 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hypothesis-driven Stream Learning with Augmented Memory
Apr 07, 2021
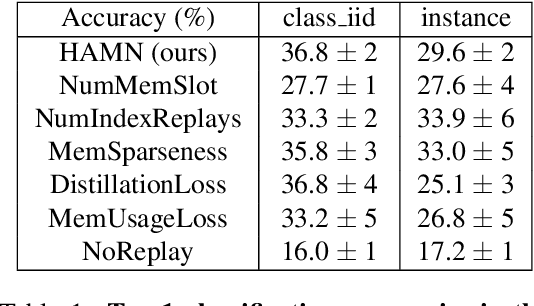
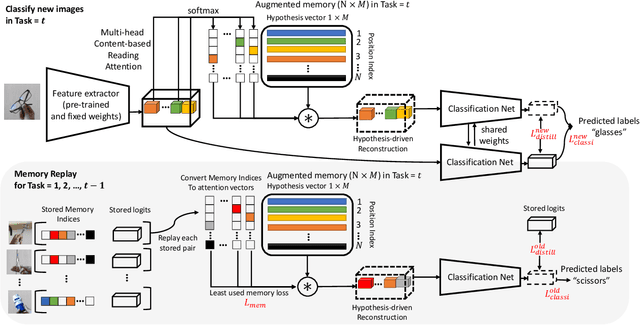
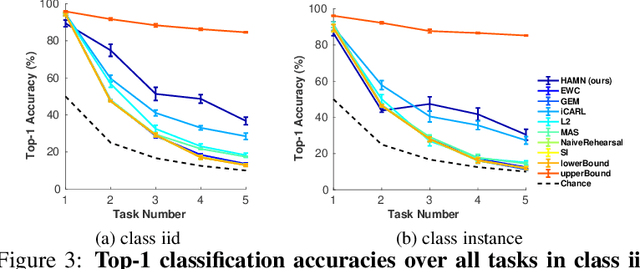
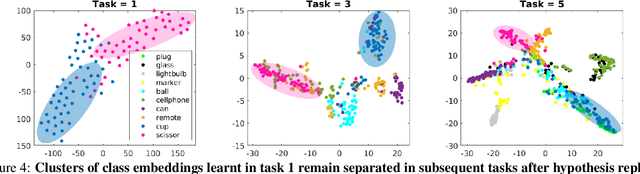
Stream learning refers to the ability to acquire and transfer knowledge across a continuous stream of data without forgetting and without repeated passes over the data. A common way to avoid catastrophic forgetting is to intersperse new examples with replays of old examples stored as image pixels or reproduced by generative models. Here, we considered stream learning in image classification tasks and proposed a novel hypotheses-driven Augmented Memory Network, which efficiently consolidates previous knowledge with a limited number of hypotheses in the augmented memory and replays relevant hypotheses to avoid catastrophic forgetting. The advantages of hypothesis-driven replay over image pixel replay and generative replay are two-fold. First, hypothesis-based knowledge consolidation avoids redundant information in the image pixel space and makes memory usage more efficient. Second, hypotheses in the augmented memory can be re-used for learning new tasks, improving generalization and transfer learning ability. We evaluated our method on three stream learning object recognition datasets. Our method performs comparably well or better than SOTA methods, while offering more efficient memory usage. All source code and data are publicly available https://github.com/kreimanlab/AugMem.
Weakly-Supervised Photo-realistic Texture Generation for 3D Face Reconstruction
Jun 14, 2021
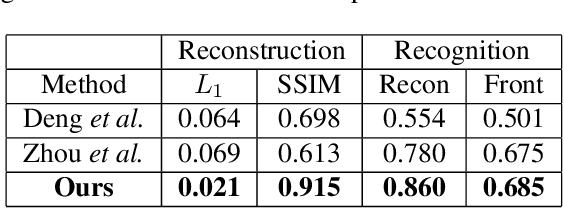
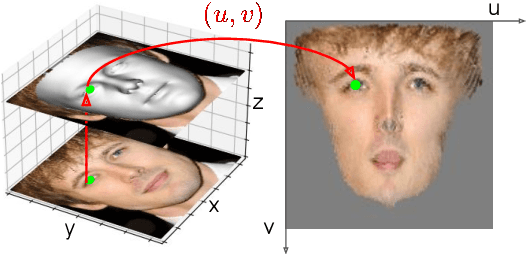
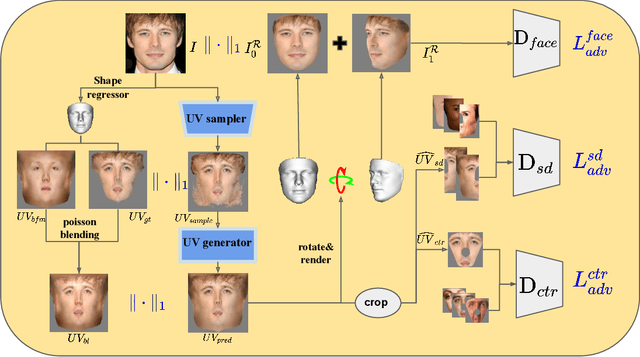
Although much progress has been made recently in 3D face reconstruction, most previous work has been devoted to predicting accurate and fine-grained 3D shapes. In contrast, relatively little work has focused on generating high-fidelity face textures. Compared with the prosperity of photo-realistic 2D face image generation, high-fidelity 3D face texture generation has yet to be studied. In this paper, we proposed a novel UV map generation model that predicts the UV map from a single face image. The model consists of a UV sampler and a UV generator. By selectively sampling the input face image's pixels and adjusting their relative locations, the UV sampler generates an incomplete UV map that could faithfully reconstruct the original face. Missing textures in the incomplete UV map are further full-filled by the UV generator. The training is based on pseudo ground truth blended by the 3DMM texture and the input face texture, thus weakly supervised. To deal with the artifacts in the imperfect pseudo UV map, multiple partial UV map discriminators are leveraged.
Intriguing Properties of Vision Transformers
Jun 08, 2021



Vision transformers (ViT) have demonstrated impressive performance across various machine vision problems. These models are based on multi-head self-attention mechanisms that can flexibly attend to a sequence of image patches to encode contextual cues. An important question is how such flexibility in attending image-wide context conditioned on a given patch can facilitate handling nuisances in natural images e.g., severe occlusions, domain shifts, spatial permutations, adversarial and natural perturbations. We systematically study this question via an extensive set of experiments encompassing three ViT families and comparisons with a high-performing convolutional neural network (CNN). We show and analyze the following intriguing properties of ViT: (a) Transformers are highly robust to severe occlusions, perturbations and domain shifts, e.g., retain as high as 60% top-1 accuracy on ImageNet even after randomly occluding 80% of the image content. (b) The robust performance to occlusions is not due to a bias towards local textures, and ViTs are significantly less biased towards textures compared to CNNs. When properly trained to encode shape-based features, ViTs demonstrate shape recognition capability comparable to that of human visual system, previously unmatched in the literature. (c) Using ViTs to encode shape representation leads to an interesting consequence of accurate semantic segmentation without pixel-level supervision. (d) Off-the-shelf features from a single ViT model can be combined to create a feature ensemble, leading to high accuracy rates across a range of classification datasets in both traditional and few-shot learning paradigms. We show effective features of ViTs are due to flexible and dynamic receptive fields possible via the self-attention mechanism.
BLNet: A Fast Deep Learning Framework for Low-Light Image Enhancement with Noise Removal and Color Restoration
Jun 30, 2021

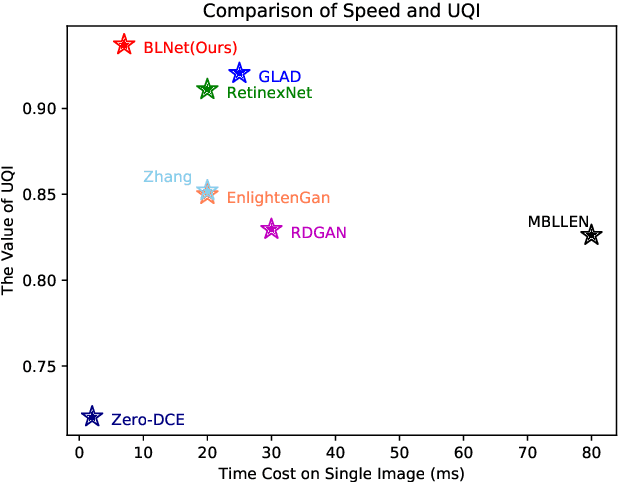

Images obtained in real-world low-light conditions are not only low in brightness, but they also suffer from many other types of degradation, such as color bias, unknown noise, detail loss and halo artifacts. In this paper, we propose a very fast deep learning framework called Bringing the Lightness (denoted as BLNet) that consists of two U-Nets with a series of well-designed loss functions to tackle all of the above degradations. Based on Retinex Theory, the decomposition net in our model can decompose low-light images into reflectance and illumination and remove noise in the reflectance during the decomposition phase. We propose a Noise and Color Bias Control module (NCBC Module) that contains a convolutional neural network and two loss functions (noise loss and color loss). This module is only used to calculate the loss functions during the training phase, so our method is very fast during the test phase. This module can smooth the reflectance to achieve the purpose of noise removal while preserving details and edge information and controlling color bias. We propose a network that can be trained to learn the mapping between low-light and normal-light illumination and enhance the brightness of images taken in low-light illumination. We train and evaluate the performance of our proposed model over the real-world Low-Light (LOL) dataset), and we also test our model over several other frequently used datasets (LIME, DICM and MEF datasets). We conduct extensive experiments to demonstrate that our approach achieves a promising effect with good rubustness and generalization and outperforms many other state-of-the-art methods qualitatively and quantitatively. Our method achieves high speed because we use loss functions instead of introducing additional denoisers for noise removal and color correction. The code and model are available at https://github.com/weixinxu666/BLNet.
Category-Level Metric Scale Object Shape and Pose Estimation
Sep 01, 2021
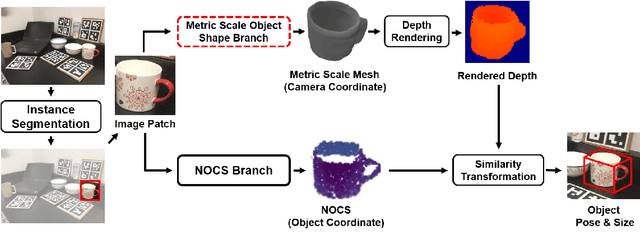
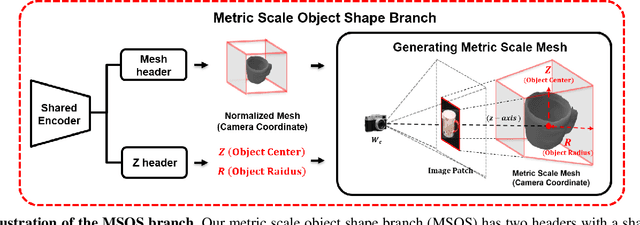
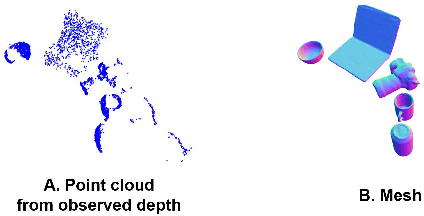
Advances in deep learning recognition have led to accurate object detection with 2D images. However, these 2D perception methods are insufficient for complete 3D world information. Concurrently, advanced 3D shape estimation approaches focus on the shape itself, without considering metric scale. These methods cannot determine the accurate location and orientation of objects. To tackle this problem, we propose a framework that jointly estimates a metric scale shape and pose from a single RGB image. Our framework has two branches: the Metric Scale Object Shape branch (MSOS) and the Normalized Object Coordinate Space branch (NOCS). The MSOS branch estimates the metric scale shape observed in the camera coordinates. The NOCS branch predicts the normalized object coordinate space (NOCS) map and performs similarity transformation with the rendered depth map from a predicted metric scale mesh to obtain 6d pose and size. Additionally, we introduce the Normalized Object Center Estimation (NOCE) to estimate the geometrically aligned distance from the camera to the object center. We validated our method on both synthetic and real-world datasets to evaluate category-level object pose and shape.
GAN Inversion for Out-of-Range Images with Geometric Transformations
Aug 20, 2021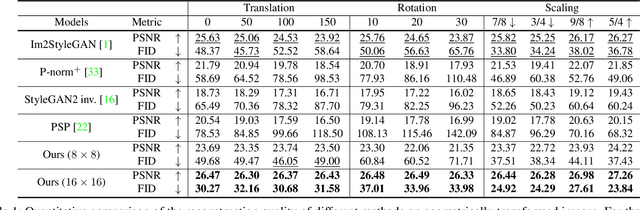
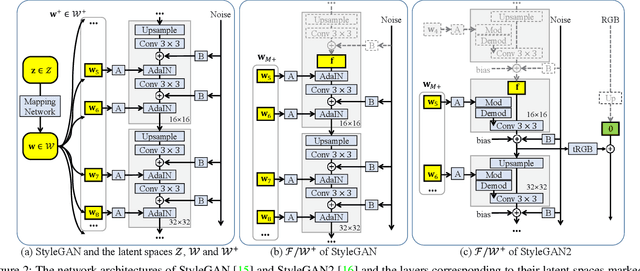
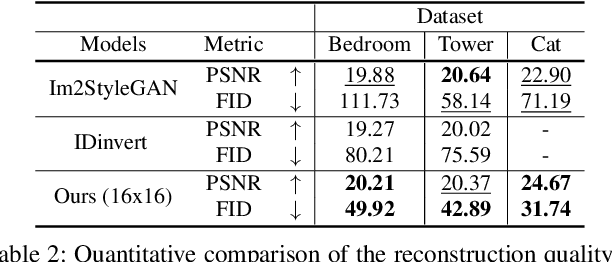

For successful semantic editing of real images, it is critical for a GAN inversion method to find an in-domain latent code that aligns with the domain of a pre-trained GAN model. Unfortunately, such in-domain latent codes can be found only for in-range images that align with the training images of a GAN model. In this paper, we propose BDInvert, a novel GAN inversion approach to semantic editing of out-of-range images that are geometrically unaligned with the training images of a GAN model. To find a latent code that is semantically editable, BDInvert inverts an input out-of-range image into an alternative latent space than the original latent space. We also propose a regularized inversion method to find a solution that supports semantic editing in the alternative space. Our experiments show that BDInvert effectively supports semantic editing of out-of-range images with geometric transformations.
Image Based Review Text Generation with Emotional Guidance
Jan 14, 2019
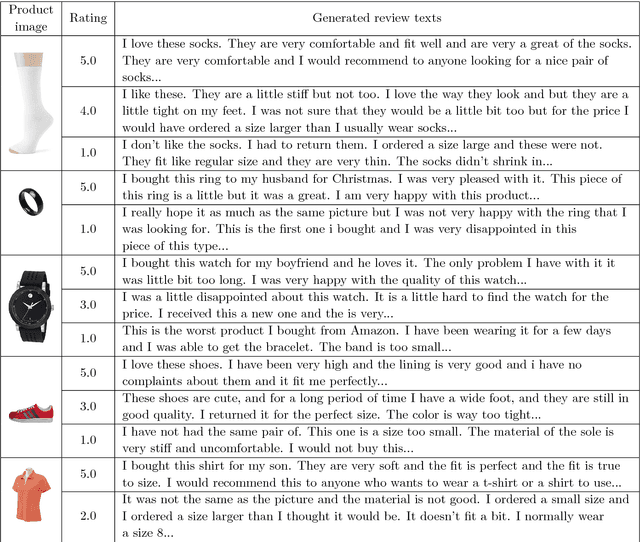
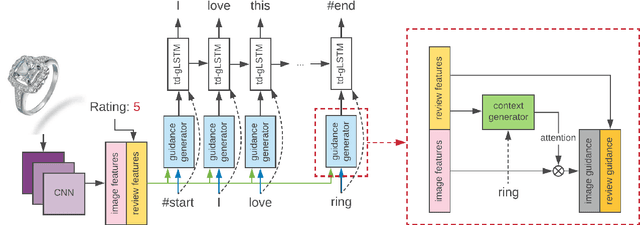
In the current field of computer vision, automatically generating texts from given images has been a fully worked technique. Up till now, most works of this area focus on image content describing, namely image-captioning. However, rare researches focus on generating product review texts, which is ubiquitous in the online shopping malls and is crucial for online shopping selection and evaluation. Different from content describing, review texts include more subjective information of customers, which may bring difference to the results. Therefore, we aimed at a new field concerning generating review text from customers based on images together with the ratings of online shopping products, which appear as non-image attributes. We made several adjustments to the existing image-captioning model to fit our task, in which we should also take non-image features into consideration. We also did experiments based on our model and get effective primary results.
Zero-Shot Image Classification Using Coupled Dictionary Embedding
Jun 10, 2019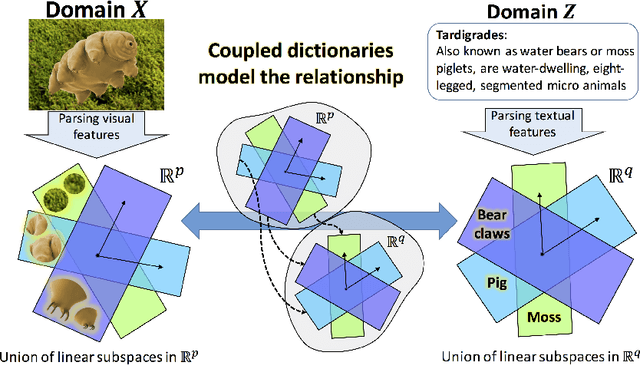
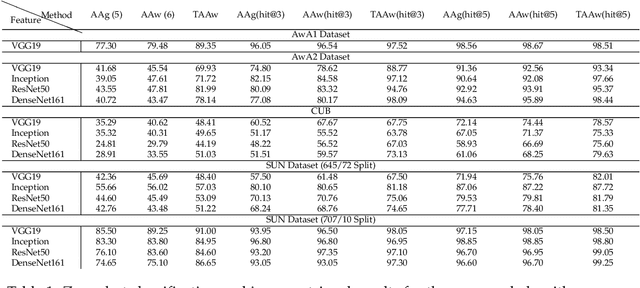
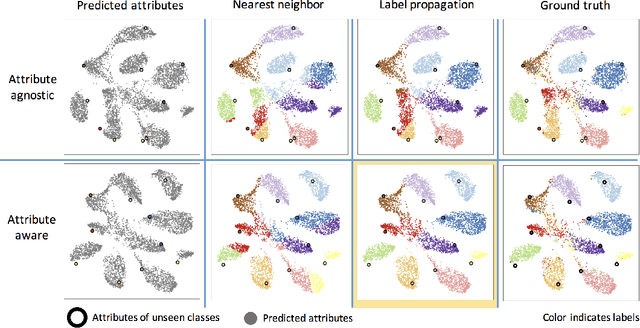
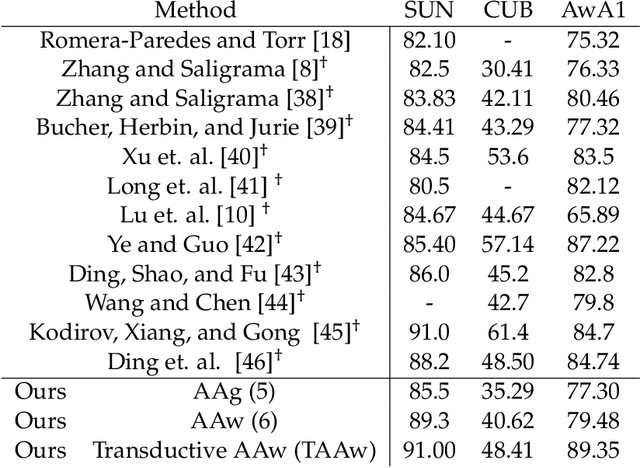
Zero-shot learning (ZSL) is a framework to classify images belonging to unseen classes based on solely semantic information about these unseen classes. In this paper, we propose a new ZSL algorithm using coupled dictionary learning. The core idea is that the visual features and the semantic attributes of an image can share the same sparse representation in an intermediate space. We use images from seen classes and semantic attributes from seen and unseen classes to learn two dictionaries that can represent sparsely the visual and semantic feature vectors of an image. In the ZSL testing stage and in the absence of labeled data, images from unseen classes can be mapped into the attribute space by finding the joint sparse representation using solely the visual data. The image is then classified in the attribute space given semantic descriptions of unseen classes. We also provide an attribute-aware formulation to tackle domain shift and hubness problems in ZSL. Extensive experiments are provided to demonstrate the superior performance of our approach against the state of the art ZSL algorithms on benchmark ZSL datasets.
Dual Contrastive Loss and Attention for GANs
Mar 31, 2021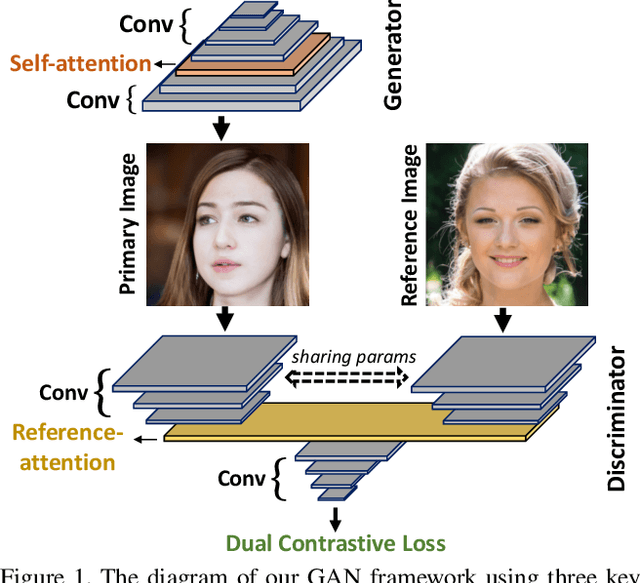
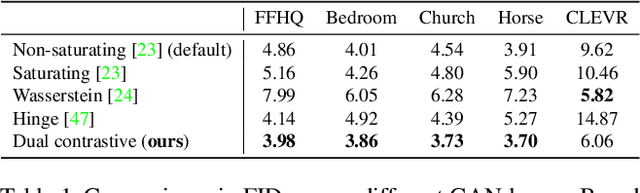
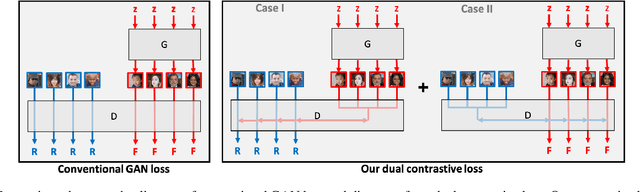

Generative Adversarial Networks (GANs) produce impressive results on unconditional image generation when powered with large-scale image datasets. Yet generated images are still easy to spot especially on datasets with high variance (e.g. bedroom, church). In this paper, we propose various improvements to further push the boundaries in image generation. Specifically, we propose a novel dual contrastive loss and show that, with this loss, discriminator learns more generalized and distinguishable representations to incentivize generation. In addition, we revisit attention and extensively experiment with different attention blocks in the generator. We find attention to be still an important module for successful image generation even though it was not used in the recent state-of-the-art models. Lastly, we study different attention architectures in the discriminator, and propose a reference attention mechanism. By combining the strengths of these remedies, we improve the compelling state-of-the-art Fr\'{e}chet Inception Distance (FID) by at least 17.5% on several benchmark datasets. We obtain even more significant improvements on compositional synthetic scenes (up to 47.5% in FID).
The Impact of Reinitialization on Generalization in Convolutional Neural Networks
Sep 01, 2021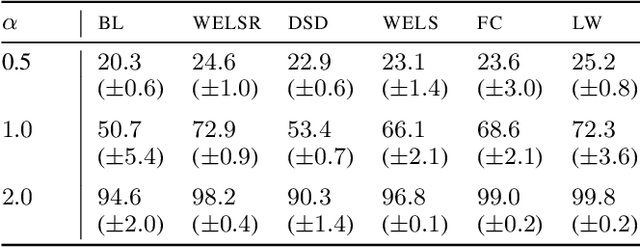
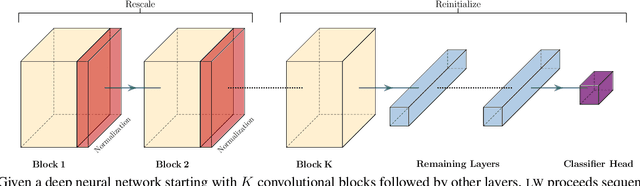
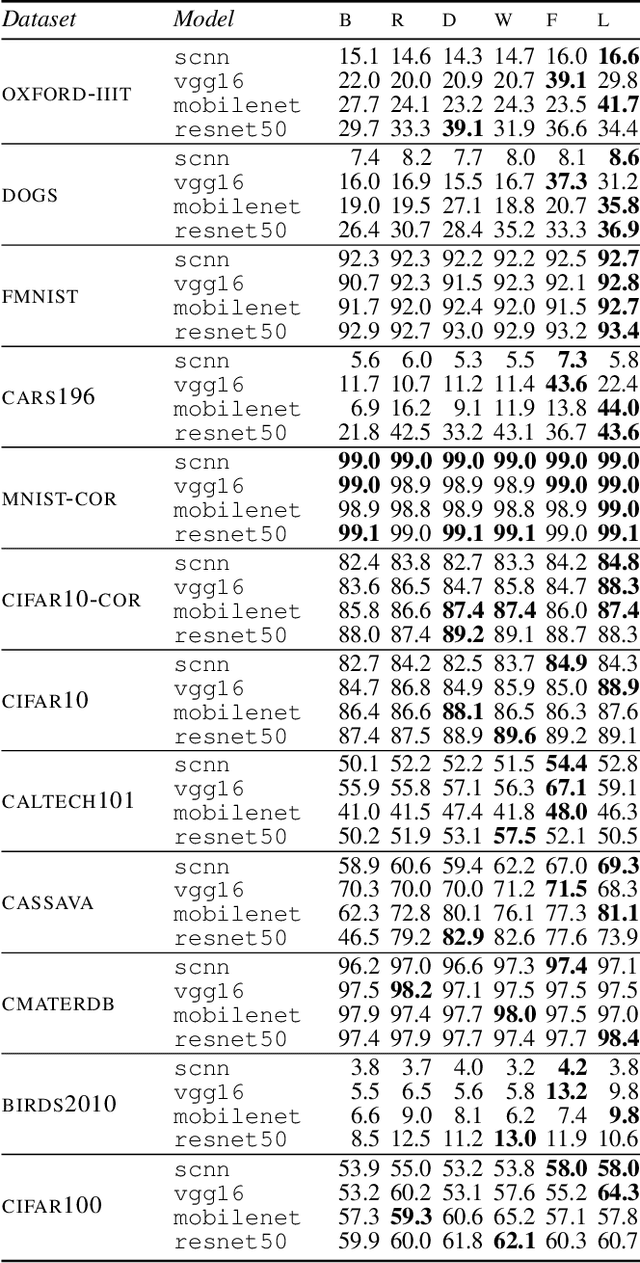
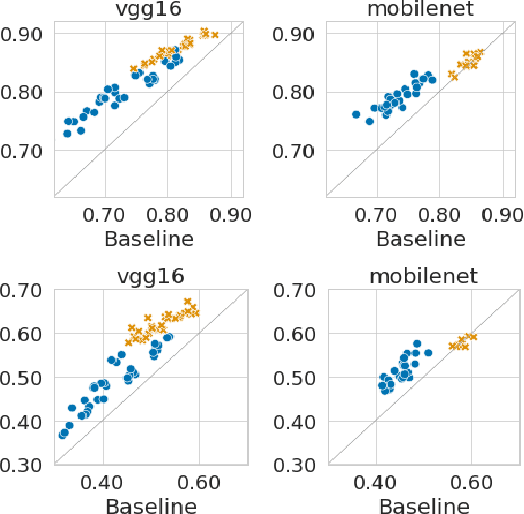
Recent results suggest that reinitializing a subset of the parameters of a neural network during training can improve generalization, particularly for small training sets. We study the impact of different reinitialization methods in several convolutional architectures across 12 benchmark image classification datasets, analyzing their potential gains and highlighting limitations. We also introduce a new layerwise reinitialization algorithm that outperforms previous methods and suggest explanations of the observed improved generalization. First, we show that layerwise reinitialization increases the margin on the training examples without increasing the norm of the weights, hence leading to an improvement in margin-based generalization bounds for neural networks. Second, we demonstrate that it settles in flatter local minima of the loss surface. Third, it encourages learning general rules and discourages memorization by placing emphasis on the lower layers of the neural network. Our takeaway message is that the accuracy of convolutional neural networks can be improved for small datasets using bottom-up layerwise reinitialization, where the number of reinitialized layers may vary depending on the available compute budget.