 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attentive Weakly Supervised land cover mapping for object-based satellite image time series data with spatial interpretation
Apr 30, 2020
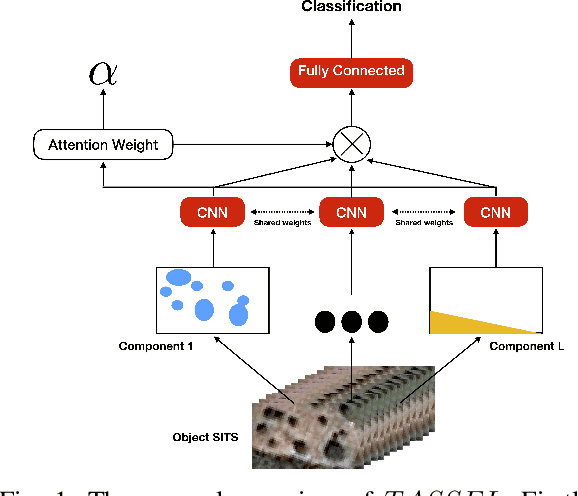


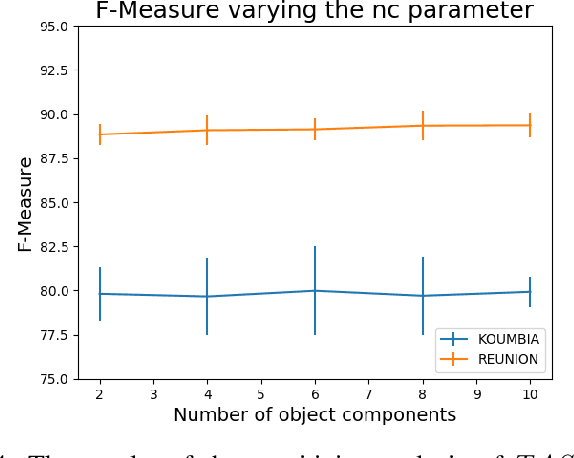
Nowadays, modern Earth Observation systems continuously collect massive amounts of satellite information. The unprecedented possibility to acquire high resolution Satellite Image Time Series (SITS) data (series of images with high revisit time period on the same geographical area) is opening new opportunities to monitor the different aspects of the Earth Surface but, at the same time, it is raising up new challenges in term of suitable methods to analyze and exploit such huge amount of rich and complex image data. One of the main task associated to SITS data analysis is related to land cover mapping where satellite data are exploited via learning methods to recover the Earth Surface status aka the corresponding land cover classes. Due to operational constraints, the collected label information, on which machine learning strategies are trained, is often limited in volume and obtained at coarse granularity carrying out inexact and weak knowledge that can affect the whole process. To cope with such issues, in the context of object-based SITS land cover mapping, we propose a new deep learning framework, named TASSEL (aTtentive weAkly Supervised Satellite image time sEries cLassifier), that is able to intelligently exploit the weak supervision provided by the coarse granularity labels. Furthermore, our framework also produces an additional side-information that supports the model interpretability with the aim to make the black box gray. Such side-information allows to associate spatial interpretation to the model decision via visual inspection.
Robust Reference-based Super-Resolution via C2-Matching
Jun 03, 2021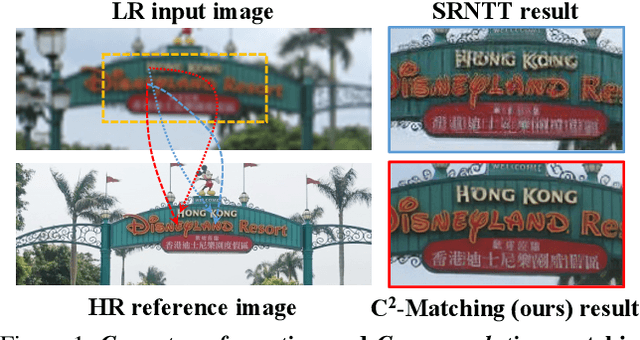
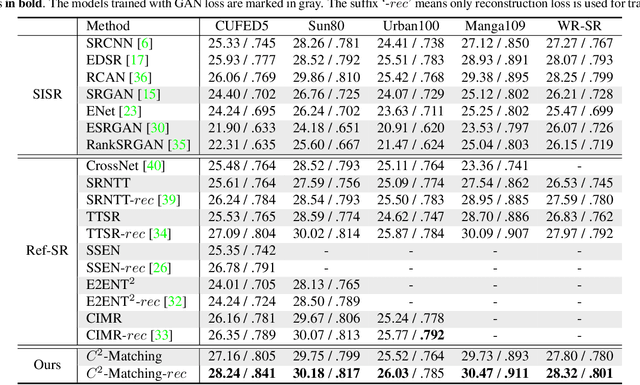
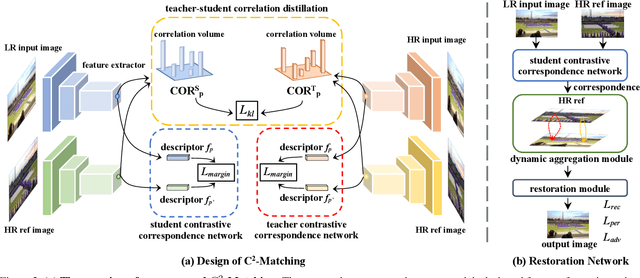
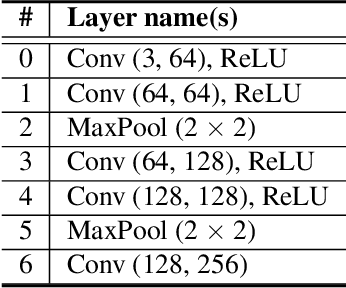
Reference-based Super-Resolution (Ref-SR) has recently emerged as a promising paradigm to enhance a low-resolution (LR) input image by introducing an additional high-resolution (HR) reference image. Existing Ref-SR methods mostly rely on implicit correspondence matching to borrow HR textures from reference images to compensate for the information loss in input images. However, performing local transfer is difficult because of two gaps between input and reference images: the transformation gap (e.g. scale and rotation) and the resolution gap (e.g. HR and LR). To tackle these challenges, we propose C2-Matching in this work, which produces explicit robust matching crossing transformation and resolution. 1) For the transformation gap, we propose a contrastive correspondence network, which learns transformation-robust correspondences using augmented views of the input image. 2) For the resolution gap, we adopt a teacher-student correlation distillation, which distills knowledge from the easier HR-HR matching to guide the more ambiguous LR-HR matching. 3) Finally, we design a dynamic aggregation module to address the potential misalignment issue. In addition, to faithfully evaluate the performance of Ref-SR under a realistic setting, we contribute the Webly-Referenced SR (WR-SR) dataset, mimicking the practical usage scenario. Extensive experiments demonstrate that our proposed C2-Matching significantly outperforms state of the arts by over 1dB on the standard CUFED5 benchmark. Notably, it also shows great generalizability on WR-SR dataset as well as robustness across large scale and rotation transformations.
Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
Aug 19, 2020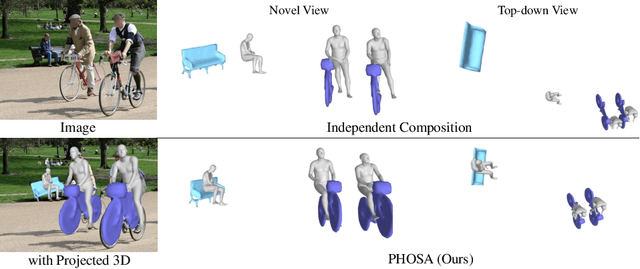
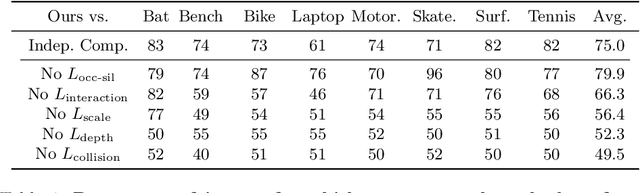
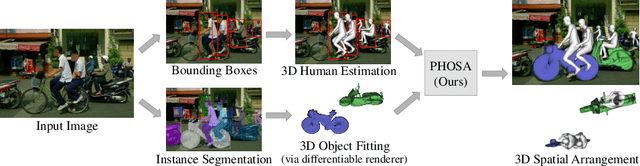
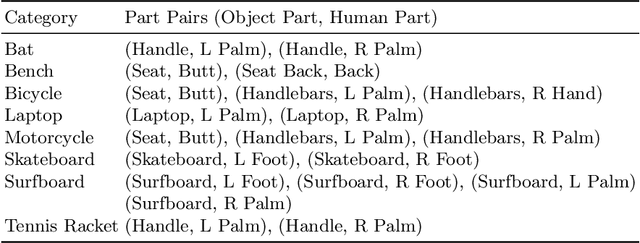
We present a method that infers spatial arrangements and shapes of humans and objects in a globally consistent 3D scene, all from a single image in-the-wild captured in an uncontrolled environment. Notably, our method runs on datasets without any scene- or object-level 3D supervision. Our key insight is that considering humans and objects jointly gives rise to "3D common sense" constraints that can be used to resolve ambiguity. In particular, we introduce a scale loss that learns the distribution of object size from data; an occlusion-aware silhouette re-projection loss to optimize object pose; and a human-object interaction loss to capture the spatial layout of objects with which humans interact. We empirically validate that our constraints dramatically reduce the space of likely 3D spatial configurations. We demonstrate our approach on challenging, in-the-wild images of humans interacting with large objects (such as bicycles, motorcycles, and surfboards) and handheld objects (such as laptops, tennis rackets, and skateboards). We quantify the ability of our approach to recover human-object arrangements and outline remaining challenges in this relatively domain. The project webpage can be found at https://jasonyzhang.com/phosa.
Learning Multimodal Affinities for Textual Editing in Images
Mar 18, 2021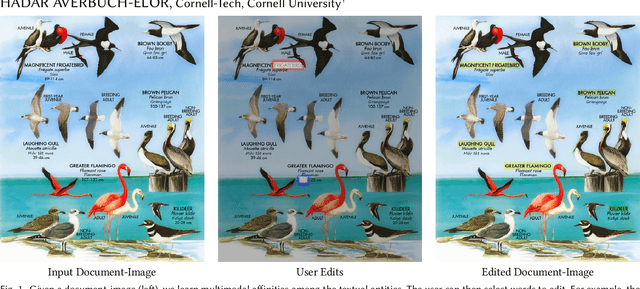
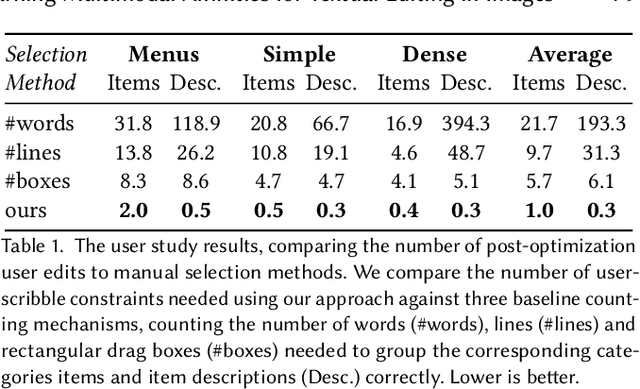
Nowadays, as cameras are rapidly adopted in our daily routine, images of documents are becoming both abundant and prevalent. Unlike natural images that capture physical objects, document-images contain a significant amount of text with critical semantics and complicated layouts. In this work, we devise a generic unsupervised technique to learn multimodal affinities between textual entities in a document-image, considering their visual style, the content of their underlying text and their geometric context within the image. We then use these learned affinities to automatically cluster the textual entities in the image into different semantic groups. The core of our approach is a deep optimization scheme dedicated for an image provided by the user that detects and leverages reliable pairwise connections in the multimodal representation of the textual elements in order to properly learn the affinities. We show that our technique can operate on highly varying images spanning a wide range of documents and demonstrate its applicability for various editing operations manipulating the content, appearance and geometry of the image.
SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels
Mar 14, 2021
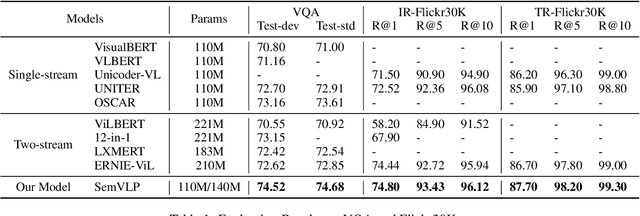
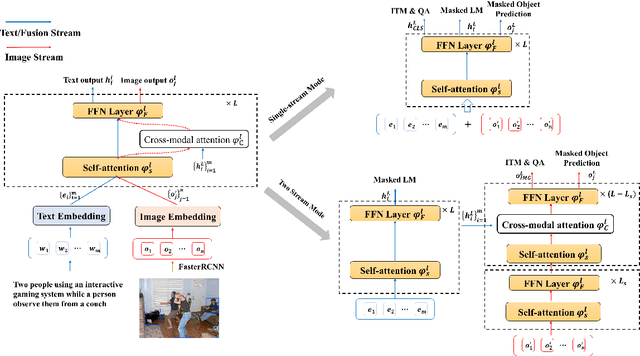

Vision-language pre-training (VLP) on large-scale image-text pairs has recently witnessed rapid progress for learning cross-modal representations. Existing pre-training methods either directly concatenate image representation and text representation at a feature level as input to a single-stream Transformer, or use a two-stream cross-modal Transformer to align the image-text representation at a high-level semantic space. In real-world image-text data, we observe that it is easy for some of the image-text pairs to align simple semantics on both modalities, while others may be related after higher-level abstraction. Therefore, in this paper, we propose a new pre-training method SemVLP, which jointly aligns both the low-level and high-level semantics between image and text representations. The model is pre-trained iteratively with two prevalent fashions: single-stream pre-training to align at a fine-grained feature level and two-stream pre-training to align high-level semantics, by employing a shared Transformer network with a pluggable cross-modal attention module. An extensive set of experiments have been conducted on four well-established vision-language understanding tasks to demonstrate the effectiveness of the proposed SemVLP in aligning cross-modal representations towards different semantic granularities.
Image Morphing with Perceptual Constraints and STN Alignment
Apr 29, 2020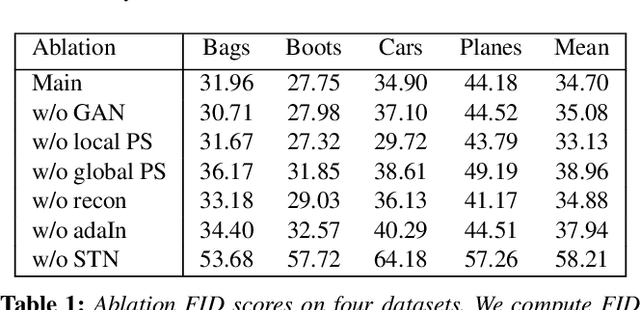
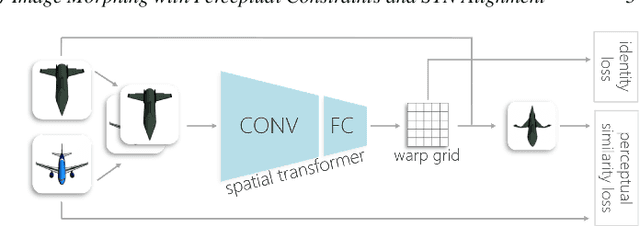
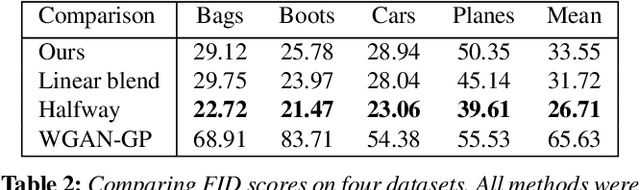

In image morphing, a sequence of plausible frames are synthesized and composited together to form a smooth transformation between given instances. Intermediates must remain faithful to the input, stand on their own as members of the set, and maintain a well-paced visual transition from one to the next. In this paper, we propose a conditional GAN morphing framework operating on a pair of input images. The network is trained to synthesize frames corresponding to temporal samples along the transformation, and learns a proper shape prior that enhances the plausibility of intermediate frames. While individual frame plausibility is boosted by the adversarial setup, a special training protocol producing sequences of frames, combined with a perceptual similarity loss, promote smooth transformation over time. Explicit stating of correspondences is replaced with a grid-based freeform deformation spatial transformer that predicts the geometric warp between the inputs, instituting the smooth geometric effect by bringing the shapes into an initial alignment. We provide comparisons to classic as well as latent space morphing techniques, and demonstrate that, given a set of images for self-supervision, our network learns to generate visually pleasing morphing effects featuring believable in-betweens, with robustness to changes in shape and texture, requiring no correspondence annotation.
An End-to-End Khmer Optical Character Recognition using Sequence-to-Sequence with Attention
Jun 21, 2021
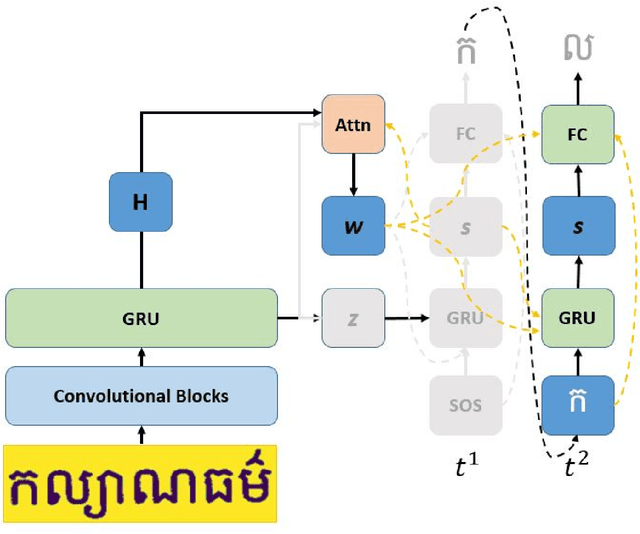
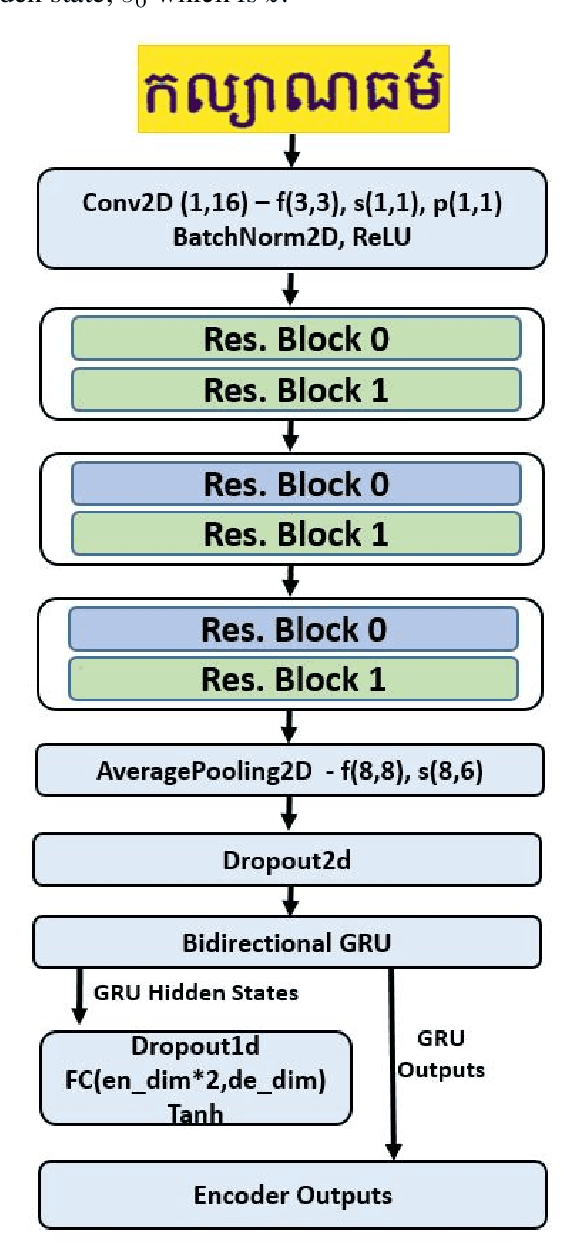
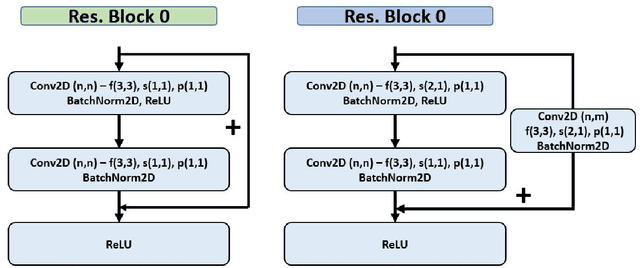
This paper presents an end-to-end deep convolutional recurrent neural network solution for Khmer optical character recognition (OCR) task. The proposed solution uses a sequence-to-sequence (Seq2Seq) architecture with attention mechanism. The encoder extracts visual features from an input text-line image via layers of residual convolutional blocks and a layer of gated recurrent units (GRU). The features are encoded in a single context vector and a sequence of hidden states which are fed to the decoder for decoding one character at a time until a special end-of-sentence (EOS) token is reached. The attention mechanism allows the decoder network to adaptively select parts of the input image while predicting a target character. The Seq2Seq Khmer OCR network was trained on a large collection of computer-generated text-line images for seven common Khmer fonts. The proposed model's performance outperformed the state-of-art Tesseract OCR engine for Khmer language on the 3000-images test set by achieving a character error rate (CER) of 1% vs 3%.
NeighCNN: A CNN based SAR Speckle Reduction using Feature preserving Loss Function
Aug 26, 2021

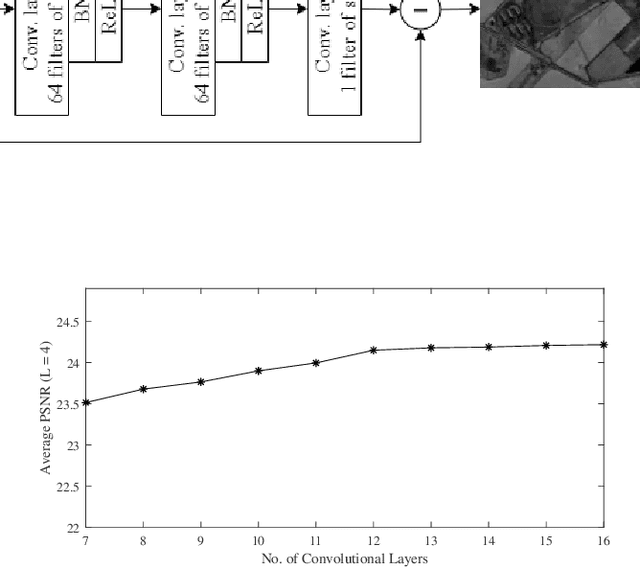

Coherent imaging systems like synthetic aperture radar are susceptible to multiplicative noise that makes applications like automatic target recognition challenging. In this paper, NeighCNN, a deep learning-based speckle reduction algorithm that handles multiplicative noise with relatively simple convolutional neural network architecture, is proposed. We have designed a loss function which is an unique combination of weighted sum of Euclidean, neighbourhood, and perceptual loss for training the deep network. Euclidean and neighbourhood losses take pixel-level information into account, whereas perceptual loss considers high-level semantic features between two images. Various synthetic, as well as real SAR images, are used for testing the NeighCNN architecture, and the results verify the noise removal and edge preservation abilities of the proposed architecture. Performance metrics like peak-signal-to-noise ratio, structural similarity index, and universal image quality index are used for evaluating the efficiency of the proposed architecture on synthetic images.
Bayesian deep learning of affordances from RGB images
Sep 27, 2021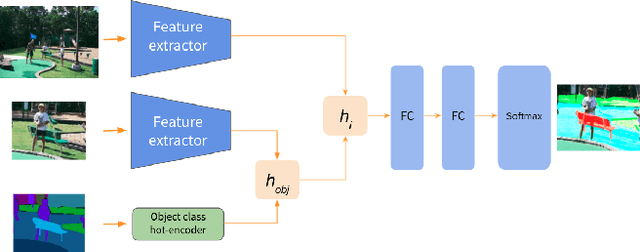
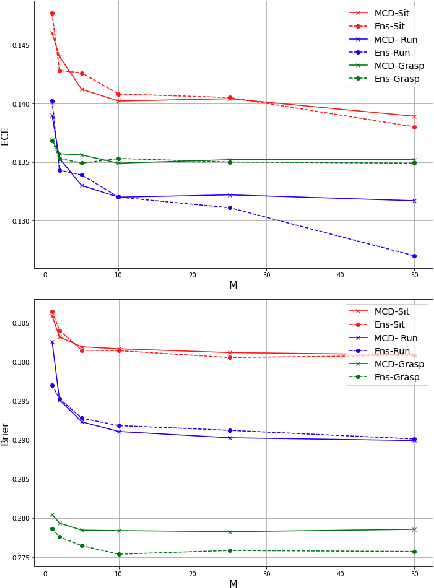
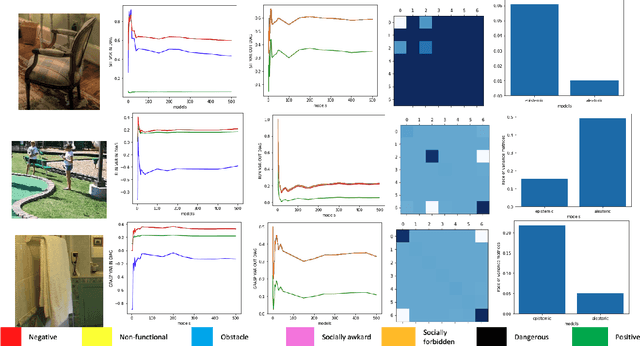
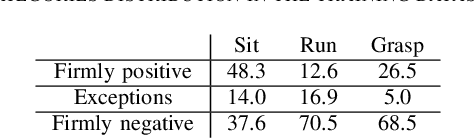
Autonomous agents, such as robots or intelligent devices, need to understand how to interact with objects and its environment. Affordances are defined as the relationships between an agent, the objects, and the possible future actions in the environment. In this paper, we present a Bayesian deep learning method to predict the affordances available in the environment directly from RGB images. Based on previous work on socially accepted affordances, our model is based on a multiscale CNN that combines local and global information from the object and the full image. However, previous works assume a deterministic model, but uncertainty quantification is fundamental for robust detection, affordance-based reason, continual learning, etc. Our Bayesian model is able to capture both the aleatoric uncertainty from the scene and the epistemic uncertainty associated with the model and previous learning process. For comparison, we estimate the uncertainty using two state-of-the-art techniques: Monte Carlo dropout and deep ensembles. We also compare different types of CNN encoders for feature extraction. We have performed several experiments on an affordance database on socially acceptable behaviours and we have shown improved performance compared with previous works. Furthermore, the uncertainty estimation is consistent with the the type of objects and scenarios. Our results show a marginal better performance of deep ensembles, compared to MC-dropout on the Brier score and the Expected Calibration Error.
Coarse-to-Fine Domain Adaptive Semantic Segmentation with Photometric Alignment and Category-Center Regularization
Mar 24, 2021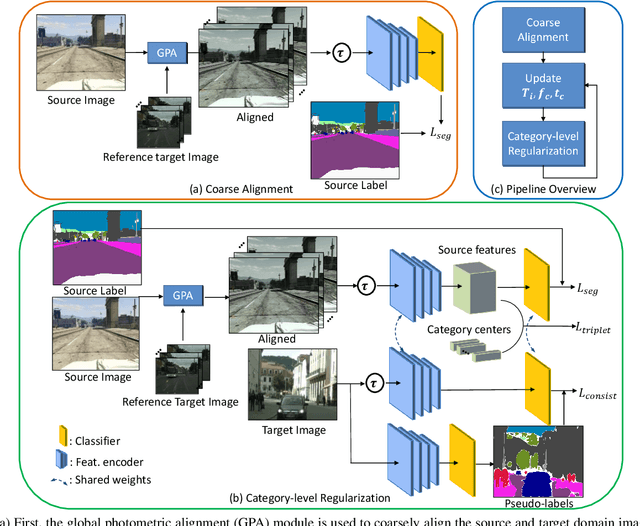
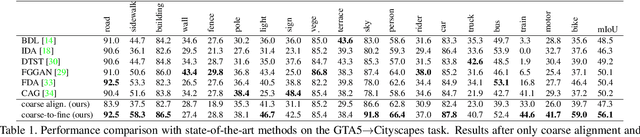
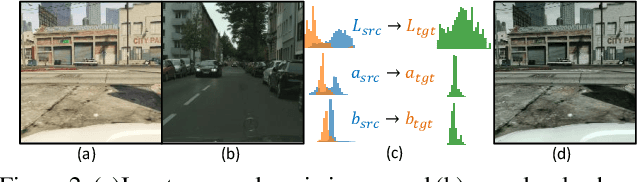
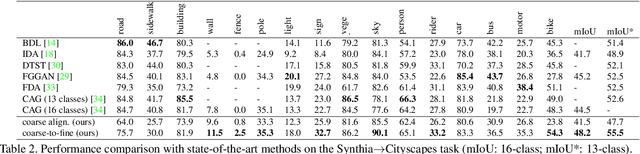
Unsupervised domain adaptation (UDA) in semantic segmentation is a fundamental yet promising task relieving the need for laborious annotation works. However, the domain shifts/discrepancies problem in this task compromise the final segmentation performance. Based on our observation, the main causes of the domain shifts are differences in imaging conditions, called image-level domain shifts, and differences in object category configurations called category-level domain shifts. In this paper, we propose a novel UDA pipeline that unifies image-level alignment and category-level feature distribution regularization in a coarse-to-fine manner. Specifically, on the coarse side, we propose a photometric alignment module that aligns an image in the source domain with a reference image from the target domain using a set of image-level operators; on the fine side, we propose a category-oriented triplet loss that imposes a soft constraint to regularize category centers in the source domain and a self-supervised consistency regularization method in the target domain. Experimental results show that our proposed pipeline improves the generalization capability of the final segmentation model and significantly outperforms all previous state-of-the-arts.