 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatially-Varying Outdoor Lighting Estimation from Intrinsics
Apr 09, 2021
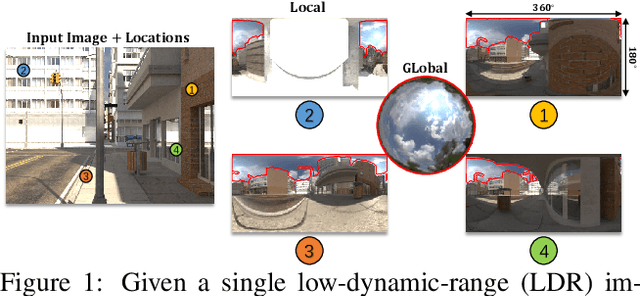
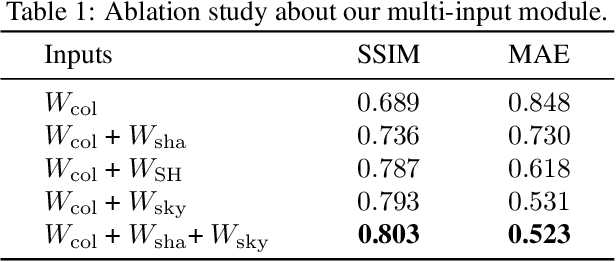
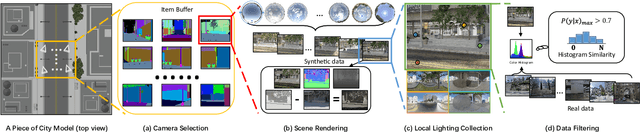
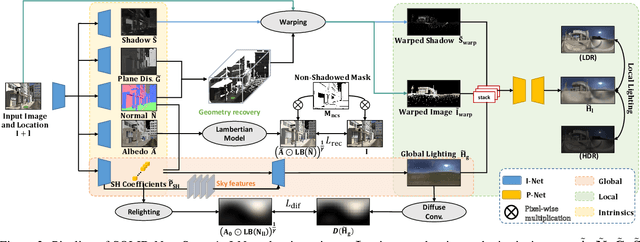
We present SOLID-Net, a neural network for spatially-varying outdoor lighting estimation from a single outdoor image for any 2D pixel location. Previous work has used a unified sky environment map to represent outdoor lighting. Instead, we generate spatially-varying local lighting environment maps by combining global sky environment map with warped image information according to geometric information estimated from intrinsics. As no outdoor dataset with image and local lighting ground truth is readily available, we introduce the SOLID-Img dataset with physically-based rendered images and their corresponding intrinsic and lighting information. We train a deep neural network to regress intrinsic cues with physically-based constraints and use them to conduct global and local lightings estimation. Experiments on both synthetic and real datasets show that SOLID-Net significantly outperforms previous methods.
DC-WCNN: A deep cascade of wavelet based convolutional neural networks for MR Image Reconstruction
Jan 08, 2020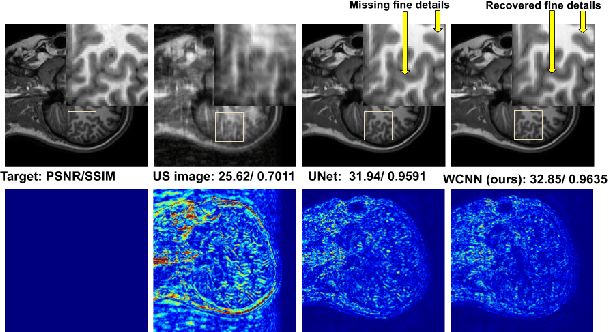
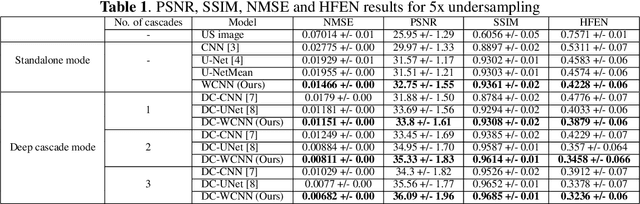
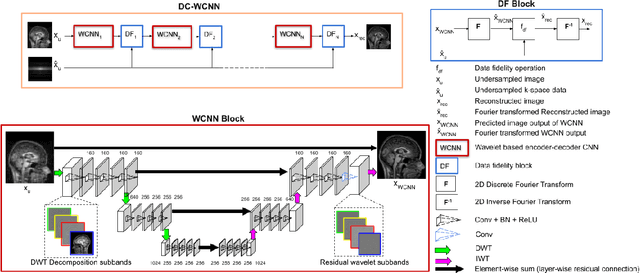
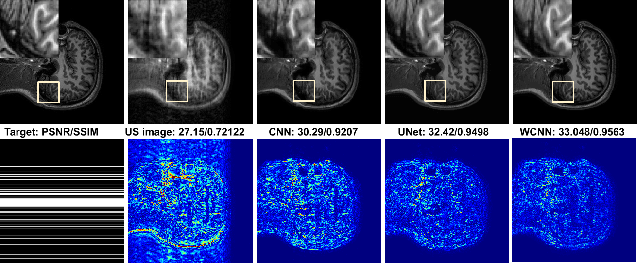
Several variants of Convolutional Neural Networks (CNN) have been developed for Magnetic Resonance (MR) image reconstruction. Among them, U-Net has shown to be the baseline architecture for MR image reconstruction. However, sub-sampling is performed by its pooling layers, causing information loss which in turn leads to blur and missing fine details in the reconstructed image. We propose a modification to the U-Net architecture to recover fine structures. The proposed network is a wavelet packet transform based encoder-decoder CNN with residual learning called CNN. The proposed WCNN has discrete wavelet transform instead of pooling and inverse wavelet transform instead of unpooling layers and residual connections. We also propose a deep cascaded framework (DC-WCNN) which consists of cascades of WCNN and k-space data fidelity units to achieve high quality MR reconstruction. Experimental results show that WCNN and DC-WCNN give promising results in terms of evaluation metrics and better recovery of fine details as compared to other methods.
Learning Fine-Grained Motion Embedding for Landscape Animation
Sep 13, 2021

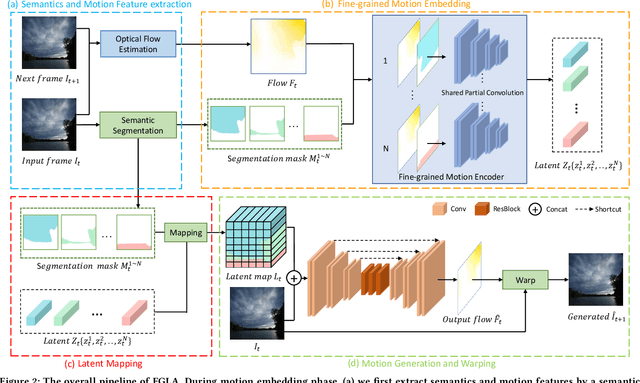
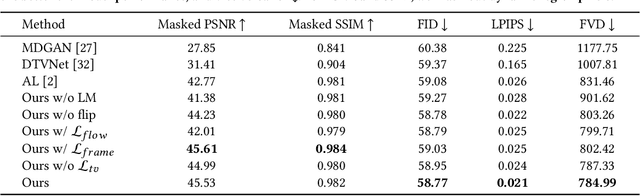
In this paper we focus on landscape animation, which aims to generate time-lapse videos from a single landscape image. Motion is crucial for landscape animation as it determines how objects move in videos. Existing methods are able to generate appealing videos by learning motion from real time-lapse videos. However, current methods suffer from inaccurate motion generation, which leads to unrealistic video results. To tackle this problem, we propose a model named FGLA to generate high-quality and realistic videos by learning Fine-Grained motion embedding for Landscape Animation. Our model consists of two parts: (1) a motion encoder which embeds time-lapse motion in a fine-grained way. (2) a motion generator which generates realistic motion to animate input images. To train and evaluate on diverse time-lapse videos, we build the largest high-resolution Time-lapse video dataset with Diverse scenes, namely Time-lapse-D, which includes 16,874 video clips with over 10 million frames. Quantitative and qualitative experimental results demonstrate the superiority of our method. In particular, our method achieves relative improvements by 19% on LIPIS and 5.6% on FVD compared with state-of-the-art methods on our dataset. A user study carried out with 700 human subjects shows that our approach visually outperforms existing methods by a large margin.
Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization
Apr 12, 2021



Training deep networks with limited labeled data while achieving a strong generalization ability is key in the quest to reduce human annotation efforts. This is the goal of semi-supervised learning, which exploits more widely available unlabeled data to complement small labeled data sets. In this paper, we propose a novel framework for discriminative pixel-level tasks using a generative model of both images and labels. Concretely, we learn a generative adversarial network that captures the joint image-label distribution and is trained efficiently using a large set of unlabeled images supplemented with only few labeled ones. We build our architecture on top of StyleGAN2, augmented with a label synthesis branch. Image labeling at test time is achieved by first embedding the target image into the joint latent space via an encoder network and test-time optimization, and then generating the label from the inferred embedding. We evaluate our approach in two important domains: medical image segmentation and part-based face segmentation. We demonstrate strong in-domain performance compared to several baselines, and are the first to showcase extreme out-of-domain generalization, such as transferring from CT to MRI in medical imaging, and photographs of real faces to paintings, sculptures, and even cartoons and animal faces. Project Page: \url{https://nv-tlabs.github.io/semanticGAN/}
Natural and Realistic Single Image Super-Resolution with Explicit Natural Manifold Discrimination
Nov 09, 2019
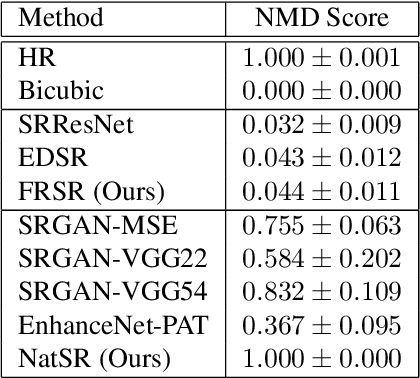
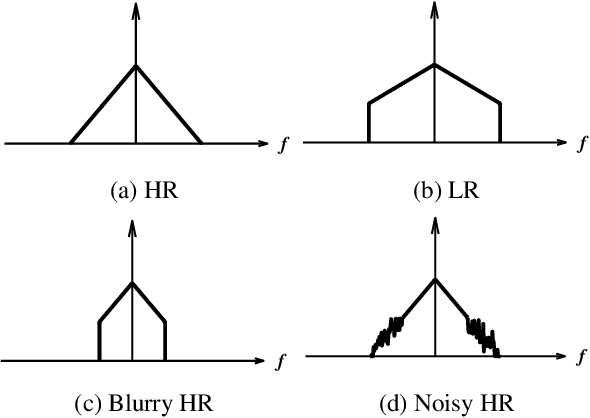
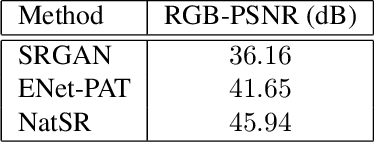
Recently, many convolutional neural networks for single image super-resolution (SISR) have been proposed, which focus on reconstructing the high-resolution images in terms of objective distortion measures. However, the networks trained with objective loss functions generally fail to reconstruct the realistic fine textures and details that are essential for better perceptual quality. Recovering the realistic details remains a challenging problem, and only a few works have been proposed which aim at increasing the perceptual quality by generating enhanced textures. However, the generated fake details often make undesirable artifacts and the overall image looks somewhat unnatural. Therefore, in this paper, we present a new approach to reconstructing realistic super-resolved images with high perceptual quality, while maintaining the naturalness of the result. In particular, we focus on the domain prior properties of SISR problem. Specifically, we define the naturalness prior in the low-level domain and constrain the output image in the natural manifold, which eventually generates more natural and realistic images. Our results show better naturalness compared to the recent super-resolution algorithms including perception-oriented ones.
Online Unsupervised Learning of Visual Representations and Categories
Sep 13, 2021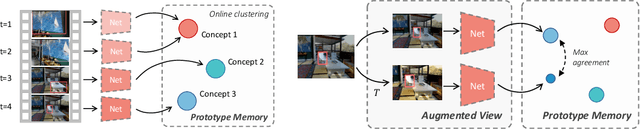
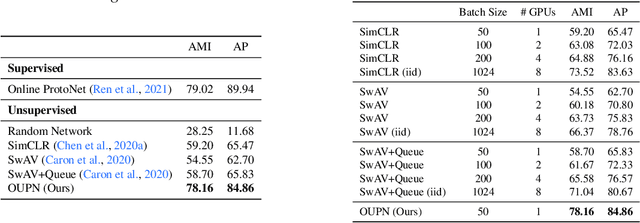


Real world learning scenarios involve a nonstationary distribution of classes with sequential dependencies among the samples, in contrast to the standard machine learning formulation of drawing samples independently from a fixed, typically uniform distribution. Furthermore, real world interactions demand learning on-the-fly from few or no class labels. In this work, we propose an unsupervised model that simultaneously performs online visual representation learning and few-shot learning of new categories without relying on any class labels. Our model is a prototype-based memory network with a control component that determines when to form a new class prototype. We formulate it as an online Gaussian mixture model, where components are created online with only a single new example, and assignments do not have to be balanced, which permits an approximation to natural imbalanced distributions from uncurated raw data. Learning includes a contrastive loss that encourages different views of the same image to be assigned to the same prototype. The result is a mechanism that forms categorical representations of objects in nonstationary environments. Experiments show that our method can learn from an online stream of visual input data and is significantly better at category recognition compared to state-of-the-art self-supervised learning methods.
SkyCam: A Dataset of Sky Images and their Irradiance values
May 06, 2021
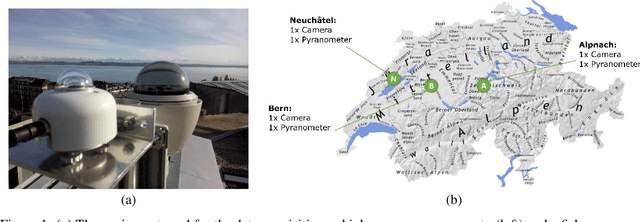
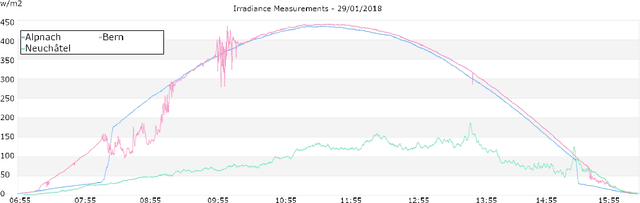

Recent advances in Computer Vision and Deep Learning have enabled astonishing results in a variety of fields and applications. Motivated by this success, the SkyCam Dataset aims to enable image-based Deep Learning solutions for short-term, precise prediction of solar radiation on a local level. For the span of a year, three different cameras in three topographically different locations in Switzerland are acquiring images of the sky every 10 seconds. Thirteen high resolution images with different exposure times are captured and used to create an additional HDR image. The images are paired with highly precise irradiance values gathered from a high-accuracy pyranometer.
Image Deformation Meta-Networks for One-Shot Learning
May 28, 2019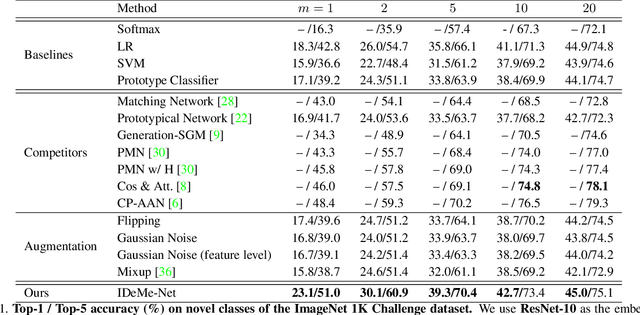
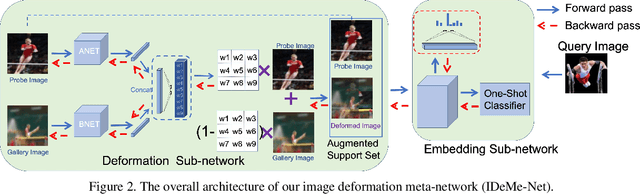
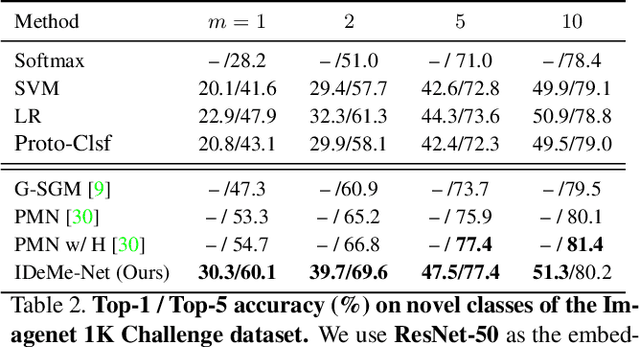
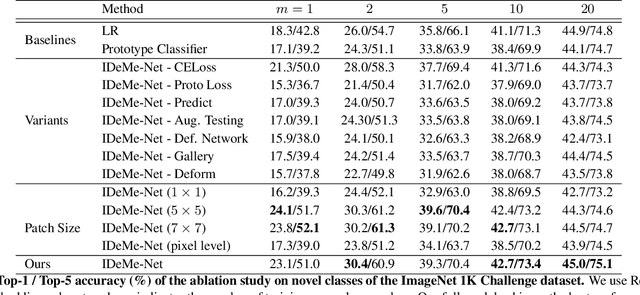
Humans can robustly learn novel visual concepts even when images undergo various deformations and loose certain information. Mimicking the same behavior and synthesizing deformed instances of new concepts may help visual recognition systems perform better one-shot learning, i.e., learning concepts from one or few examples. Our key insight is that, while the deformed images may not be visually realistic, they still maintain critical semantic information and contribute significantly to formulating classifier decision boundaries. Inspired by the recent progress of meta-learning, we combine a meta-learner with an image deformation sub-network that produces additional training examples, and optimize both models in an end-to-end manner. The deformation sub-network learns to deform images by fusing a pair of images -- a probe image that keeps the visual content and a gallery image that diversifies the deformations. We demonstrate results on the widely used one-shot learning benchmarks (miniImageNet and ImageNet 1K Challenge datasets), which significantly outperform state-of-the-art approaches.
Multiview Hessian Regularization for Image Annotation
Apr 23, 2019
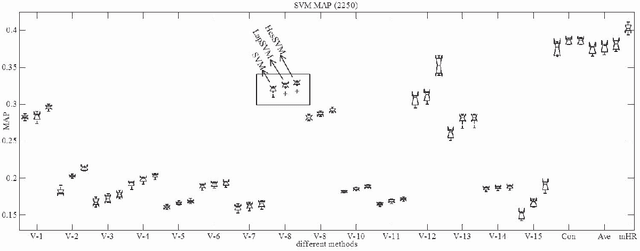
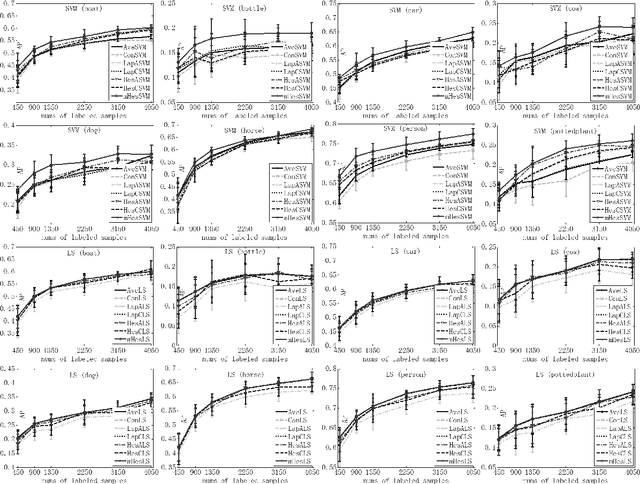
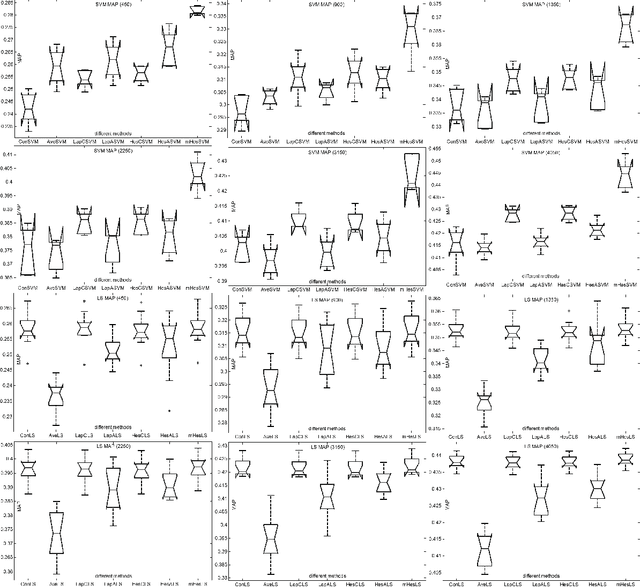
The rapid development of computer hardware and Internet technology makes large scale data dependent models computationally tractable, and opens a bright avenue for annotating images through innovative machine learning algorithms. Semi-supervised learning (SSL) has consequently received intensive attention in recent years and has been successfully deployed in image annotation. One representative work in SSL is Laplacian regularization (LR), which smoothes the conditional distribution for classification along the manifold encoded in the graph Laplacian, however, it has been observed that LR biases the classification function towards a constant function which possibly results in poor generalization. In addition, LR is developed to handle uniformly distributed data (or single view data), although instances or objects, such as images and videos, are usually represented by multiview features, such as color, shape and texture. In this paper, we present multiview Hessian regularization (mHR) to address the above two problems in LR-based image annotation. In particular, mHR optimally combines multiple Hessian regularizations, each of which is obtained from a particular view of instances, and steers the classification function which varies linearly along the data manifold. We apply mHR to kernel least squares and support vector machines as two examples for image annotation. Extensive experiments on the PASCAL VOC'07 dataset validate the effectiveness of mHR by comparing it with baseline algorithms, including LR and HR.
Predicting Depth from Semantic Segmentation using Game Engine Dataset
Jun 12, 2021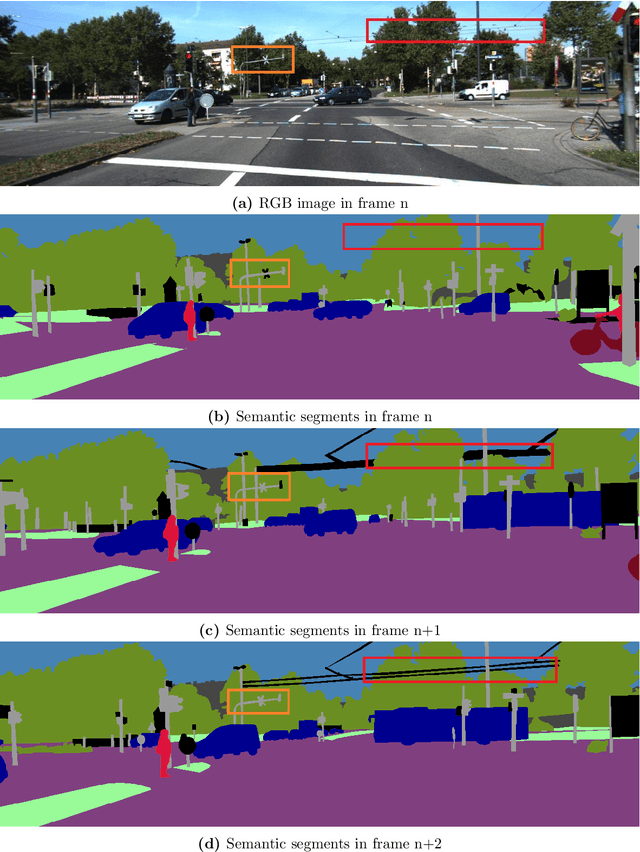
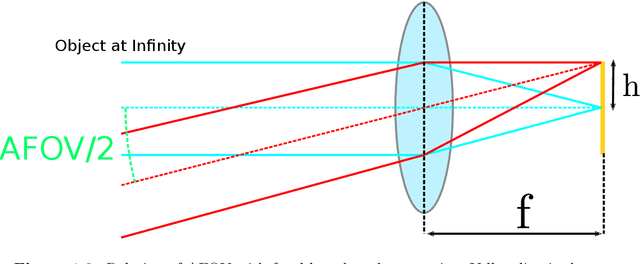
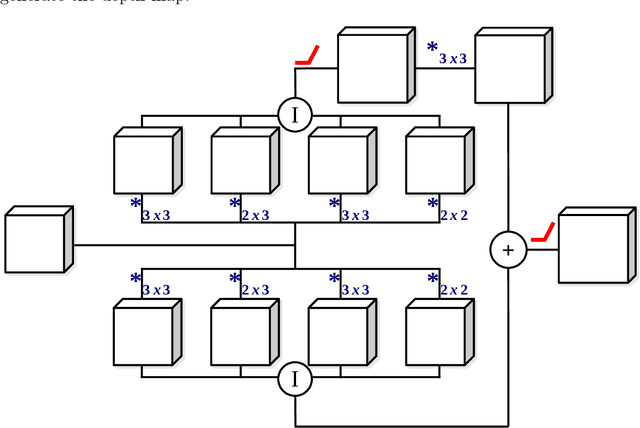
Depth perception is fundamental for robots to understand the surrounding environment. As the view of cognitive neuroscience, visual depth perception methods are divided into three categories, namely binocular, active, and pictorial. The first two categories have been studied for decades in detail. However, research for the exploration of the third category is still in its infancy and has got momentum by the advent of deep learning methods in recent years. In cognitive neuroscience, it is known that pictorial depth perception mechanisms are dependent on the perception of seen objects. Inspired by this fact, in this thesis, we investigated the relation of perception of objects and depth estimation convolutional neural networks. For this purpose, we developed new network structures based on a simple depth estimation network that only used a single image at its input. Our proposed structures use both an image and a semantic label of the image as their input. We used semantic labels as the output of object perception. The obtained results of performance comparison between the developed network and original network showed that our novel structures can improve the performance of depth estimation by 52\% of relative error of distance in the examined cases. Most of the experimental studies were carried out on synthetic datasets that were generated by game engines to isolate the performance comparison from the effect of inaccurate depth and semantic labels of non-synthetic datasets. It is shown that particular synthetic datasets may be used for training of depth networks in cases that an appropriate dataset is not available. Furthermore, we showed that in these cases, usage of semantic labels improves the robustness of the network against domain shift from synthetic training data to non-synthetic test data.