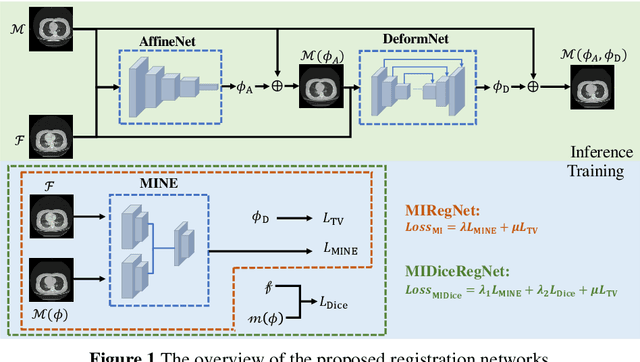
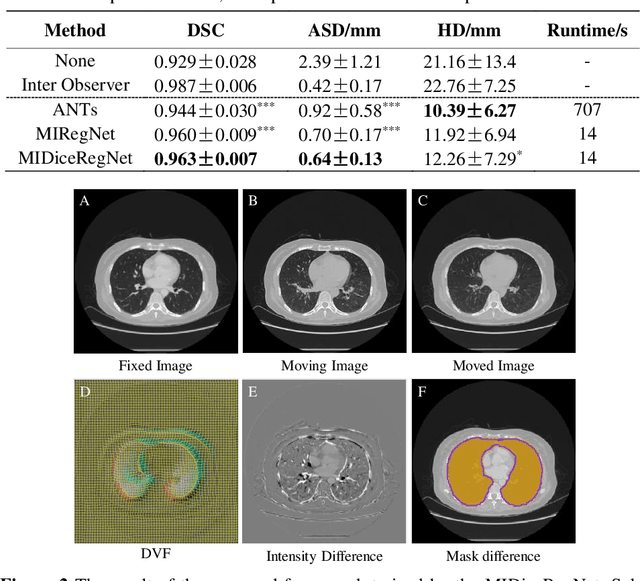
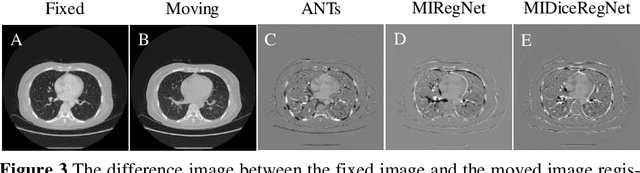
Image registration is one of the most underlined processes in medical image analysis. Recently, convolutional neural networks (CNNs) have shown significant potential in both affine and deformable registration. However, the lack of voxel-wise ground truth challenges the training of an accurate CNN-based registration. In this work, we implement a CNN-based mutual information neural estimator for image registration that evaluates the registration outputs in an unsupervised manner. Based on the estimator, we propose an end-to-end registration framework, denoted as MIRegNet, to realize one-shot affine and deformable registration. Furthermore, we propose a weakly supervised network combining mutual information with the Dice similarity coefficients (DSC) loss. We employed a dataset consisting of 190 pairs of 3D pulmonary CT images for validation. Results showed that the MIRegNet obtained an average Dice score of 0.960 for registering the pulmonary images, and the Dice score was further improved to 0.963 when the DSC was included for a weakly supervised learning of image registration.
Unsupervised learning of text line segmentation by differentiating coarse patterns
May 21, 2021
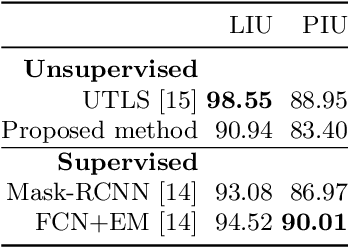

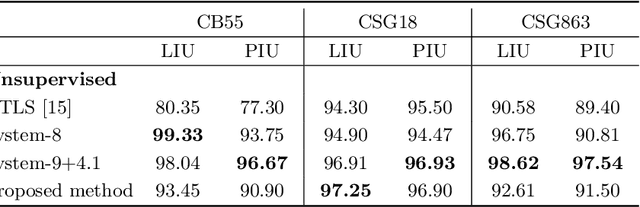
Despite recent advances in the field of supervised deep learning for text line segmentation, unsupervised deep learning solutions are beginning to gain popularity. In this paper, we present an unsupervised deep learning method that embeds document image patches to a compact Euclidean space where distances correspond to a coarse text line pattern similarity. Once this space has been produced, text line segmentation can be easily implemented using standard techniques with the embedded feature vectors. To train the model, we extract random pairs of document image patches with the assumption that neighbour patches contain a similar coarse trend of text lines, whereas if one of them is rotated, they contain different coarse trends of text lines. Doing well on this task requires the model to learn to recognize the text lines and their salient parts. The benefit of our approach is zero manual labelling effort. We evaluate the method qualitatively and quantitatively on several variants of text line segmentation datasets to demonstrate its effectivity.
The Report on China-Spain Joint Clinical Testing for Rapid COVID-19 Risk Screening by Eye-region Manifestations
Sep 18, 2021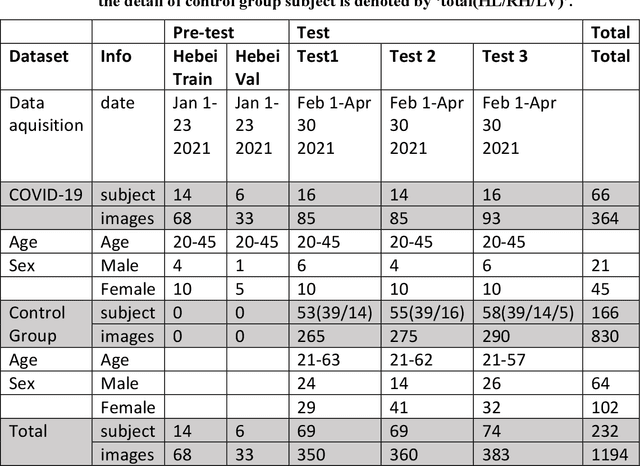

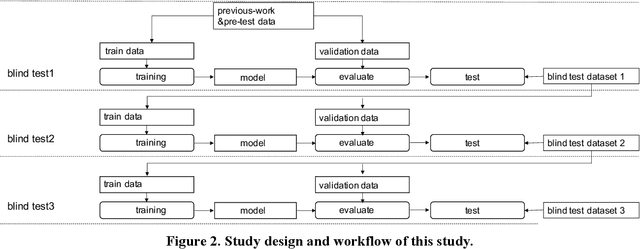
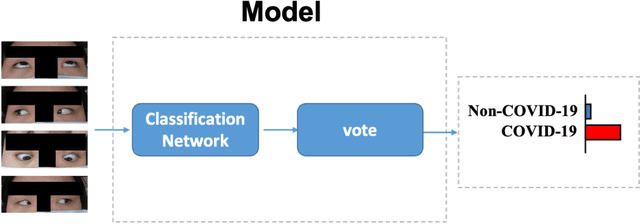
Background: The worldwide surge in coronavirus cases has led to the COVID-19 testing demand surge. Rapid, accurate, and cost-effective COVID-19 screening tests working at a population level are in imperative demand globally. Methods: Based on the eye symptoms of COVID-19, we developed and tested a COVID-19 rapid prescreening model using the eye-region images captured in China and Spain with cellphone cameras. The convolutional neural networks (CNNs)-based model was trained on these eye images to complete binary classification task of identifying the COVID-19 cases. The performance was measured using area under receiver-operating-characteristic curve (AUC), sensitivity, specificity, accuracy, and F1. The application programming interface was open access. Findings: The multicenter study included 2436 pictures corresponding to 657 subjects (155 COVID-19 infection, 23.6%) in development dataset (train and validation) and 2138 pictures corresponding to 478 subjects (64 COVID-19 infections, 13.4%) in test dataset. The image-level performance of COVID-19 prescreening model in the China-Spain multicenter study achieved an AUC of 0.913 (95% CI, 0.898-0.927), with a sensitivity of 0.695 (95% CI, 0.643-0.748), a specificity of 0.904 (95% CI, 0.891 -0.919), an accuracy of 0.875(0.861-0.889), and a F1 of 0.611(0.568-0.655). Interpretation: The CNN-based model for COVID-19 rapid prescreening has reliable specificity and sensitivity. This system provides a low-cost, fully self-performed, non-invasive, real-time feedback solution for continuous surveillance and large-scale rapid prescreening for COVID-19. Funding: This project is supported by Aimomics (Shanghai) Intelligent
An Approach Towards Physics Informed Lung Ultrasound Image Scoring Neural Network for Diagnostic Assistance in COVID-19
Jun 13, 2021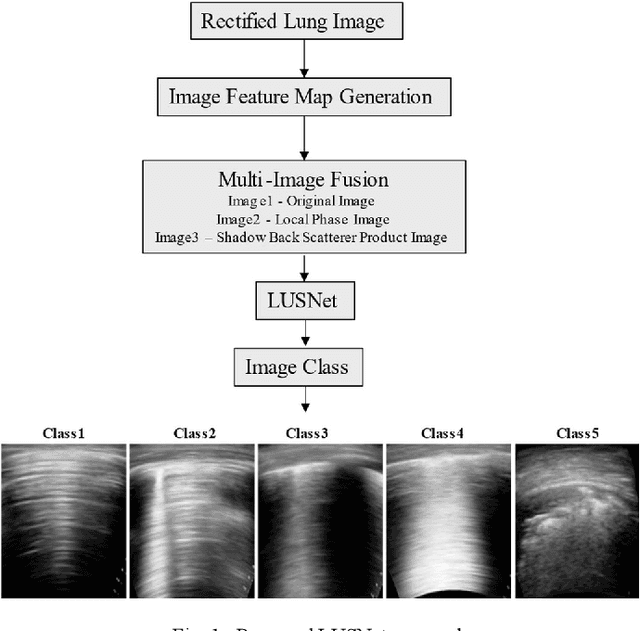
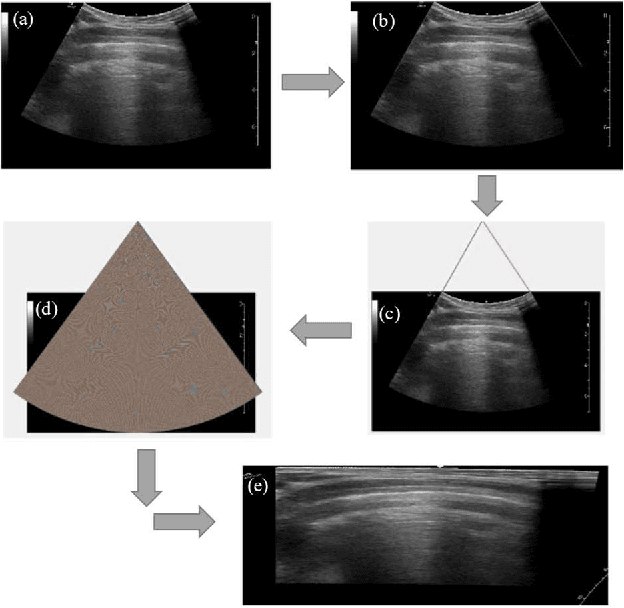
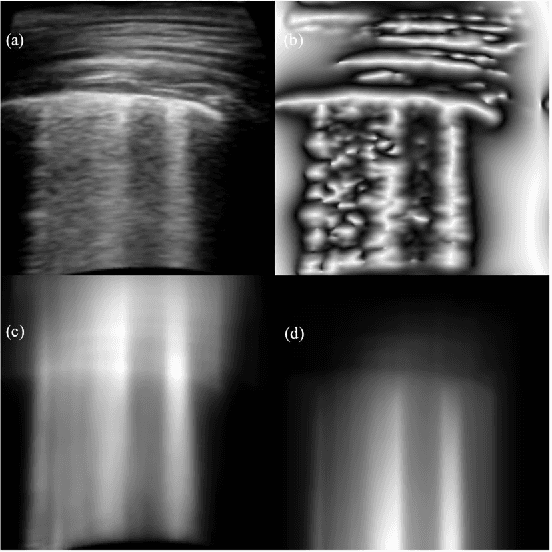
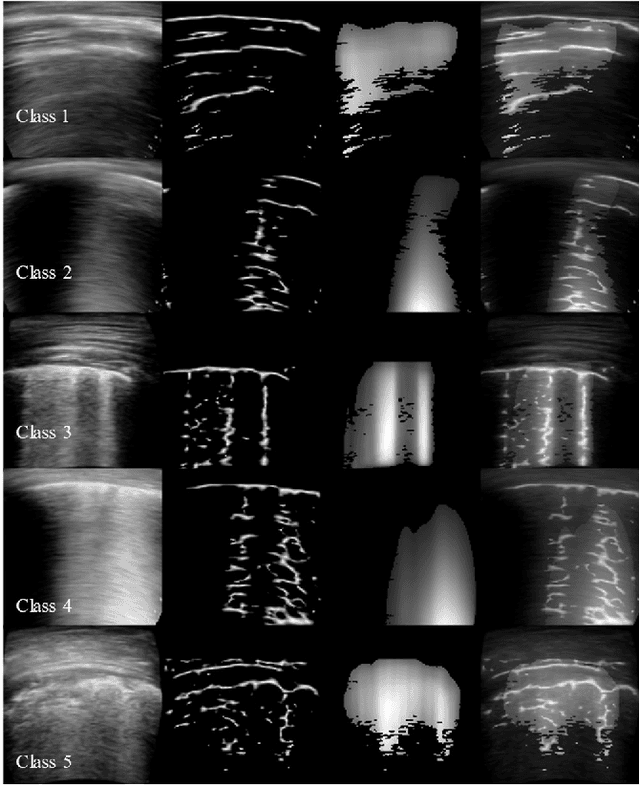
Ultrasound is fast becoming an inevitable diagnostic tool for regular and continuous monitoring of the lung with the recent outbreak of COVID-19. In this work, a novel approach is presented to extract acoustic propagation-based features to automatically highlight the region below pleura, which is an important landmark in lung ultrasound (LUS). Subsequently, a multichannel input formed by using the acoustic physics-based feature maps is fused to train a neural network, referred to as LUSNet, to classify the LUS images into five classes of varying severity of lung infection to track the progression of COVID-19. In order to ensure that the proposed approach is agnostic to the type of acquisition, the LUSNet, which consists of a U-net architecture is trained in an unsupervised manner with the acoustic feature maps to ensure that the encoder-decoder architecture is learning features in the pleural region of interest. A novel combination of the U-net output and the U-net encoder output is employed for the classification of severity of infection in the lung. A detailed analysis of the proposed approach on LUS images over the infection to full recovery period of ten confirmed COVID-19 subjects shows an average five-fold cross-validation accuracy, sensitivity, and specificity of 97%, 93%, and 98% respectively over 5000 frames of COVID-19 videos. The analysis also shows that, when the input dataset is limited and diverse as in the case of COVID-19 pandemic, an aided effort of combining acoustic propagation-based features along with the gray scale images, as proposed in this work, improves the performance of the neural network significantly and also aids the labelling and triaging process.