 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hire-MLP: Vision MLP via Hierarchical Rearrangement
Aug 30, 2021
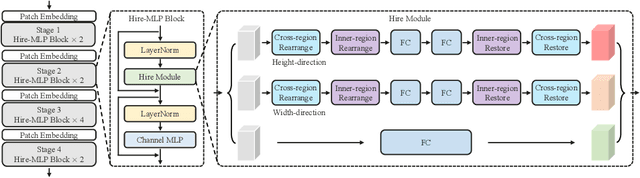
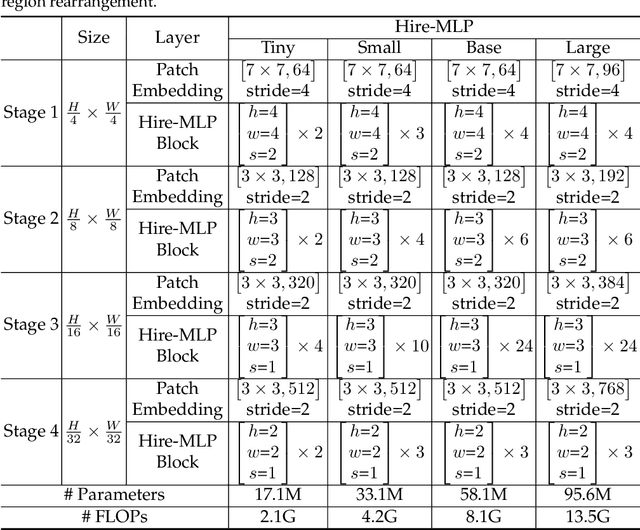
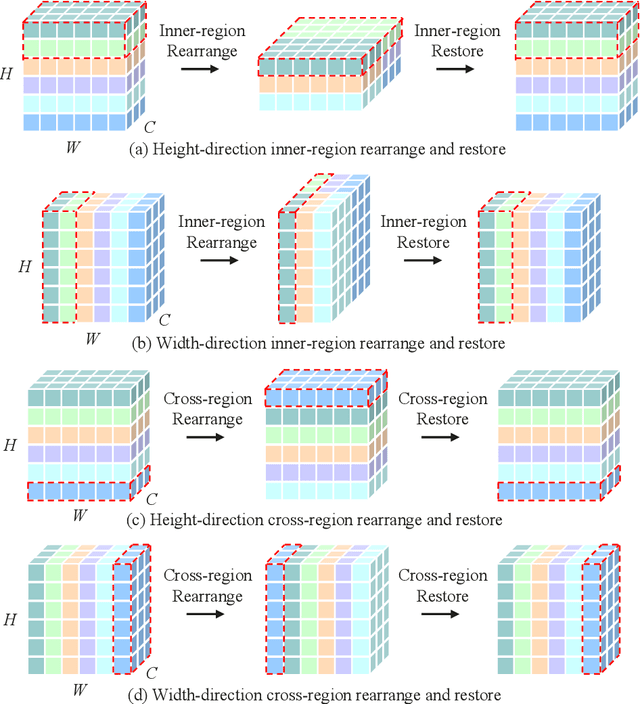
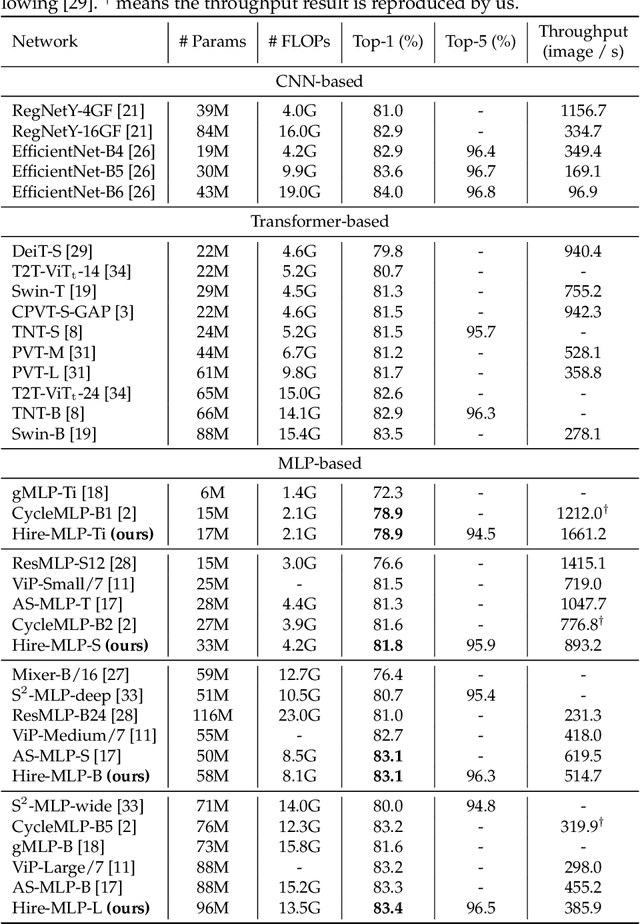
This paper presents Hire-MLP, a simple yet competitive vision MLP architecture via hierarchical rearrangement. Previous vision MLPs like MLP-Mixer are not flexible for various image sizes and are inefficient to capture spatial information by flattening the tokens. Hire-MLP innovates the existing MLP-based models by proposing the idea of hierarchical rearrangement to aggregate the local and global spatial information while being versatile for downstream tasks. Specifically, the inner-region rearrangement is designed to capture local information inside a spatial region. Moreover, to enable information communication between different regions and capture global context, the cross-region rearrangement is proposed to circularly shift all tokens along spatial directions. The proposed Hire-MLP architecture is built with simple channel-mixing MLPs and rearrangement operations, thus enjoys high flexibility and inference speed. Experiments show that our Hire-MLP achieves state-of-the-art performance on the ImageNet-1K benchmark. In particular, Hire-MLP achieves an 83.4\% top-1 accuracy on ImageNet, which surpasses previous Transformer-based and MLP-based models with better trade-off for accuracy and throughput.
Learning to Ground Visual Objects for Visual Dialog
Sep 13, 2021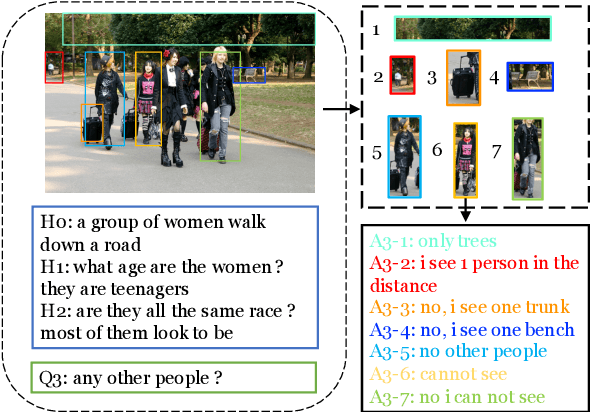
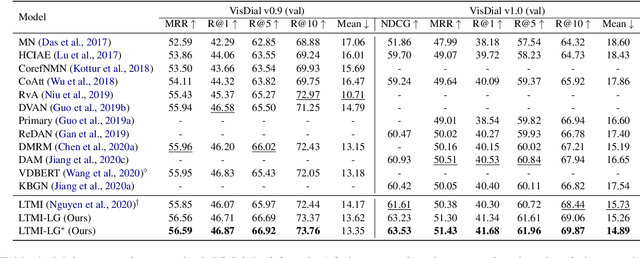
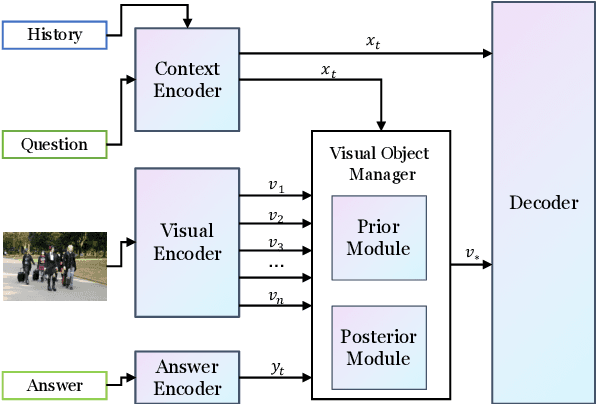
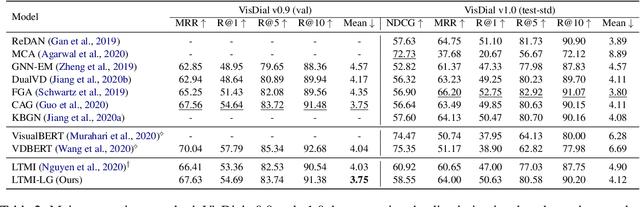
Visual dialog is challenging since it needs to answer a series of coherent questions based on understanding the visual environment. How to ground related visual objects is one of the key problems. Previous studies utilize the question and history to attend to the image and achieve satisfactory performance, however these methods are not sufficient to locate related visual objects without any guidance. The inappropriate grounding of visual objects prohibits the performance of visual dialog models. In this paper, we propose a novel approach to Learn to Ground visual objects for visual dialog, which employs a novel visual objects grounding mechanism where both prior and posterior distributions over visual objects are used to facilitate visual objects grounding. Specifically, a posterior distribution over visual objects is inferred from both context (history and questions) and answers, and it ensures the appropriate grounding of visual objects during the training process. Meanwhile, a prior distribution, which is inferred from context only, is used to approximate the posterior distribution so that appropriate visual objects can be grounded even without answers during the inference process. Experimental results on the VisDial v0.9 and v1.0 datasets demonstrate that our approach improves the previous strong models in both generative and discriminative settings by a significant margin.
Deep Image Super Resolution via Natural Image Priors
Feb 08, 2018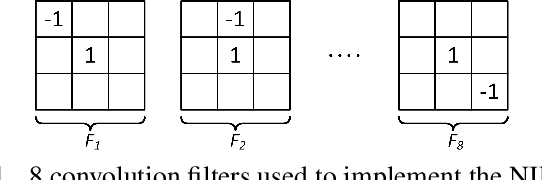
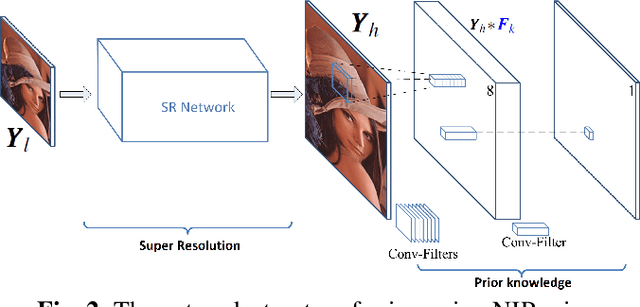
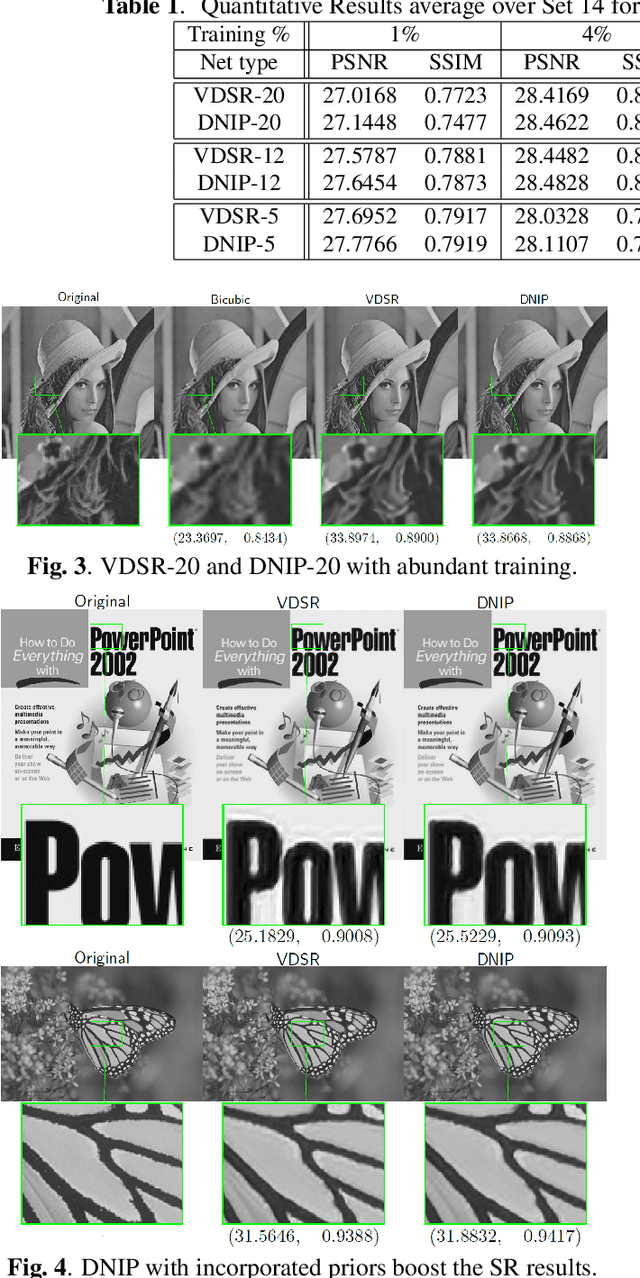
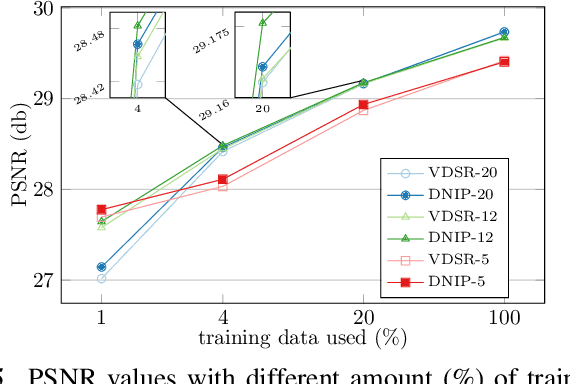
Single image super-resolution (SR) via deep learning has recently gained significant attention in the literature. Convolutional neural networks (CNNs) are typically learned to represent the mapping between low-resolution (LR) and high-resolution (HR) images/patches with the help of training examples. Most existing deep networks for SR produce high quality results when training data is abundant. However, their performance degrades sharply when training is limited. We propose to regularize deep structures with prior knowledge about the images so that they can capture more structural information from the same limited data. In particular, we incorporate in a tractable fashion within the CNN framework, natural image priors which have shown to have much recent success in imaging and vision inverse problems. Experimental results show that the proposed deep network with natural image priors is particularly effective in training starved regimes.
A Novel Patch Convolutional Neural Network for View-based 3D Model Retrieval
Sep 25, 2021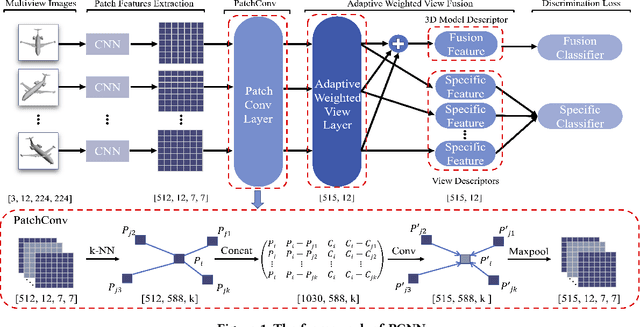
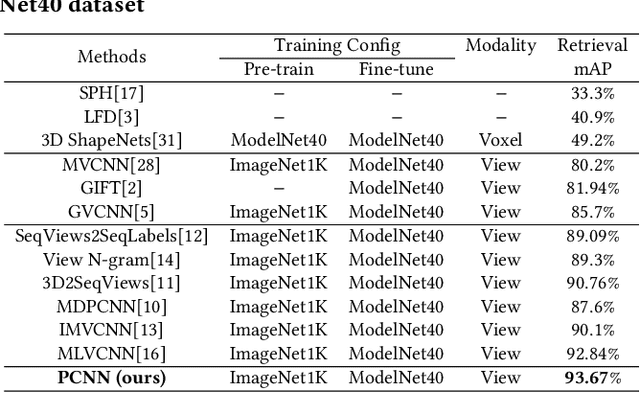
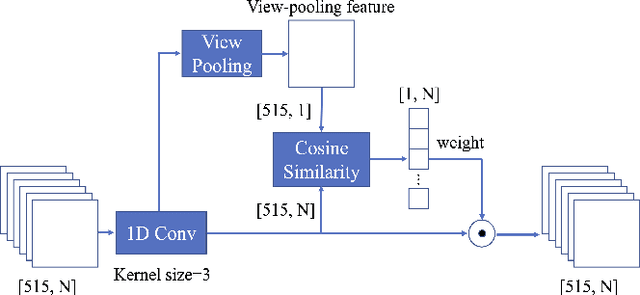
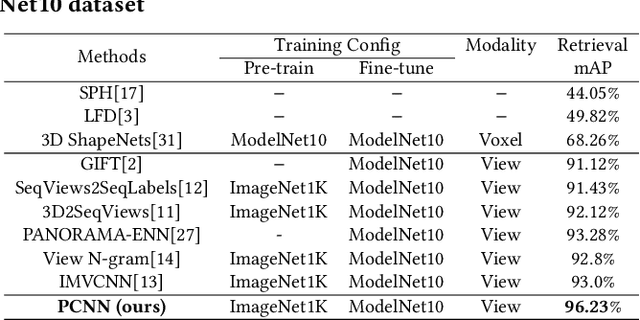
Recently, many view-based 3D model retrieval methods have been proposed and have achieved state-of-the-art performance. Most of these methods focus on extracting more discriminative view-level features and effectively aggregating the multi-view images of a 3D model, but the latent relationship among these multi-view images is not fully explored. Thus, we tackle this problem from the perspective of exploiting the relationships between patch features to capture long-range associations among multi-view images. To capture associations among views, in this work, we propose a novel patch convolutional neural network (PCNN) for view-based 3D model retrieval. Specifically, we first employ a CNN to extract patch features of each view image separately. Secondly, a novel neural network module named PatchConv is designed to exploit intrinsic relationships between neighboring patches in the feature space to capture long-range associations among multi-view images. Then, an adaptive weighted view layer is further embedded into PCNN to automatically assign a weight to each view according to the similarity between each view feature and the view-pooling feature. Finally, a discrimination loss function is employed to extract the discriminative 3D model feature, which consists of softmax loss values generated by the fusion lassifier and the specific classifier. Extensive experimental results on two public 3D model retrieval benchmarks, namely, the ModelNet40, and ModelNet10, demonstrate that our proposed PCNN can outperform state-of-the-art approaches, with mAP alues of 93.67%, and 96.23%, respectively.
Image declipping with deep networks
Nov 15, 2018

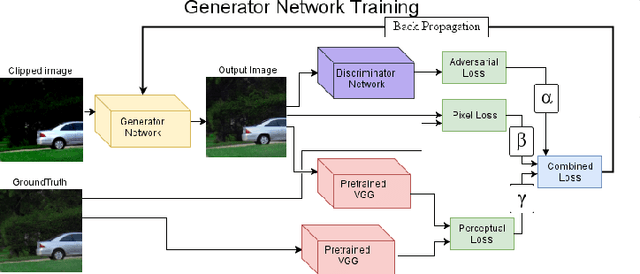

We present a deep network to recover pixel values lost to clipping. The clipped area of the image is typically a uniform area of minimum or maximum brightness, losing image detail and color fidelity. The degree to which the clipping is visually noticeable depends on the amount by which values were clipped, and the extent of the clipped area. Clipping may occur in any (or all) of the pixel's color channels. Although clipped pixels are common and occur to some degree in almost every image we tested, current automatic solutions have only partial success in repairing clipped pixels and work only in limited cases such as only with overexposure (not under-exposure) and when some of the color channels are not clipped. Using neural networks and their ability to model natural images allows our neural network, DeclipNet, to reconstruct data in clipped regions producing state of the art results.
* 5 pages
Predicting Depth from Semantic Segmentation using Game Engine Dataset
Jun 12, 2021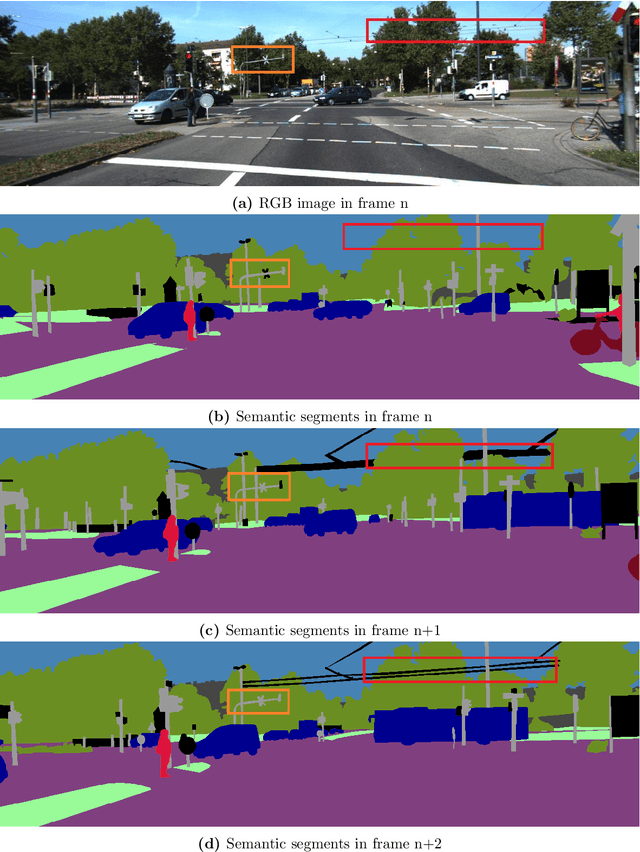
Depth perception is fundamental for robots to understand the surrounding environment. As the view of cognitive neuroscience, visual depth perception methods are divided into three categories, namely binocular, active, and pictorial. The first two categories have been studied for decades in detail. However, research for the exploration of the third category is still in its infancy and has got momentum by the advent of deep learning methods in recent years. In cognitive neuroscience, it is known that pictorial depth perception mechanisms are dependent on the perception of seen objects. Inspired by this fact, in this thesis, we investigated the relation of perception of objects and depth estimation convolutional neural networks. For this purpose, we developed new network structures based on a simple depth estimation network that only used a single image at its input. Our proposed structures use both an image and a semantic label of the image as their input. We used semantic labels as the output of object perception. The obtained results of performance comparison between the developed network and original network showed that our novel structures can improve the performance of depth estimation by 52\% of relative error of distance in the examined cases. Most of the experimental studies were carried out on synthetic datasets that were generated by game engines to isolate the performance comparison from the effect of inaccurate depth and semantic labels of non-synthetic datasets. It is shown that particular synthetic datasets may be used for training of depth networks in cases that an appropriate dataset is not available. Furthermore, we showed that in these cases, usage of semantic labels improves the robustness of the network against domain shift from synthetic training data to non-synthetic test data.
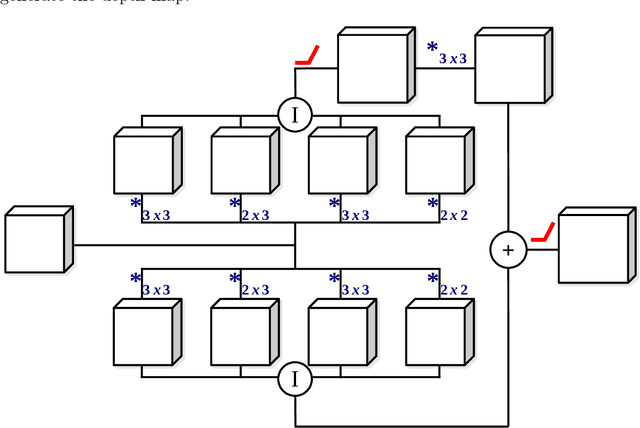
Recursive-NeRF: An Efficient and Dynamically Growing NeRF
May 19, 2021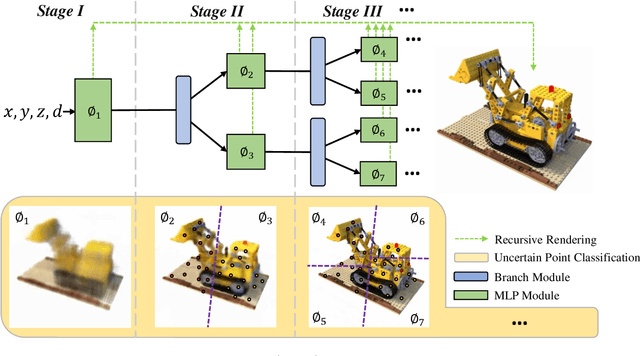
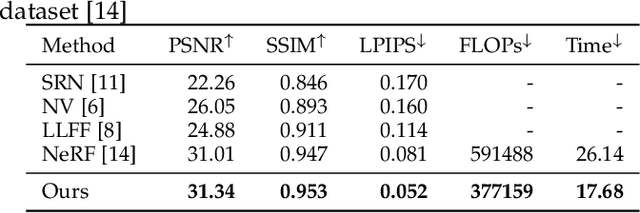
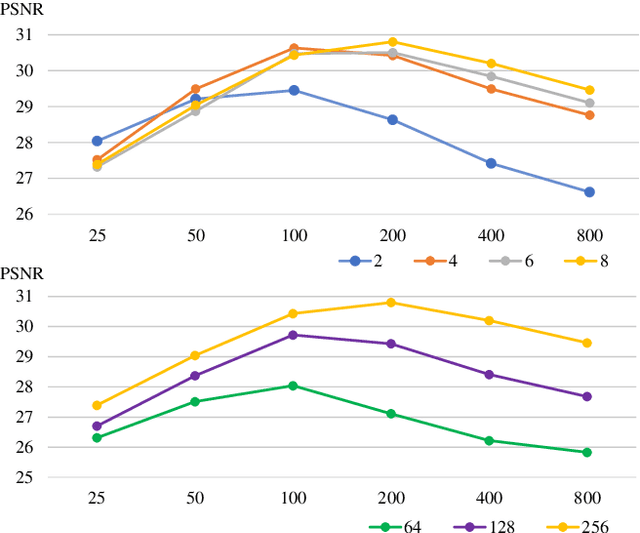
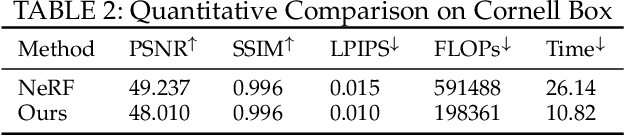
View synthesis methods using implicit continuous shape representations learned from a set of images, such as the Neural Radiance Field (NeRF) method, have gained increasing attention due to their high quality imagery and scalability to high resolution. However, the heavy computation required by its volumetric approach prevents NeRF from being useful in practice; minutes are taken to render a single image of a few megapixels. Now, an image of a scene can be rendered in a level-of-detail manner, so we posit that a complicated region of the scene should be represented by a large neural network while a small neural network is capable of encoding a simple region, enabling a balance between efficiency and quality. Recursive-NeRF is our embodiment of this idea, providing an efficient and adaptive rendering and training approach for NeRF. The core of Recursive-NeRF learns uncertainties for query coordinates, representing the quality of the predicted color and volumetric intensity at each level. Only query coordinates with high uncertainties are forwarded to the next level to a bigger neural network with a more powerful representational capability. The final rendered image is a composition of results from neural networks of all levels. Our evaluation on three public datasets shows that Recursive-NeRF is more efficient than NeRF while providing state-of-the-art quality. The code will be available at https://github.com/Gword/Recursive-NeRF.
Occlusion-aware Visual Tracker using Spatial Structural Information and Dominant Features
Apr 16, 2021
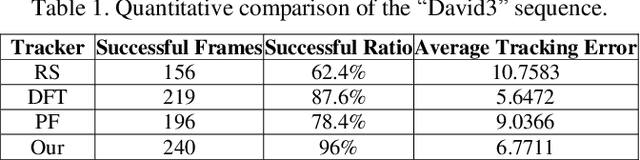

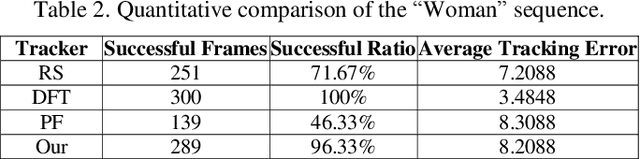
To overcome the problem of occlusion in visual tracking, this paper proposes an occlusion-aware tracking algorithm. The proposed algorithm divides the object into discrete image patches according to the pixel distribution of the object by means of clustering. To avoid the drifting of the tracker to false targets, the proposed algorithm extracts the dominant features, such as color histogram or histogram of oriented gradient orientation, from these image patches, and uses them as cues for tracking. To enhance the robustness of the tracker, the proposed algorithm employs an implicit spatial structure between these patches as another cue for tracking; Afterwards, the proposed algorithm incorporates these components into the particle filter framework, which results in a robust and precise tracker. Experimental results on color image sequences with different resolutions show that the proposed tracker outperforms the comparison algorithms on handling occlusion in visual tracking.
* 8 pages, 5 figures, Journal
Efficient and Effective Context-Based Convolutional Entropy Modeling for Image Compression
Jun 24, 2019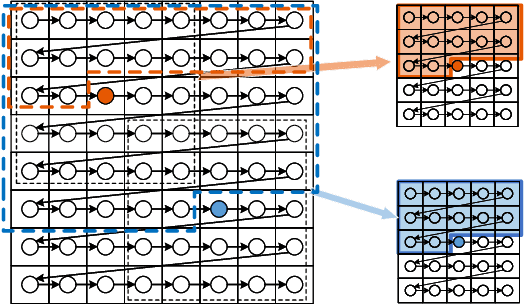
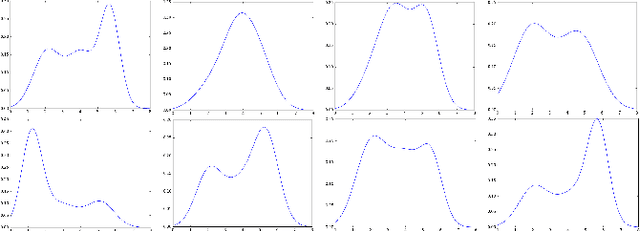
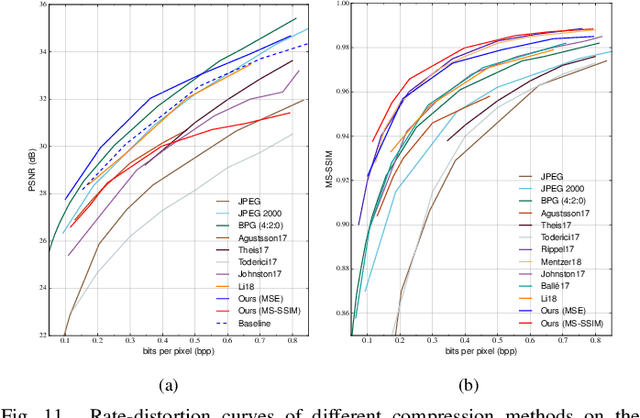
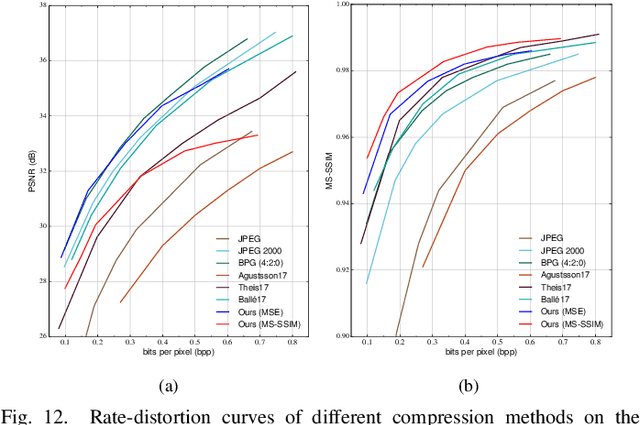
It has long been understood that precisely estimating the probabilistic structure of natural visual images is crucial for image compression. Despite the remarkable success of recent end-to-end optimized image compression, the latent code representation is assumed to be fully statistically factorized such that the entropy modeling is feasible. Here we describe context-based convolutional networks (CCNs) that exploit statistical redundancies in the codes for improved entropy modeling. We introduce a 3D zigzag coding order together with a 3D code dividing technique to define proper context and to achieve parallel entropy decoding, both of which boil down to place translation-invariant binary masks on convolution filters of CCNs. We demonstrate the power of CCNs for entropy modeling in both lossless and lossy image compression. For the former, we directly apply a CCN to binarized image planes for estimating the Bernoulli distribution of each code. For the latter, the categorical distribution of each code is represented by a discretized mixture of Gaussian distributions, whose parameters are estimated by three CCNs. We jointly optimize the CCN-based entropy model with analysis and synthesis transforms for rate-distortion performance. Experiments on two image datasets show that the proposed lossless and lossy image compression methods based on CCNs generally exhibit better compression performance than existing methods with manageable computational complexity.
Task-Independent Knowledge Makes for Transferable Representations for Generalized Zero-Shot Learning
Apr 05, 2021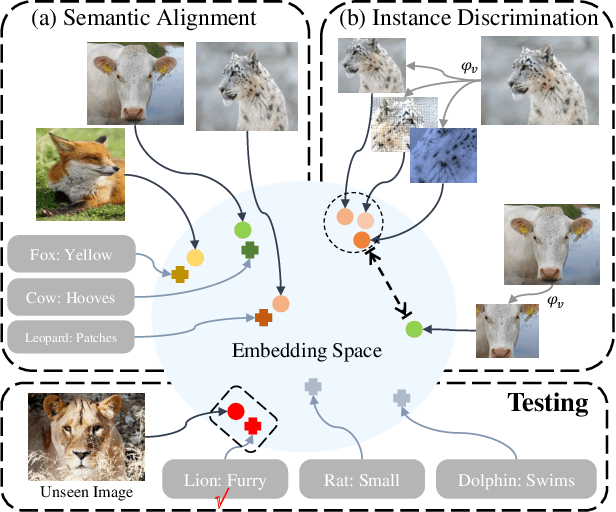
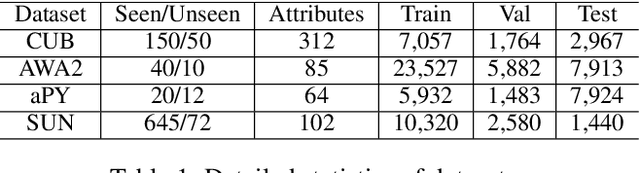
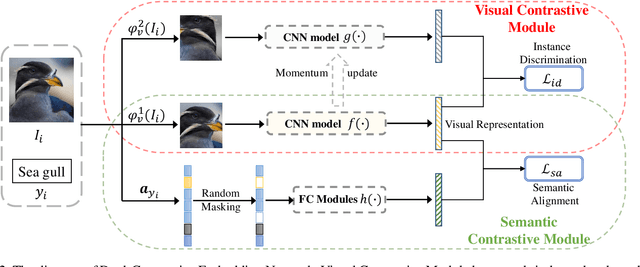
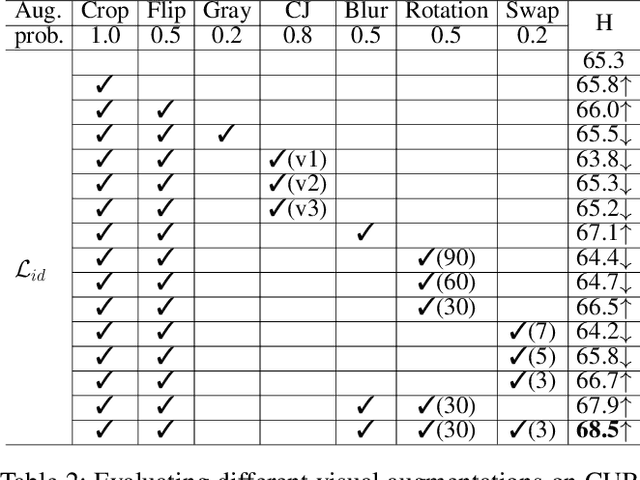
Generalized Zero-Shot Learning (GZSL) targets recognizing new categories by learning transferable image representations. Existing methods find that, by aligning image representations with corresponding semantic labels, the semantic-aligned representations can be transferred to unseen categories. However, supervised by only seen category labels, the learned semantic knowledge is highly task-specific, which makes image representations biased towards seen categories. In this paper, we propose a novel Dual-Contrastive Embedding Network (DCEN) that simultaneously learns task-specific and task-independent knowledge via semantic alignment and instance discrimination. First, DCEN leverages task labels to cluster representations of the same semantic category by cross-modal contrastive learning and exploring semantic-visual complementarity. Besides task-specific knowledge, DCEN then introduces task-independent knowledge by attracting representations of different views of the same image and repelling representations of different images. Compared to high-level seen category supervision, this instance discrimination supervision encourages DCEN to capture low-level visual knowledge, which is less biased toward seen categories and alleviates the representation bias. Consequently, the task-specific and task-independent knowledge jointly make for transferable representations of DCEN, which obtains averaged 4.1% improvement on four public benchmarks.