 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Turbulence-immune computational ghost imaging based on a multi-scale generative adversarial network
Jul 14, 2021
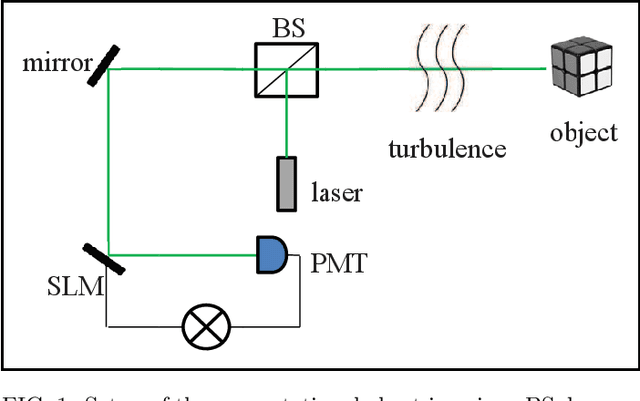
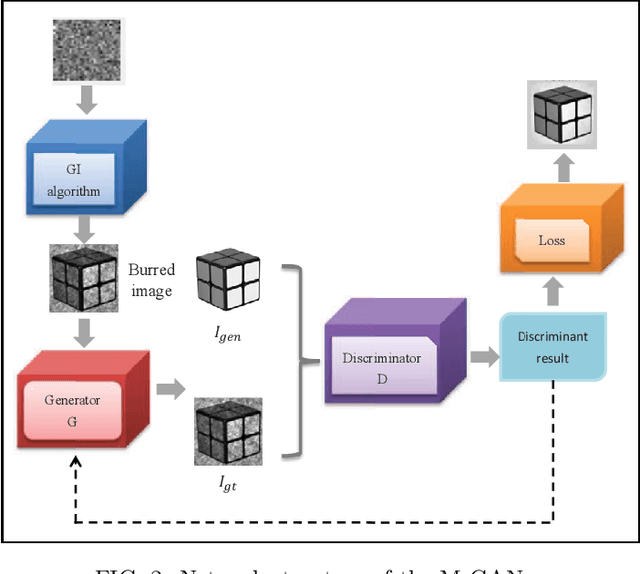
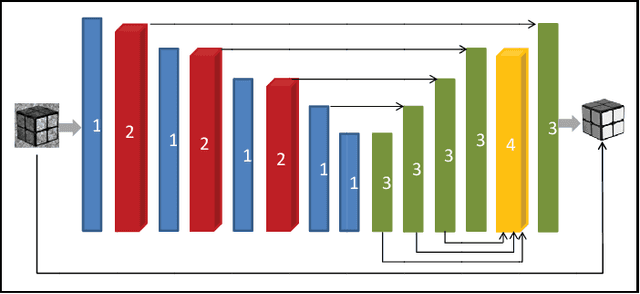
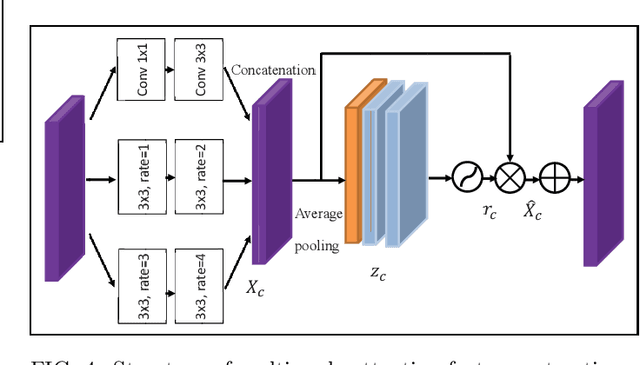
There is a consensus that turbulence-free images cannot be obtained by conventional computational ghost imaging (CGI) because the CGI is only a classic simulation, which does not satisfy the conditions of turbulence-free imaging. In this article, we first report a turbulence-immune CGI method based on a multi-scale generative adversarial network (MsGAN). Here, the conventional CGI framework is not changed, but the conventional CGI coincidence measurement algorithm is optimized by an MsGAN. Thus, the satisfactory turbulence-free ghost image can be reconstructed by training the network, and the visual effect can be significantly improved.
IPatch: A Remote Adversarial Patch
Apr 30, 2021
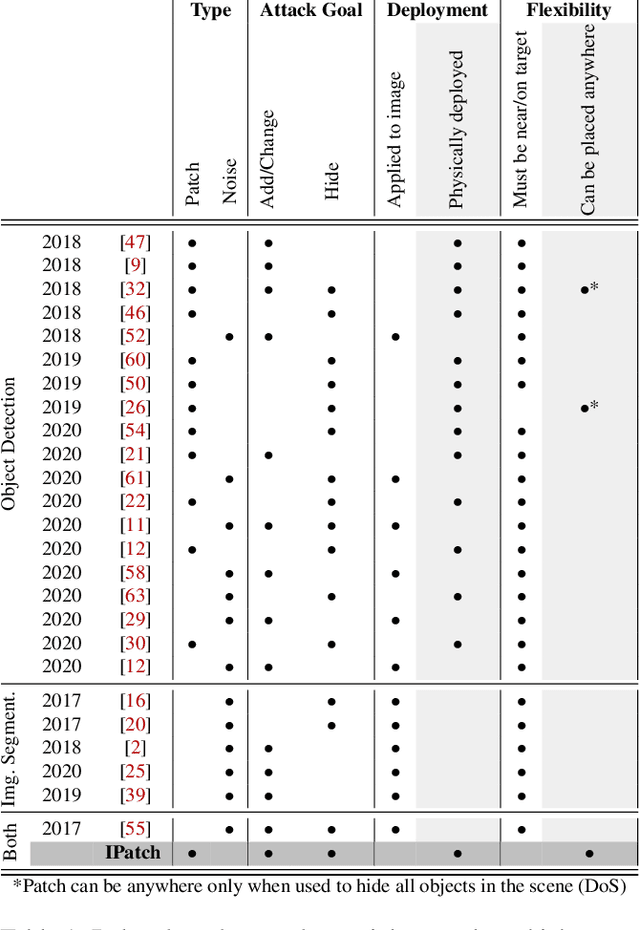
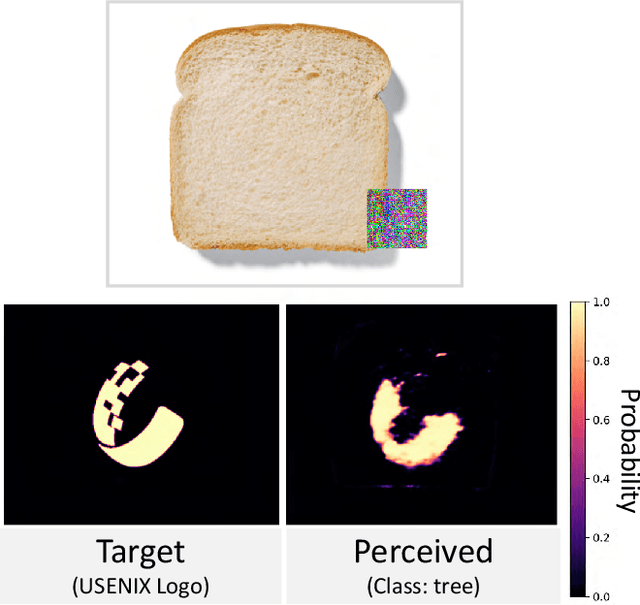
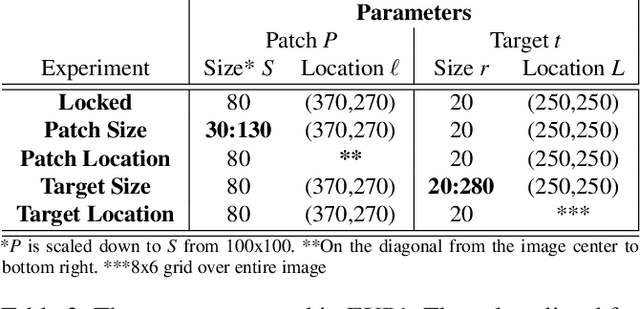
Applications such as autonomous vehicles and medical screening use deep learning models to localize and identify hundreds of objects in a single frame. In the past, it has been shown how an attacker can fool these models by placing an adversarial patch within a scene. However, these patches must be placed in the target location and do not explicitly alter the semantics elsewhere in the image. In this paper, we introduce a new type of adversarial patch which alters a model's perception of an image's semantics. These patches can be placed anywhere within an image to change the classification or semantics of locations far from the patch. We call this new class of adversarial examples `remote adversarial patches' (RAP). We implement our own RAP called IPatch and perform an in-depth analysis on image segmentation RAP attacks using five state-of-the-art architectures with eight different encoders on the CamVid street view dataset. Moreover, we demonstrate that the attack can be extended to object recognition models with preliminary results on the popular YOLOv3 model. We found that the patch can change the classification of a remote target region with a success rate of up to 93% on average.
W2WNet: a two-module probabilistic Convolutional Neural Network with embedded data cleansing functionality
Mar 24, 2021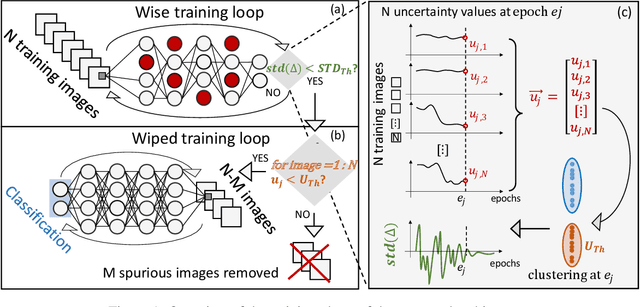
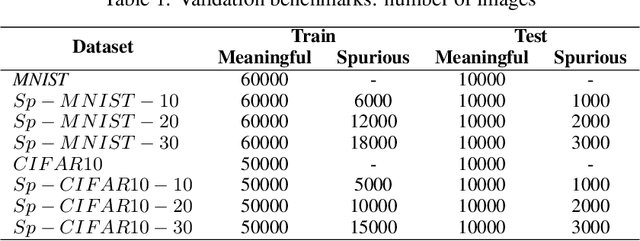
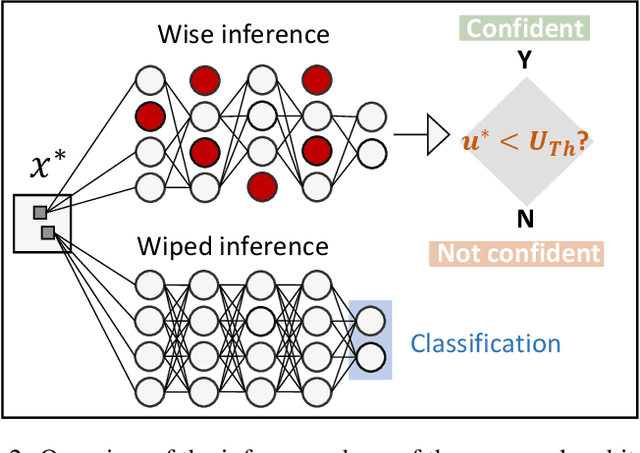
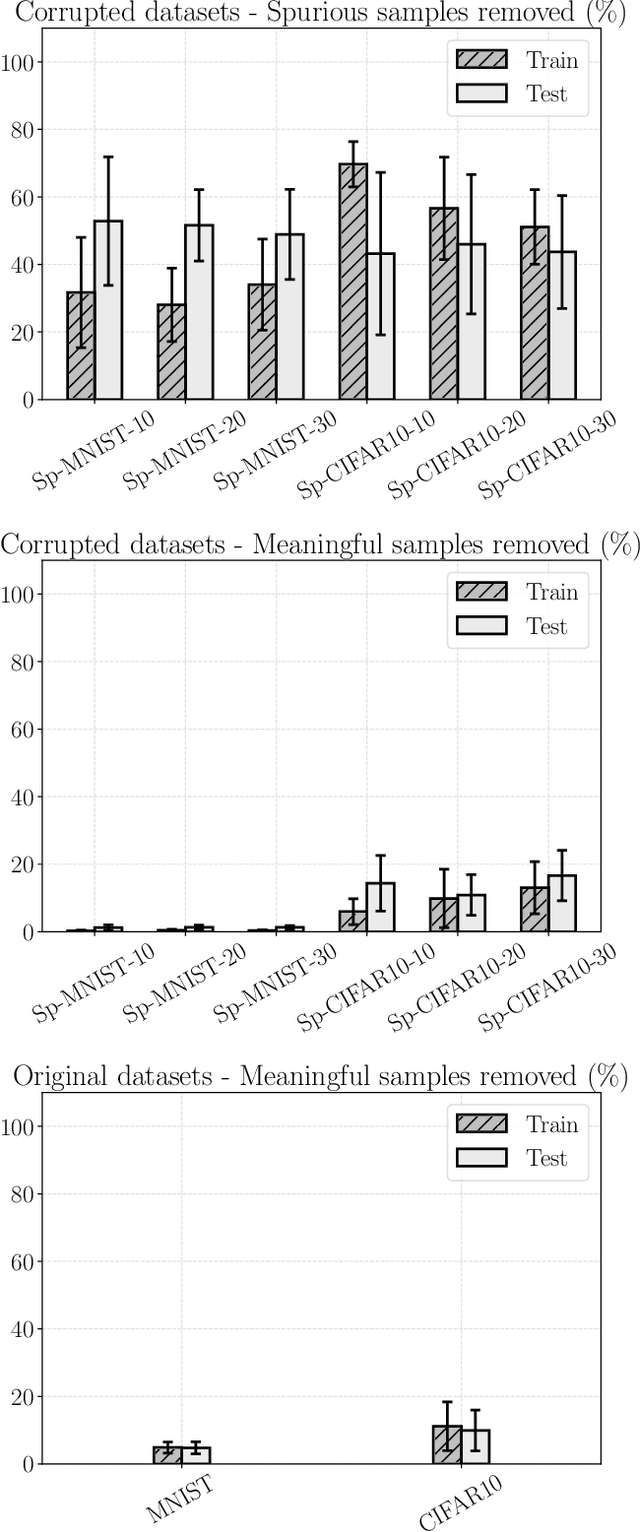
Convolutional Neural Networks (CNNs) are supposed to be fed with only high-quality annotated datasets. Nonetheless, in many real-world scenarios, such high quality is very hard to obtain, and datasets may be affected by any sort of image degradation and mislabelling issues. This negatively impacts the performance of standard CNNs, both during the training and the inference phase. To address this issue we propose Wise2WipedNet (W2WNet), a new two-module Convolutional Neural Network, where a Wise module exploits Bayesian inference to identify and discard spurious images during the training, and a Wiped module takes care of the final classification while broadcasting information on the prediction confidence at inference time. The goodness of our solution is demonstrated on a number of public benchmarks addressing different image classification tasks, as well as on a real-world case study on histological image analysis. Overall, our experiments demonstrate that W2WNet is able to identify image degradation and mislabelling issues both at training and at inference time, with a positive impact on the final classification accuracy.
Reinforced active learning for image segmentation
Feb 16, 2020
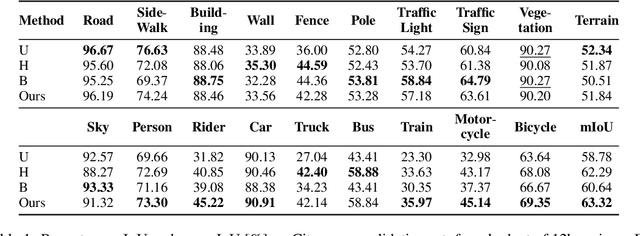
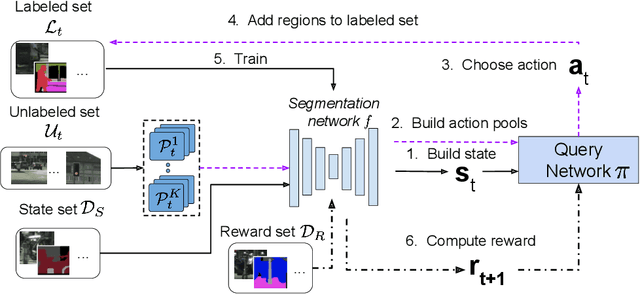
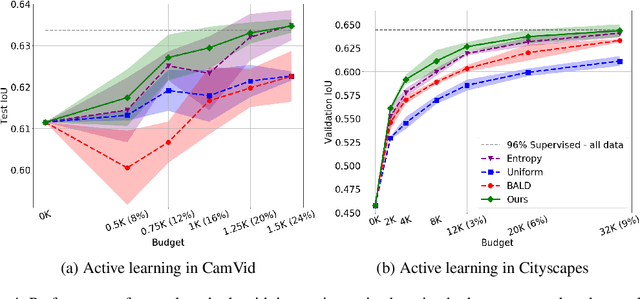
Learning-based approaches for semantic segmentation have two inherent challenges. First, acquiring pixel-wise labels is expensive and time-consuming. Second, realistic segmentation datasets are highly unbalanced: some categories are much more abundant than others, biasing the performance to the most represented ones. In this paper, we are interested in focusing human labelling effort on a small subset of a larger pool of data, minimizing this effort while maximizing performance of a segmentation model on a hold-out set. We present a new active learning strategy for semantic segmentation based on deep reinforcement learning (RL). An agent learns a policy to select a subset of small informative image regions -- opposed to entire images -- to be labeled, from a pool of unlabeled data. The region selection decision is made based on predictions and uncertainties of the segmentation model being trained. Our method proposes a new modification of the deep Q-network (DQN) formulation for active learning, adapting it to the large-scale nature of semantic segmentation problems. We test the proof of concept in CamVid and provide results in the large-scale dataset Cityscapes. On Cityscapes, our deep RL region-based DQN approach requires roughly 30% less additional labeled data than our most competitive baseline to reach the same performance. Moreover, we find that our method asks for more labels of under-represented categories compared to the baselines, improving their performance and helping to mitigate class imbalance.
Does Haze Removal Help CNN-based Image Classification?
Oct 12, 2018



Hazy images are common in real scenarios and many dehazing methods have been developed to automatically remove the haze from images. Typically, the goal of image dehazing is to produce clearer images from which human vision can better identify the object and structural details present in the images. When the ground-truth haze-free image is available for a hazy image, quantitative evaluation of image dehazing is usually based on objective metrics, such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM). However, in many applications, large-scale images are collected not for visual examination by human. Instead, they are used for many high-level vision tasks, such as automatic classification, recognition and categorization. One fundamental problem here is whether various dehazing methods can produce clearer images that can help improve the performance of the high-level tasks. In this paper, we empirically study this problem in the important task of image classification by using both synthetic and real hazy image datasets. From the experimental results, we find that the existing image-dehazing methods cannot improve much the image-classification performance and sometimes even reduce the image-classification performance.
Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
Jul 30, 2020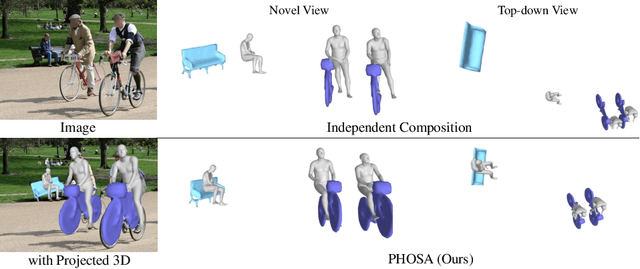
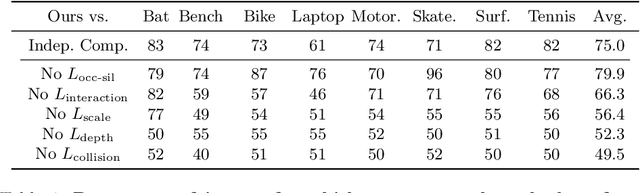
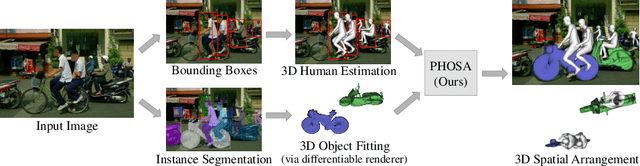
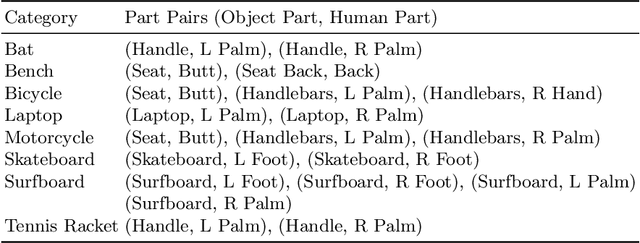
We present a method that infers spatial arrangements and shapes of humans and objects in a globally consistent 3D scene, all from a single image in-the-wild captured in an uncontrolled environment. Notably, our method runs on datasets without any scene- or object-level 3D supervision. Our key insight is that considering humans and objects jointly gives rise to "3D common sense" constraints that can be used to resolve ambiguity. In particular, we introduce a scale loss that learns the distribution of object size from data; an occlusion-aware silhouette re-projection loss to optimize object pose; and a human-object interaction loss to capture the spatial layout of objects with which humans interact. We empirically validate that our constraints dramatically reduce the space of likely 3D spatial configurations. We demonstrate our approach on challenging, in-the-wild images of humans interacting with large objects (such as bicycles, motorcycles, and surfboards) and handheld objects (such as laptops, tennis rackets, and skateboards). We quantify the ability of our approach to recover human-object arrangements and outline remaining challenges in this relatively domain. The project webpage can be found at https://jasonyzhang.com/phosa.
Neural Style Transfer Improves 3D Cardiovascular MR Image Segmentation on Inconsistent Data
Sep 20, 2019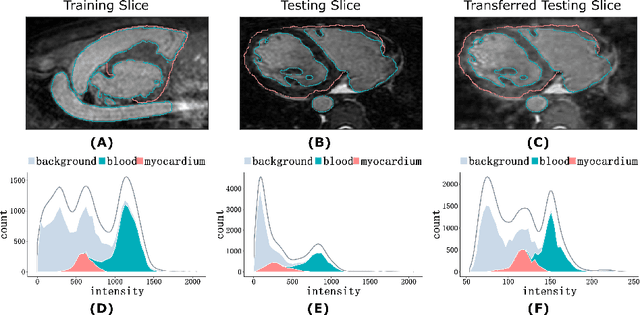
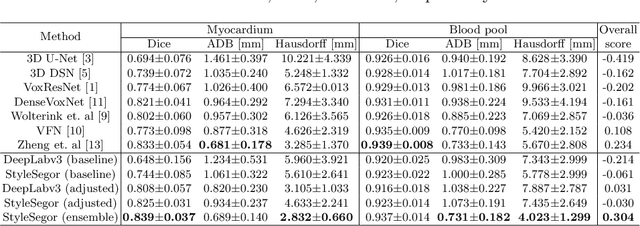
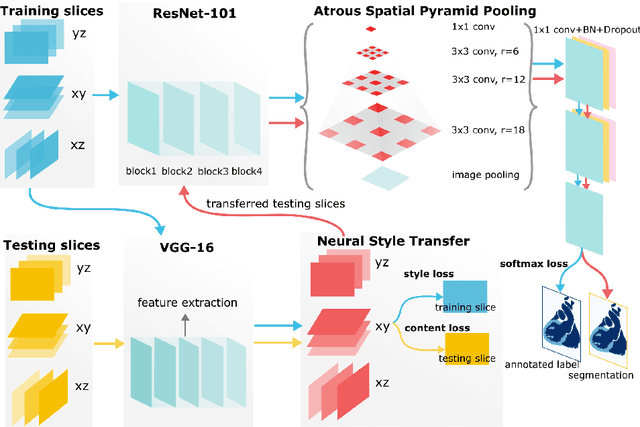
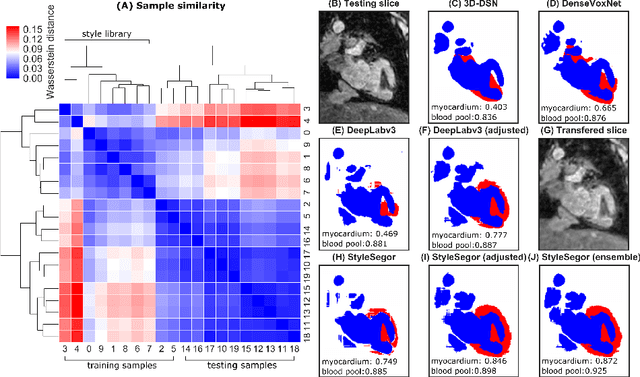
Three-dimensional medical image segmentation is one of the most important problems in medical image analysis and plays a key role in downstream diagnosis and treatment. Recent years, deep neural networks have made groundbreaking success in medical image segmentation problem. However, due to the high variance in instrumental parameters, experimental protocols, and subject appearances, the generalization of deep learning models is often hindered by the inconsistency in medical images generated by different machines and hospitals. In this work, we present StyleSegor, an efficient and easy-to-use strategy to alleviate this inconsistency issue. Specifically, neural style transfer algorithm is applied to unlabeled data in order to minimize the differences in image properties including brightness, contrast, texture, etc. between the labeled and unlabeled data. We also apply probabilistic adjustment on the network output and integrate multiple predictions through ensemble learning. On a publicly available whole heart segmentation benchmarking dataset from MICCAI HVSMR 2016 challenge, we have demonstrated an elevated dice accuracy surpassing current state-of-the-art method and notably, an improvement of the total score by 29.91\%. StyleSegor is thus corroborated to be an accurate tool for 3D whole heart segmentation especially on highly inconsistent data, and is available at https://github.com/horsepurve/StyleSegor.
Few-Shot Object Detection by Attending to Per-Sample-Prototype
Sep 16, 2021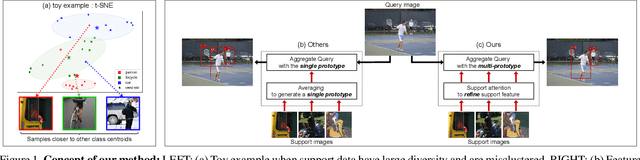

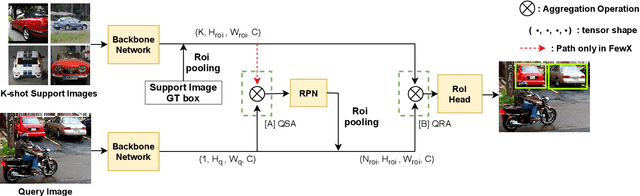

Few-shot object detection aims to detect instances of specific categories in a query image with only a handful of support samples. Although this takes less effort than obtaining enough annotated images for supervised object detection, it results in a far inferior performance compared to the conventional object detection methods. In this paper, we propose a meta-learning-based approach that considers the unique characteristics of each support sample. Rather than simply averaging the information of the support samples to generate a single prototype per category, our method can better utilize the information of each support sample by treating each support sample as an individual prototype. Specifically, we introduce two types of attention mechanisms for aggregating the query and support feature maps. The first is to refine the information of few-shot samples by extracting shared information between the support samples through attention. Second, each support sample is used as a class code to leverage the information by comparing similarities between each support feature and query features. Our proposed method is complementary to the previous methods, making it easy to plug and play for further improvement. We have evaluated our method on PASCAL VOC and COCO benchmarks, and the results verify the effectiveness of our method. In particular, the advantages of our method are maximized when there is more diversity among support data.
How Well do Feature Visualizations Support Causal Understanding of CNN Activations?
Jun 23, 2021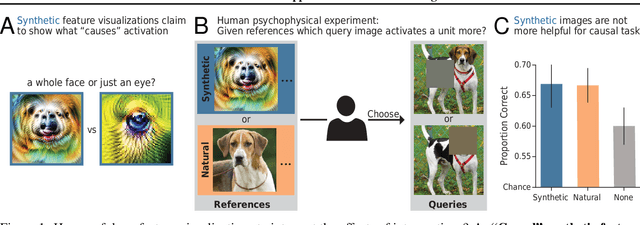

One widely used approach towards understanding the inner workings of deep convolutional neural networks is to visualize unit responses via activation maximization. Feature visualizations via activation maximization are thought to provide humans with precise information about the image features that cause a unit to be activated. If this is indeed true, these synthetic images should enable humans to predict the effect of an intervention, such as whether occluding a certain patch of the image (say, a dog's head) changes a unit's activation. Here, we test this hypothesis by asking humans to predict which of two square occlusions causes a larger change to a unit's activation. Both a large-scale crowdsourced experiment and measurements with experts show that on average, the extremely activating feature visualizations by Olah et al. (2017) indeed help humans on this task ($67 \pm 4\%$ accuracy; baseline performance without any visualizations is $60 \pm 3\%$). However, they do not provide any significant advantage over other visualizations (such as e.g. dataset samples), which yield similar performance ($66 \pm 3\%$ to $67 \pm 3\%$ accuracy). Taken together, we propose an objective psychophysical task to quantify the benefit of unit-level interpretability methods for humans, and find no evidence that feature visualizations provide humans with better "causal understanding" than simple alternative visualizations.
Self-Supervised 3D Hand Pose Estimation from monocular RGB via Contrastive Learning
Jun 30, 2021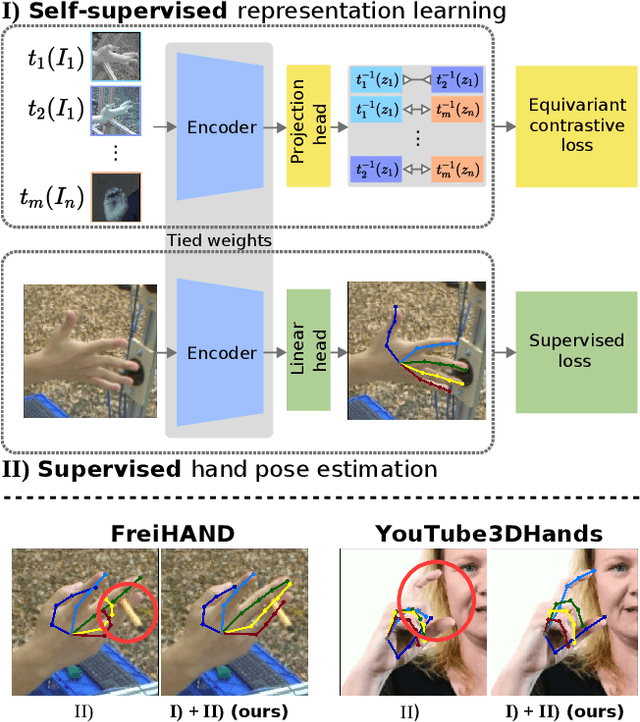
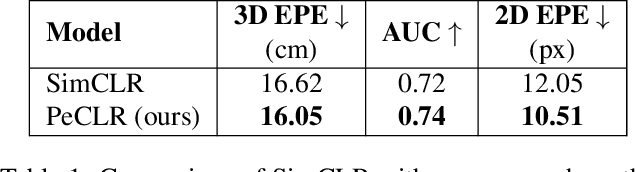
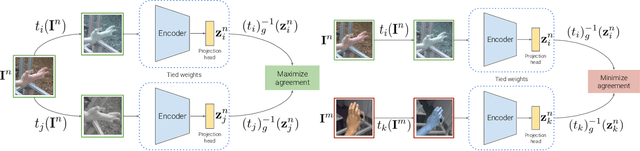
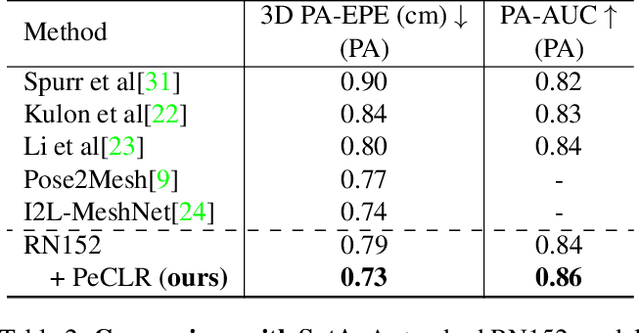
Acquiring accurate 3D annotated data for hand pose estimation is a notoriously difficult problem. This typically requires complex multi-camera setups and controlled conditions, which in turn creates a domain gap that is hard to bridge to fully unconstrained settings. Encouraged by the success of contrastive learning on image classification tasks, we propose a new self-supervised method for the structured regression task of 3D hand pose estimation. Contrastive learning makes use of unlabeled data for the purpose of representation learning via a loss formulation that encourages the learned feature representations to be invariant under any image transformation. For 3D hand pose estimation, it too is desirable to have invariance to appearance transformation such as color jitter. However, the task requires equivariance under affine transformations, such as rotation and translation. To address this issue, we propose an equivariant contrastive objective and demonstrate its effectiveness in the context of 3D hand pose estimation. We experimentally investigate the impact of invariant and equivariant contrastive objectives and show that learning equivariant features leads to better representations for the task of 3D hand pose estimation. Furthermore, we show that a standard ResNet-152, trained on additional unlabeled data, attains an improvement of $7.6\%$ in PA-EPE on FreiHAND and thus achieves state-of-the-art performance without any task specific, specialized architectures.