 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FrequentNet : A New Deep Learning Baseline for Image Classification
Jan 04, 2020


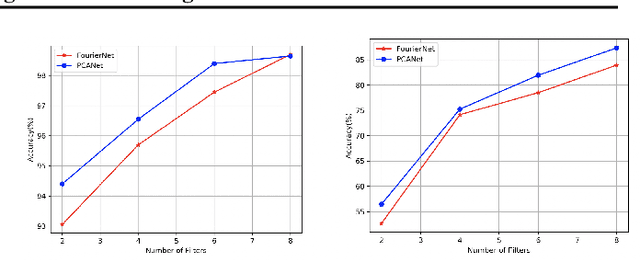
In this paper, we generalize the idea from the method called "PCANet" to achieve a new baseline deep learning model for image classification. Instead of using principal component vectors as the filter vector in "PCANet", we use basis vectors in discrete Fourier analysis and wavelets analysis as our filter vectors. Both of them achieve comparable performance to "PCANet" in benchmark datasets. It is noticeable that our algorithms do not require any optimization techniques to get those basis.
To The Point: Correspondence-driven monocular 3D category reconstruction
Jun 10, 2021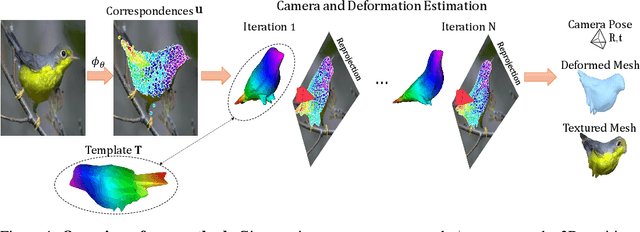
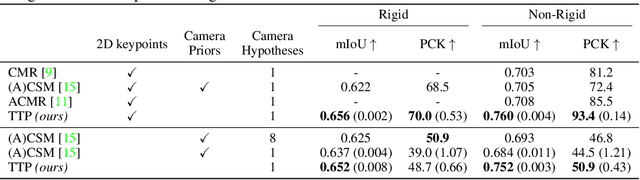
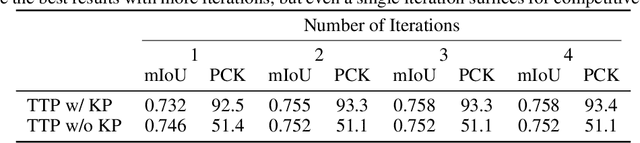
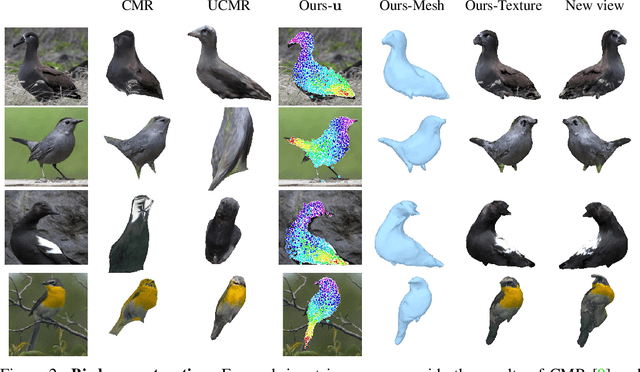
We present To The Point (TTP), a method for reconstructing 3D objects from a single image using 2D to 3D correspondences learned from weak supervision. We recover a 3D shape from a 2D image by first regressing the 2D positions corresponding to the 3D template vertices and then jointly estimating a rigid camera transform and non-rigid template deformation that optimally explain the 2D positions through the 3D shape projection. By relying on 3D-2D correspondences we use a simple per-sample optimization problem to replace CNN-based regression of camera pose and non-rigid deformation and thereby obtain substantially more accurate 3D reconstructions. We treat this optimization as a differentiable layer and train the whole system in an end-to-end manner. We report systematic quantitative improvements on multiple categories and provide qualitative results comprising diverse shape, pose and texture prediction examples. Project website: https://fkokkinos.github.io/to_the_point/.
Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
Feb 02, 2021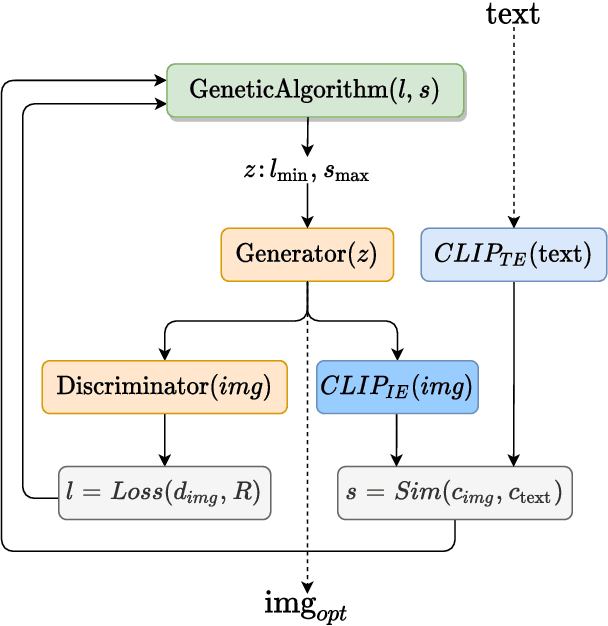
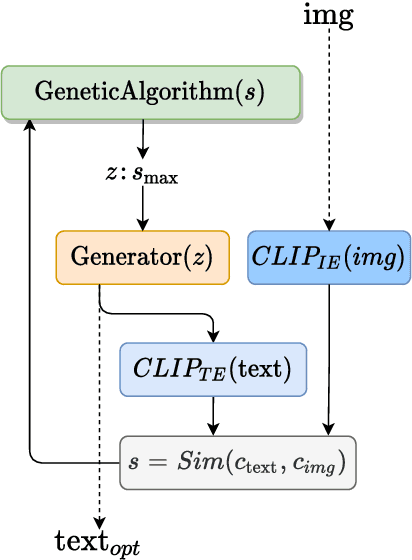


In this research work we present GLaSS, a novel zero-shot framework to generate an image(or a caption) corresponding to a given caption(or image). GLaSS is based on the CLIP neural network which given an image and a descriptive caption provides similar embeddings. Differently, GLaSS takes a caption (or an image) as an input, and generates the image (or the caption) whose CLIP embedding is most similar to the input one. This optimal image (or caption) is produced via a generative network after an exploration by a genetic algorithm. Promising results are shown, based on the experimentation of the image generators BigGAN and StyleGAN2, and of the text generator GPT2.
Deformable Medical Image Registration Using a Randomly-Initialized CNN as Regularization Prior
Aug 02, 2019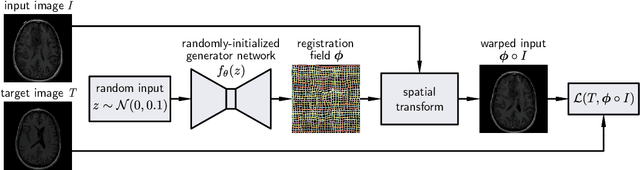
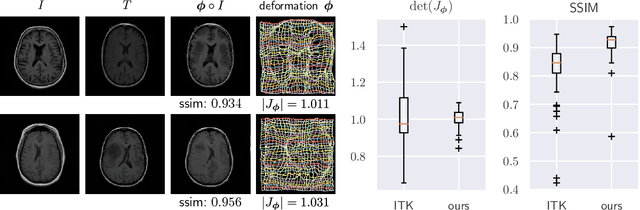
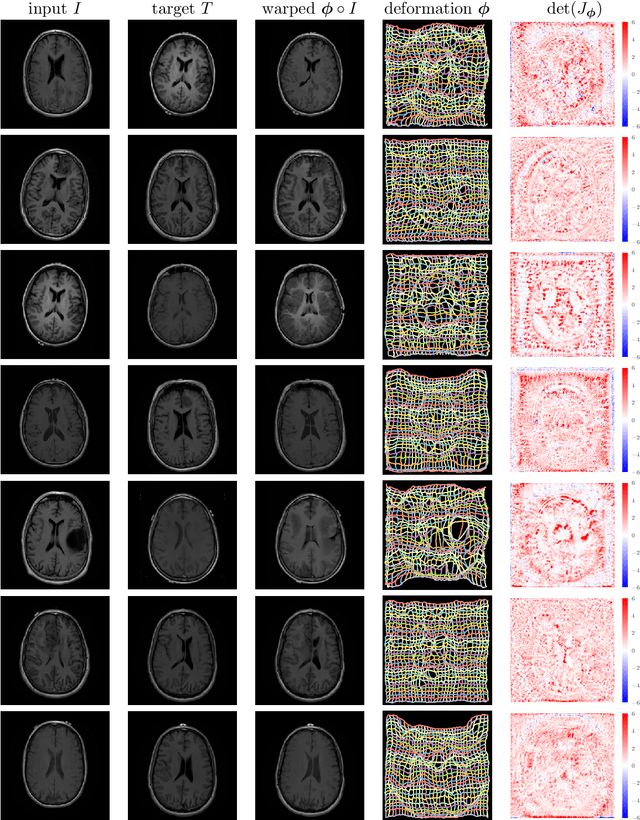
We present deformable unsupervised medical image registration using a randomly-initialized deep convolutional neural network (CNN) as regularization prior. Conventional registration methods predict a transformation by minimizing dissimilarities between an image pair. The minimization is usually regularized with manually engineered priors, which limits the potential of the registration. By learning transformation priors from a large dataset, CNNs have achieved great success in deformable registration. However, learned methods are restricted to domain-specific data and the required amounts of medical data are difficult to obtain. Our approach uses the idea of deep image priors to combine convolutional networks with conventional registration methods based on manually engineered priors. The proposed method is applied to brain MRI scans. We show that our approach registers image pairs with state-of-the-art accuracy by providing dense, pixel-wise correspondence maps. It does not rely on prior training and is therefore not limited to a specific image domain.
Automated quantitative analysis of first-pass myocardial perfusion magnetic resonance imaging data
May 10, 2021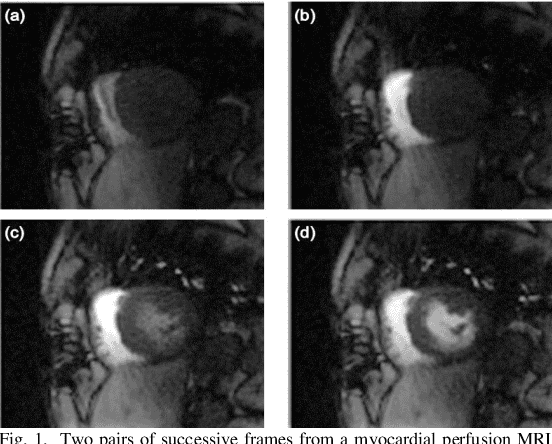
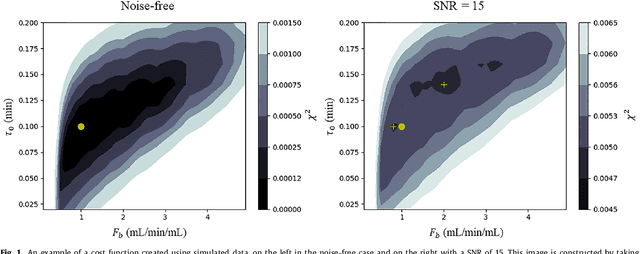

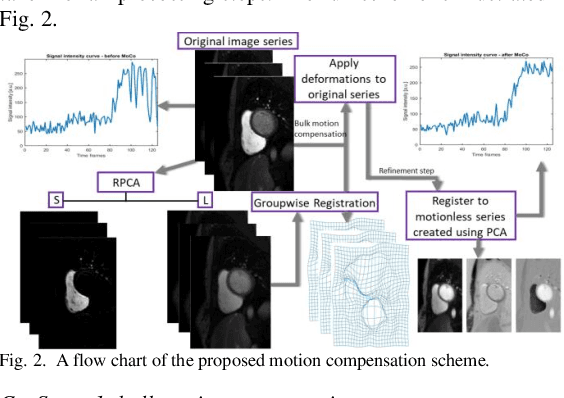
Coronary artery disease (CAD) remains the world's leading cause of mortality and the disease burden is continually expanding as the population ages. Recently, the MR-INFORM randomised trial has demonstrated that the management of patients with stable CAD can be guided by stress perfusion cardiovascular magnetic resonance (CMR) imaging and it is non-inferior to the using the invasive reference standard of fractional flow reserve. The benefits of using stress perfusion CMR include that it is non-invasive and significantly reduces the number of unnecessary coronary revascularisations. As compared to other ischaemia tests, it boasts a high spatial resolution and does not expose the patient to ionising radiation. However, the main limitation of stress perfusion CMR is that the diagnostic accuracy is highly dependent on the level of training of the operator, resulting in the test only being performed routinely in experienced tertiary centres. The clinical translation of stress perfusion CMR would be greatly aided by a fully automated, user-independent, quantitative evaluation of myocardial blood flow. This thesis presents major steps towards this goal: robust motion correction, automated image processing, reliable quantitative modelling, and thorough validation. The motion correction scheme makes use of data decomposition techniques, such as robust principal component analysis, to mitigate the difficulties in image registration caused by the dynamic contrast enhancement. The motion corrected image series are input to a processing pipeline which leverages the recent advances in image processing facilitated by deep learning. The pipeline utilises convolutional neural networks to perform a series of computer vision tasks including myocardial segmentation and right ventricular insertion point detection...
Path-Restore: Learning Network Path Selection for Image Restoration
Apr 23, 2019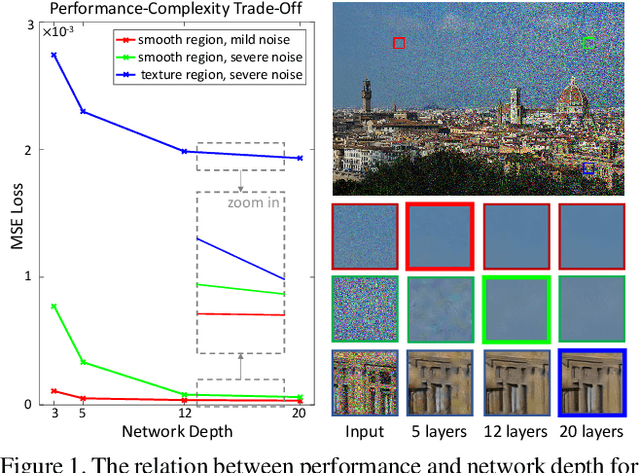
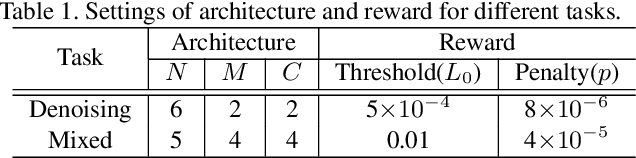
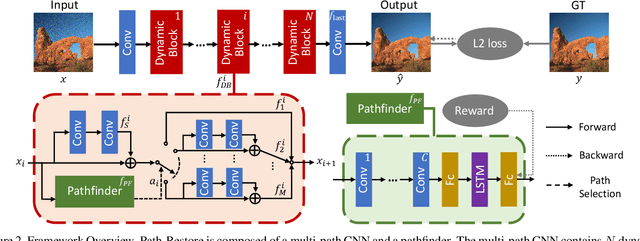
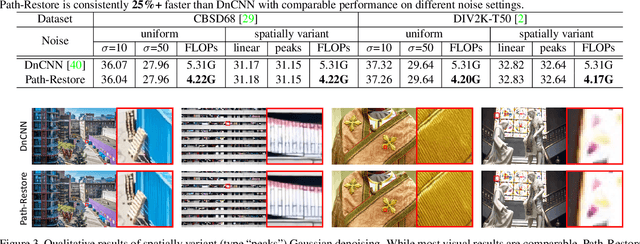
Very deep Convolutional Neural Networks (CNNs) have greatly improved the performance on various image restoration tasks. However, this comes at a price of increasing computational burden, which limits their practical usages. We believe that some corrupted image regions are inherently easier to restore than others since the distortion and content vary within an image. To this end, we propose Path-Restore, a multi-path CNN with a pathfinder that could dynamically select an appropriate route for each image region. We train the pathfinder using reinforcement learning with a difficulty-regulated reward, which is related to the performance, complexity and "the difficulty of restoring a region". We conduct experiments on denoising and mixed restoration tasks. The results show that our method could achieve comparable or superior performance to existing approaches with less computational cost. In particular, our method is effective for real-world denoising, where the noise distribution varies across different regions of a single image. We surpass the state-of-the-art CBDNet by 0.94 dB and run 29% faster on the realistic Darmstadt Noise Dataset. Models and codes will be released.
Less is More: Unified Model for Unsupervised Multi-Domain Image-to-Image Translation
May 28, 2018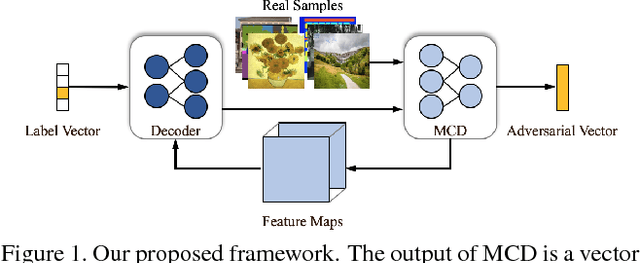
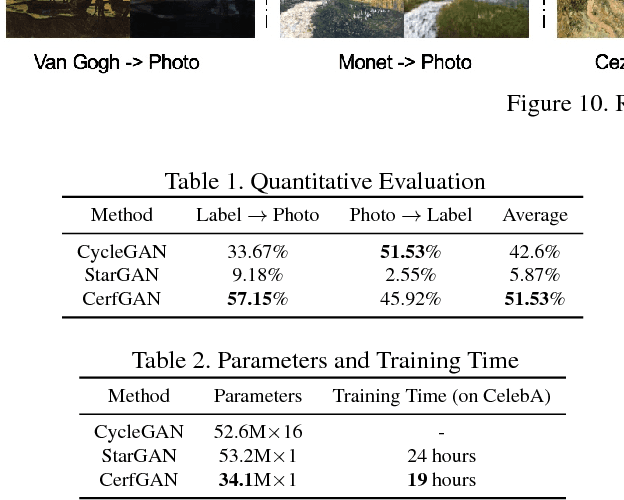
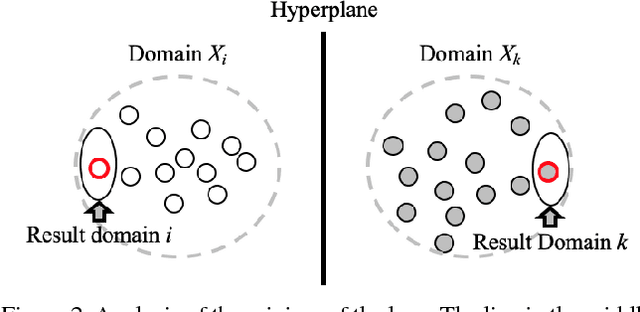
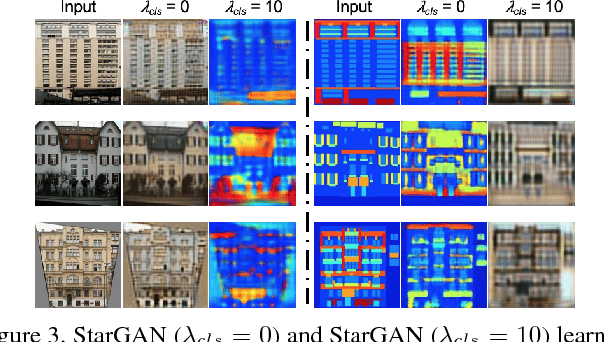
In this paper, we aim at solving the multi-domain image-to-image translation problem by a single GAN-based model in an unsupervised manner. In the field of image-to-image translation, most previous works mainly focus on adopting a generative adversarial network, which contains three parts, i.e., encoder, decoder and discriminator. These three parts are trained to give the encoder and the decoder together as a translator. However, the discriminator that occupies a lot of parameters is abandoned after the training process, which is wasteful of computation and memory. To handle this problem, we integrate the discriminator and the encoder of the traditional framework into a single network, where the decoder in our framework translates the information encoded by the discriminator to the target image. As a result, our framework only contains two parts, i.e., decoder and discriminator, which effectively reduces the number of the parameters of the network and achieves more effective training. Then, we expand the traditional binary-class discriminator to the multi-classes discriminator, which solves the multi-domain image-to-image translation problem in traditional settings. At last, we propose the label encoder to transform the label vector to high-dimension representation automatically rather than designing a one-hot vector manually. We performed extensive experiments on many image-to-image translation tasks including style transfer, season transfer, face hallucination, etc. A unified model was trained to translate images sampled from 14 considerable different domains and the comparisons to several recently-proposed approaches demonstrate the superiority and novelty of our framework.
Deep Optimized Multiple Description Image Coding via Scalar Quantization Learning
Jan 12, 2020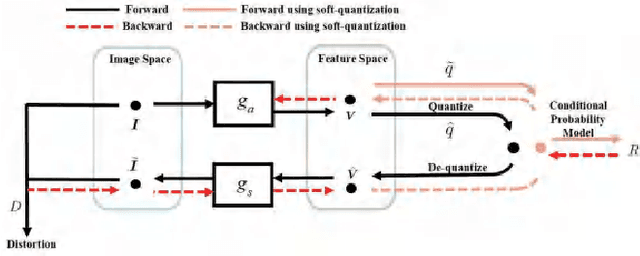

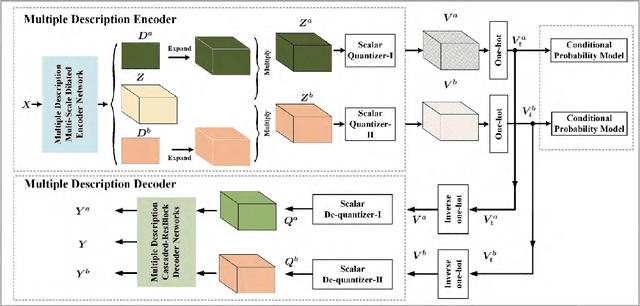
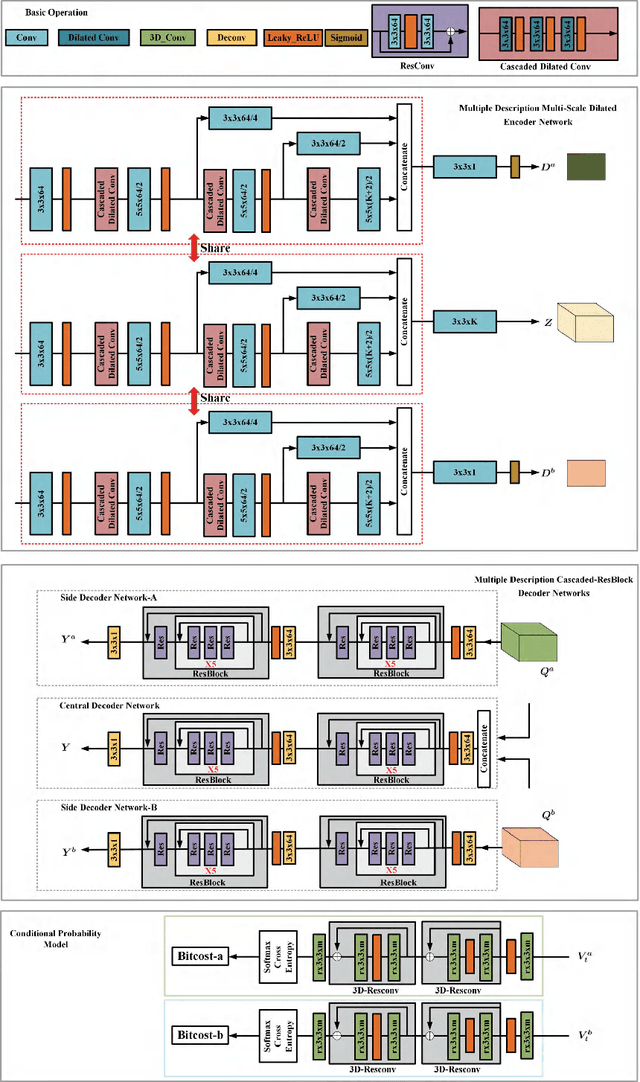
In this paper, we introduce a deep multiple description coding (MDC) framework optimized by minimizing multiple description (MD) compressive loss. First, MD multi-scale-dilated encoder network generates multiple description tensors, which are discretized by scalar quantizers, while these quantized tensors are decompressed by MD cascaded-ResBlock decoder networks. To greatly reduce the total amount of artificial neural network parameters, an auto-encoder network composed of these two types of network is designed as a symmetrical parameter sharing structure. Second, this autoencoder network and a pair of scalar quantizers are simultaneously learned in an end-to-end self-supervised way. Third, considering the variation in the image spatial distribution, each scalar quantizer is accompanied by an importance-indicator map to generate MD tensors, rather than using direct quantization. Fourth, we introduce the multiple description structural similarity distance loss, which implicitly regularizes the diversified multiple description generations, to explicitly supervise multiple description diversified decoding in addition to MD reconstruction loss. Finally, we demonstrate that our MDC framework performs better than several state-of-the-art MDC approaches regarding image coding efficiency when tested on several commonly available datasets.
Robust Mitosis Detection Using a Cascade Mask-RCNN Approach With Domain-Specific Residual Cycle-GAN Data Augmentation
Sep 28, 2021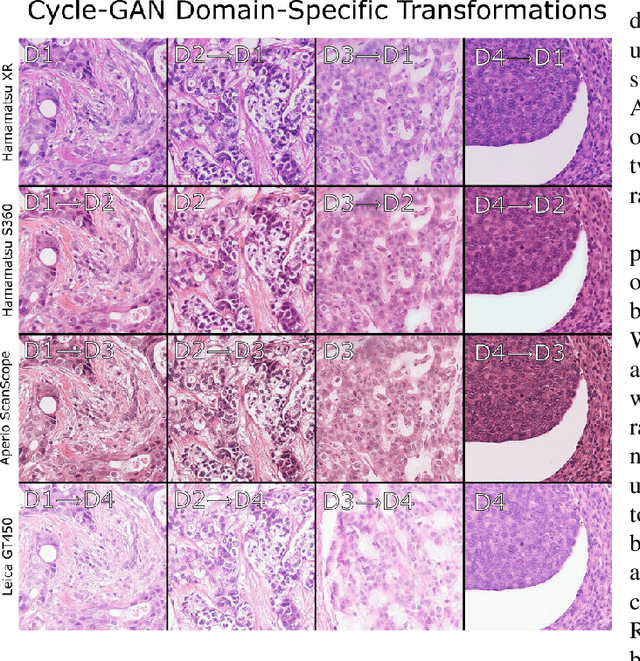
For the MIDOG mitosis detection challenge, we created a cascade algorithm consisting of a Mask-RCNN detector, followed by a classification ensemble consisting of ResNet50 and DenseNet201 to refine detected mitotic candidates. The MIDOG training data consists of 200 frames originating from four scanners, three of which are annotated for mitotic instances with centroid annotations. Our main algorithmic choices are as follows: first, to enhance the generalizability of our detector and classification networks, we use a state-of-the-art residual Cycle-GAN to transform each scanner domain to every other scanner domain. During training, we then randomly load, for each image, one of the four domains. In this way, our networks can learn from the fourth non-annotated scanner domain even if we don't have annotations for it. Second, for training the detector network, rather than using centroid-based fixed-size bounding boxes, we create mitosis-specific bounding boxes. We do this by manually annotating a small selection of mitoses, training a Mask-RCNN on this small dataset, and applying it to the rest of the data to obtain full annotations. We trained the follow-up classification ensemble using only the challenge-provided positive and hard-negative examples. On the preliminary test set, the algorithm scores an F1 score of 0.7578, putting us as the second-place team on the leaderboard.
You Better Look Twice: a new perspective for designing accurate detectors with reduced computations
Jul 21, 2021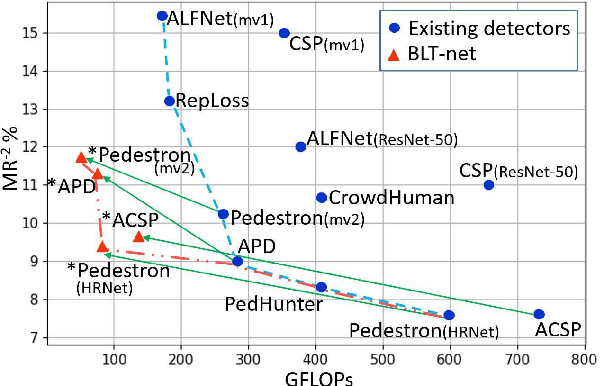
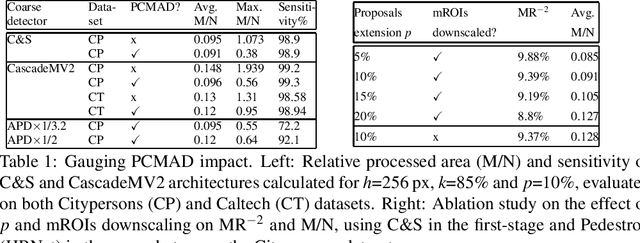
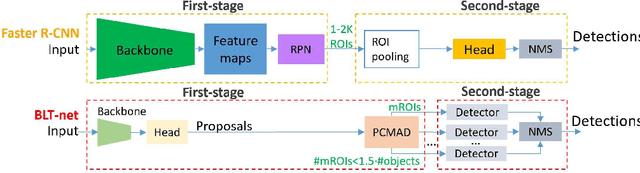
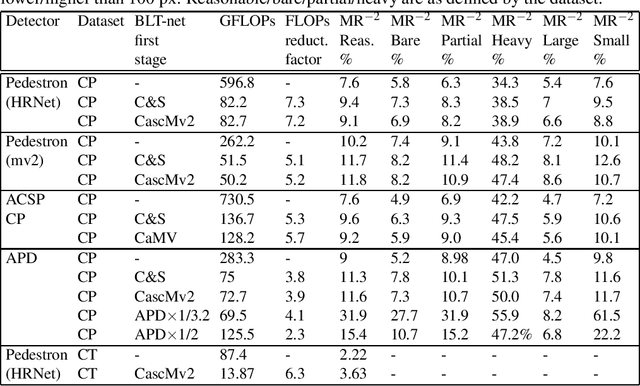
General object detectors use powerful backbones that uniformly extract features from images for enabling detection of a vast amount of object types. However, utilization of such backbones in object detection applications developed for specific object types can unnecessarily over-process an extensive amount of background. In addition, they are agnostic to object scales, thus redundantly process all image regions at the same resolution. In this work we introduce BLT-net, a new low-computation two-stage object detection architecture designed to process images with a significant amount of background and objects of variate scales. BLT-net reduces computations by separating objects from background using a very lite first-stage. BLT-net then efficiently merges obtained proposals to further decrease processed background and then dynamically reduces their resolution to minimize computations. Resulting image proposals are then processed in the second-stage by a highly accurate model. We demonstrate our architecture on the pedestrian detection problem, where objects are of different sizes, images are of high resolution and object detection is required to run in real-time. We show that our design reduces computations by a factor of x4-x7 on the Citypersons and Caltech datasets with respect to leading pedestrian detectors, on account of a small accuracy degradation. This method can be applied on other object detection applications in scenes with a considerable amount of background and variate object sizes to reduce computations.