 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Cross-modal Contrastive Features for Video Domain Adaptation
Aug 26, 2021


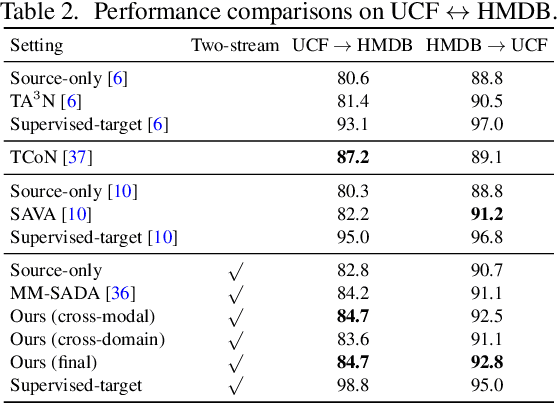
Learning transferable and domain adaptive feature representations from videos is important for video-relevant tasks such as action recognition. Existing video domain adaptation methods mainly rely on adversarial feature alignment, which has been derived from the RGB image space. However, video data is usually associated with multi-modal information, e.g., RGB and optical flow, and thus it remains a challenge to design a better method that considers the cross-modal inputs under the cross-domain adaptation setting. To this end, we propose a unified framework for video domain adaptation, which simultaneously regularizes cross-modal and cross-domain feature representations. Specifically, we treat each modality in a domain as a view and leverage the contrastive learning technique with properly designed sampling strategies. As a result, our objectives regularize feature spaces, which originally lack the connection across modalities or have less alignment across domains. We conduct experiments on domain adaptive action recognition benchmark datasets, i.e., UCF, HMDB, and EPIC-Kitchens, and demonstrate the effectiveness of our components against state-of-the-art algorithms.
A Pathology Deep Learning System Capable of Triage of Melanoma Specimens Utilizing Dermatopathologist Consensus as Ground Truth
Sep 15, 2021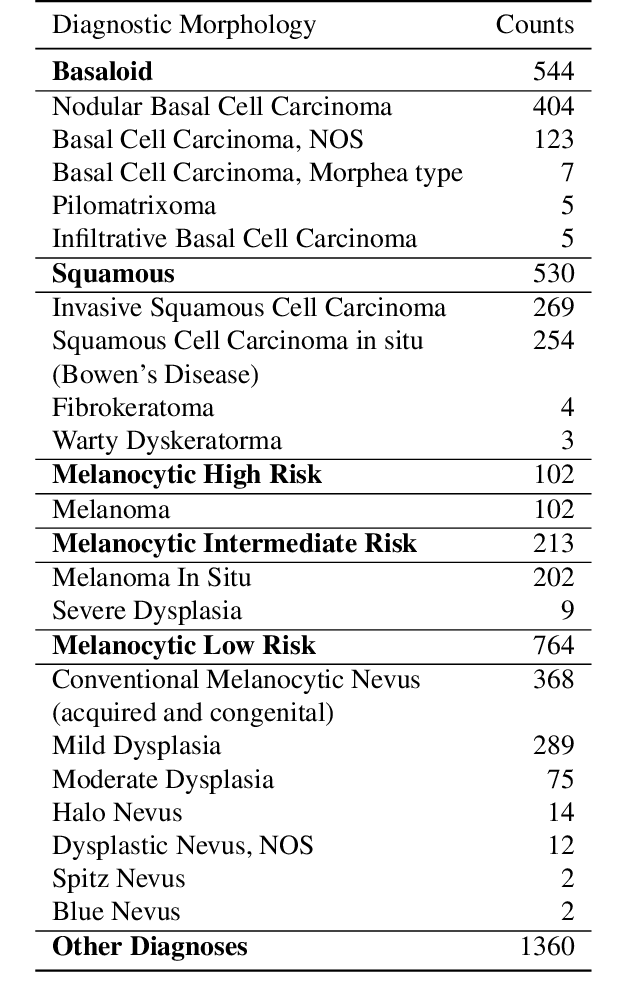
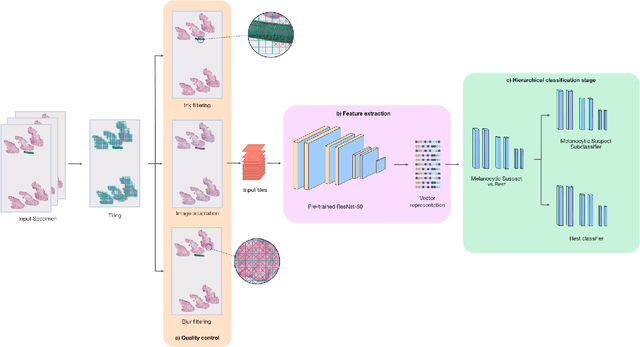
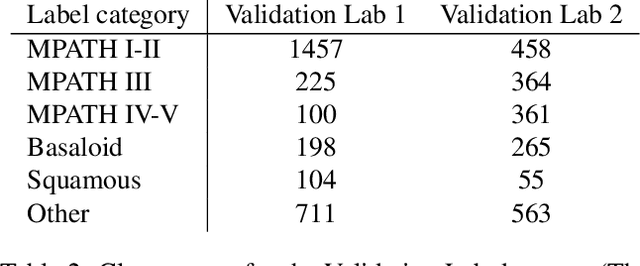
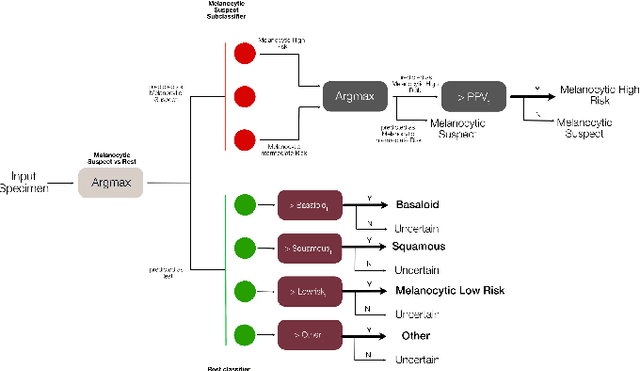
Although melanoma occurs more rarely than several other skin cancers, patients' long term survival rate is extremely low if the diagnosis is missed. Diagnosis is complicated by a high discordance rate among pathologists when distinguishing between melanoma and benign melanocytic lesions. A tool that allows pathology labs to sort and prioritize melanoma cases in their workflow could improve turnaround time by prioritizing challenging cases and routing them directly to the appropriate subspecialist. We present a pathology deep learning system (PDLS) that performs hierarchical classification of digitized whole slide image (WSI) specimens into six classes defined by their morphological characteristics, including classification of "Melanocytic Suspect" specimens likely representing melanoma or severe dysplastic nevi. We trained the system on 7,685 images from a single lab (the reference lab), including the the largest set of triple-concordant melanocytic specimens compiled to date, and tested the system on 5,099 images from two distinct validation labs. We achieved Area Underneath the ROC Curve (AUC) values of 0.93 classifying Melanocytic Suspect specimens on the reference lab, 0.95 on the first validation lab, and 0.82 on the second validation lab. We demonstrate that the PDLS is capable of automatically sorting and triaging skin specimens with high sensitivity to Melanocytic Suspect cases and that a pathologist would only need between 30% and 60% of the caseload to address all melanoma specimens.
LocTex: Learning Data-Efficient Visual Representations from Localized Textual Supervision
Aug 26, 2021



Computer vision tasks such as object detection and semantic/instance segmentation rely on the painstaking annotation of large training datasets. In this paper, we propose LocTex that takes advantage of the low-cost localized textual annotations (i.e., captions and synchronized mouse-over gestures) to reduce the annotation effort. We introduce a contrastive pre-training framework between images and captions and propose to supervise the cross-modal attention map with rendered mouse traces to provide coarse localization signals. Our learned visual features capture rich semantics (from free-form captions) and accurate localization (from mouse traces), which are very effective when transferred to various downstream vision tasks. Compared with ImageNet supervised pre-training, LocTex can reduce the size of the pre-training dataset by 10x or the target dataset by 2x while achieving comparable or even improved performance on COCO instance segmentation. When provided with the same amount of annotations, LocTex achieves around 4% higher accuracy than the previous state-of-the-art "vision+language" pre-training approach on the task of PASCAL VOC image classification.
Investigating Task-driven Latent Feasibility for Nonconvex Image Modeling
Oct 18, 2019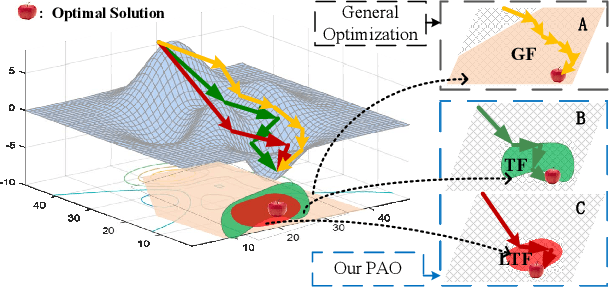


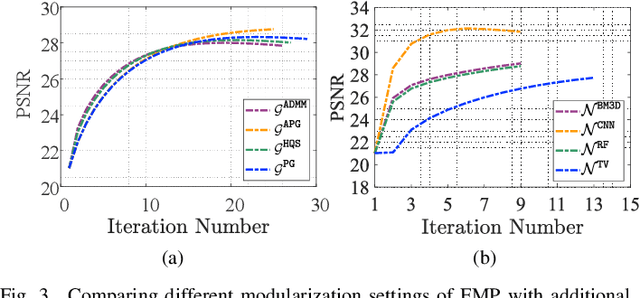
Properly modeling the latent image distributions always plays a key role in a variety of low-level vision problems. Most existing approaches, such as Maximum A Posterior (MAP), aimed at establishing optimization models with prior regularization to address this task. However, designing sophisticated priors may lead to challenging optimization model and time-consuming iteration process. Recent studies tried to embed learnable network architectures into the MAP scheme. Unfortunately, for the MAP model with deeply trained priors, the exact behaviors and the inference process are actually hard to investigate, due to their inexact and uncontrolled nature. In this work, by investigating task-driven latent feasibility for the MAP-based model, we provide a new perspective to enforce domain knowledge and data distributions to MAP-based image modeling. Specifically, we first introduce an energy-based feasibility constraint to the given MAP model. By introducing the proximal gradient updating scheme to the objective and performing an adaptive averaging process, we obtain a completely new MAP inference process, named Proximal Average Optimization (PAO), for image modeling. Owning to the flexibility of PAO, we can also incorporate deeply trained architectures into the feasibility module. Finally, we provide a simple monotone descent-based control mechanism to guide the propagation of PAO. We prove in theory that the sequence generated by both our PAO and its learning-based extension can successfully converge to the critical point of the original MAP optimization task. We demonstrate how to apply our framework to address different vision applications. Extensive experiments verify the theoretical results and show the advantages of our method against existing state-of-the-art approaches.
A Novel Hybrid Convolutional Neural Network for Accurate Organ Segmentation in 3D Head and Neck CT Images
Sep 26, 2021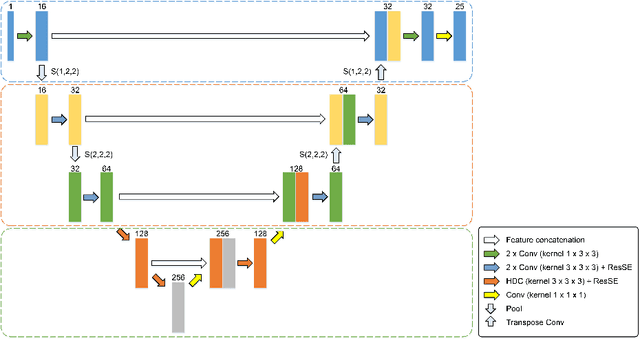


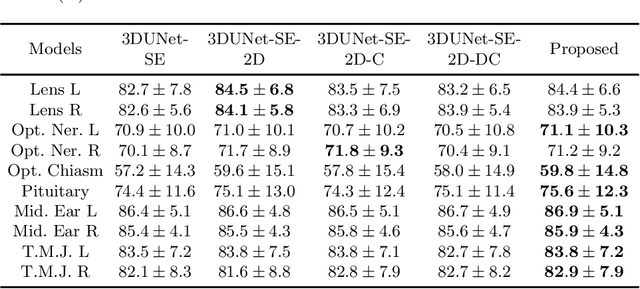
Radiation therapy (RT) is widely employed in the clinic for the treatment of head and neck (HaN) cancers. An essential step of RT planning is the accurate segmentation of various organs-at-risks (OARs) in HaN CT images. Nevertheless, segmenting OARs manually is time-consuming, tedious, and error-prone considering that typical HaN CT images contain tens to hundreds of slices. Automated segmentation algorithms are urgently required. Recently, convolutional neural networks (CNNs) have been extensively investigated on this task. Particularly, 3D CNNs are frequently adopted to process 3D HaN CT images. There are two issues with na\"ive 3D CNNs. First, the depth resolution of 3D CT images is usually several times lower than the in-plane resolution. Direct employment of 3D CNNs without distinguishing this difference can lead to the extraction of distorted image features and influence the final segmentation performance. Second, a severe class imbalance problem exists, and large organs can be orders of times larger than small organs. It is difficult to simultaneously achieve accurate segmentation for all the organs. To address these issues, we propose a novel hybrid CNN that fuses 2D and 3D convolutions to combat the different spatial resolutions and extract effective edge and semantic features from 3D HaN CT images. To accommodate large and small organs, our final model, named OrganNet2.5D, consists of only two instead of the classic four downsampling operations, and hybrid dilated convolutions are introduced to maintain the respective field. Experiments on the MICCAI 2015 challenge dataset demonstrate that OrganNet2.5D achieves promising performance compared to state-of-the-art methods.
Image Alignment in Unseen Domains via Domain Deep Generalization
May 31, 2019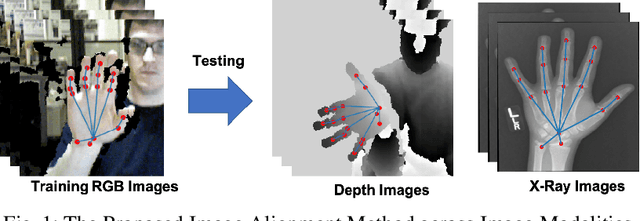
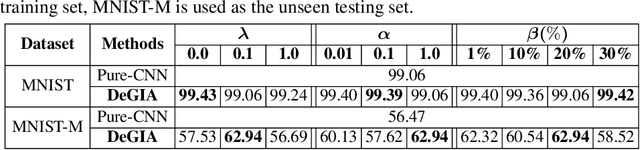
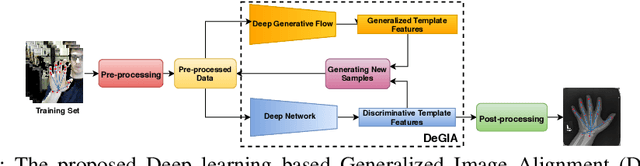
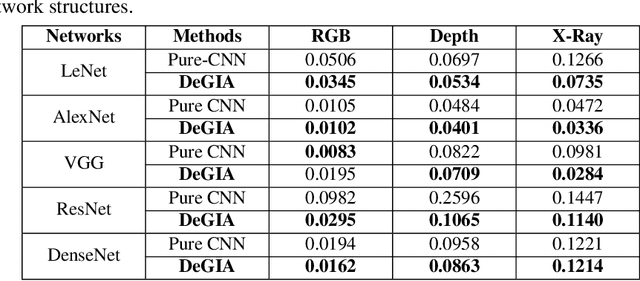
Image alignment across domains has recently become one of the realistic and popular topics in the research community. In this problem, a deep learning-based image alignment method is usually trained on an available largescale database. During the testing steps, this trained model is deployed on unseen images collected under different camera conditions and modalities. The delivered deep network models are unable to be updated, adapted or fine-tuned in these scenarios. Thus, recent deep learning techniques, e.g. domain adaptation, feature transferring, and fine-tuning, are unable to be deployed. This paper presents a novel deep learning based approach to tackle the problem of across unseen modalities. The proposed network is then applied to image alignment as an illustration. The proposed approach is designed as an end-to-end deep convolutional neural network to optimize the deep models to improve the performance. The proposed network has been evaluated in digit recognition when the model is trained on MNIST and then tested on unseen domain MNIST-M. Finally, the proposed method is benchmarked in image alignment problem when training on RGB images and testing on Depth and X-Ray images.
Masked Face Recognition Challenge: The InsightFace Track Report
Aug 18, 2021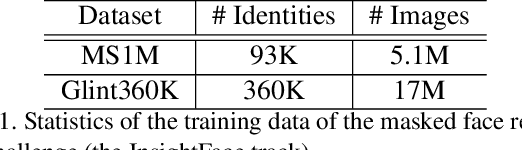

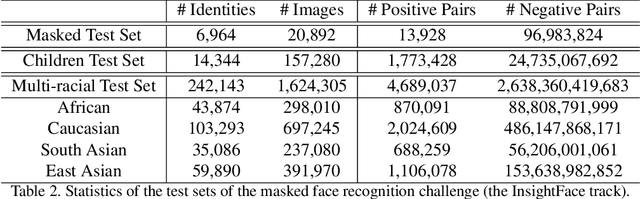
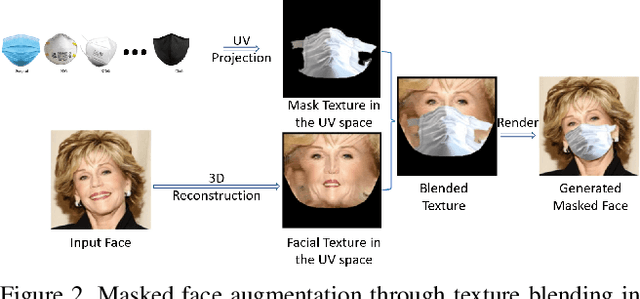
During the COVID-19 coronavirus epidemic, almost everyone wears a facial mask, which poses a huge challenge to deep face recognition. In this workshop, we organize Masked Face Recognition (MFR) challenge and focus on bench-marking deep face recognition methods under the existence of facial masks. In the MFR challenge, there are two main tracks: the InsightFace track and the WebFace260M track. For the InsightFace track, we manually collect a large-scale masked face test set with 7K identities. In addition, we also collect a children test set including 14K identities and a multi-racial test set containing 242K identities. By using these three test sets, we build up an online model testing system, which can give a comprehensive evaluation of face recognition models. To avoid data privacy problems, no test image is released to the public. As the challenge is still under-going, we will keep on updating the top-ranked solutions as well as this report on the arxiv.
BigEarthNet Deep Learning Models with A New Class-Nomenclature for Remote Sensing Image Understanding
Jan 17, 2020


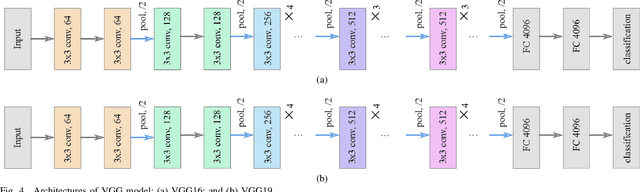
Success of deep neural networks in the framework of remote sensing (RS) image analysis depends on the availability of a high number of annotated images. BigEarthNet is a new large-scale Sentinel-2 benchmark archive that has been recently introduced in RS to advance deep learning (DL) studies. Each image patch in BigEarthNet is annotated with multi-labels provided by the CORINE Land Cover (CLC) map of 2018 based on its most thematic detailed Level-3 class nomenclature. BigEarthNet has enabled data-hungry DL algorithms to reach high performance in the context of multi-label RS image retrieval and classification. However, initial research demonstrates that some CLC classes are challenging to be accurately described by considering only (single-date) Sentinel-2 images. To further increase the effectiveness of BigEarthNet, in this paper we introduce an alternative class-nomenclature to allow DL models for better learning and describing the complex spatial and spectral information content of the Sentinel-2 images. This is achieved by interpreting and arranging the CLC Level-3 nomenclature based on the properties of Sentinel-2 images in a new nomenclature of 19 classes. Then, the new class-nomenclature of BigEarthNet is used within state-of-the-art DL models (namely VGG model at the depth of 16 and 19 layers [VGG16 and VGG19] and ResNet model at the depth of 50, 101 and 152 layers [ResNet50, ResNet101, ResNet152] as well as K-Branch CNN model) in the context of multi-label classification. Experimental results show that the models trained from scratch on BigEarthNet outperform those pre-trained on ImageNet, especially in relation to some complex classes including agriculture and other vegetated and natural environments. All DL models are made publicly available, offering an important resource to guide future progress on content based image retrieval and scene classification problems in RS.
Towards Fully Automated Segmentation of Rat Cardiac MRI by Leveraging Deep Learning Frameworks
Sep 09, 2021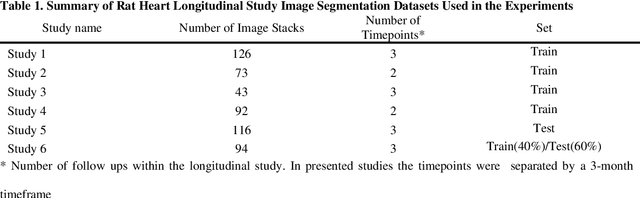
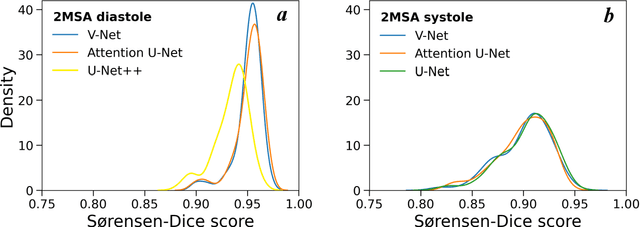

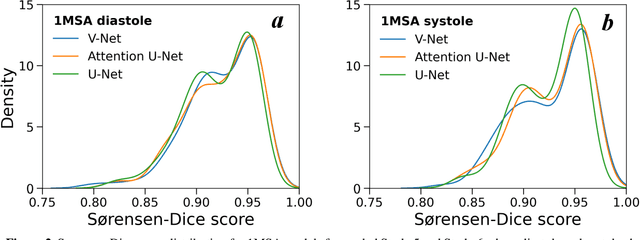
Automated segmentation of human cardiac magnetic resonance datasets has been steadily improving during recent years. However, these methods are not directly applicable in preclinical context due to limited datasets and lower image resolution. Successful application of deep architectures for rat cardiac segmentation, although of critical importance for preclinical evaluation of cardiac function, has to our knowledge not yet been reported. We developed segmentation models that expand on the standard U-Net architecture and evaluated separate models for systole and diastole phases, 2MSA, and one model for all timepoints, 1MSA. Furthermore, we calibrated model outputs using a Gaussian Process (GP)-based prior to improve phase selection. Resulting models approach human performance in terms of left ventricular segmentation quality and ejection fraction (EF) estimation in both 1MSA and 2MSA settings (S{\o}rensen-Dice score 0.91 +/- 0.072 and 0.93 +/- 0.032, respectively). 2MSA achieved a mean absolute difference between estimated and reference EF of 3.5 +/- 2.5 %, while 1MSA resulted in 4.1 +/- 3.0 %. Applying Gaussian Processes to 1MSA allows to automate the selection of systole and diastole phases. Combined with a novel cardiac phase selection strategy, our work presents an important first step towards a fully automated segmentation pipeline in the context of rat cardiac analysis.
Deployment of Deep Neural Networks for Object Detection on Edge AI Devices with Runtime Optimization
Aug 18, 2021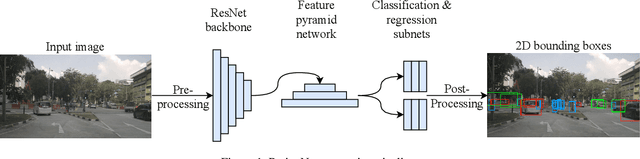

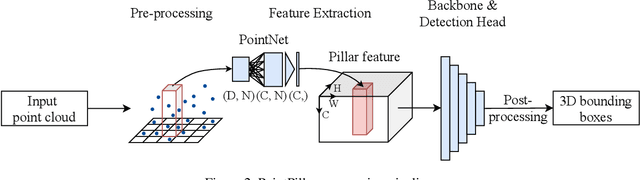
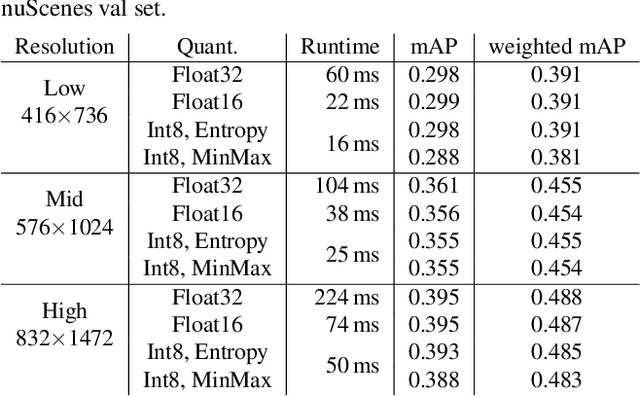
Deep neural networks have proven increasingly important for automotive scene understanding with new algorithms offering constant improvements of the detection performance. However, there is little emphasis on experiences and needs for deployment in embedded environments. We therefore perform a case study of the deployment of two representative object detection networks on an edge AI platform. In particular, we consider RetinaNet for image-based 2D object detection and PointPillars for LiDAR-based 3D object detection. We describe the modifications necessary to convert the algorithms from a PyTorch training environment to the deployment environment taking into account the available tools. We evaluate the runtime of the deployed DNN using two different libraries, TensorRT and TorchScript. In our experiments, we observe slight advantages of TensorRT for convolutional layers and TorchScript for fully connected layers. We also study the trade-off between runtime and performance, when selecting an optimized setup for deployment, and observe that quantization significantly reduces the runtime while having only little impact on the detection performance.