 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting
Apr 16, 2019

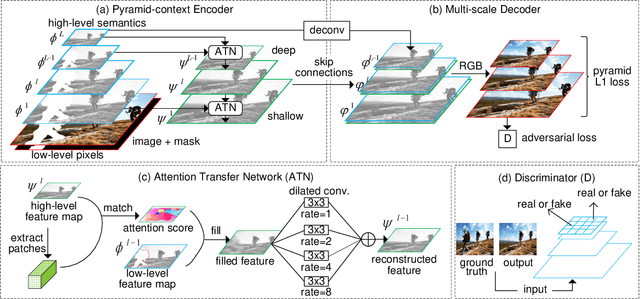

High-quality image inpainting requires filling missing regions in a damaged image with plausible content. Existing works either fill the regions by copying image patches or generating semantically-coherent patches from region context, while neglect the fact that both visual and semantic plausibility are highly-demanded. In this paper, we propose a Pyramid-context ENcoder Network (PEN-Net) for image inpainting by deep generative models. The PEN-Net is built upon a U-Net structure, which can restore an image by encoding contextual semantics from full resolution input, and decoding the learned semantic features back into images. Specifically, we propose a pyramid-context encoder, which progressively learns region affinity by attention from a high-level semantic feature map and transfers the learned attention to the previous low-level feature map. As the missing content can be filled by attention transfer from deep to shallow in a pyramid fashion, both visual and semantic coherence for image inpainting can be ensured. We further propose a multi-scale decoder with deeply-supervised pyramid losses and an adversarial loss. Such a design not only results in fast convergence in training, but more realistic results in testing. Extensive experiments on various datasets show the superior performance of the proposed network
Morphence: Moving Target Defense Against Adversarial Examples
Sep 02, 2021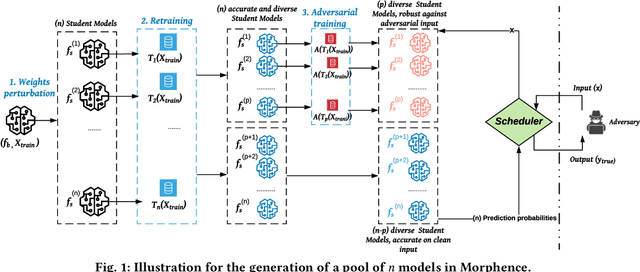
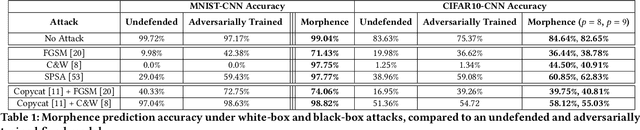
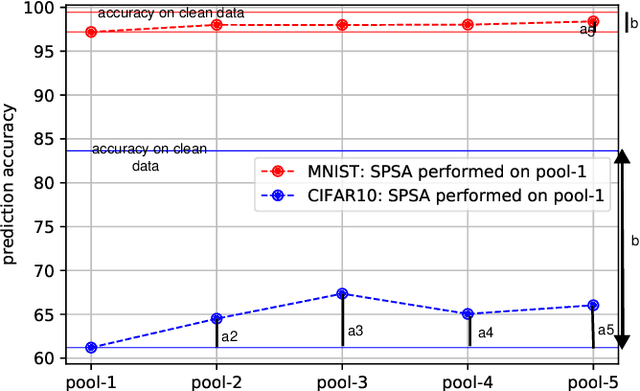
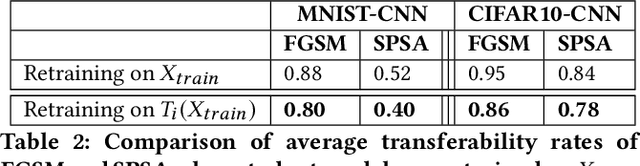
Robustness to adversarial examples of machine learning models remains an open topic of research. Attacks often succeed by repeatedly probing a fixed target model with adversarial examples purposely crafted to fool it. In this paper, we introduce Morphence, an approach that shifts the defense landscape by making a model a moving target against adversarial examples. By regularly moving the decision function of a model, Morphence makes it significantly challenging for repeated or correlated attacks to succeed. Morphence deploys a pool of models generated from a base model in a manner that introduces sufficient randomness when it responds to prediction queries. To ensure repeated or correlated attacks fail, the deployed pool of models automatically expires after a query budget is reached and the model pool is seamlessly replaced by a new model pool generated in advance. We evaluate Morphence on two benchmark image classification datasets (MNIST and CIFAR10) against five reference attacks (2 white-box and 3 black-box). In all cases, Morphence consistently outperforms the thus-far effective defense, adversarial training, even in the face of strong white-box attacks, while preserving accuracy on clean data.
A New Journey from SDRTV to HDRTV
Aug 18, 2021Nowadays modern displays are capable to render video content with high dynamic range (HDR) and wide color gamut (WCG). However, most available resources are still in standard dynamic range (SDR). Therefore, there is an urgent demand to transform existing SDR-TV contents into their HDR-TV versions. In this paper, we conduct an analysis of SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Base on the analysis, we propose a three-step solution pipeline including adaptive global color mapping, local enhancement and highlight generation. Moreover, the above analysis inspires us to present a lightweight network that utilizes global statistics as guidance to conduct image-adaptive color mapping. In addition, we construct a dataset using HDR videos in HDR10 standard, named HDRTV1K, and select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Furthermore, our final results achieve state-of-the-art performance in quantitative comparisons and visual quality. The code and dataset are available at https://github.com/chxy95/HDRTVNet.
Evidential Deep Learning for Open Set Action Recognition
Aug 18, 2021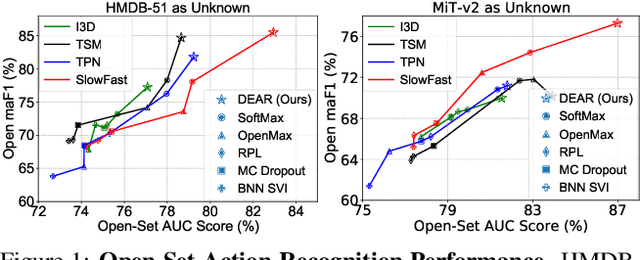
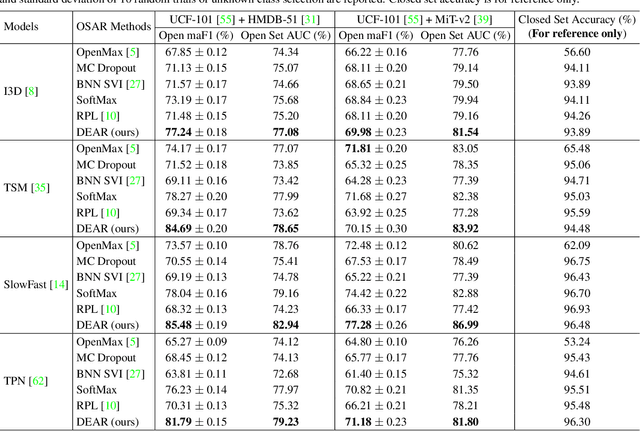

In a real-world scenario, human actions are typically out of the distribution from training data, which requires a model to both recognize the known actions and reject the unknown. Different from image data, video actions are more challenging to be recognized in an open-set setting due to the uncertain temporal dynamics and static bias of human actions. In this paper, we propose a Deep Evidential Action Recognition (DEAR) method to recognize actions in an open testing set. Specifically, we formulate the action recognition problem from the evidential deep learning (EDL) perspective and propose a novel model calibration method to regularize the EDL training. Besides, to mitigate the static bias of video representation, we propose a plug-and-play module to debias the learned representation through contrastive learning. Experimental results show that our DEAR method achieves consistent performance gain on multiple mainstream action recognition models and benchmarks. Code and pre-trained models are available at {\small{\url{https://www.rit.edu/actionlab/dear}}}.
Towards a Unified Approach to Single Image Deraining and Dehazing
Mar 26, 2021
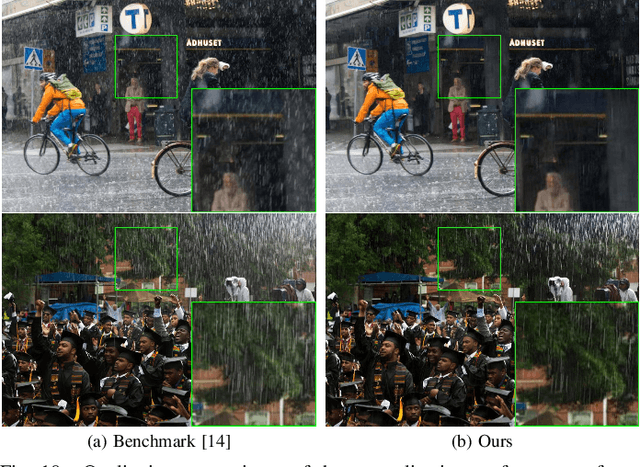
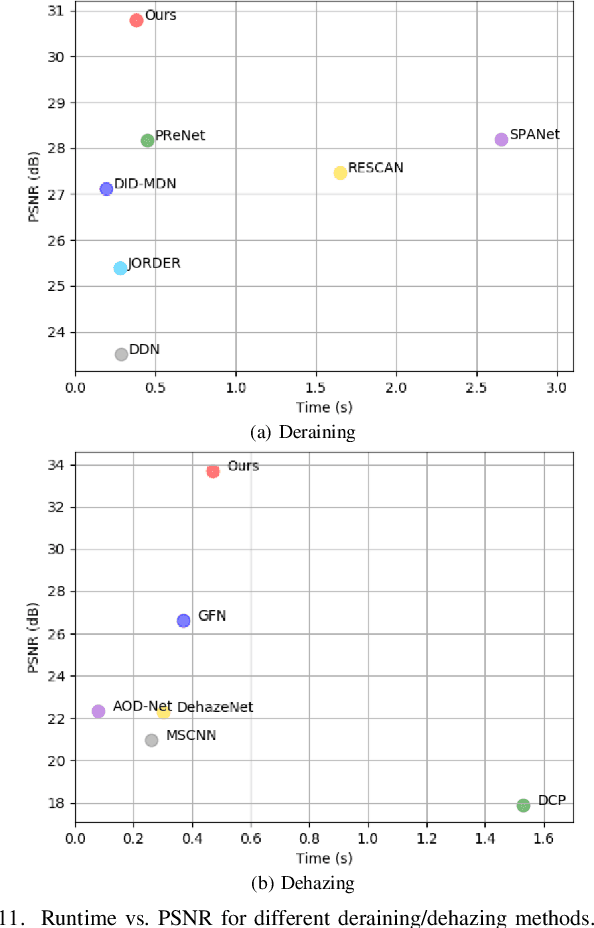
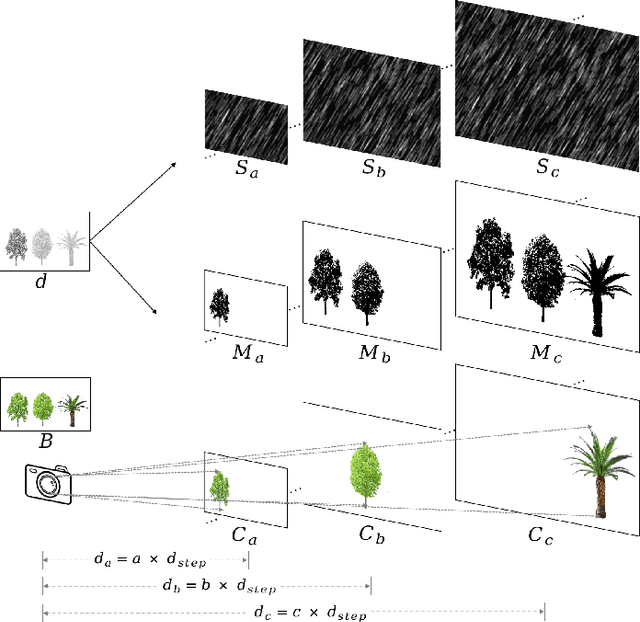
We develop a new physical model for the rain effect and show that the well-known atmosphere scattering model (ASM) for the haze effect naturally emerges as its homogeneous continuous limit. Via depth-aware fusion of multi-layer rain streaks according to the camera imaging mechanism, the new model can better capture the sophisticated non-deterministic degradation patterns commonly seen in real rainy images. We also propose a Densely Scale-Connected Attentive Network (DSCAN) that is suitable for both deraining and dehazing tasks. Our design alleviates the bottleneck issue existent in conventional multi-scale networks and enables more effective information exchange and aggregation. Extensive experimental results demonstrate that the proposed DSCAN is able to deliver superior derained/dehazed results on both synthetic and real images as compared to the state-of-the-art. Moreover, it is shown that for our DSCAN, the synthetic dataset built using the new physical model yields better generalization performance on real images in comparison with the existing datasets based on over-simplified models.
Surface HOF: Surface Reconstruction from a Single Image Using Higher Order Function Networks
Dec 18, 2019

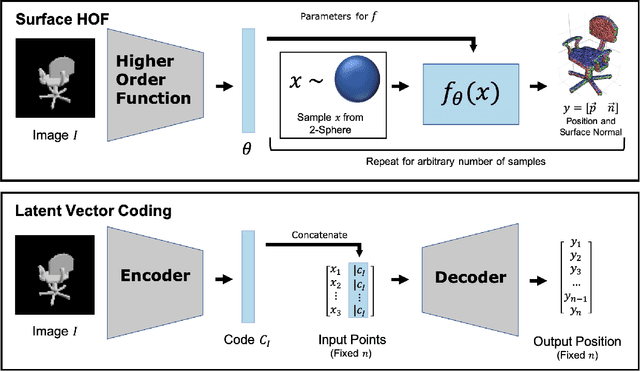

We address the problem of generating a high-resolution surface reconstruction from a single image. Our approach is to learn a Higher Order Function (HOF) which takes an image of an object as input and generates a mapping function. The mapping function takes samples from a canonical domain (e.g. the unit sphere) and maps each sample to a local tangent plane on the 3D reconstruction of the object. Each tangent plane is represented as an origin point and a normal vector at that point. By efficiently learning a continuous mapping function, the surface can be generated at arbitrary resolution in contrast to other methods which generate fixed resolution outputs. We present the Surface HOF in which both the higher order function and the mapping function are represented as neural networks, and train the networks to generate reconstructions of PointNet objects. Experiments show that Surface HOF is more accurate and uses more efficient representations than other state of the art methods for surface reconstruction. Surface HOF is also easier to train: it requires minimal input pre-processing and output post-processing and generates surface representations that are more parameter efficient. Its accuracy and convenience make Surface HOF an appealing method for single image reconstruction.
Self-Calibrating Neural Radiance Fields
Sep 02, 2021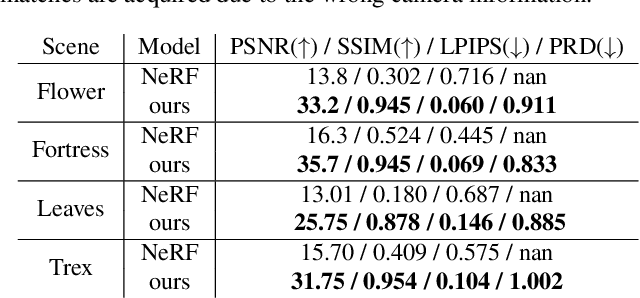
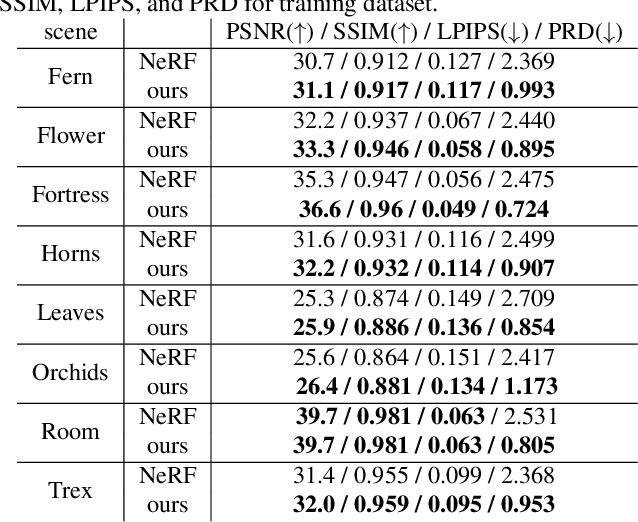

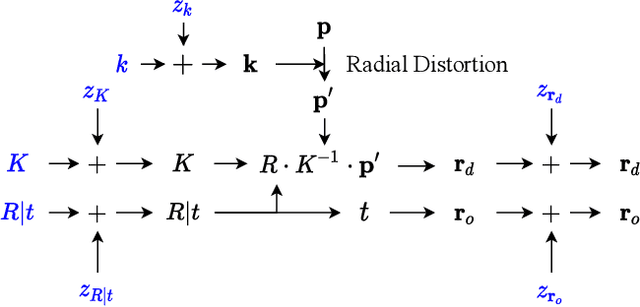
In this work, we propose a camera self-calibration algorithm for generic cameras with arbitrary non-linear distortions. We jointly learn the geometry of the scene and the accurate camera parameters without any calibration objects. Our camera model consists of a pinhole model, a fourth order radial distortion, and a generic noise model that can learn arbitrary non-linear camera distortions. While traditional self-calibration algorithms mostly rely on geometric constraints, we additionally incorporate photometric consistency. This requires learning the geometry of the scene, and we use Neural Radiance Fields (NeRF). We also propose a new geometric loss function, viz., projected ray distance loss, to incorporate geometric consistency for complex non-linear camera models. We validate our approach on standard real image datasets and demonstrate that our model can learn the camera intrinsics and extrinsics (pose) from scratch without COLMAP initialization. Also, we show that learning accurate camera models in a differentiable manner allows us to improve PSNR over baselines. Our module is an easy-to-use plugin that can be applied to NeRF variants to improve performance. The code and data are currently available at https://github.com/POSTECH-CVLab/SCNeRF.
A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing
Jun 10, 2018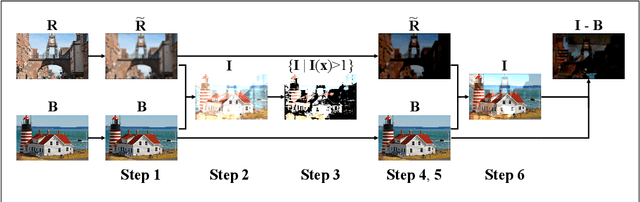
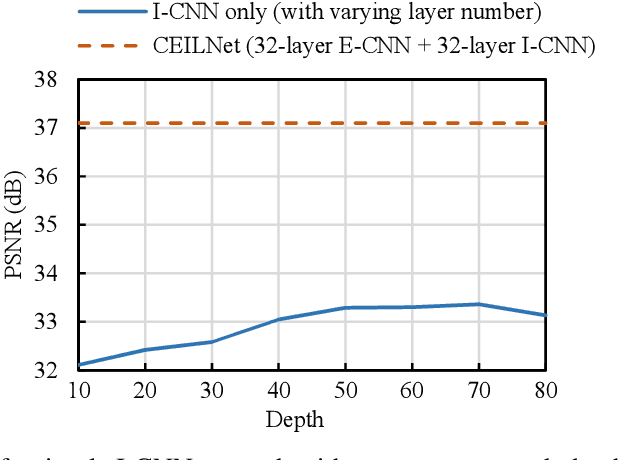


This paper proposes a deep neural network structure that exploits edge information in addressing representative low-level vision tasks such as layer separation and image filtering. Unlike most other deep learning strategies applied in this context, our approach tackles these challenging problems by estimating edges and reconstructing images using only cascaded convolutional layers arranged such that no handcrafted or application-specific image-processing components are required. We apply the resulting transferrable pipeline to two different problem domains that are both sensitive to edges, namely, single image reflection removal and image smoothing. For the former, using a mild reflection smoothness assumption and a novel synthetic data generation method that acts as a type of weak supervision, our network is able to solve much more difficult reflection cases that cannot be handled by previous methods. For the latter, we also exceed the state-of-the-art quantitative and qualitative results by wide margins. In all cases, the proposed framework is simple, fast, and easy to transfer across disparate domains.
A Novel Hybrid Convolutional Neural Network for Accurate Organ Segmentation in 3D Head and Neck CT Images
Sep 26, 2021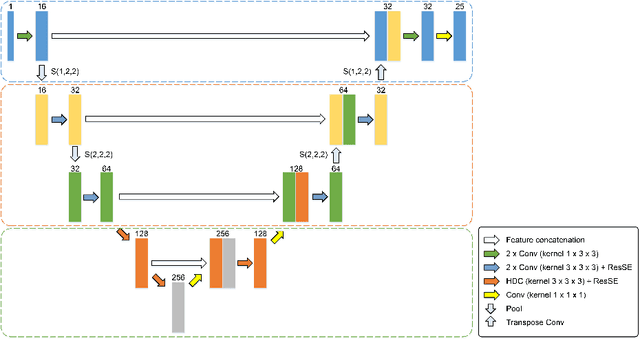


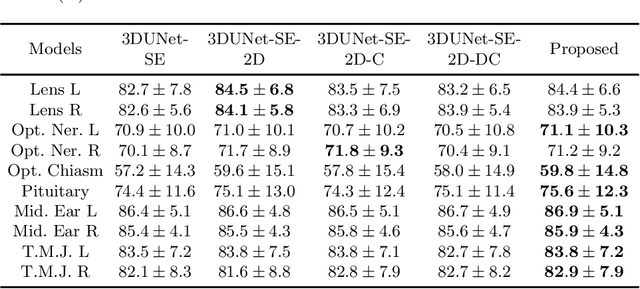
Radiation therapy (RT) is widely employed in the clinic for the treatment of head and neck (HaN) cancers. An essential step of RT planning is the accurate segmentation of various organs-at-risks (OARs) in HaN CT images. Nevertheless, segmenting OARs manually is time-consuming, tedious, and error-prone considering that typical HaN CT images contain tens to hundreds of slices. Automated segmentation algorithms are urgently required. Recently, convolutional neural networks (CNNs) have been extensively investigated on this task. Particularly, 3D CNNs are frequently adopted to process 3D HaN CT images. There are two issues with na\"ive 3D CNNs. First, the depth resolution of 3D CT images is usually several times lower than the in-plane resolution. Direct employment of 3D CNNs without distinguishing this difference can lead to the extraction of distorted image features and influence the final segmentation performance. Second, a severe class imbalance problem exists, and large organs can be orders of times larger than small organs. It is difficult to simultaneously achieve accurate segmentation for all the organs. To address these issues, we propose a novel hybrid CNN that fuses 2D and 3D convolutions to combat the different spatial resolutions and extract effective edge and semantic features from 3D HaN CT images. To accommodate large and small organs, our final model, named OrganNet2.5D, consists of only two instead of the classic four downsampling operations, and hybrid dilated convolutions are introduced to maintain the respective field. Experiments on the MICCAI 2015 challenge dataset demonstrate that OrganNet2.5D achieves promising performance compared to state-of-the-art methods.
Zero-sample surface defect detection and classification based on semantic feedback neural network
Jun 15, 2021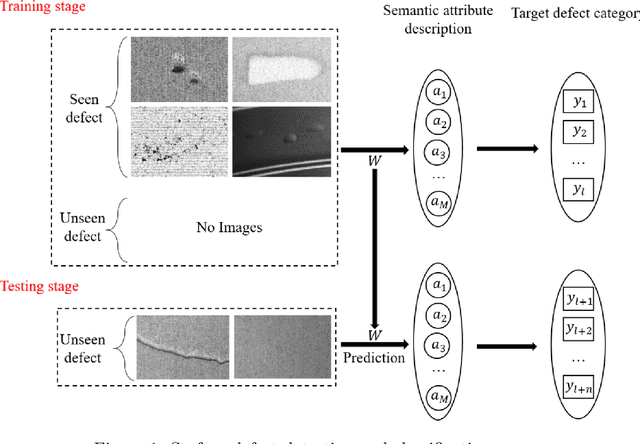



Defect detection and classification technology has changed from traditional artificial visual inspection to current intelligent automated inspection, but most of the current defect detection methods are training related detection models based on a data-driven approach, taking into account the difficulty of collecting some sample data in the industrial field. We apply zero-shot learning technology to the industrial field. Aiming at the problem of the existing "Latent Feature Guide Attribute Attention" (LFGAA) zero-shot image classification network, the output latent attributes and artificially defined attributes are different in the semantic space, which leads to the problem of model performance degradation, proposed an LGFAA network based on semantic feedback, and improved model performance by constructing semantic embedded modules and feedback mechanisms. At the same time, for the common domain shift problem in zero-shot learning, based on the idea of co-training algorithm using the difference information between different views of data to learn from each other, we propose an Ensemble Co-training algorithm, which adaptively reduces the prediction error in image tag embedding from multiple angles. Various experiments conducted on the zero-shot dataset and the cylinder liner dataset in the industrial field provide competitive results.