 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intention Oriented Image Captions with Guiding Objects
Nov 19, 2018
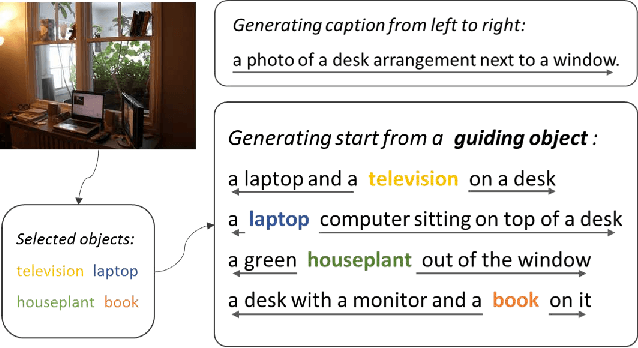
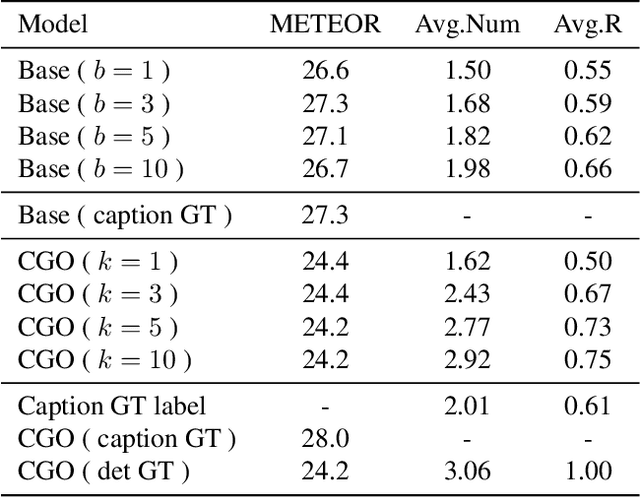
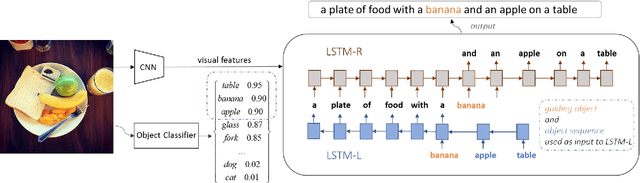
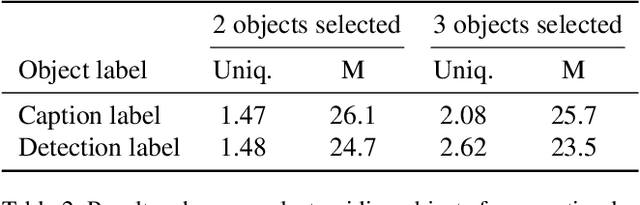
Although existing image caption models can produce promising results using recurrent neural networks (RNNs), it is difficult to guarantee that an object we care about is contained in generated descriptions, for example in the case that the object is inconspicuous in image. Problems become even harder when these objects did not appear in training stage. In this paper, we propose a novel approach for generating image captions with guiding objects (CGO). The CGO constrains the model to involve a human-concerned object, when the object is in the image, in the generated description while maintaining fluency. Instead of generating the sequence from left to right, we start description with a selected object and generate other parts of the sequence based on this object. To achieve this, we design a novel framework combining two LSTMs in opposite directions. We demonstrate the characteristics of our method on MSCOCO to generate descriptions for each detected object in images. With CGO, we can extend the ability of description to the objects being neglected in image caption labels and provide a set of more comprehensive and diverse descriptions for an image. CGO shows obvious advantages when applied to the task of describing novel objects. We show experiment results on both MSCOCO and ImageNet datasets. Evaluations show that our method outperforms the state-of-the-art models in the task with average F1 75.8, leading to better descriptions in terms of both content accuracy and fluency.
Analogous to Evolutionary Algorithm: Designing a Unified Sequence Model
May 31, 2021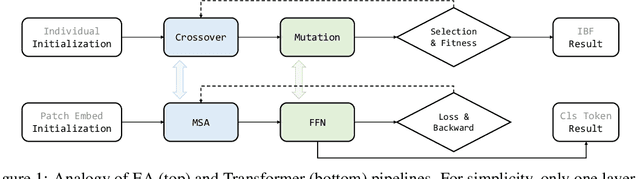
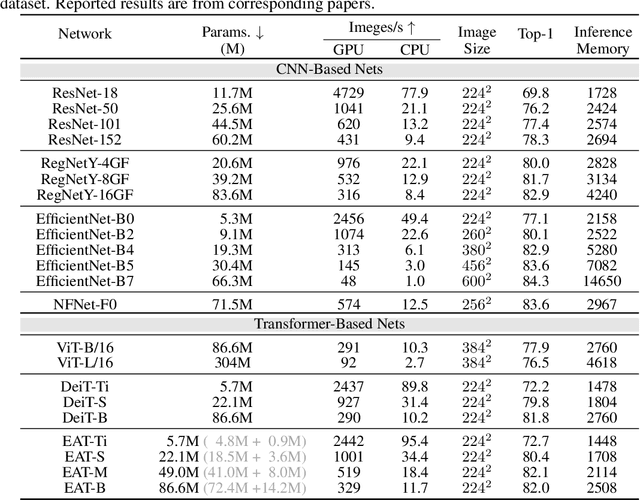

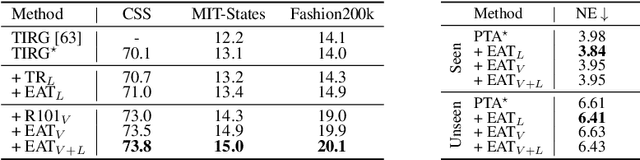
Inspired by biological evolution, we explain the rationality of Vision Transformer by analogy with the proven practical Evolutionary Algorithm (EA) and derive that both of them have consistent mathematical representation. Analogous to the dynamic local population in EA, we improve the existing transformer structure and propose a more efficient EAT model, and design task-related heads to deal with different tasks more flexibly. Moreover, we introduce the spatial-filling curve into the current vision transformer to sequence image data into a uniform sequential format. Thus we can design a unified EAT framework to address multi-modal tasks, separating the network architecture from the data format adaptation. Our approach achieves state-of-the-art results on the ImageNet classification task compared with recent vision transformer works while having smaller parameters and greater throughput. We further conduct multi-model tasks to demonstrate the superiority of the unified EAT, e.g., Text-Based Image Retrieval, and our approach improves the rank-1 by +3.7 points over the baseline on the CSS dataset.
Multi-Path Learnable Wavelet Neural Network for Image Classification
Aug 26, 2019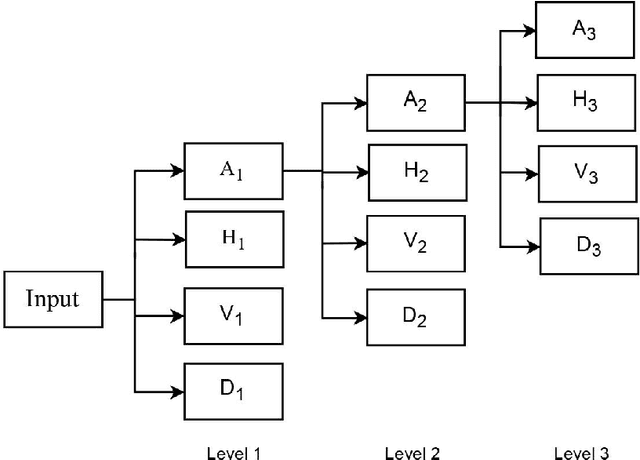
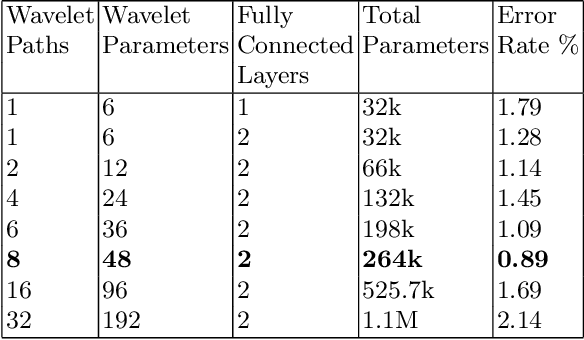
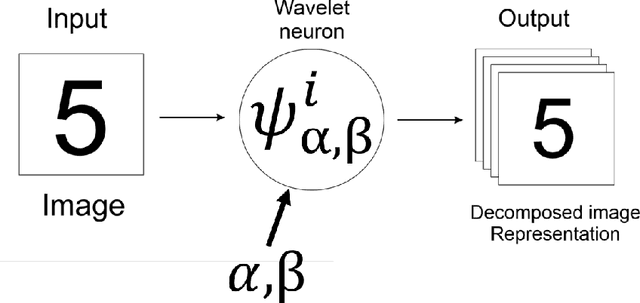
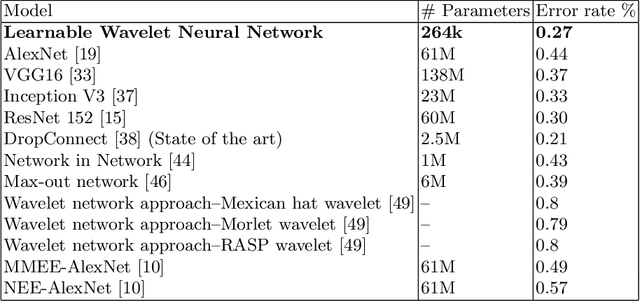
Despite the remarkable success of deep learning in pattern recognition, deep network models face the problem of training a large number of parameters. In this paper, we propose and evaluate a novel multi-path wavelet neural network architecture for image classification with far less number of trainable parameters. The model architecture consists of a multi-path layout with several levels of wavelet decompositions performed in parallel followed by fully connected layers. These decomposition operations comprise wavelet neurons with learnable parameters, which are updated during the training phase using the back-propagation algorithm. We evaluate the performance of the introduced network using common image datasets without data augmentation except for SVHN and compare the results with influential deep learning models. Our findings support the possibility of reducing the number of parameters significantly in deep neural networks without compromising its accuracy.
Stereo Matching Based on Visual Sensitive Information
May 23, 2021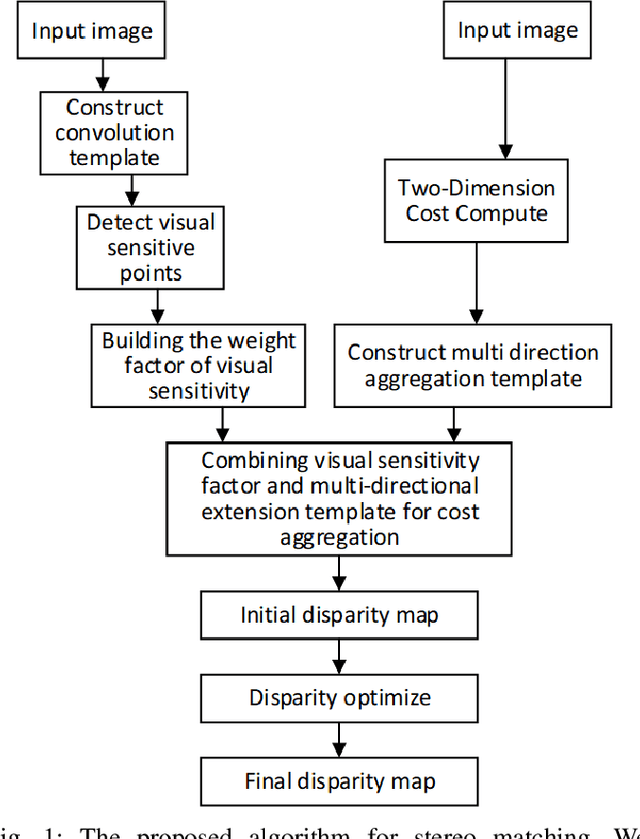
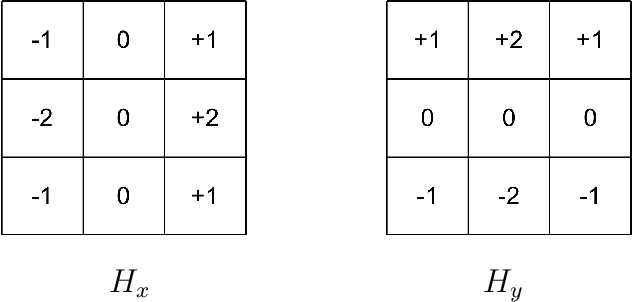

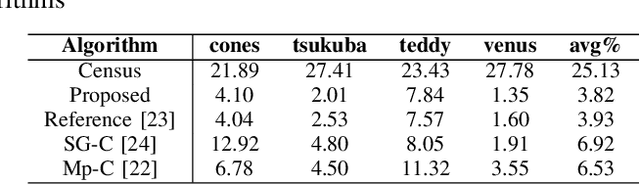
The area of computer vision is one of the most discussed topics amongst many scholars, and stereo matching is its most important sub fields. After the parallax map is transformed into a depth map, it can be applied to many intelligent fields. In this paper, a stereo matching algorithm based on visual sensitive information is proposed by using standard images from Middlebury dataset. Aiming at the limitation of traditional stereo matching algorithms regarding the cost window, a cost aggregation algorithm based on the dynamic window is proposed, and the disparity image is optimized by using left and right consistency detection to further reduce the error matching rate. The experimental results show that the proposed algorithm can effectively enhance the stereo matching effect of the image providing significant improvement in accuracy as compared with the classical census algorithm. The proposed model code, dataset, and experimental results are available at https://github.com/WangHewei16/Stereo-Matching.
Dominant Patterns: Critical Features Hidden in Deep Neural Networks
May 31, 2021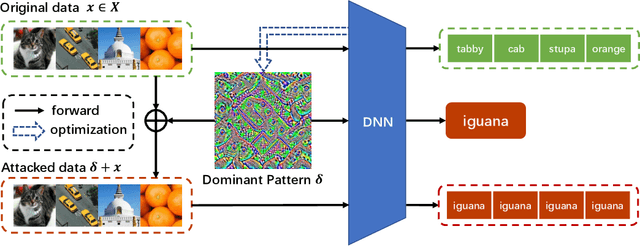
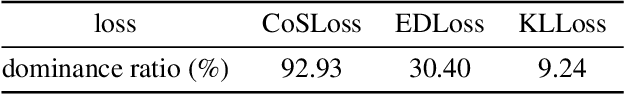

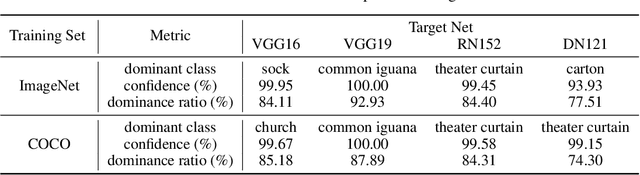
In this paper, we find the existence of critical features hidden in Deep NeuralNetworks (DNNs), which are imperceptible but can actually dominate the outputof DNNs. We call these features dominant patterns. As the name suggests, for a natural image, if we add the dominant pattern of a DNN to it, the output of this DNN is determined by the dominant pattern instead of the original image, i.e., DNN's prediction is the same with the dominant pattern's. We design an algorithm to find such patterns by pursuing the insensitivity in the feature space. A direct application of the dominant patterns is the Universal Adversarial Perturbations(UAPs). Numerical experiments show that the found dominant patterns defeat state-of-the-art UAP methods, especially in label-free settings. In addition, dominant patterns are proved to have the potential to attack downstream tasks in which DNNs share the same backbone. We claim that DNN-specific dominant patterns reveal some essential properties of a DNN and are of great importance for its feature analysis and robustness enhancement.
Data-Efficient Instance Generation from Instance Discrimination
Jun 08, 2021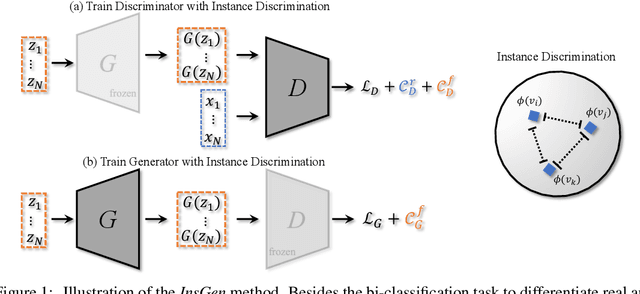
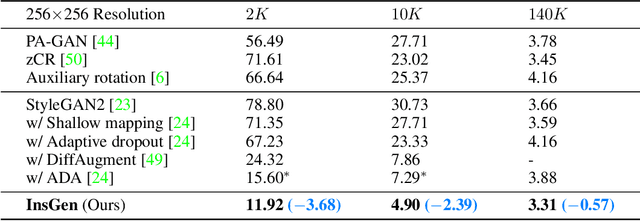
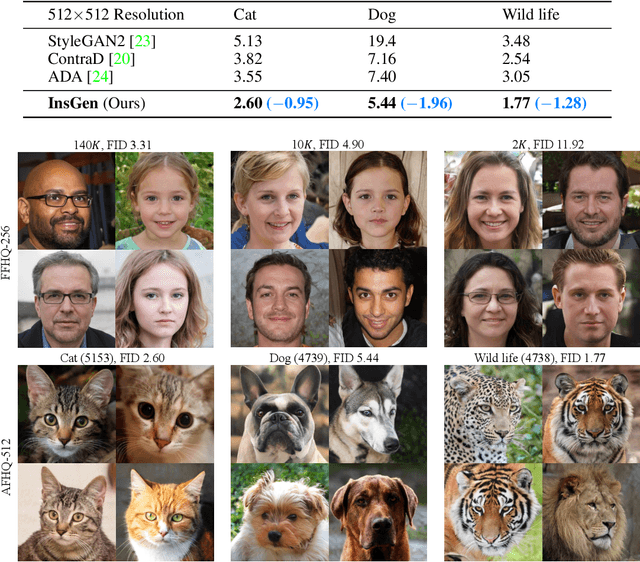
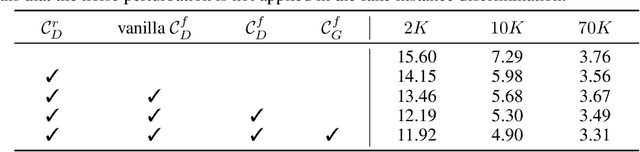
Generative Adversarial Networks (GANs) have significantly advanced image synthesis, however, the synthesis quality drops significantly given a limited amount of training data. To improve the data efficiency of GAN training, prior work typically employs data augmentation to mitigate the overfitting of the discriminator yet still learn the discriminator with a bi-classification (i.e., real vs. fake) task. In this work, we propose a data-efficient Instance Generation (InsGen) method based on instance discrimination. Concretely, besides differentiating the real domain from the fake domain, the discriminator is required to distinguish every individual image, no matter it comes from the training set or from the generator. In this way, the discriminator can benefit from the infinite synthesized samples for training, alleviating the overfitting problem caused by insufficient training data. A noise perturbation strategy is further introduced to improve its discriminative power. Meanwhile, the learned instance discrimination capability from the discriminator is in turn exploited to encourage the generator for diverse generation. Extensive experiments demonstrate the effectiveness of our method on a variety of datasets and training settings. Noticeably, on the setting of 2K training images from the FFHQ dataset, we outperform the state-of-the-art approach with 23.5% FID improvement.
Ghost Loss to Question the Reliability of Training Data
Sep 03, 2021
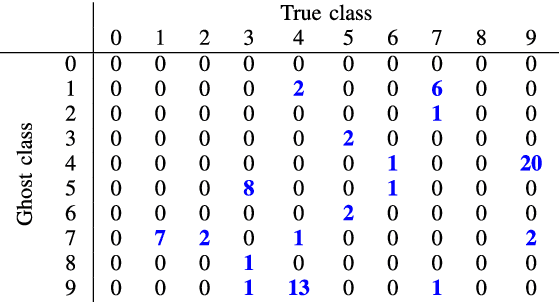
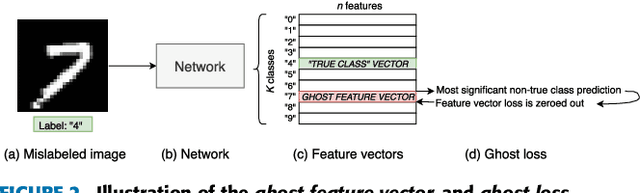
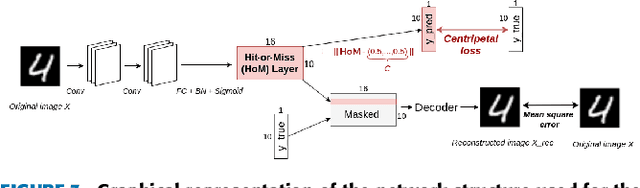
Supervised image classification problems rely on training data assumed to have been correctly annotated; this assumption underpins most works in the field of deep learning. In consequence, during its training, a network is forced to match the label provided by the annotator and is not given the flexibility to choose an alternative to inconsistencies that it might be able to detect. Therefore, erroneously labeled training images may end up ``correctly'' classified in classes which they do not actually belong to. This may reduce the performances of the network and thus incite to build more complex networks without even checking the quality of the training data. In this work, we question the reliability of the annotated datasets. For that purpose, we introduce the notion of ghost loss, which can be seen as a regular loss that is zeroed out for some predicted values in a deterministic way and that allows the network to choose an alternative to the given label without being penalized. After a proof of concept experiment, we use the ghost loss principle to detect confusing images and erroneously labeled images in well-known training datasets (MNIST, Fashion-MNIST, SVHN, CIFAR10) and we provide a new tool, called sanity matrix, for summarizing these confusions.
* This is the authors' preprint version of a paper published in IEEE Access in 2020. Please cite it as follows: A. Deli\`ege, A. Cioppa and M. Van Droogenbroeck, "Ghost Loss to Question the Reliability of Training Data", in IEEE Access, vol. 8, pp. 44774-44782, 2020, doi: 10.1109/ACCESS.2020.2978283
Real-time Detection of Practical Universal Adversarial Perturbations
May 22, 2021

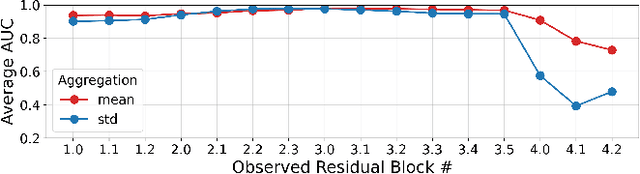
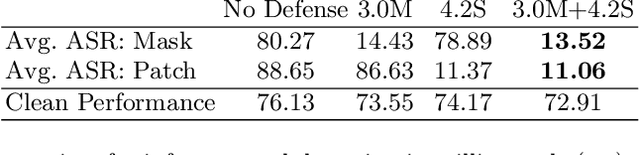
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
DC-GNet: Deep Mesh Relation Capturing Graph Convolution Network for 3D Human Shape Reconstruction
Aug 27, 2021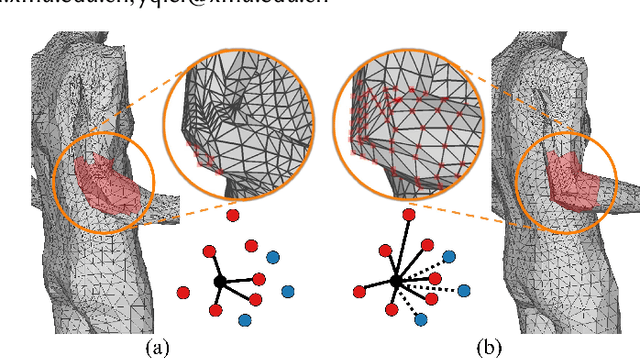
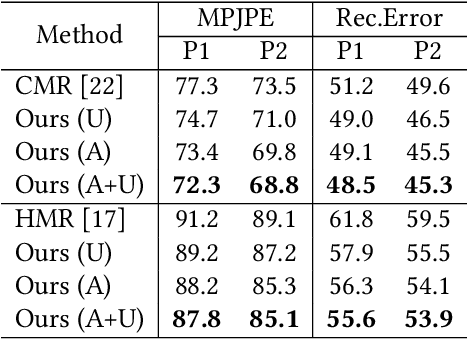
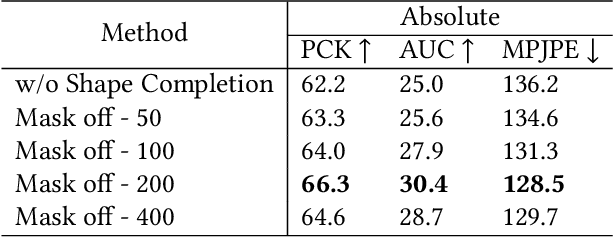
In this paper, we aim to reconstruct a full 3D human shape from a single image. Previous vertex-level and parameter regression approaches reconstruct 3D human shape based on a pre-defined adjacency matrix to encode positive relations between nodes. The deep topological relations for the surface of the 3D human body are not carefully exploited. Moreover, the performance of most existing approaches often suffer from domain gap when handling more occlusion cases in real-world scenes. In this work, we propose a Deep Mesh Relation Capturing Graph Convolution Network, DC-GNet, with a shape completion task for 3D human shape reconstruction. Firstly, we propose to capture deep relations within mesh vertices, where an adaptive matrix encoding both positive and negative relations is introduced. Secondly, we propose a shape completion task to learn prior about various kinds of occlusion cases. Our approach encodes mesh structure from more subtle relations between nodes in a more distant region. Furthermore, our shape completion module alleviates the performance degradation issue in the outdoor scene. Extensive experiments on several benchmarks show that our approach outperforms the previous 3D human pose and shape estimation approaches.
Aesthetic-Driven Image Enhancement by Adversarial Learning
Jul 02, 2018
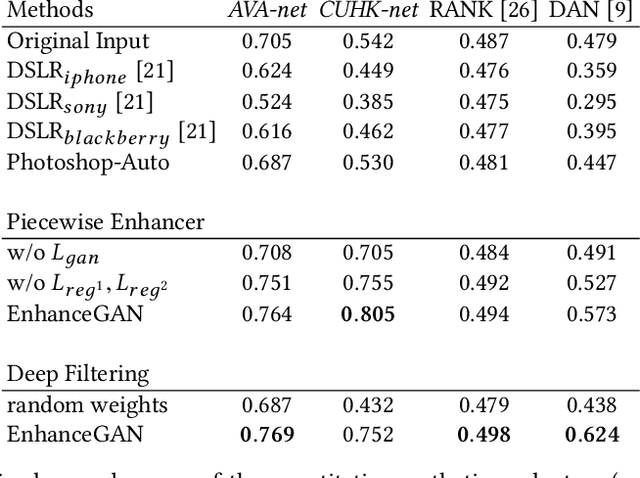
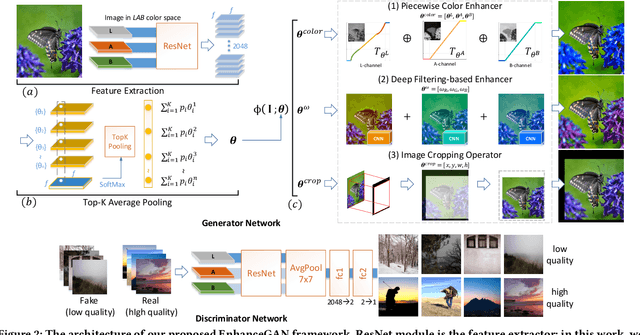
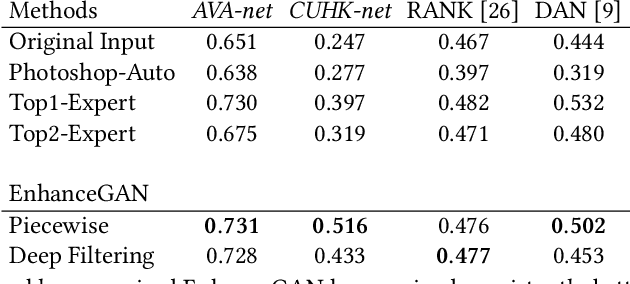
We introduce EnhanceGAN, an adversarial learning based model that performs automatic image enhancement. Traditional image enhancement frameworks typically involve training models in a fully-supervised manner, which require expensive annotations in the form of aligned image pairs. In contrast to these approaches, our proposed EnhanceGAN only requires weak supervision (binary labels on image aesthetic quality) and is able to learn enhancement operators for the task of aesthetic-based image enhancement. In particular, we show the effectiveness of a piecewise color enhancement module trained with weak supervision, and extend the proposed EnhanceGAN framework to learning a deep filtering-based aesthetic enhancer. The full differentiability of our image enhancement operators enables the training of EnhanceGAN in an end-to-end manner. We further demonstrate the capability of EnhanceGAN in learning aesthetic-based image cropping without any groundtruth cropping pairs. Our weakly-supervised EnhanceGAN reports competitive quantitative results on aesthetic-based color enhancement as well as automatic image cropping, and a user study confirms that our image enhancement results are on par with or even preferred over professional enhancement.