 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual resemblance and communicative context constrain the emergence of graphical conventions
Sep 17, 2021
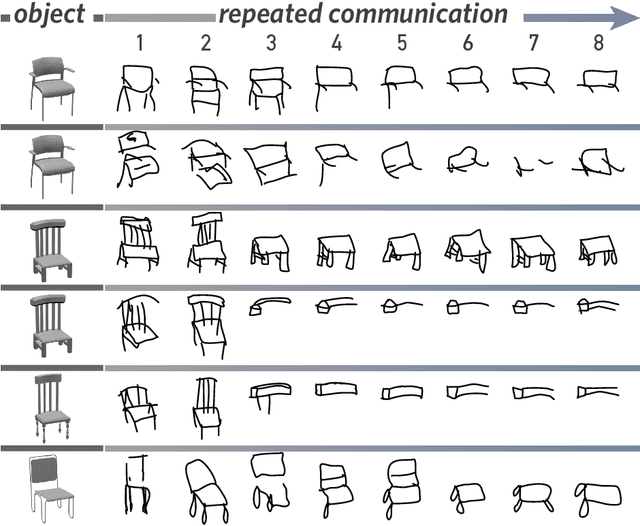
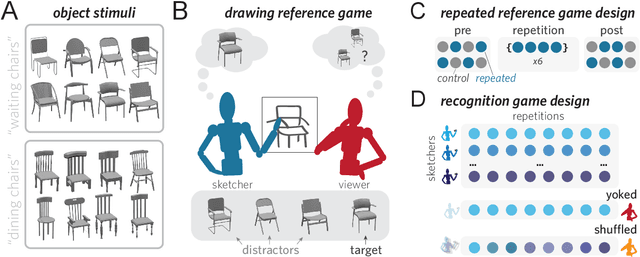
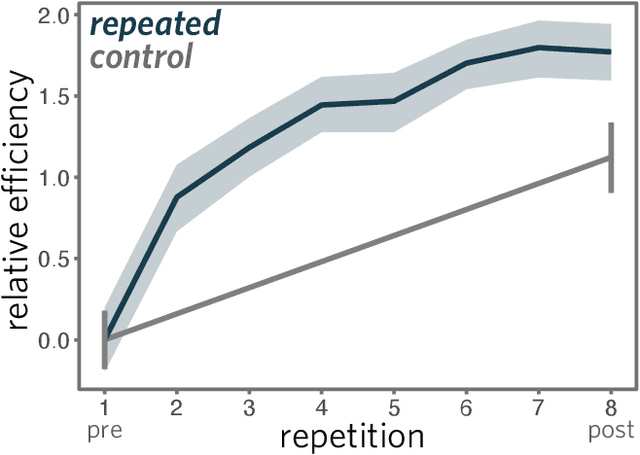
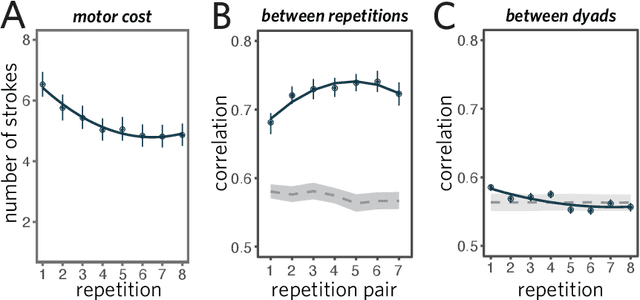
From photorealistic sketches to schematic diagrams, drawing provides a versatile medium for communicating about the visual world. How do images spanning such a broad range of appearances reliably convey meaning? Do viewers understand drawings based solely on their ability to resemble the entities they refer to (i.e., as images), or do they understand drawings based on shared but arbitrary associations with these entities (i.e., as symbols)? In this paper, we provide evidence for a cognitive account of pictorial meaning in which both visual and social information is integrated to support effective visual communication. To evaluate this account, we used a communication task where pairs of participants used drawings to repeatedly communicate the identity of a target object among multiple distractor objects. We manipulated social cues across three experiments and a full internal replication, finding pairs of participants develop referent-specific and interaction-specific strategies for communicating more efficiently over time, going beyond what could be explained by either task practice or a pure resemblance-based account alone. Using a combination of model-based image analyses and crowdsourced sketch annotations, we further determined that drawings did not drift toward arbitrariness, as predicted by a pure convention-based account, but systematically preserved those visual features that were most distinctive of the target object. Taken together, these findings advance theories of pictorial meaning and have implications for how successful graphical conventions emerge via complex interactions between visual perception, communicative experience, and social context.
Brain Image Synthesis with Unsupervised Multivariate Canonical CSC$\ell_4$Net
Mar 22, 2021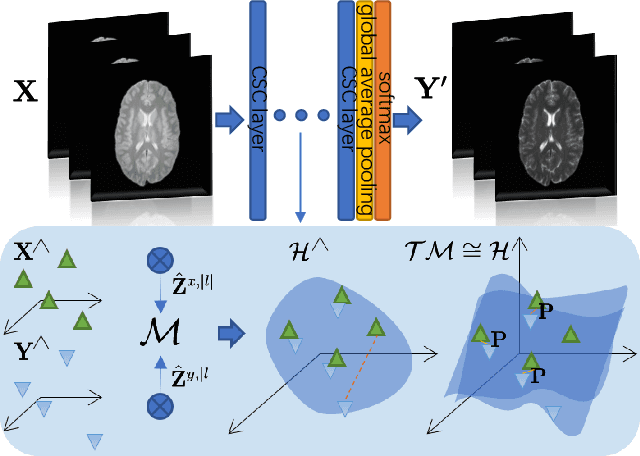
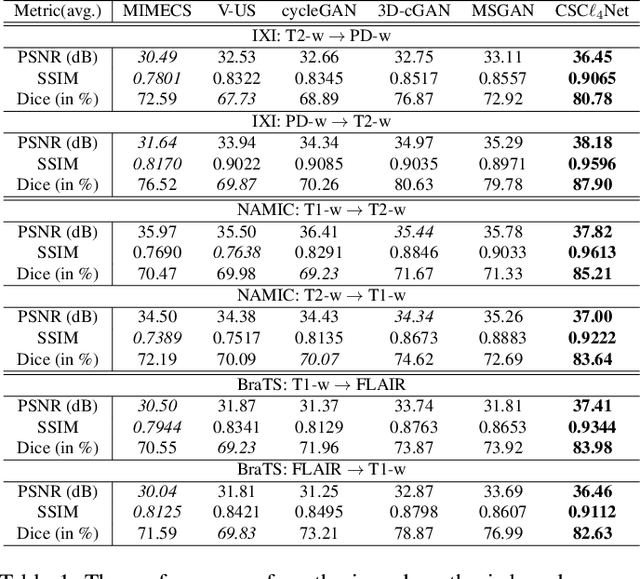
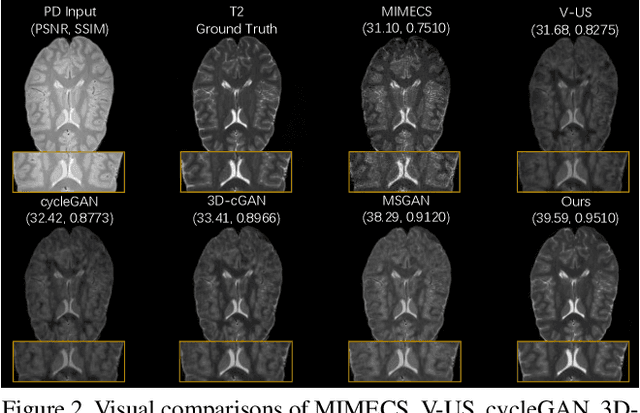
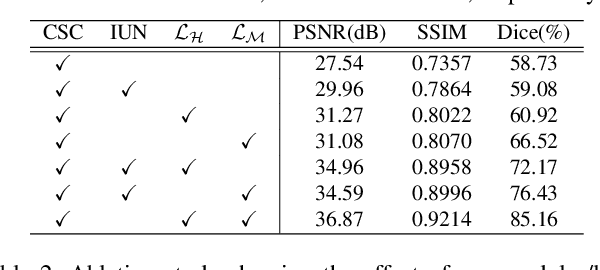
Recent advances in neuroscience have highlighted the effectiveness of multi-modal medical data for investigating certain pathologies and understanding human cognition. However, obtaining full sets of different modalities is limited by various factors, such as long acquisition times, high examination costs and artifact suppression. In addition, the complexity, high dimensionality and heterogeneity of neuroimaging data remains another key challenge in leveraging existing randomized scans effectively, as data of the same modality is often measured differently by different machines. There is a clear need to go beyond the traditional imaging-dependent process and synthesize anatomically specific target-modality data from a source input. In this paper, we propose to learn dedicated features that cross both intre- and intra-modal variations using a novel CSC$\ell_4$Net. Through an initial unification of intra-modal data in the feature maps and multivariate canonical adaptation, CSC$\ell_4$Net facilitates feature-level mutual transformation. The positive definite Riemannian manifold-penalized data fidelity term further enables CSC$\ell_4$Net to reconstruct missing measurements according to transformed features. Finally, the maximization $\ell_4$-norm boils down to a computationally efficient optimization problem. Extensive experiments validate the ability and robustness of our CSC$\ell_4$Net compared to the state-of-the-art methods on multiple datasets.
Rational Polynomial Camera Model Warping for Deep Learning Based Satellite Multi-View Stereo Matching
Sep 23, 2021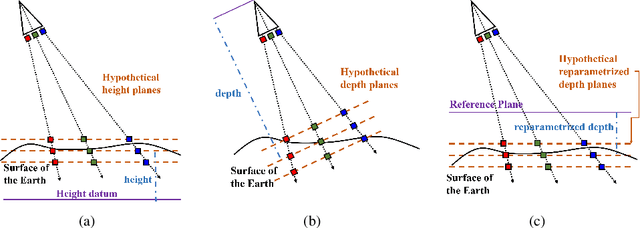

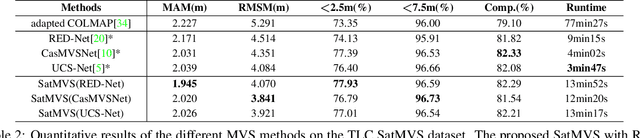
Satellite multi-view stereo (MVS) imagery is particularly suited for large-scale Earth surface reconstruction. Differing from the perspective camera model (pin-hole model) that is commonly used for close-range and aerial cameras, the cubic rational polynomial camera (RPC) model is the mainstream model for push-broom linear-array satellite cameras. However, the homography warping used in the prevailing learning based MVS methods is only applicable to pin-hole cameras. In order to apply the SOTA learning based MVS technology to the satellite MVS task for large-scale Earth surface reconstruction, RPC warping should be considered. In this work, we propose, for the first time, a rigorous RPC warping module. The rational polynomial coefficients are recorded as a tensor, and the RPC warping is formulated as a series of tensor transformations. Based on the RPC warping, we propose the deep learning based satellite MVS (SatMVS) framework for large-scale and wide depth range Earth surface reconstruction. We also introduce a large-scale satellite image dataset consisting of 519 5120${\times}$5120 images, which we call the TLC SatMVS dataset. The satellite images were acquired from a three-line camera (TLC) that catches triple-view images simultaneously, forming a valuable supplement to the existing open-source WorldView-3 datasets with single-scanline images. Experiments show that the proposed RPC warping module and the SatMVS framework can achieve a superior reconstruction accuracy compared to the pin-hole fitting method and conventional MVS methods. Code and data are available at https://github.com/WHU-GPCV/SatMVS.
Does Haze Removal Help CNN-based Image Classification?
Oct 12, 2018



Hazy images are common in real scenarios and many dehazing methods have been developed to automatically remove the haze from images. Typically, the goal of image dehazing is to produce clearer images from which human vision can better identify the object and structural details present in the images. When the ground-truth haze-free image is available for a hazy image, quantitative evaluation of image dehazing is usually based on objective metrics, such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM). However, in many applications, large-scale images are collected not for visual examination by human. Instead, they are used for many high-level vision tasks, such as automatic classification, recognition and categorization. One fundamental problem here is whether various dehazing methods can produce clearer images that can help improve the performance of the high-level tasks. In this paper, we empirically study this problem in the important task of image classification by using both synthetic and real hazy image datasets. From the experimental results, we find that the existing image-dehazing methods cannot improve much the image-classification performance and sometimes even reduce the image-classification performance.
Digging into Uncertainty in Self-supervised Multi-view Stereo
Aug 30, 2021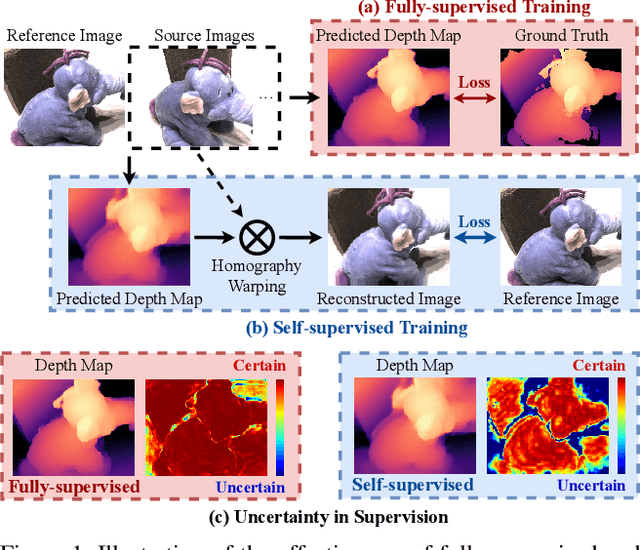
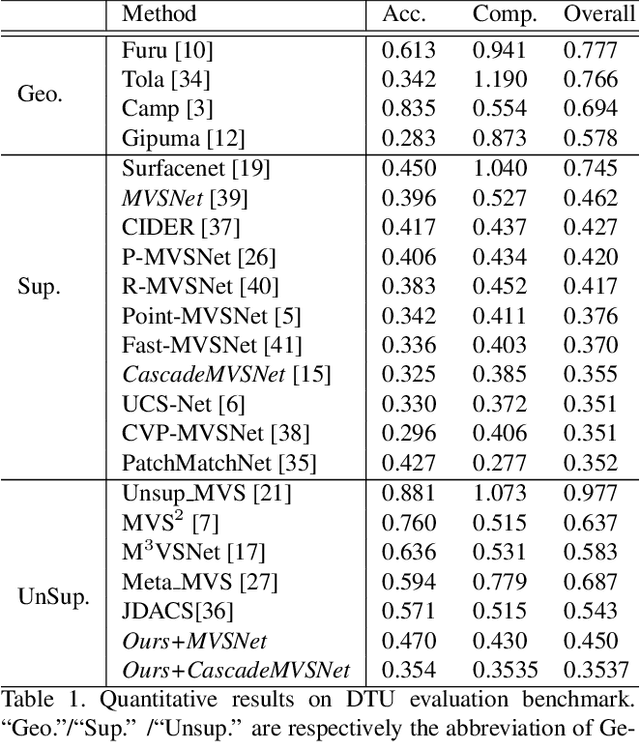
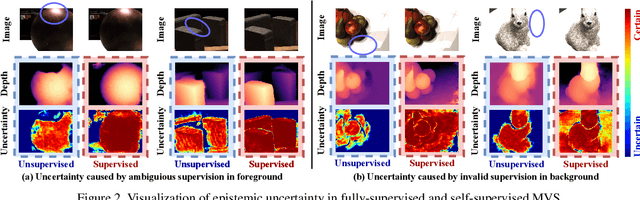
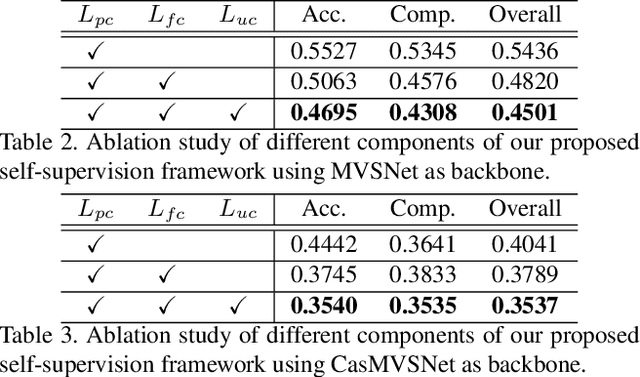
Self-supervised Multi-view stereo (MVS) with a pretext task of image reconstruction has achieved significant progress recently. However, previous methods are built upon intuitions, lacking comprehensive explanations about the effectiveness of the pretext task in self-supervised MVS. To this end, we propose to estimate epistemic uncertainty in self-supervised MVS, accounting for what the model ignores. Specially, the limitations can be categorized into two types: ambiguious supervision in foreground and invalid supervision in background. To address these issues, we propose a novel Uncertainty reduction Multi-view Stereo (UMVS) framework for self-supervised learning. To alleviate ambiguous supervision in foreground, we involve extra correspondence prior with a flow-depth consistency loss. The dense 2D correspondence of optical flows is used to regularize the 3D stereo correspondence in MVS. To handle the invalid supervision in background, we use Monte-Carlo Dropout to acquire the uncertainty map and further filter the unreliable supervision signals on invalid regions. Extensive experiments on DTU and Tank&Temples benchmark show that our U-MVS framework achieves the best performance among unsupervised MVS methods, with competitive performance with its supervised opponents.
Segmentation of Brain MRI using an Altruistic Harris Hawks' Optimization algorithm
Sep 17, 2021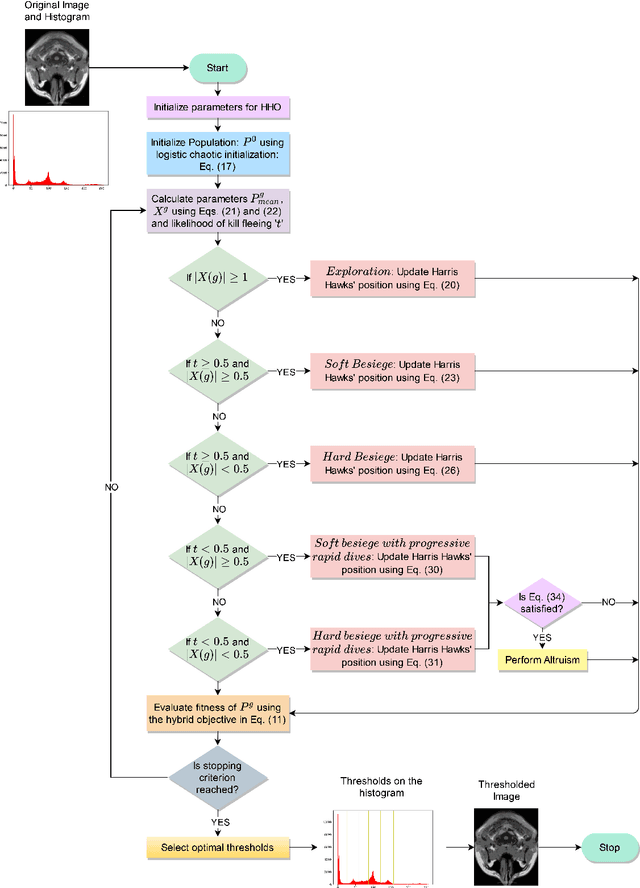
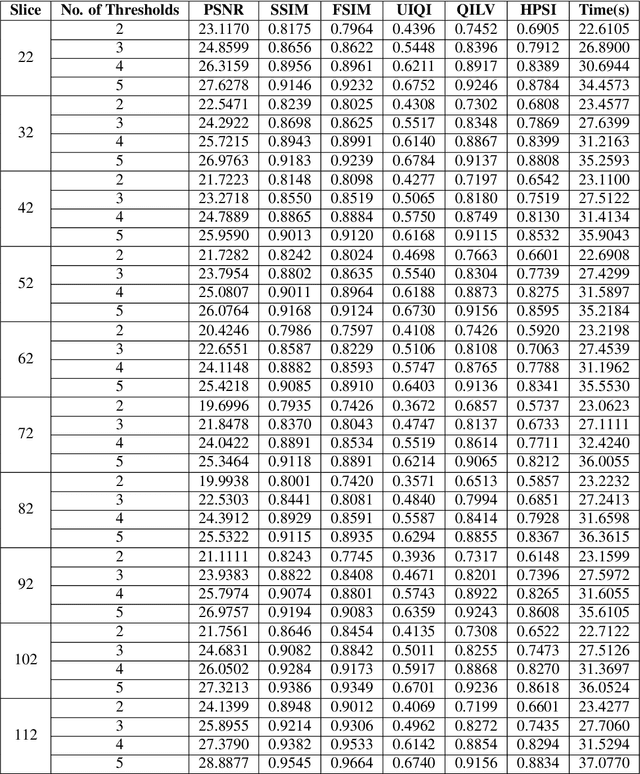
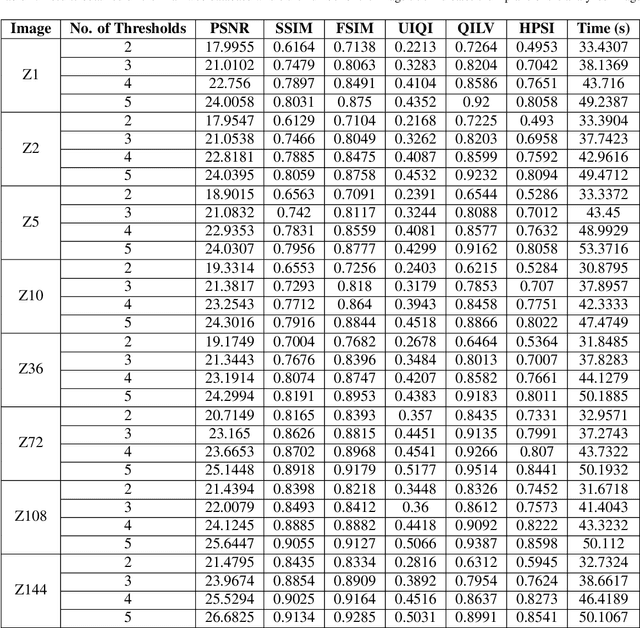
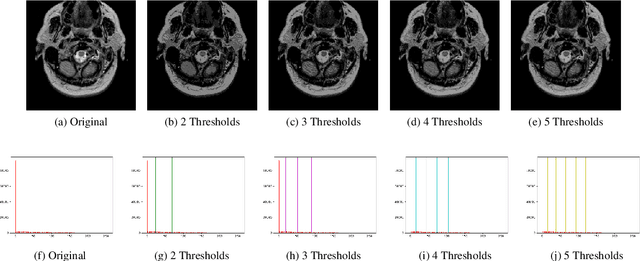
Segmentation is an essential requirement in medicine when digital images are used in illness diagnosis, especially, in posterior tasks as analysis and disease identification. An efficient segmentation of brain Magnetic Resonance Images (MRIs) is of prime concern to radiologists due to their poor illumination and other conditions related to de acquisition of the images. Thresholding is a popular method for segmentation that uses the histogram of an image to label different homogeneous groups of pixels into different classes. However, the computational cost increases exponentially according to the number of thresholds. In this paper, we perform the multi-level thresholding using an evolutionary metaheuristic. It is an improved version of the Harris Hawks Optimization (HHO) algorithm that combines the chaotic initialization and the concept of altruism. Further, for fitness assignment, we use a hybrid objective function where along with the cross-entropy minimization, we apply a new entropy function, and leverage weights to the two objective functions to form a new hybrid approach. The HHO was originally designed to solve numerical optimization problems. Earlier, the statistical results and comparisons have demonstrated that the HHO provides very promising results compared with well-established metaheuristic techniques. In this article, the altruism has been incorporated into the HHO algorithm to enhance its exploitation capabilities. We evaluate the proposed method over 10 benchmark images from the WBA database of the Harvard Medical School and 8 benchmark images from the Brainweb dataset using some standard evaluation metrics.
Shallow Encoder Deep Decoder (SEDD) Networks for Image Encryption and Decryption
Jan 09, 2020
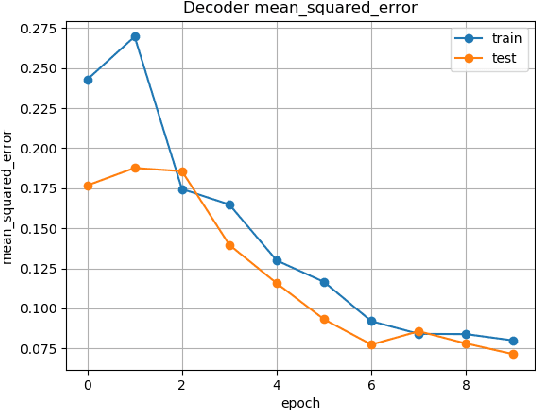

This paper explores a new framework for lossy image encryption and decryption using a simple shallow encoder neural network E for encryption, and a complex deep decoder neural network D for decryption. E is kept simple so that encoding can be done on low power and portable devices and can in principle be any nonlinear function which outputs an encoded vector. D is trained to decode the encodings using the dataset of image - encoded vector pairs obtained from E and happens independently of E. As the encodings come from E which while being a simple neural network, still has thousands of random parameters and therefore the encodings would be practically impossible to crack without D. This approach differs from autoencoders as D is trained completely independently of E, although the structure may seem similar. Therefore, this paper also explores empirically if a deep neural network can learn to reconstruct the original data in any useful form given the output of a neural network or any other nonlinear function, which can have very useful applications in Cryptanalysis. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the decoded images from D along with some limitations.
Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting
Apr 16, 2019
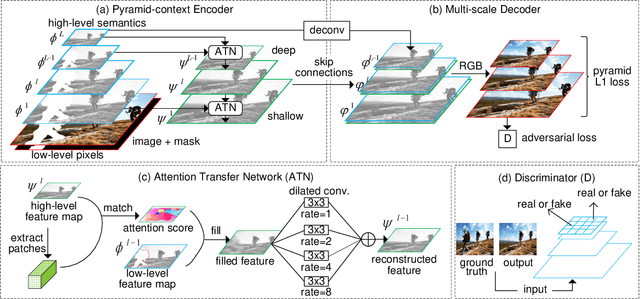

High-quality image inpainting requires filling missing regions in a damaged image with plausible content. Existing works either fill the regions by copying image patches or generating semantically-coherent patches from region context, while neglect the fact that both visual and semantic plausibility are highly-demanded. In this paper, we propose a Pyramid-context ENcoder Network (PEN-Net) for image inpainting by deep generative models. The PEN-Net is built upon a U-Net structure, which can restore an image by encoding contextual semantics from full resolution input, and decoding the learned semantic features back into images. Specifically, we propose a pyramid-context encoder, which progressively learns region affinity by attention from a high-level semantic feature map and transfers the learned attention to the previous low-level feature map. As the missing content can be filled by attention transfer from deep to shallow in a pyramid fashion, both visual and semantic coherence for image inpainting can be ensured. We further propose a multi-scale decoder with deeply-supervised pyramid losses and an adversarial loss. Such a design not only results in fast convergence in training, but more realistic results in testing. Extensive experiments on various datasets show the superior performance of the proposed network
Extreme Face Inpainting with Sketch-Guided Conditional GAN
May 13, 2021
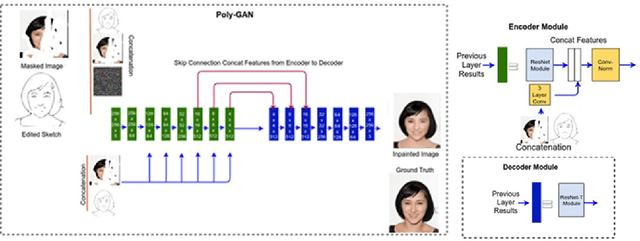
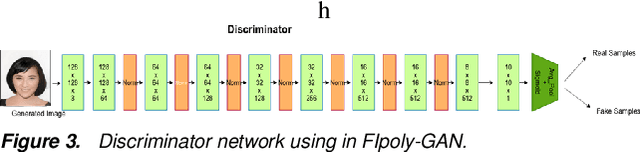

Recovering badly damaged face images is a useful yet challenging task, especially in extreme cases where the masked or damaged region is very large. One of the major challenges is the ability of the system to generalize on faces outside the training dataset. We propose to tackle this extreme inpainting task with a conditional Generative Adversarial Network (GAN) that utilizes structural information, such as edges, as a prior condition. Edge information can be obtained from the partially masked image and a structurally similar image or a hand drawing. In our proposed conditional GAN, we pass the conditional input in every layer of the encoder while maintaining consistency in the distributions between the learned weights and the incoming conditional input. We demonstrate the effectiveness of our method with badly damaged face examples.
Axial-to-lateral super-resolution for 3D fluorescence microscopy using unsupervised deep learning
Apr 19, 2021
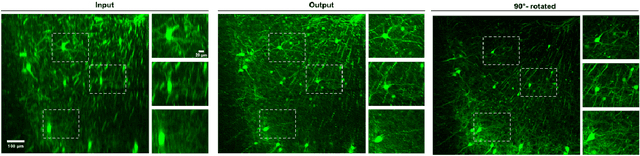
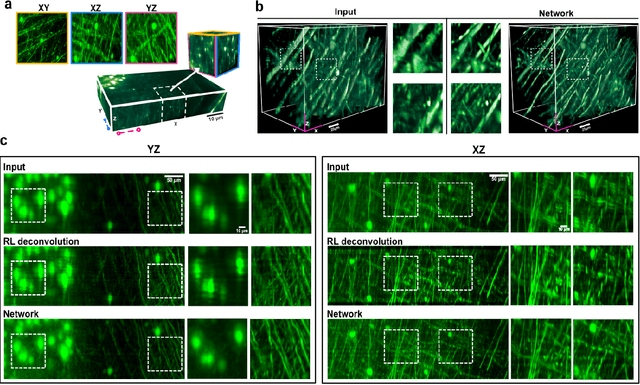
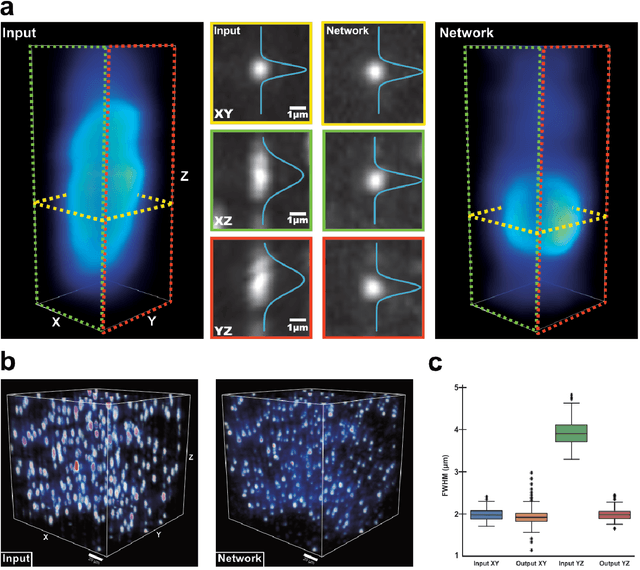
Volumetric imaging by fluorescence microscopy is often limited by anisotropic spatial resolution from inferior axial resolution compared to the lateral resolution. To address this problem, here we present a deep-learning-enabled unsupervised super-resolution technique that enhances anisotropic images in volumetric fluorescence microscopy. In contrast to the existing deep learning approaches that require matched high-resolution target volume images, our method greatly reduces the effort to put into practice as the training of a network requires as little as a single 3D image stack, without a priori knowledge of the image formation process, registration of training data, or separate acquisition of target data. This is achieved based on the optimal transport driven cycle-consistent generative adversarial network that learns from an unpaired matching between high-resolution 2D images in lateral image plane and low-resolution 2D images in the other planes. Using fluorescence confocal microscopy and light-sheet microscopy, we demonstrate that the trained network not only enhances axial resolution beyond the diffraction limit, but also enhances suppressed visual details between the imaging planes and removes imaging artifacts.