 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Proposing a System Level Machine Learning Hybrid Architecture and Approach for a Comprehensive Autism Spectrum Disorder Diagnosis
Sep 18, 2021
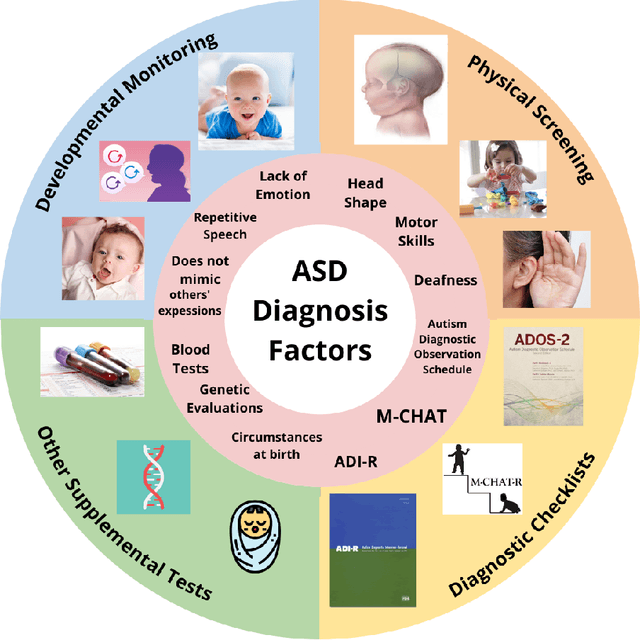
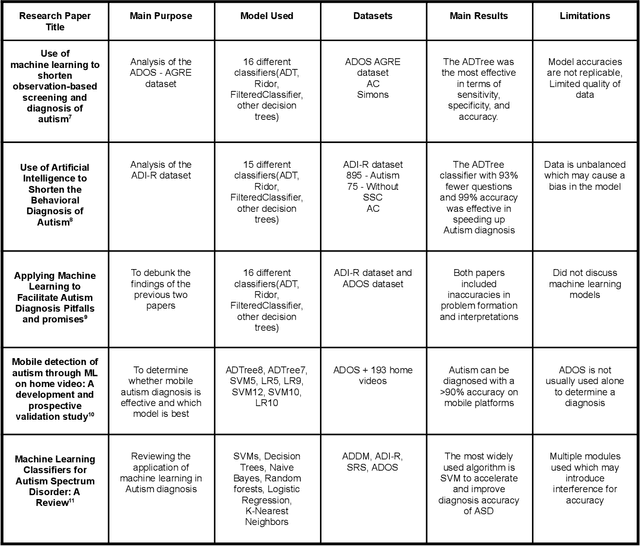
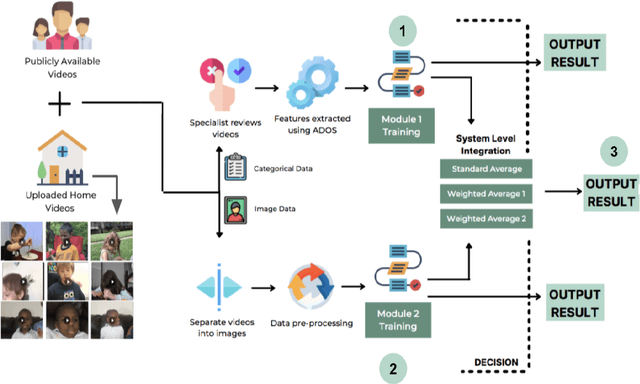
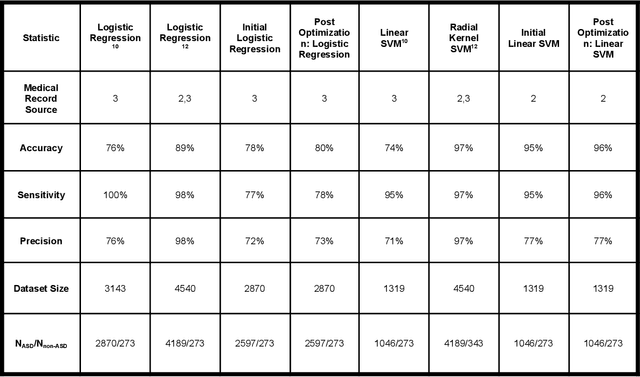
Autism Spectrum Disorder (ASD) is a severe neuropsychiatric disorder that affects intellectual development, social behavior, and facial features, and the number of cases is still significantly increasing. Due to the variety of symptoms ASD displays, the diagnosis process remains challenging, with numerous misdiagnoses as well as lengthy and expensive diagnoses. Fortunately, if ASD is diagnosed and treated early, then the patient will have a much higher chance of developing normally. For an ASD diagnosis, machine learning algorithms can analyze both social behavior and facial features accurately and efficiently, providing an ASD diagnosis in a drastically shorter amount of time than through current clinical diagnosis processes. Therefore, we propose to develop a hybrid architecture fully utilizing both social behavior and facial feature data to improve the accuracy of diagnosing ASD. We first developed a Linear Support Vector Machine for the social behavior based module, which analyzes Autism Diagnostic Observation Schedule (ADOS) social behavior data. For the facial feature based module, a DenseNet model was utilized to analyze facial feature image data. Finally, we implemented our hybrid model by incorporating different features of the Support Vector Machine and the DenseNet into one model. Our results show that the highest accuracy of 87% for ASD diagnosis has been achieved by our proposed hybrid model. The pros and cons of each module will be discussed in this paper.
Is deep learning a good choice for image segmentation?
Apr 16, 2019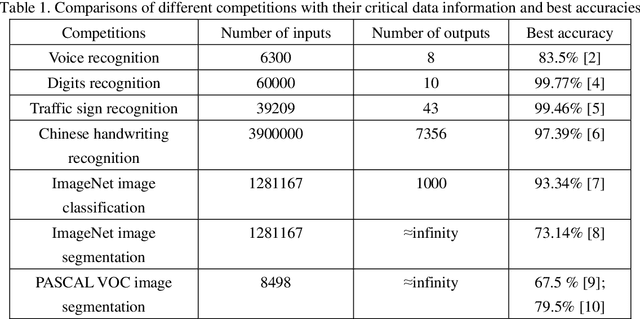
Deep learning works as a discrete non-linear mapping function and has achieved great success as a powerful classification tool. However, it has been overhyped in many fields. This comment takes image segmentation as a typical filed to prove this point of view. Firstly, deep learning is not omnipotent. It only generates a prediction map and relies on other segmentation methods to complete the segmentation task. Secondly, the performance of deep learning is inversely proportional to the number of outputs. Consequently, deep learning is not a good choice for image segmentation unless the resolution of the image is extremely small.
On the Initial Behavior Monitoring Issues in Federated Learning
Sep 11, 2021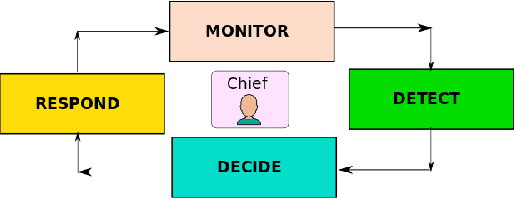
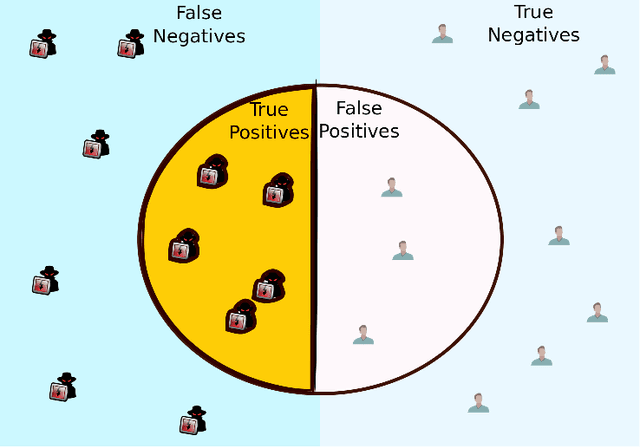
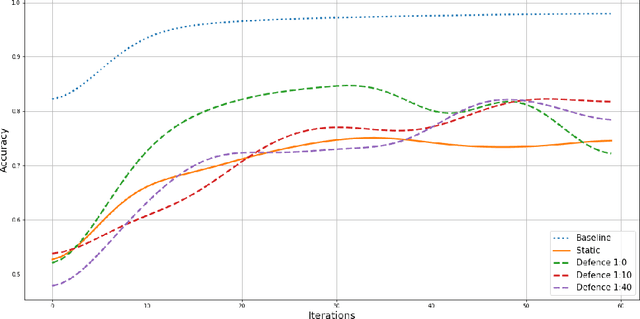
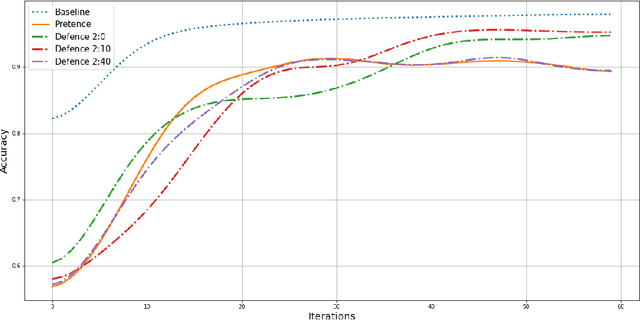
In Federated Learning (FL), a group of workers participate to build a global model under the coordination of one node, the chief. Regarding the cybersecurity of FL, some attacks aim at injecting the fabricated local model updates into the system. Some defenses are based on malicious worker detection and behavioral pattern analysis. In this context, without timely and dynamic monitoring methods, the chief cannot detect and remove the malicious or unreliable workers from the system. Our work emphasize the urgency to prepare the federated learning process for monitoring and eventually behavioral pattern analysis. We study the information inside the learning process in the early stages of training, propose a monitoring process and evaluate the monitoring period required. The aim is to analyse at what time is it appropriate to start the detection algorithm in order to remove the malicious or unreliable workers from the system and optimise the defense mechanism deployment. We tested our strategy on a behavioral pattern analysis defense applied to the FL process of different benchmark systems for text and image classification. Our results show that the monitoring process lowers false positives and false negatives and consequently increases system efficiency by enabling the distributed learning system to achieve better performance in the early stage of training.
A Fast Content-Based Image Retrieval Method Using Deep Visual Features
Aug 05, 2019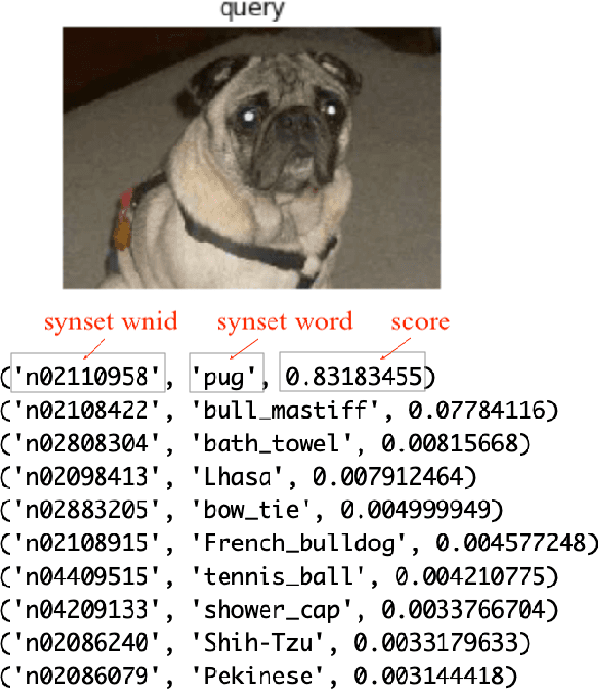



Fast and scalable Content-Based Image Retrieval using visual features is required for document analysis, Medical image analysis, etc. in the present age. Convolutional Neural Network (CNN) activations as features achieved their outstanding performance in this area. Deep Convolutional representations using the softmax function in the output layer are also ones among visual features. However, almost all the image retrieval systems hold their index of visual features on main memory in order to high responsiveness, limiting their applicability for big data applications. In this paper, we propose a fast calculation method of cosine similarity with L2 norm indexed in advance on Elasticsearch. We evaluate our approach with ImageNet Dataset and VGG-16 pre-trained model. The evaluation results show the effectiveness and efficiency of our proposed method.
XNAT-PIC: Extending XNAT to Preclinical Imaging Centers
Feb 23, 2021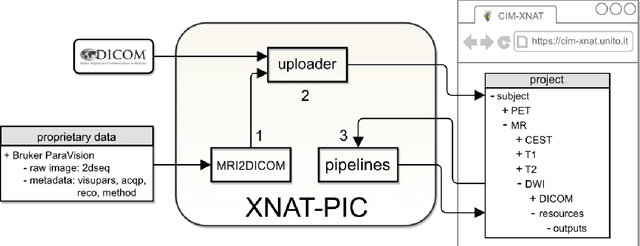
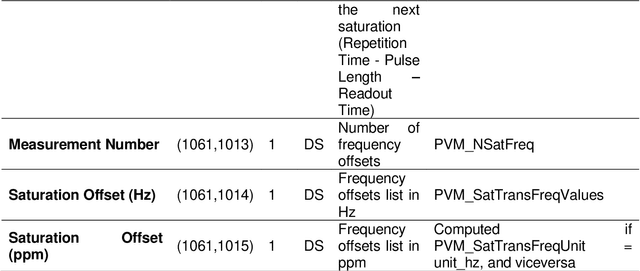
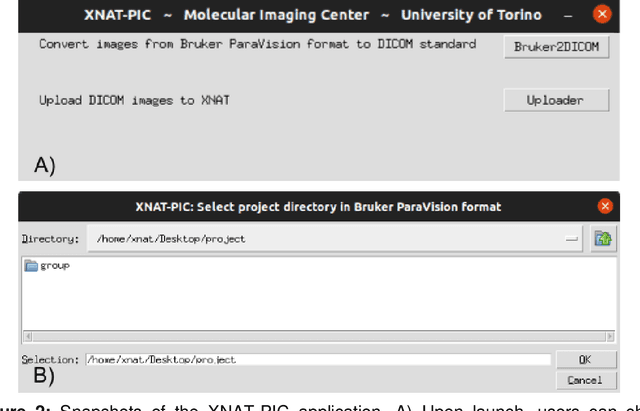
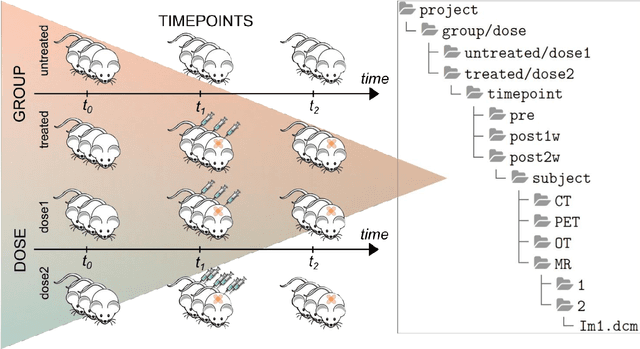
Molecular imaging generates large volumes of heterogeneous biomedical imagery with an impelling need of guidelines for handling image data. Although several successful solutions have been implemented for human epidemiologic studies, few and limited approaches have been proposed for animal population studies. Preclinical imaging research deals with a variety of machinery yielding tons of raw data but the current practices to store and distribute image data are inadequate. Therefore, standard tools for the analysis of large image datasets need to be established. In this paper, we present an extension of XNAT for Preclinical Imaging Centers (XNAT-PIC). XNAT is a worldwide used, open-source platform for securely hosting, sharing, and processing of clinical imaging studies. Despite its success, neither tools for importing large, multimodal preclinical image datasets nor pipelines for processing whole imaging studies are yet available in XNAT. In order to overcome these limitations, we have developed several tools to expand the XNAT core functionalities for supporting preclinical imaging facilities. Our aim is to streamline the management and exchange of image data within the preclinical imaging community, thereby enhancing the reproducibility of the results of image processing and promoting open science practices.
A Workflow for Offline Model-Free Robotic Reinforcement Learning
Sep 23, 2021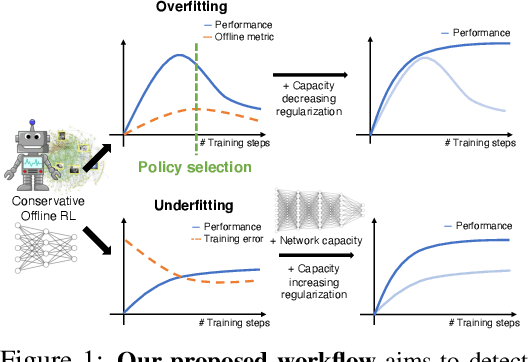

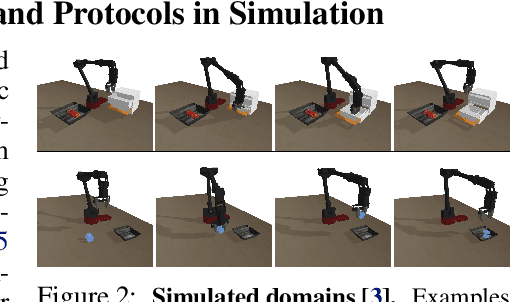
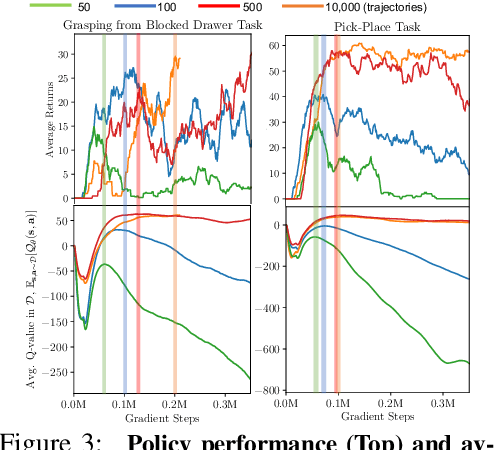
Offline reinforcement learning (RL) enables learning control policies by utilizing only prior experience, without any online interaction. This can allow robots to acquire generalizable skills from large and diverse datasets, without any costly or unsafe online data collection. Despite recent algorithmic advances in offline RL, applying these methods to real-world problems has proven challenging. Although offline RL methods can learn from prior data, there is no clear and well-understood process for making various design choices, from model architecture to algorithm hyperparameters, without actually evaluating the learned policies online. In this paper, our aim is to develop a practical workflow for using offline RL analogous to the relatively well-understood workflows for supervised learning problems. To this end, we devise a set of metrics and conditions that can be tracked over the course of offline training, and can inform the practitioner about how the algorithm and model architecture should be adjusted to improve final performance. Our workflow is derived from a conceptual understanding of the behavior of conservative offline RL algorithms and cross-validation in supervised learning. We demonstrate the efficacy of this workflow in producing effective policies without any online tuning, both in several simulated robotic learning scenarios and for three tasks on two distinct real robots, focusing on learning manipulation skills with raw image observations with sparse binary rewards. Explanatory video and additional results can be found at sites.google.com/view/offline-rl-workflow
SAIL-VOS 3D: A Synthetic Dataset and Baselines for Object Detection and 3D Mesh Reconstruction from Video Data
May 18, 2021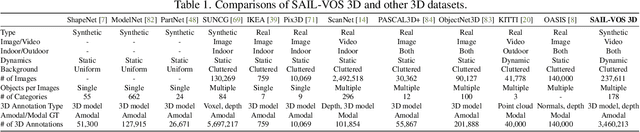
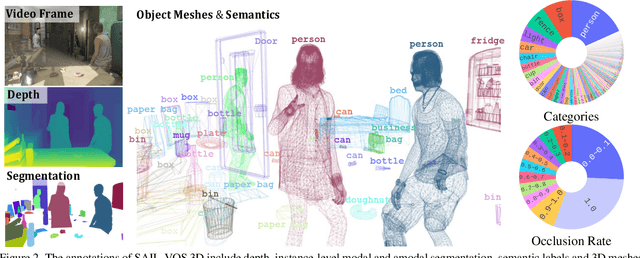

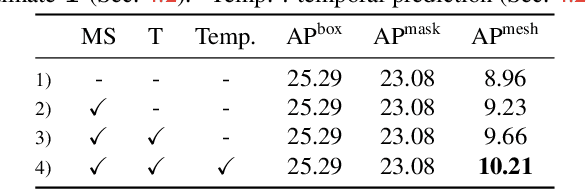
Extracting detailed 3D information of objects from video data is an important goal for holistic scene understanding. While recent methods have shown impressive results when reconstructing meshes of objects from a single image, results often remain ambiguous as part of the object is unobserved. Moreover, existing image-based datasets for mesh reconstruction don't permit to study models which integrate temporal information. To alleviate both concerns we present SAIL-VOS 3D: a synthetic video dataset with frame-by-frame mesh annotations which extends SAIL-VOS. We also develop first baselines for reconstruction of 3D meshes from video data via temporal models. We demonstrate efficacy of the proposed baseline on SAIL-VOS 3D and Pix3D, showing that temporal information improves reconstruction quality. Resources and additional information are available at http://sailvos.web.illinois.edu.
Scalable Visual Transformers with Hierarchical Pooling
Mar 19, 2021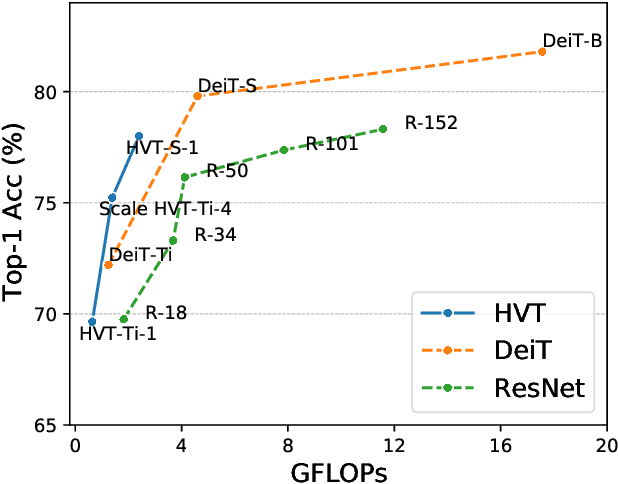

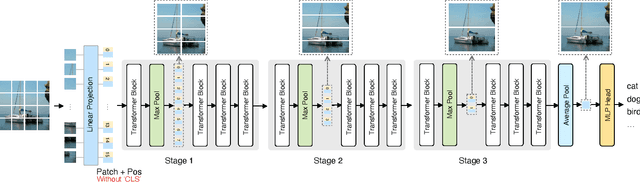

The recently proposed Visual image Transformers (ViT) with pure attention have achieved promising performance on image recognition tasks, such as image classification. However, the routine of the current ViT model is to maintain a full-length patch sequence during inference, which is redundant and lacks hierarchical representation. To this end, we propose a Hierarchical Visual Transformer (HVT) which progressively pools visual tokens to shrink the sequence length and hence reduces the computational cost, analogous to the feature maps downsampling in Convolutional Neural Networks (CNNs). It brings a great benefit that we can increase the model capacity by scaling dimensions of depth/width/resolution/patch size without introducing extra computational complexity due to the reduced sequence length. Moreover, we empirically find that the average pooled visual tokens contain more discriminative information than the single class token. To demonstrate the improved scalability of our HVT, we conduct extensive experiments on the image classification task. With comparable FLOPs, our HVT outperforms the competitive baselines on ImageNet and CIFAR-100 datasets.
NewsCLIPpings: Automatic Generation of Out-of-Context Multimodal Media
Apr 13, 2021
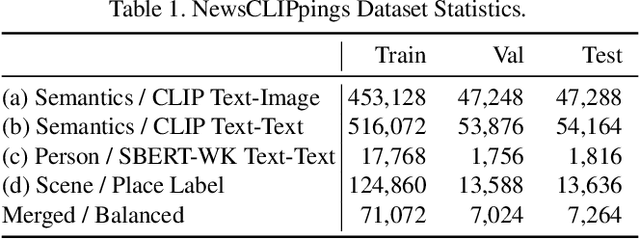
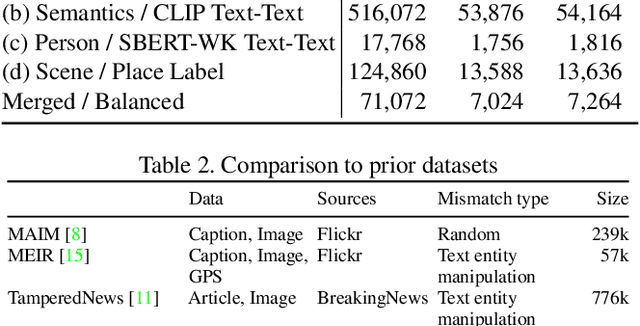

The threat of online misinformation is hard to overestimate, with adversaries relying on a range of tools, from cheap fakes to sophisticated deep fakes. We are motivated by a threat scenario where an image is being used out of context to support a certain narrative expressed in a caption. While some prior datasets for detecting image-text inconsistency can be solved with blind models due to linguistic cues introduced by text manipulation, we propose a dataset where both image and text are unmanipulated but mismatched. We introduce several strategies for automatic retrieval of suitable images for the given captions, capturing cases with related semantics but inconsistent entities as well as matching entities but inconsistent semantic context. Our large-scale automatically generated NewsCLIPpings Dataset requires models to jointly analyze both modalities and to reason about entity mismatch as well as semantic mismatch between text and images in news media.
Deep Visual Reasoning: Learning to Predict Action Sequences for Task and Motion Planning from an Initial Scene Image
Jun 09, 2020
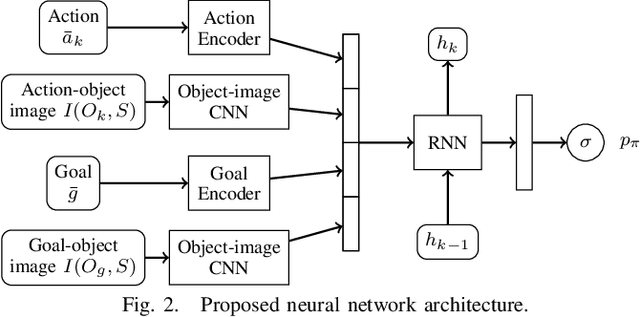
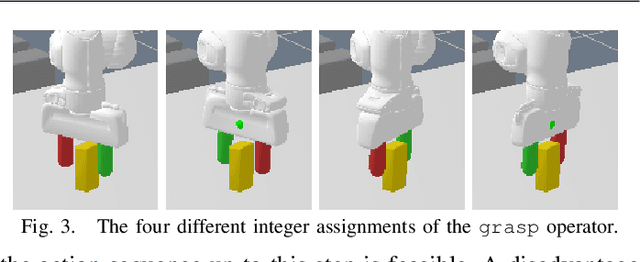
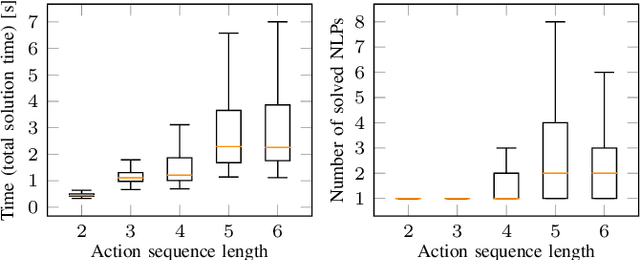
In this paper, we propose a deep convolutional recurrent neural network that predicts action sequences for task and motion planning (TAMP) from an initial scene image. Typical TAMP problems are formalized by combining reasoning on a symbolic, discrete level (e.g. first-order logic) with continuous motion planning such as nonlinear trajectory optimization. Due to the great combinatorial complexity of possible discrete action sequences, a large number of optimization/motion planning problems have to be solved to find a solution, which limits the scalability of these approaches. To circumvent this combinatorial complexity, we develop a neural network which, based on an initial image of the scene, directly predicts promising discrete action sequences such that ideally only one motion planning problem has to be solved to find a solution to the overall TAMP problem. A key aspect is that our method generalizes to scenes with many and varying number of objects, although being trained on only two objects at a time. This is possible by encoding the objects of the scene in images as input to the neural network, instead of a fixed feature vector. Results show runtime improvements of several magnitudes. Video: https://youtu.be/i8yyEbbvoEk