 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AdaPruner: Adaptive Channel Pruning and Effective Weights Inheritance
Sep 14, 2021
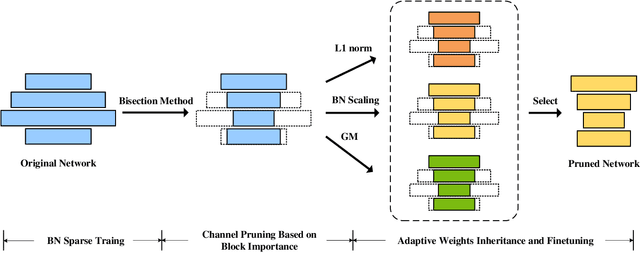
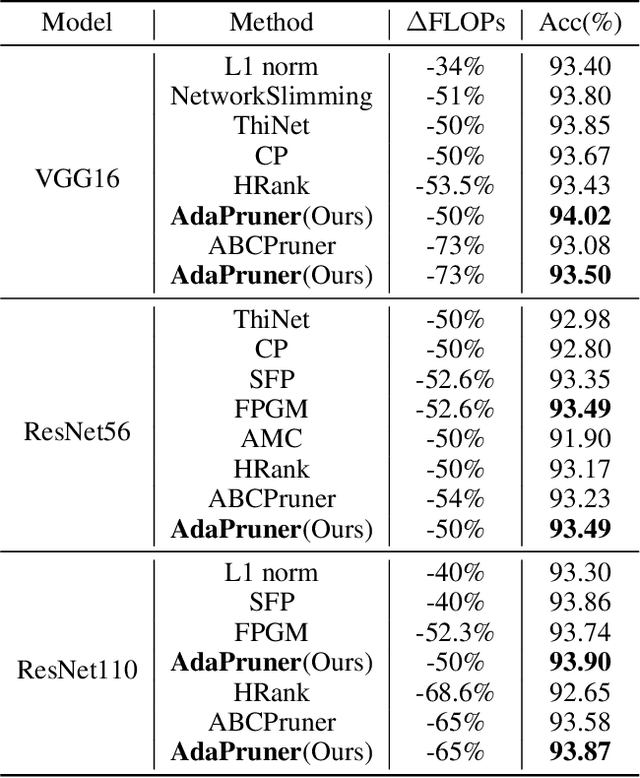
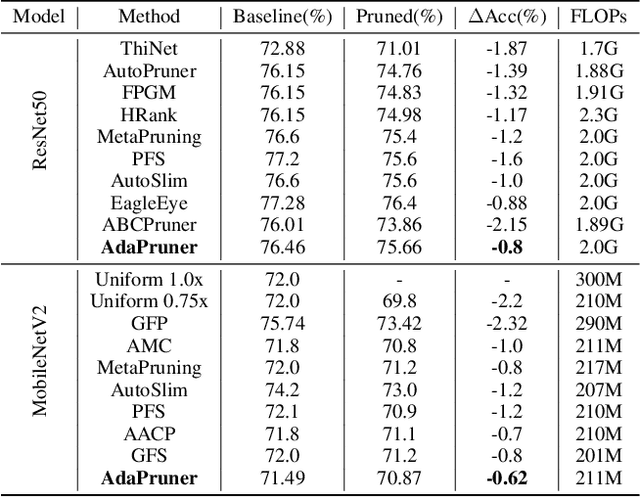
Channel pruning is one of the major compression approaches for deep neural networks. While previous pruning methods have mostly focused on identifying unimportant channels, channel pruning is considered as a special case of neural architecture search in recent years. However, existing methods are either complicated or prone to sub-optimal pruning. In this paper, we propose a pruning framework that adaptively determines the number of each layer's channels as well as the wights inheritance criteria for sub-network. Firstly, evaluate the importance of each block in the network based on the mean of the scaling parameters of the BN layers. Secondly, use the bisection method to quickly find the compact sub-network satisfying the budget. Finally, adaptively and efficiently choose the weight inheritance criterion that fits the current architecture and fine-tune the pruned network to recover performance. AdaPruner allows to obtain pruned network quickly, accurately and efficiently, taking into account both the structure and initialization weights. We prune the currently popular CNN models (VGG, ResNet, MobileNetV2) on different image classification datasets, and the experimental results demonstrate the effectiveness of our proposed method. On ImageNet, we reduce 32.8% FLOPs of MobileNetV2 with only 0.62% decrease for top-1 accuracy, which exceeds all previous state-of-the-art channel pruning methods. The code will be released.
Single Image Depth Estimation Trained via Depth from Defocus Cues
Jan 14, 2020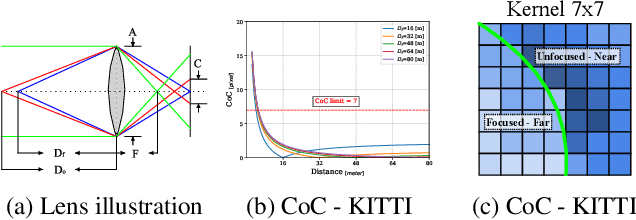


Estimating depth from a single RGB images is a fundamental task in computer vision, which is most directly solved using supervised deep learning. In the field of unsupervised learning of depth from a single RGB image, depth is not given explicitly. Existing work in the field receives either a stereo pair, a monocular video, or multiple views, and, using losses that are based on structure-from-motion, trains a depth estimation network. In this work, we rely, instead of different views, on depth from focus cues. Learning is based on a novel Point Spread Function convolutional layer, which applies location specific kernels that arise from the Circle-Of-Confusion in each image location. We evaluate our method on data derived from five common datasets for depth estimation and lightfield images, and present results that are on par with supervised methods on KITTI and Make3D datasets and outperform unsupervised learning approaches. Since the phenomenon of depth from defocus is not dataset specific, we hypothesize that learning based on it would overfit less to the specific content in each dataset. Our experiments show that this is indeed the case, and an estimator learned on one dataset using our method provides better results on other datasets, than the directly supervised methods.
Heterogeneous Grid Convolution for Adaptive, Efficient, and Controllable Computation
Apr 22, 2021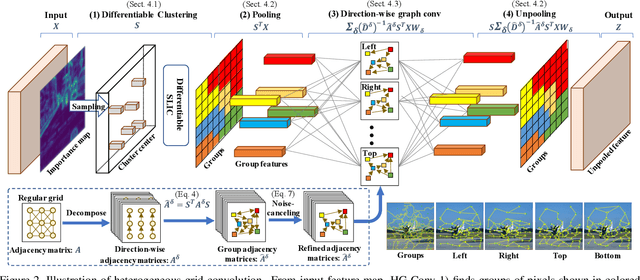
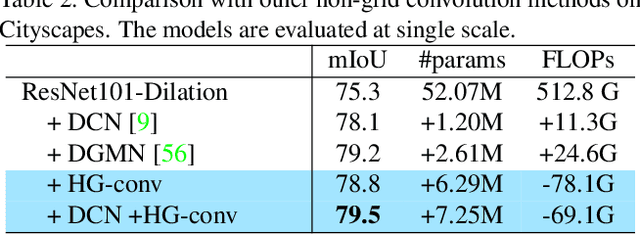

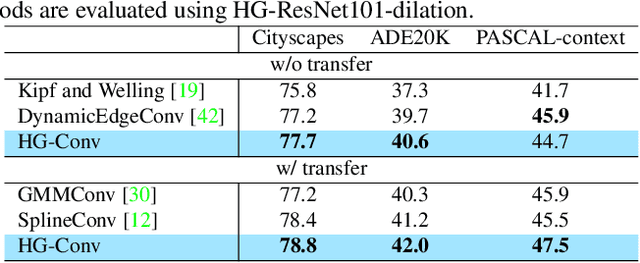
This paper proposes a novel heterogeneous grid convolution that builds a graph-based image representation by exploiting heterogeneity in the image content, enabling adaptive, efficient, and controllable computations in a convolutional architecture. More concretely, the approach builds a data-adaptive graph structure from a convolutional layer by a differentiable clustering method, pools features to the graph, performs a novel direction-aware graph convolution, and unpool features back to the convolutional layer. By using the developed module, the paper proposes heterogeneous grid convolutional networks, highly efficient yet strong extension of existing architectures. We have evaluated the proposed approach on four image understanding tasks, semantic segmentation, object localization, road extraction, and salient object detection. The proposed method is effective on three of the four tasks. Especially, the method outperforms a strong baseline with more than 90% reduction in floating-point operations for semantic segmentation, and achieves the state-of-the-art result for road extraction. We will share our code, model, and data.
MSE Loss with Outlying Label for Imbalanced Classification
Jul 06, 2021

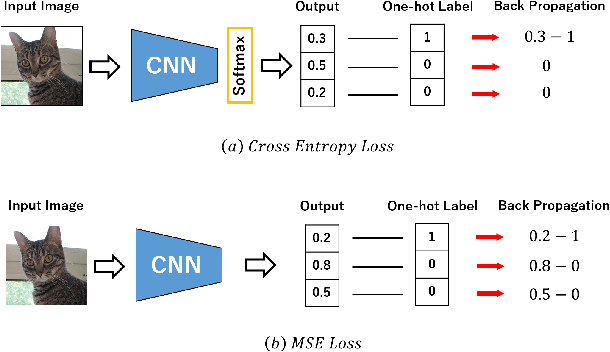

In this paper, we propose mean squared error (MSE) loss with outlying label for class imbalanced classification. Cross entropy (CE) loss, which is widely used for image recognition, is learned so that the probability value of true class is closer to one by back propagation. However, for imbalanced datasets, the learning is insufficient for the classes with a small number of samples. Therefore, we propose a novel classification method using the MSE loss that can be learned the relationships of all classes no matter which image is input. Unlike CE loss, MSE loss is possible to equalize the number of back propagation for all classes and to learn the feature space considering the relationships between classes as metric learning. Furthermore, instead of the usual one-hot teacher label, we use a novel teacher label that takes the number of class samples into account. This induces the outlying label which depends on the number of samples in each class, and the class with a small number of samples has outlying margin in a feature space. It is possible to create the feature space for separating high-difficulty classes and low-difficulty classes. By the experiments on imbalanced classification and semantic segmentation, we confirmed that the proposed method was much improved in comparison with standard CE loss and conventional methods, even though only the loss and teacher labels were changed.
Similar Image Search for Histopathology: SMILY
Feb 06, 2019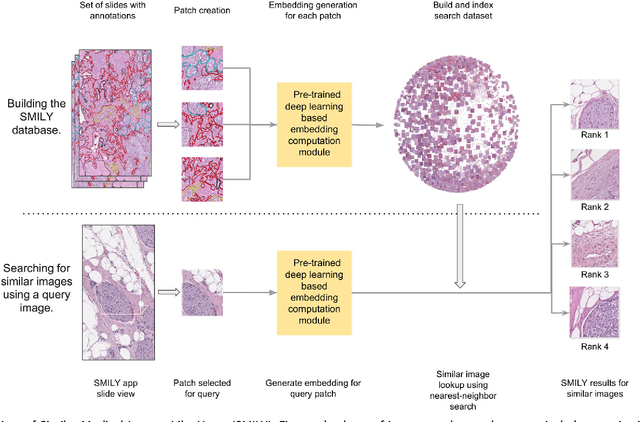
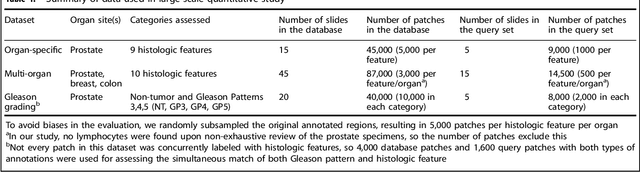
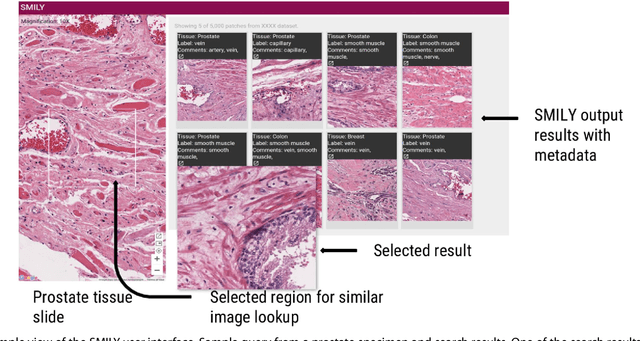
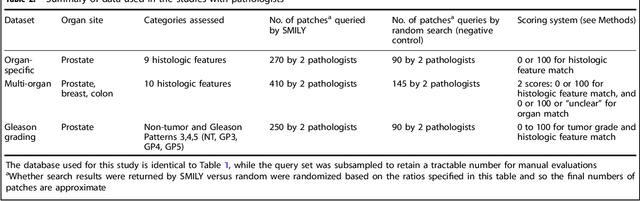
The increasing availability of large institutional and public histopathology image datasets is enabling the searching of these datasets for diagnosis, research, and education. Though these datasets typically have associated metadata such as diagnosis or clinical notes, even carefully curated datasets rarely contain annotations of the location of regions of interest on each image. Because pathology images are extremely large (up to 100,000 pixels in each dimension), further laborious visual search of each image may be needed to find the feature of interest. In this paper, we introduce a deep learning based reverse image search tool for histopathology images: Similar Medical Images Like Yours (SMILY). We assessed SMILY's ability to retrieve search results in two ways: using pathologist-provided annotations, and via prospective studies where pathologists evaluated the quality of SMILY search results. As a negative control in the second evaluation, pathologists were blinded to whether search results were retrieved by SMILY or randomly. In both types of assessments, SMILY was able to retrieve search results with similar histologic features, organ site, and prostate cancer Gleason grade compared with the original query. SMILY may be a useful general-purpose tool in the pathologist's arsenal, to improve the efficiency of searching large archives of histopathology images, without the need to develop and implement specific tools for each application.
High Resolution Medical Image Analysis with Spatial Partitioning
Sep 12, 2019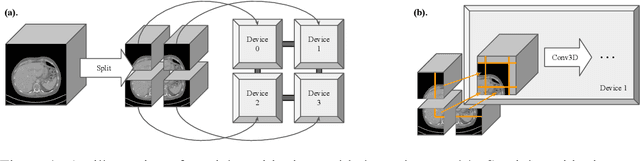
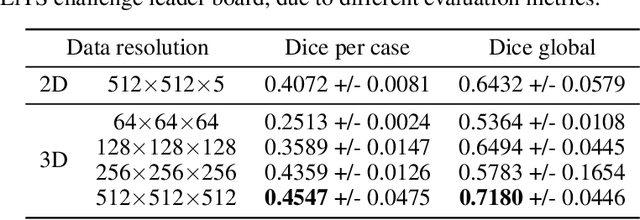

Medical images such as 3D computerized tomography (CT) scans and pathology images, have hundreds of millions or billions of voxels/pixels. It is infeasible to train CNN models directly on such high resolution images, because neural activations of a single image do not fit in the memory of a single GPU/TPU, and naive data and model parallelism approaches do not work. Existing image analysis approaches alleviate this problem by cropping or down-sampling input images, which leads to complicated implementation and sub-optimal performance due to information loss. In this paper, we implement spatial partitioning, which internally distributes the input and output of convolutional layers across GPUs/TPUs. Our implementation is based on the Mesh-TensorFlow framework and the computation distribution is transparent to end users. With this technique, we train a 3D Unet on up to 512 by 512 by 512 resolution data. To the best of our knowledge, this is the first work for handling such high resolution images end-to-end.
Communication-Efficient Distributed Linear and Deep Generalized Canonical Correlation Analysis
Sep 25, 2021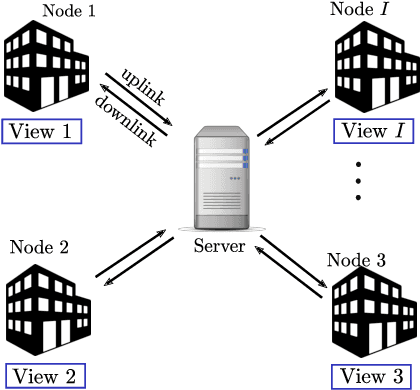
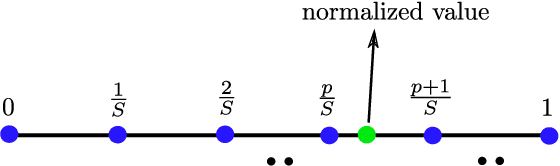
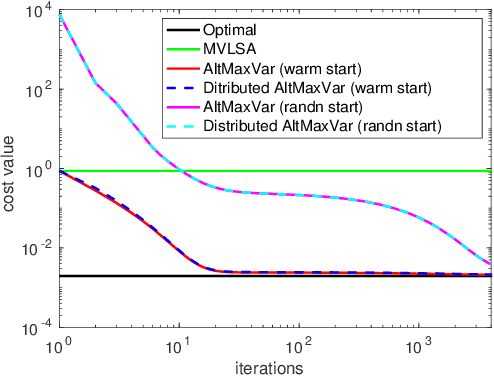
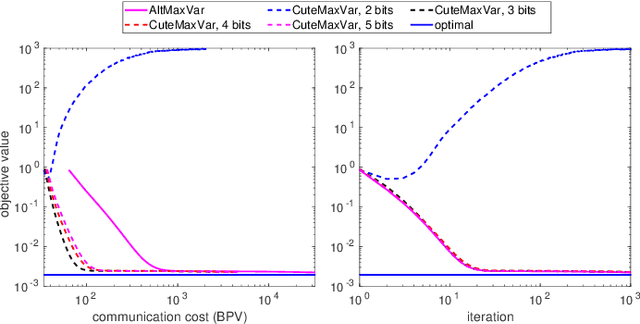
Classic and deep learning-based generalized canonical correlation analysis (GCCA) algorithms seek low-dimensional common representations of data entities from multiple ``views'' (e.g., audio and image) using linear transformations and neural networks, respectively. When the views are acquired and stored at different locations, organizations and edge devices, computing GCCA in a distributed, parallel and efficient manner is well-motivated. However, existing distributed GCCA algorithms may incur prohitively high communication overhead. This work puts forth a communication-efficient distributed framework for both linear and deep GCCA under the maximum variance (MAX-VAR) paradigm. The overhead issue is addressed by aggressively compressing (via quantization) the exchanging information between the distributed computing agents and a central controller. Compared to the unquantized version, the proposed algorithm consistently reduces the communication overhead by about $90\%$ with virtually no loss in accuracy and convergence speed. Rigorous convergence analyses are also presented -- which is a nontrivial effort since no existing generic result from quantized distributed optimization covers the special problem structure of GCCA. Our result shows that the proposed algorithms for both linear and deep GCCA converge to critical points in a sublinear rate, even under heavy quantization and stochastic approximations. In addition, it is shown that in the linear MAX-VAR case, the quantized algorithm approaches a {\it global optimum} in a {\it geometric} rate -- if the computing agents' updates meet a certain accuracy level. Synthetic and real data experiments are used to showcase the effectiveness of the proposed approach.
SegMix: Co-occurrence Driven Mixup for Semantic Segmentation and Adversarial Robustness
Aug 23, 2021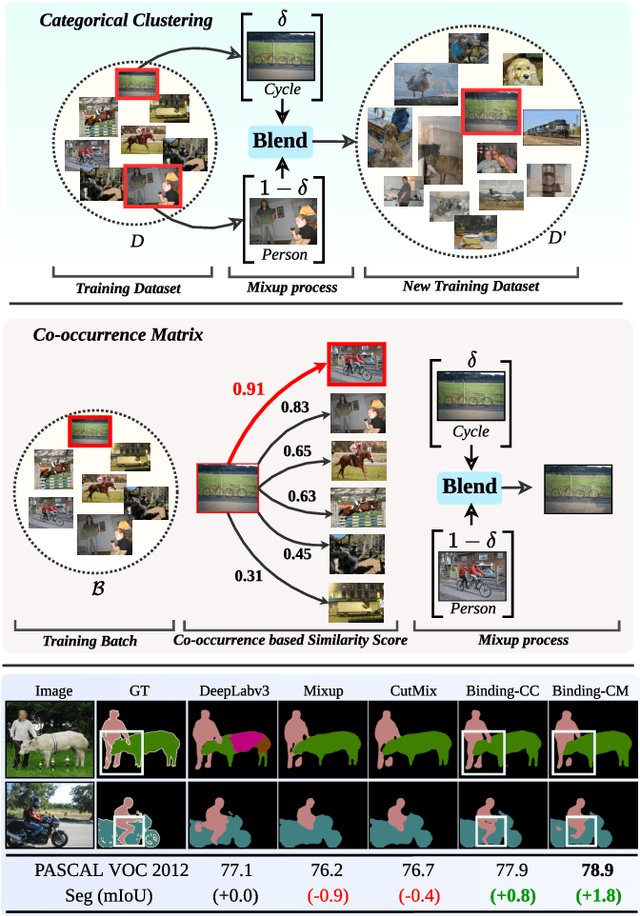
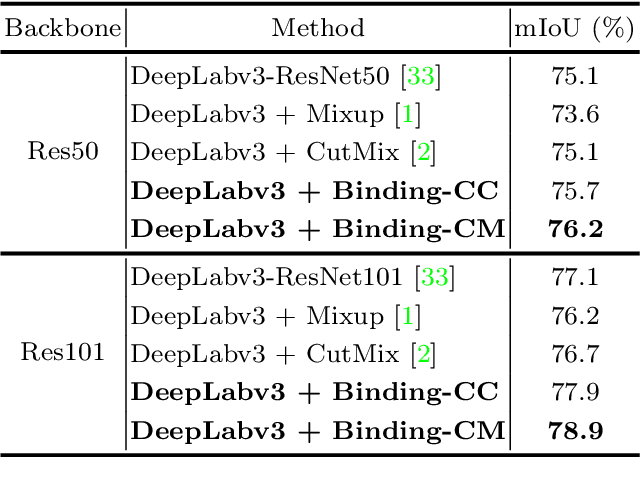
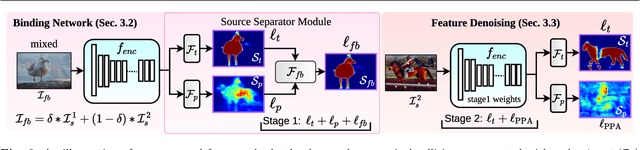

In this paper, we present a strategy for training convolutional neural networks to effectively resolve interference arising from competing hypotheses relating to inter-categorical information throughout the network. The premise is based on the notion of feature binding, which is defined as the process by which activations spread across space and layers in the network are successfully integrated to arrive at a correct inference decision. In our work, this is accomplished for the task of dense image labelling by blending images based on (i) categorical clustering or (ii) the co-occurrence likelihood of categories. We then train a feature binding network which simultaneously segments and separates the blended images. Subsequent feature denoising to suppress noisy activations reveals additional desirable properties and high degrees of successful predictions. Through this process, we reveal a general mechanism, distinct from any prior methods, for boosting the performance of the base segmentation and saliency network while simultaneously increasing robustness to adversarial attacks.
Unified Vision-Language Pre-Training for Image Captioning and VQA
Sep 24, 2019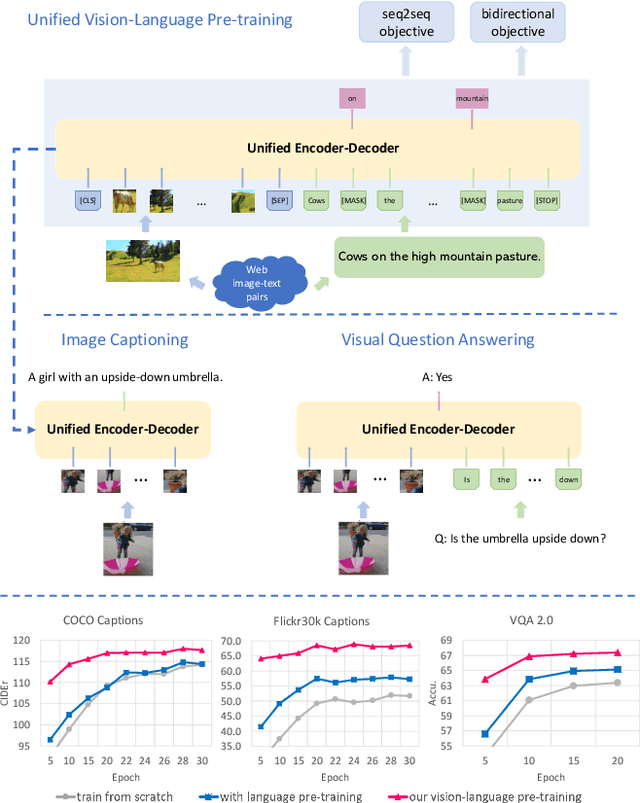
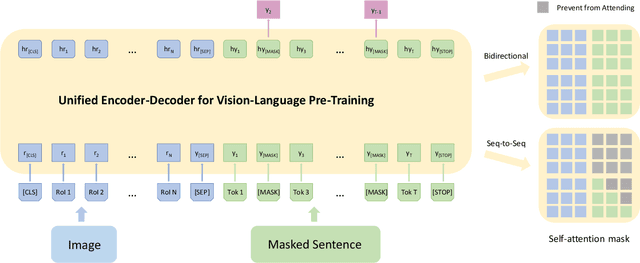
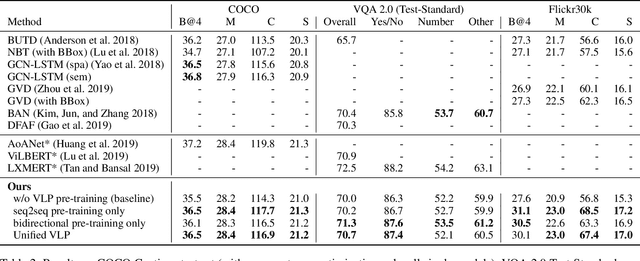
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be fine-tuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) it uses a shared multi-layer transformer network for both encoding and decoding, which differs from many existing methods where the encoder and decoder are implemented using separate models. The unified VLP model is pre-trained on a large amount of image-text pairs using the unsupervised learning objectives of two tasks: bidirectional and sequence-to-sequence (seq2seq) masked vision-language prediction. The two tasks differ solely in what context the prediction conditions on. This is controlled by utilizing specific self-attention masks for the shared transformer network. To the best of our knowledge, VLP is the first reported model that achieves state-of-the-art results on both vision-language generation and understanding tasks, as disparate as image captioning and visual question answering, across three challenging benchmark datasets: COCO Captions, Flickr30k Captions, and VQA 2.0. The code and the pre-trained models are available at https://github.com/LuoweiZhou/VLP.
One-Shot GAN: Learning to Generate Samples from Single Images and Videos
Mar 24, 2021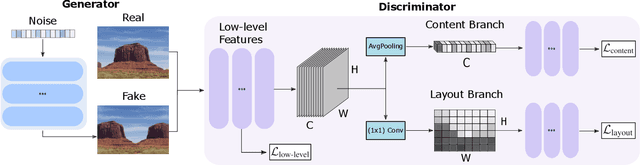
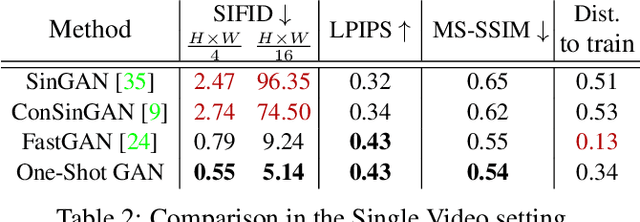

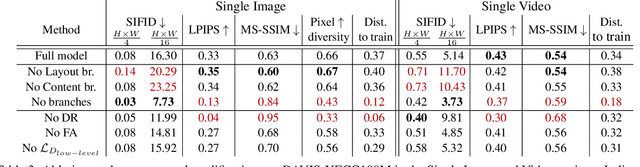
Given a large number of training samples, GANs can achieve remarkable performance for the image synthesis task. However, training GANs in extremely low-data regimes remains a challenge, as overfitting often occurs, leading to memorization or training divergence. In this work, we introduce One-Shot GAN, an unconditional generative model that can learn to generate samples from a single training image or a single video clip. We propose a two-branch discriminator architecture, with content and layout branches designed to judge internal content and scene layout realism separately from each other. This allows synthesis of visually plausible, novel compositions of a scene, with varying content and layout, while preserving the context of the original sample. Compared to previous single-image GAN models, One-Shot GAN generates more diverse, higher quality images, while also not being restricted to a single image setting. We show that our model successfully deals with other one-shot regimes, and introduce a new task of learning generative models from a single video.