 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Privacy-Preserved Blockchain-Federated-Learning for Medical Image Analysis Towards Multiple Parties
Apr 22, 2021
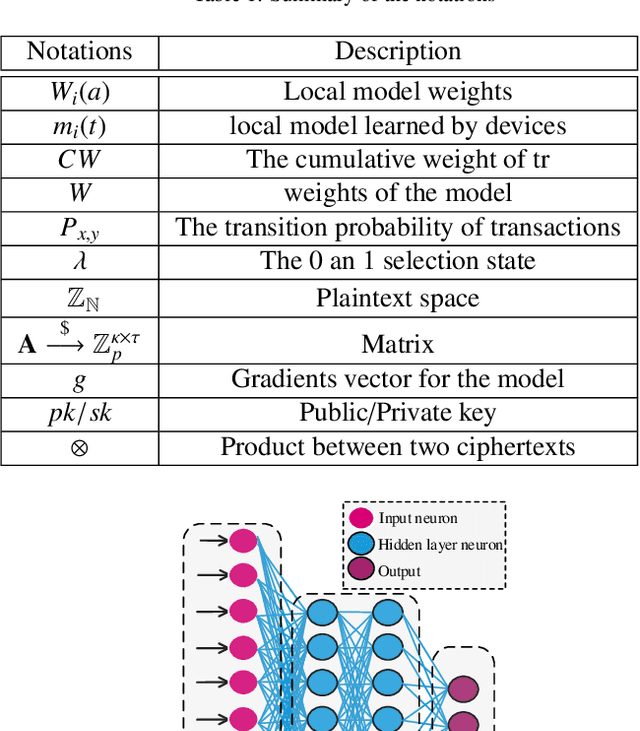
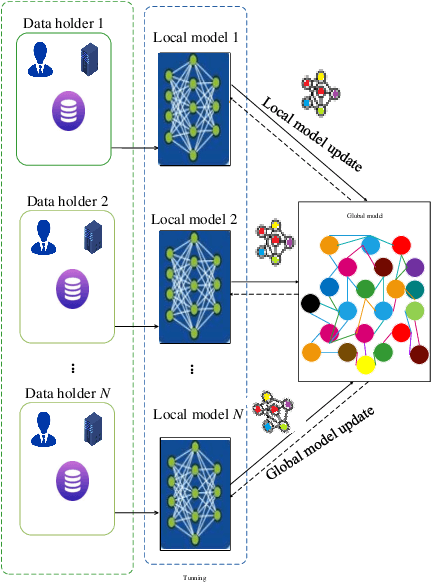
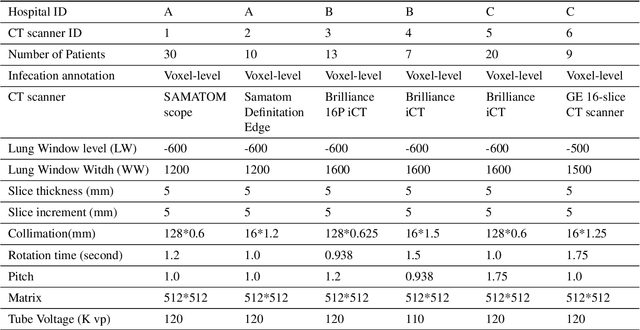
To share the patient\textquoteright s data in the blockchain network can help to learn the accurate deep learning model for the better prediction of COVID-19 patients. However, privacy (e.g., data leakage) and security (e.g., reliability or trust of data) concerns are the main challenging task for the health care centers. To solve this challenging task, this article designs a privacy-preserving framework based on federated learning and blockchain. In the first step, we train the local model by using the capsule network for the segmentation and classification of the COVID-19 images. The segmentation aims to extract nodules and classification to train the model. In the second step, we secure the local model through the homomorphic encryption scheme. The designed scheme encrypts and decrypts the gradients for federated learning. Moreover, for the decentralization of the model, we design a blockchain-based federated learning algorithm that can aggregate the gradients and update the local model. In this way, the proposed encryption scheme achieves the data provider privacy, and blockchain guarantees the reliability of the shared data. The experiment results demonstrate the performance of the proposed scheme.
Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation
May 25, 2021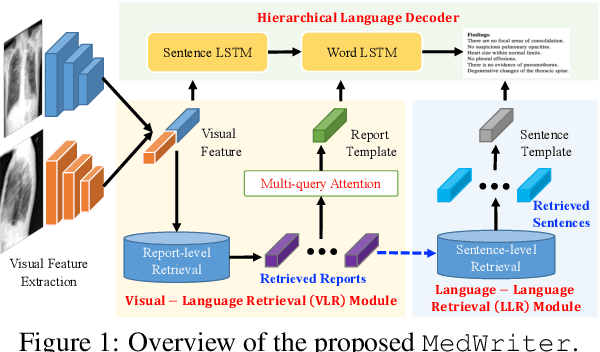
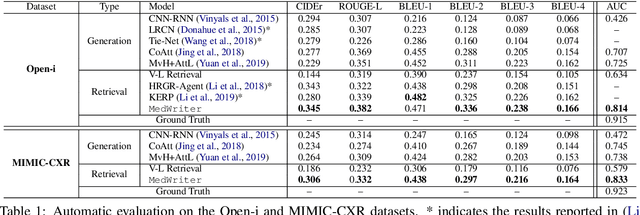
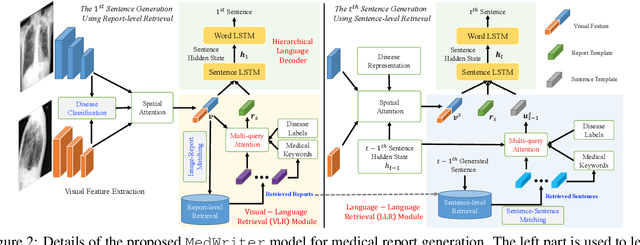
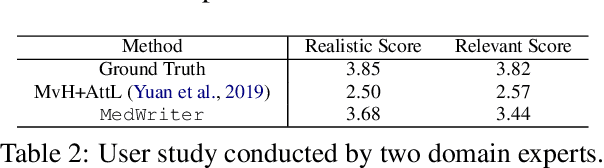
Medical report generation is one of the most challenging tasks in medical image analysis. Although existing approaches have achieved promising results, they either require a predefined template database in order to retrieve sentences or ignore the hierarchical nature of medical report generation. To address these issues, we propose MedWriter that incorporates a novel hierarchical retrieval mechanism to automatically extract both report and sentence-level templates for clinically accurate report generation. MedWriter first employs the Visual-Language Retrieval~(VLR) module to retrieve the most relevant reports for the given images. To guarantee the logical coherence between sentences, the Language-Language Retrieval~(LLR) module is introduced to retrieve relevant sentences based on the previous generated description. At last, a language decoder fuses image features and features from retrieved reports and sentences to generate meaningful medical reports. We verified the effectiveness of our model by automatic evaluation and human evaluation on two datasets, i.e., Open-I and MIMIC-CXR.
Generative-Adversarial-Networks-based Ghost Recognition
Mar 25, 2021
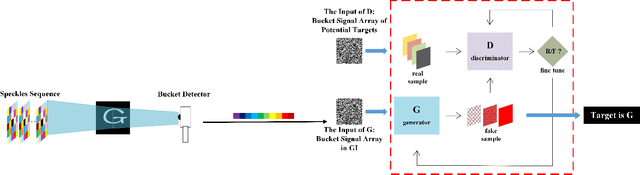

Nowadays, target recognition technique plays an important role in many fields. However, the existing image information based methods suffer from the influence of target image quality. In addition, some methods also need image reconstruction, which will bring additional time cost. In this paper, we propose a novel coincidence recognition method combining ghost imaging (GI) and generative adversarial networks (GAN). Based on the mechanism of GI, a set of random speckles sequence is employed to illuminate target, and a bucket detector without resolution is utilized to receive echo signal. The bucket signal sequence formed after continuous detections is constructed into a bucket signal array, which is regarded as the sample of GAN. Then, conditional GAN is used to map bucket signal array and target category. In practical application, the speckles sequence in training step is still employed to illuminate target, and the bucket signal array is input GAN for recognition. The proposed method can improve the problems caused by existing recognition methods that based on image information, and provide a certain turbulence-free ability. Extensive experiments are show that the proposed method achieves promising performance.
AdvFilter: Predictive Perturbation-aware Filtering against Adversarial Attack via Multi-domain Learning
Jul 14, 2021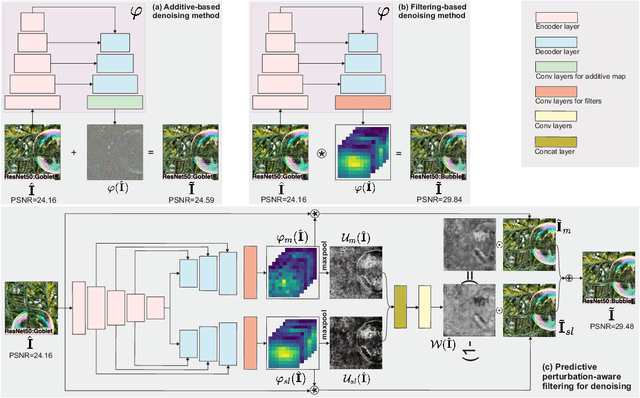


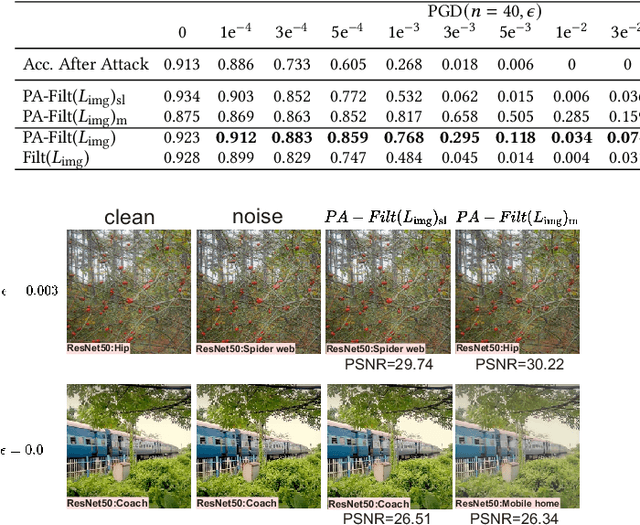
High-level representation-guided pixel denoising and adversarial training are independent solutions to enhance the robustness of CNNs against adversarial attacks by pre-processing input data and re-training models, respectively. Most recently, adversarial training techniques have been widely studied and improved while the pixel denoising-based method is getting less attractive. However, it is still questionable whether there exists a more advanced pixel denoising-based method and whether the combination of the two solutions benefits each other. To this end, we first comprehensively investigate two kinds of pixel denoising methods for adversarial robustness enhancement (i.e., existing additive-based and unexplored filtering-based methods) under the loss functions of image-level and semantic-level restorations, respectively, showing that pixel-wise filtering can obtain much higher image quality (e.g., higher PSNR) as well as higher robustness (e.g., higher accuracy on adversarial examples) than existing pixel-wise additive-based method. However, we also observe that the robustness results of the filtering-based method rely on the perturbation amplitude of adversarial examples used for training. To address this problem, we propose predictive perturbation-aware pixel-wise filtering, where dual-perturbation filtering and an uncertainty-aware fusion module are designed and employed to automatically perceive the perturbation amplitude during the training and testing process. The proposed method is termed as AdvFilter. Moreover, we combine adversarial pixel denoising methods with three adversarial training-based methods, hinting that considering data and models jointly is able to achieve more robust CNNs. The experiments conduct on NeurIPS-2017DEV, SVHN, and CIFAR10 datasets and show the advantages over enhancing CNNs' robustness, high generalization to different models, and noise levels.
Implicit-PDF: Non-Parametric Representation of Probability Distributions on the Rotation Manifold
Jun 10, 2021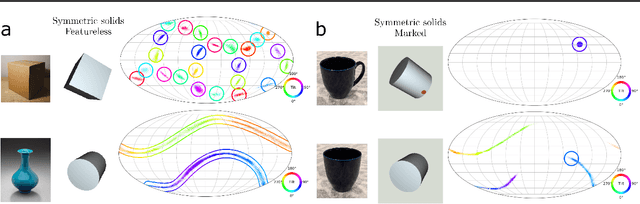
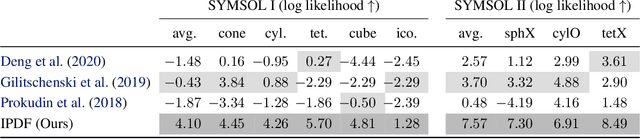
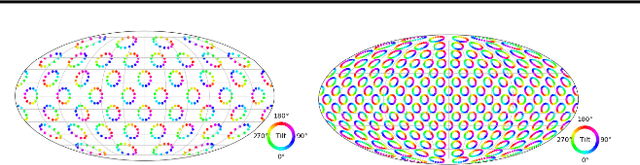
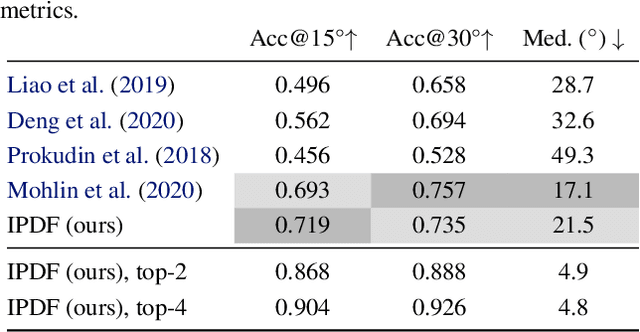
Single image pose estimation is a fundamental problem in many vision and robotics tasks, and existing deep learning approaches suffer by not completely modeling and handling: i) uncertainty about the predictions, and ii) symmetric objects with multiple (sometimes infinite) correct poses. To this end, we introduce a method to estimate arbitrary, non-parametric distributions on SO(3). Our key idea is to represent the distributions implicitly, with a neural network that estimates the probability given the input image and a candidate pose. Grid sampling or gradient ascent can be used to find the most likely pose, but it is also possible to evaluate the probability at any pose, enabling reasoning about symmetries and uncertainty. This is the most general way of representing distributions on manifolds, and to showcase the rich expressive power, we introduce a dataset of challenging symmetric and nearly-symmetric objects. We require no supervision on pose uncertainty -- the model trains only with a single pose per example. Nonetheless, our implicit model is highly expressive to handle complex distributions over 3D poses, while still obtaining accurate pose estimation on standard non-ambiguous environments, achieving state-of-the-art performance on Pascal3D+ and ModelNet10-SO(3) benchmarks.
No-reference Image Denoising Quality Assessment
Oct 13, 2018

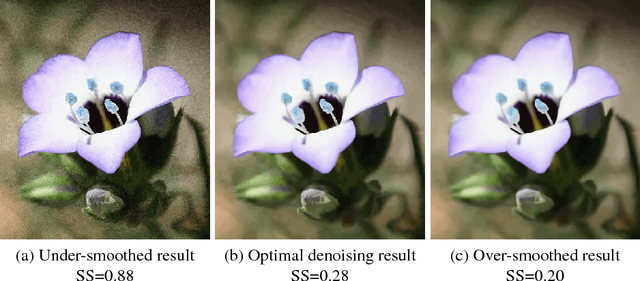
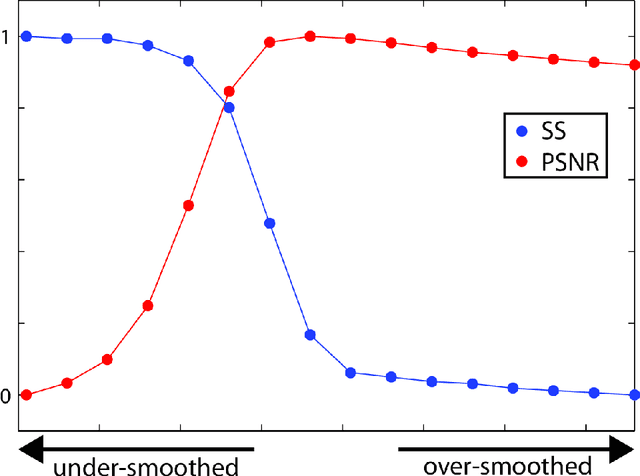
A wide variety of image denoising methods are available now. However, the performance of a denoising algorithm often depends on individual input noisy images as well as its parameter setting. In this paper, we present a no-reference image denoising quality assessment method that can be used to select for an input noisy image the right denoising algorithm with the optimal parameter setting. This is a challenging task as no ground truth is available. This paper presents a data-driven approach to learn to predict image denoising quality. Our method is based on the observation that while individual existing quality metrics and denoising models alone cannot robustly rank denoising results, they often complement each other. We accordingly design denoising quality features based on these existing metrics and models and then use Random Forests Regression to aggregate them into a more powerful unified metric. Our experiments on images with various types and levels of noise show that our no-reference denoising quality assessment method significantly outperforms the state-of-the-art quality metrics. This paper also provides a method that leverages our quality assessment method to automatically tune the parameter settings of a denoising algorithm for an input noisy image to produce an optimal denoising result.
Error Diffusion Halftoning Against Adversarial Examples
Jan 23, 2021
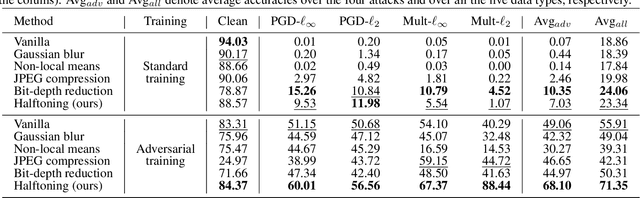
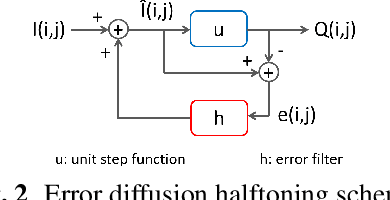
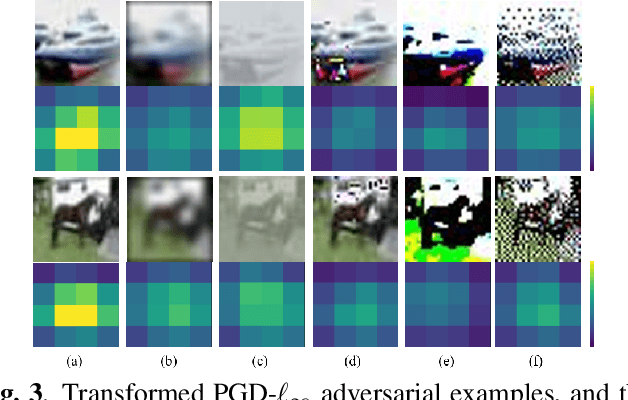
Adversarial examples contain carefully crafted perturbations that can fool deep neural networks (DNNs) into making wrong predictions. Enhancing the adversarial robustness of DNNs has gained considerable interest in recent years. Although image transformation-based defenses were widely considered at an earlier time, most of them have been defeated by adaptive attacks. In this paper, we propose a new image transformation defense based on error diffusion halftoning, and combine it with adversarial training to defend against adversarial examples. Error diffusion halftoning projects an image into a 1-bit space and diffuses quantization error to neighboring pixels. This process can remove adversarial perturbations from a given image while maintaining acceptable image quality in the meantime in favor of recognition. Experimental results demonstrate that the proposed method is able to improve adversarial robustness even under advanced adaptive attacks, while most of the other image transformation-based defenses do not. We show that a proper image transformation can still be an effective defense approach.
Knowledge driven Description Synthesis for Floor Plan Interpretation
Mar 15, 2021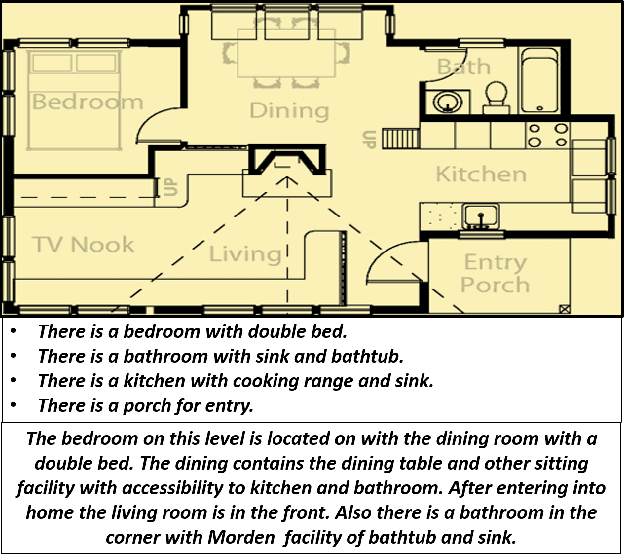
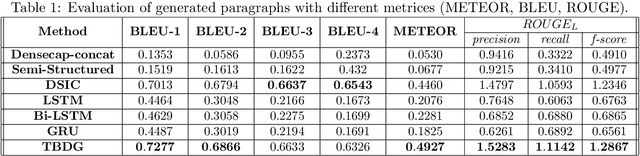
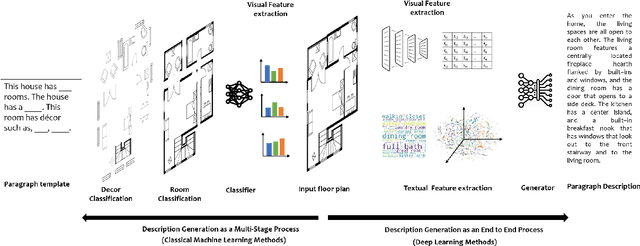
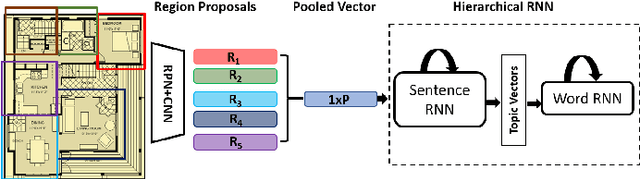
Image captioning is a widely known problem in the area of AI. Caption generation from floor plan images has applications in indoor path planning, real estate, and providing architectural solutions. Several methods have been explored in literature for generating captions or semi-structured descriptions from floor plan images. Since only the caption is insufficient to capture fine-grained details, researchers also proposed descriptive paragraphs from images. However, these descriptions have a rigid structure and lack flexibility, making it difficult to use them in real-time scenarios. This paper offers two models, Description Synthesis from Image Cue (DSIC) and Transformer Based Description Generation (TBDG), for the floor plan image to text generation to fill the gaps in existing methods. These two models take advantage of modern deep neural networks for visual feature extraction and text generation. The difference between both models is in the way they take input from the floor plan image. The DSIC model takes only visual features automatically extracted by a deep neural network, while the TBDG model learns textual captions extracted from input floor plan images with paragraphs. The specific keywords generated in TBDG and understanding them with paragraphs make it more robust in a general floor plan image. Experiments were carried out on a large-scale publicly available dataset and compared with state-of-the-art techniques to show the proposed model's superiority.
Detection and Captioning with Unseen Object Classes
Aug 13, 2021
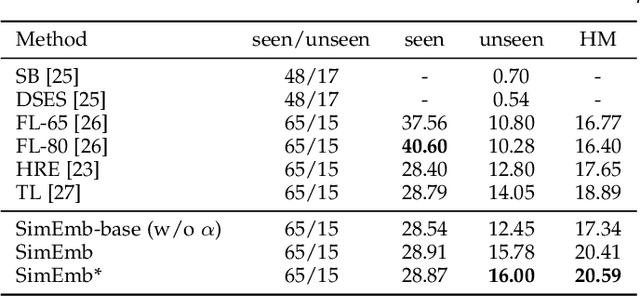
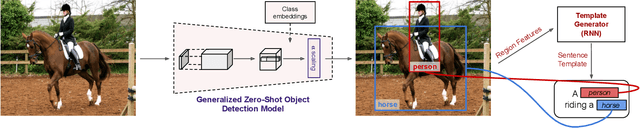
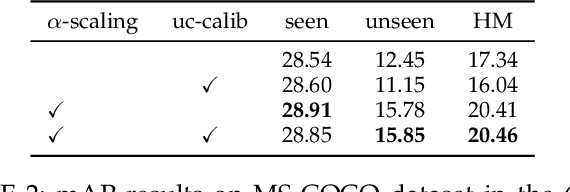
Image caption generation is one of the most challenging problems at the intersection of visual recognition and natural language modeling domains. In this work, we propose and study a practically important variant of this problem where test images may contain visual objects with no corresponding visual or textual training examples. For this problem, we propose a detection-driven approach based on a generalized zero-shot detection model and a template-based sentence generation model. In order to improve the detection component, we jointly define a class-to-class similarity based class representation and a practical score calibration mechanism. We also propose a novel evaluation metric that provides complimentary insights to the captioning outputs, by separately handling the visual and non-visual components of the captions. Our experiments show that the proposed zero-shot detection model obtains state-of-the-art performance on the MS-COCO dataset and the zero-shot captioning approach yields promising results.
Regularized Adaptation for Stable and Efficient Continuous-Level Learning on Image Processing Networks
Mar 12, 2020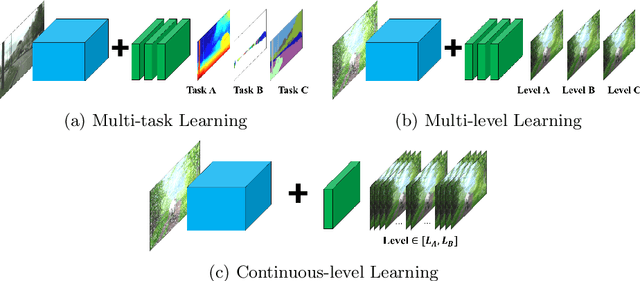

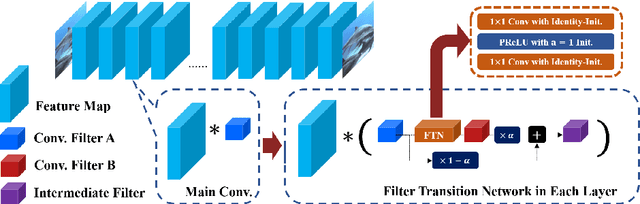

In Convolutional Neural Network (CNN) based image processing, most of the studies propose networks that are optimized for a single-level (or a single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train the networks on two different levels and propose their own interpolation methods to enable the arbitrary intermediate levels. However, many of them fail to adapt hard tasks or interpolate smoothly, or the others still require large memory and computational cost. In this paper, we propose a novel continuous-level learning framework using a Filter Transition Network (FTN) which is a non-linear module that easily adapt to new levels, and is regularized to prevent undesirable side-effects. Additionally, for stable learning of FTN, we newly propose a method to initialize non-linear CNNs with identity mappings. Furthermore, FTN is extremely lightweight module since it is a data-independent module, which means it is not affected by the spatial resolution of the inputs. Extensive results for various image processing tasks indicate that the performance of FTN is stable in terms of adaptation and interpolation, and comparable to that of the other heavy frameworks.