 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Segmentation of Brain MRI using an Altruistic Harris Hawks' Optimization algorithm
Sep 17, 2021
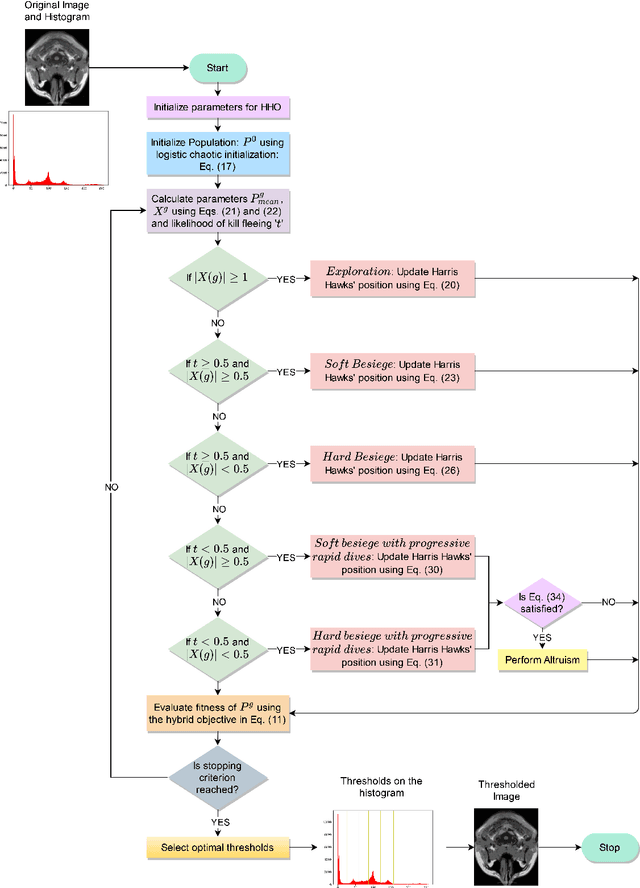
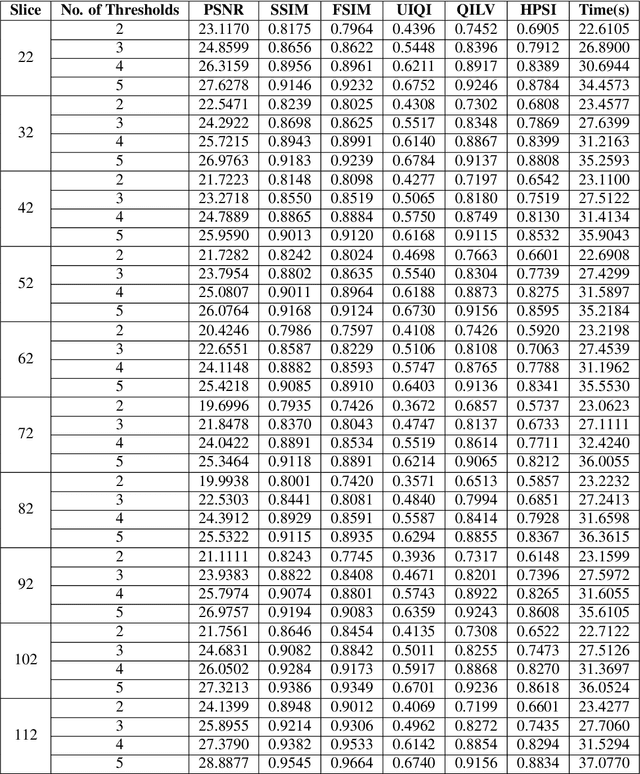
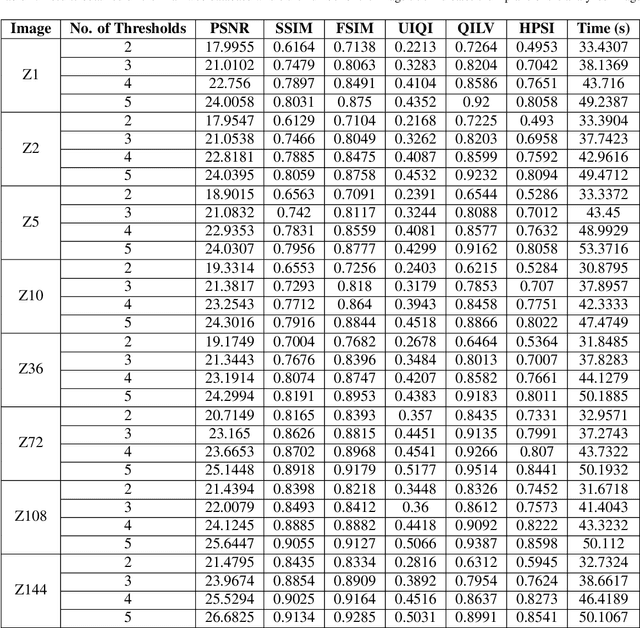
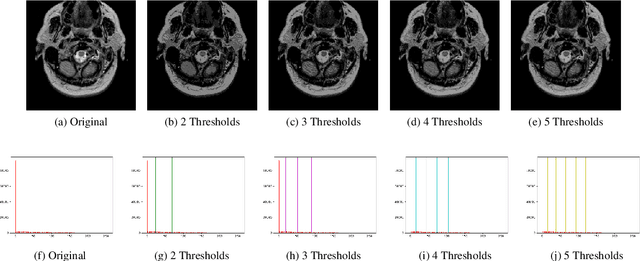
Segmentation is an essential requirement in medicine when digital images are used in illness diagnosis, especially, in posterior tasks as analysis and disease identification. An efficient segmentation of brain Magnetic Resonance Images (MRIs) is of prime concern to radiologists due to their poor illumination and other conditions related to de acquisition of the images. Thresholding is a popular method for segmentation that uses the histogram of an image to label different homogeneous groups of pixels into different classes. However, the computational cost increases exponentially according to the number of thresholds. In this paper, we perform the multi-level thresholding using an evolutionary metaheuristic. It is an improved version of the Harris Hawks Optimization (HHO) algorithm that combines the chaotic initialization and the concept of altruism. Further, for fitness assignment, we use a hybrid objective function where along with the cross-entropy minimization, we apply a new entropy function, and leverage weights to the two objective functions to form a new hybrid approach. The HHO was originally designed to solve numerical optimization problems. Earlier, the statistical results and comparisons have demonstrated that the HHO provides very promising results compared with well-established metaheuristic techniques. In this article, the altruism has been incorporated into the HHO algorithm to enhance its exploitation capabilities. We evaluate the proposed method over 10 benchmark images from the WBA database of the Harvard Medical School and 8 benchmark images from the Brainweb dataset using some standard evaluation metrics.
Relaxing Local Robustness
Jun 11, 2021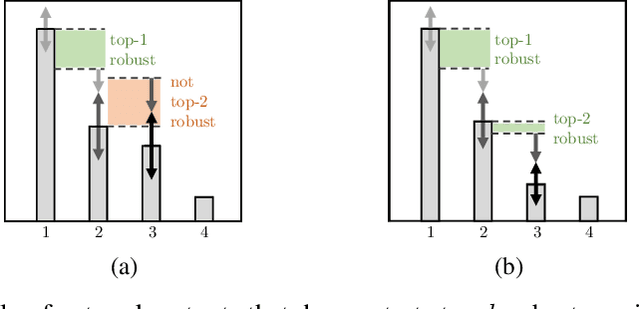
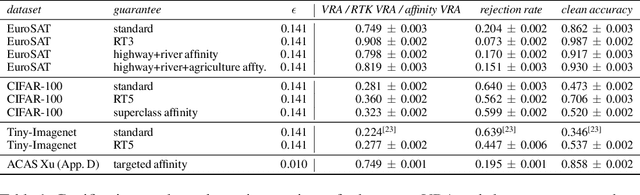


Certifiable local robustness, which rigorously precludes small-norm adversarial examples, has received significant attention as a means of addressing security concerns in deep learning. However, for some classification problems, local robustness is not a natural objective, even in the presence of adversaries; for example, if an image contains two classes of subjects, the correct label for the image may be considered arbitrary between the two, and thus enforcing strict separation between them is unnecessary. In this work, we introduce two relaxed safety properties for classifiers that address this observation: (1) relaxed top-k robustness, which serves as the analogue of top-k accuracy; and (2) affinity robustness, which specifies which sets of labels must be separated by a robustness margin, and which can be $\epsilon$-close in $\ell_p$ space. We show how to construct models that can be efficiently certified against each relaxed robustness property, and trained with very little overhead relative to standard gradient descent. Finally, we demonstrate experimentally that these relaxed variants of robustness are well-suited to several significant classification problems, leading to lower rejection rates and higher certified accuracies than can be obtained when certifying "standard" local robustness.
A simple and effective postprocessing method for image classification
Jun 19, 2019
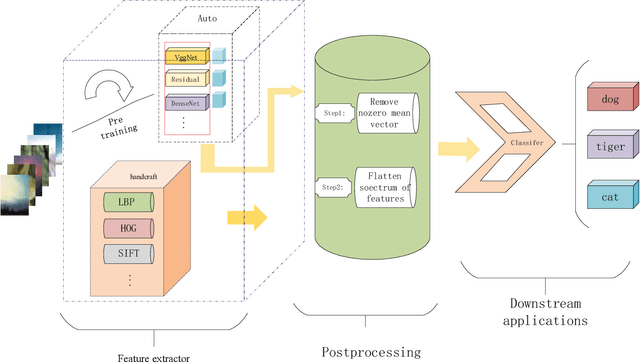

Whether it is computer vision, natural language processing or speech recognition, the essence of these applications is to obtain powerful feature representations that make downstream applications completion more efficient. Taking image recognition as an example, whether it is hand-crafted low-level feature representation or feature representation extracted by a convolutional neural networks(CNNs), the goal is to extract features that better represent image features, thereby improving classification accuracy. However, we observed that image feature representations share a large common vector and a few top dominating directions. To address this problems, we propose a simple but effective postprocessing method to render off-the-shelf feature representations even stronger by eliminating the common mean vector from off-the-shelf feature representations. The postprocessing is empirically validated on a variety of datasets and feature extraction methods.such as VGG, LBP, and HOG. Some experiments show that the features that have been post-processed by postprocessing algorithm can get better results than original ones.
A Survey on Deep Learning of Small Sample in Biomedical Image Analysis
Aug 01, 2019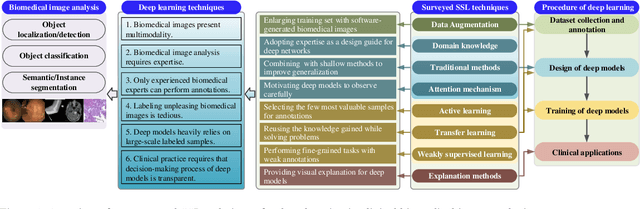
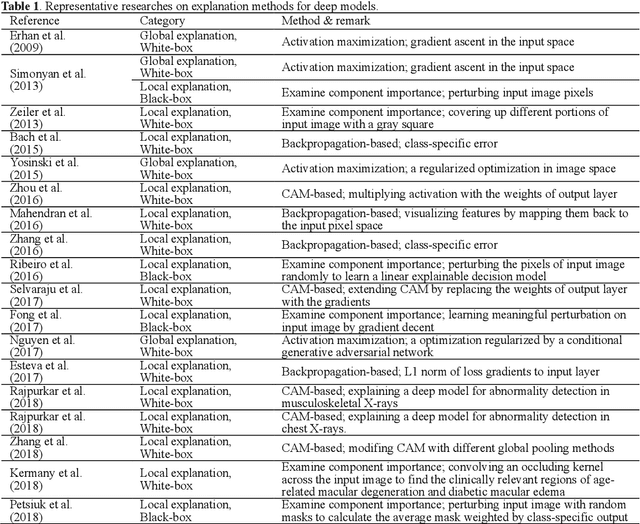
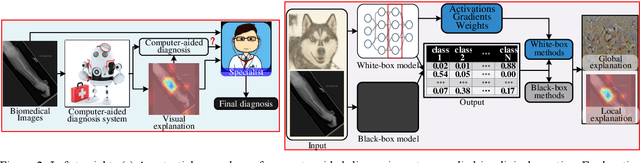
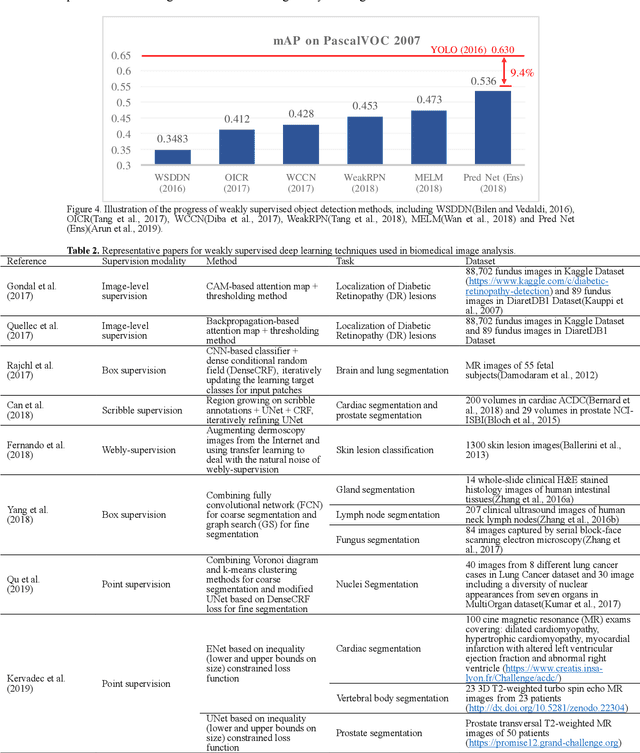
The success of deep learning has been witnessed as a promising technique for computer-aided biomedical image analysis, due to end-to-end learning framework and availability of large-scale labelled samples. However, in many cases of biomedical image analysis, deep learning techniques suffer from the small sample learning (SSL) dilemma caused mainly by lack of annotations. To be more practical for biomedical image analysis, in this paper we survey the key SSL techniques that help relieve the suffering of deep learning by combining with the development of related techniques in computer vision applications. In order to accelerate the clinical usage of biomedical image analysis based on deep learning techniques, we intentionally expand this survey to include the explanation methods for deep models that are important to clinical decision making. We survey the key SSL techniques by dividing them into five categories: (1) explanation techniques, (2) weakly supervised learning techniques, (3) transfer learning techniques, (4) active learning techniques, and (5) miscellaneous techniques involving data augmentation, domain knowledge, traditional shallow methods and attention mechanism. These key techniques are expected to effectively support the application of deep learning in clinical biomedical image analysis, and furtherly improve the analysis performance, especially when large-scale annotated samples are not available. We bulid demos at https://github.com/PengyiZhang/MIADeepSSL.
Spatial Transformer Networks for Curriculum Learning
Aug 22, 2021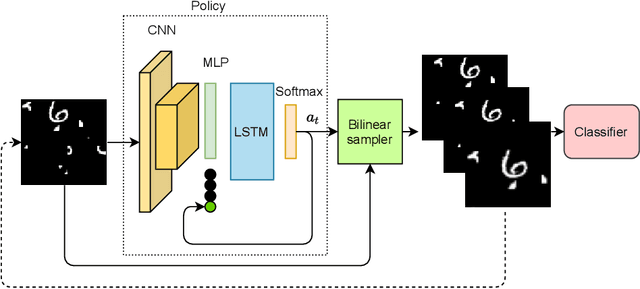



Curriculum learning is a bio-inspired training technique that is widely adopted to machine learning for improved optimization and better training of neural networks regarding the convergence rate or obtained accuracy. The main concept in curriculum learning is to start the training with simpler tasks and gradually increase the level of difficulty. Therefore, a natural question is how to determine or generate these simpler tasks. In this work, we take inspiration from Spatial Transformer Networks (STNs) in order to form an easy-to-hard curriculum. As STNs have been proven to be capable of removing the clutter from the input images and obtaining higher accuracy in image classification tasks, we hypothesize that images processed by STNs can be seen as easier tasks and utilized in the interest of curriculum learning. To this end, we study multiple strategies developed for shaping the training curriculum, using the data generated by STNs. We perform various experiments on cluttered MNIST and Fashion-MNIST datasets, where on the former, we obtain an improvement of $3.8$pp in classification accuracy compared to the baseline.
Progressive and Aligned Pose Attention Transfer for Person Image Generation
Mar 22, 2021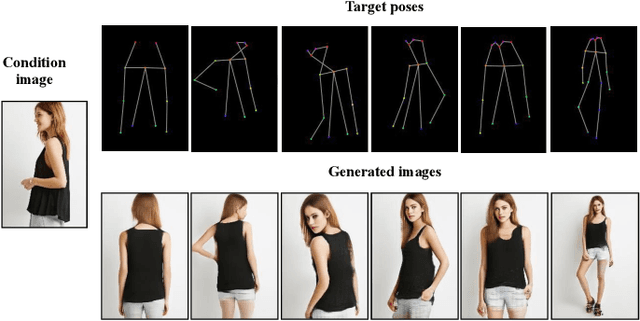
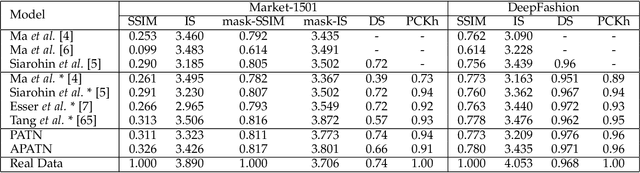
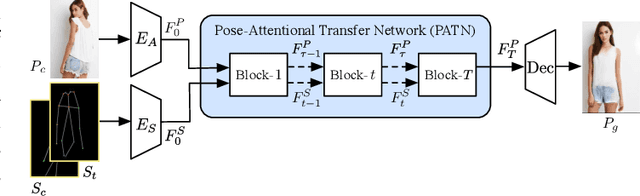
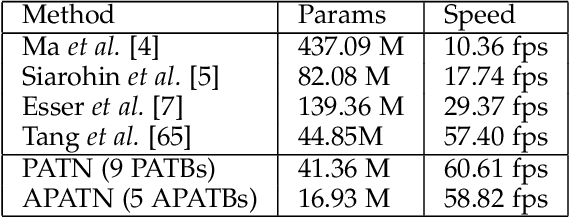
This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. We design a progressive generator which comprises a sequence of transfer blocks. Each block performs an intermediate transfer step by modeling the relationship between the condition and the target poses with attention mechanism. Two types of blocks are introduced, namely Pose-Attentional Transfer Block (PATB) and Aligned Pose-Attentional Transfer Bloc ~(APATB). Compared with previous works, our model generates more photorealistic person images that retain better appearance consistency and shape consistency compared with input images. We verify the efficacy of the model on the Market-1501 and DeepFashion datasets, using quantitative and qualitative measures. Furthermore, we show that our method can be used for data augmentation for the person re-identification task, alleviating the issue of data insufficiency. Code and pretrained models are available at https://github.com/tengteng95/Pose-Transfer.git.
Residual Attention: A Simple but Effective Method for Multi-Label Recognition
Aug 05, 2021
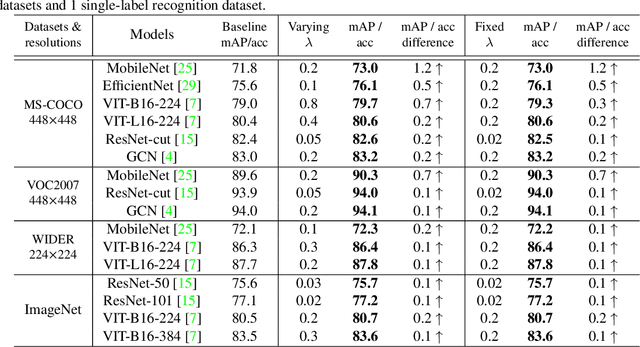
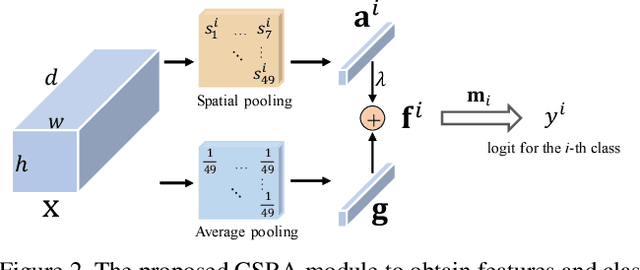
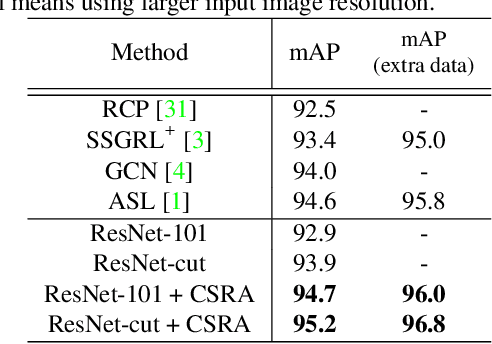
Multi-label image recognition is a challenging computer vision task of practical use. Progresses in this area, however, are often characterized by complicated methods, heavy computations, and lack of intuitive explanations. To effectively capture different spatial regions occupied by objects from different categories, we propose an embarrassingly simple module, named class-specific residual attention (CSRA). CSRA generates class-specific features for every category by proposing a simple spatial attention score, and then combines it with the class-agnostic average pooling feature. CSRA achieves state-of-the-art results on multilabel recognition, and at the same time is much simpler than them. Furthermore, with only 4 lines of code, CSRA also leads to consistent improvement across many diverse pretrained models and datasets without any extra training. CSRA is both easy to implement and light in computations, which also enjoys intuitive explanations and visualizations.
Comprehensive Validation of Automated Whole Body Skeletal Muscle, Adipose Tissue, and Bone Segmentation from 3D CT images for Body Composition Analysis: Towards Extended Body Composition
Jun 03, 2021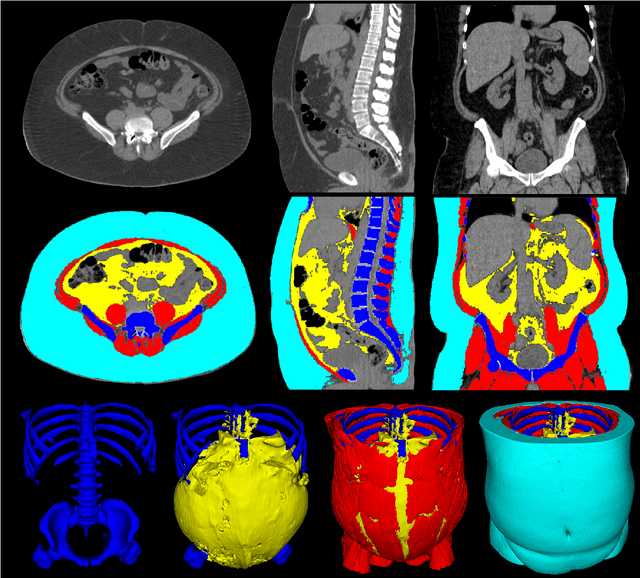

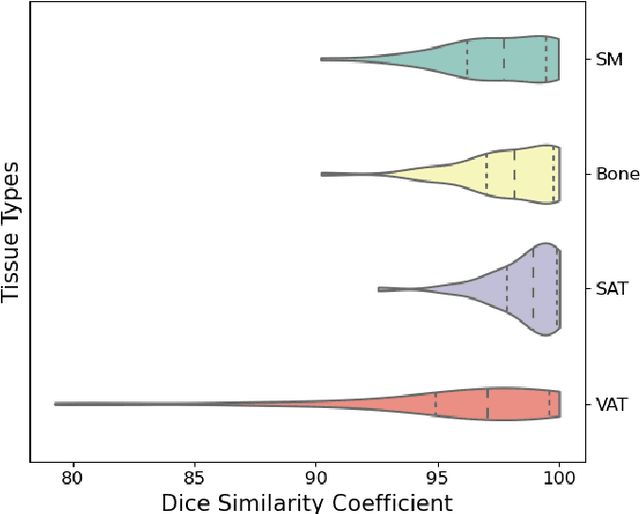
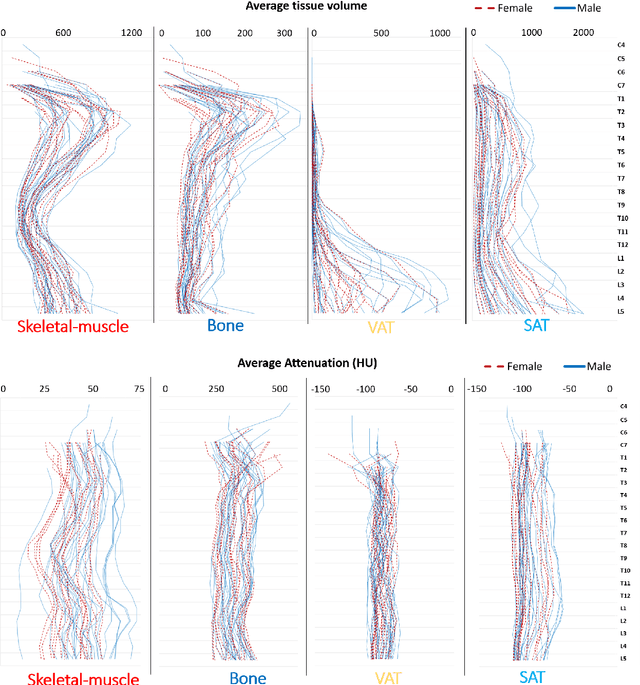
The latest advances in computer-assisted precision medicine are making it feasible to move from population-wide models that are useful to discover aggregate patterns that hold for group-based analysis to patient-specific models that can drive patient-specific decisions with regard to treatment choices, and predictions of outcomes of treatment. Body Composition is recognized as an important driver and risk factor for a wide variety of diseases, as well as a predictor of individual patient-specific clinical outcomes to treatment choices or surgical interventions. 3D CT images are routinely acquired in the oncological worklows and deliver accurate rendering of internal anatomy and therefore can be used opportunistically to assess the amount of skeletal muscle and adipose tissue compartments. Powerful tools of artificial intelligence such as deep learning are making it feasible now to segment the entire 3D image and generate accurate measurements of all internal anatomy. These will enable the overcoming of the severe bottleneck that existed previously, namely, the need for manual segmentation, which was prohibitive to scale to the hundreds of 2D axial slices that made up a 3D volumetric image. Automated tools such as presented here will now enable harvesting whole-body measurements from 3D CT or MRI images, leading to a new era of discovery of the drivers of various diseases based on individual tissue, organ volume, shape, and functional status. These measurements were hitherto unavailable thereby limiting the field to a very small and limited subset. These discoveries and the potential to perform individual image segmentation with high speed and accuracy are likely to lead to the incorporation of these 3D measures into individual specific treatment planning models related to nutrition, aging, chemotoxicity, surgery and survival after the onset of a major disease such as cancer.
Brain Image Synthesis with Unsupervised Multivariate Canonical CSC$\ell_4$Net
Mar 22, 2021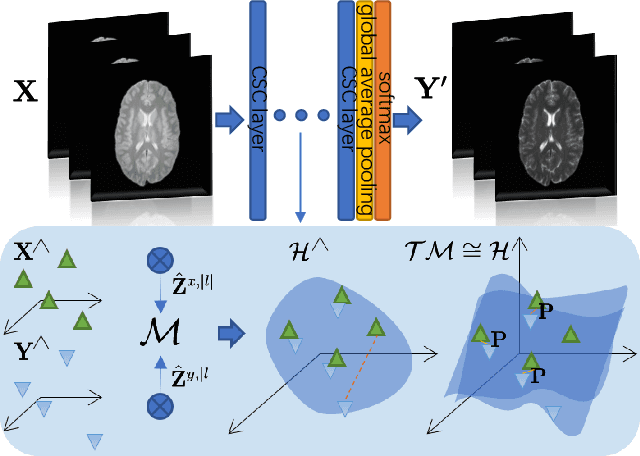
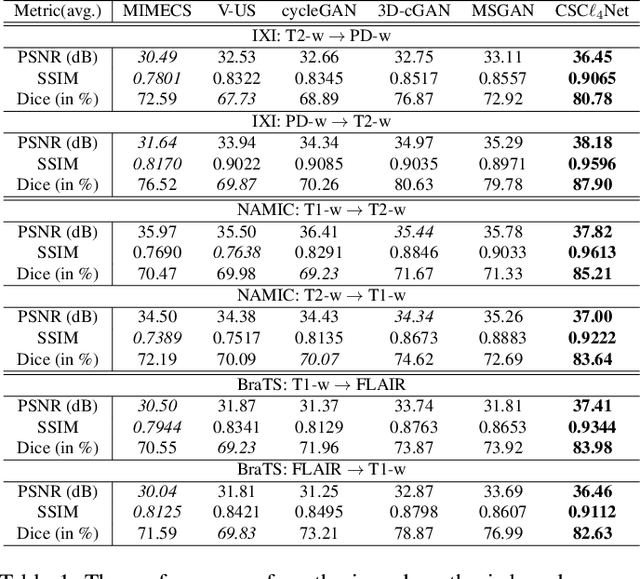
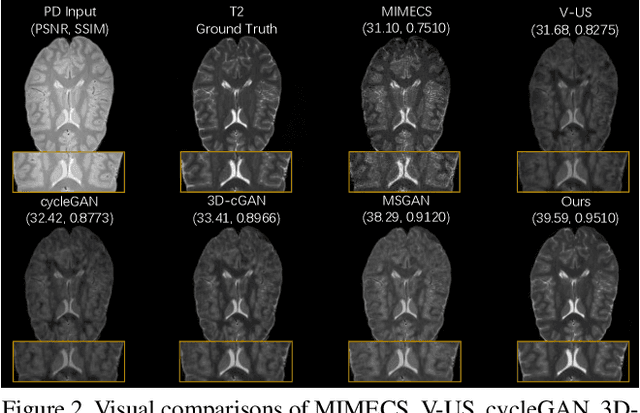
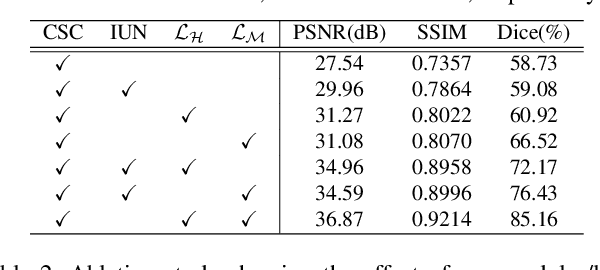
Recent advances in neuroscience have highlighted the effectiveness of multi-modal medical data for investigating certain pathologies and understanding human cognition. However, obtaining full sets of different modalities is limited by various factors, such as long acquisition times, high examination costs and artifact suppression. In addition, the complexity, high dimensionality and heterogeneity of neuroimaging data remains another key challenge in leveraging existing randomized scans effectively, as data of the same modality is often measured differently by different machines. There is a clear need to go beyond the traditional imaging-dependent process and synthesize anatomically specific target-modality data from a source input. In this paper, we propose to learn dedicated features that cross both intre- and intra-modal variations using a novel CSC$\ell_4$Net. Through an initial unification of intra-modal data in the feature maps and multivariate canonical adaptation, CSC$\ell_4$Net facilitates feature-level mutual transformation. The positive definite Riemannian manifold-penalized data fidelity term further enables CSC$\ell_4$Net to reconstruct missing measurements according to transformed features. Finally, the maximization $\ell_4$-norm boils down to a computationally efficient optimization problem. Extensive experiments validate the ability and robustness of our CSC$\ell_4$Net compared to the state-of-the-art methods on multiple datasets.
Cooperative image captioning
Jul 26, 2019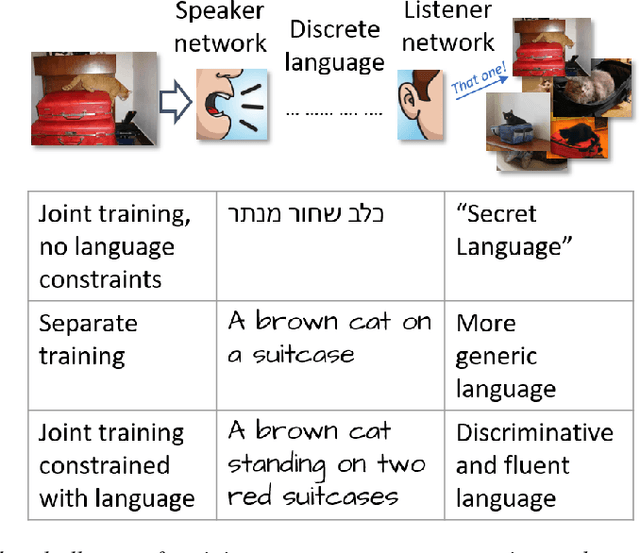

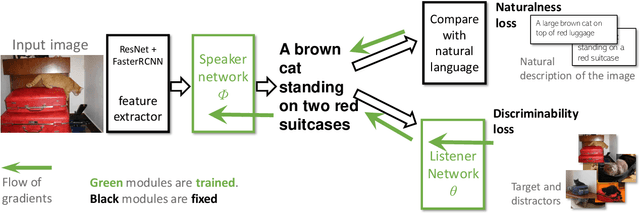
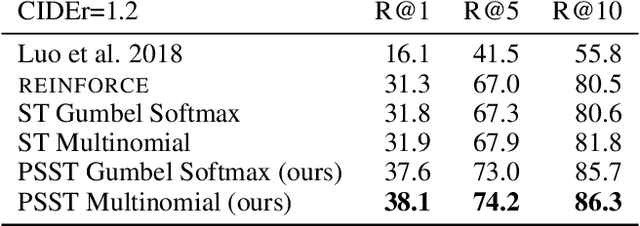
When describing images with natural language, the descriptions can be made more informative if tuned using downstream tasks. This is often achieved by training two networks: a "speaker network" that generates sentences given an image, and a "listener network" that uses them to perform a task. Unfortunately, training multiple networks jointly to communicate to achieve a joint task, faces two major challenges. First, the descriptions generated by a speaker network are discrete and stochastic, making optimization very hard and inefficient. Second, joint training usually causes the vocabulary used during communication to drift and diverge from natural language. We describe an approach that addresses both challenges. We first develop a new effective optimization based on partial-sampling from a multinomial distribution combined with straight-through gradient updates, which we name PSST for Partial-Sampling Straight-Through. Second, we show that the generated descriptions can be kept close to natural by constraining them to be similar to human descriptions. Together, this approach creates descriptions that are both more discriminative and more natural than previous approaches. Evaluations on the standard COCO benchmark show that PSST Multinomial dramatically improve the recall@10 from 60% to 86% maintaining comparable language naturalness, and human evaluations show that it also increases naturalness while keeping the discriminative power of generated captions.