 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Integrated Construction of Multimodal Atlases with Structural Connectomes in the Space of Riemannian Metrics
Sep 20, 2021
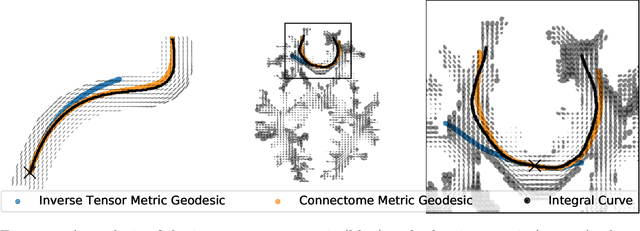

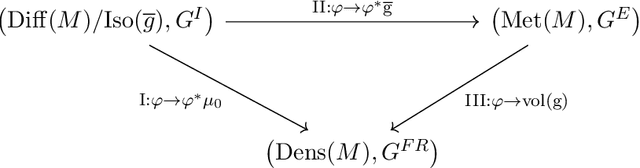
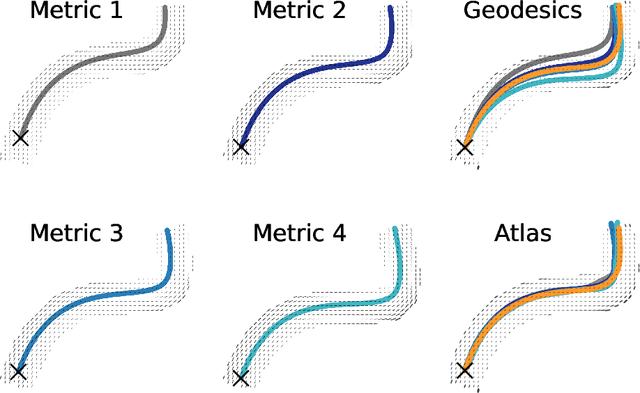
The structural network of the brain, or structural connectome, can be represented by fiber bundles generated by a variety of tractography methods. While such methods give qualitative insights into brain structure, there is controversy over whether they can provide quantitative information, especially at the population level. In order to enable population-level statistical analysis of the structural connectome, we propose representing a connectome as a Riemannian metric, which is a point on an infinite-dimensional manifold. We equip this manifold with the Ebin metric, a natural metric structure for this space, to get a Riemannian manifold along with its associated geometric properties. We then use this Riemannian framework to apply object-oriented statistical analysis to define an atlas as the Fr\'echet mean of a population of Riemannian metrics. This formulation ties into the existing framework for diffeomorphic construction of image atlases, allowing us to construct a multimodal atlas by simultaneously integrating complementary white matter structure details from DWMRI and cortical details from T1-weighted MRI. We illustrate our framework with 2D data examples of connectome registration and atlas formation. Finally, we build an example 3D multimodal atlas using T1 images and connectomes derived from diffusion tensors estimated from a subset of subjects from the Human Connectome Project.
Multiple instance dense connected convolution neural network for aerial image scene classification
Aug 22, 2019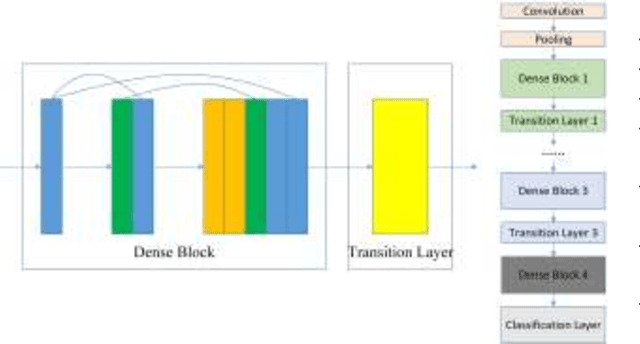
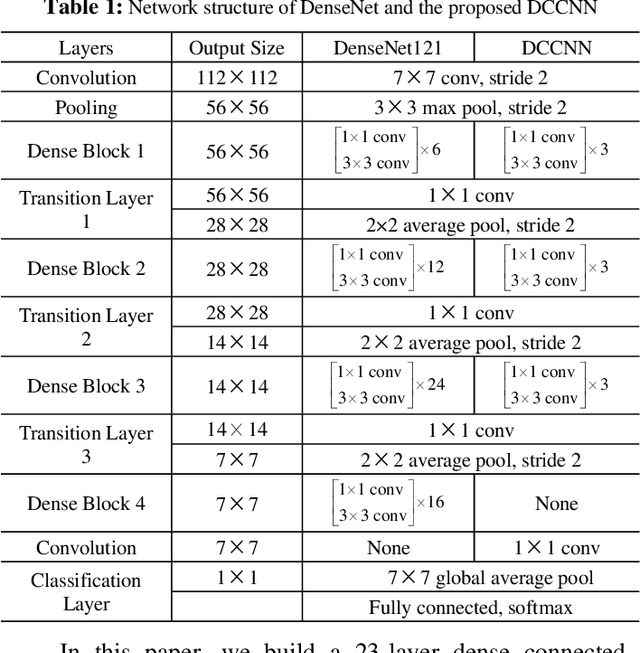
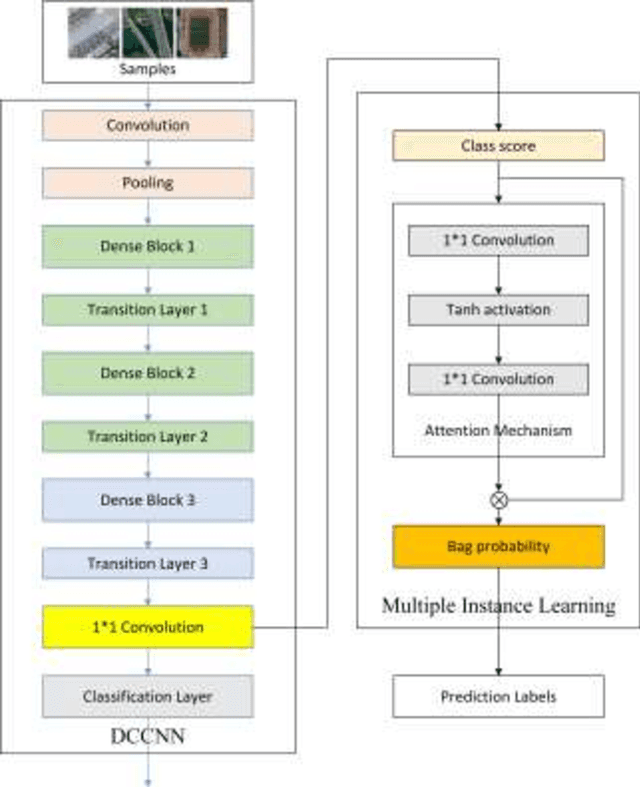
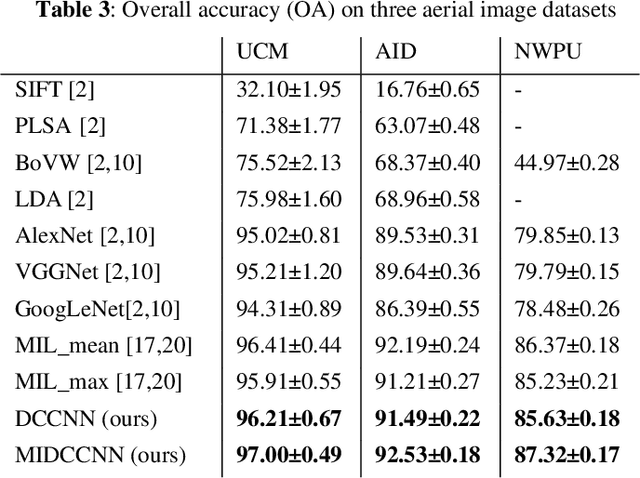
With the development of deep learning, many state-of-the-art natural image scene classification methods have demonstrated impressive performance. While the current convolution neural network tends to extract global features and global semantic information in a scene, the geo-spatial objects can be located at anywhere in an aerial image scene and their spatial arrangement tends to be more complicated. One possible solution is to preserve more local semantic information and enhance feature propagation. In this paper, an end to end multiple instance dense connected convolution neural network (MIDCCNN) is proposed for aerial image scene classification. First, a 23 layer dense connected convolution neural network (DCCNN) is built and served as a backbone to extract convolution features. It is capable of preserving middle and low level convolution features. Then, an attention based multiple instance pooling is proposed to highlight the local semantics in an aerial image scene. Finally, we minimize the loss between the bag-level predictions and the ground truth labels so that the whole framework can be trained directly. Experiments on three aerial image datasets demonstrate that our proposed methods can outperform current baselines by a large margin.
DeepImageSpam: Deep Learning based Image Spam Detection
Oct 03, 2018
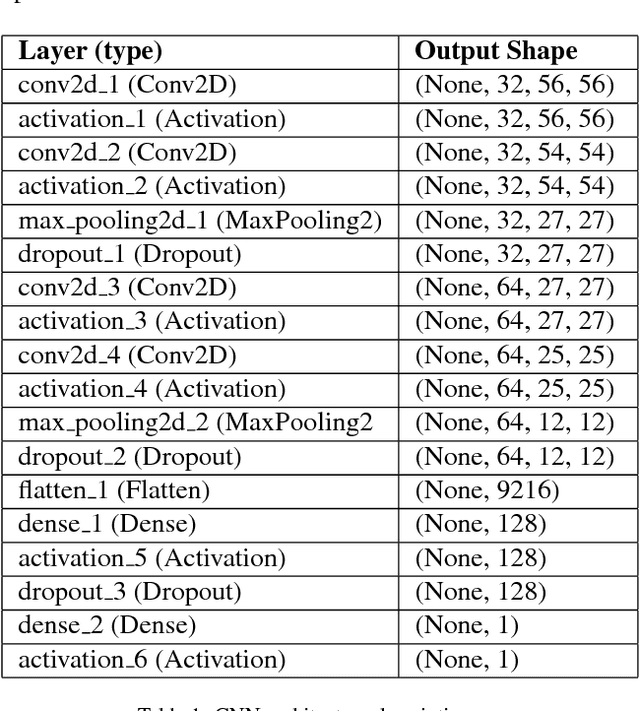

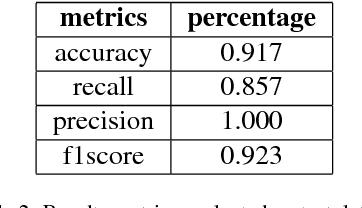
Hackers and spammers are employing innovative and novel techniques to deceive novice and even knowledgeable internet users. Image spam is one of such technique where the spammer varies and changes some portion of the image such that it is indistinguishable from the original image fooling the users. This paper proposes a deep learning based approach for image spam detection using the convolutional neural networks which uses a dataset with 810 natural images and 928 spam images for classification achieving an accuracy of 91.7% outperforming the existing image processing and machine learning techniques
Underwater Image Super-Resolution using Deep Residual Multipliers
Sep 20, 2019

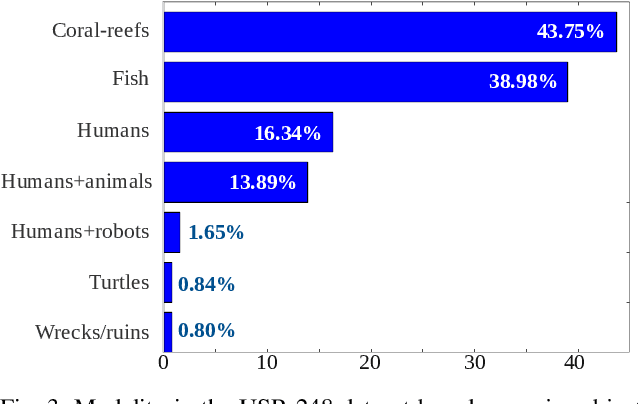
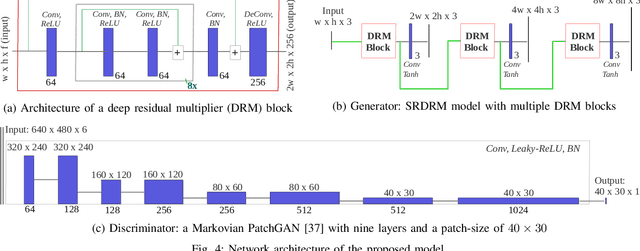
We present a deep residual network-based generative model for single image super-resolution (SISR) of underwater imagery for use by autonomous underwater robots. We also provide an adversarial training pipeline for learning SISR from paired data. In order to supervise the training, we formulate an objective function that evaluates the perceptual quality of an image based on its global content, color, and local style information. Additionally, we present USR-248, a large-scale dataset of three sets of underwater images of high (640x480) and low (80x60, 160x120, and 320x240) resolution. USR-248 contains over 7K paired instances in each set of data for supervised training of 2x, 4x, or 8x SISR models. Furthermore, we validate the effectiveness of our proposed model through qualitative and quantitative experiments and compare the results with several state-of-the-art models' performances. We also analyze its practical feasibility for applications such as scene understanding and attention modeling in noisy visual conditions.
Camera-Tracklet-Aware Contrastive Learning for Unsupervised Vehicle Re-Identification
Sep 14, 2021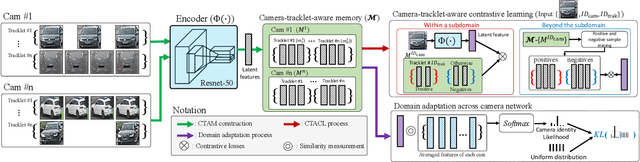
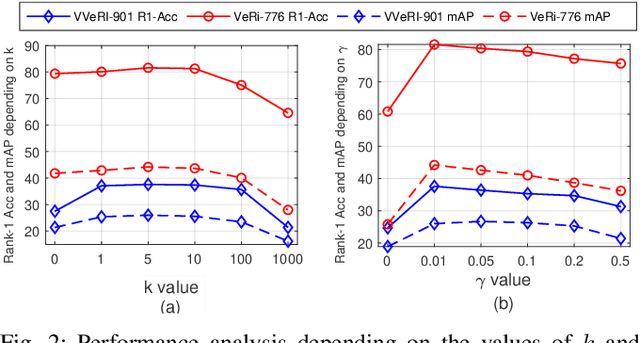
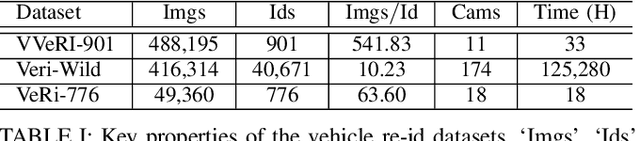
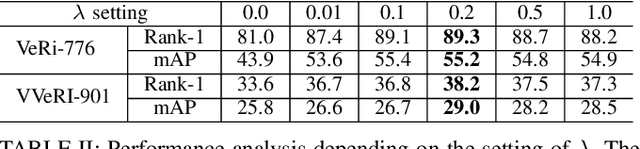
Recently, vehicle re-identification methods based on deep learning constitute remarkable achievement. However, this achievement requires large-scale and well-annotated datasets. In constructing the dataset, assigning globally available identities (Ids) to vehicles captured from a great number of cameras is labour-intensive, because it needs to consider their subtle appearance differences or viewpoint variations. In this paper, we propose camera-tracklet-aware contrastive learning (CTACL) using the multi-camera tracklet information without vehicle identity labels. The proposed CTACL divides an unlabelled domain, i.e., entire vehicle images, into multiple camera-level subdomains and conducts contrastive learning within and beyond the subdomains. The positive and negative samples for contrastive learning are defined using tracklet Ids of each camera. Additionally, the domain adaptation across camera networks is introduced to improve the generalisation performance of learnt representations and alleviate the performance degradation resulted from the domain gap between the subdomains. We demonstrate the effectiveness of our approach on video-based and image-based vehicle Re-ID datasets. Experimental results show that the proposed method outperforms the recent state-of-the-art unsupervised vehicle Re-ID methods. The source code for this paper is publicly available on `https://github.com/andreYoo/CTAM-CTACL-VVReID.git'.
Adversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors
Jun 12, 2020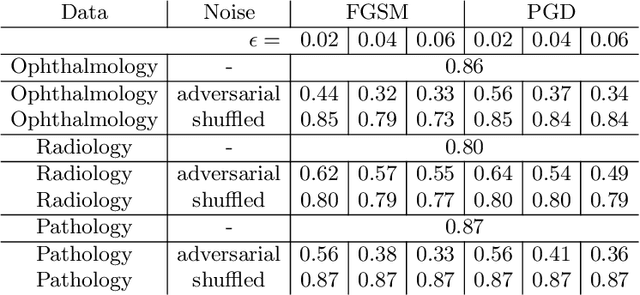
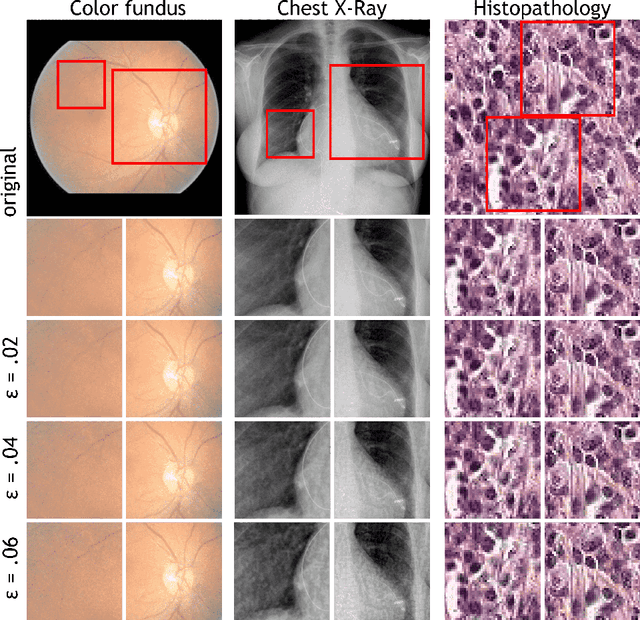
Adversarial attacks are considered a potentially serious security threat for machine learning systems. Medical image analysis (MedIA) systems have recently been argued to be particularly vulnerable to adversarial attacks due to strong financial incentives. In this paper, we study several previously unexplored factors affecting adversarial attack vulnerability of deep learning MedIA systems in three medical domains: ophthalmology, radiology and pathology. Firstly, we study the effect of varying the degree of adversarial perturbation on the attack performance and its visual perceptibility. Secondly, we study how pre-training on a public dataset (ImageNet) affects the models' vulnerability to attacks. Thirdly, we study the influence of data and model architecture disparity between target and attacker models. Our experiments show that the degree of perturbation significantly affects both performance and human perceptibility of attacks. Pre-training may dramatically increase the transfer of adversarial examples; the larger the performance gain achieved by pre-training, the larger the transfer. Finally, disparity in data and/or model architecture between target and attacker models substantially decreases the success of attacks. We believe that these factors should be considered when designing cybersecurity-critical MedIA systems, as well as kept in mind when evaluating their vulnerability to adversarial attacks.
Transductive Zero-Shot Hashing for Multi-Label Image Retrieval
Nov 17, 2019
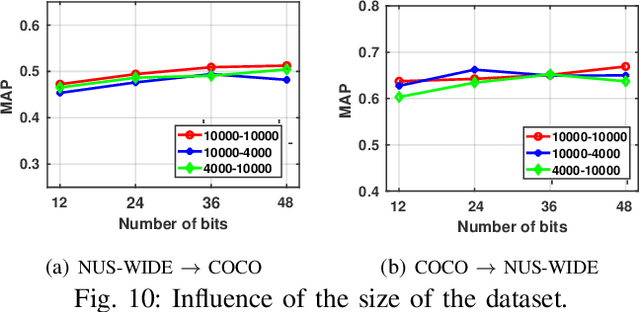
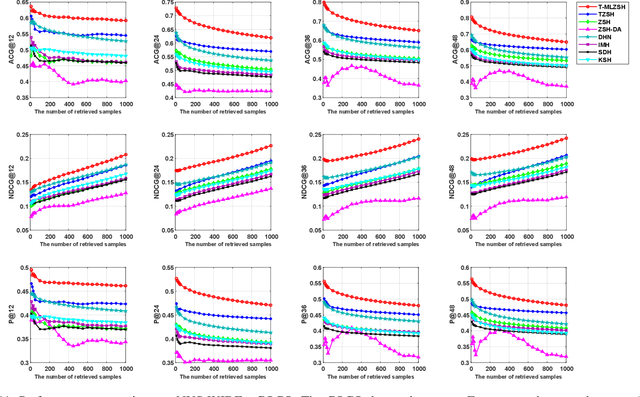
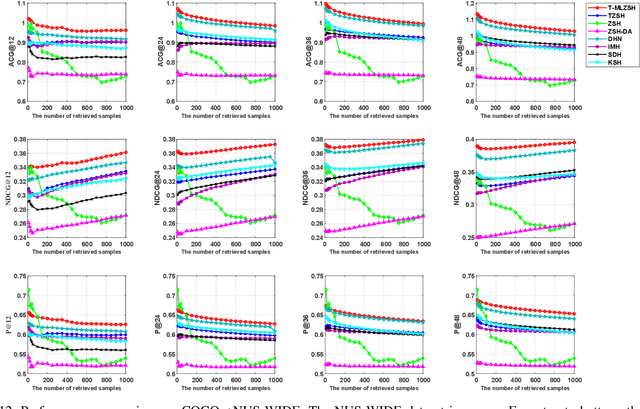
Hash coding has been widely used in approximate nearest neighbor search for large-scale image retrieval. Given semantic annotations such as class labels and pairwise similarities of the training data, hashing methods can learn and generate effective and compact binary codes. While some newly introduced images may contain undefined semantic labels, which we call unseen images, zeor-shot hashing techniques have been studied. However, existing zeor-shot hashing methods focus on the retrieval of single-label images, and cannot handle multi-label images. In this paper, for the first time, a novel transductive zero-shot hashing method is proposed for multi-label unseen image retrieval. In order to predict the labels of the unseen/target data, a visual-semantic bridge is built via instance-concept coherence ranking on the seen/source data. Then, pairwise similarity loss and focal quantization loss are constructed for training a hashing model using both the seen/source and unseen/target data. Extensive evaluations on three popular multi-label datasets demonstrate that, the proposed hashing method achieves significantly better results than the competing methods.
Danish Fungi 2020 -- Not Just Another Image Recognition Dataset
Mar 22, 2021
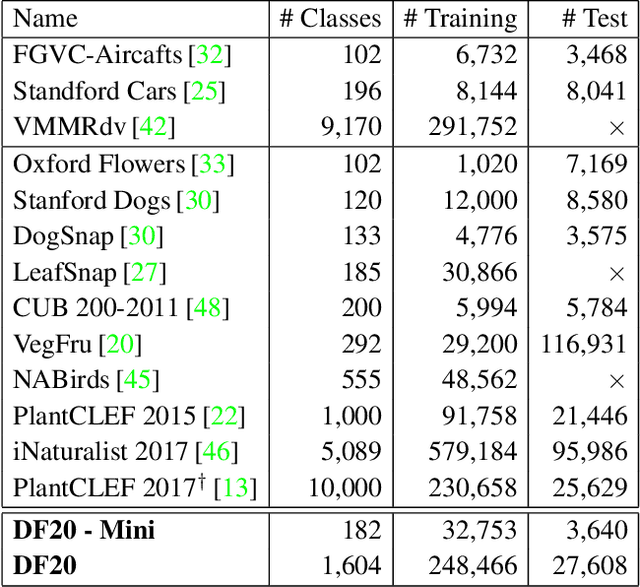
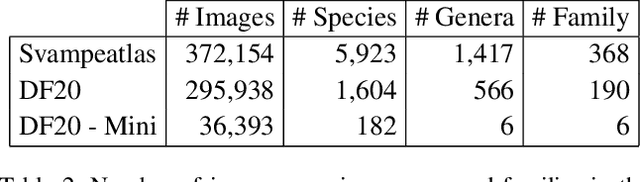
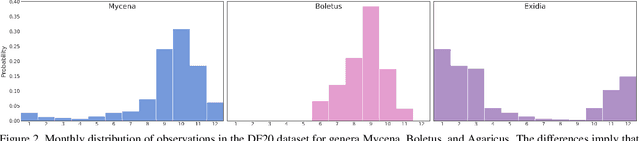
We introduce a novel fine-grained dataset and benchmark, the Danish Fungi 2020 (DF20). The dataset, constructed from observations submitted to the Danish Fungal Atlas, is unique in its taxonomy-accurate class labels, small number of errors, highly unbalanced long-tailed class distribution, rich observation metadata, and well-defined class hierarchy. DF20 has zero overlap with ImageNet, allowing unbiased comparison of models fine-tuned from publicly available ImageNet checkpoints. The proposed evaluation protocol enables testing the ability to improve classification using metadata -- e.g. precise geographic location, habitat, and substrate, facilitates classifier calibration testing, and finally allows to study the impact of the device settings on the classification performance. Experiments using Convolutional Neural Networks (CNN) and the recent Vision Transformers (ViT) show that DF20 presents a challenging task. Interestingly, ViT achieves results superior to CNN baselines with 81.25% accuracy, reducing the CNN error by 13%. A baseline procedure for including metadata into the decision process improves the classification accuracy by more than 3.5 percentage points, reducing the error rate by 20%. The source code for all methods and experiments is available at https://sites.google.com/view/danish-fungi-dataset.
False Negative Reduction in Video Instance Segmentation using Uncertainty Estimates
Jun 28, 2021

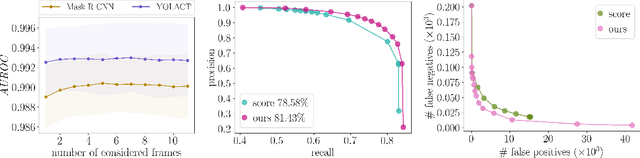
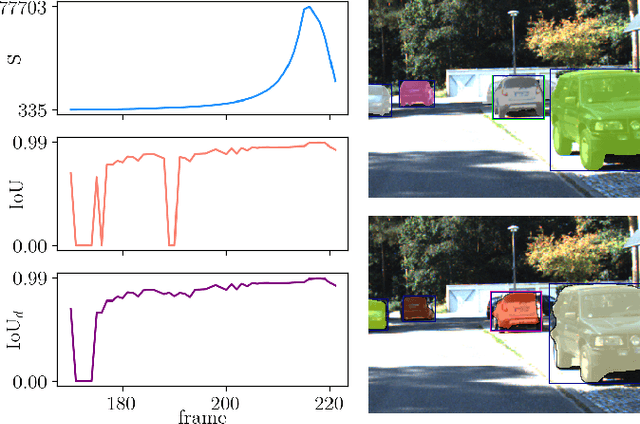
Instance segmentation of images is an important tool for automated scene understanding. Neural networks are usually trained to optimize their overall performance in terms of accuracy. Meanwhile, in applications such as automated driving, an overlooked pedestrian seems more harmful than a falsely detected one. In this work, we present a false negative detection method for image sequences based on inconsistencies in time series of tracked instances given the availability of image sequences in online applications. As the number of instances can be greatly increased by this algorithm, we apply a false positive pruning using uncertainty estimates aggregated over instances. To this end, instance-wise metrics are constructed which characterize uncertainty and geometry of a given instance or are predicated on depth estimation. The proposed method serves as a post-processing step applicable to any neural network that can also be trained on single frames only. In our tests, we obtain an improved trade-off between false negative and false positive instances by our fused detection approach in comparison to the use of an ordinary score value provided by the instance segmentation network during inference.
Bridging the Gap between Events and Frames through Unsupervised Domain Adaptation
Sep 06, 2021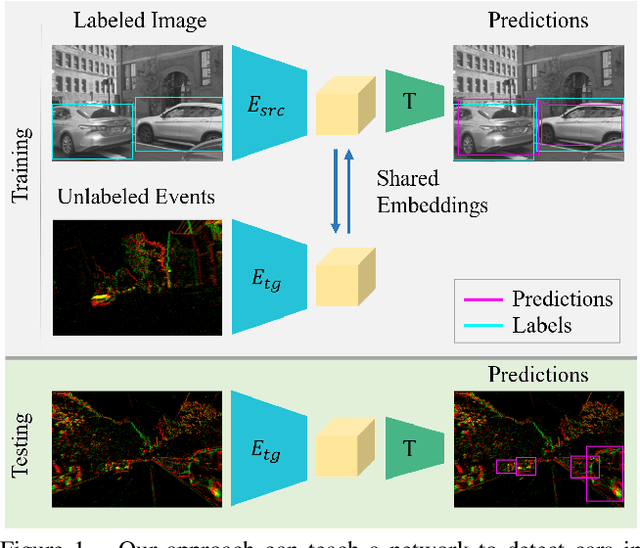
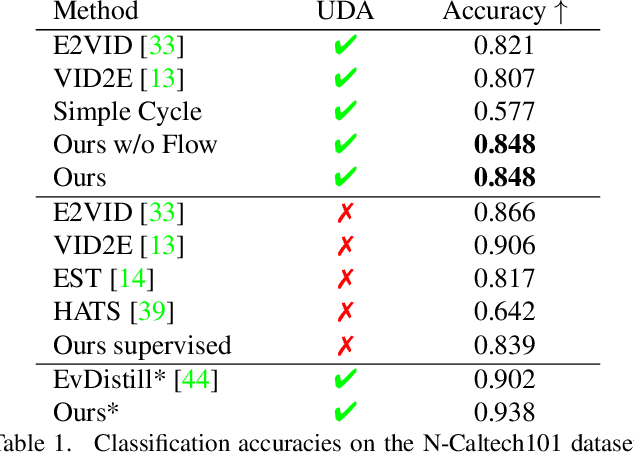
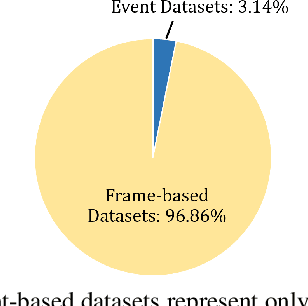
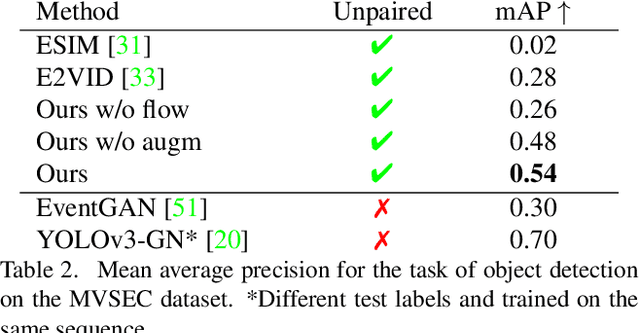
Event cameras are novel sensors with outstanding properties such as high temporal resolution and high dynamic range. Despite these characteristics, event-based vision has been held back by the shortage of labeled datasets due to the novelty of event cameras. To overcome this drawback, we propose a task transfer method that allows models to be trained directly with labeled images and unlabeled event data. Compared to previous approaches, (i) our method transfers from single images to events instead of high frame rate videos, and (ii) does not rely on paired sensor data. To achieve this, we leverage the generative event model to split event features into content and motion features. This feature split enables to efficiently match the latent space for events and images, which is crucial for a successful task transfer. Thus, our approach unlocks the vast amount of existing image datasets for the training of event-based neural networks. Our task transfer method consistently outperforms methods applicable in the Unsupervised Domain Adaptation setting for object detection by 0.26 mAP (increase by 93%) and classification by 2.7% accuracy.