 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visibility graphs for image processing
Apr 19, 2018
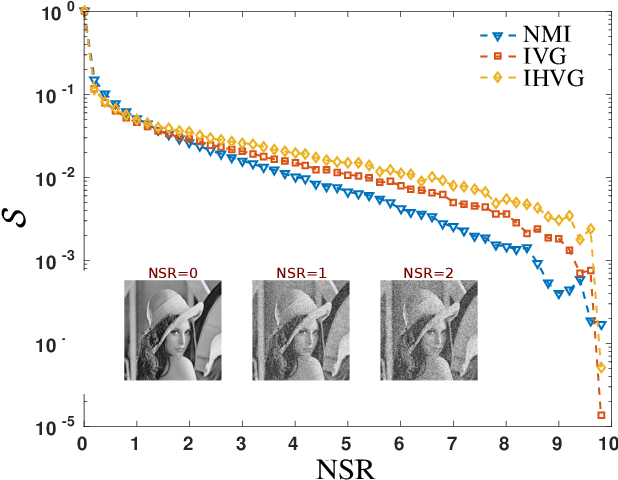
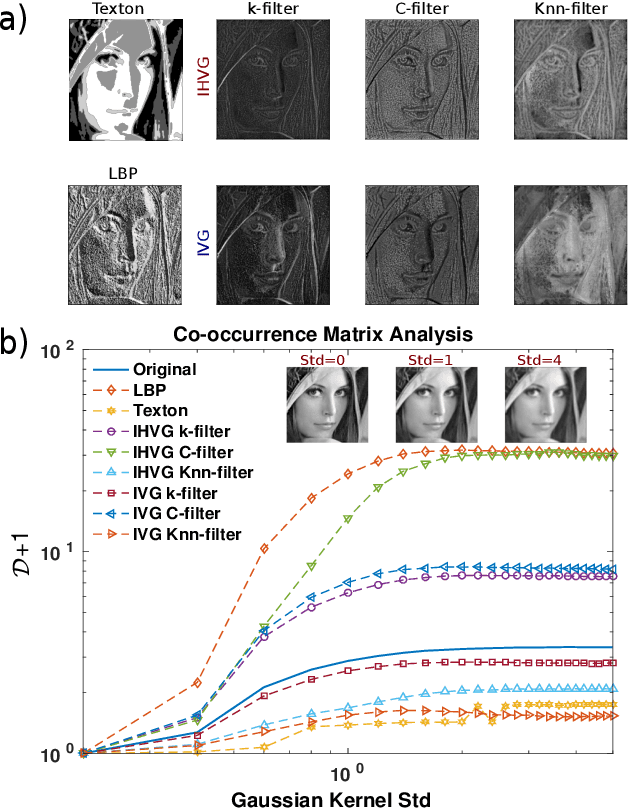
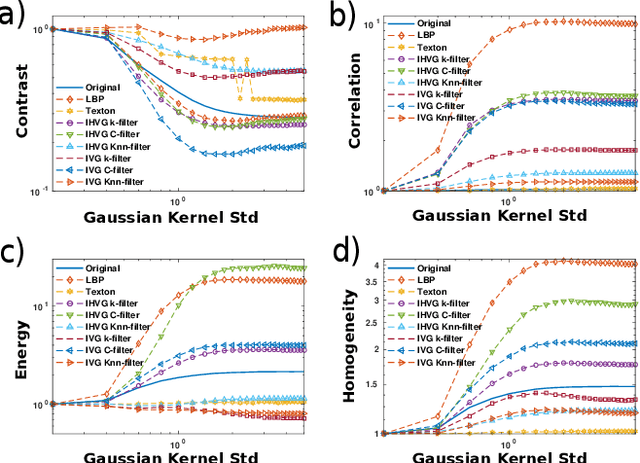

The family of image visibility graphs (IVGs) have been recently introduced as simple algorithms by which scalar fields can be mapped into graphs. Here we explore the usefulness of such operator in the scenario of image processing and image classification. We demonstrate that the link architecture of the image visibility graphs encapsulates relevant information on the structure of the images and we explore their potential as image filters and compressors. We introduce several graph features, including the novel concept of Visibility Patches, and show through several examples that these features are highly informative, computationally efficient and universally applicable for general pattern recognition and image classification tasks.
A new smart-cropping pipeline for prostate segmentation using deep learning networks
Jul 07, 2021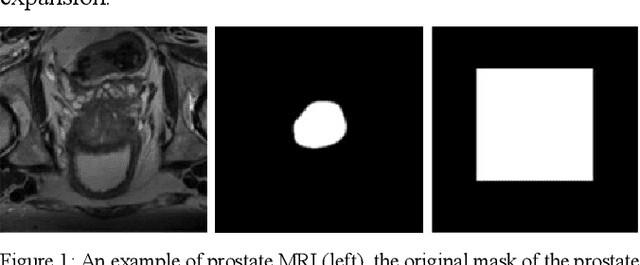
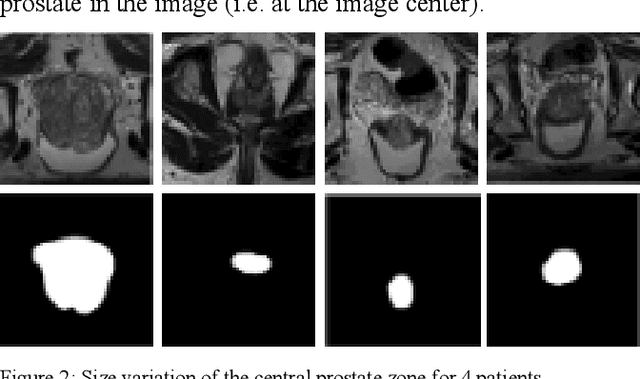
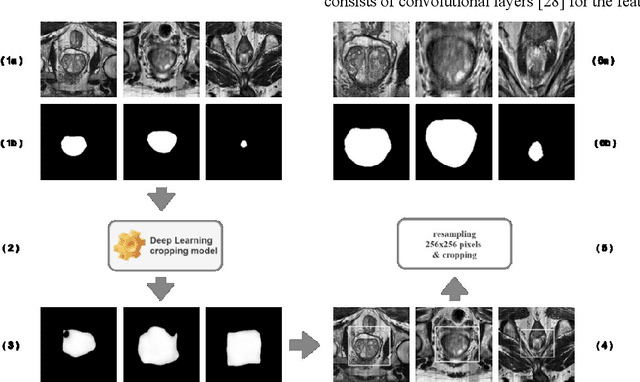
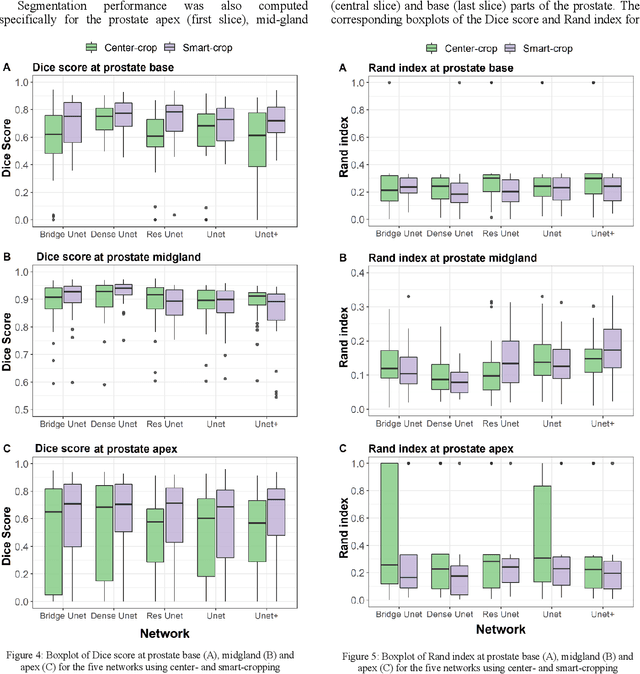
Prostate segmentation from magnetic resonance imaging (MRI) is a challenging task. In recent years, several network architectures have been proposed to automate this process and alleviate the burden of manual annotation. Although the performance of these models has achieved promising results, there is still room for improvement before these models can be used safely and effectively in clinical practice. One of the major challenges in prostate MR image segmentation is the presence of class imbalance in the image labels where the background pixels dominate over the prostate. In the present work we propose a DL-based pipeline for cropping the region around the prostate from MRI images to produce a more balanced distribution of the foreground pixels (prostate) and the background pixels and improve segmentation accuracy. The effect of DL-cropping for improving the segmentation performance compared to standard center-cropping is assessed using five popular DL networks for prostate segmentation, namely U-net, U-net+, Res Unet++, Bridge U-net and Dense U-net. The proposed smart-cropping outperformed the standard center cropping in terms of segmentation accuracy for all the evaluated prostate segmentation networks. In terms of Dice score, the highest improvement was achieved for the U-net+ and ResU-net++ architectures corresponding to 8.9% and 8%, respectively.
Exploring Visual Relationship for Image Captioning
Sep 19, 2018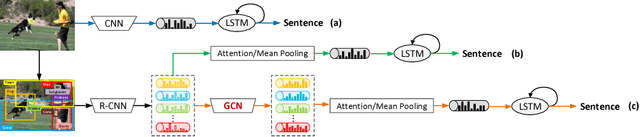
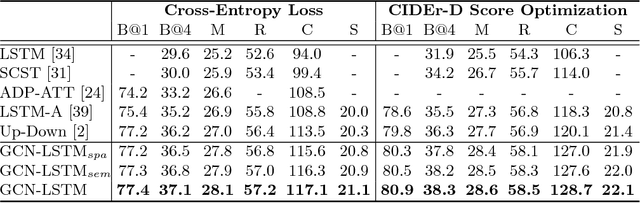
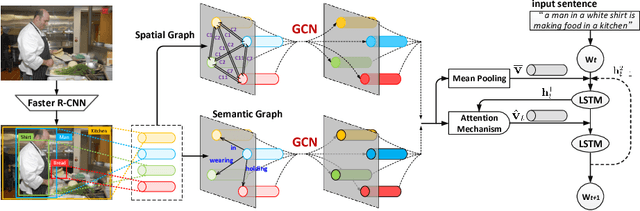
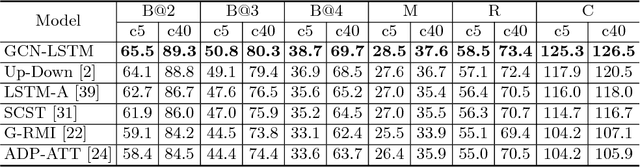
It is always well believed that modeling relationships between objects would be helpful for representing and eventually describing an image. Nevertheless, there has not been evidence in support of the idea on image description generation. In this paper, we introduce a new design to explore the connections between objects for image captioning under the umbrella of attention-based encoder-decoder framework. Specifically, we present Graph Convolutional Networks plus Long Short-Term Memory (dubbed as GCN-LSTM) architecture that novelly integrates both semantic and spatial object relationships into image encoder. Technically, we build graphs over the detected objects in an image based on their spatial and semantic connections. The representations of each region proposed on objects are then refined by leveraging graph structure through GCN. With the learnt region-level features, our GCN-LSTM capitalizes on LSTM-based captioning framework with attention mechanism for sentence generation. Extensive experiments are conducted on COCO image captioning dataset, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, GCN-LSTM increases CIDEr-D performance from 120.1% to 128.7% on COCO testing set.
Every Annotation Counts: Multi-label Deep Supervision for Medical Image Segmentation
Apr 27, 2021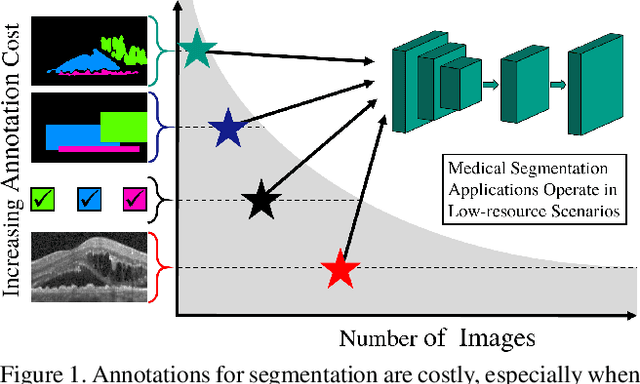
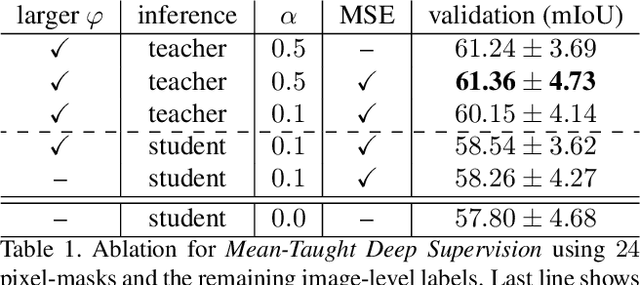
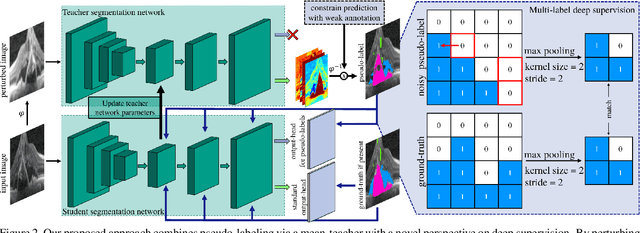
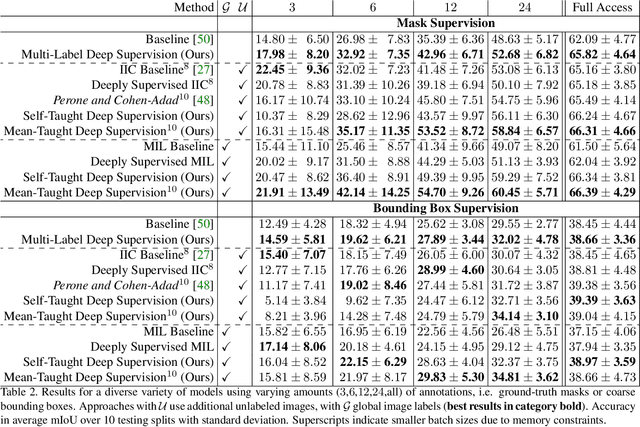
Pixel-wise segmentation is one of the most data and annotation hungry tasks in our field. Providing representative and accurate annotations is often mission-critical especially for challenging medical applications. In this paper, we propose a semi-weakly supervised segmentation algorithm to overcome this barrier. Our approach is based on a new formulation of deep supervision and student-teacher model and allows for easy integration of different supervision signals. In contrast to previous work, we show that care has to be taken how deep supervision is integrated in lower layers and we present multi-label deep supervision as the most important secret ingredient for success. With our novel training regime for segmentation that flexibly makes use of images that are either fully labeled, marked with bounding boxes, just global labels, or not at all, we are able to cut the requirement for expensive labels by 94.22% - narrowing the gap to the best fully supervised baseline to only 5% mean IoU. Our approach is validated by extensive experiments on retinal fluid segmentation and we provide an in-depth analysis of the anticipated effect each annotation type can have in boosting segmentation performance.
Transformer Network for Significant Stenosis Detection in CCTA of Coronary Arteries
Jul 07, 2021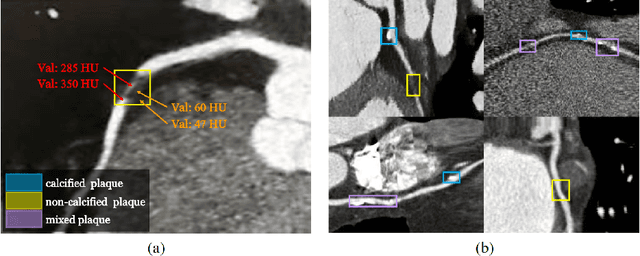
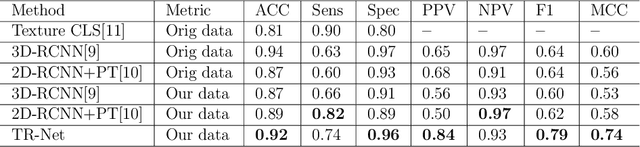
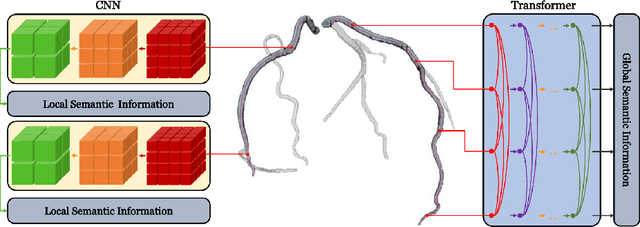
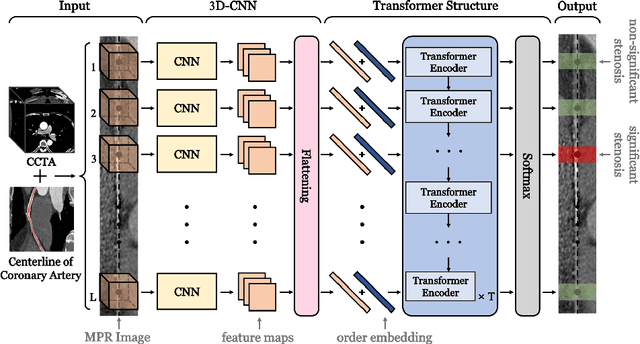
Coronary artery disease (CAD) has posed a leading threat to the lives of cardiovascular disease patients worldwide for a long time. Therefore, automated diagnosis of CAD has indispensable significance in clinical medicine. However, the complexity of coronary artery plaques that cause CAD makes the automatic detection of coronary artery stenosis in Coronary CT angiography (CCTA) a difficult task. In this paper, we propose a Transformer network (TR-Net) for the automatic detection of significant stenosis (i.e. luminal narrowing > 50%) while practically completing the computer-assisted diagnosis of CAD. The proposed TR-Net introduces a novel Transformer, and tightly combines convolutional layers and Transformer encoders, allowing their advantages to be demonstrated in the task. By analyzing semantic information sequences, TR-Net can fully understand the relationship between image information in each position of a multiplanar reformatted (MPR) image, and accurately detect significant stenosis based on both local and global information. We evaluate our TR-Net on a dataset of 76 patients from different patients annotated by experienced radiologists. Experimental results illustrate that our TR-Net has achieved better results in ACC (0.92), Spec (0.96), PPV (0.84), F1 (0.79) and MCC (0.74) indicators compared with the state-of-the-art methods. The source code is publicly available from the link (https://github.com/XinghuaMa/TR-Net).
YouRefIt: Embodied Reference Understanding with Language and Gesture
Sep 08, 2021
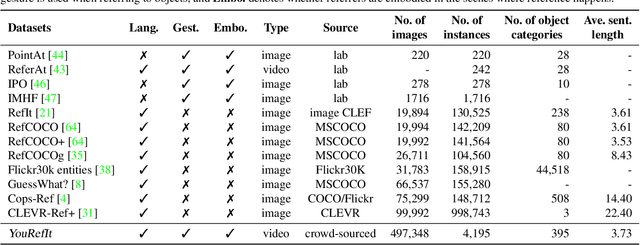

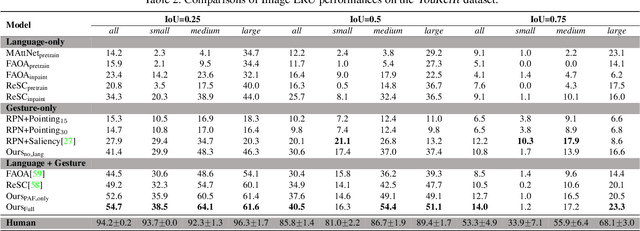
We study the understanding of embodied reference: One agent uses both language and gesture to refer to an object to another agent in a shared physical environment. Of note, this new visual task requires understanding multimodal cues with perspective-taking to identify which object is being referred to. To tackle this problem, we introduce YouRefIt, a new crowd-sourced dataset of embodied reference collected in various physical scenes; the dataset contains 4,195 unique reference clips in 432 indoor scenes. To the best of our knowledge, this is the first embodied reference dataset that allows us to study referring expressions in daily physical scenes to understand referential behavior, human communication, and human-robot interaction. We further devise two benchmarks for image-based and video-based embodied reference understanding. Comprehensive baselines and extensive experiments provide the very first result of machine perception on how the referring expressions and gestures affect the embodied reference understanding. Our results provide essential evidence that gestural cues are as critical as language cues in understanding the embodied reference.
Boosting in Image Quality Assessment
Nov 21, 2018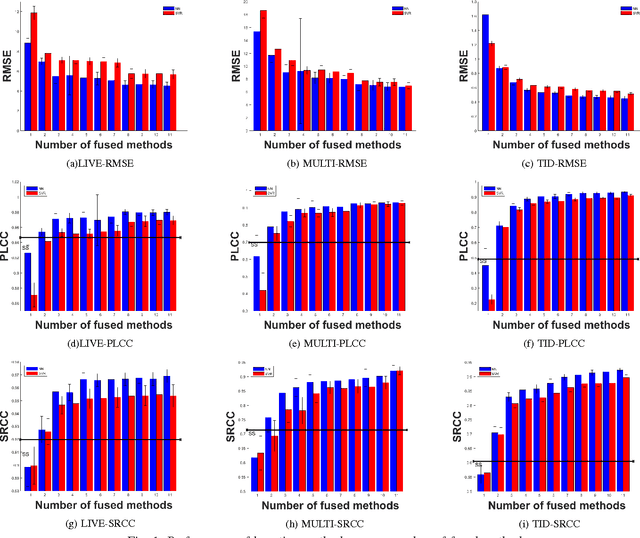
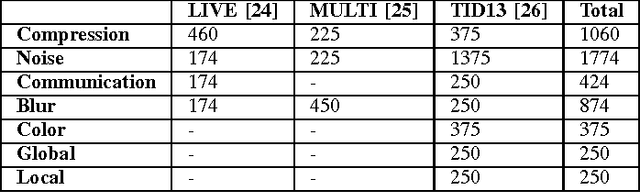
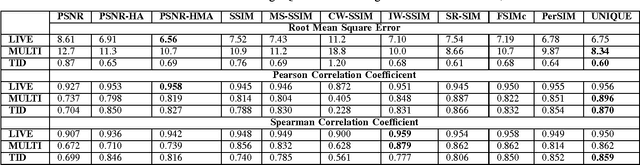
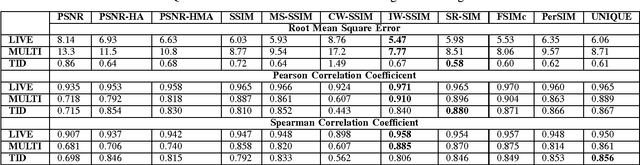
In this paper, we analyze the effect of boosting in image quality assessment through multi-method fusion. Existing multi-method studies focus on proposing a single quality estimator. On the contrary, we investigate the generalizability of multi-method fusion as a framework. In addition to support vector machines that are commonly used in the multi-method fusion, we propose using neural networks in the boosting. To span different types of image quality assessment algorithms, we use quality estimators based on fidelity, perceptually-extended fidelity, structural similarity, spectral similarity, color, and learning. In the experiments, we perform k-fold cross validation using the LIVE, the multiply distorted LIVE, and the TID 2013 databases and the performance of image quality assessment algorithms are measured via accuracy-, linearity-, and ranking-based metrics. Based on the experiments, we show that boosting methods generally improve the performance of image quality assessment and the level of improvement depends on the type of the boosting algorithm. Our experimental results also indicate that boosting the worst performing quality estimator with two or more additional methods leads to statistically significant performance enhancements independent of the boosting technique and neural network-based boosting outperforms support vector machine-based boosting when two or more methods are fused.
* Paper: 6 pages, 5 tables, 1 figure, Presentation: 16 slides [Ancillary files]
HAT: Hierarchical Aggregation Transformers for Person Re-identification
Jul 14, 2021
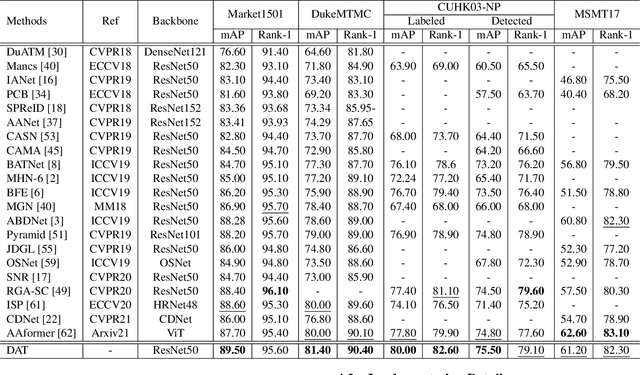
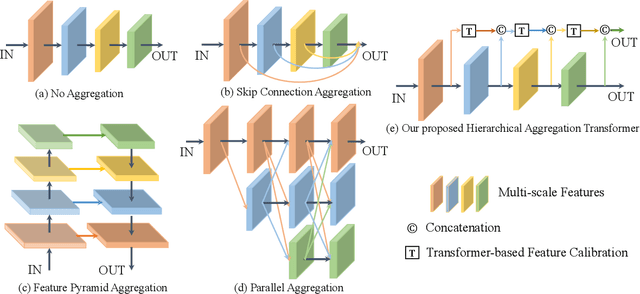
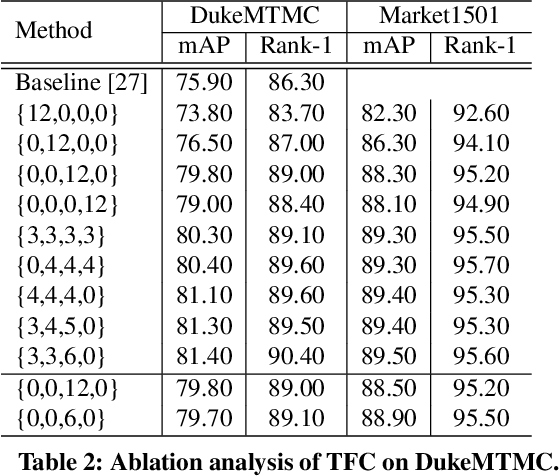
Recently, with the advance of deep Convolutional Neural Networks (CNNs), person Re-Identification (Re-ID) has witnessed great success in various applications. However, with limited receptive fields of CNNs, it is still challenging to extract discriminative representations in a global view for persons under non-overlapped cameras. Meanwhile, Transformers demonstrate strong abilities of modeling long-range dependencies for spatial and sequential data. In this work, we take advantages of both CNNs and Transformers, and propose a novel learning framework named Hierarchical Aggregation Transformer (HAT) for image-based person Re-ID with high performance. To achieve this goal, we first propose a Deeply Supervised Aggregation (DSA) to recurrently aggregate hierarchical features from CNN backbones. With multi-granularity supervisions, the DSA can enhance multi-scale features for person retrieval, which is very different from previous methods. Then, we introduce a Transformer-based Feature Calibration (TFC) to integrate low-level detail information as the global prior for high-level semantic information. The proposed TFC is inserted to each level of hierarchical features, resulting in great performance improvements. To our best knowledge, this work is the first to take advantages of both CNNs and Transformers for image-based person Re-ID. Comprehensive experiments on four large-scale Re-ID benchmarks demonstrate that our method shows better results than several state-of-the-art methods. The code is released at https://github.com/AI-Zhpp/HAT.
End-to-End Deep Convolutional Active Contours for Image Segmentation
Oct 04, 2019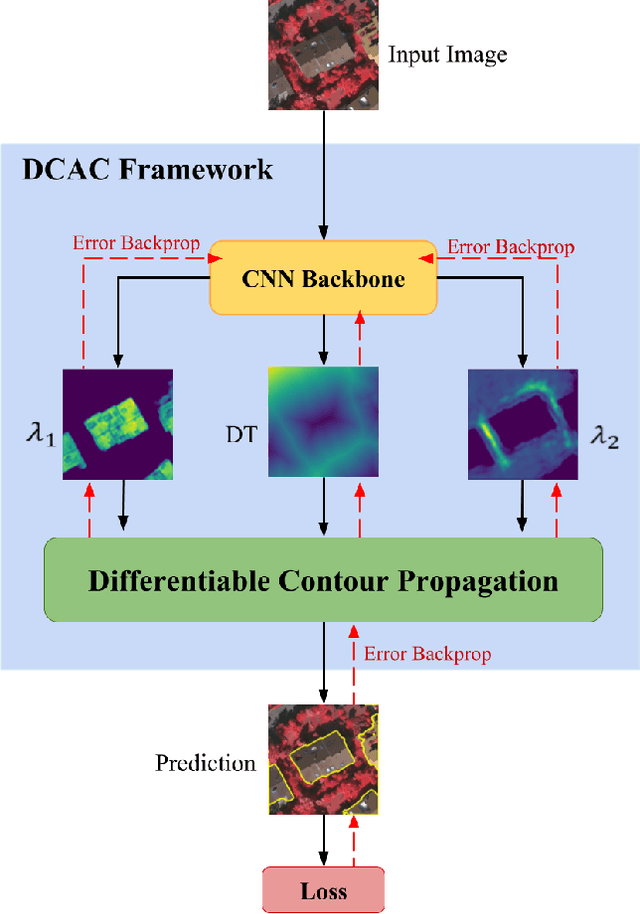
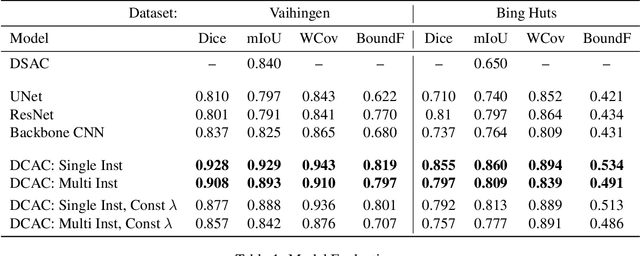
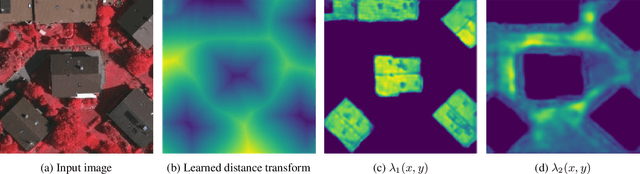
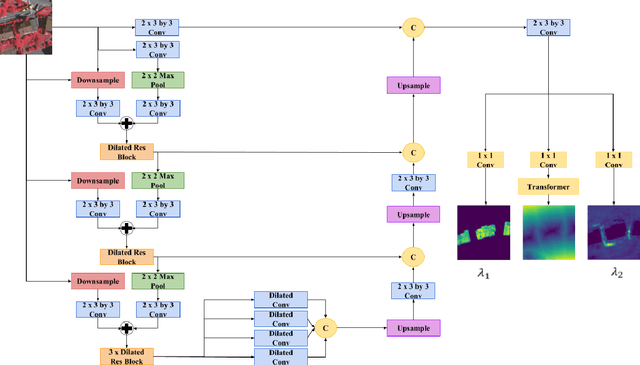
The Active Contour Model (ACM) is a standard image analysis technique whose numerous variants have attracted an enormous amount of research attention across multiple fields. Incorrectly, however, the ACM's differential-equation-based formulation and prototypical dependence on user initialization have been regarded as being largely incompatible with the recently popular deep learning approaches to image segmentation. This paper introduces the first tight unification of these two paradigms. In particular, we devise Deep Convolutional Active Contours (DCAC), a truly end-to-end trainable image segmentation framework comprising a Convolutional Neural Network (CNN) and an ACM with learnable parameters. The ACM's Eulerian energy functional includes per-pixel parameter maps predicted by the backbone CNN, which also initializes the ACM. Importantly, both the CNN and ACM components are fully implemented in TensorFlow, and the entire DCAC architecture is end-to-end automatically differentiable and backpropagation trainable without user intervention. As a challenging test case, we tackle the problem of building instance segmentation in aerial images and evaluate DCAC on two publicly available datasets, Vaihingen and Bing Huts. Our reseults demonstrate that, for building segmentation, the DCAC establishes a new state-of-the-art performance by a wide margin.
Deep Learning for Fine-Grained Image Analysis: A Survey
Jul 06, 2019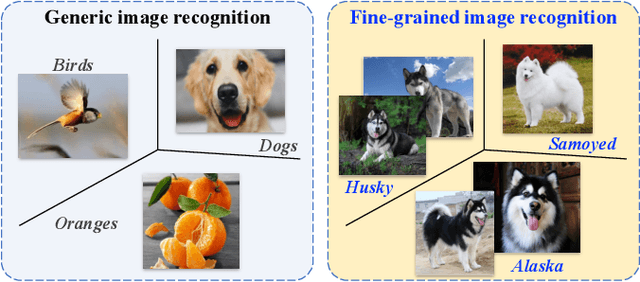
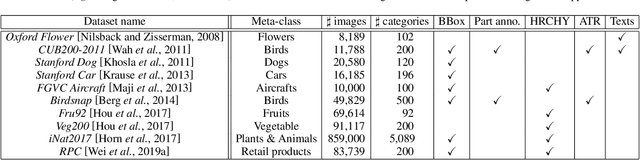
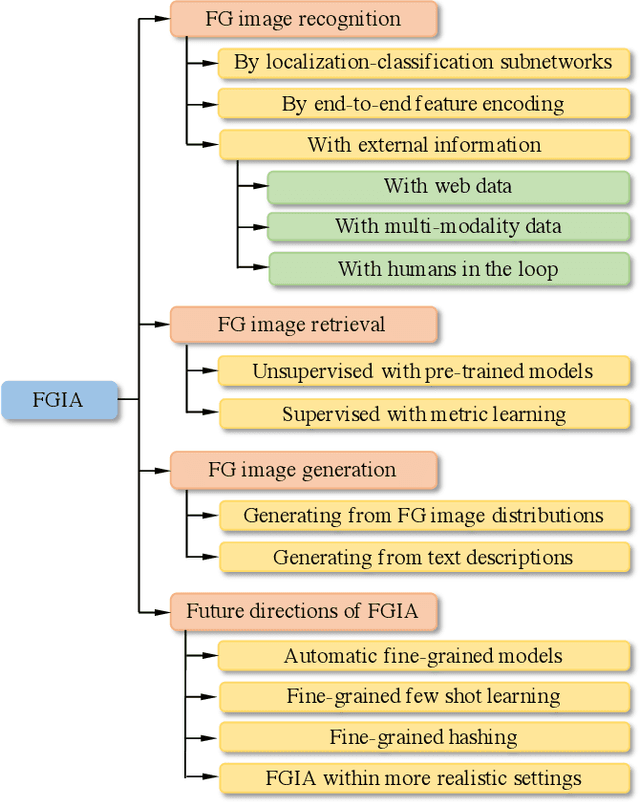

Computer vision (CV) is the process of using machines to understand and analyze imagery, which is an integral branch of artificial intelligence. Among various research areas of CV, fine-grained image analysis (FGIA) is a longstanding and fundamental problem, and has become ubiquitous in diverse real-world applications. The task of FGIA targets analyzing visual objects from subordinate categories, \eg, species of birds or models of cars. The small inter-class variations and the large intra-class variations caused by the fine-grained nature makes it a challenging problem. During the booming of deep learning, recent years have witnessed remarkable progress of FGIA using deep learning techniques. In this paper, we aim to give a survey on recent advances of deep learning based FGIA techniques in a systematic way. Specifically, we organize the existing studies of FGIA techniques into three major categories: fine-grained image recognition, fine-grained image retrieval and fine-grained image generation. In addition, we also cover some other important issues of FGIA, such as publicly available benchmark datasets and its related domain specific applications. Finally, we conclude this survey by highlighting several directions and open problems which need be further explored by the community in the future.