 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Countering Adversarial Examples: Combining Input Transformation and Noisy Training
Jun 25, 2021
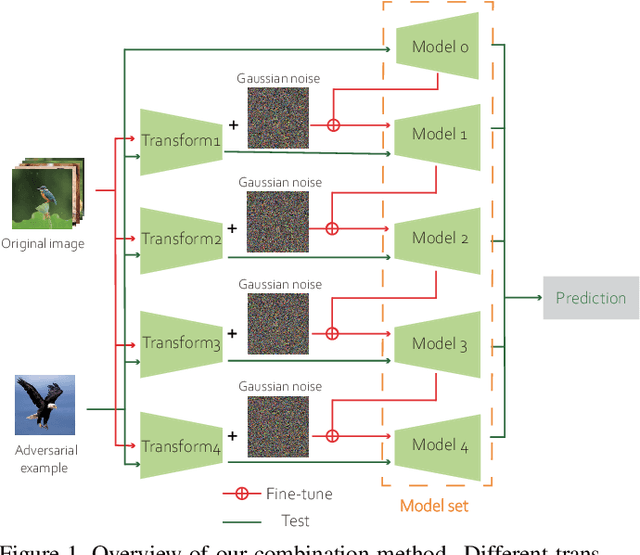
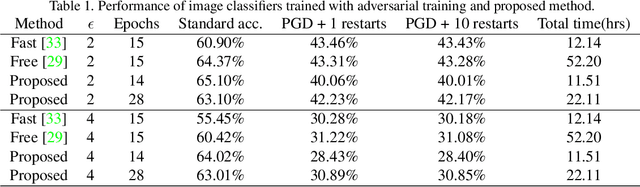
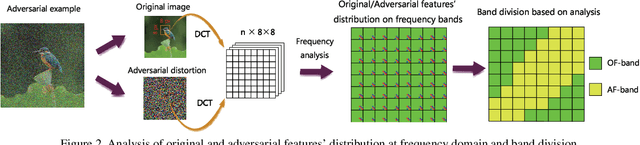
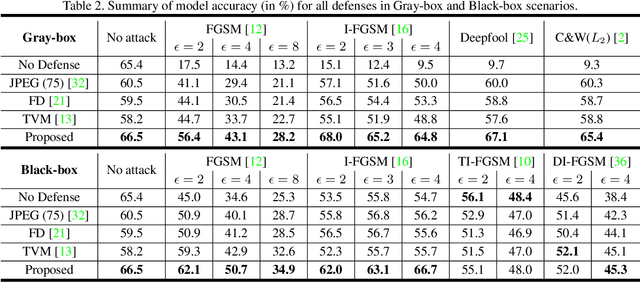
Recent studies have shown that neural network (NN) based image classifiers are highly vulnerable to adversarial examples, which poses a threat to security-sensitive image recognition task. Prior work has shown that JPEG compression can combat the drop in classification accuracy on adversarial examples to some extent. But, as the compression ratio increases, traditional JPEG compression is insufficient to defend those attacks but can cause an abrupt accuracy decline to the benign images. In this paper, with the aim of fully filtering the adversarial perturbations, we firstly make modifications to traditional JPEG compression algorithm which becomes more favorable for NN. Specifically, based on an analysis of the frequency coefficient, we design a NN-favored quantization table for compression. Considering compression as a data augmentation strategy, we then combine our model-agnostic preprocess with noisy training. We fine-tune the pre-trained model by training with images encoded at different compression levels, thus generating multiple classifiers. Finally, since lower (higher) compression ratio can remove both perturbations and original features slightly (aggressively), we use these trained multiple models for model ensemble. The majority vote of the ensemble of models is adopted as final predictions. Experiments results show our method can improve defense efficiency while maintaining original accuracy.
Deep HDR Hallucination for Inverse Tone Mapping
Jun 17, 2021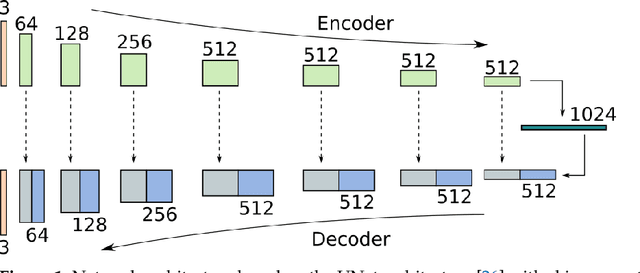
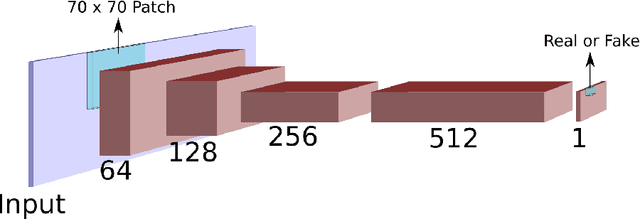
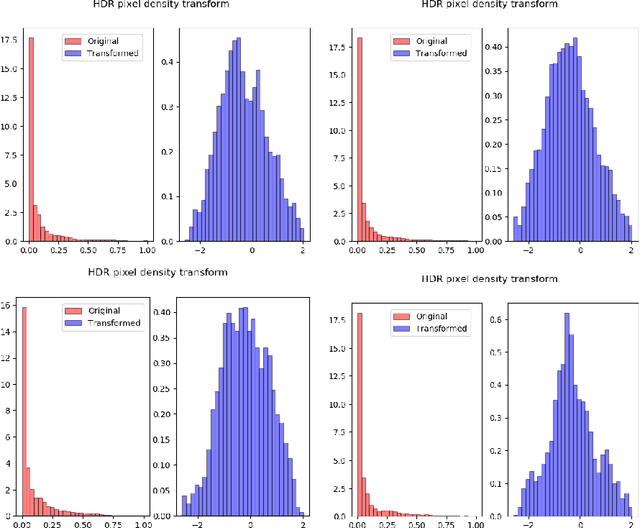

Inverse Tone Mapping (ITM) methods attempt to reconstruct High Dynamic Range (HDR) information from Low Dynamic Range (LDR) image content. The dynamic range of well-exposed areas must be expanded and any missing information due to over/under-exposure must be recovered (hallucinated). The majority of methods focus on the former and are relatively successful, while most attempts on the latter are not of sufficient quality, even ones based on Convolutional Neural Networks (CNNs). A major factor for the reduced inpainting quality in some works is the choice of loss function. Work based on Generative Adversarial Networks (GANs) shows promising results for image synthesis and LDR inpainting, suggesting that GAN losses can improve inverse tone mapping results. This work presents a GAN-based method that hallucinates missing information from badly exposed areas in LDR images and compares its efficacy with alternative variations. The proposed method is quantitatively competitive with state-of-the-art inverse tone mapping methods, providing good dynamic range expansion for well-exposed areas and plausible hallucinations for saturated and under-exposed areas. A density-based normalisation method, targeted for HDR content, is also proposed, as well as an HDR data augmentation method targeted for HDR hallucination.
MFuseNet: Robust Depth Estimation with Learned Multiscopic Fusion
Aug 06, 2021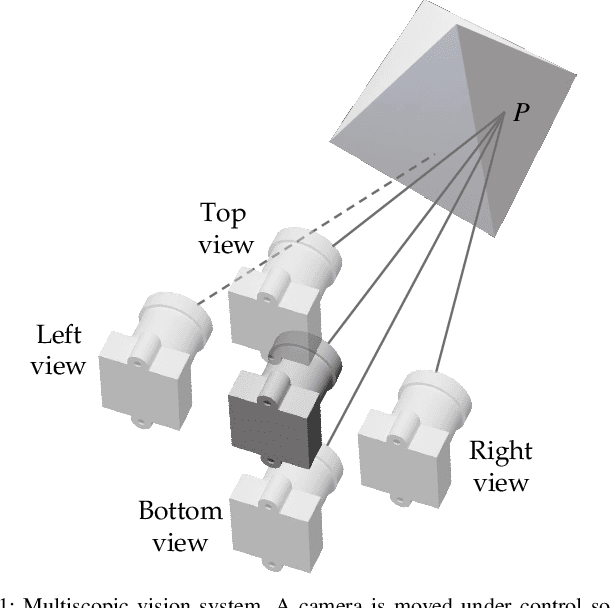

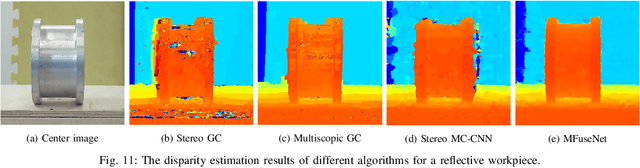
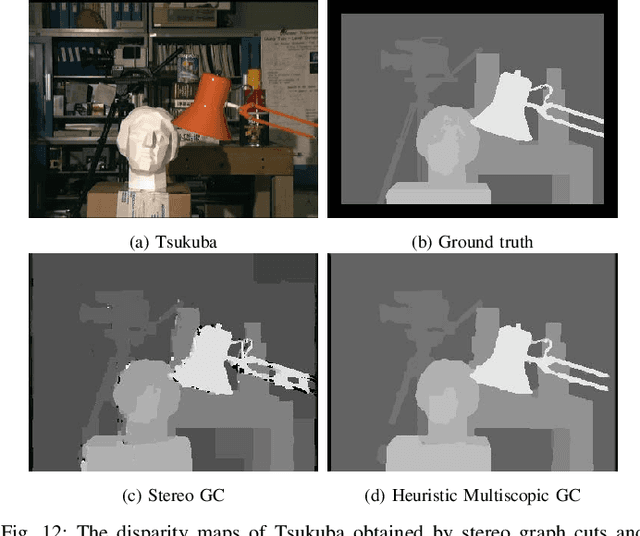
We design a multiscopic vision system that utilizes a low-cost monocular RGB camera to acquire accurate depth estimation. Unlike multi-view stereo with images captured at unconstrained camera poses, the proposed system controls the motion of a camera to capture a sequence of images in horizontally or vertically aligned positions with the same parallax. In this system, we propose a new heuristic method and a robust learning-based method to fuse multiple cost volumes between the reference image and its surrounding images. To obtain training data, we build a synthetic dataset with multiscopic images. The experiments on the real-world Middlebury dataset and real robot demonstration show that our multiscopic vision system outperforms traditional two-frame stereo matching methods in depth estimation. Our code and dataset are available at https://sites.google.com/view/multiscopic.
Deep Visual Reasoning: Learning to Predict Action Sequences for Task and Motion Planning from an Initial Scene Image
Jun 09, 2020
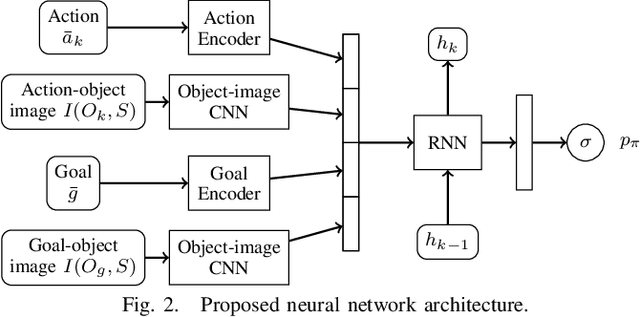
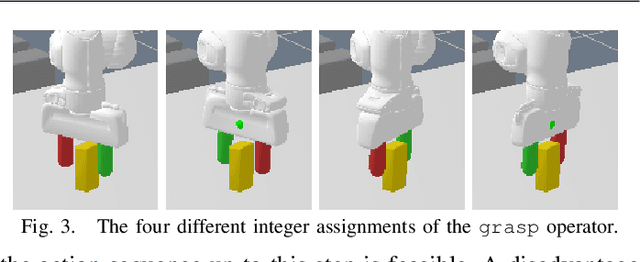
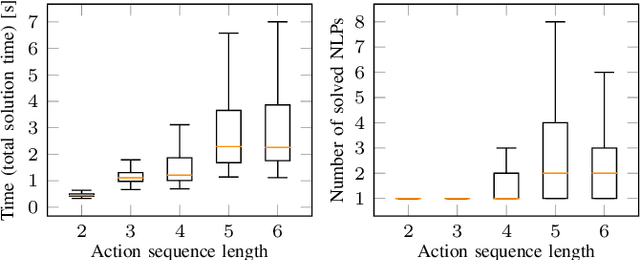
In this paper, we propose a deep convolutional recurrent neural network that predicts action sequences for task and motion planning (TAMP) from an initial scene image. Typical TAMP problems are formalized by combining reasoning on a symbolic, discrete level (e.g. first-order logic) with continuous motion planning such as nonlinear trajectory optimization. Due to the great combinatorial complexity of possible discrete action sequences, a large number of optimization/motion planning problems have to be solved to find a solution, which limits the scalability of these approaches. To circumvent this combinatorial complexity, we develop a neural network which, based on an initial image of the scene, directly predicts promising discrete action sequences such that ideally only one motion planning problem has to be solved to find a solution to the overall TAMP problem. A key aspect is that our method generalizes to scenes with many and varying number of objects, although being trained on only two objects at a time. This is possible by encoding the objects of the scene in images as input to the neural network, instead of a fixed feature vector. Results show runtime improvements of several magnitudes. Video: https://youtu.be/i8yyEbbvoEk
3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Apr 01, 2021
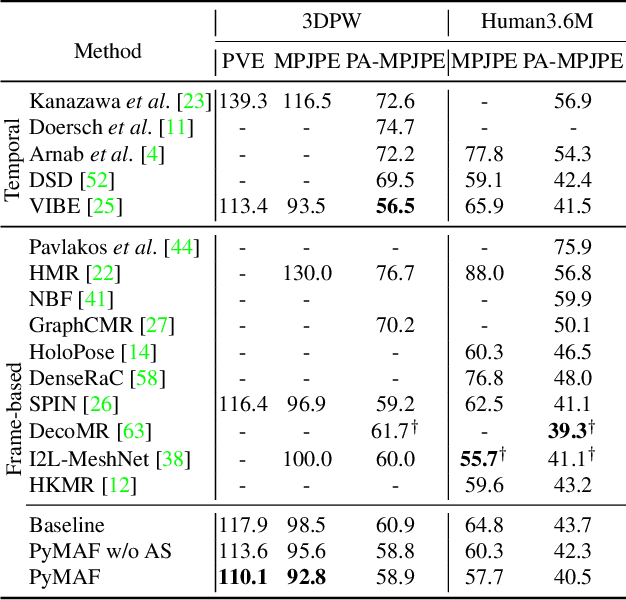
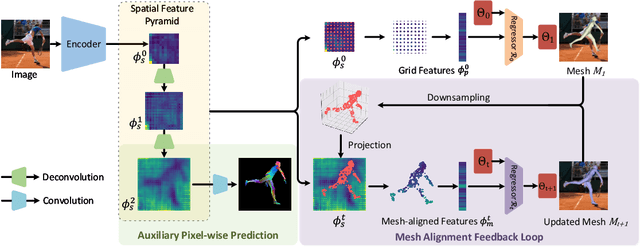
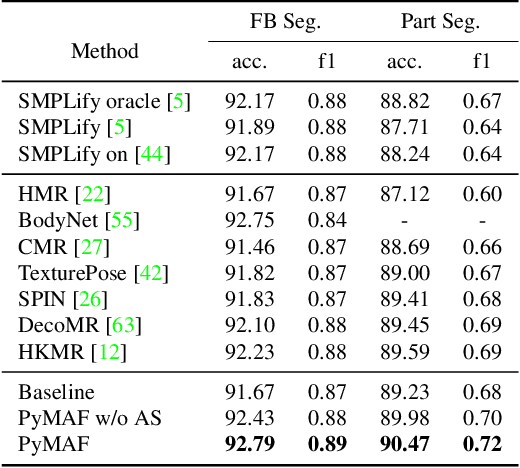
Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at https://hongwenzhang.github.io/pymaf .
Learning from Small Samples: Transformation-Invariant SVMs with Composition and Locality at Multiple Scales
Sep 28, 2021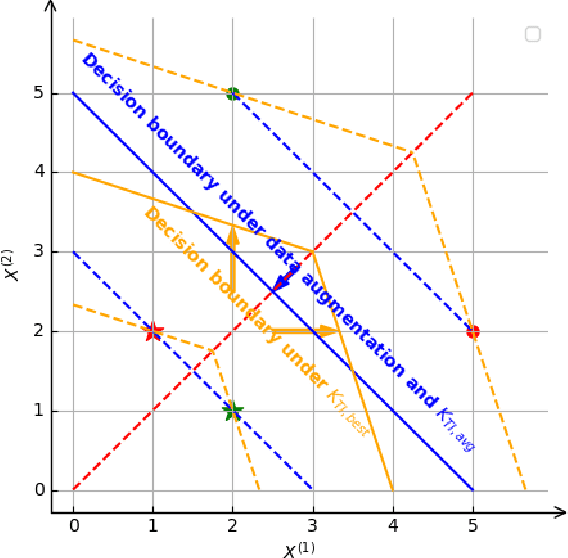
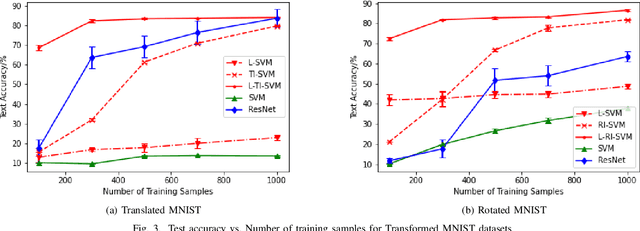

Motivated by the problem of learning when the number of training samples is small, this paper shows how to incorporate into support-vector machines (SVMs) those properties that have made convolutional neural networks (CNNs) successful. Particularly important is the ability to incorporate domain knowledge of invariances, e.g., translational invariance of images. Kernels based on the \textit{minimum} distance over a group of transformations, which corresponds to defining similarity as the \textit{best} over the possible transformations, are not generally positive definite. Perhaps it is for this reason that they have neither previously been experimentally tested for their performance nor studied theoretically. Instead, previous attempts have employed kernels based on the \textit{average} distance over a group of transformations, which are trivially positive definite, but which generally yield both poor margins as well as poor performance, as we show. We address this lacuna and show that positive definiteness indeed holds \textit{with high probability} for kernels based on the minimum distance in the small training sample set regime of interest, and that they do yield the best results in that regime. Another important property of CNNs is their ability to incorporate local features at multiple spatial scales, e.g., through max pooling. A third important property is their ability to provide the benefits of composition through the architecture of multiple layers. We show how these additional properties can also be embedded into SVMs. We verify through experiments on widely available image sets that the resulting SVMs do provide superior accuracy in comparison to well-established deep neural network (DNN) benchmarks for small sample sizes.
Click to Move: Controlling Video Generation with Sparse Motion
Aug 19, 2021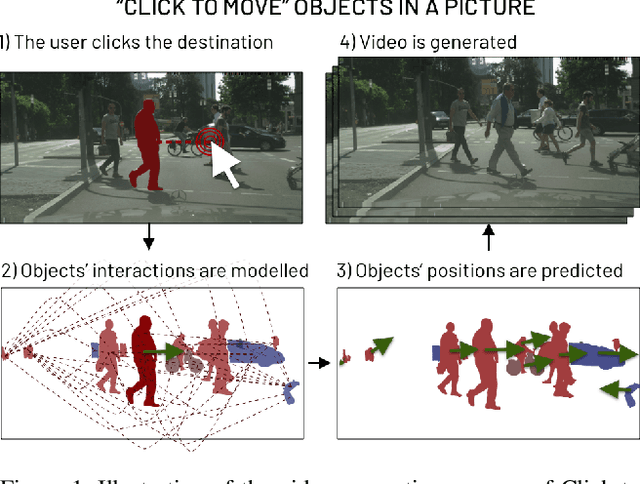
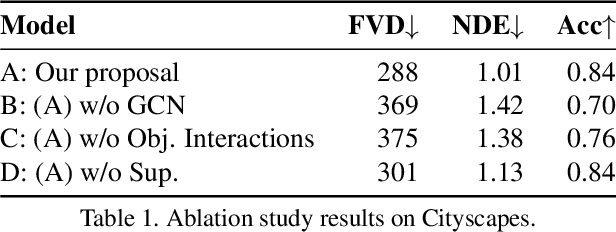
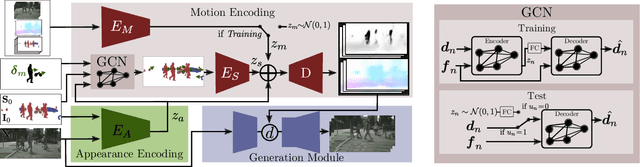
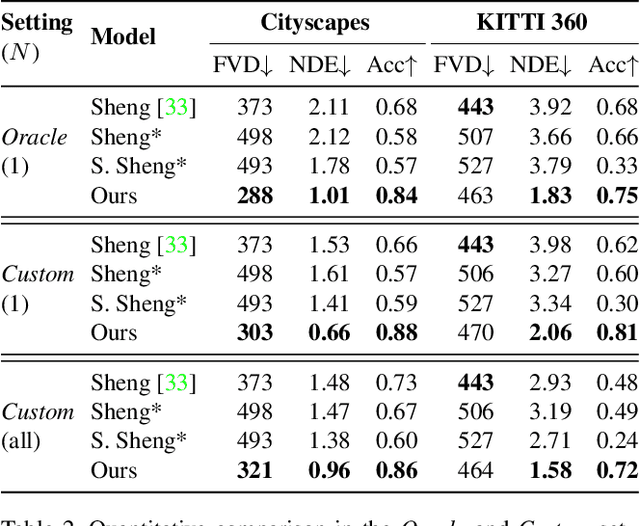
This paper introduces Click to Move (C2M), a novel framework for video generation where the user can control the motion of the synthesized video through mouse clicks specifying simple object trajectories of the key objects in the scene. Our model receives as input an initial frame, its corresponding segmentation map and the sparse motion vectors encoding the input provided by the user. It outputs a plausible video sequence starting from the given frame and with a motion that is consistent with user input. Notably, our proposed deep architecture incorporates a Graph Convolution Network (GCN) modelling the movements of all the objects in the scene in a holistic manner and effectively combining the sparse user motion information and image features. Experimental results show that C2M outperforms existing methods on two publicly available datasets, thus demonstrating the effectiveness of our GCN framework at modelling object interactions. The source code is publicly available at https://github.com/PierfrancescoArdino/C2M.
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Jun 24, 2021
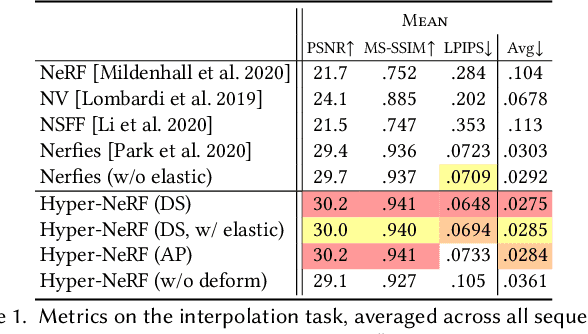
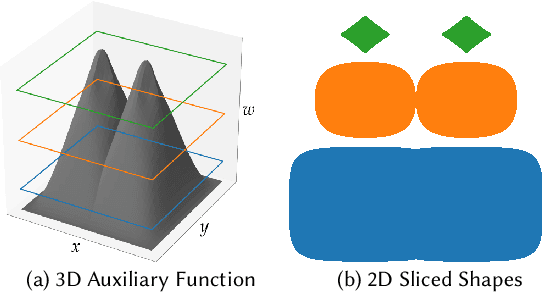
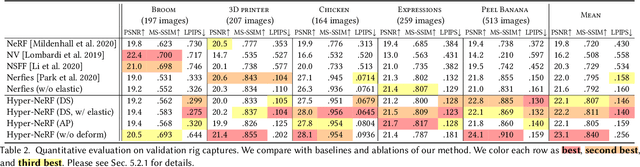
Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this "hyper-space". Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks by significant margins. Compared to Nerfies, HyperNeRF reduces average error rates by 8.6% for interpolation and 8.8% for novel-view synthesis, as measured by LPIPS.
Zero-Shot Open Set Detection by Extending CLIP
Sep 10, 2021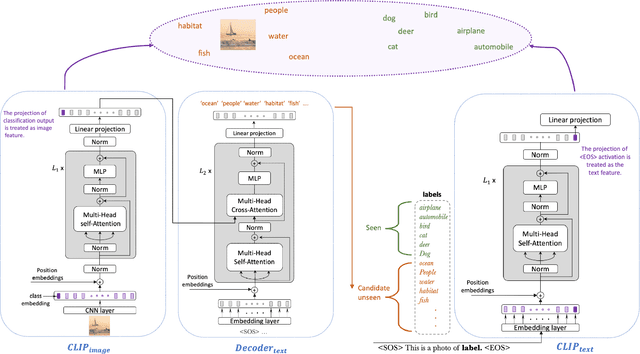
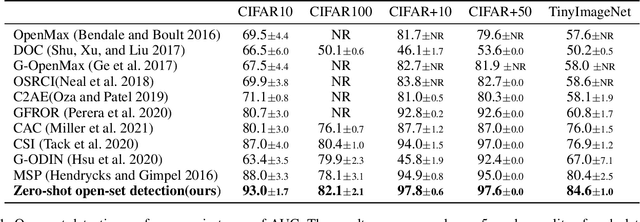
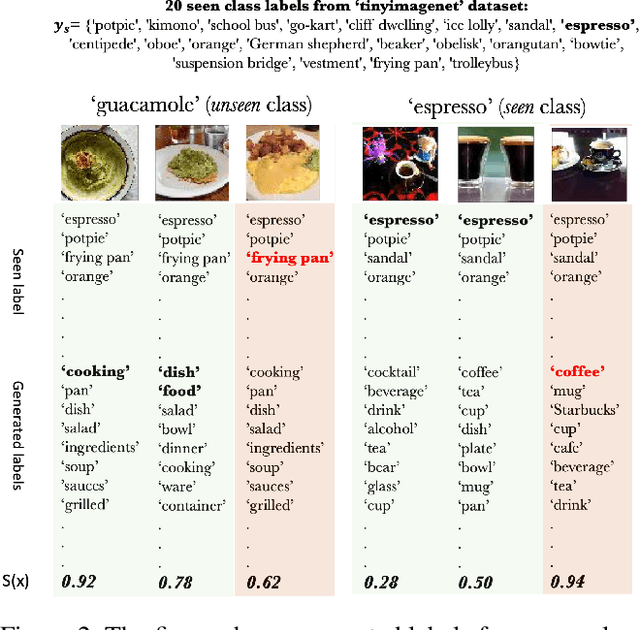
In a regular open set detection problem, samples of known classes (also called closed set classes) are used to train a special classifier. In testing, the classifier can (1) classify the test samples of known classes to their respective classes and (2) also detect samples that do not belong to any of the known classes (we say they belong to some unknown or open set classes). This paper studies the problem of zero-shot open-set detection, which still performs the same two tasks in testing but has no training except using the given known class names. This paper proposes a novel and yet simple method (called ZO-CLIP) to solve the problem. ZO-CLIP builds on top of the recent advances in zero-shot classification through multi-modal representation learning. It first extends the pre-trained multi-modal model CLIP by training a text-based image description generator on top of CLIP. In testing, it uses the extended model to generate some candidate unknown class names for each test sample and computes a confidence score based on both the known class names and candidate unknown class names for zero-shot open set detection. Experimental results on 5 benchmark datasets for open set detection confirm that ZO-CLIP outperforms the baselines by a large margin.
Variational Diffusion Models
Jul 01, 2021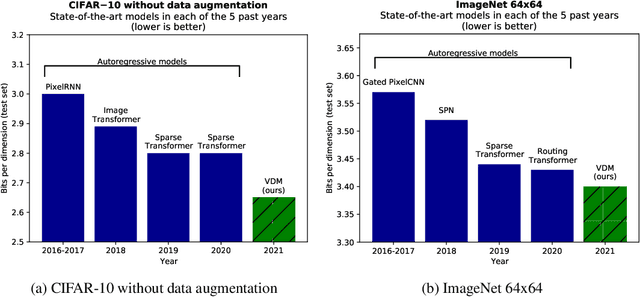
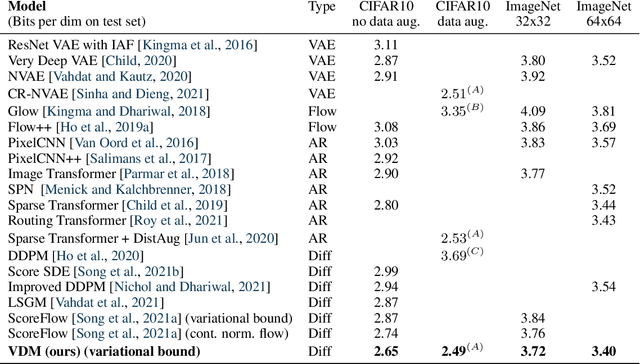

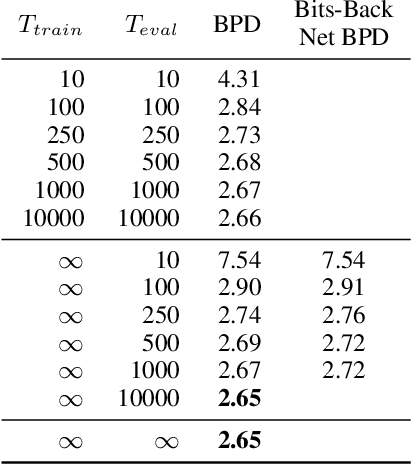
Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.