 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HAL: Improved Text-Image Matching by Mitigating Visual Semantic Hubs
Nov 22, 2019
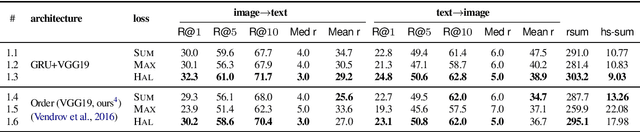
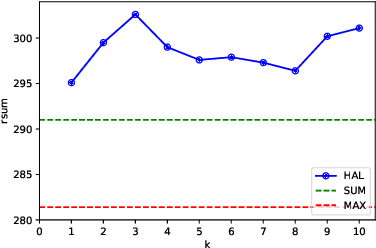
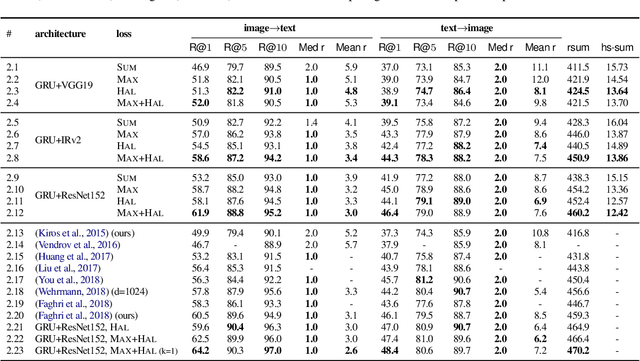
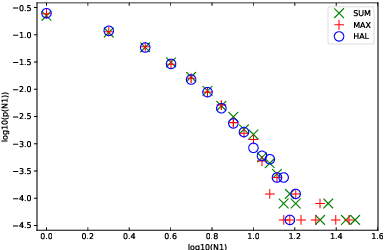
The hubness problem widely exists in high-dimensional embedding space and is a fundamental source of error for cross-modal matching tasks. In this work, we study the emergence of hubs in Visual Semantic Embeddings (VSE) with application to text-image matching. We analyze the pros and cons of two widely adopted optimization objectives for training VSE and propose a novel hubness-aware loss function (HAL) that addresses previous methods' defects. Unlike (Faghri et al.2018) which simply takes the hardest sample within a mini-batch, HAL takes all samples into account, using both local and global statistics to scale up the weights of "hubs". We experiment our method with various configurations of model architectures and datasets. The method exhibits exceptionally good robustness and brings consistent improvement on the task of text-image matching across all settings. Specifically, under the same model architectures as (Faghri et al. 2018) and (Lee at al. 2018), by switching only the learning objective, we report a maximum R@1improvement of 7.4% on MS-COCO and 8.3% on Flickr30k.
Axial-to-lateral super-resolution for 3D fluorescence microscopy using unsupervised deep learning
Apr 19, 2021
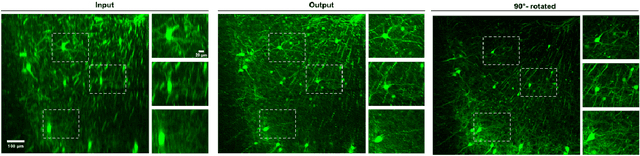
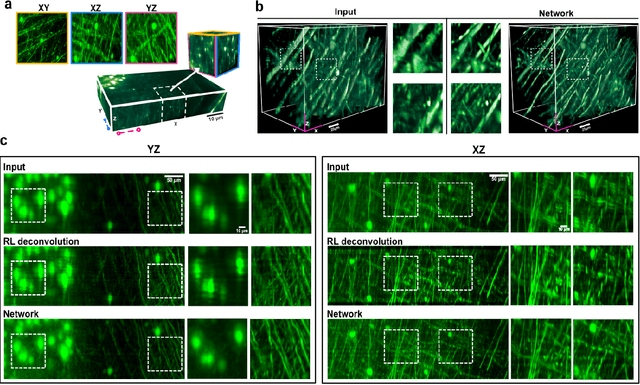
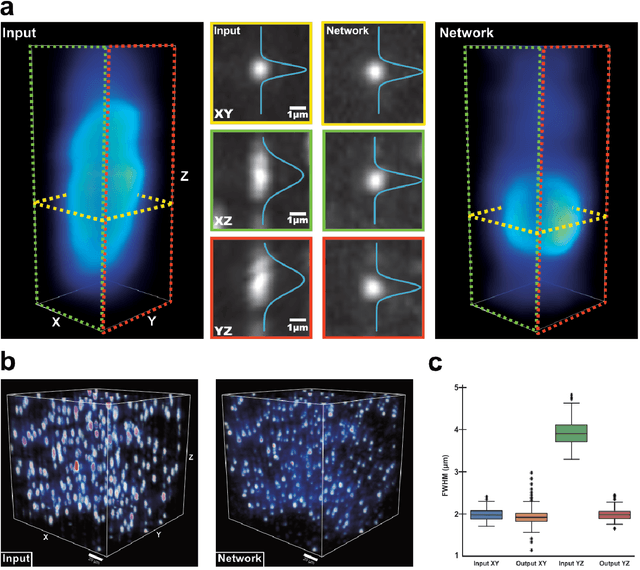
Volumetric imaging by fluorescence microscopy is often limited by anisotropic spatial resolution from inferior axial resolution compared to the lateral resolution. To address this problem, here we present a deep-learning-enabled unsupervised super-resolution technique that enhances anisotropic images in volumetric fluorescence microscopy. In contrast to the existing deep learning approaches that require matched high-resolution target volume images, our method greatly reduces the effort to put into practice as the training of a network requires as little as a single 3D image stack, without a priori knowledge of the image formation process, registration of training data, or separate acquisition of target data. This is achieved based on the optimal transport driven cycle-consistent generative adversarial network that learns from an unpaired matching between high-resolution 2D images in lateral image plane and low-resolution 2D images in the other planes. Using fluorescence confocal microscopy and light-sheet microscopy, we demonstrate that the trained network not only enhances axial resolution beyond the diffraction limit, but also enhances suppressed visual details between the imaging planes and removes imaging artifacts.
Interpretable and Generalizable Deep Image Matching with Adaptive Convolutions
Apr 23, 2019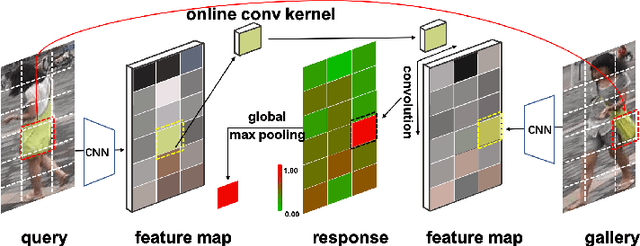
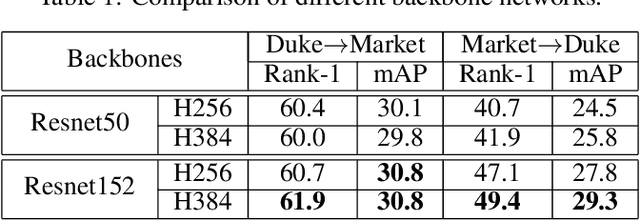

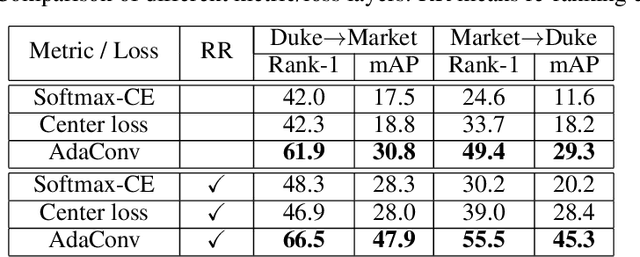
For image matching tasks, like face recognition and person re-identification, existing deep networks often focus on representation learning. However, without domain adaptation or transfer learning, the learned model is fixed as is, which is not adaptable to handle various unseen scenarios. In this paper, beyond representation learning, we consider how to formulate image matching directly in deep feature maps. We treat image matching as finding local correspondences in feature maps, and construct adaptive convolution kernels on the fly to achieve local matching. In this way, the matching process and result is interpretable, and this explicit matching is more generalizable than representation features to unseen scenarios, such as unknown misalignments, pose or viewpoint changes. To facilitate end-to-end training of such an image matching architecture, we further build a class memory module to cache feature maps of the most recent samples of each class, so as to compute image matching losses for metric learning. The proposed method is preliminarily validated on the person re-identification task. Through direct cross-dataset evaluation without further transfer learning, it achieves better results than many transfer learning methods. Besides, a model-free temporal cooccurrence based score weighting method is proposed, which improves the performance to a further extent, resulting in state-of-the-art results in cross-dataset evaluation.
DetCo: Unsupervised Contrastive Learning for Object Detection
Feb 09, 2021
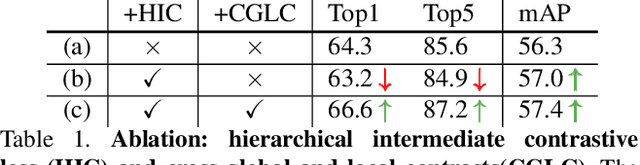
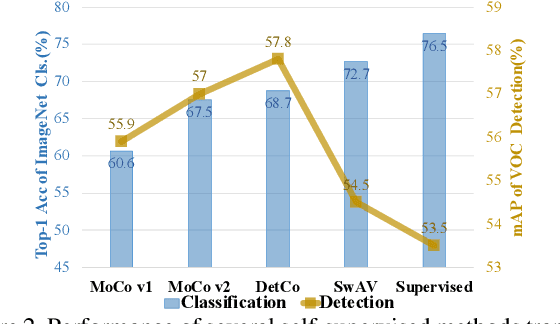
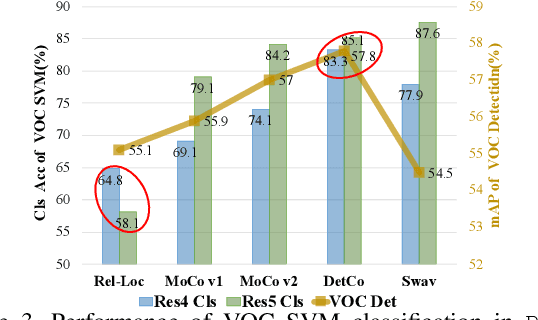
Unsupervised contrastive learning achieves great success in learning image representations with CNN. Unlike most recent methods that focused on improving accuracy of image classification, we present a novel contrastive learning approach, named DetCo, which fully explores the contrasts between global image and local image patches to learn discriminative representations for object detection. DetCo has several appealing benefits. (1) It is carefully designed by investigating the weaknesses of current self-supervised methods, which discard important representations for object detection. (2) DetCo builds hierarchical intermediate contrastive losses between global image and local patches to improve object detection, while maintaining global representations for image recognition. Theoretical analysis shows that the local patches actually remove the contextual information of an image, improving the lower bound of mutual information for better contrastive learning. (3) Extensive experiments on PASCAL VOC, COCO and Cityscapes demonstrate that DetCo not only outperforms state-of-the-art methods on object detection, but also on segmentation, pose estimation, and 3D shape prediction, while it is still competitive on image classification. For example, on PASCAL VOC, DetCo-100ep achieves 57.4 mAP, which is on par with the result of MoCov2-800ep. Moreover, DetCo consistently outperforms supervised method by 1.6/1.2/1.0 AP on Mask RCNN-C4/FPN/RetinaNet with 1x schedule. Code will be released at \href{https://github.com/xieenze/DetCo}{\color{blue}{\tt github.com/xieenze/DetCo}} and \href{https://github.com/open-mmlab/OpenSelfSup}{\color{blue}{\tt github.com/open-mmlab/OpenSelfSup}}.
Instagram Filter Removal on Fashionable Images
Apr 11, 2021
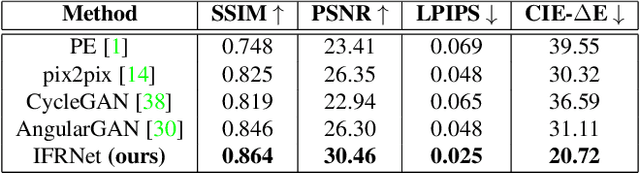

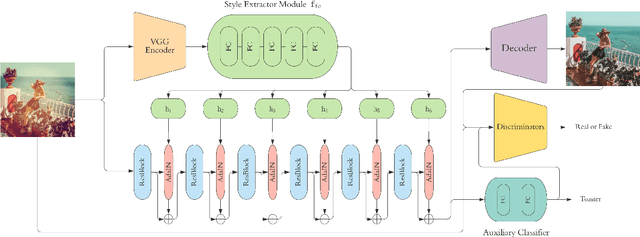
Social media images are generally transformed by filtering to obtain aesthetically more pleasing appearances. However, CNNs generally fail to interpret both the image and its filtered version as the same in the visual analysis of social media images. We introduce Instagram Filter Removal Network (IFRNet) to mitigate the effects of image filters for social media analysis applications. To achieve this, we assume any filter applied to an image substantially injects a piece of additional style information to it, and we consider this problem as a reverse style transfer problem. The visual effects of filtering can be directly removed by adaptively normalizing external style information in each level of the encoder. Experiments demonstrate that IFRNet outperforms all compared methods in quantitative and qualitative comparisons, and has the ability to remove the visual effects to a great extent. Additionally, we present the filter classification performance of our proposed model, and analyze the dominant color estimation on the images unfiltered by all compared methods.
Self-supervised Monocular Multi-robot Relative Localization with Efficient Deep Neural Networks
May 26, 2021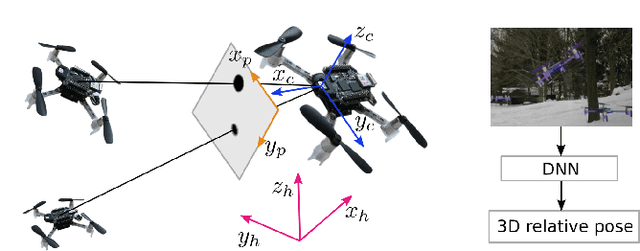
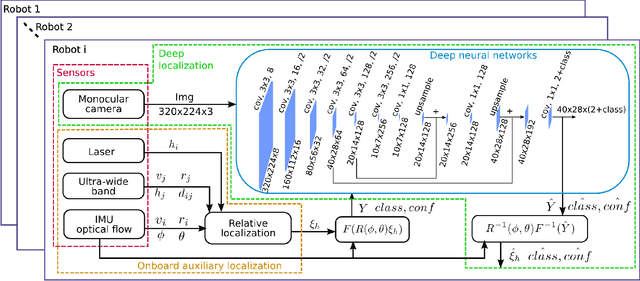
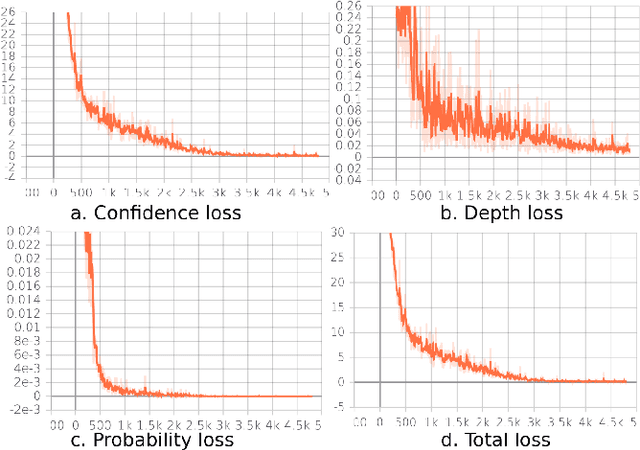

Relative localization is an important ability for multiple robots to perform cooperative tasks. This paper presents a deep neural network (DNN) for monocular relative localization between multiple tiny flying robots. This approach does not require any ground-truth data from external systems or manual labeling. Our system is able to label real-world images with 3D relative positions between robots by another onboard relative estimation technology. After the training from scratch in this self-supervised way, the DNN can predict the relative positions of peer robots by purely using the monocular image. This deep-learning based visual relative localization is scalable, distributed and autonomous. Simulation shows the pipeline for synthetic image generation for multiple robots with Blender and 3D rendering, which allows for preliminary validation of the designed network. Experiments are conducted on two Crazyflie quadrotors for dataset collection with random attitude and velocity. Training and testing of the proposed network on these real-world datasets further validate the self-supervised localization effectiveness in real environment.
Spatial Transformer Networks for Curriculum Learning
Aug 22, 2021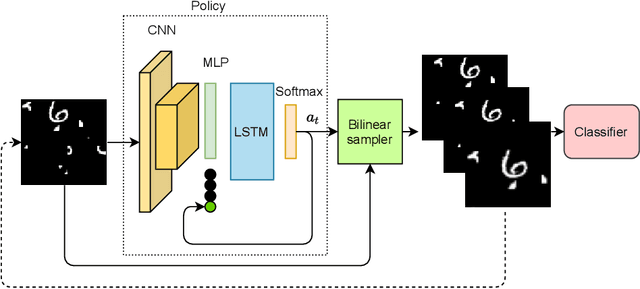



Curriculum learning is a bio-inspired training technique that is widely adopted to machine learning for improved optimization and better training of neural networks regarding the convergence rate or obtained accuracy. The main concept in curriculum learning is to start the training with simpler tasks and gradually increase the level of difficulty. Therefore, a natural question is how to determine or generate these simpler tasks. In this work, we take inspiration from Spatial Transformer Networks (STNs) in order to form an easy-to-hard curriculum. As STNs have been proven to be capable of removing the clutter from the input images and obtaining higher accuracy in image classification tasks, we hypothesize that images processed by STNs can be seen as easier tasks and utilized in the interest of curriculum learning. To this end, we study multiple strategies developed for shaping the training curriculum, using the data generated by STNs. We perform various experiments on cluttered MNIST and Fashion-MNIST datasets, where on the former, we obtain an improvement of $3.8$pp in classification accuracy compared to the baseline.
DiaRet: A browser-based application for the grading of Diabetic Retinopathy with Integrated Gradients
Apr 11, 2021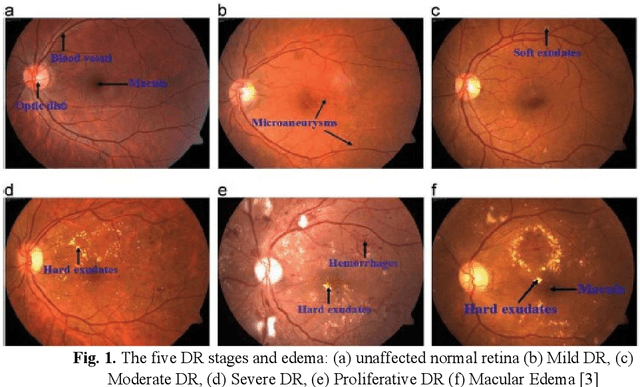



Patients with long-standing diabetes often fall prey to Diabetic Retinopathy (DR) resulting in changes in the retina of the human eye, which may lead to loss of vision in extreme cases. The aim of this study is two-fold: (a) create deep learning models that were trained to grade degraded retinal fundus images and (b) to create a browser-based application that will aid in diagnostic procedures by highlighting the key features of the fundus image. In this research work, we have emulated the images plagued by distortions by degrading the images based on multiple different combinations of Light Transmission Disturbance, Image Blurring and insertion of Retinal Artifacts. InceptionV3, ResNet-50 and InceptionResNetV2 were trained and used to classify retinal fundus images based on their severity level and then further used in the creation of a browser-based application, which implements the Integration Gradient (IG) Attribution Mask on the input image and demonstrates the predictions made by the model and the probability associated with each class.
Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey
May 26, 2021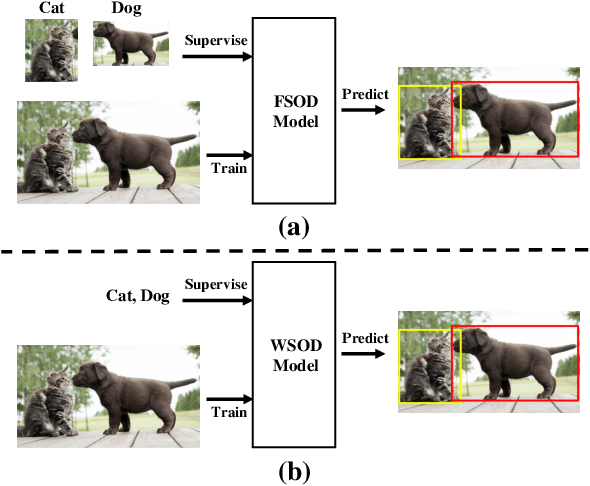
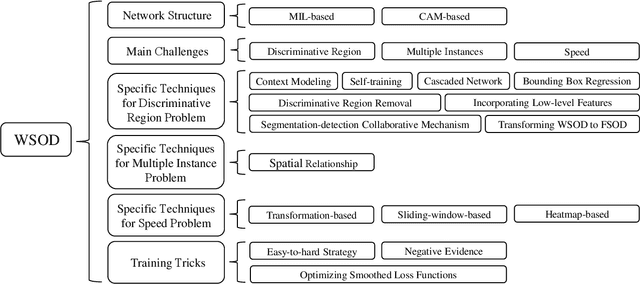

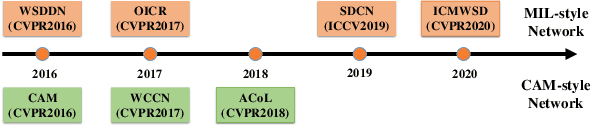
Weakly-Supervised Object Detection (WSOD) and Localization (WSOL), i.e., detecting multiple and single instances with bounding boxes in an image using image-level labels, are long-standing and challenging tasks in the CV community. With the success of deep neural networks in object detection, both WSOD and WSOL have received unprecedented attention. Hundreds of WSOD and WSOL methods and numerous techniques have been proposed in the deep learning era. To this end, in this paper, we consider WSOL is a sub-task of WSOD and provide a comprehensive survey of the recent achievements of WSOD. Specifically, we firstly describe the formulation and setting of the WSOD, including the background, challenges, basic framework. Meanwhile, we summarize and analyze all advanced techniques and training tricks for improving detection performance. Then, we introduce the widely-used datasets and evaluation metrics of WSOD. Lastly, we discuss the future directions of WSOD. We believe that these summaries can help pave a way for future research on WSOD and WSOL.
A Kinematic Bottleneck Approach For Pose Regression of Flexible Surgical Instruments directly from Images
Feb 28, 2021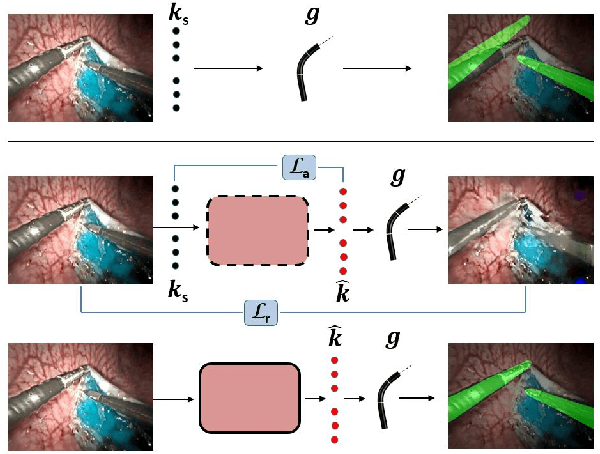
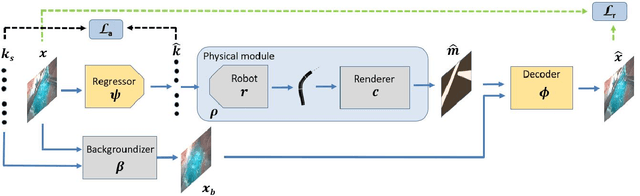
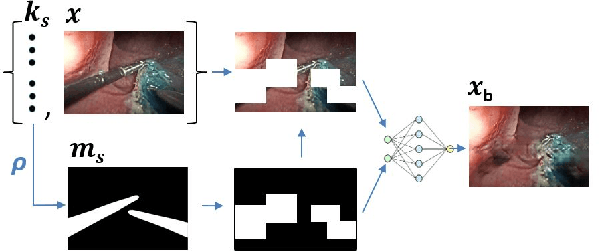
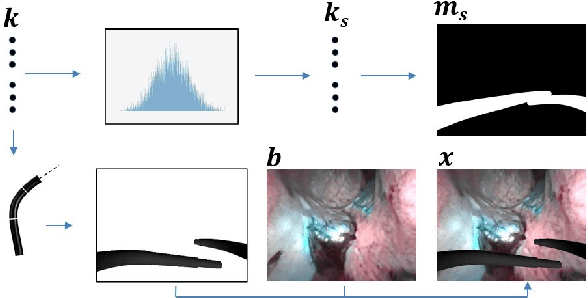
3-D pose estimation of instruments is a crucial step towards automatic scene understanding in robotic minimally invasive surgery. Although robotic systems can potentially directly provide joint values, this information is not commonly exploited inside the operating room, due to its possible unreliability, limited access and the time-consuming calibration required, especially for continuum robots. For this reason, standard approaches for 3-D pose estimation involve the use of external tracking systems. Recently, image-based methods have emerged as promising, non-invasive alternatives. While many image-based approaches in the literature have shown accurate results, they generally require either a complex iterative optimization for each processed image, making them unsuitable for real-time applications, or a large number of manually-annotated images for efficient learning. In this paper we propose a self-supervised image-based method, exploiting, at training time only, the imprecise kinematic information provided by the robot. In order to avoid introducing time-consuming manual annotations, the problem is formulated as an auto-encoder, smartly bottlenecked by the presence of a physical model of the robotic instruments and surgical camera, forcing a separation between image background and kinematic content. Validation of the method was performed on semi-synthetic, phantom and in-vivo datasets, obtained using a flexible robotized endoscope, showing promising results for real-time image-based 3-D pose estimation of surgical instruments.