 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative-Adversarial-Networks-based Ghost Recognition
Mar 25, 2021
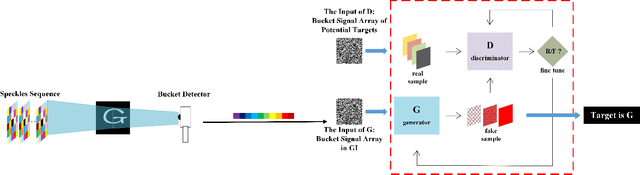

Nowadays, target recognition technique plays an important role in many fields. However, the existing image information based methods suffer from the influence of target image quality. In addition, some methods also need image reconstruction, which will bring additional time cost. In this paper, we propose a novel coincidence recognition method combining ghost imaging (GI) and generative adversarial networks (GAN). Based on the mechanism of GI, a set of random speckles sequence is employed to illuminate target, and a bucket detector without resolution is utilized to receive echo signal. The bucket signal sequence formed after continuous detections is constructed into a bucket signal array, which is regarded as the sample of GAN. Then, conditional GAN is used to map bucket signal array and target category. In practical application, the speckles sequence in training step is still employed to illuminate target, and the bucket signal array is input GAN for recognition. The proposed method can improve the problems caused by existing recognition methods that based on image information, and provide a certain turbulence-free ability. Extensive experiments are show that the proposed method achieves promising performance.
Small and large scale critical infrastructures detection based on deep learning using high resolution orthogonal images
May 25, 2021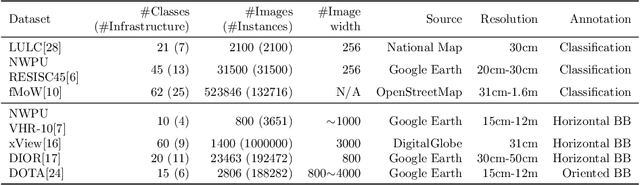
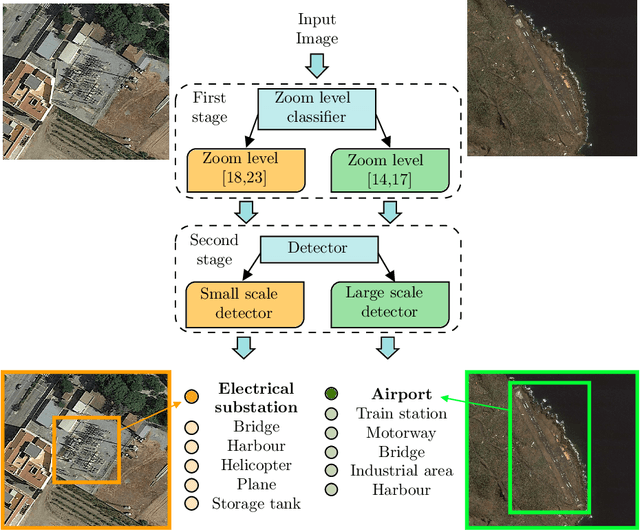
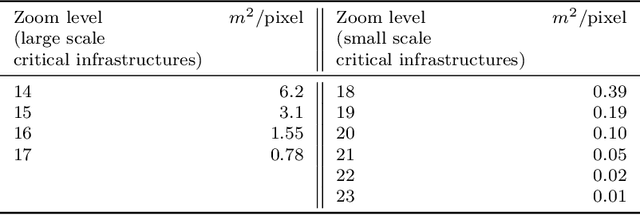
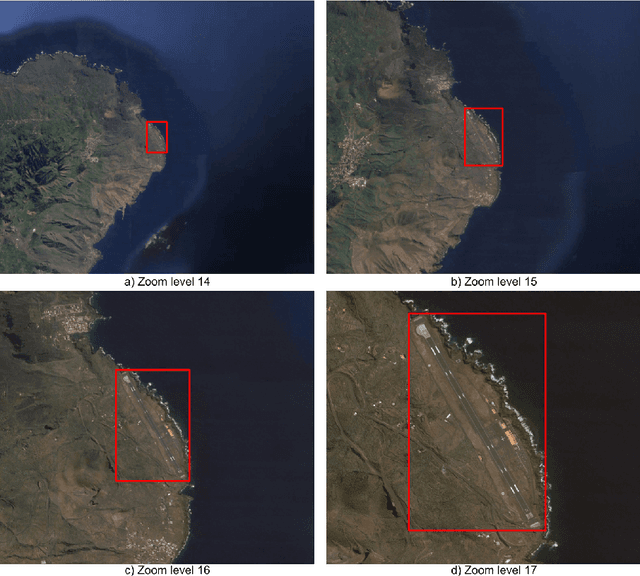
The detection of critical infrastructures is of high importance in several fields such as security, anomaly detection, land use planning and land use change detection. However, critical infrastructures detection in aerial and satellite images is still a challenge as each one has completely different size and requires different spacial resolution to be identified correctly. Heretofore, there are no special datasets for training critical infrastructures detectors. This paper presents a smart dataset as well as a resolution-independent critical infrastructure detection system. In particular, guided by the performance of the detection model, we built a dataset organized into two scales, small and large scale, and designed a two-stage deep learning detection of different scale critical infrastructures (DetDSCI) methodology in ortho-images. DetDSCI methodology first determines the input image zoom level using a classification model, then analyses the input image with the appropriate scale detection model. Our experiments show that DetDSCI methodology achieves up to 37,53% F1 improvement with respect to the baseline detector.
A Bayesian Perspective on the Deep Image Prior
Apr 16, 2019
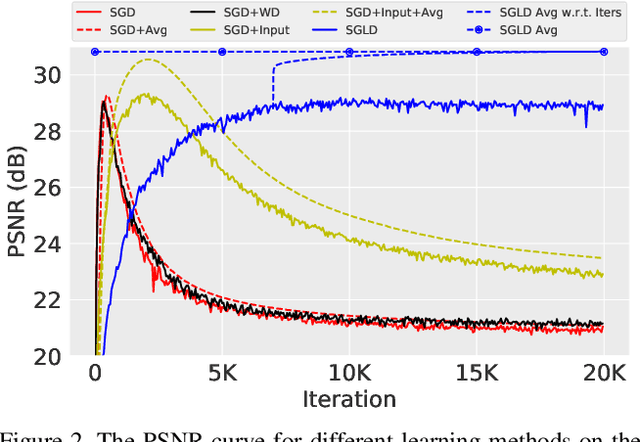
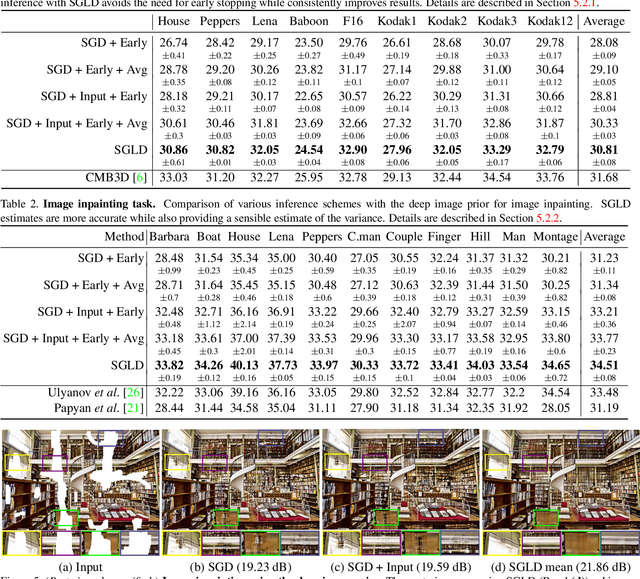
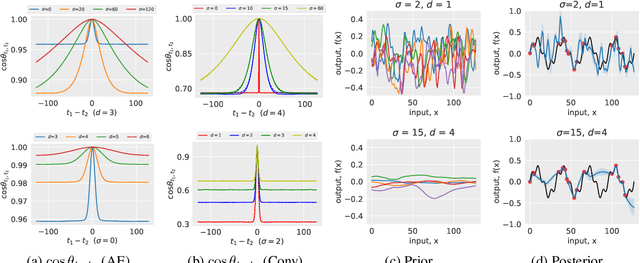
The deep image prior was recently introduced as a prior for natural images. It represents images as the output of a convolutional network with random inputs. For "inference", gradient descent is performed to adjust network parameters to make the output match observations. This approach yields good performance on a range of image reconstruction tasks. We show that the deep image prior is asymptotically equivalent to a stationary Gaussian process prior in the limit as the number of channels in each layer of the network goes to infinity, and derive the corresponding kernel. This informs a Bayesian approach to inference. We show that by conducting posterior inference using stochastic gradient Langevin we avoid the need for early stopping, which is a drawback of the current approach, and improve results for denoising and impainting tasks. We illustrate these intuitions on a number of 1D and 2D signal reconstruction tasks.
Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation
Sep 15, 2017

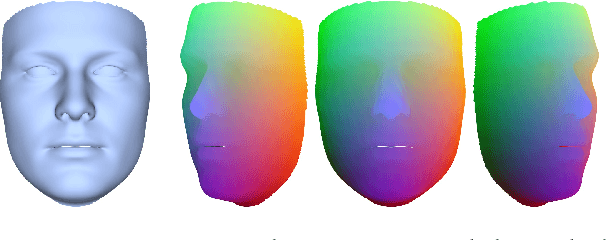
It has been recently shown that neural networks can recover the geometric structure of a face from a single given image. A common denominator of most existing face geometry reconstruction methods is the restriction of the solution space to some low-dimensional subspace. While such a model significantly simplifies the reconstruction problem, it is inherently limited in its expressiveness. As an alternative, we propose an Image-to-Image translation network that jointly maps the input image to a depth image and a facial correspondence map. This explicit pixel-based mapping can then be utilized to provide high quality reconstructions of diverse faces under extreme expressions, using a purely geometric refinement process. In the spirit of recent approaches, the network is trained only with synthetic data, and is then evaluated on in-the-wild facial images. Both qualitative and quantitative analyses demonstrate the accuracy and the robustness of our approach.
Knowledge driven Description Synthesis for Floor Plan Interpretation
Mar 15, 2021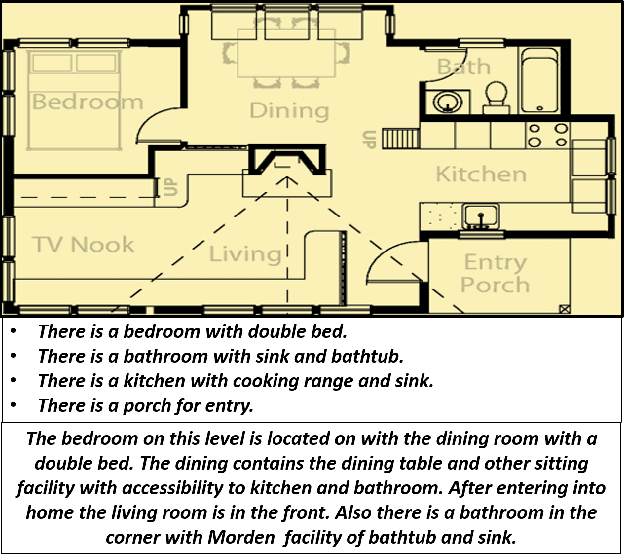
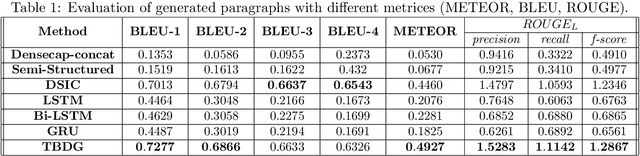
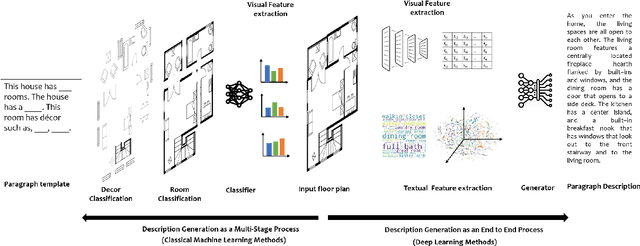
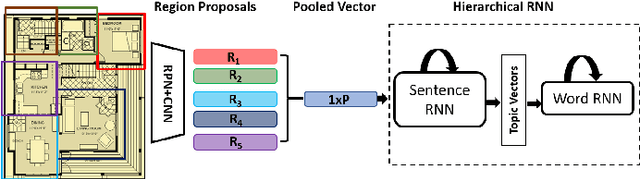
Image captioning is a widely known problem in the area of AI. Caption generation from floor plan images has applications in indoor path planning, real estate, and providing architectural solutions. Several methods have been explored in literature for generating captions or semi-structured descriptions from floor plan images. Since only the caption is insufficient to capture fine-grained details, researchers also proposed descriptive paragraphs from images. However, these descriptions have a rigid structure and lack flexibility, making it difficult to use them in real-time scenarios. This paper offers two models, Description Synthesis from Image Cue (DSIC) and Transformer Based Description Generation (TBDG), for the floor plan image to text generation to fill the gaps in existing methods. These two models take advantage of modern deep neural networks for visual feature extraction and text generation. The difference between both models is in the way they take input from the floor plan image. The DSIC model takes only visual features automatically extracted by a deep neural network, while the TBDG model learns textual captions extracted from input floor plan images with paragraphs. The specific keywords generated in TBDG and understanding them with paragraphs make it more robust in a general floor plan image. Experiments were carried out on a large-scale publicly available dataset and compared with state-of-the-art techniques to show the proposed model's superiority.
Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation
May 25, 2021
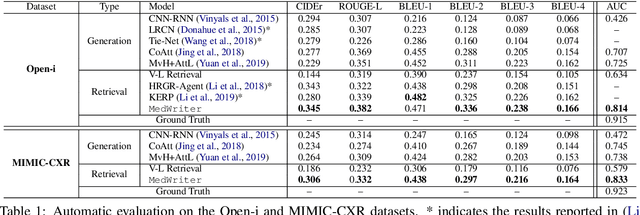
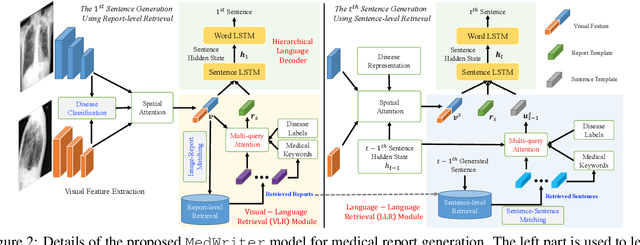
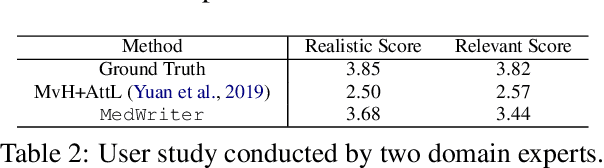
Medical report generation is one of the most challenging tasks in medical image analysis. Although existing approaches have achieved promising results, they either require a predefined template database in order to retrieve sentences or ignore the hierarchical nature of medical report generation. To address these issues, we propose MedWriter that incorporates a novel hierarchical retrieval mechanism to automatically extract both report and sentence-level templates for clinically accurate report generation. MedWriter first employs the Visual-Language Retrieval~(VLR) module to retrieve the most relevant reports for the given images. To guarantee the logical coherence between sentences, the Language-Language Retrieval~(LLR) module is introduced to retrieve relevant sentences based on the previous generated description. At last, a language decoder fuses image features and features from retrieved reports and sentences to generate meaningful medical reports. We verified the effectiveness of our model by automatic evaluation and human evaluation on two datasets, i.e., Open-I and MIMIC-CXR.
Improved Residual Networks for Image and Video Recognition
Apr 10, 2020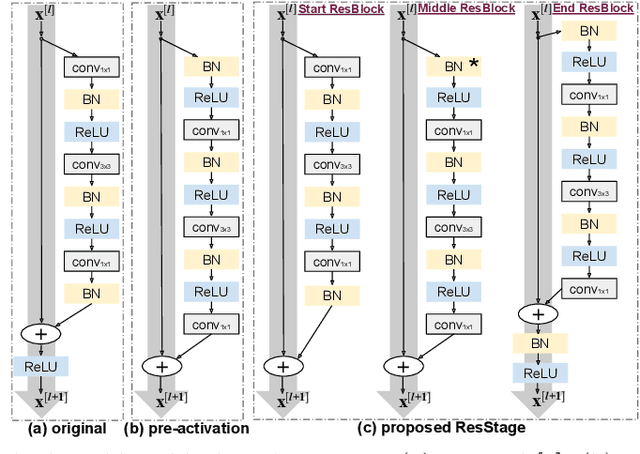
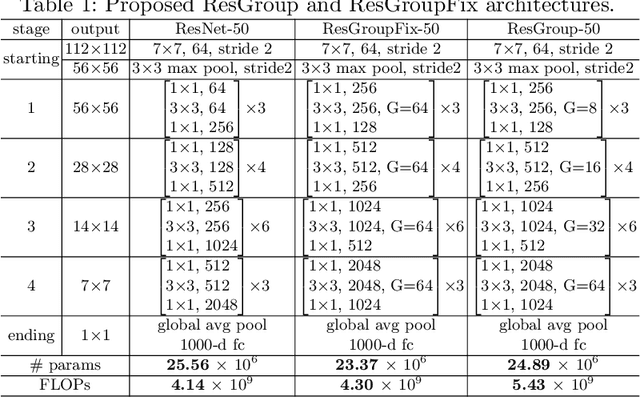
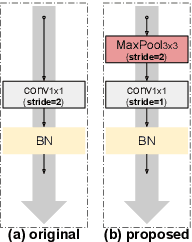
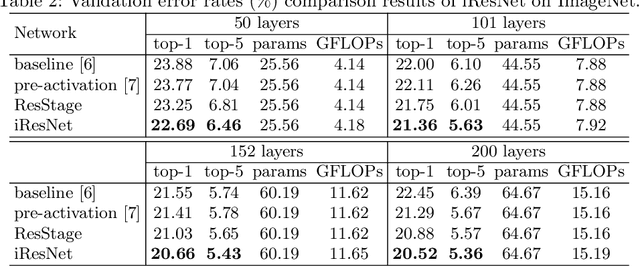
Residual networks (ResNets) represent a powerful type of convolutional neural network (CNN) architecture, widely adopted and used in various tasks. In this work we propose an improved version of ResNets. Our proposed improvements address all three main components of a ResNet: the flow of information through the network layers, the residual building block, and the projection shortcut. We are able to show consistent improvements in accuracy and learning convergence over the baseline. For instance, on ImageNet dataset, using the ResNet with 50 layers, for top-1 accuracy we can report a 1.19% improvement over the baseline in one setting and around 2% boost in another. Importantly, these improvements are obtained without increasing the model complexity. Our proposed approach allows us to train extremely deep networks, while the baseline shows severe optimization issues. We report results on three tasks over six datasets: image classification (ImageNet, CIFAR-10 and CIFAR-100), object detection (COCO) and video action recognition (Kinetics-400 and Something-Something-v2). In the deep learning era, we establish a new milestone for the depth of a CNN. We successfully train a 404-layer deep CNN on the ImageNet dataset and a 3002-layer network on CIFAR-10 and CIFAR-100, while the baseline is not able to converge at such extreme depths. Code is available at: https://github.com/iduta/iresnet
A CNN With Multi-scale Convolution for Hyperspectral Image Classification using Target-Pixel-Orientation scheme
Feb 02, 2020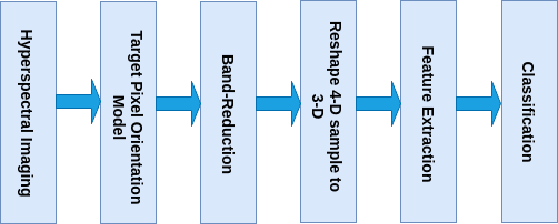

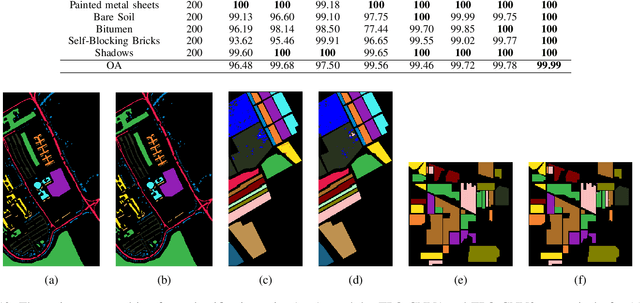
Recently, CNN is a popular choice to handle the hyperspectral image classification challenges. In spite of having such large spectral information in Hyper-Spectral Image(s) (HSI), it creates a curse of dimensionality. Also, large spatial variability of spectral signature adds more difficulty in classification problem. Additionally, training a CNN in the end to end fashion with scarced training examples is another challenging and interesting problem. In this paper, a novel target-patch-orientation method is proposed to train a CNN based network. Also, we have introduced a hybrid of 3D-CNN and 2D-CNN based network architecture to implement band reduction and feature extraction methods, respectively. Experimental results show that our method outperforms the accuracies reported in the existing state of the art methods.
Transductive Few-Shot Classification on the Oblique Manifold
Aug 09, 2021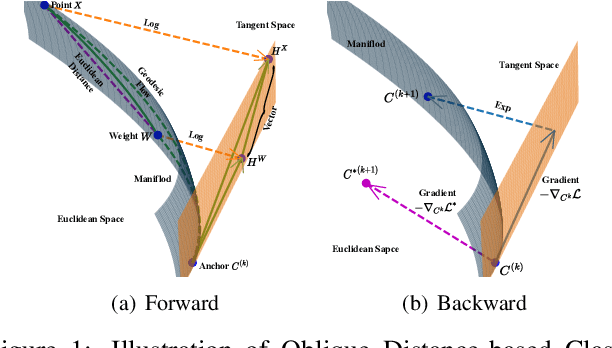
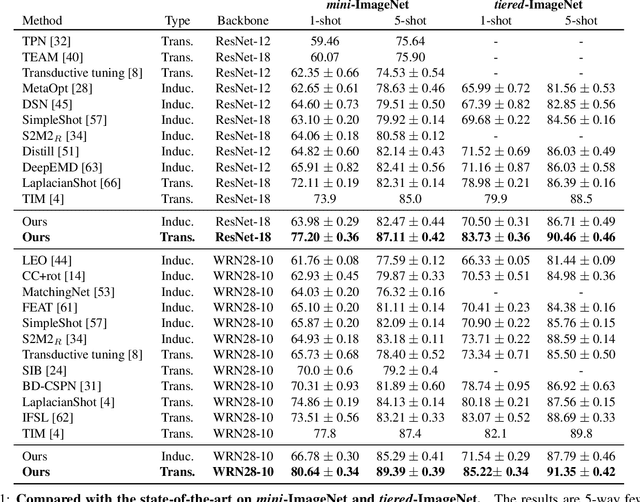
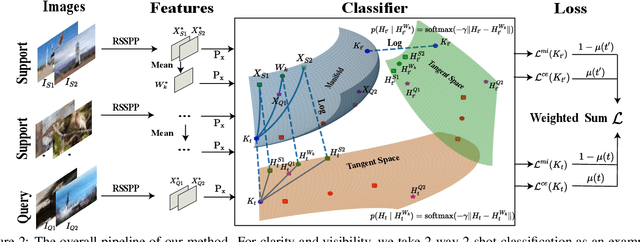
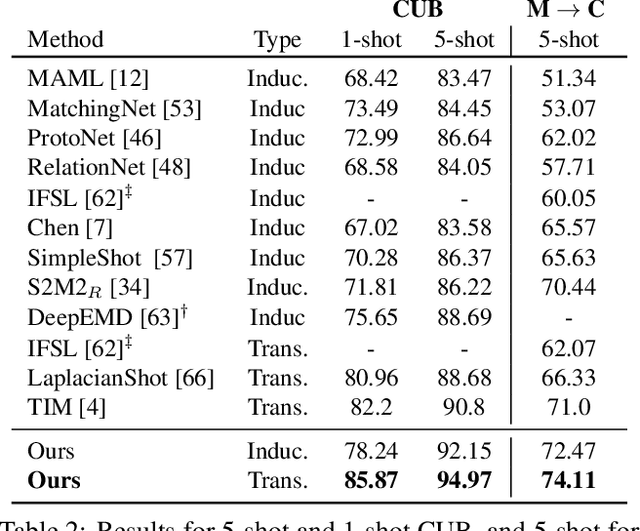
Few-shot learning (FSL) attempts to learn with limited data. In this work, we perform the feature extraction in the Euclidean space and the geodesic distance metric on the Oblique Manifold (OM). Specially, for better feature extraction, we propose a non-parametric Region Self-attention with Spatial Pyramid Pooling (RSSPP), which realizes a trade-off between the generalization and the discriminative ability of the single image feature. Then, we embed the feature to OM as a point. Furthermore, we design an Oblique Distance-based Classifier (ODC) that achieves classification in the tangent spaces which better approximate OM locally by learnable tangency points. Finally, we introduce a new method for parameters initialization and a novel loss function in the transductive settings. Extensive experiments demonstrate the effectiveness of our algorithm and it outperforms state-of-the-art methods on the popular benchmarks: mini-ImageNet, tiered-ImageNet, and Caltech-UCSD Birds-200-2011 (CUB).
Applying Tensor Decomposition to image for Robustness against Adversarial Attack
Mar 05, 2020
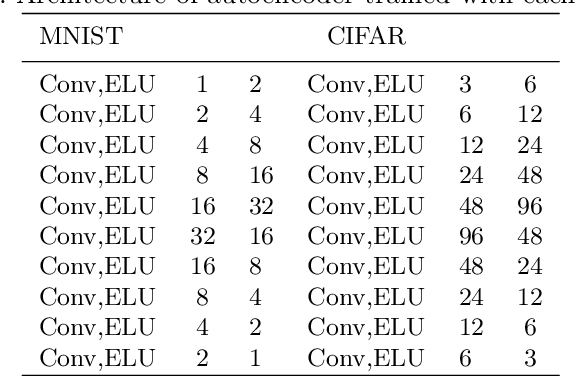
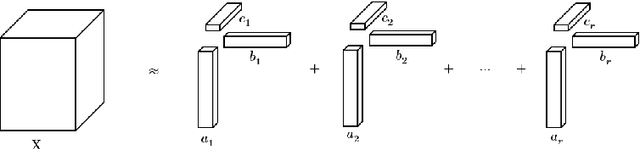
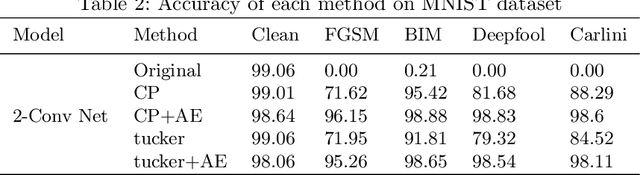
Nowadays the deep learning technology is growing faster and shows dramatic performance in computer vision areas. However, it turns out a deep learning based model is highly vulnerable to some small perturbation called an adversarial attack. It can easily fool the deep learning model by adding small perturbations. On the other hand, tensor decomposition method widely uses for compressing the tensor data, including data matrix, image, etc. In this paper, we suggest combining tensor decomposition for defending the model against adversarial example. We verify this idea is simple and effective to resist adversarial attack. In addition, this method rarely degrades the original performance of clean data. We experiment on MNIST, CIFAR10 and ImageNet data and show our method robust on state-of-the-art attack methods.