 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors
Jun 11, 2020
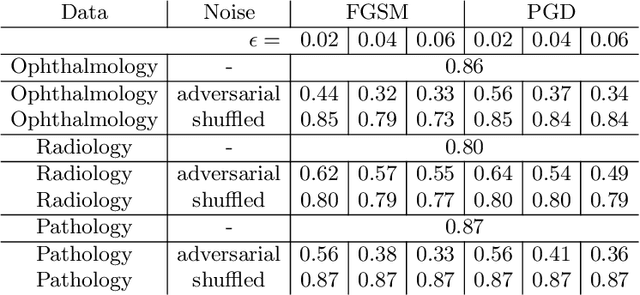
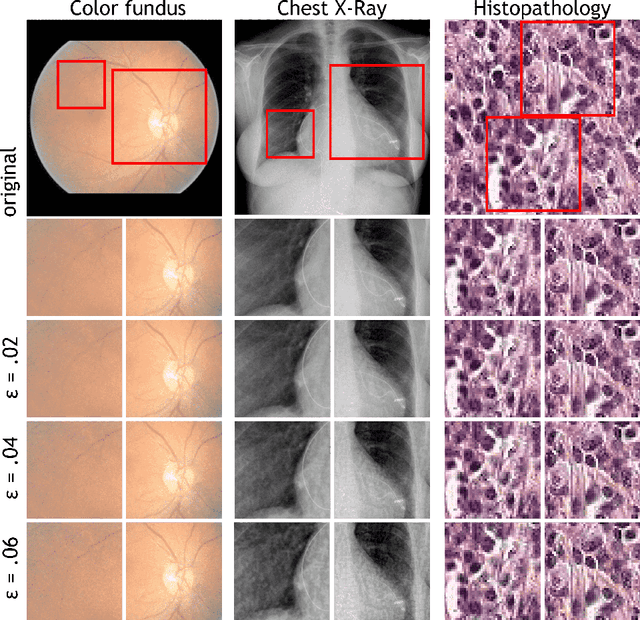
Adversarial attacks are considered a potentially serious security threat for machine learning systems. Medical image analysis (MedIA) systems have recently been argued to be particularly vulnerable to adversarial attacks due to strong financial incentives. In this paper, we study several previously unexplored factors affecting adversarial attack vulnerability of deep learning MedIA systems in three medical domains: ophthalmology, radiology and pathology. Firstly, we study the effect of varying the degree of adversarial perturbation on the attack performance and its visual perceptibility. Secondly, we study how pre-training on a public dataset (ImageNet) affects the models' vulnerability to attacks. Thirdly, we study the influence of data and model architecture disparity between target and attacker models. Our experiments show that the degree of perturbation significantly affects both performance and human perceptibility of attacks. Pre-training may dramatically increase the transfer of adversarial examples; the larger the performance gain achieved by pre-training, the larger the transfer. Finally, disparity in data and/or model architecture between target and attacker models substantially decreases the success of attacks. We believe that these factors should be considered when designing cybersecurity-critical MedIA systems, as well as kept in mind when evaluating their vulnerability to adversarial attacks. * indicates equal contribution
Physically-Constrained Transfer Learning through Shared Abundance Space for Hyperspectral Image Classification
Aug 19, 2020

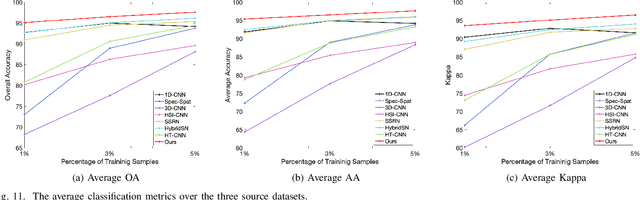
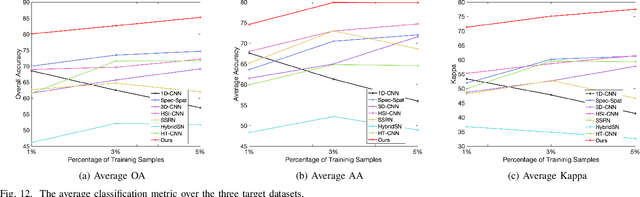
Hyperspectral image (HSI) classification is one of the most active research topics and has achieved promising results boosted by the recent development of deep learning. However, most state-of-the-art approaches tend to perform poorly when the training and testing images are on different domains, e.g., source domain and target domain, respectively, due to the spectral variability caused by different acquisition conditions. Transfer learning-based methods address this problem by pre-training in the source domain and fine-tuning on the target domain. Nonetheless, a considerable amount of data on the target domain has to be labeled and non-negligible computational resources are required to retrain the whole network. In this paper, we propose a new transfer learning scheme to bridge the gap between the source and target domains by projecting the HSI data from the source and target domains into a shared abundance space based on their own physical characteristics. In this way, the domain discrepancy would be largely reduced such that the model trained on the source domain could be applied on the target domain without extra efforts for data labeling or network retraining. The proposed method is referred to as physically-constrained transfer learning through shared abundance space (PCTL-SAS). Extensive experimental results demonstrate the superiority of the proposed method as compared to the state-of-the-art. The success of this endeavor would largely facilitate the deployment of HSI classification for real-world sensing scenarios.
Hire-MLP: Vision MLP via Hierarchical Rearrangement
Aug 30, 2021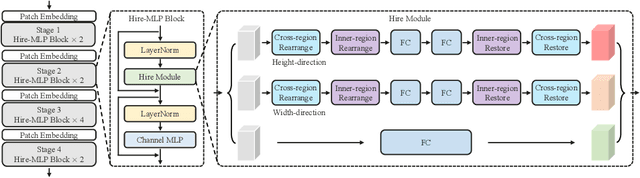
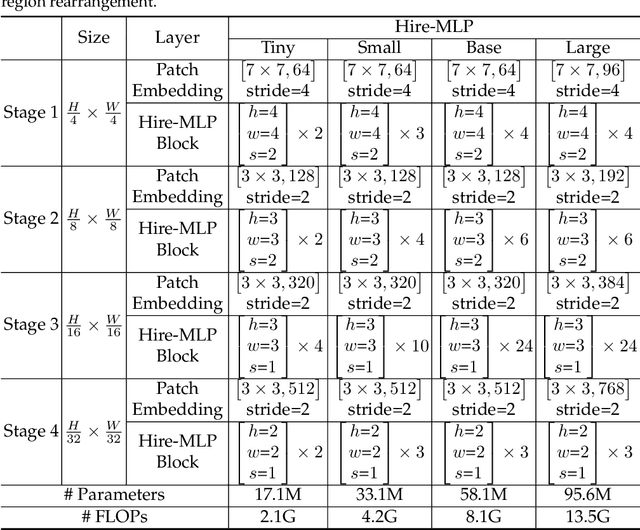
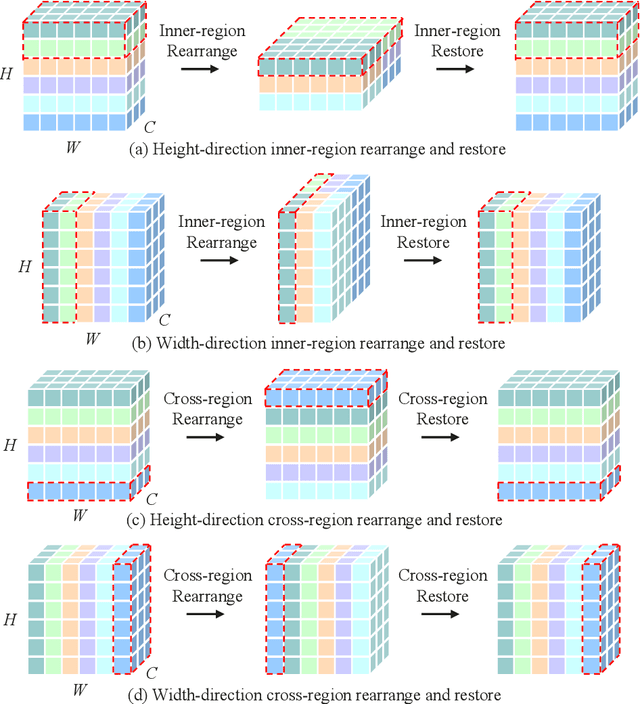
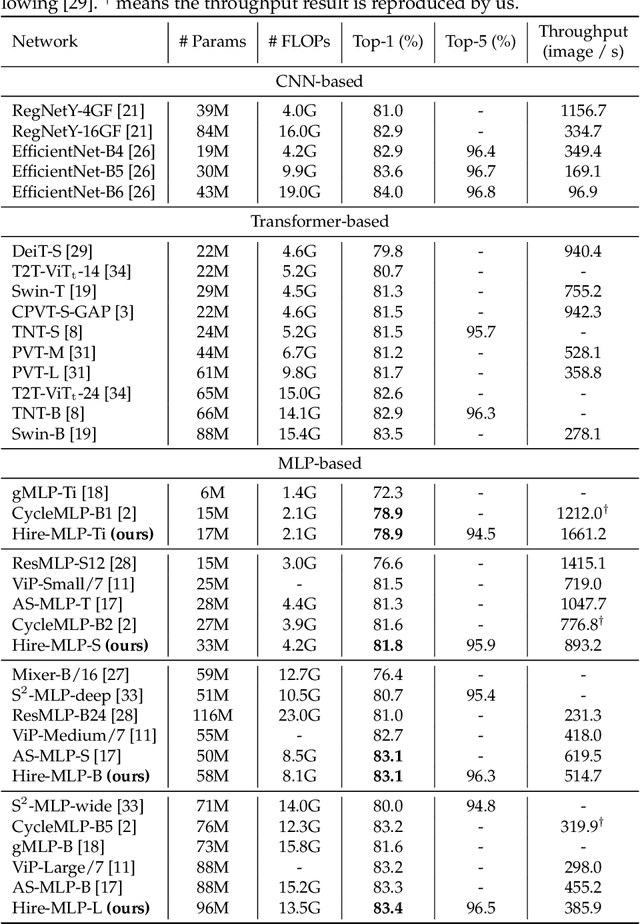
This paper presents Hire-MLP, a simple yet competitive vision MLP architecture via hierarchical rearrangement. Previous vision MLPs like MLP-Mixer are not flexible for various image sizes and are inefficient to capture spatial information by flattening the tokens. Hire-MLP innovates the existing MLP-based models by proposing the idea of hierarchical rearrangement to aggregate the local and global spatial information while being versatile for downstream tasks. Specifically, the inner-region rearrangement is designed to capture local information inside a spatial region. Moreover, to enable information communication between different regions and capture global context, the cross-region rearrangement is proposed to circularly shift all tokens along spatial directions. The proposed Hire-MLP architecture is built with simple channel-mixing MLPs and rearrangement operations, thus enjoys high flexibility and inference speed. Experiments show that our Hire-MLP achieves state-of-the-art performance on the ImageNet-1K benchmark. In particular, Hire-MLP achieves an 83.4\% top-1 accuracy on ImageNet, which surpasses previous Transformer-based and MLP-based models with better trade-off for accuracy and throughput.
Communication-Efficient Distributed Linear and Deep Generalized Canonical Correlation Analysis
Sep 25, 2021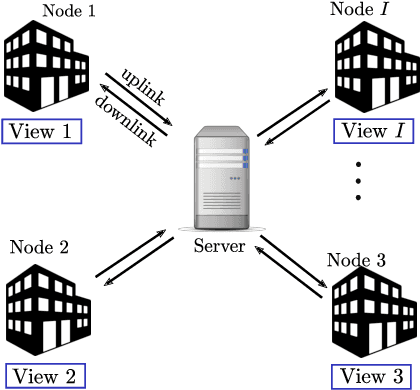
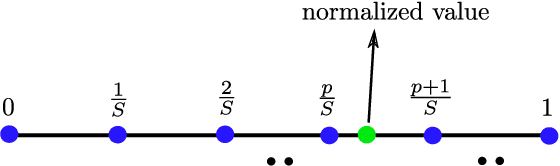
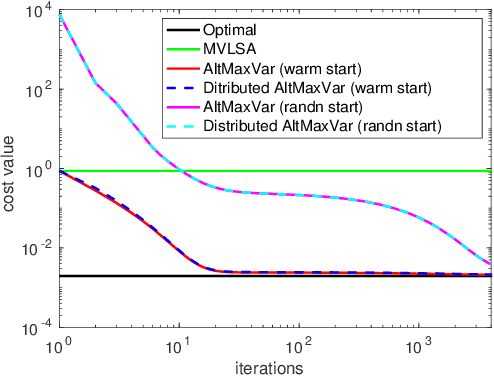
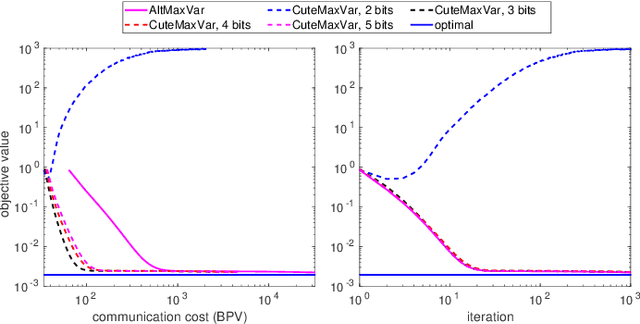
Classic and deep learning-based generalized canonical correlation analysis (GCCA) algorithms seek low-dimensional common representations of data entities from multiple ``views'' (e.g., audio and image) using linear transformations and neural networks, respectively. When the views are acquired and stored at different locations, organizations and edge devices, computing GCCA in a distributed, parallel and efficient manner is well-motivated. However, existing distributed GCCA algorithms may incur prohitively high communication overhead. This work puts forth a communication-efficient distributed framework for both linear and deep GCCA under the maximum variance (MAX-VAR) paradigm. The overhead issue is addressed by aggressively compressing (via quantization) the exchanging information between the distributed computing agents and a central controller. Compared to the unquantized version, the proposed algorithm consistently reduces the communication overhead by about $90\%$ with virtually no loss in accuracy and convergence speed. Rigorous convergence analyses are also presented -- which is a nontrivial effort since no existing generic result from quantized distributed optimization covers the special problem structure of GCCA. Our result shows that the proposed algorithms for both linear and deep GCCA converge to critical points in a sublinear rate, even under heavy quantization and stochastic approximations. In addition, it is shown that in the linear MAX-VAR case, the quantized algorithm approaches a {\it global optimum} in a {\it geometric} rate -- if the computing agents' updates meet a certain accuracy level. Synthetic and real data experiments are used to showcase the effectiveness of the proposed approach.
BCNet: Learning Body and Cloth Shape from A Single Image
Apr 01, 2020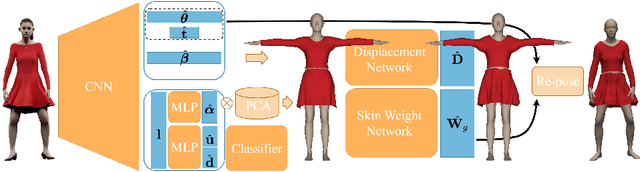
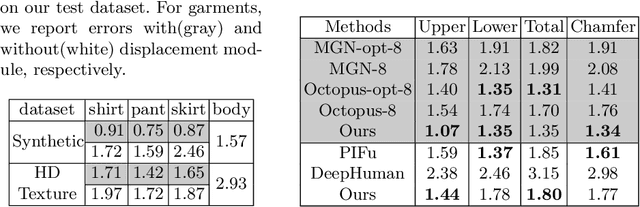
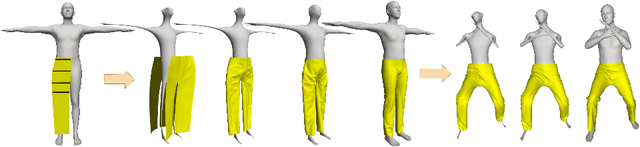

In this paper, we consider the problem to automatically reconstruct both garment and body shapes from a single near front view RGB image. To this end, we propose a layered garment representation on top of SMPL and novelly make the skinning weight of garment to be independent with the body mesh, which significantly improves the expression ability of our garment model. Compared with existing methods, our method can support more garment categories like skirts and recover more accurate garment geometry. To train our model, we construct two large scale datasets with ground truth body and garment geometries as well as paired color images. Compared with single mesh or non-parametric representation, our method can achieve more flexible control with separate meshes, makes applications like re-pose, garment transfer, and garment texture mapping possible.
Bilinear Faster RCNN with ELA for Image Tampering Detection
Apr 07, 2019



With technological advances leading to an increase in mechanisms of image tampering, our fraud detection methods must continue to be upgraded to match their sophistication. One problem with current methods is that they require prior knowledge of the method of forgery in order to determine which features to extract from the image to localize the region of interest. When a machine learning algorithm is used to learn different types tampering from a large set of various image types, with a big enough database we can easily classify which images are tampered (by training on the entire image feature map for each image), but we still are left with the question of which features to train on, and how to localize the manipulation. To solve this, object detection networks such as Faster RCNN, which combine an RPN (Region Proposal Network) with a CNN have recently been adapted to fraud detection by utilizing their ability to propose bounding boxes for objects of interest to localize the tampering artifacts. In this work, an existing bilinear Faster RCNN model that was developed will be modified with the second stream having an input of the ELA (Error Level Analysis) JPEG compression level mask.
Selfie: Self-supervised Pretraining for Image Embedding
Jun 07, 2019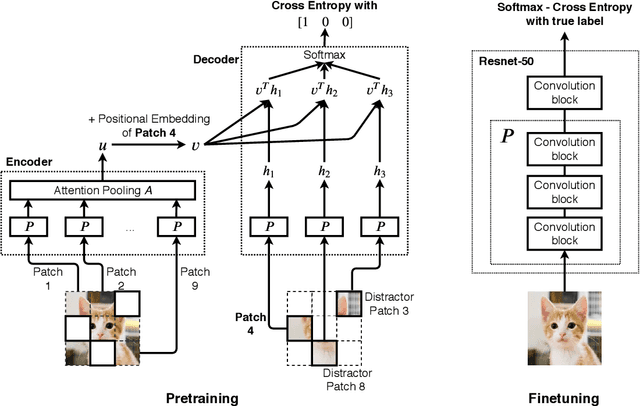
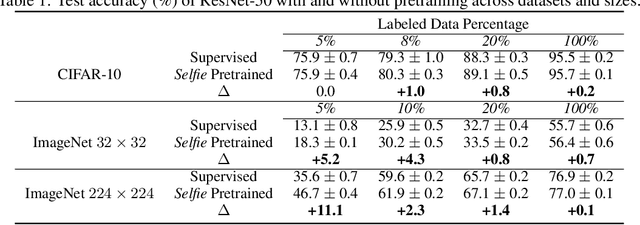

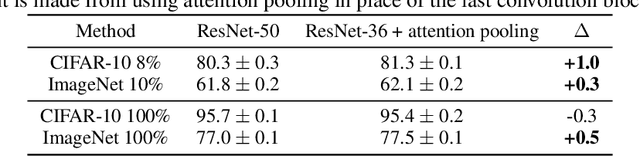
We introduce a pretraining technique called Selfie, which stands for SELF-supervised Image Embedding. Selfie generalizes the concept of masked language modeling to continuous data, such as images. Given masked-out patches in an input image, our method learns to select the correct patch, among other "distractor" patches sampled from the same image, to fill in the masked location. This classification objective sidesteps the need for predicting exact pixel values of the target patches. The pretraining architecture includes a network of convolutional blocks to process patches followed by an attention pooling network to summarize the content of unmasked patches before predicting masked ones. During finetuning, we reuse the convolutional weights found by pretraining. We evaluate our method on three benchmarks (CIFAR-10, ImageNet 32 x 32, and ImageNet 224 x 224) with varying amounts of labeled data, from 5% to 100% of the training sets. Our pretraining method provides consistent improvements to ResNet-50 across all settings compared to the standard supervised training of the same network. Notably, on ImageNet 224 x 224 with 60 examples per class (5%), our method improves the mean accuracy of ResNet-50 from 35.6% to 46.7%, an improvement of 11.1 points in absolute accuracy. Our pretraining method also improves ResNet-50 training stability, especially on low data regime, by significantly lowering the standard deviation of test accuracies across datasets.
VITAL: A Visual Interpretation on Text with Adversarial Learning for Image Labeling
Aug 01, 2019
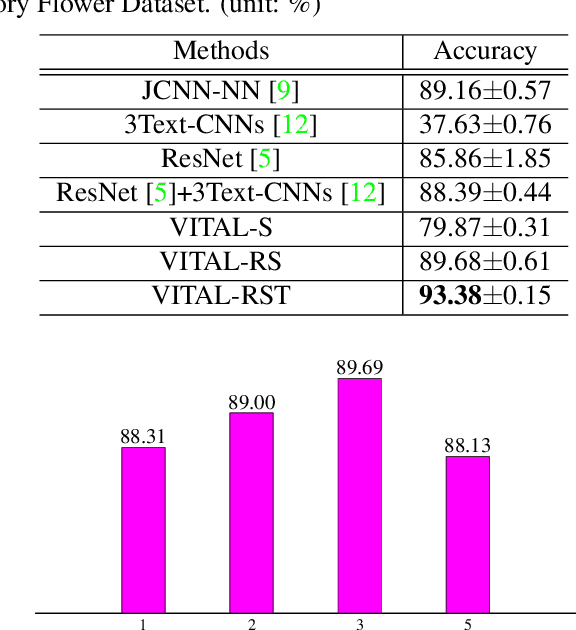
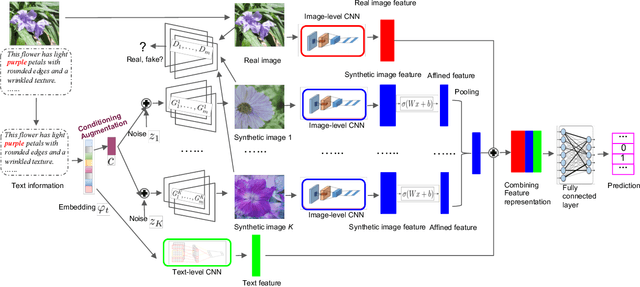
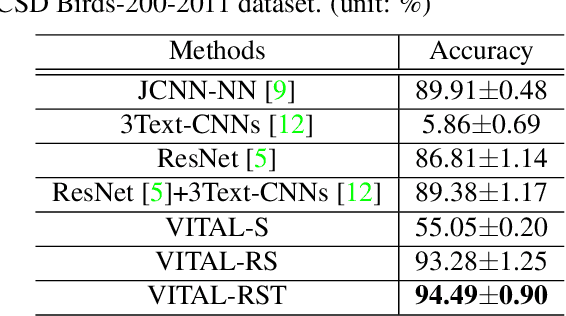
In this paper, we propose a novel way to interpret text information by extracting visual feature presentation from multiple high-resolution and photo-realistic synthetic images generated by Text-to-image Generative Adversarial Network (GAN) to improve the performance of image labeling. Firstly, we design a stacked Generative Multi-Adversarial Network (GMAN), StackGMAN++, a modified version of the current state-of-the-art Text-to-image GAN, StackGAN++, to generate multiple synthetic images with various prior noises conditioned on a text. And then we extract deep visual features from the generated synthetic images to explore the underlying visual concepts for text. Finally, we combine image-level visual feature, text-level feature and visual features based on synthetic images together to predict labels for images. We conduct experiments on two benchmark datasets and the experimental results clearly demonstrate the efficacy of our proposed approach.
Color Filter Arrays for Quanta Image Sensors
Mar 26, 2019
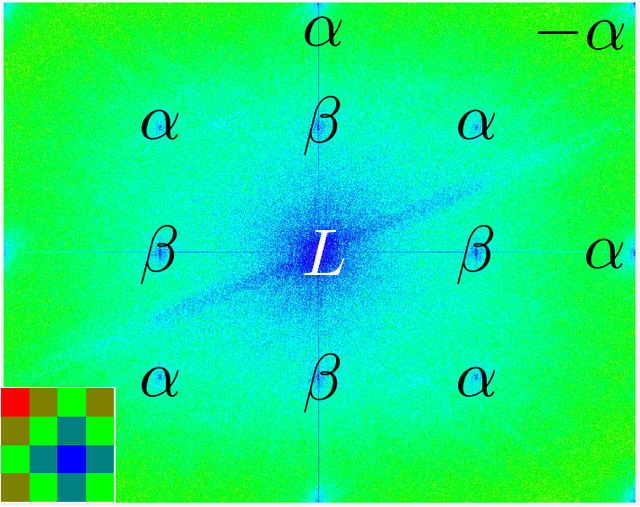

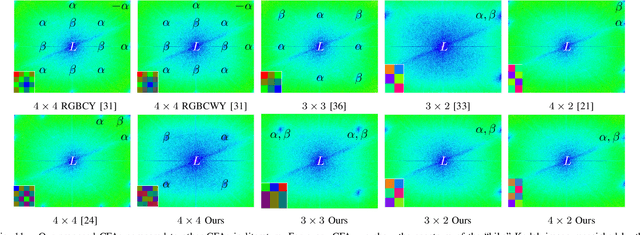
Quanta image sensor (QIS) is to be the next generation image sensor after CCD and CMOS. To enable such technology, significant progress was made over the past five years to advance both the device and image reconstruction algorithms. In this paper, we discuss color imaging using QIS, in particular how to design color filter arrays. Designing color filter arrays for QIS is challenging because at the pixel pitch of 1.1$\mu$m, maximizing the light efficiency while suppressing aliasing and crosstalk are conflicting tasks. We present an optimization-based framework to design color filter arrays for very small pixels. The new framework unifies several mainstream color filter array design frameworks by offering generality and flexibility. Compared to the existing frameworks which can only handle one or two design criteria, the new framework can simultaneously handle luminance gain, chrominance gain, cross-talk, anti-aliasing, manufacturability and orthogonality. Extensive experimental comparisons demonstrate the effectiveness and generality of the framework.
Learning to Ground Visual Objects for Visual Dialog
Sep 13, 2021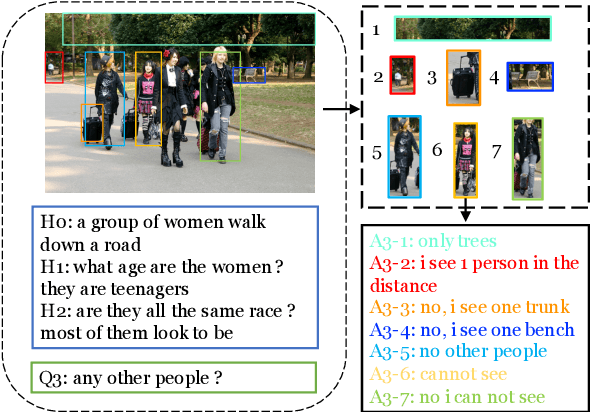
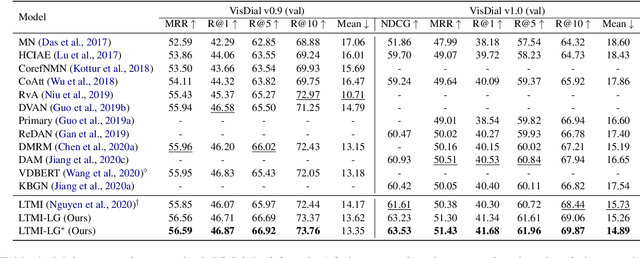
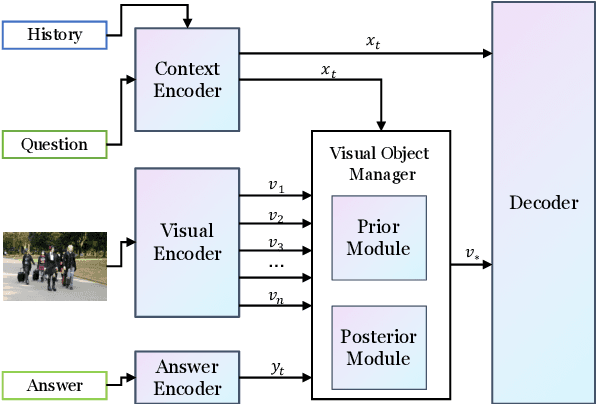
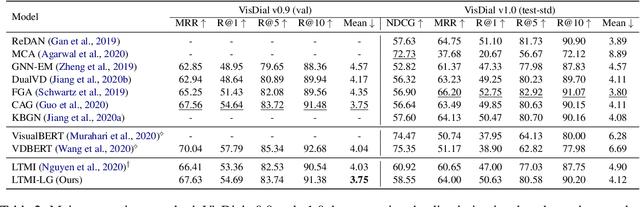
Visual dialog is challenging since it needs to answer a series of coherent questions based on understanding the visual environment. How to ground related visual objects is one of the key problems. Previous studies utilize the question and history to attend to the image and achieve satisfactory performance, however these methods are not sufficient to locate related visual objects without any guidance. The inappropriate grounding of visual objects prohibits the performance of visual dialog models. In this paper, we propose a novel approach to Learn to Ground visual objects for visual dialog, which employs a novel visual objects grounding mechanism where both prior and posterior distributions over visual objects are used to facilitate visual objects grounding. Specifically, a posterior distribution over visual objects is inferred from both context (history and questions) and answers, and it ensures the appropriate grounding of visual objects during the training process. Meanwhile, a prior distribution, which is inferred from context only, is used to approximate the posterior distribution so that appropriate visual objects can be grounded even without answers during the inference process. Experimental results on the VisDial v0.9 and v1.0 datasets demonstrate that our approach improves the previous strong models in both generative and discriminative settings by a significant margin.