 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Three dimensional blind image deconvolution for fluorescence microscopy using generative adversarial networks
Apr 19, 2019
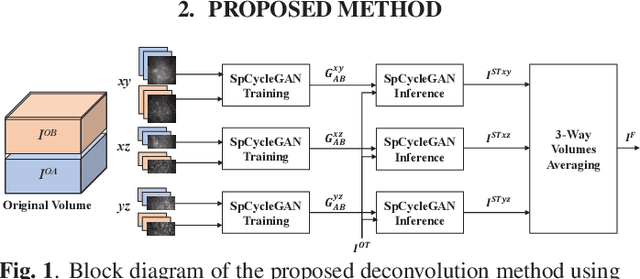
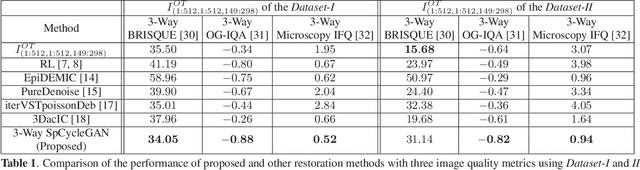
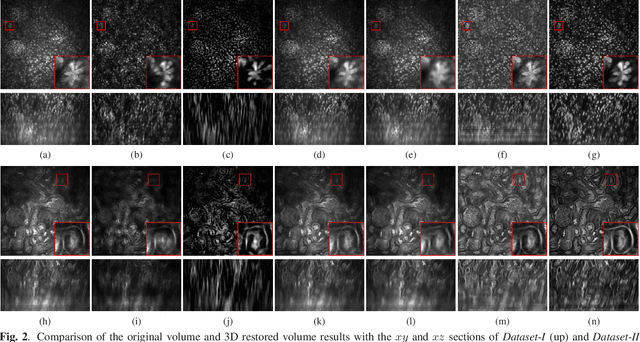

Due to image blurring image deconvolution is often used for studying biological structures in fluorescence microscopy. Fluorescence microscopy image volumes inherently suffer from intensity inhomogeneity, blur, and are corrupted by various types of noise which exacerbate image quality at deeper tissue depth. Therefore, quantitative analysis of fluorescence microscopy in deeper tissue still remains a challenge. This paper presents a three dimensional blind image deconvolution method for fluorescence microscopy using 3-way spatially constrained cycle-consistent adversarial networks. The restored volumes of the proposed deconvolution method and other well-known deconvolution methods, denoising methods, and an inhomogeneity correction method are visually and numerically evaluated. Experimental results indicate that the proposed method can restore and improve the quality of blurred and noisy deep depth microscopy image visually and quantitatively.
Disrupting Model Training with Adversarial Shortcuts
Jun 30, 2021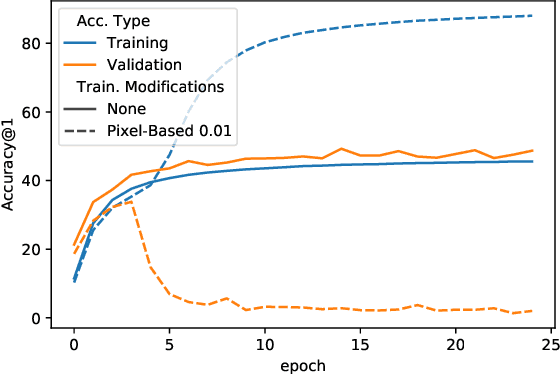

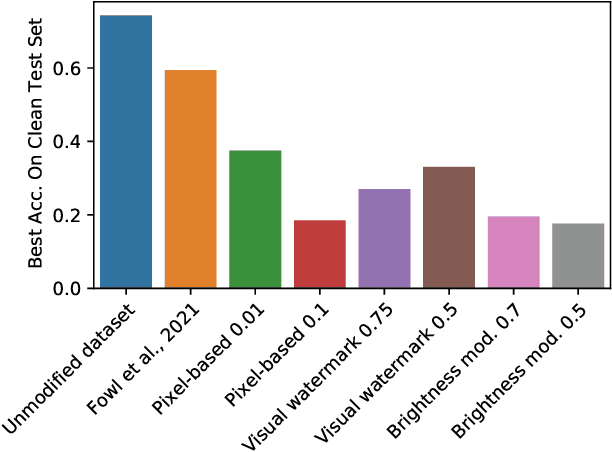
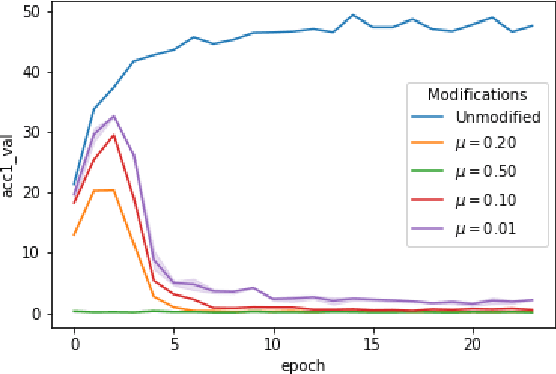
When data is publicly released for human consumption, it is unclear how to prevent its unauthorized usage for machine learning purposes. Successful model training may be preventable with carefully designed dataset modifications, and we present a proof-of-concept approach for the image classification setting. We propose methods based on the notion of adversarial shortcuts, which encourage models to rely on non-robust signals rather than semantic features, and our experiments demonstrate that these measures successfully prevent deep learning models from achieving high accuracy on real, unmodified data examples.
United We Learn Better: Harvesting Learning Improvements From Class Hierarchies Across Tasks
Jul 28, 2021


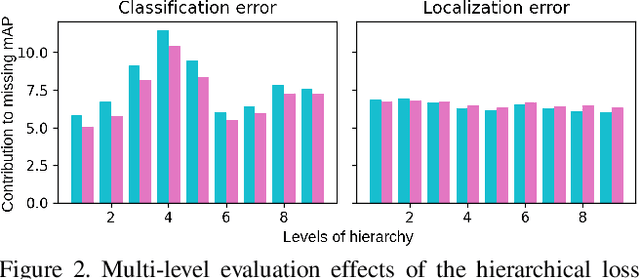
Attempts of learning from hierarchical taxonomies in computer vision have been mostly focusing on image classification. Though ways of best harvesting learning improvements from hierarchies in classification are far from being solved, there is a need to target these problems in other vision tasks such as object detection. As progress on the classification side is often dependent on hierarchical cross-entropy losses, novel detection architectures using sigmoid as an output function instead of softmax cannot easily apply these advances, requiring novel methods in detection. In this work we establish a theoretical framework based on probability and set theory for extracting parent predictions and a hierarchical loss that can be used across tasks, showing results across classification and detection benchmarks and opening up the possibility of hierarchical learning for sigmoid-based detection architectures.
Detection of Morphed Face Images Using Discriminative Wavelet Sub-bands
Jun 16, 2021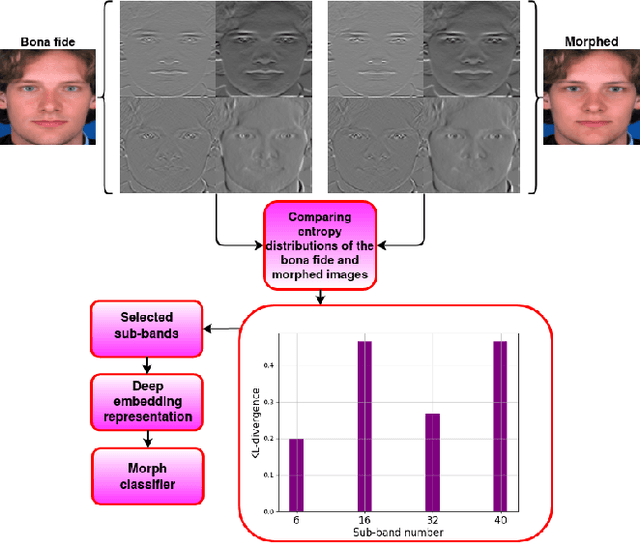
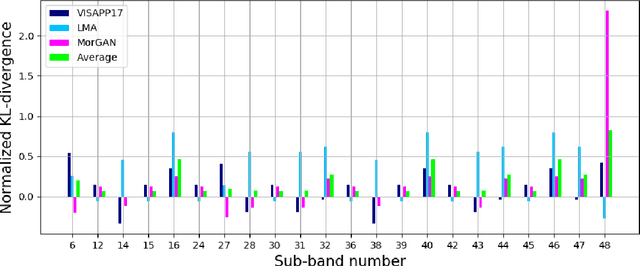
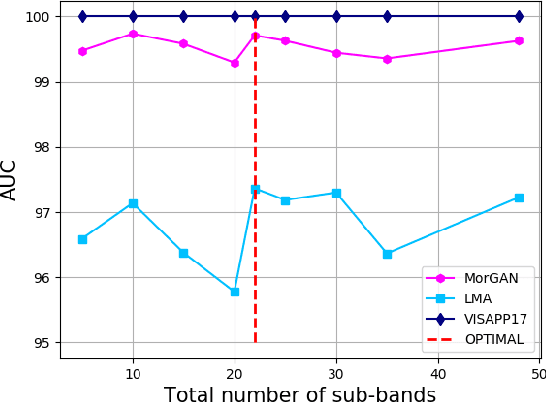
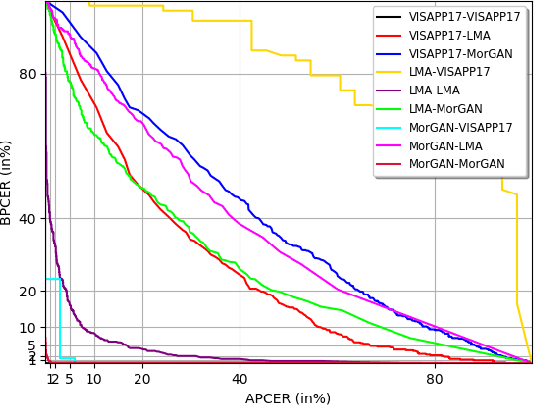
This work investigates the well-known problem of morphing attacks, which has drawn considerable attention in the biometrics community. Morphed images have exposed face recognition systems' susceptibility to false acceptance, resulting in dire consequences, especially for national security applications. To detect morphing attacks, we propose a method which is based on a discriminative 2D Discrete Wavelet Transform (2D-DWT). A discriminative wavelet sub-band can highlight inconsistencies between a real and a morphed image. We observe that there is a salient discrepancy between the entropy of a given sub-band in a bona fide image, and the same sub-band's entropy in a morphed sample. Considering this dissimilarity between these two entropy values, we find the Kullback-Leibler divergence between the two distributions, namely the entropy of the bona fide and the corresponding morphed images. The most discriminative wavelet sub-bands are those with the highest corresponding KL-divergence values. Accordingly, 22 sub-bands are selected as the most discriminative ones in terms of morph detection. We show that a Deep Neural Network (DNN) trained on the 22 discriminative sub-bands can detect morphed samples precisely. Most importantly, the effectiveness of our algorithm is validated through experiments on three datasets: VISAPP17, LMA, and MorGAN. We also performed an ablation study on the sub-band selection.
Data-Efficient Instance Generation from Instance Discrimination
Jun 08, 2021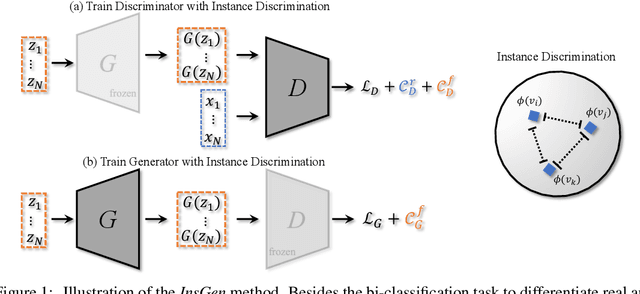
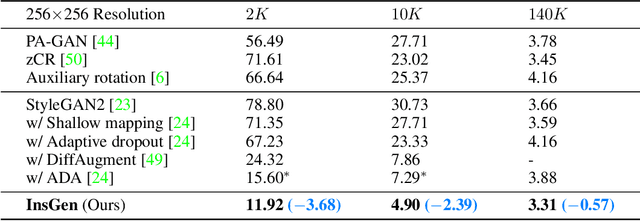
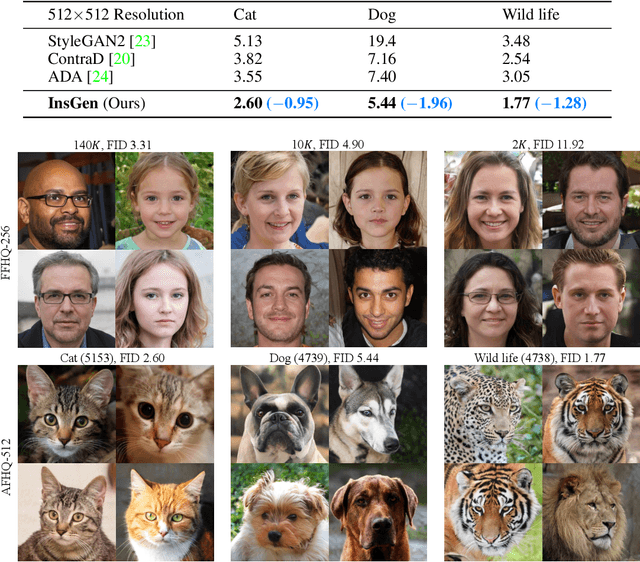
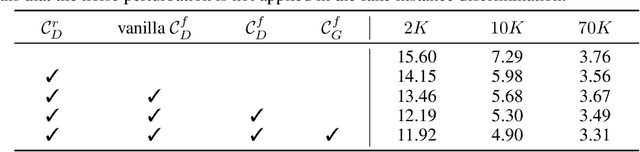
Generative Adversarial Networks (GANs) have significantly advanced image synthesis, however, the synthesis quality drops significantly given a limited amount of training data. To improve the data efficiency of GAN training, prior work typically employs data augmentation to mitigate the overfitting of the discriminator yet still learn the discriminator with a bi-classification (i.e., real vs. fake) task. In this work, we propose a data-efficient Instance Generation (InsGen) method based on instance discrimination. Concretely, besides differentiating the real domain from the fake domain, the discriminator is required to distinguish every individual image, no matter it comes from the training set or from the generator. In this way, the discriminator can benefit from the infinite synthesized samples for training, alleviating the overfitting problem caused by insufficient training data. A noise perturbation strategy is further introduced to improve its discriminative power. Meanwhile, the learned instance discrimination capability from the discriminator is in turn exploited to encourage the generator for diverse generation. Extensive experiments demonstrate the effectiveness of our method on a variety of datasets and training settings. Noticeably, on the setting of 2K training images from the FFHQ dataset, we outperform the state-of-the-art approach with 23.5% FID improvement.
On the Computation of PSNR for a Set of Images or Video
Apr 30, 2021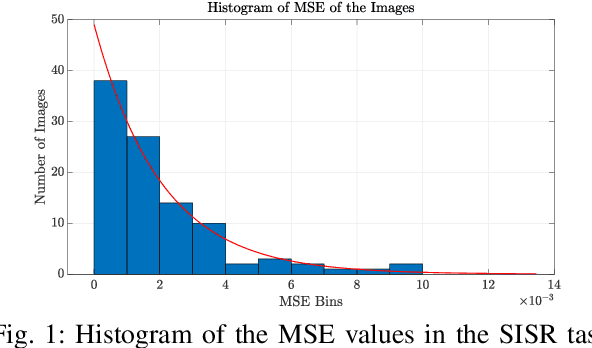
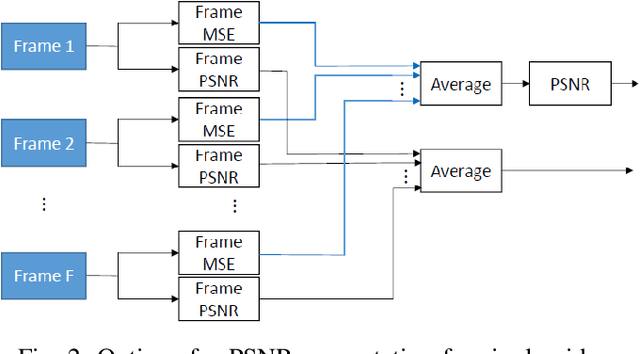
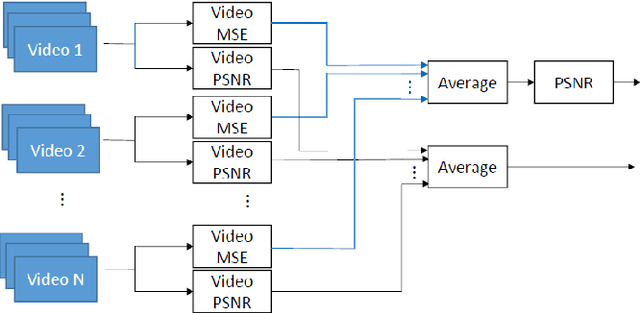
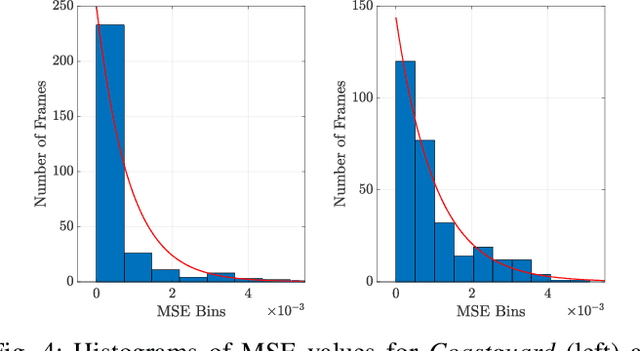
When comparing learned image/video restoration and compression methods, it is common to report peak-signal to noise ratio (PSNR) results. However, there does not exist a generally agreed upon practice to compute PSNR for sets of images or video. Some authors report average of individual image/frame PSNR, which is equivalent to computing a single PSNR from the geometric mean of individual image/frame mean-square error (MSE). Others compute a single PSNR from the arithmetic mean of frame MSEs for each video. Furthermore, some compute the MSE/PSNR of Y-channel only, while others compute MSE/PSNR for RGB channels. This paper investigates different approaches to computing PSNR for sets of images, single video, and sets of video and the relation between them. We show the difference between computing the PSNR based on arithmetic vs. geometric mean of MSE depends on the distribution of MSE over the set of images or video, and that this distribution is task-dependent. In particular, these two methods yield larger differences in restoration problems, where the MSE is exponentially distributed and smaller differences in compression problems, where the MSE distribution is narrower. We hope this paper will motivate the community to clearly describe how they compute reported PSNR values to enable consistent comparison.
Towards Robust Object Detection: Bayesian RetinaNet for Homoscedastic Aleatoric Uncertainty Modeling
Aug 02, 2021
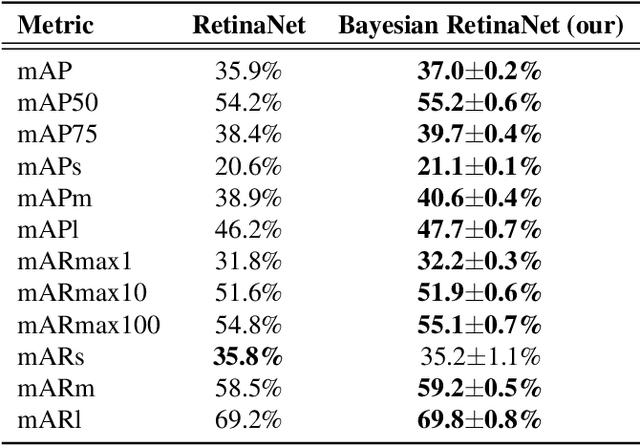
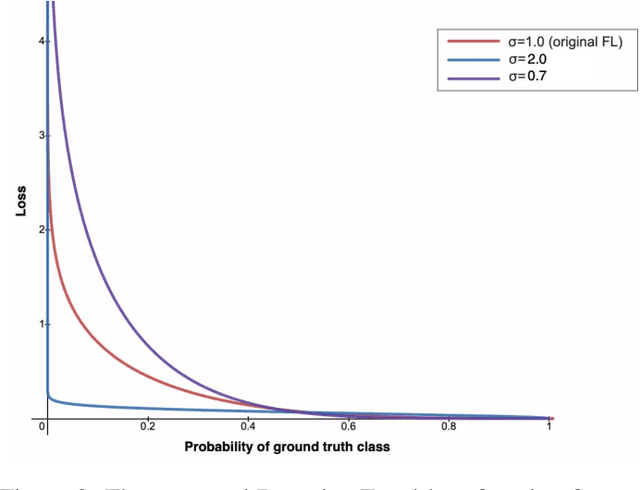
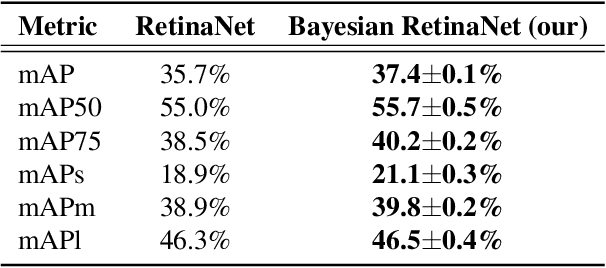
According to recent studies, commonly used computer vision datasets contain about 4% of label errors. For example, the COCO dataset is known for its high level of noise in data labels, which limits its use for training robust neural deep architectures in a real-world scenario. To model such a noise, in this paper we have proposed the homoscedastic aleatoric uncertainty estimation, and present a series of novel loss functions to address the problem of image object detection at scale. Specifically, the proposed functions are based on Bayesian inference and we have incorporated them into the common community-adopted object detection deep learning architecture RetinaNet. We have also shown that modeling of homoscedastic aleatoric uncertainty using our novel functions allows to increase the model interpretability and to improve the object detection performance being evaluated on the COCO dataset.
Analogous to Evolutionary Algorithm: Designing a Unified Sequence Model
May 31, 2021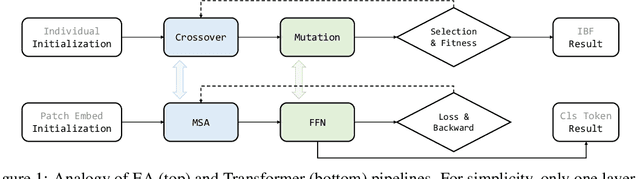
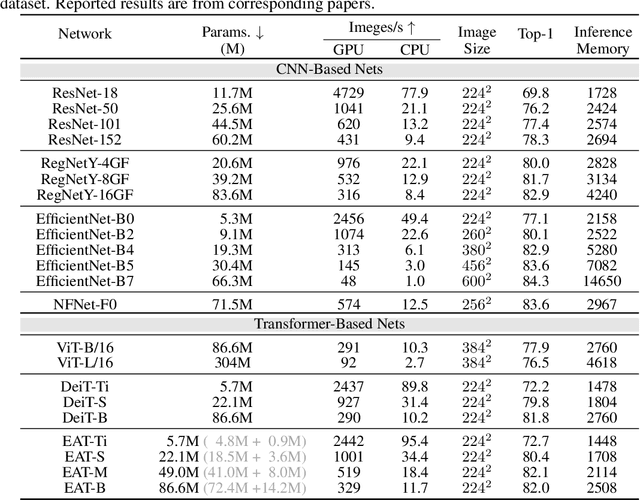

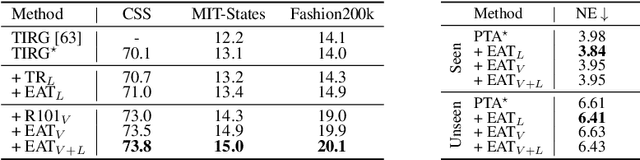
Inspired by biological evolution, we explain the rationality of Vision Transformer by analogy with the proven practical Evolutionary Algorithm (EA) and derive that both of them have consistent mathematical representation. Analogous to the dynamic local population in EA, we improve the existing transformer structure and propose a more efficient EAT model, and design task-related heads to deal with different tasks more flexibly. Moreover, we introduce the spatial-filling curve into the current vision transformer to sequence image data into a uniform sequential format. Thus we can design a unified EAT framework to address multi-modal tasks, separating the network architecture from the data format adaptation. Our approach achieves state-of-the-art results on the ImageNet classification task compared with recent vision transformer works while having smaller parameters and greater throughput. We further conduct multi-model tasks to demonstrate the superiority of the unified EAT, e.g., Text-Based Image Retrieval, and our approach improves the rank-1 by +3.7 points over the baseline on the CSS dataset.
Dominant Patterns: Critical Features Hidden in Deep Neural Networks
May 31, 2021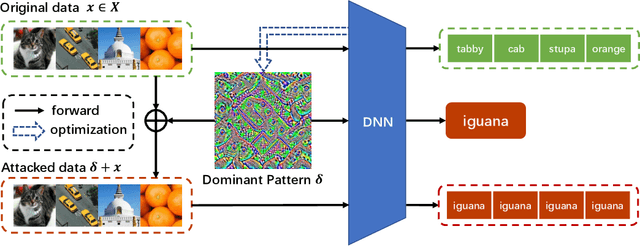
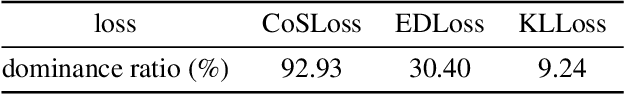

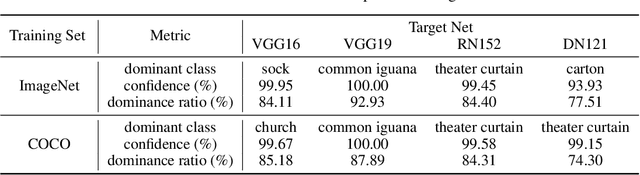
In this paper, we find the existence of critical features hidden in Deep NeuralNetworks (DNNs), which are imperceptible but can actually dominate the outputof DNNs. We call these features dominant patterns. As the name suggests, for a natural image, if we add the dominant pattern of a DNN to it, the output of this DNN is determined by the dominant pattern instead of the original image, i.e., DNN's prediction is the same with the dominant pattern's. We design an algorithm to find such patterns by pursuing the insensitivity in the feature space. A direct application of the dominant patterns is the Universal Adversarial Perturbations(UAPs). Numerical experiments show that the found dominant patterns defeat state-of-the-art UAP methods, especially in label-free settings. In addition, dominant patterns are proved to have the potential to attack downstream tasks in which DNNs share the same backbone. We claim that DNN-specific dominant patterns reveal some essential properties of a DNN and are of great importance for its feature analysis and robustness enhancement.
Neural Aesthetic Image Reviewer
Feb 28, 2018
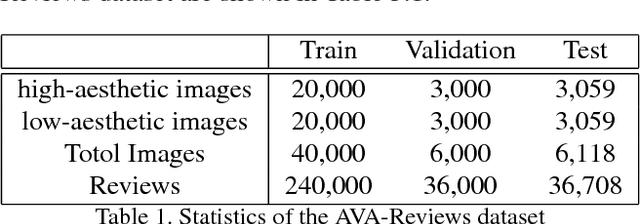
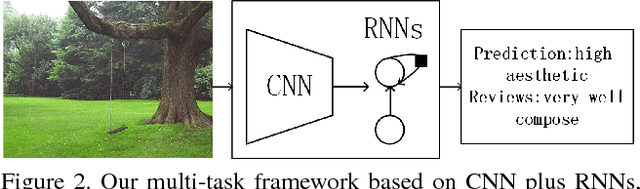

Recently, there is a rising interest in perceiving image aesthetics. The existing works deal with image aesthetics as a classification or regression problem. To extend the cognition from rating to reasoning, a deeper understanding of aesthetics should be based on revealing why a high- or low-aesthetic score should be assigned to an image. From such a point of view, we propose a model referred to as Neural Aesthetic Image Reviewer, which can not only give an aesthetic score for an image, but also generate a textual description explaining why the image leads to a plausible rating score. Specifically, we propose two multi-task architectures based on shared aesthetically semantic layers and task-specific embedding layers at a high level for performance improvement on different tasks. To facilitate researches on this problem, we collect the AVA-Reviews dataset, which contains 52,118 images and 312,708 comments in total. Through multi-task learning, the proposed models can rate aesthetic images as well as produce comments in an end-to-end manner. It is confirmed that the proposed models outperform the baselines according to the performance evaluation on the AVA-Reviews dataset. Moreover, we demonstrate experimentally that our model can generate textual reviews related to aesthetics, which are consistent with human perception.