 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bilinear Faster RCNN with ELA for Image Tampering Detection
Apr 07, 2019




With technological advances leading to an increase in mechanisms of image tampering, our fraud detection methods must continue to be upgraded to match their sophistication. One problem with current methods is that they require prior knowledge of the method of forgery in order to determine which features to extract from the image to localize the region of interest. When a machine learning algorithm is used to learn different types tampering from a large set of various image types, with a big enough database we can easily classify which images are tampered (by training on the entire image feature map for each image), but we still are left with the question of which features to train on, and how to localize the manipulation. To solve this, object detection networks such as Faster RCNN, which combine an RPN (Region Proposal Network) with a CNN have recently been adapted to fraud detection by utilizing their ability to propose bounding boxes for objects of interest to localize the tampering artifacts. In this work, an existing bilinear Faster RCNN model that was developed will be modified with the second stream having an input of the ELA (Error Level Analysis) JPEG compression level mask.
Learning Cross-modal Contrastive Features for Video Domain Adaptation
Aug 26, 2021

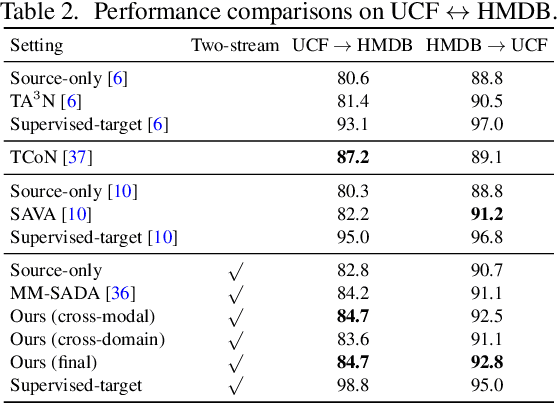
Learning transferable and domain adaptive feature representations from videos is important for video-relevant tasks such as action recognition. Existing video domain adaptation methods mainly rely on adversarial feature alignment, which has been derived from the RGB image space. However, video data is usually associated with multi-modal information, e.g., RGB and optical flow, and thus it remains a challenge to design a better method that considers the cross-modal inputs under the cross-domain adaptation setting. To this end, we propose a unified framework for video domain adaptation, which simultaneously regularizes cross-modal and cross-domain feature representations. Specifically, we treat each modality in a domain as a view and leverage the contrastive learning technique with properly designed sampling strategies. As a result, our objectives regularize feature spaces, which originally lack the connection across modalities or have less alignment across domains. We conduct experiments on domain adaptive action recognition benchmark datasets, i.e., UCF, HMDB, and EPIC-Kitchens, and demonstrate the effectiveness of our components against state-of-the-art algorithms.
LocTex: Learning Data-Efficient Visual Representations from Localized Textual Supervision
Aug 26, 2021



Computer vision tasks such as object detection and semantic/instance segmentation rely on the painstaking annotation of large training datasets. In this paper, we propose LocTex that takes advantage of the low-cost localized textual annotations (i.e., captions and synchronized mouse-over gestures) to reduce the annotation effort. We introduce a contrastive pre-training framework between images and captions and propose to supervise the cross-modal attention map with rendered mouse traces to provide coarse localization signals. Our learned visual features capture rich semantics (from free-form captions) and accurate localization (from mouse traces), which are very effective when transferred to various downstream vision tasks. Compared with ImageNet supervised pre-training, LocTex can reduce the size of the pre-training dataset by 10x or the target dataset by 2x while achieving comparable or even improved performance on COCO instance segmentation. When provided with the same amount of annotations, LocTex achieves around 4% higher accuracy than the previous state-of-the-art "vision+language" pre-training approach on the task of PASCAL VOC image classification.
Color Filter Arrays for Quanta Image Sensors
Mar 26, 2019
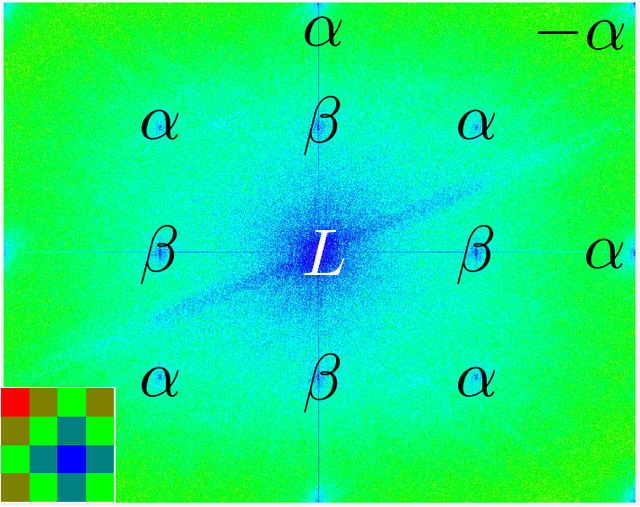

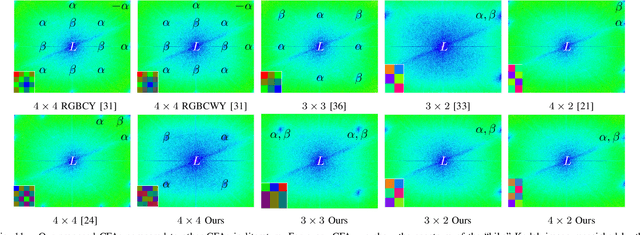
Quanta image sensor (QIS) is to be the next generation image sensor after CCD and CMOS. To enable such technology, significant progress was made over the past five years to advance both the device and image reconstruction algorithms. In this paper, we discuss color imaging using QIS, in particular how to design color filter arrays. Designing color filter arrays for QIS is challenging because at the pixel pitch of 1.1$\mu$m, maximizing the light efficiency while suppressing aliasing and crosstalk are conflicting tasks. We present an optimization-based framework to design color filter arrays for very small pixels. The new framework unifies several mainstream color filter array design frameworks by offering generality and flexibility. Compared to the existing frameworks which can only handle one or two design criteria, the new framework can simultaneously handle luminance gain, chrominance gain, cross-talk, anti-aliasing, manufacturability and orthogonality. Extensive experimental comparisons demonstrate the effectiveness and generality of the framework.
Real-Time Video Super-Resolution by Joint Local Inference and Global Parameter Estimation
May 06, 2021
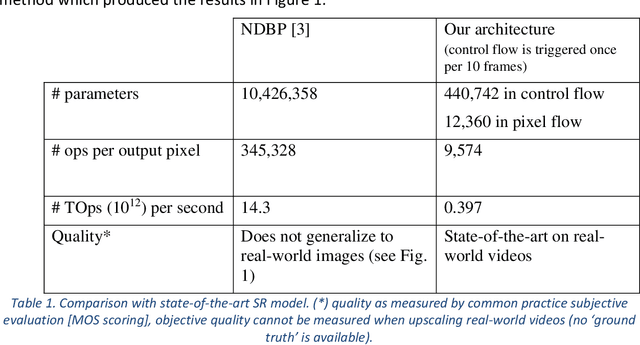
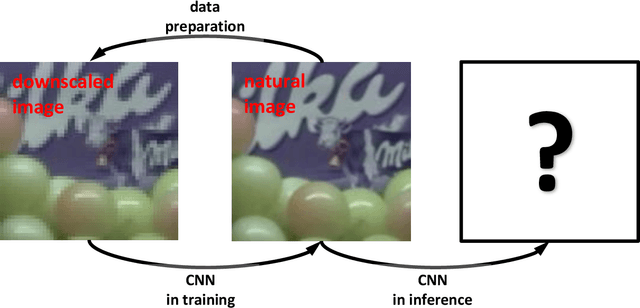
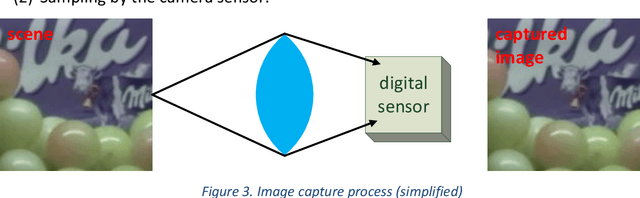
The state of the art in video super-resolution (SR) are techniques based on deep learning, but they perform poorly on real-world videos (see Figure 1). The reason is that training image-pairs are commonly created by downscaling a high-resolution image to produce a low-resolution counterpart. Deep models are therefore trained to undo downscaling and do not generalize to super-resolving real-world images. Several recent publications present techniques for improving the generalization of learning-based SR, but are all ill-suited for real-time application. We present a novel approach to synthesizing training data by simulating two digital-camera image-capture processes at different scales. Our method produces image-pairs in which both images have properties of natural images. Training an SR model using this data leads to far better generalization to real-world images and videos. In addition, deep video-SR models are characterized by a high operations-per-pixel count, which prohibits their application in real-time. We present an efficient CNN architecture, which enables real-time application of video SR on low-power edge-devices. We split the SR task into two sub-tasks: a control-flow which estimates global properties of the input video and adapts the weights and biases of a processing-CNN that performs the actual processing. Since the process-CNN is tailored to the statistics of the input, its capacity kept low, while retaining effectivity. Also, since video-statistics evolve slowly, the control-flow operates at a much lower rate than the video frame-rate. This reduces the overall computational load by as much as two orders of magnitude. This framework of decoupling the adaptivity of the algorithm from the pixel processing, can be applied in a large family of real-time video enhancement applications, e.g., video denoising, local tone-mapping, stabilization, etc.
* Technical report; accompanying a poster appearing in ICCP 2021
Turbulence-immune computational ghost imaging based on a multi-scale generative adversarial network
Jul 14, 2021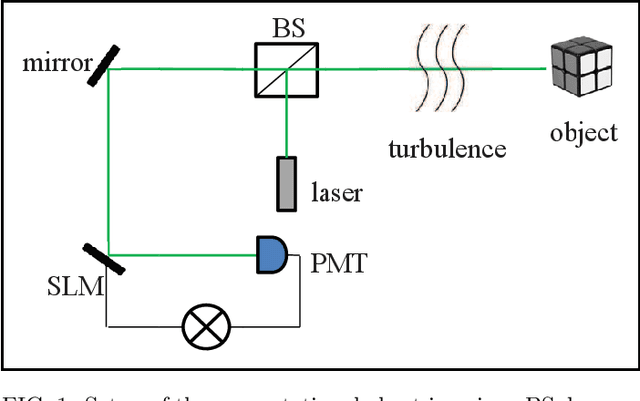
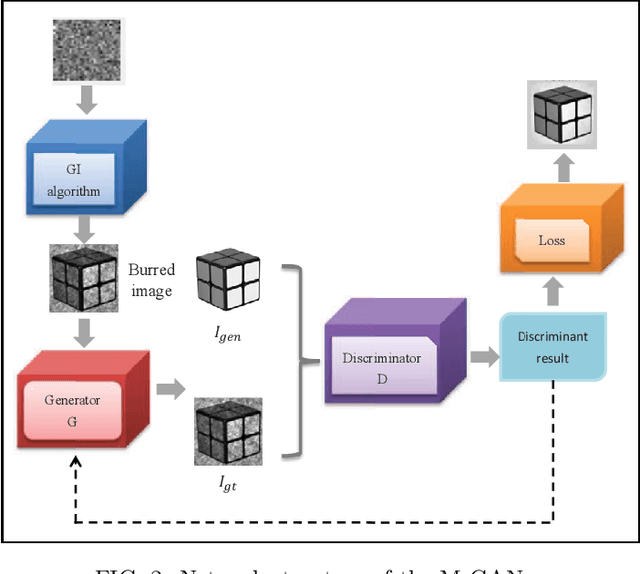
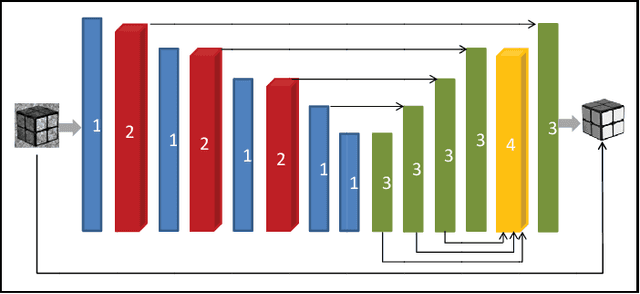
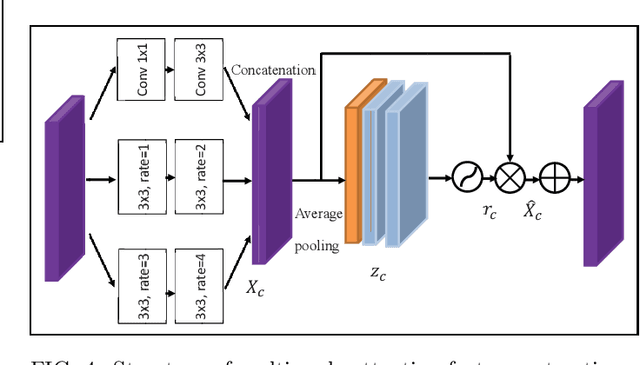
There is a consensus that turbulence-free images cannot be obtained by conventional computational ghost imaging (CGI) because the CGI is only a classic simulation, which does not satisfy the conditions of turbulence-free imaging. In this article, we first report a turbulence-immune CGI method based on a multi-scale generative adversarial network (MsGAN). Here, the conventional CGI framework is not changed, but the conventional CGI coincidence measurement algorithm is optimized by an MsGAN. Thus, the satisfactory turbulence-free ghost image can be reconstructed by training the network, and the visual effect can be significantly improved.
On the relation between statistical learning and perceptual distances
Jun 08, 2021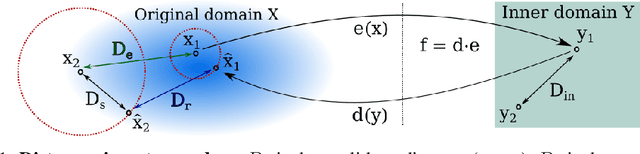
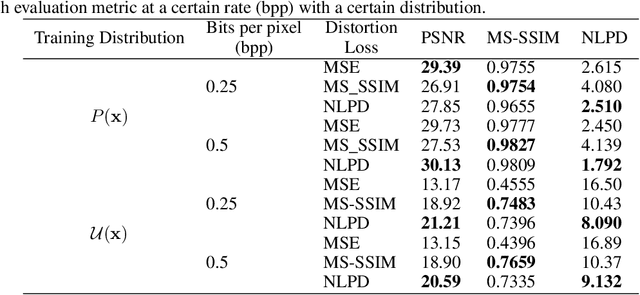
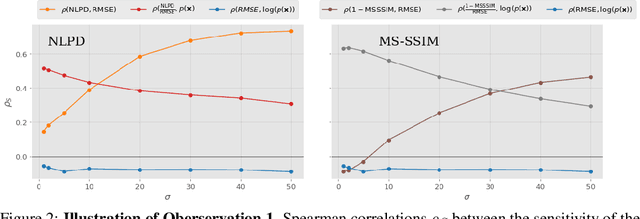
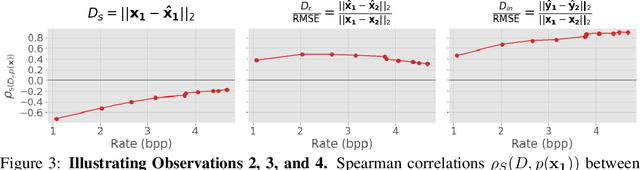
It has been demonstrated many times that the behavior of the human visual system is connected to the statistics of natural images. Since machine learning relies on the statistics of training data as well, the above connection has interesting implications when using perceptual distances (which mimic the behavior of the human visual system) as a loss function. In this paper, we aim to unravel the non-trivial relationship between the probability distribution of the data, perceptual distances, and unsupervised machine learning. To this end, we show that perceptual sensitivity is correlated with the probability of an image in its close neighborhood. We also explore the relation between distances induced by autoencoders and the probability distribution of the data used for training them, as well as how these induced distances are correlated with human perception. Finally, we discuss why perceptual distances might not lead to noticeable gains in performance over standard Euclidean distances in common image processing tasks except when data is scarce and the perceptual distance provides regularization.
Masked Face Recognition Challenge: The InsightFace Track Report
Aug 18, 2021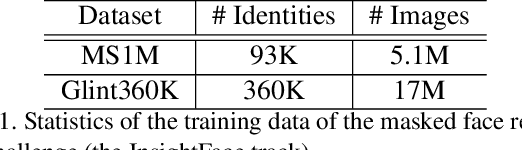

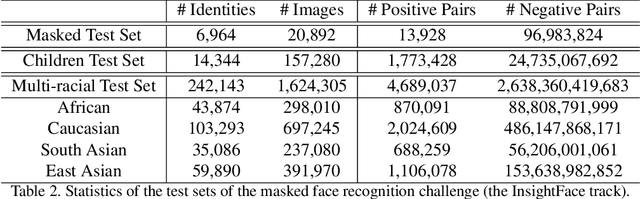
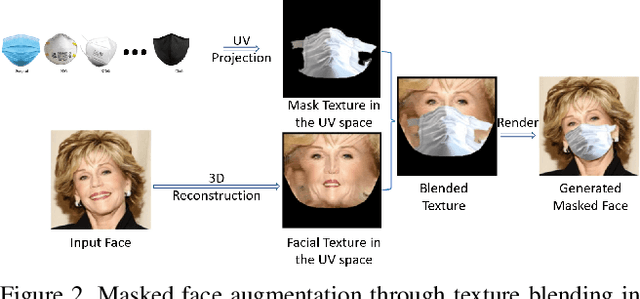
During the COVID-19 coronavirus epidemic, almost everyone wears a facial mask, which poses a huge challenge to deep face recognition. In this workshop, we organize Masked Face Recognition (MFR) challenge and focus on bench-marking deep face recognition methods under the existence of facial masks. In the MFR challenge, there are two main tracks: the InsightFace track and the WebFace260M track. For the InsightFace track, we manually collect a large-scale masked face test set with 7K identities. In addition, we also collect a children test set including 14K identities and a multi-racial test set containing 242K identities. By using these three test sets, we build up an online model testing system, which can give a comprehensive evaluation of face recognition models. To avoid data privacy problems, no test image is released to the public. As the challenge is still under-going, we will keep on updating the top-ranked solutions as well as this report on the arxiv.
One-class Steel Detector Using Patch GAN Discriminator for Visualising Anomalous Feature Map
Jun 30, 2021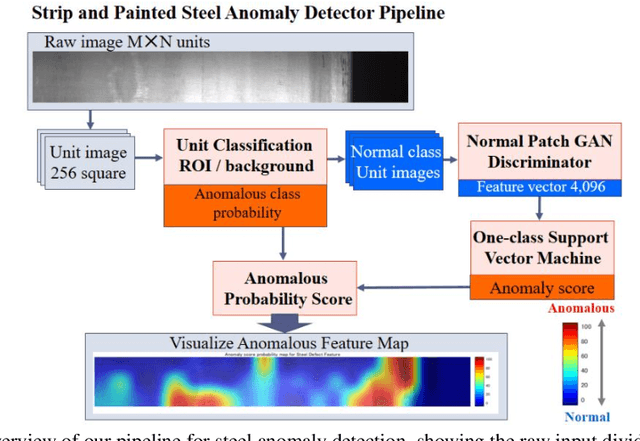

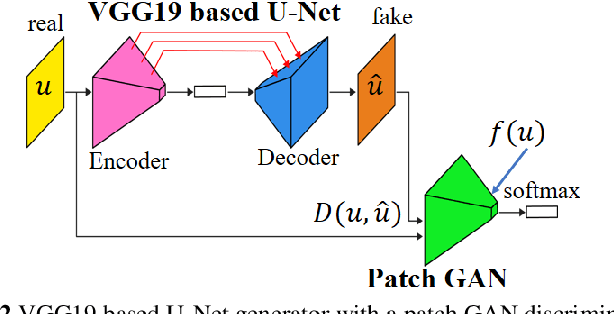
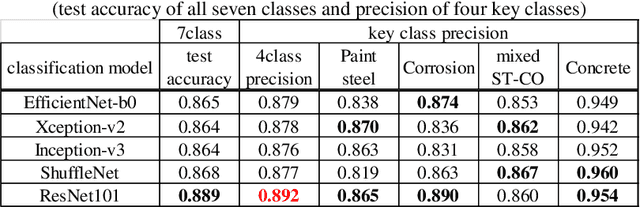
For steel product manufacturing in indoor factories, steel defect detection is important for quality control. For example, a steel sheet is extremely delicate, and must be accurately inspected. However, to maintain the painted steel parts of the infrastructure around a severe outdoor environment, corrosion detection is critical for predictive maintenance. In this paper, we propose a general-purpose application for steel anomaly detection that consists of the following four components. The first, a learner, is a unit image classification network to determine whether the region of interest or background has been recognised, after dividing the original large sized image into 256 square unit images. The second, an extractor, is a discriminator feature encoder based on a pre-trained steel generator with a patch generative adversarial network discriminator(GAN). The third, an anomaly detector, is a one-class support vector machine(SVM) to predict the anomaly score using the discriminator feature. The fourth, an indicator, is an anomalous probability map used to visually explain the anomalous features. Furthermore, we demonstrated our method through the inspection of steel sheet defects with 13,774 unit images using high-speed cameras, and painted steel corrosion with 19,766 unit images based on an eye inspection of the photographs. Finally, we visualise anomalous feature maps of steel using a strip and painted steel inspection dataset
Deployment of Deep Neural Networks for Object Detection on Edge AI Devices with Runtime Optimization
Aug 18, 2021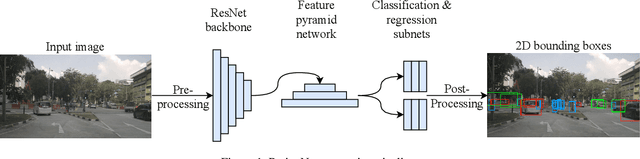

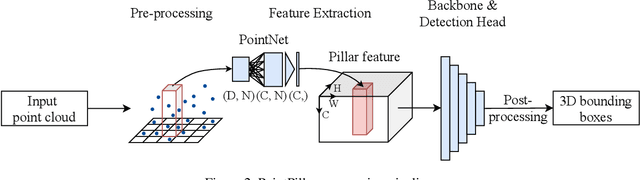
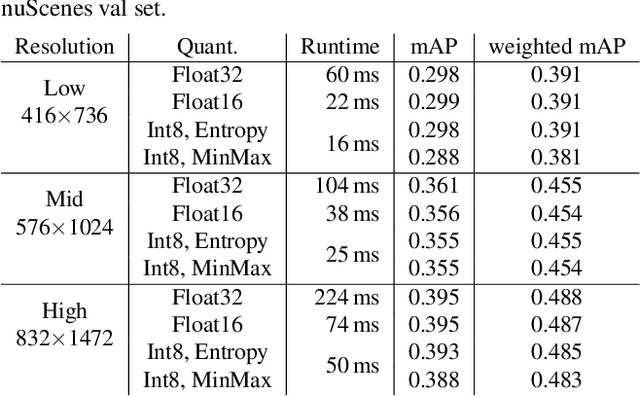
Deep neural networks have proven increasingly important for automotive scene understanding with new algorithms offering constant improvements of the detection performance. However, there is little emphasis on experiences and needs for deployment in embedded environments. We therefore perform a case study of the deployment of two representative object detection networks on an edge AI platform. In particular, we consider RetinaNet for image-based 2D object detection and PointPillars for LiDAR-based 3D object detection. We describe the modifications necessary to convert the algorithms from a PyTorch training environment to the deployment environment taking into account the available tools. We evaluate the runtime of the deployed DNN using two different libraries, TensorRT and TorchScript. In our experiments, we observe slight advantages of TensorRT for convolutional layers and TorchScript for fully connected layers. We also study the trade-off between runtime and performance, when selecting an optimized setup for deployment, and observe that quantization significantly reduces the runtime while having only little impact on the detection performance.