 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Salient Object Ranking with Position-Preserved Attention
Jun 10, 2021

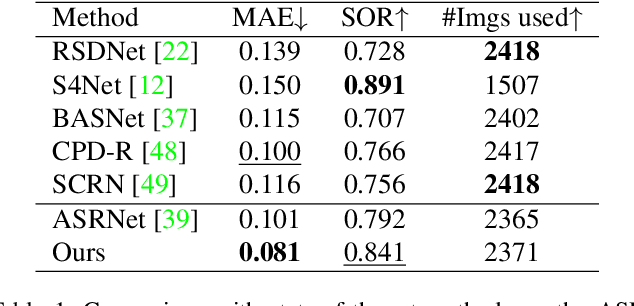
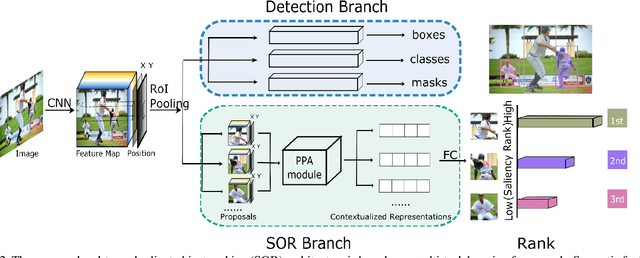
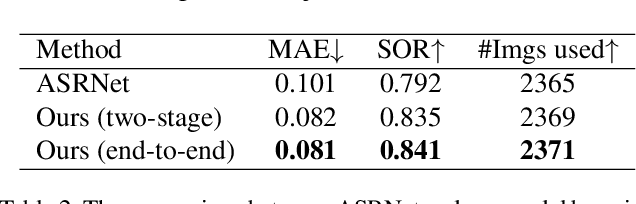
Instance segmentation can detect where the objects are in an image, but hard to understand the relationship between them. We pay attention to a typical relationship, relative saliency. A closely related task, salient object detection, predicts a binary map highlighting a visually salient region while hard to distinguish multiple objects. Directly combining two tasks by post-processing also leads to poor performance. There is a lack of research on relative saliency at present, limiting the practical applications such as content-aware image cropping, video summary, and image labeling. In this paper, we study the Salient Object Ranking (SOR) task, which manages to assign a ranking order of each detected object according to its visual saliency. We propose the first end-to-end framework of the SOR task and solve it in a multi-task learning fashion. The framework handles instance segmentation and salient object ranking simultaneously. In this framework, the SOR branch is independent and flexible to cooperate with different detection methods, so that easy to use as a plugin. We also introduce a Position-Preserved Attention (PPA) module tailored for the SOR branch. It consists of the position embedding stage and feature interaction stage. Considering the importance of position in saliency comparison, we preserve absolute coordinates of objects in ROI pooling operation and then fuse positional information with semantic features in the first stage. In the feature interaction stage, we apply the attention mechanism to obtain proposals' contextualized representations to predict their relative ranking orders. Extensive experiments have been conducted on the ASR dataset. Without bells and whistles, our proposed method outperforms the former state-of-the-art method significantly. The code will be released publicly available.
Neural Representation Learning for Scribal Hands of Linear B
Jul 14, 2021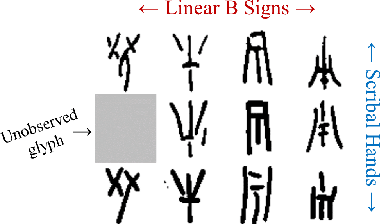
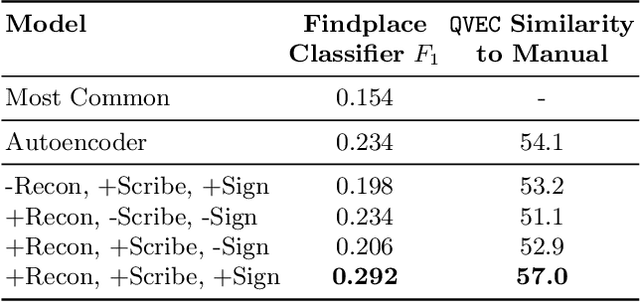
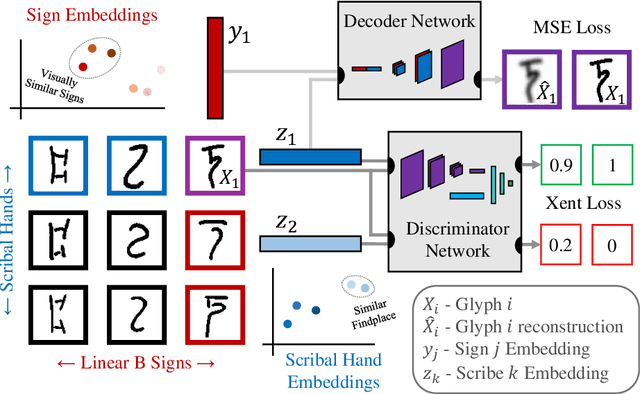
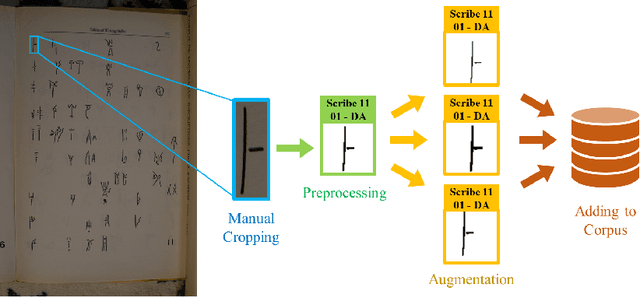
In this work, we present an investigation into the use of neural feature extraction in performing scribal hand analysis of the Linear B writing system. While prior work has demonstrated the usefulness of strategies such as phylogenetic systematics in tracing Linear B's history, these approaches have relied on manually extracted features which can be very time consuming to define by hand. Instead we propose learning features using a fully unsupervised neural network that does not require any human annotation. Specifically our model assigns each glyph written by the same scribal hand a shared vector embedding to represent that author's stylistic patterns, and each glyph representing the same syllabic sign a shared vector embedding to represent the identifying shape of that character. Thus the properties of each image in our dataset are represented as the combination of a scribe embedding and a sign embedding. We train this model using both a reconstructive loss governed by a decoder that seeks to reproduce glyphs from their corresponding embeddings, and a discriminative loss which measures the model's ability to predict whether or not an embedding corresponds to a given image. Among the key contributions of this work we (1) present a new dataset of Linear B glyphs, annotated by scribal hand and sign type, (2) propose a neural model for disentangling properties of scribal hands from glyph shape, and (3) quantitatively evaluate the learned embeddings on findplace prediction and similarity to manually extracted features, showing improvements over simpler baseline methods.
Multiview Hessian Regularization for Image Annotation
Apr 23, 2019
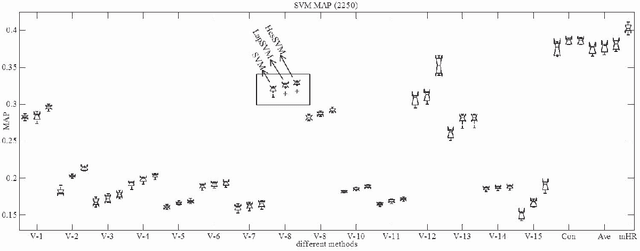
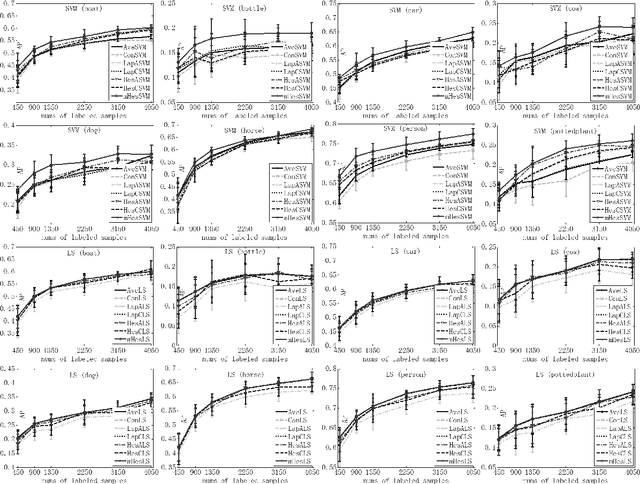
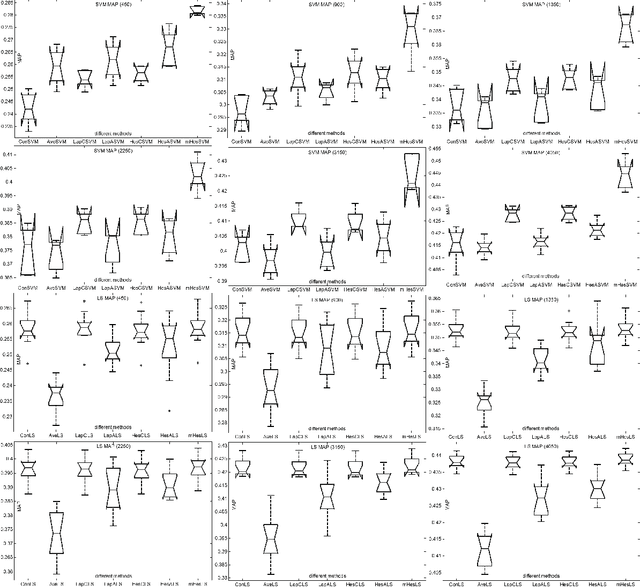
The rapid development of computer hardware and Internet technology makes large scale data dependent models computationally tractable, and opens a bright avenue for annotating images through innovative machine learning algorithms. Semi-supervised learning (SSL) has consequently received intensive attention in recent years and has been successfully deployed in image annotation. One representative work in SSL is Laplacian regularization (LR), which smoothes the conditional distribution for classification along the manifold encoded in the graph Laplacian, however, it has been observed that LR biases the classification function towards a constant function which possibly results in poor generalization. In addition, LR is developed to handle uniformly distributed data (or single view data), although instances or objects, such as images and videos, are usually represented by multiview features, such as color, shape and texture. In this paper, we present multiview Hessian regularization (mHR) to address the above two problems in LR-based image annotation. In particular, mHR optimally combines multiple Hessian regularizations, each of which is obtained from a particular view of instances, and steers the classification function which varies linearly along the data manifold. We apply mHR to kernel least squares and support vector machines as two examples for image annotation. Extensive experiments on the PASCAL VOC'07 dataset validate the effectiveness of mHR by comparing it with baseline algorithms, including LR and HR.
Imperceptible Adversarial Examples by Spatial Chroma-Shift
Sep 02, 2021
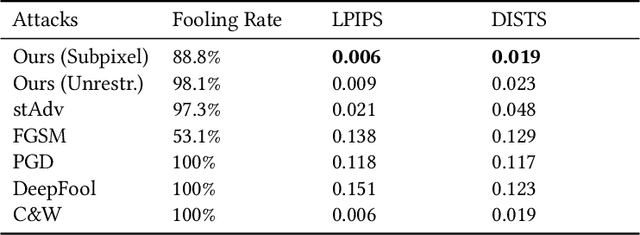

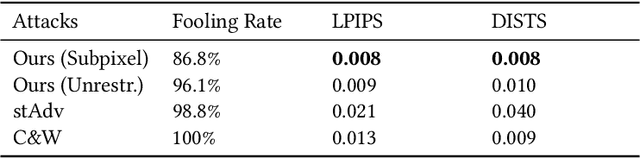
Deep Neural Networks have been shown to be vulnerable to various kinds of adversarial perturbations. In addition to widely studied additive noise based perturbations, adversarial examples can also be created by applying a per pixel spatial drift on input images. While spatial transformation based adversarial examples look more natural to human observers due to absence of additive noise, they still possess visible distortions caused by spatial transformations. Since the human vision is more sensitive to the distortions in the luminance compared to those in chrominance channels, which is one of the main ideas behind the lossy visual multimedia compression standards, we propose a spatial transformation based perturbation method to create adversarial examples by only modifying the color components of an input image. While having competitive fooling rates on CIFAR-10 and NIPS2017 Adversarial Learning Challenge datasets, examples created with the proposed method have better scores with regards to various perceptual quality metrics. Human visual perception studies validate that the examples are more natural looking and often indistinguishable from their original counterparts.
Person Search Challenges and Solutions: A Survey
May 01, 2021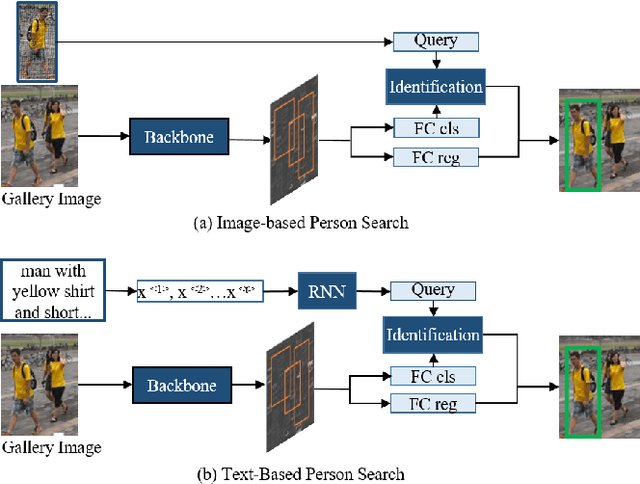
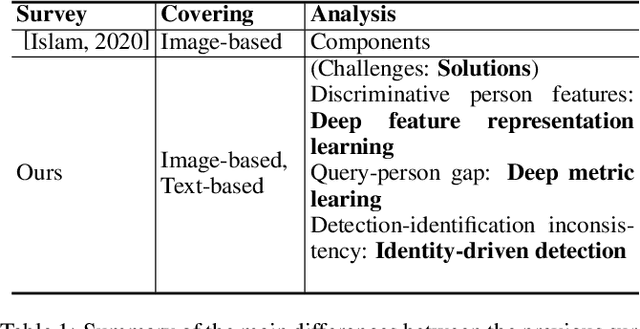


Person search has drawn increasing attention due to its real-world applications and research significance. Person search aims to find a probe person in a gallery of scene images with a wide range of applications, such as criminals search, multicamera tracking, missing person search, etc. Early person search works focused on image-based person search, which uses person image as the search query. Text-based person search is another major person search category that uses free-form natural language as the search query. Person search is challenging, and corresponding solutions are diverse and complex. Therefore, systematic surveys on this topic are essential. This paper surveyed the recent works on image-based and text-based person search from the perspective of challenges and solutions. Specifically, we provide a brief analysis of highly influential person search methods considering the three significant challenges: the discriminative person features, the query-person gap, and the detection-identification inconsistency. We summarise and compare evaluation results. Finally, we discuss open issues and some promising future research directions.
EDDA: Explanation-driven Data Augmentation to Improve Model and Explanation Alignment
May 29, 2021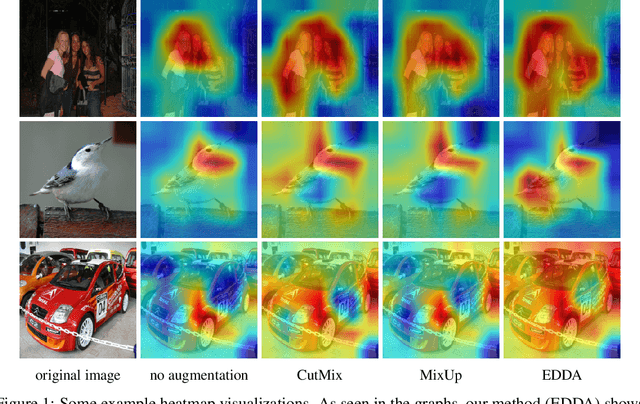
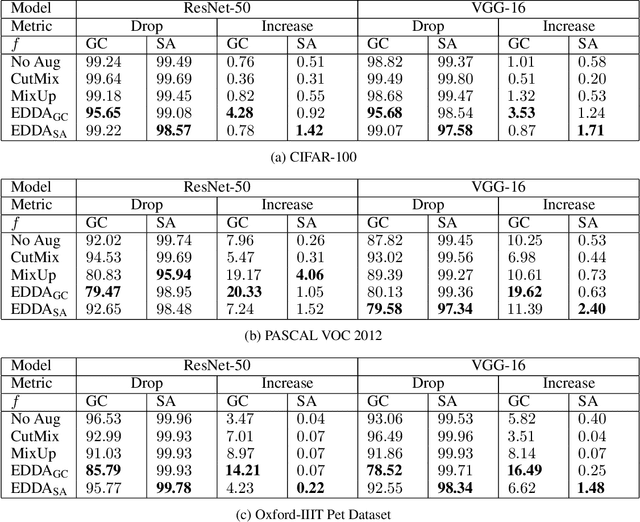
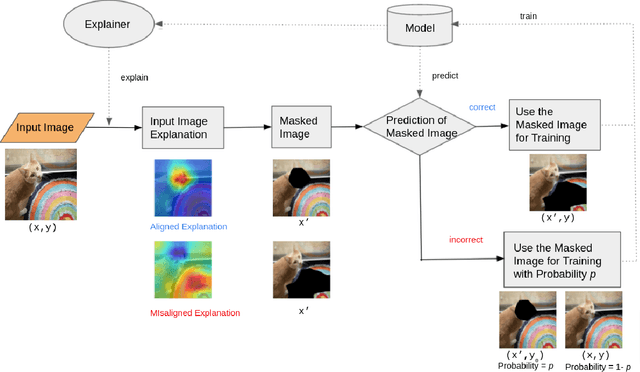
Recent years have seen the introduction of a range of methods for post-hoc explainability of image classifier predictions. However, these post-hoc explanations may not always align perfectly with classifier predictions, which poses a significant challenge when attempting to debug models based on such explanations. To this end, we seek a methodology that can improve alignment between model predictions and explanation method that is both agnostic to the model and explanation classes and which does not require ground truth explanations. We achieve this through a novel explanation-driven data augmentation (EDDA) method that augments the training data with occlusions of existing data stemming from model-explanations; this is based on the simple motivating principle that occluding salient regions for the model prediction should decrease the model confidence in the prediction, while occluding non-salient regions should not change the prediction -- if the model and explainer are aligned. To verify that this augmentation method improves model and explainer alignment, we evaluate the methodology on a variety of datasets, image classification models, and explanation methods. We verify in all cases that our explanation-driven data augmentation method improves alignment of the model and explanation in comparison to no data augmentation and non-explanation driven data augmentation methods. In conclusion, this approach provides a novel model- and explainer-agnostic methodology for improving alignment between model predictions and explanations, which we see as a critical step forward for practical deployment and debugging of image classification models.
Spectral Distribution aware Image Generation
Dec 05, 2020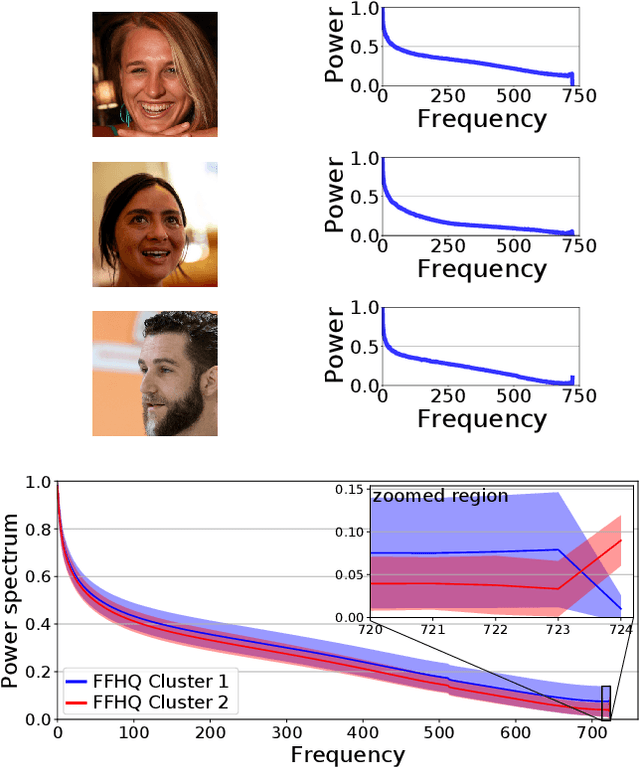
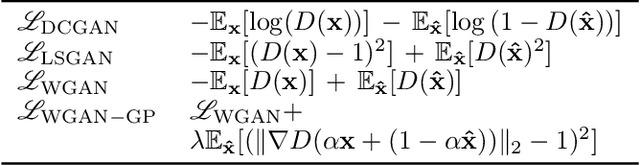
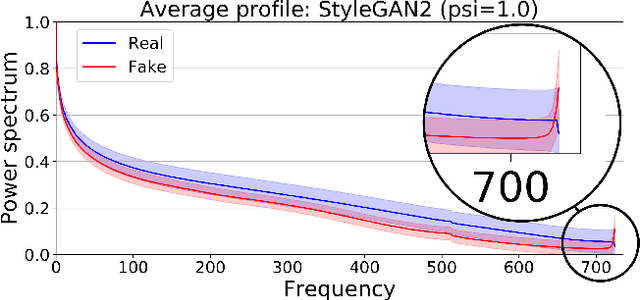
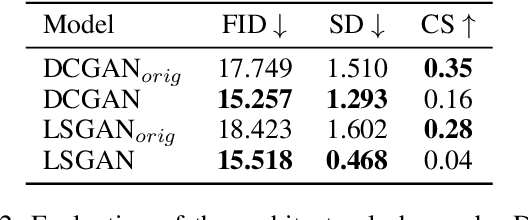
Recent advances in deep generative models for photo-realistic images have led to high quality visual results. Such models learn to generate data from a given training distribution such that generated images can not be easily distinguished from real images by the human eye. Yet, recent work on the detection of such fake images pointed out that they are actually easily distinguishable by artifacts in their frequency spectra. In this paper, we propose to generate images according to the frequency distribution of the real data by employing a spectral discriminator. The proposed discriminator is lightweight, modular and works stably with different commonly used GAN losses. We show that the resulting models can better generate images with realistic frequency spectra, which are thus harder to detect by this cue.
Invertable Frowns: Video-to-Video Facial Emotion Translation
Sep 16, 2021
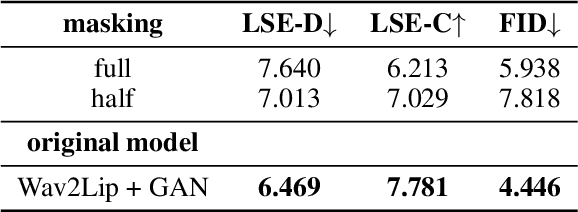

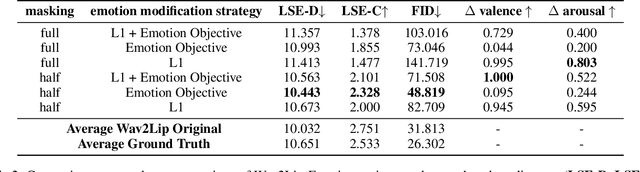
We present Wav2Lip-Emotion, a video-to-video translation architecture that modifies facial expressions of emotion in videos of speakers. Previous work modifies emotion in images, uses a single image to produce a video with animated emotion, or puppets facial expressions in videos with landmarks from a reference video. However, many use cases such as modifying an actor's performance in post-production, coaching individuals to be more animated speakers, or touching up emotion in a teleconference require a video-to-video translation approach. We explore a method to maintain speakers' lip movements, identity, and pose while translating their expressed emotion. Our approach extends an existing multi-modal lip synchronization architecture to modify the speaker's emotion using L1 reconstruction and pre-trained emotion objectives. We also propose a novel automated emotion evaluation approach and corroborate it with a user study. These find that we succeed in modifying emotion while maintaining lip synchronization. Visual quality is somewhat diminished, with a trade off between greater emotion modification and visual quality between model variants. Nevertheless, we demonstrate (1) that facial expressions of emotion can be modified with nothing other than L1 reconstruction and pre-trained emotion objectives and (2) that our automated emotion evaluation approach aligns with human judgements.
A Benchmark Comparison of Visual Place Recognition Techniques for Resource-Constrained Embedded Platforms
Sep 22, 2021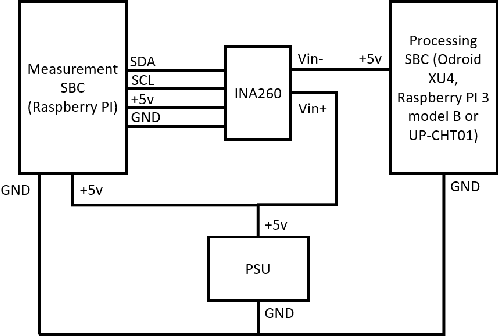
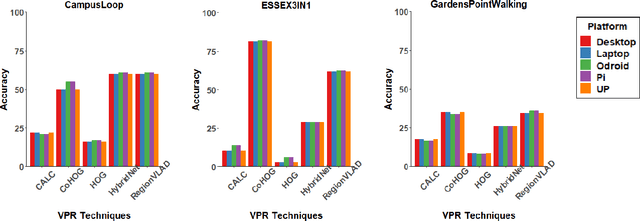
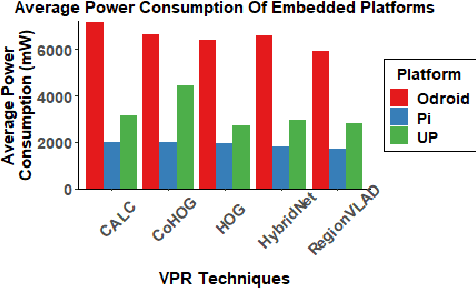
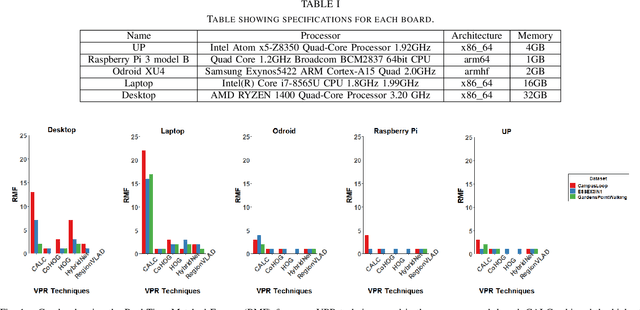
Visual Place Recognition (VPR) has been a subject of significant research over the last 15 to 20 years. VPR is a fundamental task for autonomous navigation as it enables self-localization within an environment. Although robots are often equipped with resource-constrained hardware, the computational requirements of and effects on VPR techniques have received little attention. In this work, we present a hardware-focused benchmark evaluation of a number of state-of-the-art VPR techniques on public datasets. We consider popular single board computers, including ODroid, UP and Raspberry Pi 3, in addition to a commodity desktop and laptop for reference. We present our analysis based on several key metrics, including place-matching accuracy, image encoding time, descriptor matching time and memory needs. Key questions addressed include: (1) How does the performance accuracy of a VPR technique change with processor architecture? (2) How does power consumption vary for different VPR techniques and embedded platforms? (3) How much does descriptor size matter in comparison to today's embedded platforms' storage? (4) How does the performance of a high-end platform relate to an on-board low-end embedded platform for VPR? The extensive analysis and results in this work serve not only as a benchmark for the VPR community, but also provide useful insights for real-world adoption of VPR applications.
Progressive Semantic Segmentation
Apr 08, 2021

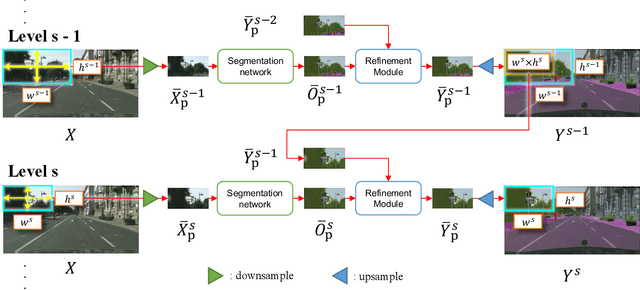
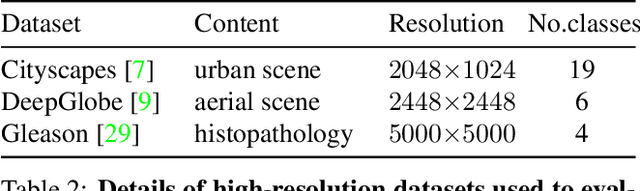
The objective of this work is to segment high-resolution images without overloading GPU memory usage or losing the fine details in the output segmentation map. The memory constraint means that we must either downsample the big image or divide the image into local patches for separate processing. However, the former approach would lose the fine details, while the latter can be ambiguous due to the lack of a global picture. In this work, we present MagNet, a multi-scale framework that resolves local ambiguity by looking at the image at multiple magnification levels. MagNet has multiple processing stages, where each stage corresponds to a magnification level, and the output of one stage is fed into the next stage for coarse-to-fine information propagation. Each stage analyzes the image at a higher resolution than the previous stage, recovering the previously lost details due to the lossy downsampling step, and the segmentation output is progressively refined through the processing stages. Experiments on three high-resolution datasets of urban views, aerial scenes, and medical images show that MagNet consistently outperforms the state-of-the-art methods by a significant margin.