 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Optimized Architecture for Unpaired Image-to-Image Translation
Feb 13, 2018
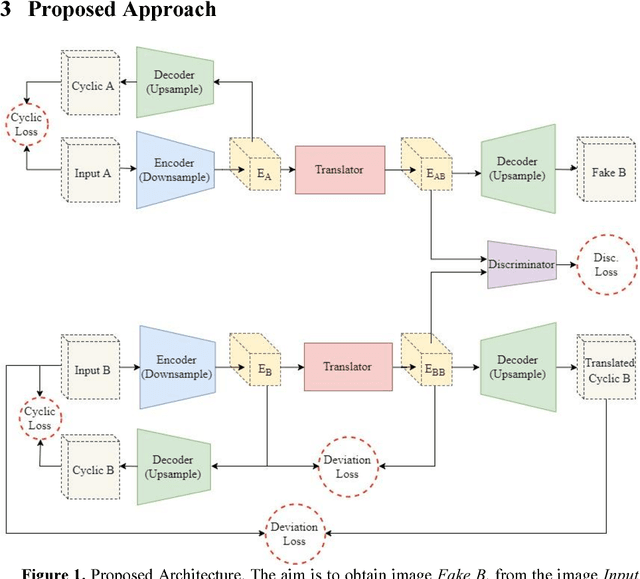

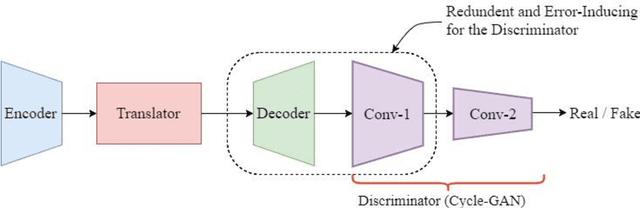
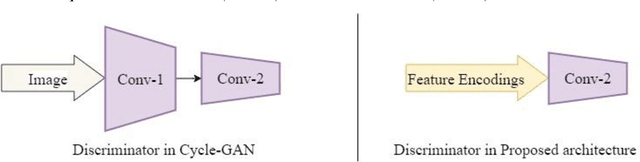
Unpaired Image-to-Image translation aims to convert the image from one domain (input domain A) to another domain (target domain B), without providing paired examples for the training. The state-of-the-art, Cycle-GAN demonstrated the power of Generative Adversarial Networks with Cycle-Consistency Loss. While its results are promising, there is scope for optimization in the training process. This paper introduces a new neural network architecture, which only learns the translation from domain A to B and eliminates the need for reverse mapping (B to A), by introducing a new Deviation-loss term. Furthermore, few other improvements to the Cycle-GAN are found and utilized in this new architecture, contributing to significantly lesser training duration.
Learning to Ground Visual Objects for Visual Dialog
Sep 13, 2021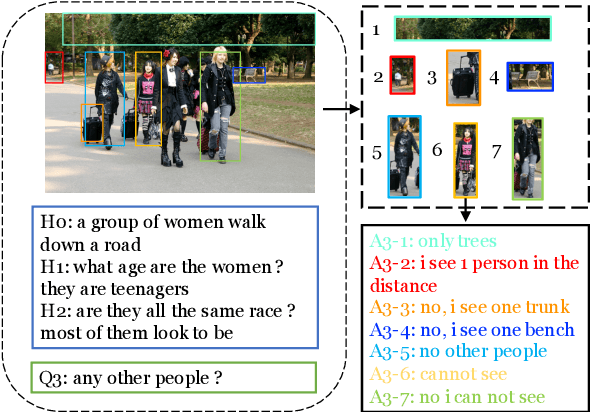
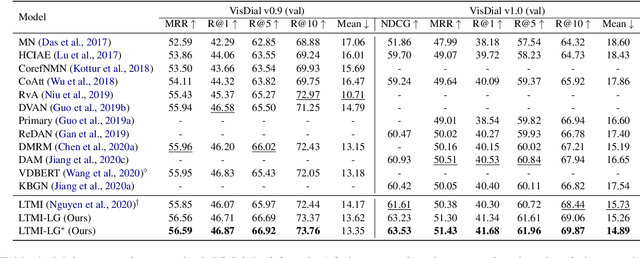
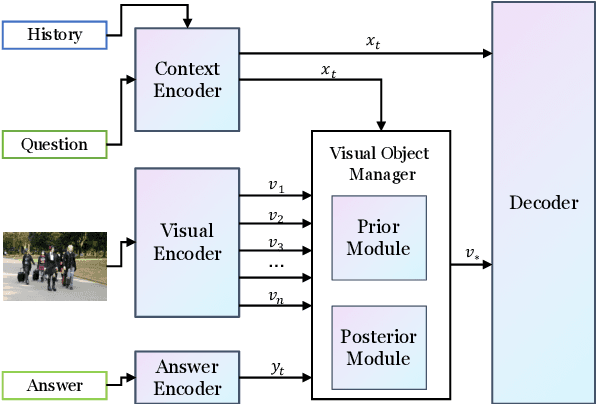
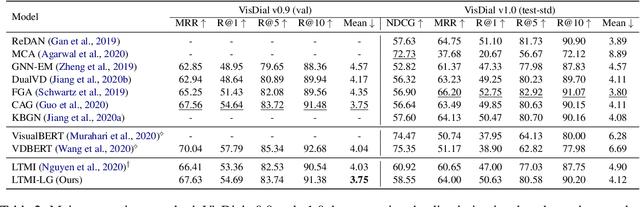
Visual dialog is challenging since it needs to answer a series of coherent questions based on understanding the visual environment. How to ground related visual objects is one of the key problems. Previous studies utilize the question and history to attend to the image and achieve satisfactory performance, however these methods are not sufficient to locate related visual objects without any guidance. The inappropriate grounding of visual objects prohibits the performance of visual dialog models. In this paper, we propose a novel approach to Learn to Ground visual objects for visual dialog, which employs a novel visual objects grounding mechanism where both prior and posterior distributions over visual objects are used to facilitate visual objects grounding. Specifically, a posterior distribution over visual objects is inferred from both context (history and questions) and answers, and it ensures the appropriate grounding of visual objects during the training process. Meanwhile, a prior distribution, which is inferred from context only, is used to approximate the posterior distribution so that appropriate visual objects can be grounded even without answers during the inference process. Experimental results on the VisDial v0.9 and v1.0 datasets demonstrate that our approach improves the previous strong models in both generative and discriminative settings by a significant margin.
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution
Jun 12, 2021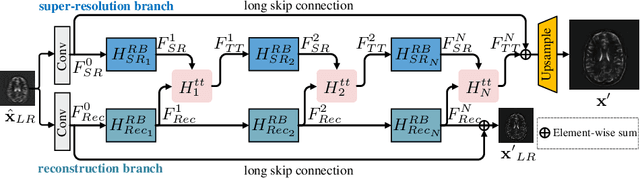
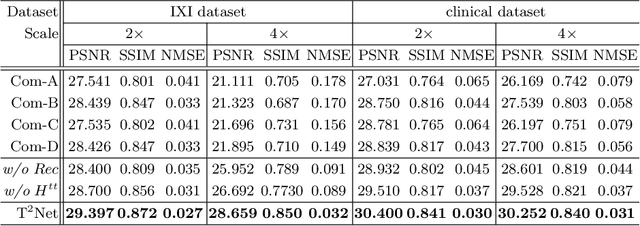
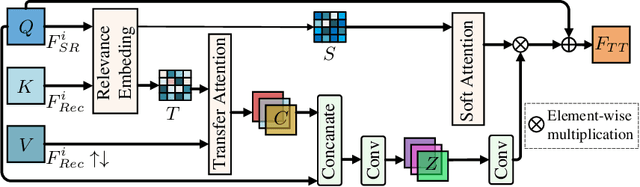
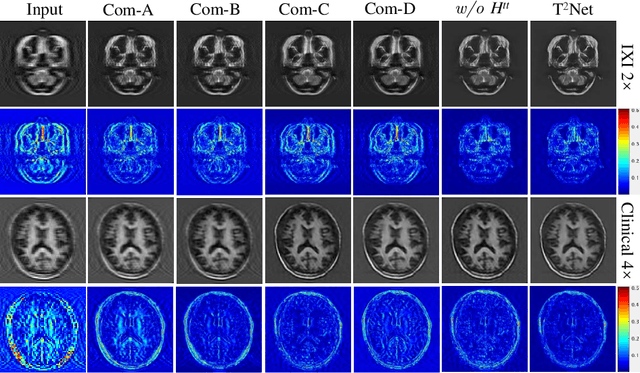
The core problem of Magnetic Resonance Imaging (MRI) is the trade off between acceleration and image quality. Image reconstruction and super-resolution are two crucial techniques in Magnetic Resonance Imaging (MRI). Current methods are designed to perform these tasks separately, ignoring the correlations between them. In this work, we propose an end-to-end task transformer network (T$^2$Net) for joint MRI reconstruction and super-resolution, which allows representations and feature transmission to be shared between multiple task to achieve higher-quality, super-resolved and motion-artifacts-free images from highly undersampled and degenerated MRI data. Our framework combines both reconstruction and super-resolution, divided into two sub-branches, whose features are expressed as queries and keys. Specifically, we encourage joint feature learning between the two tasks, thereby transferring accurate task information. We first use two separate CNN branches to extract task-specific features. Then, a task transformer module is designed to embed and synthesize the relevance between the two tasks. Experimental results show that our multi-task model significantly outperforms advanced sequential methods, both quantitatively and qualitatively.
EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
Jan 11, 2019
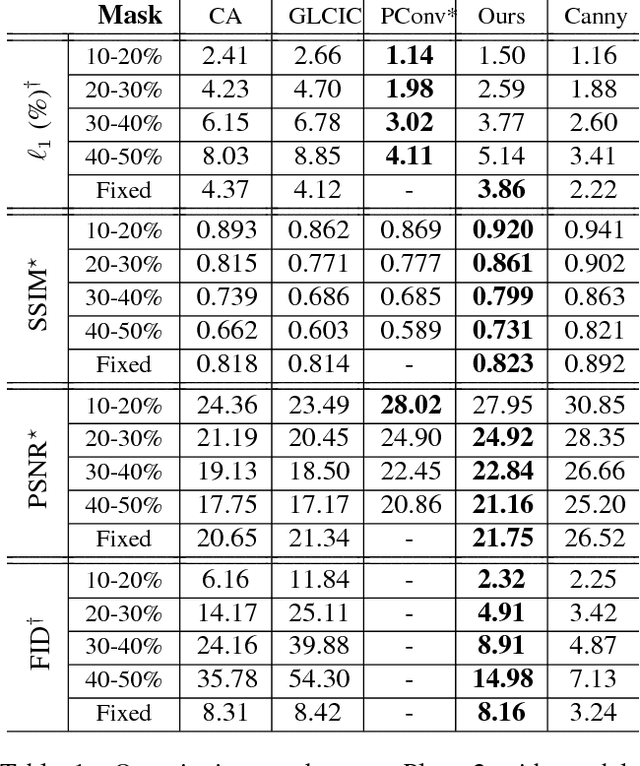
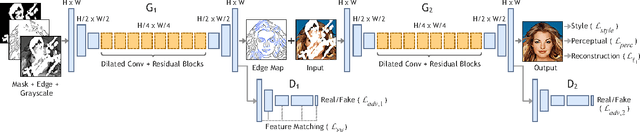
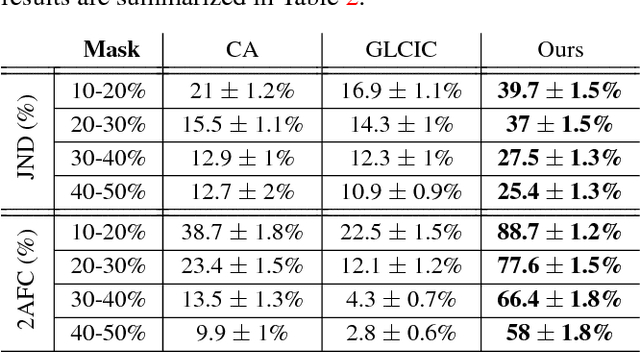
Over the last few years, deep learning techniques have yielded significant improvements in image inpainting. However, many of these techniques fail to reconstruct reasonable structures as they are commonly over-smoothed and/or blurry. This paper develops a new approach for image inpainting that does a better job of reproducing filled regions exhibiting fine details. We propose a two-stage adversarial model EdgeConnect that comprises of an edge generator followed by an image completion network. The edge generator hallucinates edges of the missing region (both regular and irregular) of the image, and the image completion network fills in the missing regions using hallucinated edges as a priori. We evaluate our model end-to-end over the publicly available datasets CelebA, Places2, and Paris StreetView, and show that it outperforms current state-of-the-art techniques quantitatively and qualitatively. Code and models available at: https://github.com/knazeri/edge-connect
DeepHuman: 3D Human Reconstruction from a Single Image
Mar 28, 2019
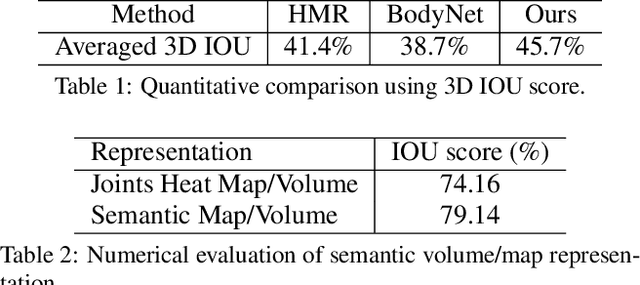
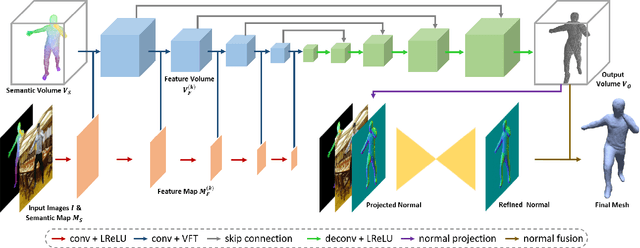
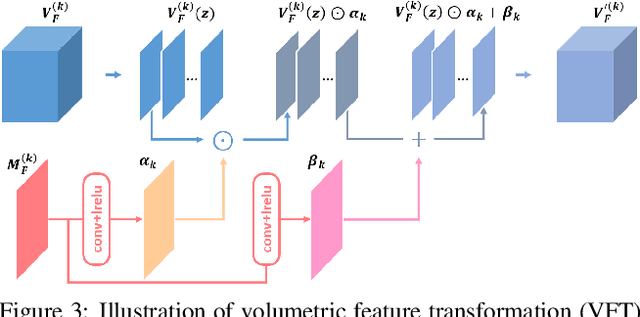
We propose DeepHuman, an image-guided volume-to-volume translation CNN for 3D human reconstruction from a single RGB image. To reduce the ambiguities associated with the surface geometry reconstruction, even for the reconstruction of invisible areas, we propose and leverage a dense semantic representation generated from SMPL model as an additional input. One key feature of our network is that it fuses different scales of image features into the 3D space through volumetric feature transformation, which helps to recover accurate surface geometry. The visible surface details are further refined through a normal refinement network, which can be concatenated with the volume generation network using our proposed volumetric normal projection layer. We also contribute THuman, a 3D real-world human model dataset containing about 7000 models. The network is trained using training data generated from the dataset. Overall, due to the specific design of our network and the diversity in our dataset, our method enables 3D human model estimation given only a single image and outperforms state-of-the-art approaches.
Defoiling Foiled Image Captions
May 16, 2018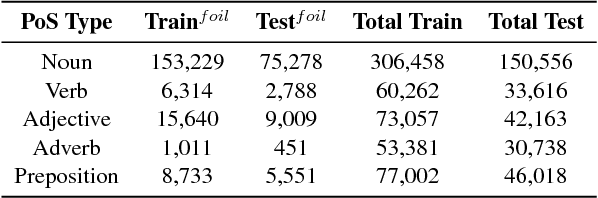

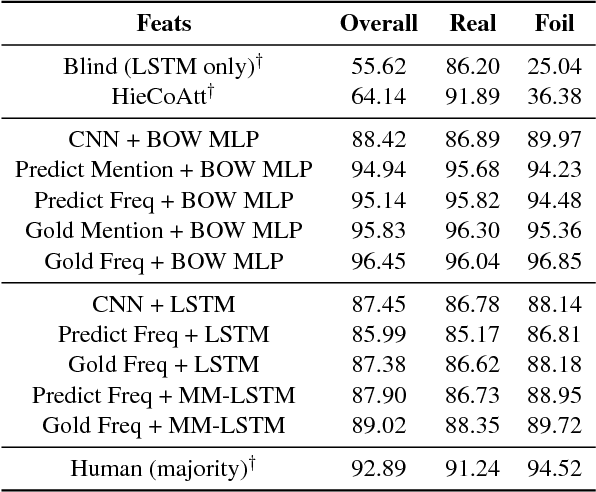
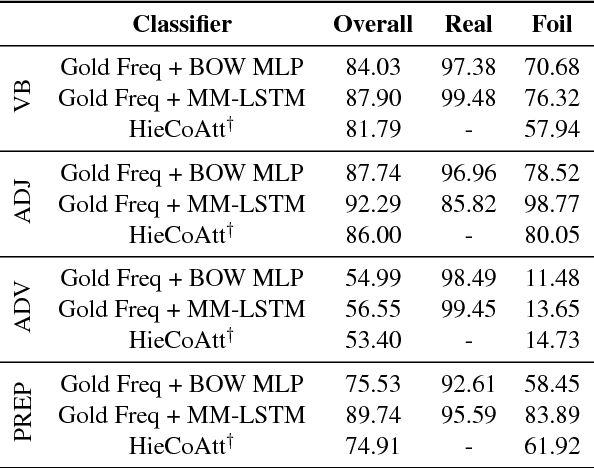
We address the task of detecting foiled image captions, i.e. identifying whether a caption contains a word that has been deliberately replaced by a semantically similar word, thus rendering it inaccurate with respect to the image being described. Solving this problem should in principle require a fine-grained understanding of images to detect linguistically valid perturbations in captions. In such contexts, encoding sufficiently descriptive image information becomes a key challenge. In this paper, we demonstrate that it is possible to solve this task using simple, interpretable yet powerful representations based on explicit object information. Our models achieve state-of-the-art performance on a standard dataset, with scores exceeding those achieved by humans on the task. We also measure the upper-bound performance of our models using gold standard annotations. Our analysis reveals that the simpler model performs well even without image information, suggesting that the dataset contains strong linguistic bias.
Comparative Performance Analysis of Image De-noising Techniques
Jan 19, 2019
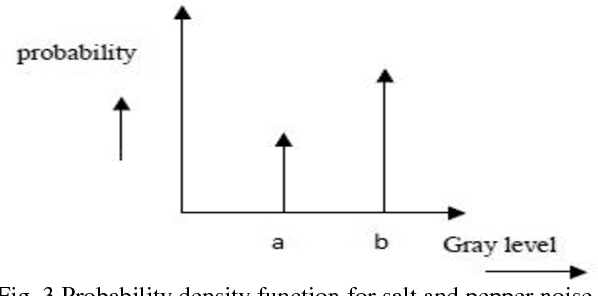

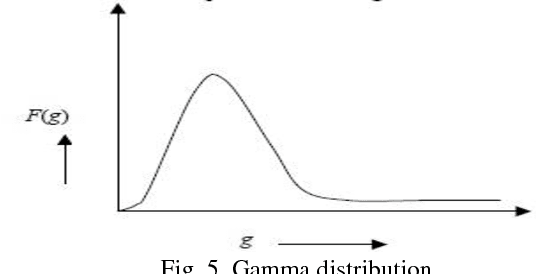
Noise is an important factor which when get added to an image reduces its quality and appearance. So in order to enhance the image qualities, it has to be removed with preserving the textural information and structural features of image. There are different types of noises exist who corrupt the images. Selection of the denoising algorithm is application dependent. Hence, it is necessary to have knowledge about the noise present in the image so as to select the appropriate denoising algorithm. Objective of this paper is to present brief account on types of noises, its types and different noise removal algorithms. In the first section types of noises on the basis of their additive and multiplicative nature are being discussed. In second section a precise classification and analysis of the different potential image denoising algorithm is presented. At the end of paper, a comparative study of all these algorithms in context of performance evaluation is done and concluded with several promising directions for future research work.
* 6 pages, 9 figures, 1 Table, International Conference on Innovations in Engineering and Technology (ICIET'2013) Dec. 25-26, 2013 Bangkok (Thailand)
Synergistic Image and Feature Adaptation: Towards Cross-Modality Domain Adaptation for Medical Image Segmentation
Jan 24, 2019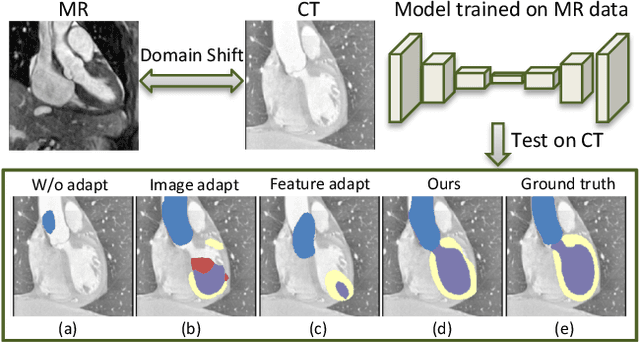
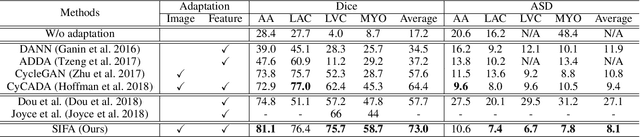
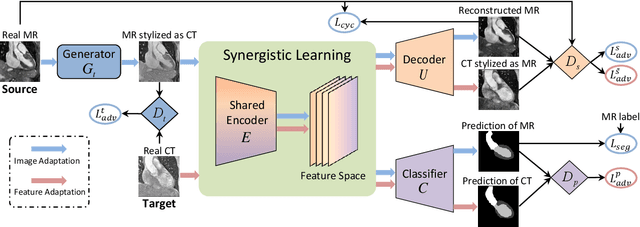

This paper presents a novel unsupervised domain adaptation framework, called Synergistic Image and Feature Adaptation (SIFA), to effectively tackle the problem of domain shift. Domain adaptation has become an important and hot topic in recent studies on deep learning, aiming to recover performance degradation when applying the neural networks to new testing domains. Our proposed SIFA is an elegant learning diagram which presents synergistic fusion of adaptations from both image and feature perspectives. In particular, we simultaneously transform the appearance of images across domains and enhance domain-invariance of the extracted features towards the segmentation task. The feature encoder layers are shared by both perspectives to grasp their mutual benefits during the end-to-end learning procedure. Without using any annotation from the target domain, the learning of our unified model is guided by adversarial losses, with multiple discriminators employed from various aspects. We have extensively validated our method with a challenging application of cross-modality medical image segmentation of cardiac structures. Experimental results demonstrate that our SIFA model recovers the degraded performance from 17.2% to 73.0%, and outperforms the state-of-the-art methods by a significant margin.
A Novel Patch Convolutional Neural Network for View-based 3D Model Retrieval
Sep 25, 2021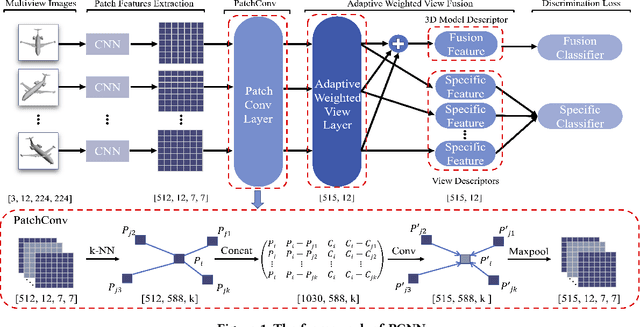
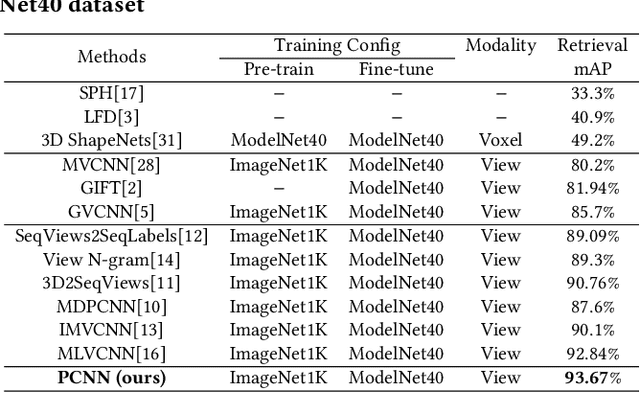
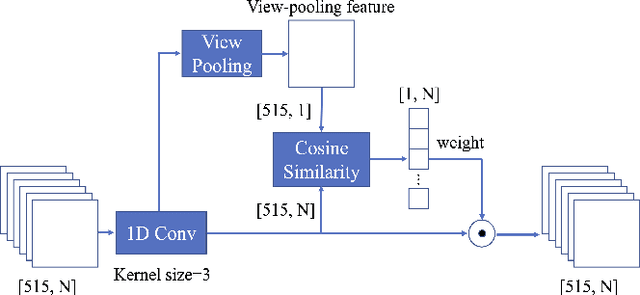
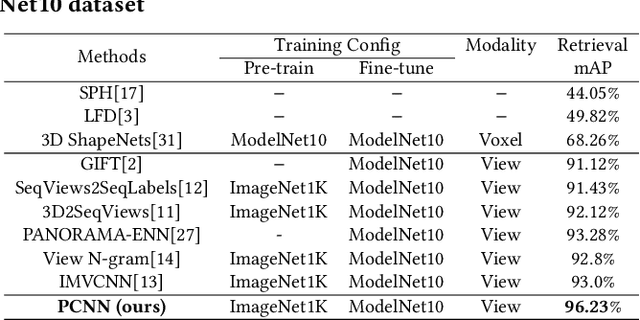
Recently, many view-based 3D model retrieval methods have been proposed and have achieved state-of-the-art performance. Most of these methods focus on extracting more discriminative view-level features and effectively aggregating the multi-view images of a 3D model, but the latent relationship among these multi-view images is not fully explored. Thus, we tackle this problem from the perspective of exploiting the relationships between patch features to capture long-range associations among multi-view images. To capture associations among views, in this work, we propose a novel patch convolutional neural network (PCNN) for view-based 3D model retrieval. Specifically, we first employ a CNN to extract patch features of each view image separately. Secondly, a novel neural network module named PatchConv is designed to exploit intrinsic relationships between neighboring patches in the feature space to capture long-range associations among multi-view images. Then, an adaptive weighted view layer is further embedded into PCNN to automatically assign a weight to each view according to the similarity between each view feature and the view-pooling feature. Finally, a discrimination loss function is employed to extract the discriminative 3D model feature, which consists of softmax loss values generated by the fusion lassifier and the specific classifier. Extensive experimental results on two public 3D model retrieval benchmarks, namely, the ModelNet40, and ModelNet10, demonstrate that our proposed PCNN can outperform state-of-the-art approaches, with mAP alues of 93.67%, and 96.23%, respectively.
Local Activity-tuned Image Filtering for Noise Removal and Image Smoothing
Nov 18, 2017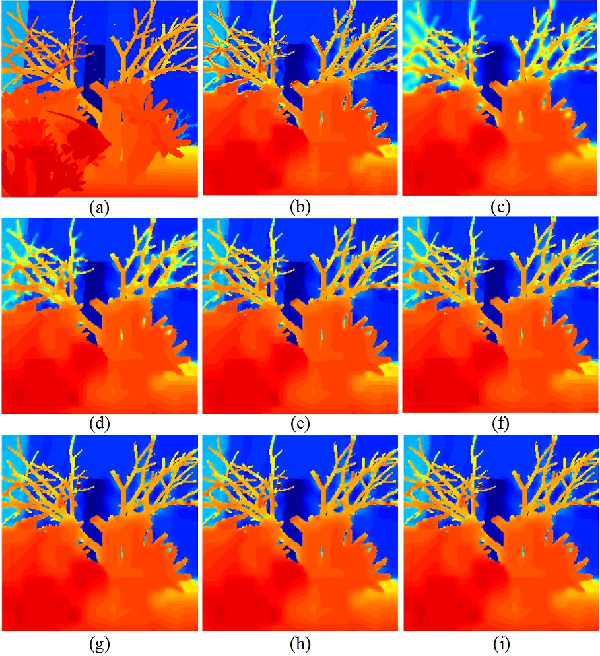
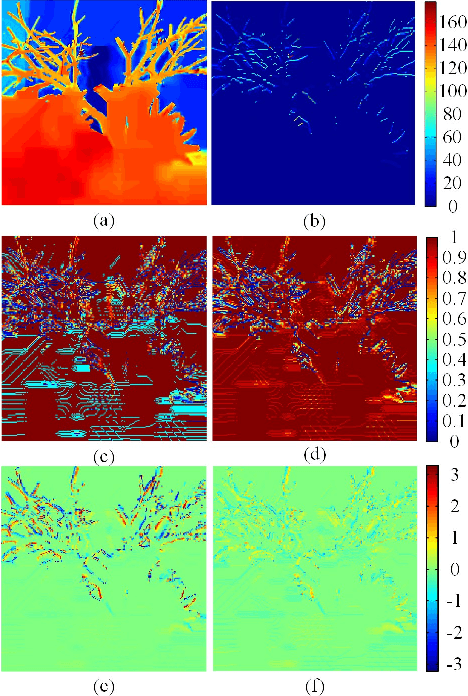

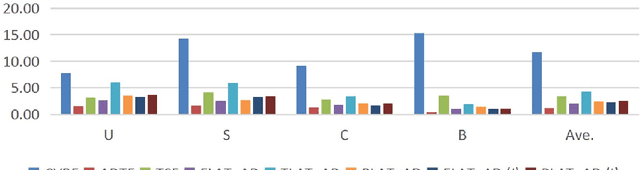
In this paper, two local activity-tuned filtering frameworks are proposed for noise removal and image smoothing, where the local activity measurement is given by the clipped and normalized local variance or standard deviation. The first framework is a modified anisotropic diffusion for noise removal of piece-wise smooth image. The second framework is a local activity-tuned Relative Total Variation (LAT-RTV) method for image smoothing. Both frameworks employ the division of gradient and the local activity measurement to achieve noise removal. In addition, to better capture local information, the proposed LAT-RTV uses the product of gradient and local activity measurement to boost the performance of image smoothing. Experimental results are presented to demonstrate the efficiency of the proposed methods on various applications, including depth image filtering, clip-art compression artifact removal, image smoothing, and image denoising.