 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian deep learning of affordances from RGB images
Sep 27, 2021
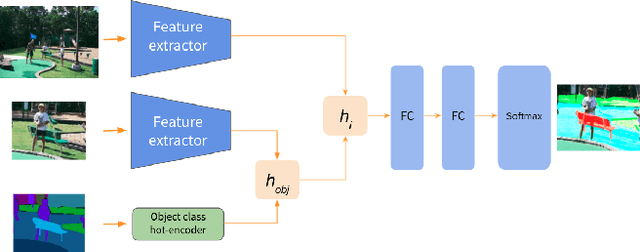
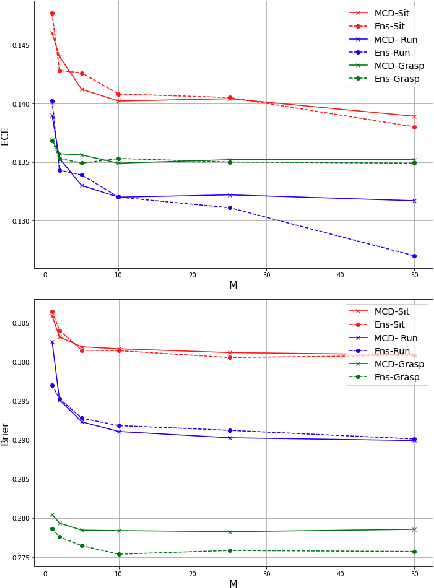
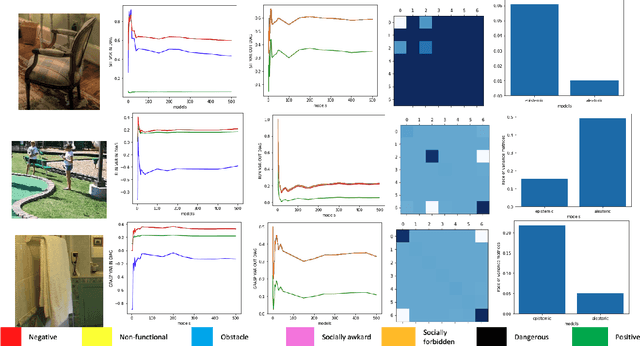
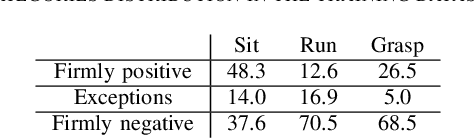
Autonomous agents, such as robots or intelligent devices, need to understand how to interact with objects and its environment. Affordances are defined as the relationships between an agent, the objects, and the possible future actions in the environment. In this paper, we present a Bayesian deep learning method to predict the affordances available in the environment directly from RGB images. Based on previous work on socially accepted affordances, our model is based on a multiscale CNN that combines local and global information from the object and the full image. However, previous works assume a deterministic model, but uncertainty quantification is fundamental for robust detection, affordance-based reason, continual learning, etc. Our Bayesian model is able to capture both the aleatoric uncertainty from the scene and the epistemic uncertainty associated with the model and previous learning process. For comparison, we estimate the uncertainty using two state-of-the-art techniques: Monte Carlo dropout and deep ensembles. We also compare different types of CNN encoders for feature extraction. We have performed several experiments on an affordance database on socially acceptable behaviours and we have shown improved performance compared with previous works. Furthermore, the uncertainty estimation is consistent with the the type of objects and scenarios. Our results show a marginal better performance of deep ensembles, compared to MC-dropout on the Brier score and the Expected Calibration Error.
Lightweight Image Super-Resolution with Information Multi-distillation Network
Sep 26, 2019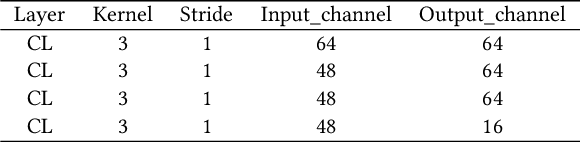
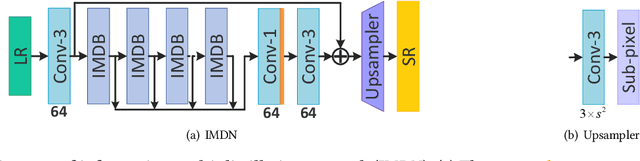
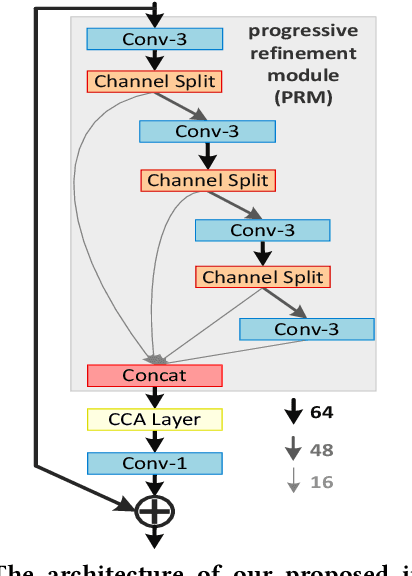

In recent years, single image super-resolution (SISR) methods using deep convolution neural network (CNN) have achieved impressive results. Thanks to the powerful representation capabilities of the deep networks, numerous previous ways can learn the complex non-linear mapping between low-resolution (LR) image patches and their high-resolution (HR) versions. However, excessive convolutions will limit the application of super-resolution technology in low computing power devices. Besides, super-resolution of any arbitrary scale factor is a critical issue in practical applications, which has not been well solved in the previous approaches. To address these issues, we propose a lightweight information multi-distillation network (IMDN) by constructing the cascaded information multi-distillation blocks (IMDB), which contains distillation and selective fusion parts. Specifically, the distillation module extracts hierarchical features step-by-step, and fusion module aggregates them according to the importance of candidate features, which is evaluated by the proposed contrast-aware channel attention mechanism. To process real images with any sizes, we develop an adaptive cropping strategy (ACS) to super-resolve block-wise image patches using the same well-trained model. Extensive experiments suggest that the proposed method performs favorably against the state-of-the-art SR algorithms in term of visual quality, memory footprint, and inference time. Code is available at \url{https://github.com/Zheng222/IMDN}.
Unified Vision-Language Pre-Training for Image Captioning and VQA
Oct 03, 2019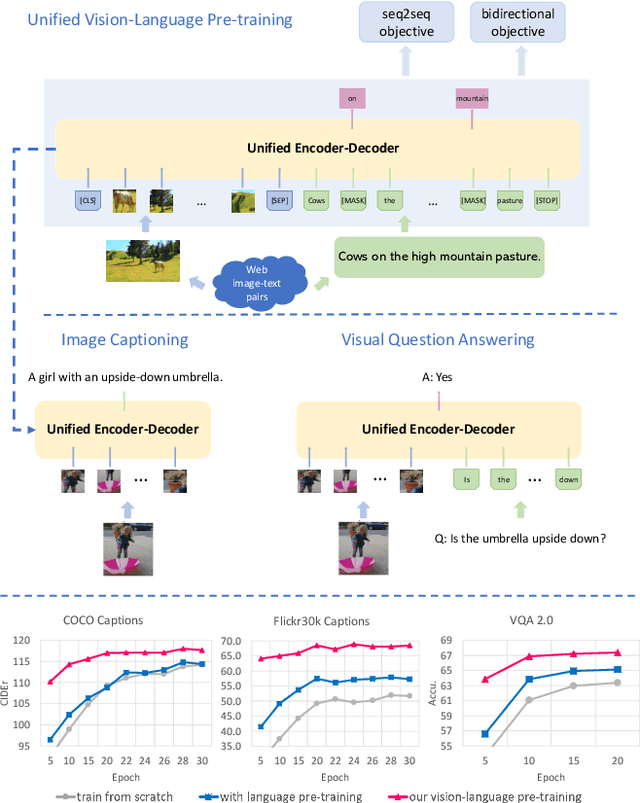
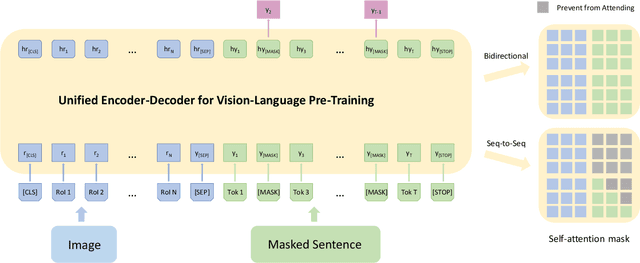
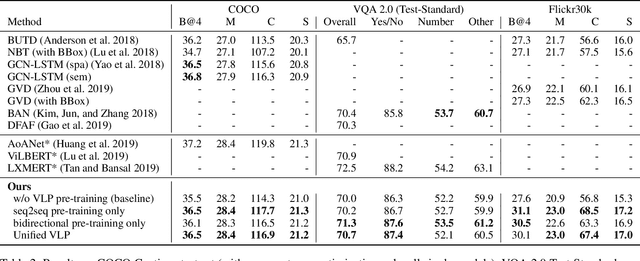
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be fine-tuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) it uses a shared multi-layer transformer network for both encoding and decoding, which differs from many existing methods where the encoder and decoder are implemented using separate models. The unified VLP model is pre-trained on a large amount of image-text pairs using the unsupervised learning objectives of two tasks: bidirectional and sequence-to-sequence (seq2seq) masked vision-language prediction. The two tasks differ solely in what context the prediction conditions on. This is controlled by utilizing specific self-attention masks for the shared transformer network. To the best of our knowledge, VLP is the first reported model that achieves state-of-the-art results on both vision-language generation and understanding tasks, as disparate as image captioning and visual question answering, across three challenging benchmark datasets: COCO Captions, Flickr30k Captions, and VQA 2.0. The code and the pre-trained models are available at https://github.com/LuoweiZhou/VLP.
Advancing machine learning for MR image reconstruction with an open competition: Overview of the 2019 fastMRI challenge
Jan 06, 2020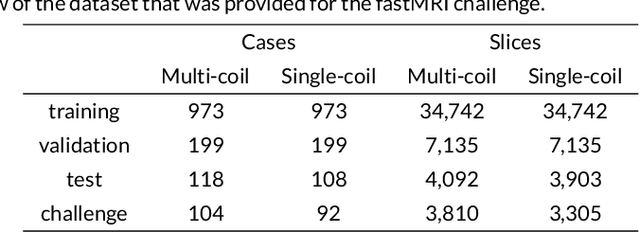
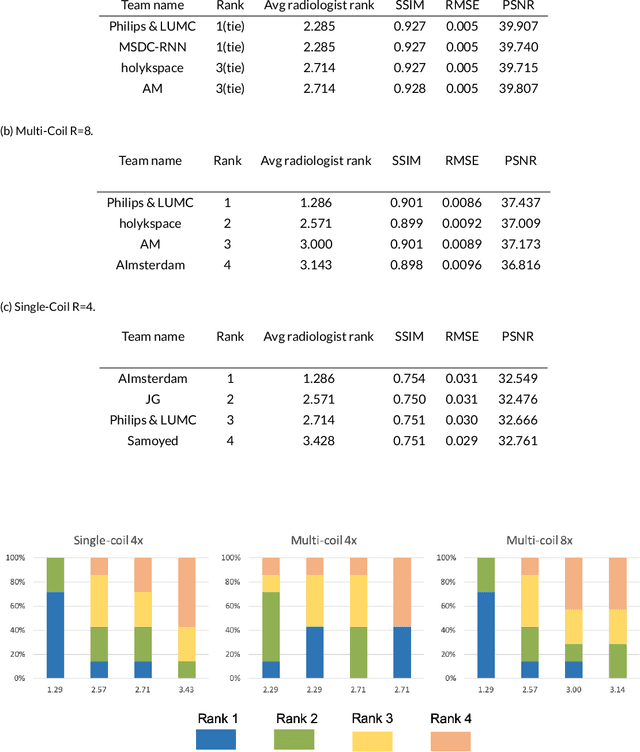

Purpose: To advance research in the field of machine learning for MR image reconstruction with an open challenge. Methods: We provided participants with a dataset of raw k-space data from 1,594 consecutive clinical exams of the knee. The goal of the challenge was to reconstruct images from these data. In order to strike a balance between realistic data and a shallow learning curve for those not already familiar with MR image reconstruction, we ran multiple tracks for multi-coil and single-coil data. We performed a two-stage evaluation based on quantitative image metrics followed by evaluation by a panel of radiologists. The challenge ran from June to December of 2019. Results: We received a total of 33 challenge submissions. All participants chose to submit results from supervised machine learning approaches. Conclusion: The challenge led to new developments in machine learning for image reconstruction, provided insight into the current state of the art in the field, and highlighted remaining hurdles for clinical adoption.
Image classification in frequency domain with 2SReLU: a second harmonics superposition activation function
Jun 18, 2020

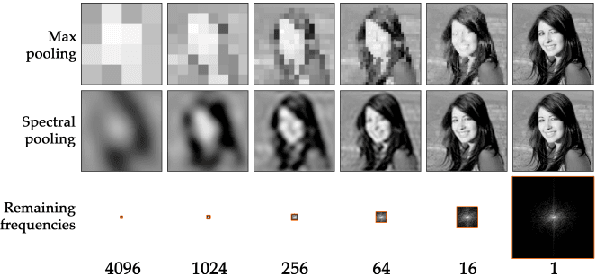
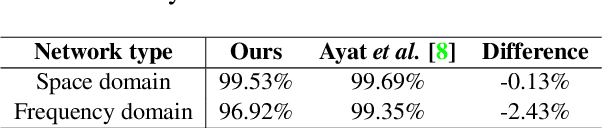
Deep Convolutional Neural Networks are able to identify complex patterns and perform tasks with super-human capabilities. However, besides the exceptional results, they are not completely understood and it is still impractical to hand-engineer similar solutions. In this work, an image classification Convolutional Neural Network and its building blocks are described from a frequency domain perspective. Some network layers have established counterparts in the frequency domain like the convolutional and pooling layers. We propose the 2SReLU layer, a novel non-linear activation function that preserves high frequency components in deep networks. It is demonstrated that in the frequency domain it is possible to achieve competitive results without using the computationally costly convolution operation. A source code implementation in PyTorch is provided at: https://gitlab.com/thomio/2srelu
Deep Domain-Adversarial Image Generation for Domain Generalisation
Mar 12, 2020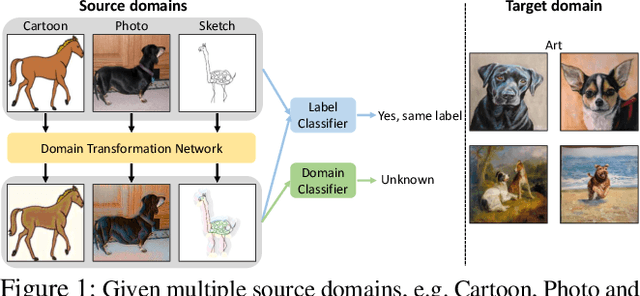
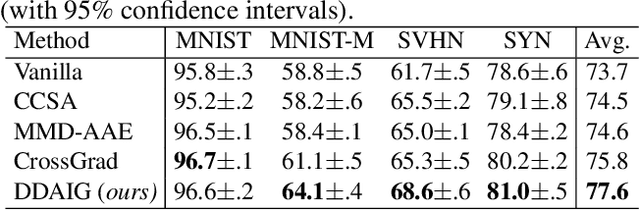
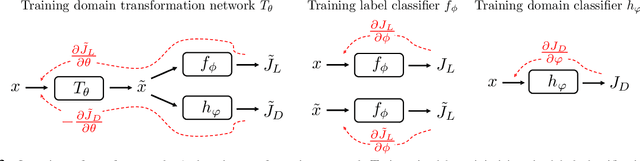
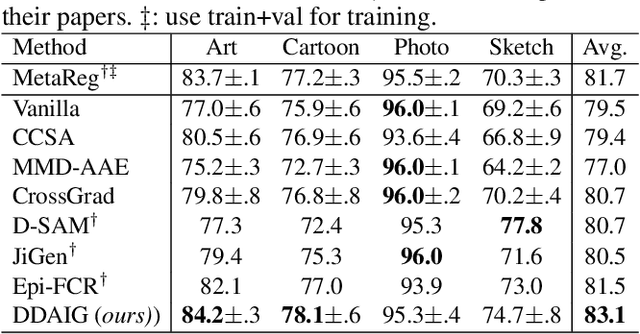
Machine learning models typically suffer from the domain shift problem when trained on a source dataset and evaluated on a target dataset of different distribution. To overcome this problem, domain generalisation (DG) methods aim to leverage data from multiple source domains so that a trained model can generalise to unseen domains. In this paper, we propose a novel DG approach based on \emph{Deep Domain-Adversarial Image Generation} (DDAIG). Specifically, DDAIG consists of three components, namely a label classifier, a domain classifier and a domain transformation network (DoTNet). The goal for DoTNet is to map the source training data to unseen domains. This is achieved by having a learning objective formulated to ensure that the generated data can be correctly classified by the label classifier while fooling the domain classifier. By augmenting the source training data with the generated unseen domain data, we can make the label classifier more robust to unknown domain changes. Extensive experiments on four DG datasets demonstrate the effectiveness of our approach.
Image-Based Feature Representation for Insider Threat Classification
Nov 13, 2019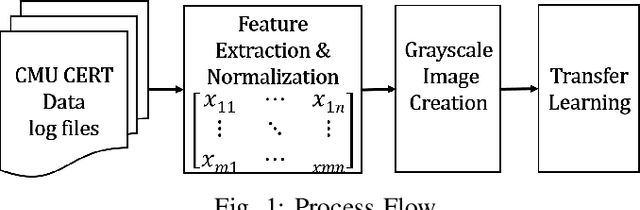
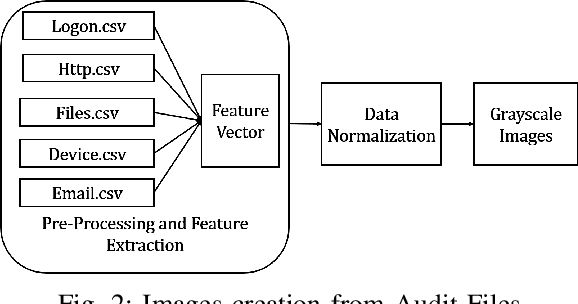

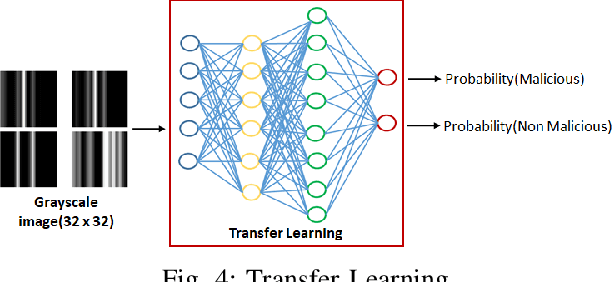
Insiders are the trusted entities in the organization, but poses threat to the with access to sensitive information network and resources. The insider threat detection is a well studied problem in security analytics. Identifying the features from data sources and using them with the right data analytics algorithms makes various kinds of threat analysis possible. The insider threat analysis is mainly done using the frequency based attributes extracted from the raw data available from data sources. In this paper, we propose an image-based feature representation of the daily resource usage pattern of users in the organization. The features extracted from the audit files of the organization are represented as gray scale images. Hence, these images are used to represent the resource access patterns and thereby the behavior of users. Classification models are applied to the representative images to detect anomalous behavior of insiders. The images are classified to malicious and non-malicious. The effectiveness of the proposed representation is evaluated using the CMU CERT data V4.2, and state-of-art image classification models like Mobilenet, VGG and ResNet. The experimental results showed improved accuracy. The comparison with existing works show a performance improvement in terms of high recall and precision values.
DeepImageSpam: Deep Learning based Image Spam Detection
Oct 03, 2018
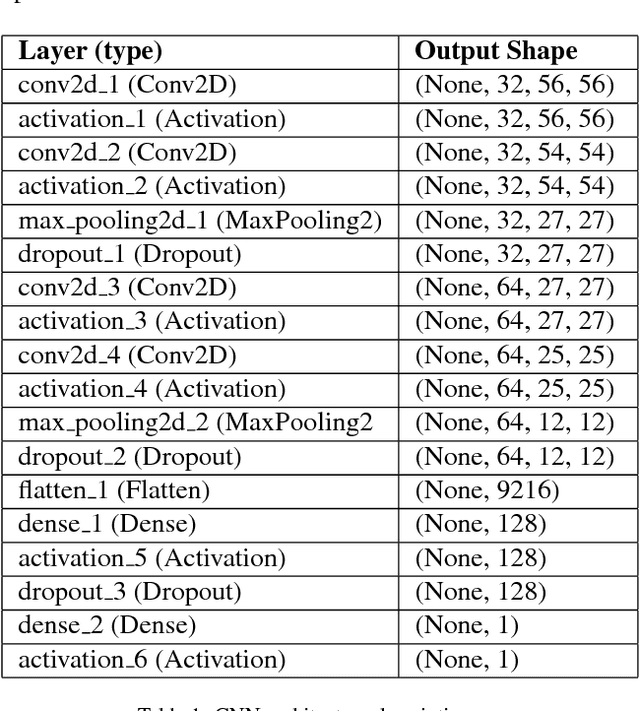

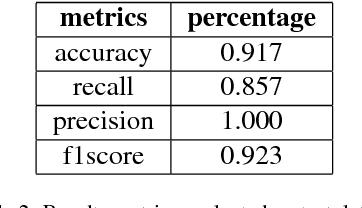
Hackers and spammers are employing innovative and novel techniques to deceive novice and even knowledgeable internet users. Image spam is one of such technique where the spammer varies and changes some portion of the image such that it is indistinguishable from the original image fooling the users. This paper proposes a deep learning based approach for image spam detection using the convolutional neural networks which uses a dataset with 810 natural images and 928 spam images for classification achieving an accuracy of 91.7% outperforming the existing image processing and machine learning techniques
Multiple instance dense connected convolution neural network for aerial image scene classification
Aug 22, 2019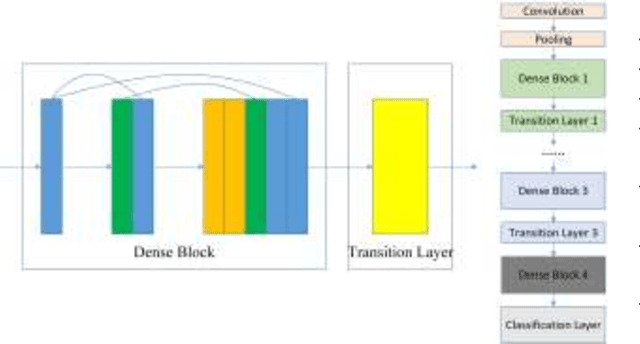
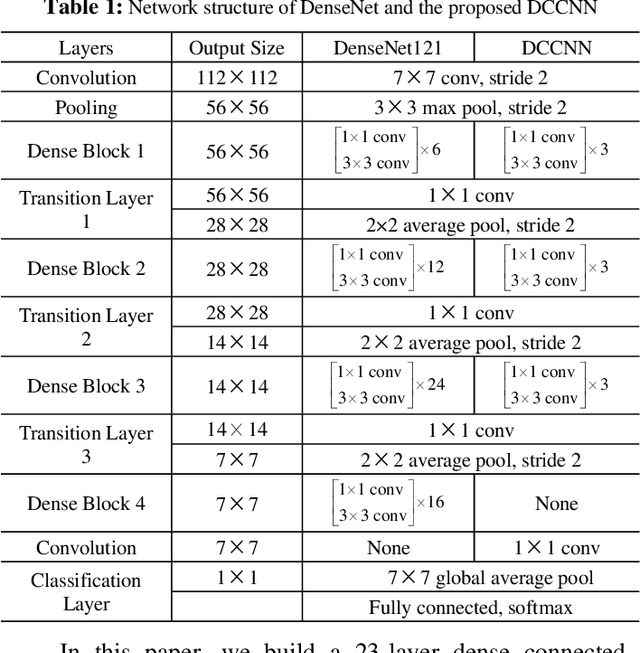
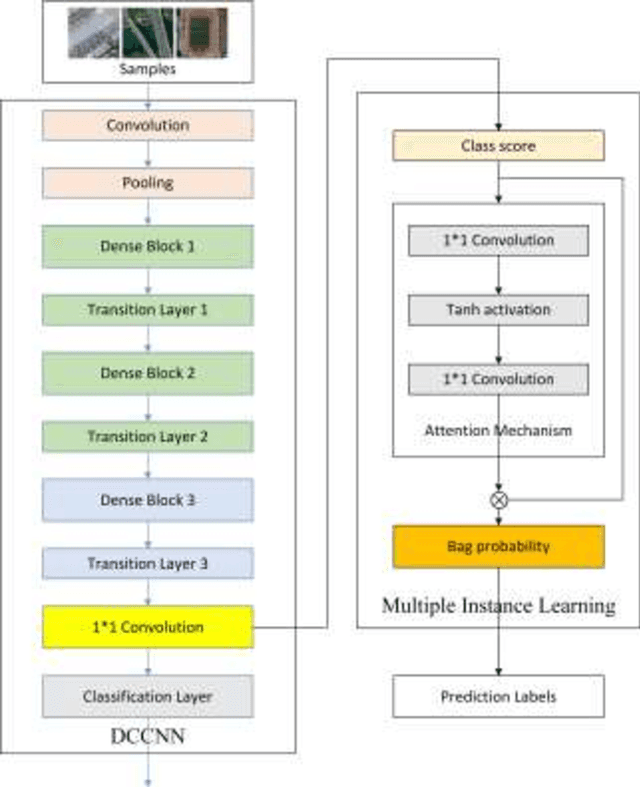
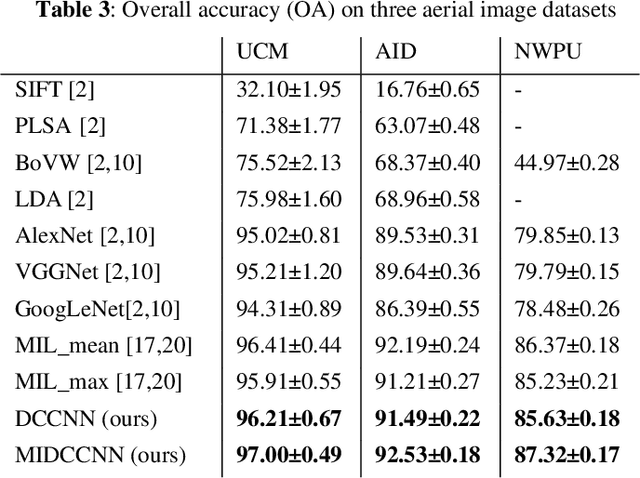
With the development of deep learning, many state-of-the-art natural image scene classification methods have demonstrated impressive performance. While the current convolution neural network tends to extract global features and global semantic information in a scene, the geo-spatial objects can be located at anywhere in an aerial image scene and their spatial arrangement tends to be more complicated. One possible solution is to preserve more local semantic information and enhance feature propagation. In this paper, an end to end multiple instance dense connected convolution neural network (MIDCCNN) is proposed for aerial image scene classification. First, a 23 layer dense connected convolution neural network (DCCNN) is built and served as a backbone to extract convolution features. It is capable of preserving middle and low level convolution features. Then, an attention based multiple instance pooling is proposed to highlight the local semantics in an aerial image scene. Finally, we minimize the loss between the bag-level predictions and the ground truth labels so that the whole framework can be trained directly. Experiments on three aerial image datasets demonstrate that our proposed methods can outperform current baselines by a large margin.
Underwater Image Super-Resolution using Deep Residual Multipliers
Sep 20, 2019

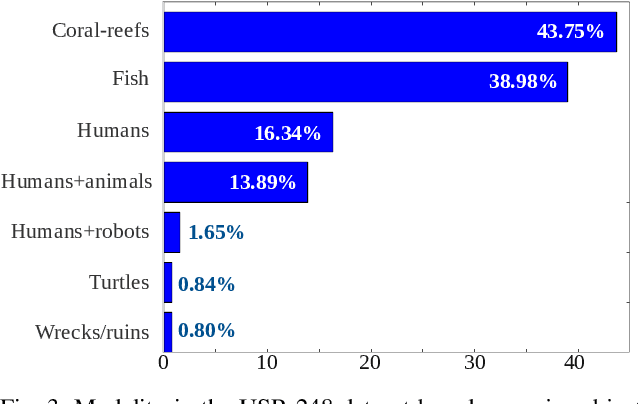
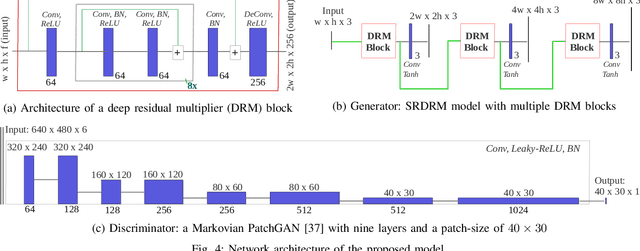
We present a deep residual network-based generative model for single image super-resolution (SISR) of underwater imagery for use by autonomous underwater robots. We also provide an adversarial training pipeline for learning SISR from paired data. In order to supervise the training, we formulate an objective function that evaluates the perceptual quality of an image based on its global content, color, and local style information. Additionally, we present USR-248, a large-scale dataset of three sets of underwater images of high (640x480) and low (80x60, 160x120, and 320x240) resolution. USR-248 contains over 7K paired instances in each set of data for supervised training of 2x, 4x, or 8x SISR models. Furthermore, we validate the effectiveness of our proposed model through qualitative and quantitative experiments and compare the results with several state-of-the-art models' performances. We also analyze its practical feasibility for applications such as scene understanding and attention modeling in noisy visual conditions.